
Saya yakin bahwa sebagian besar pembaca setidaknya sedikit mengenal istilah "Unicode" dan "UTF-8". Tapi apakah semua orang tahu persis apa yang ada di belakang mereka? Intinya, mereka mengacu pada standar pengkodean karakter, juga dikenal sebagai kumpulan karakter. Konsep ini muncul di zaman telegraf optik, dan bukan di zaman komputer, seperti yang dibayangkan. Kembali ke abad ke-18, terdapat kebutuhan untuk transmisi informasi yang cepat dari jarak jauh, yang mana yang disebut kode telegraf digunakan. Informasi tersebut dikodekan menggunakan alat optik, elektronik dan lainnya.
Dalam ratusan tahun yang telah berlalu sejak penemuan kode telegraf pertama, belum ada upaya nyata untuk standarisasi internasional skema pengkodean semacam itu. Bahkan dekade awal era teletype dan komputer rumah berubah sedikit. Sementara EBCDIC (pengkodean karakter 8-bit IBM, ditampilkan pada kartu berlubang di ilustrasi header) dan ASCII sedikit meningkatkan banyak hal, masih tidak ada cara untuk menyandikan koleksi karakter yang berkembang tanpa penggunaan memori yang signifikan.
Perkembangan Unicode dimulai pada akhir 1980-an, ketika pertumbuhan pertukaran informasi digital di seluruh dunia membuat kebutuhan akan sistem pengkodean tunggal menjadi lebih mendesak. Saat ini, Unicode memungkinkan kita menggunakan skema pengkodean tunggal untuk segala hal mulai dari teks bahasa Inggris dasar hingga bahasa Mandarin tradisional, Vietnam, bahkan Maya, hingga piktogram yang biasa kami sebut emoji.
Dari kode ke grafik
Kembali ke masa Kekaisaran Romawi, diketahui bahwa transmisi informasi yang cepat itu penting. Untuk waktu yang lama, ini berarti kehadiran pembawa pesan dengan menunggang kuda yang membawa pesan jarak jauh, atau yang setara. Cara meningkatkan sistem pengiriman informasi ditemukan pada abad ke-4 SM - begitulah cara telegraf air dan sistem lampu sinyal muncul. Tetapi baru pada abad ke-18 transmisi data jarak jauh menjadi benar-benar efektif.
Kami telah menulis tentang telegraf optik, juga disebut "semaphore", dalam sebuah artikel tentang sejarah komunikasi optik. Itu terdiri dari sejumlah stasiun relai, masing-masing dilengkapi dengan sistem sinyal belok yang digunakan untuk menampilkan simbol kode telegraf. Sistem Chappe bersaudara, yang digunakan oleh pasukan Prancis antara tahun 1795 dan 1850, didasarkan pada batang kayu dengan dua ujung yang dapat digerakkan (tuas), yang masing-masing dapat dipindahkan ke salah satu dari tujuh posisi. Bersama dengan empat posisi palang, semafor secara teori dapat menunjukkan 196 karakter (4x7x7). Dalam praktiknya, jumlah tersebut berkurang menjadi 92-94 posisi.
Sistem semaphore tidak terlalu banyak digunakan untuk menyandikan karakter secara langsung tetapi untuk menunjukkan string tertentu dalam buku kode. Metode tersebut menyiratkan bahwa dimungkinkan untuk menguraikan seluruh pesan menggunakan beberapa sinyal kode. Ini membuat transmisi lebih cepat dan tidak ada artinya untuk mencegat pesan.
Peningkatan performa
Kemudian telegraf optik diganti dengan yang elektrik. Ini berarti bahwa hari-hari ketika kode ditangkap oleh orang-orang yang menonton menara relai terdekat telah berakhir. Dengan dua alat telegraf yang dihubungkan dengan kawat logam, arus listrik menjadi alat untuk mentransmisikan informasi. Perubahan ini menghasilkan kode telegraf listrik baru, dan kode Morse akhirnya menjadi standar internasional (dengan pengecualian Amerika Serikat, yang terus menggunakan kode Morse Amerika di luar radiotelegrafi) sejak penemuannya di Jerman pada tahun 1848.
Kode Morse Internasional memiliki keunggulan dibandingkan kode Amerika: ia menggunakan lebih banyak tanda hubung daripada titik. Pendekatan ini memperlambat kecepatan transmisi tetapi meningkatkan penerimaan pesan di ujung saluran lainnya. Ini diperlukan ketika pesan panjang dikirim melalui beberapa mil kabel oleh operator dengan tingkat keahlian yang berbeda.
