Halo semuanya. Kami memasuki peregangan rumah: hari ini adalah artikel terakhir tentang apa yang dapat disediakan oleh ilmu data untuk memprediksi COVID-19.
Artikel pertama ada di sini . Yang kedua ada di sini .
Hari ini kita berbicara dengan Alexander Zhelubenkov tentang keputusannya untuk memprediksi penyebaran COVID-19.
Kondisi kami adalah sebagai berikut:
Diberikan : Kemampuan ilmu data kolosal, tiga spesialis berbakat.
Temukan : Cara memprediksi penyebaran COVID-19 seminggu ke depan.
Dan inilah keputusan dari Alexander Zhelubenkov
- Alexander, halo. Pertama, ceritakan sedikit tentang diri Anda dan pekerjaan Anda.
- Saya bekerja di Lamoda sebagai kepala grup analisis data dan pembelajaran mesin. Kami terlibat dalam mesin pencari dan algoritme untuk peringkat produk di katalog. Ilmu Data membuat saya tertarik ketika saya belajar di Universitas Negeri Moskow di Fakultas Matematika Komputasi dan Sibernetika.
- Pengetahuan dan keterampilan sangat berguna. Anda membuat model yang berkualitas: cukup sederhana untuk tidak berlebihan. Bagaimana Anda berhasil mencapai ini?
- Masalah deret waktu peramalan dipelajari dengan baik, dan pendekatan apa yang dapat diterapkan untuk itu dapat dimengerti. Dalam tugas kami, sampelnya cukup kecil menurut standar pembelajaran mesin - beberapa ribu pengamatan dalam data pelatihan dan hanya 560 prediksi yang perlu dibuat untuk setiap minggu (perkiraan untuk 80 wilayah untuk setiap hari pada minggu depan). Dalam kasus seperti itu, model yang lebih kasar digunakan yang bekerja dengan baik dalam praktiknya. Faktanya, saya berakhir dengan baseline yang rapi.
Sebagai model, saya menggunakan peningkatan gradien pada pohon. Anda mungkin memperhatikan bahwa model kayu out-of-the-box tidak tahu bagaimana memprediksi tren, tetapi jika kita beralih ke target tambahan, maka tren dapat diprediksi. Ternyata Anda perlu mengajarkan model untuk memprediksi jumlah kasus yang akan meningkat relatif terhadap hari ini selama X hari ke depan, di mana X dari 1 hingga 7 adalah cakrawala perkiraan.
Fitur lainnya adalah kualitas prediksi model dinilai pada skala logaritmik, yaitu, hukumannya bukan karena kesalahan Anda, tetapi berapa kali prediksi model ternyata tidak akurat. Dan ini berdampak sebagai berikut: kualitas akhir prakiraan untuk semua wilayah sangat dipengaruhi oleh keakuratan prakiraan di kawasan kecil.
Garis waktu untuk setiap wilayah diketahui: jumlah kasus di setiap hari di masa lalu dan secara harfiah beberapa karakteristik kualitatif, seperti populasi dan proporsi penduduk perkotaan. Pada dasarnya, itu saja. Sulit untuk melatih ulang data seperti itu jika validasi dilakukan secara normal dan menentukan di mana sebaiknya berhenti dalam pelatihan penguat.
- Library peningkatan gradien apa yang Anda gunakan?
- Saya dengan cara kuno - XGBoost. Saya tahu tentang LightGBM dan CatBoost, tetapi untuk tugas seperti itu, menurut saya pilihannya tidak begitu penting.
- Baik. Tapi tetap saja targetnya. Apa yang Anda ambil untuk target itu? Apakah ini logaritma hubungan dua hari atau logaritma dari nilai absolut?
- Sebagai target, saya mengambil perbedaan dalam logaritma jumlah kasus. Misalnya, jika hari ini ada 100 kasus, dan besok ada 200, maka saat meramalkan satu hari ke depan, Anda perlu belajar memprediksi logaritma pertumbuhan dua kali lipat.
