Namun, menulis program sepenuhnya dalam bahasa assembly tidak hanya panjang, suram dan sulit, tetapi juga agak konyol - karena abstraksi tingkat tinggi diciptakan untuk tujuan ini, untuk mengurangi waktu pengembangan dan menyederhanakan proses pemrograman. Oleh karena itu, paling sering, fungsi yang dioptimalkan dengan baik diambil secara terpisah ditulis dalam bahasa assembly, yang kemudian dipanggil dari bahasa tingkat yang lebih tinggi seperti C ++ dan C #.
Berdasarkan ini, lingkungan pemrograman yang paling nyaman adalah Visual Studio, yang sudah menyertakan MASM. Anda dapat menghubungkannya ke proyek C / C ++ melalui menu konteks proyek Ketergantungan Build - Penyesuaian Bangun ..., dengan mencentang kotak di sebelah masm, dan program assembler itu sendiri akan ditempatkan di file dengan .asm ekstensi (di properti di mana Jenis Item harus diatur ke Microsoft Macro Assembler). Ini akan memungkinkan tidak hanya kompilasi dan pemanggilan program bahasa assembly tanpa gerakan yang tidak perlu - tetapi juga melakukan debugging ujung-ke-ujung, "jatuh melalui" ke sumber assembler langsung dari c ++ atau c # (termasuk breakpoint di dalam daftar assembly) , serta melacak status register bersama dengan variabel biasa di jendela Watch.
Penyorotan sintaks
Visual Studio tidak memiliki penyorotan sintaks bawaan untuk assembler dan pencapaian lain dari struktur IDE modern; tetapi dapat diberikan dengan ekstensi pihak ketiga.
AsmHighlighter secara historis adalah yang pertama dengan fungsionalitas minimal dan set perintah yang tidak lengkap - tidak hanya AVX yang hilang, tetapi juga beberapa standar, khususnya fsqrt. Fakta ini mendorong saya untuk menulis ekstensi saya sendiri -
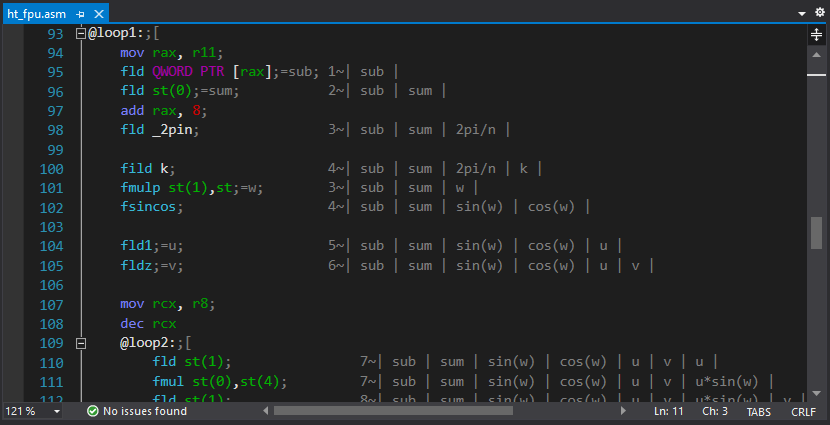
ASM Advanced Editor . Selain menyoroti dan menciutkan bagian kode (menggunakan komentar "; [", "; [+" dan ";]"), ini mengikat petunjuk ke register yang muncul saat mengarahkan kursor ke bawah kode (juga melalui komentar). Ini terlihat seperti ini:
;rdx=
atau seperti ini:
mov rcx, 8;=
Petunjuk untuk perintah juga ada, tetapi dalam bentuk percobaan - ternyata akan membutuhkan lebih banyak waktu untuk mengisinya sepenuhnya daripada menulis ekstensinya sendiri.
Tiba-tiba juga ternyata tombol biasa untuk memberi anotasi / mengomentari bagian kode yang disorot berhenti berfungsi. Oleh karena itu, saya harus menulis ekstensi lain di mana fungsi ini digantung pada tombol yang sama, dan kebutuhan untuk tindakan ini atau itu dipilih secara otomatis.
