
Kami di ForePaaS telah bereksperimen dengan DevOps untuk beberapa waktu sekarang - pertama sebagai sebuah tim, dan sekarang di seluruh perusahaan. Alasannya sederhana: organisasi berkembang. Sebelumnya, kami hanya memiliki satu tim untuk semua kesempatan. Dia terlibat dalam arsitektur produk, desain, dan keamanan dan cepat menanggapi masalah apa pun. Sekarang kami dibagi menjadi beberapa tim dengan spesialisasi: front-end, back-end, pengembangan, operasi ...
Kami menyadari bahwa metode kami sebelumnya tidak akan begitu efektif dan kami perlu mengubah sesuatu, sambil mempertahankan kecepatan tanpa mengorbankan kualitas dan sifat buruk. sebaliknya.
Sebelumnya, kami biasa memanggil tim devops, yang sebenarnya melakukan Ops, dan juga bertanggung jawab atas pengembangan di backend. Seminggu sekali, pengembang lain memberi tahu tim DevOps layanan baru apa yang perlu diterapkan dalam produksi. Hal ini terkadang menimbulkan masalah. Di satu sisi, tim DevOps tidak begitu memahami apa yang terjadi dengan para pengembang, di sisi lain, para pengembang tidak merasa bertanggung jawab atas layanan mereka.
Baru-baru ini, orang-orang di DevOps telah mencoba membangkitkan tanggung jawab ini pada pengembang - untuk ketersediaan, keandalan, dan kualitas kode layanan. Pertama-tama, kami perlu meyakinkan para pengembang, yang khawatir dengan beban yang menimpa mereka. Mereka membutuhkan lebih banyak informasi untuk mendiagnosis masalah yang muncul, jadi kami memutuskan untuk menerapkan pemantauan sistem.
Pada artikel ini, kita akan berbicara tentang apa itu pemantauan dan apa yang dimakan dengannya, mempelajari apa yang disebut empat sinyal emas, dan membahas cara menggunakan metrik dan menelusuri untuk menjelajahi masalah saat ini.
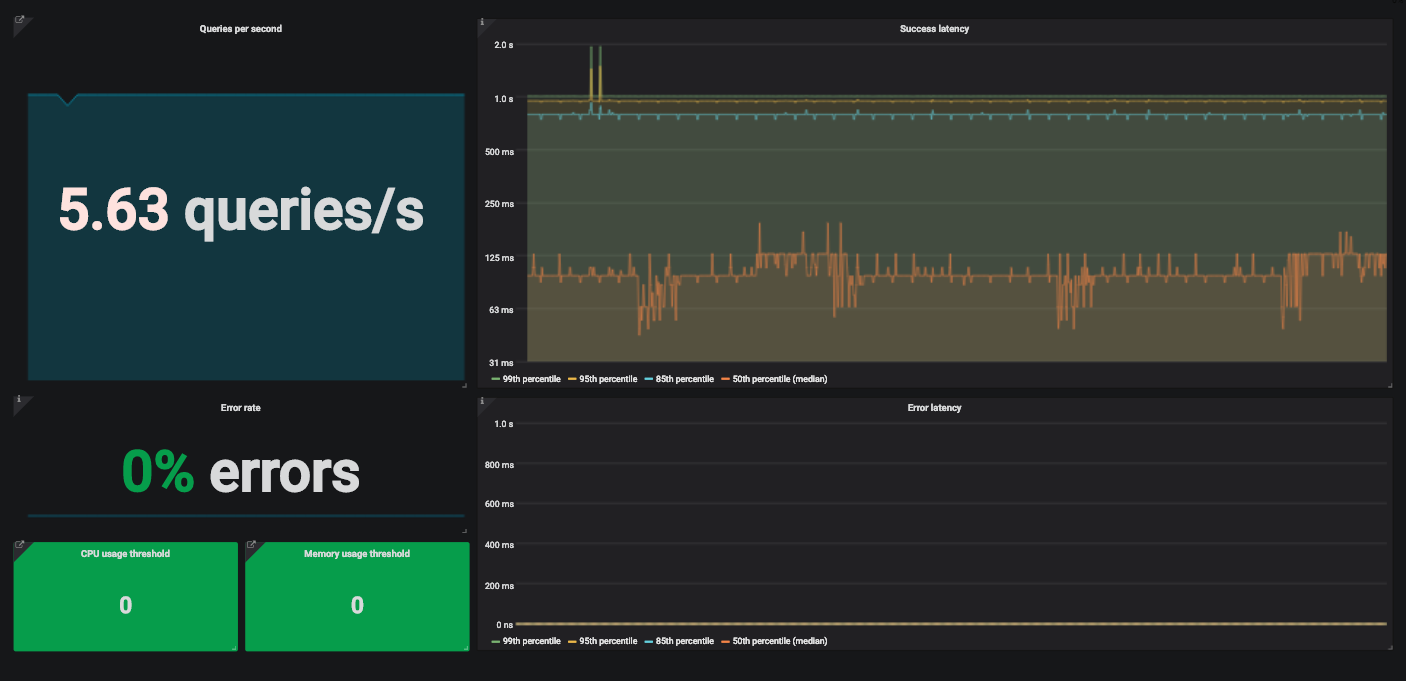
Contoh dashboard Grafana dengan empat sinyal emas untuk memantau suatu layanan.