Secara umum, diketahui bahwa pada minggu-minggu pertama terjadi peningkatan penyebaran virus secara eksponensial. Artinya jika kita menggunakan increment pada skala logaritmik sebagai target, maka sebenarnya akan memungkinkan untuk memprediksi sebuah konstanta dikalikan dengan horizon peramalan setiap hari. Peningkatan gradien adalah model serbaguna, dan dapat mengatasi tugas-tugas semacam itu dengan baik.
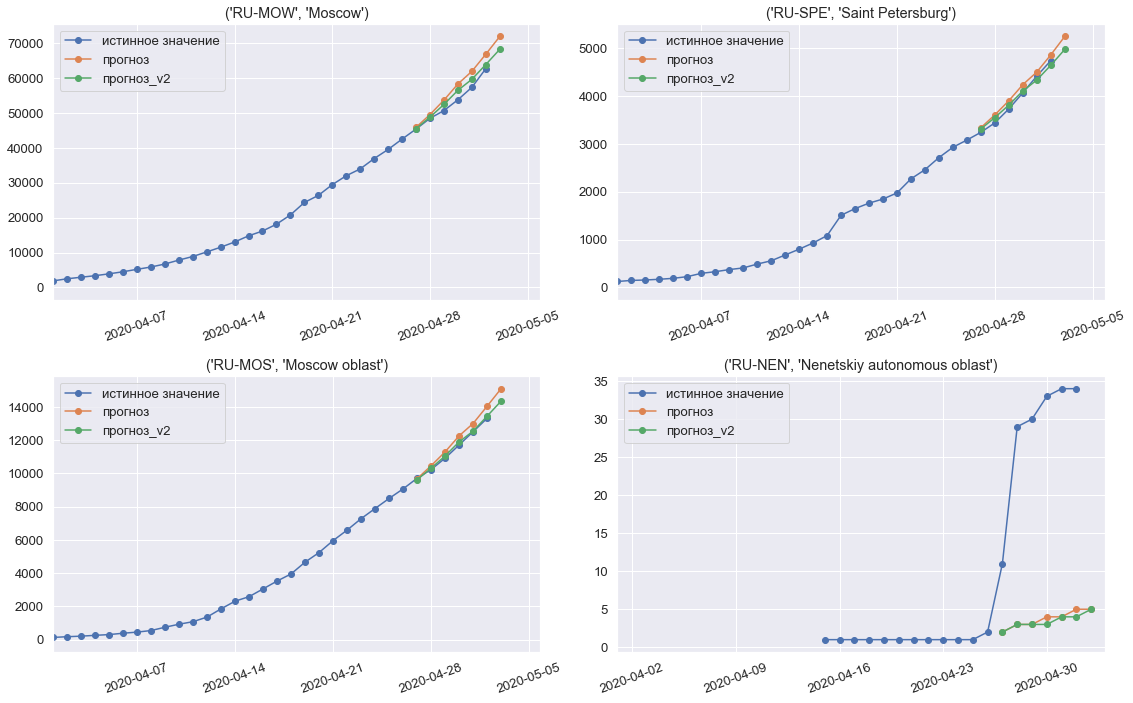
Prediksi model untuk minggu ketiga, terakhir kompetisi
- Contoh pelatihan apa yang Anda ambil?
- Untuk memprediksi wilayah, saya mengambil informasi tentang distribusi menurut negara. Tampaknya ini membantu, karena di suatu tempat pertumbuhan tajam telah melambat, dan negara-negara mulai memasuki dataran tinggi. Di wilayah Rusia, saya memotong periode awal, ketika ada beberapa kasus yang terisolasi. Untuk pelatihan, saya menggunakan data dari Februari.
- Bagaimana Anda divalidasi?
- Divalidasi dalam waktu, untuk deret waktu dan biasa dilakukan. Saya menggunakan dua minggu terakhir untuk tes. Jika kami memprediksi minggu lalu, maka untuk pelatihan kami menggunakan semua data sebelumnya. Jika kami memprediksi yang terakhir, maka kami menggunakan semua data, tanpa dua minggu terakhir.
- Apakah Anda menggunakan yang lain? Beberapa hari, 10 atau 20 hari, artinya dari sana?
- Faktor utama yang penting adalah statistik yang berbeda: rata-rata, median, peningkatan selama N hari terakhir. Untuk setiap wilayah, dapat dihitung secara terpisah. Anda juga dapat menambahkan faktor yang sama secara terpisah, hanya dihitung untuk semua wilayah sekaligus.