Asm bung- muncul beberapa saat kemudian. Di dalamnya, penulis mengambil jalan lain dan memfokuskan upayanya pada referensi perintah bawaan dan pelengkapan otomatis, termasuk tag pelacakan. Pelipatan kode juga ada di sana (menurut "#region / #end region"), tetapi tampaknya belum ada pengikatan komentar ke register.
32 vs. 64
Sejak platform 64-bit muncul, menulis 2 versi aplikasi telah menjadi norma. Saatnya berhenti dari ini! Berapa banyak warisan yang bisa Anda tarik. Hal yang sama berlaku untuk ekstensi - Anda hanya dapat menemukan prosesor tanpa SSE2 di museum - selain itu, tanpa SSE2 aplikasi 64-bit tidak akan berfungsi. Tidak akan ada kesenangan pemrograman jika Anda menulis 4 varian fungsi yang dioptimalkan untuk setiap platform.
Keuntungan dari platform 64-bit sama sekali tidak ada dalam register "lebar" - tetapi dalam kenyataan bahwa jumlah register ini berlipat ganda - masing-masing 16 buah, baik untuk keperluan umum maupun XMM / YMM. Ini tidak hanya menyederhanakan pemrograman, tetapi juga secara signifikan mengurangi akses memori.
FPU
Jika sebelumnya tidak ada tempat tanpa FPU, tk. fungsi dengan bilangan real meninggalkan hasil di atas tumpukan, kemudian pada platform 64-bit pertukaran berlangsung tanpa partisipasinya menggunakan register xmm dari ekstensi SSE2. Intel juga secara aktif merekomendasikan untuk tidak menggunakan FPU dan mendukung SSE2 dalam pedomannya. Namun, ada peringatan: FPU memungkinkan Anda melakukan penghitungan dengan presisi 80-bit - yang dalam beberapa kasus dapat menjadi sangat penting. Oleh karena itu, dukungan FPU belum kemana-mana, dan sudah pasti tidak layak untuk dianggap sebagai teknologi yang ketinggalan jaman. Misalnya, perhitungan sisi miring dapat dilakukan "langsung" tanpa takut meluap,
yaitu
fld x fmul st(0), st(0) fld y fmul st(0), st(0) faddp st(1), st(0) fsqrt fstp hypot
Kesulitan utama dalam memprogram FPU adalah pengaturan tumpukannya. Untuk menyederhanakan, sebuah utilitas kecil telah ditulis yang secara otomatis menghasilkan komentar dengan status tumpukan saat ini (direncanakan untuk menambahkan fungsionalitas serupa secara langsung ke ekstensi utama untuk penyorotan sintaks - tetapi kami tidak pernah melakukannya)
Contoh pengoptimalan: Transformasi Hartley
Kompiler C ++ modern cukup pintar untuk secara otomatis membuat vektor kode untuk tugas-tugas sederhana seperti menjumlahkan angka dalam larik atau vektor yang berputar, mengenali pola yang sesuai dalam kode. Oleh karena itu, mendapatkan peningkatan kinerja yang signifikan pada tugas-tugas primitif bukanlah sesuatu yang tidak akan berhasil - sebaliknya, mungkin ternyata program Anda yang sangat dioptimalkan berjalan lebih lambat daripada yang dihasilkan oleh kompilator. Tetapi Anda juga tidak boleh menarik kesimpulan luas dari ini - segera setelah algoritme menjadi sedikit lebih rumit dan tidak jelas untuk pengoptimalan, semua keajaiban pengoptimalan kompiler menghilang. Peningkatan kinerja sepuluh kali lipat masih dimungkinkan melalui pengoptimalan manual pada tahun 2021.