Apa itu pemantauan?
Pemantauan adalah pembuatan, pengumpulan, agregasi, dan penggunaan metrik yang memberikan wawasan tentang kesehatan sistem.
Untuk memantau suatu sistem, kita memerlukan informasi tentang komponen perangkat lunak dan perangkat kerasnya. Informasi tersebut dapat diperoleh melalui metrik yang dikumpulkan menggunakan program khusus atau instrumentasi kode.
Instrumentasi mengubah kode Anda sehingga Anda dapat mengukur kinerjanya. Kami menambahkan kode yang tidak memengaruhi fungsionalitas produk itu sendiri, tetapi hanya menghitung dan menyediakan metrik. Katakanlah kita ingin mengukur latensi permintaan. Tambahkan kode yang akan menghitung berapa lama layanan memproses permintaan yang diterima.
Metrik yang dibuat dengan cara ini masih perlu dikumpulkan dan digabungkan dengan yang lain. Ini biasanya dilakukan dengan Metricbeat untuk pengumpulan dan Logstash untuk pengindeksan metrik di Elasticsearch . Kemudian metrik ini dapat digunakan untuk tujuan Anda sendiri. Biasanya, tumpukan ini dilengkapi dengan Kibana , yang menampilkan data yang diindeks di Elasticsearch.
Mengapa memantau?
Anda perlu memantau sistem karena berbagai alasan. Misalnya, kami memantau status sistem saat ini dan variasinya untuk menghasilkan peringatan dan mengisi dasbor. Saat kami menerima peringatan, kami mencari alasan kegagalan di dasbor. Terkadang pemantauan digunakan untuk membandingkan dua versi layanan atau menganalisis tren jangka panjang.
Apa yang harus dipantau?
Rekayasa Keandalan Situs memiliki bab bermanfaat tentang memantau sistem terdistribusi yang menjelaskan pendekatan Google untuk melacak Empat Sinyal Emas.

Beyer, B., Jones C., Murphy, N. & Petoff, J. (2016) Rekayasa Keandalan Situs. Bagaimana Google menjalankan sistem produksi. O'Reilly. Versi online gratis: https://landing.google.com/sre/sre-book/toc/index.html
- — . . — , .
- — . API . , .
- . (, 500- ) . — , .
- , , . ? . . , , .
?
Ambil tumpukan teknologi, misalnya. Kami biasanya memilih alat standar populer daripada solusi khusus. Kecuali jika fungsionalitas yang tersedia tidak cukup bagi kami. Kami menerapkan sebagian besar layanan di lingkungan Kubernetes dan melengkapi kodenya untuk mendapatkan metrik tentang setiap layanan kustom. Untuk mengumpulkan metrik ini dan mempersiapkannya untuk Prometheus, kami menggunakan salah satu pustaka klien Prometheus . Ada perpustakaan klien untuk hampir semua bahasa populer. Dalam dokumentasi, Anda dapat menemukan semua yang Anda butuhkan untuk menulis perpustakaan Anda sendiri.
Jika ini adalah layanan sumber terbuka pihak ketiga, kami biasanya mengambil eksportir yang disarankan oleh komunitas. Eksportir adalah kode yang mengumpulkan metrik dari layanan dan memformatnya untuk Prometheus. Mereka biasanya digunakan dengan layanan yang tidak menghasilkan metrik Prometheus.