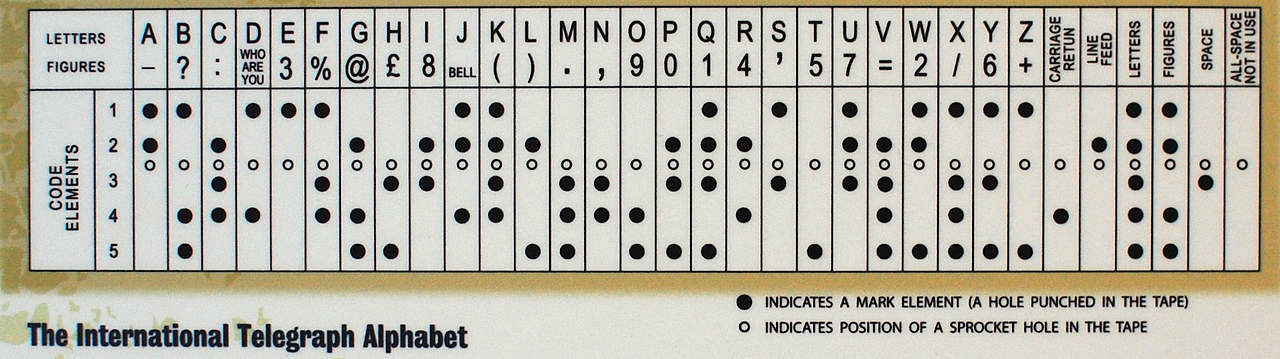
Dengan perkembangan teknologi, telegraf manual di Barat digantikan oleh telegraf otomatis. Ini menggunakan kode Baudot 5-bit, serta kode Murray yang diturunkan darinya (yang terakhir didasarkan pada penggunaan selotip kertas di mana lubang dilubangi). Sistem Murray memungkinkan untuk menyiapkan rekaman pesan terlebih dahulu, dan kemudian memuatnya ke pembaca untuk pesan yang akan dikirim secara otomatis. Kode Baudot membentuk dasar untuk International Telegraphic Alphabet Version 1 (ITA 1), dan kode Baudot-Murray yang dimodifikasi menjadi dasar untuk ITA 2, yang digunakan sampai tahun 1960-an.
Pada 1960-an, batas 5-bit per karakter tidak lagi diperlukan, yang mengarah pada pengembangan ASCII 7-bit di Amerika Serikat dan standar seperti JIS X 0201 (untuk karakter katakana Jepang) di Asia. Dalam kombinasi dengan teletypewriter, yang kemudian banyak digunakan, ini memungkinkan transmisi pesan yang cukup kompleks, termasuk karakter huruf besar dan kecil.
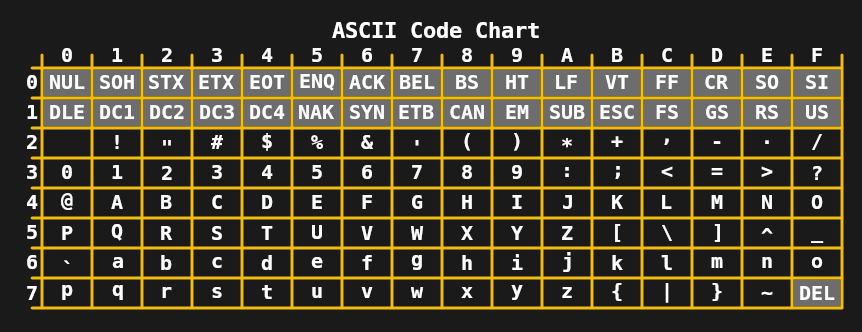
Selama tahun 1970-an dan awal 1980-an, batasan pengkodean 7- dan 8-bit seperti ASCII yang diperluas (seperti ISO 8859-1 atau Latin 1) sudah cukup untuk komputer rumah dan kebutuhan kantor arus utama. Meskipun demikian, kebutuhan untuk perbaikan sudah jelas, karena tugas umum seperti bertukar dokumen digital dan teks sering menimbulkan malapetaka dengan banyak pengkodean ISO 8859. Langkah pertama diambil pada tahun 1991 dengan 16-bit Unicode 1.0.
Pengembangan pengkodean 16-bit
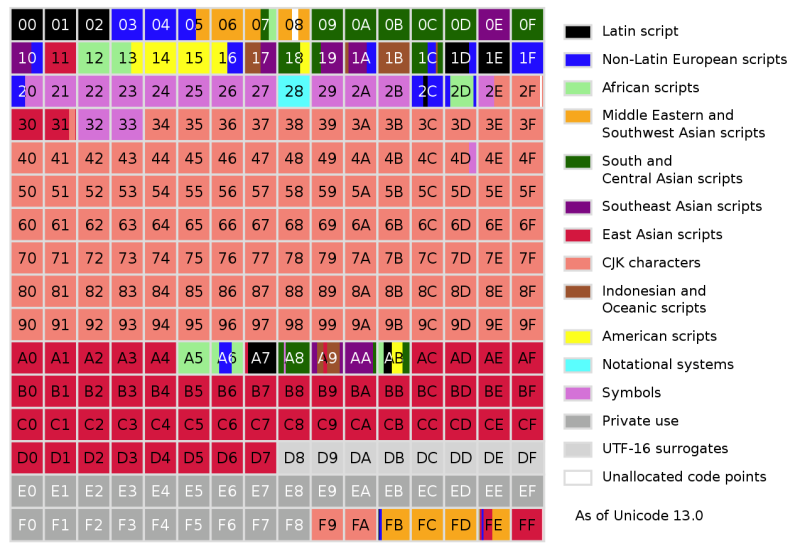
Anehnya, hanya dalam 16 bit, Unicode berhasil mencakup tidak hanya semua sistem penulisan Barat, tetapi juga banyak karakter Cina dan banyak karakter khusus yang digunakan, misalnya, dalam matematika. Dengan 16 bit yang memungkinkan hingga 65.536 titik kode, Unicode 1.0 dengan mudah menampung 7.129 karakter. Tetapi pada saat Unicode 3.1 muncul pada tahun 2001, itu berisi setidaknya 94.140 karakter.