Jadi, sebagai tugas, kami mengambil algoritme (lambat) Hartley mengubah :
Kode
static void ht_csharp(double[] data, double[] result)
{
int n = data.Length;
double phi = 2.0 * Math.PI / n;
for (int i = 0; i < n; ++i)
{
double sum = 0.0;
for (int j = 0; j < n; ++j)
{
double w = phi * i * j;
sum += data[j] * (Math.Cos(w) + Math.Sin(w));
}
result[i] = sum / Math.Sqrt(n);
}
}
Ini juga cukup sepele untuk vektorisasi otomatis (kita akan lihat nanti), tetapi memberikan sedikit lebih banyak ruang untuk pengoptimalan. Nah, versi optimal kami akan terlihat seperti ini:
kode (komentar dihapus)
ht_asm PROC local sqrtn:REAL10 local _2pin:REAL10 local k:DWORD local n:DWORD and r8, 0ffffffffh mov n, r8d mov r11, rcx xor rcx, rcx mov r9, r8 dec r9 shr r9, 1 mov r10, r8 sub r10, 2 shl r10, 3 finit fld _2pi fild n fdivp st(1), st fstp _2pin fld1 fild n fsqrt fdivp st(1), st ; mov rax, r11 mov rcx, r8 fldz @loop0: fadd QWORD PTR [rax] add rax, 8 loop @loop0 fmul st, st(1) fstp QWORD PTR [rdx] fstp sqrtn add rdx, 8 mov k, 1 @loop1: mov rax, r11 fld QWORD PTR [rax] fld st(0) add rax, 8 fld _2pin fild k fmulp st(1),st fsincos fld1;=u fldz;=v mov rcx, r8 dec rcx @loop2: fld st(1) fmul st(0),st(4) fld st(1) fmul st,st(4) faddp st(1),st fxch st(1) fmul st, st(4) fxch st(2) fmul st,st(3) fsubrp st(2),st fld st(0) fadd st, st(2) fmul QWORD PTR [rax] faddp st(5), st fld st(0) fsubr st, st(2) fmul QWORD PTR [rax] faddp st(6), st add rax, 8 loop @loop2 fcompp fcompp fld sqrtn fmul st(1), st fxch st(1) fstp QWORD PTR [rdx] fmulp st(1), st fstp QWORD PTR [rdx+r10] add rdx,8 sub r10, 16 inc k dec r9 jnz @loop1 test r10, r10 jnz @exit mov rax, r11 fldz mov rcx, r8 shr rcx, 1 @loop3:;[ fadd QWORD PTR [rax] fsub QWORD PTR [rax+8] add rax, 16 loop @loop3;] fld sqrtn fmulp st(1), st fstp QWORD PTR [rdx] @exit: ret ht_asm ENDP
Harap diperhatikan: tidak ada loop yang membuka gulungan, tidak ada SSE / AVX, tidak ada tabel cosinus, tidak ada pengurangan kompleksitas karena algoritme transformasi "cepat". Satu-satunya pengoptimalan eksplisit adalah komputasi sinus / kosinus berulang di loop dalam algoritme langsung di register FPU.
Karena kita berbicara tentang transformasi integral, selain kecepatan, kita juga tertarik pada keakuratan perhitungan dan tingkat kesalahan yang terakumulasi. Dalam hal ini, sangat sederhana untuk menghitungnya - dengan melakukan dua transformasi berturut-turut, kita harus mendapatkan (secara teori) data awal. Dalam praktiknya, mereka akan sedikit berbeda, dan akan dimungkinkan untuk menghitung kesalahan melalui deviasi standar dari hasil yang diperoleh dari hasil analitis.
Hasil dari pengoptimalan otomatis program c ++ juga dapat sangat bergantung pada pengaturan parameter compiler dan pilihan set instruksi tambahan yang valid (SSE / AVX / etc). Namun, ada dua nuansa:
- Kompiler modern cenderung menghitung segala sesuatu yang mungkin pada tahap kompilasi - oleh karena itu, sangat mungkin dalam kode yang dikompilasi, alih-alih algoritme, untuk melihat nilai yang telah dihitung sebelumnya, yang, ketika mengukur kinerja, akan memberi kompiler keuntungan 100500 waktu. Untuk menghindari ini, pengukuran saya menggunakan fungsi eksternal nol (), yang menambahkan ambiguitas ke parameter input.