Kami mengirim metrik ke dalam pipa dan menyimpannya di Prometheus sebagai deret waktu. Selain itu, kami menggunakan kube-state-metrics di Kubernetes untuk mengumpulkan dan mengirimkan metrik ke Prometheus. Kami kemudian dapat membuat dasbor dan peringatan di Grafana menggunakan permintaan Prometheus. Kami tidak akan membahas detail teknis di sini, bereksperimenlah dengan alat ini sendiri. Mereka memiliki dokumentasi terperinci, Anda dapat dengan mudah mengetahuinya.
Misalnya, mari kita lihat API sederhana yang menerima lalu lintas dan memproses permintaan yang diterima menggunakan layanan lain.
Menunda
Latensi adalah waktu yang diperlukan untuk memproses permintaan. Kami mengukur latensi secara terpisah untuk permintaan yang berhasil dan untuk kesalahan. Kami tidak ingin statistik ini tercampur.
Latensi keseluruhan biasanya diperhitungkan, tetapi ini tidak selalu merupakan pilihan yang baik. Lebih baik melacak distribusi latensi karena lebih sesuai dengan persyaratan ketersediaan. Proporsi permintaan yang diproses lebih cepat dari ambang yang diberikan adalah Indikator Tingkat Layanan (SLI) umum. Berikut adalah contoh Service Level Objective (SLO) untuk SLI ini:
"Dalam 24 jam, 99% permintaan harus diproses dalam waktu kurang dari 1 detik."
Cara paling visual untuk merepresentasikan metrik latensi adalah dengan grafik deret waktu. Kami menempatkan metrik dalam wadah dan eksportir mengumpulkannya setiap menit. Dengan cara ini, n-kuantil untuk latensi layanan dapat dihitung.
Jika 0 <n <1, dan grafik berisi nilai q, n-kuantil grafik ini sama dengan nilai yang tidak melebihi n * q dari nilai q. Artinya, median, 0,5-kuantil grafik dengan catatan x sama dengan nilai yang tidak melebihi setengah dari catatan x.
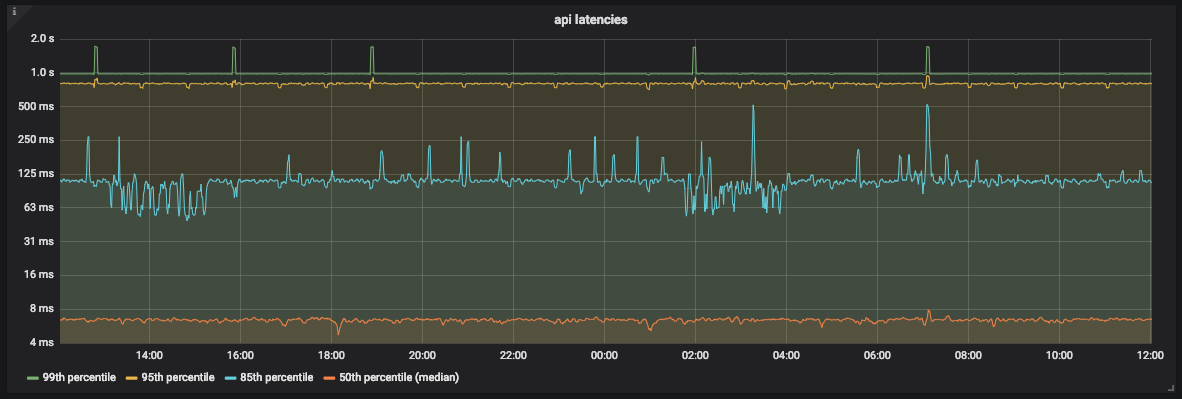
Grafik Latensi API
Seperti yang Anda lihat di grafik, sebagian besar waktu API memproses 99% permintaan dalam waktu kurang dari 1 detik. Namun, ada juga puncak sekitar 2 detik yang tidak sesuai dengan SLO kita.
Karena kami menggunakan Prometheus, kami harus sangat berhati-hati saat memilih ukuran ember. Prometheus memungkinkan ukuran bucket linier dan eksponensial. Tidak masalah mana yang kita pilih, selama kesalahan estimasi diperhitungkan .
Prometheus tidak memberikan nilai pasti untuk bilangan tersebut. Ini menentukan di bucket mana kuantil berada dan kemudian menggunakan interpolasi linier dan menghitung nilai perkiraan.
Lalu lintas
Untuk mengukur lalu lintas API, Anda perlu menghitung berapa banyak permintaan yang diterimanya setiap detik. Karena kami mengumpulkan metrik sekali dalam satu menit, kami tidak akan mendapatkan nilai pasti untuk detik tertentu. Tapi kita bisa menghitung jumlah rata-rata permintaan per detik menggunakan fungsi rate dan irate di Prometheus.