- Pertanyaan tentang validasi. Apakah Anda lebih memperhatikan stabilitas atau akurasi? Apa kriterianya?
- Saya melihat kualitas rata-rata model, yang diperoleh dalam dua minggu terakhir yang dipilih untuk validasi. Saat menambahkan beberapa faktor, kami mendapatkan gambaran bahwa dengan konfigurasi peningkatan yang tetap dan hanya memvariasikan parameter benih acak, kualitas prediksi dapat melonjak - yaitu, diperoleh varian yang besar. Agar tidak melatih ulang dan mendapatkan model yang lebih stabil, pada akhirnya saya tidak menggunakan faktor yang meragukan seperti itu di model akhir.
- Apa yang kamu ingat? Terkejut? Fitur yang berfungsi, atau semacam trik meningkatkan?
- Saya belajar dua pelajaran. Pertama, ketika saya memutuskan untuk memadukan dua model: linear dan boosting, dan pada saat yang sama, untuk setiap wilayah, koefisien yang digunakan untuk mengambil kedua model ini (ternyata berbeda) hanya disiapkan pada minggu lalu - yaitu selama tujuh hari. Faktanya, saya menyiapkan 1-2 koefisien untuk setiap wilayah selama 7 hari. Tetapi penemuannya adalah ini: ramalannya ternyata jauh lebih buruk dibandingkan jika saya tidak membuat pengaturan ini. Di beberapa wilayah, model tersebut sangat dilatih ulang, dan akibatnya, prakiraan di dalamnya menjadi buruk. Pada tahap ketiga kompetisi, saya memutuskan untuk tidak melakukan ini.
Dan poin kedua: tampaknya jumlah hari dari awal seharusnya berguna sebagai ciri: dari orang sakit pertama, dari orang sakit kesepuluh. Saya mencoba menambahkannya, tetapi setelah validasi, hal itu memperburuk situasi. Saya menjelaskannya seperti ini: distribusi nilai dalam sampel bergeser seiring waktu. Jika Anda belajar pada hari ke-20 dari awal penyebaran virus, maka ketika memprediksi distribusi nilai fitur ini akan berjalan tujuh hari ke depan, dan, mungkin, ini tidak memungkinkan faktor-faktor tersebut digunakan dengan manfaat.
- Anda mengatakan bahwa proporsi penduduk perkotaan memainkan peran tertentu. Lalu apa lagi?
- Ya, pangsa populasi perkotaan untuk negara dan wilayah Rusia selalu digunakan. Faktor ini secara konsisten memberikan sedikit dorongan pada kualitas prakiraan. Akibatnya, selain dari deret waktu itu sendiri, saya tidak memasukkan hal lain ke dalam model akhir. Mencoba menambahkan misc tetapi tidak berhasil.
- Apa pendapat Anda: SARIMA adalah abad terakhir?
- Model autoregressive - moving average - lebih sulit untuk diatur, dan lebih mahal untuk menambahkan faktor tambahan padanya, meskipun saya yakin bahwa dengan model (S) ARIMA (X) akan memungkinkan untuk membuat prediksi yang baik, tetapi tidak sebagus dibandingkan dengan meningkatkan.
- Dan untuk jangka waktu yang lebih lama dari seminggu, Anda dapat membuat prediksi, bagaimana menurut Anda?
- Ini akan menarik. Awalnya, pihak penyelenggara memiliki ide untuk mengumpulkan prakiraan jangka panjang. Bulan ini sepertinya merupakan titik balik ketika Anda masih dapat mencoba pendekatan yang saya lakukan.
- Menurutmu apa yang akan terjadi nanti?
- Kita perlu membangun kembali modelnya, lihat. Omong-omong, solusi saya dapat ditemukan di sini:
github.com/Topspin26/sberbank-covid19-challenge Untuk
berita ilmu data COVID terbaru dari komunitas internasional, kunjungi https://www.kaggle.com/tags/covid19 . Dan tentu saja kami mengundang Anda ke saluran #coronavirus di opendatascience.slack.com (diundang oleh ods.ai ).