- « AVX» — , AVX. . – , AVX .
Parameter optimasi yang paling menarik adalah Floating Point Model, yang mengambil nilai Precise | Strict | Fast. Dalam kasus Fast, penyusun diperbolehkan melakukan transformasi matematis apa pun atas kebijakannya sendiri (termasuk kalkulasi berulang) - pada kenyataannya, hanya dalam mode ini vektorisasi otomatis terjadi.
Jadi, kompiler Visual Studio 2019, kerangka kerja target AVX2, Model Titik Mengambang = Tepat. Untuk membuatnya lebih menarik, ini akan mengukur dari proyek c # pada larik 10.000 elemen:
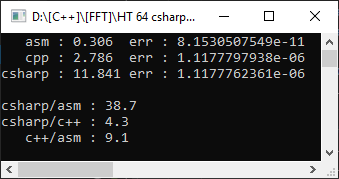
C #, seperti yang diharapkan, ternyata lebih lambat dari C ++, dan fungsi assembler ternyata 9 kali lebih cepat! Namun, terlalu dini untuk bersukacita - mari kita atur Model Titik Mengambang = Cepat:

Seperti yang Anda lihat, ini membantu mempercepat kode secara signifikan dan jeda dari pengoptimalan manual hanya 1,8 kali. Tapi yang tidak berubah adalah kesalahannya. Bahwa opsi lain memberikan kesalahan 4 digit signifikan - dan ini penting dalam perhitungan matematis.
Dalam hal ini, versi kami ternyata lebih cepat dan lebih akurat. Tapi ini tidak selalu terjadi - dan memilih FPU untuk menyimpan hasilnya, kita pasti akan kehilangan kemungkinan pengoptimalan dengan vektorisasi. Juga, tidak ada yang melarang menggabungkan FPU dan SSE2 dalam kasus-kasus yang masuk akal (khususnya, saya menggunakan pendekatan ini dalam implementasi aritmatika ganda-ganda , setelah menerima percepatan 10 kali lipat selama perkalian).
Pengoptimalan lebih lanjut dari transformasi Hartley terletak pada bidang yang berbeda dan (untuk ukuran yang berubah-ubah) memerlukan algoritme Bluestein, yang juga penting untuk keakuratan kalkulasi menengah. Nah, proyek ini bisa diunduh di GitHub , dan sebagai bonus juga ada beberapa fungsi untuk menjumlahkan / menskalakan array untuk FPU / SSE2 / AVX (untuk tujuan pendidikan).
Apa yang harus dibaca
Literatur tentang assembler dalam jumlah besar. Tetapi ada beberapa sumber utama:
1. Dokumentasi resmi dari Intel . Tidak ada yang berlebihan, kemungkinan kesalahan ketik minimal (yang ada di mana-mana dalam literatur tercetak).
2. Direktori online , diambil dari dokumentasi resmi.
3. Situs Agner Fogh , pakar pengoptimalan yang diakui. Juga berisi contoh kode C ++ yang dioptimalkan menggunakan intrinsics.
4. FPU HANYA .
5.40 Praktik Dasar dalam Pemrograman Bahasa Assembly .
6. Semua yang perlu Anda ketahui untuk memulai pemrograman untuk Windows versi 64-bit .
Lampiran: Mengapa tidak menggunakan Intrinsics saja?
Teks tersembunyi
, , , - — , SIMD- . — .
:
:
- . DOS , – .
- . – .
- . , , (FPU). . , //etc.
- - – , , . , , .
- , C++ , - SIMD-. 32- XMM8 XMM0 / XMM7 – . — , , , . – , C++.
- , . , – Microsoft , C++.