Untuk menampilkan informasi ini, kami menggunakan panel Grafana SingleStat. Ini menampilkan permintaan rata-rata saat ini per detik dan tren.

Contoh panel Grafana SingleStat dengan jumlah permintaan yang diterima API kita per detik
Jika jumlah permintaan per detik tiba-tiba berubah, kita akan melihatnya. Jika lalu lintas berkurang setengahnya dalam beberapa menit, kami akan memahami bahwa ada masalah.
Kesalahan
Mudah untuk menghitung persentase kesalahan yang jelas - bagi tanggapan HTTP 500 dengan jumlah total permintaan. Untuk lalu lintas, kami menggunakan rata-rata di sini.
Intervalnya harus sama dengan lalu lintas. Ini akan mempermudah pelacakan lalu lintas dengan kesalahan pada satu panel.
Misalkan tingkat kesalahan adalah 10% dalam lima menit terakhir dan API memproses 200 permintaan per detik. Mudah untuk menghitung bahwa, rata-rata, ada 20 kesalahan per detik.
Kejenuhan
Untuk memantau kejenuhan, Anda perlu menentukan batas layanan. Untuk API kami, kami mulai dengan mengukur sumber daya prosesor dan memori, karena kami tidak tahu mana yang lebih berpengaruh. Kubernetes dan kube-state-metrics menyediakan metrik ini untuk container.
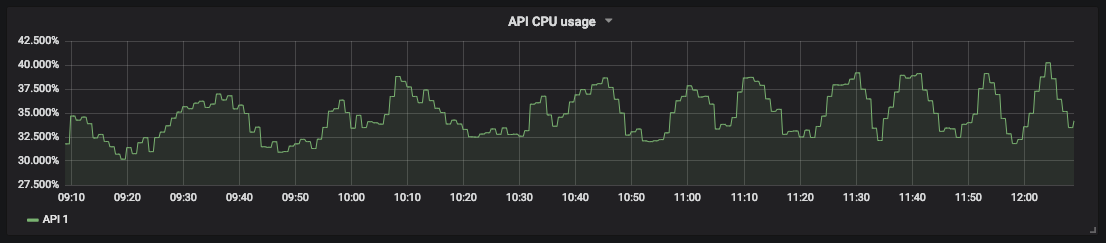
Grafik penggunaan CPU untuk
pengukuran Saturasi API kami memungkinkan Anda memprediksi waktu henti dan menjadwalkan sumber daya. Misalnya, untuk penyimpanan database, Anda dapat mengukur ruang disk kosong dan seberapa cepat ruang itu terisi untuk memahami kapan harus mengambil tindakan.
Dasbor terperinci untuk memantau layanan terdistribusi
Mari kita lihat layanan lainnya. Misalnya, API terdistribusi yang bertindak sebagai proxy untuk layanan lain. API ini memiliki banyak contoh di berbagai wilayah dan beberapa titik akhir. Masing-masing bergantung pada rangkaian layanannya sendiri. Segera menjadi sangat sulit untuk membaca grafik dengan lusinan baris. Kami membutuhkan kemampuan untuk memantau seluruh sistem, dan, jika perlu, mendeteksi kegagalan individu.
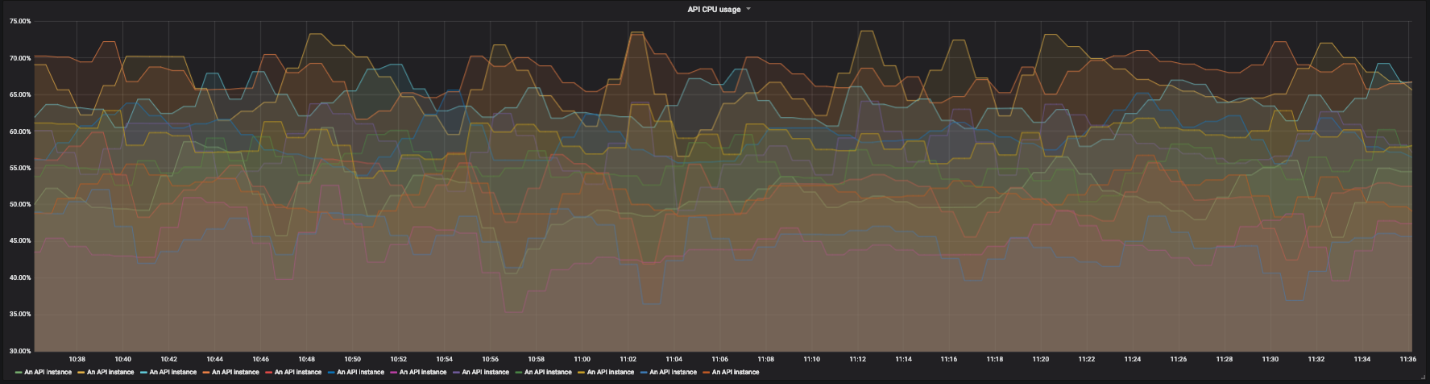
Grafik penggunaan CPU untuk 12 contoh API kami
Untuk ini kami menggunakan dasbor lihat perincian. Di setiap layar dari satu panel, kita melihat tampilan global sistem dan dapat mengklik elemen individu untuk memeriksa detailnya. Untuk saturasi, kami tidak menggunakan grafik, tetapi hanya persegi panjang berwarna yang menunjukkan penggunaan sumber daya prosesor dan memori. Jika penggunaan sumber daya melebihi ambang batas yang ditentukan, persegi panjang berubah menjadi oranye.