Sekarang, dalam versi ke-13, Unicode berisi total 143.859 karakter tidak termasuk karakter kontrol. Awalnya, Unicode dimaksudkan untuk digunakan hanya untuk pengkodean sistem notasi yang sedang digunakan. Tetapi pada rilis tahun 1996 dari Unicode 2.0, menjadi jelas bahwa tujuan ini perlu dipikirkan ulang untuk menyandikan bahkan karakter langka dan historis. Untuk mencapai hal ini tanpa pengkodean 32-bit wajib untuk setiap karakter, Unicode telah berubah: ini memungkinkan tidak hanya untuk menyandikan karakter secara langsung, tetapi juga untuk menggunakan komponen, atau grafiknya.
Konsepnya agak mirip dengan gambar vektor, di mana setiap piksel tidak ditentukan, tetapi elemen yang membentuk gambar dijelaskan. Hasilnya, pengkodean Unicode Transformation Format 8 (UTF-8) mendukung 2 31 titik kode, dengan sebagian besar karakter dalam rangkaian karakter Unicode saat ini biasanya memerlukan satu atau dua byte.
Unicode untuk setiap selera dan warna
Pada titik ini, beberapa orang mungkin bingung dengan berbagai istilah yang digunakan dalam Unicode. Oleh karena itu, penting untuk dicatat di sini bahwa Unicode mengacu pada standar dan berbagai Format Transformasi Unicode adalah implementasinya. UCS-2 dan USC-4 adalah implementasi Unicode 2- dan 4-byte yang lebih lama, dengan UCS-4 identik dengan UTF-32 dan UCS-2 menggantikan UTF-16.
UCS-2, sebagai bentuk Unicode yang paling awal, masuk ke banyak sistem operasi pada tahun 1990-an, membuat transisi ke UTF-16 sebagai pilihan yang paling tidak berbahaya. Inilah sebabnya mengapa Windows dan MacOS, pengelola jendela seperti KDE, serta runtime Java dan .NET menggunakan UTF-16 secara internal.
UTF-32, seperti namanya, mengkodekan setiap karakter dalam empat byte. Agak boros, tapi bisa diprediksi sepenuhnya. Karakter UTF-8 yang sama dapat menyandikan karakter dalam rentang satu hingga empat byte. Dalam kasus UTF-32, menentukan jumlah karakter dalam string adalah aritmatika sederhana: ambil seluruh jumlah byte dan bagi dengan empat. Hal ini menyebabkan kompiler dan beberapa bahasa, seperti Python, yang memungkinkan UTF-32 untuk mewakili string Unicode.
Namun, dari semua format Unicode, UTF-8 adalah yang paling populer. Ini sebagian besar telah difasilitasi oleh World Wide Web, di mana sebagian besar situs web menyajikan dokumen HTML mereka dalam pengkodean UTF-8. Karena tata letak bidang poin kode yang berbeda dalam UTF-8, sistem penulisan Western dan banyak sistem penulisan umum lainnya cocok dalam dua byte. Dibandingkan dengan pengkodean ISO 8859 dan Shift JIS yang lama, sebenarnya teks yang sama dalam UTF-8 tidak menggunakan lebih banyak ruang daripada sebelumnya.
Dari menara optik hingga Internet
Hari-hari kurir kuda, menara relai, dan stasiun telegraf kecil telah berakhir. Teknologi komunikasi telah berkembang pesat. Bahkan hari-hari ketika teletipe menjadi hal biasa di kantor pun sulit diingat. Namun, pada setiap tahap perkembangan sejarah, umat manusia memiliki kebutuhan untuk menyandikan, menyimpan, dan mengirimkan informasi. Dan ini membawa kami ke titik di mana kami sekarang dapat langsung mengirimkan pesan ke seluruh dunia dalam sistem simbol yang dapat diterjemahkan di mana pun Anda berada.
Bagi mereka yang kebetulan beralih antara pengkodean ISO 8859 di klien email dan browser web untuk mendapatkan sesuatu yang terlihat seperti pesan teks asli, dukungan Unicode telah menjadi berkah. Saya bisa memahami orang-orang ini. Ketika 7-bit ASCII (atau EBCDIC) adalah teknologi yang tidak terbantahkan, terkadang perlu menghabiskan waktu berjam-jam untuk memilah-milah kebingungan simbolis dari dokumen digital yang diterima dari kantor Eropa atau Amerika.
Bahkan jika Unicode bukan tanpa masalah, sulit untuk tidak merasa bersyukur membandingkannya dengan dulu. Ini dia, 30 tahun Unicode.