Indikator Penggunaan CPU dan Memori untuk Mesin
Virtual API Klik persegi panjang, buka detailnya, dan lihat beberapa persegi panjang berwarna yang mewakili berbagai instance API.

Indikator Penggunaan CPU untuk Mesin Virtual API
Jika hanya satu contoh yang bermasalah, kita dapat mengklik persegi panjang dan mencari tahu lebih detail. Di sini kita melihat wilayah instance, menerima permintaan, dan sebagainya.

Tampilan granular dari status instance API. Dari kiri ke kanan, atas ke bawah: Wilayah penyedia, nama host instance, tanggal mulai ulang terakhir, permintaan per detik, pemakaian CPU, pemakaian memori, total permintaan per jalur, dan persentase kesalahan total per jalur.
Kami melakukan hal yang sama dengan persentase kesalahan - kami mengklik dan melihat persentase kesalahan untuk setiap titik akhir API untuk memahami di mana masalahnya - di API itu sendiri atau layanan yang terkait dengannya.
Kami melakukan hal yang sama untuk penundaan dan kesalahan permintaan yang berhasil, meskipun ada nuansa di sini. Tujuan utamanya adalah untuk memastikan bahwa layanannya baik-baik saja dalam skala global. Masalahnya adalah API memiliki banyak titik akhir berbeda, yang masing-masing bergantung pada beberapa layanan. Setiap titik akhir memiliki penundaan dan lalu lintasnya sendiri.
Sulit untuk menyiapkan SLO (dan SLA) terpisah untuk setiap titik akhir layanan. Beberapa titik akhir akan memiliki latensi nominal yang lebih tinggi daripada yang lain. Dalam kasus ini, pemfaktoran ulang mungkin diperlukan. Jika SLO terpisah diperlukan, Anda perlu membagi seluruh layanan menjadi layanan yang lebih kecil. Mungkin kita akan melihat bahwa cakupan layanan kita terlalu luas.
Kami memutuskan bahwa akan lebih baik untuk memantau keseluruhan latensi. Perincian hanya memungkinkan masalah untuk diselidiki ketika deviasi latensi begitu besar untuk menarik perhatian.
Kesimpulan
Kami telah menggunakan metode ini untuk memantau sistem selama beberapa waktu sekarang dan telah memperhatikan bahwa jumlah waktu yang dibutuhkan untuk menemukan masalah dan waktu rata-rata untuk pemulihan (MTTR) telah menurun. Perincian memungkinkan kami menemukan penyebab sebenarnya dari masalah global, dan bagi kami kemampuan ini telah banyak berubah.
Tim pengembang lain juga mulai menggunakan metode ini dan hanya melihat keuntungan di dalamnya. Sekarang mereka tidak hanya bertanggung jawab atas pengoperasian layanan mereka. Mereka melangkah lebih jauh dan dapat menentukan bagaimana perubahan pada kode mempengaruhi perilaku layanan.
Empat sinyal emas tidak menyelesaikan semua masalah sama sekali, tetapi sangat membantu dengan masalah yang paling umum. Dengan hampir tanpa usaha, kami dapat meningkatkan pemantauan dan mengurangi MTTR secara signifikan. Tambahkan metrik sebanyak yang diperlukan, selama ada empat sinyal emas di antaranya.