Bisa dibilang, artikel ini adalah kelanjutan dari artikel kami tentang penentuan ukuran di Habré . Tetapi contoh kehidupan nyata muncul di sini, jadi jika ada kebutuhan akan kesinambungan, mulailah dengan artikel itu, lalu kembali ke sini. Semua detail ada di bawah potongan.
Artikel ini didasarkan pada Tolok Ukur dan ukuran klaster Elasticsearch Anda untuk log dan metrik di blog Elastic. Kami memodifikasinya sedikit dan membuang contoh dengan Elastic berbasis cloud.
Sumber daya perangkat keras cluster Elasticsearch
Kinerja cluster Elasticsearch terutama bergantung pada cara Anda menggunakannya dan apa yang berjalan di bawahnya (dalam artian perangkat kerasnya). Perangkat keras ini memiliki ciri-ciri sebagai berikut:
Kubah
Vendor merekomendasikan penggunaan SSD jika memungkinkan. Namun, jelas, ini mungkin tidak terjadi di mana-mana, jadi arsitektur panas-hangat-dingin dan Index Lifecycle Management (ILM) siap melayani Anda.
Elasticsearch tidak memerlukan penyimpanan redundan (Anda dapat melakukannya tanpa RAID 1/5/10), skenario penyimpanan log atau metrik biasanya memiliki setidaknya satu replika untuk toleransi kesalahan minimal.
Penyimpanan
Memori di server dibagi menjadi:
JVM Heap. Menyimpan metadata tentang cluster, indeks, segmen, segmen, dan data bidang dokumen. Idealnya, Anda harus mengalokasikan 50% dari RAM yang tersedia untuk ini.
Cache OS. Elasticsearch akan menggunakan sisa memori yang tersedia untuk menyimpan data, yang secara dramatis akan meningkatkan kinerja dengan mencegah pembacaan disk selama pencarian teks lengkap, agregasi nilai dokumen, dan penyortiran. Dan jangan lupa untuk menonaktifkan swap (file swap) untuk menghindari pembilasan konten RAM ke disk dan kemudian membacanya (ini lambat!).
CPU
Node Elasticsearch memiliki apa yang disebut. kumpulan benang dan antrian benang yang menggunakan sumber daya komputasi yang tersedia. Jumlah dan kinerja inti CPU menentukan kecepatan rata-rata dan throughput puncak operasi data di Elasticsearch. Paling sering ini adalah 8-16 core.
Jaringan
Performa jaringan - bandwidth dan latensi dapat secara signifikan memengaruhi komunikasi antara node Elasticsearch dan komunikasi antara kluster Elasticsearch. Harap dicatat bahwa secara default pemeriksaan ketersediaan node dilakukan setiap detik dan jika node tidak melakukan ping dalam 30 detik, itu ditandai sebagai tidak tersedia dan ditutup dari cluster.
Mengubah ukuran cluster Elasticsearch berdasarkan volume penyimpanan
Menyimpan log dan metrik biasanya membutuhkan ruang disk dalam jumlah besar, jadi sebaiknya gunakan jumlah data ini untuk menentukan ukuran klaster Elasticsearch. Berikut adalah beberapa pertanyaan untuk memahami struktur data yang perlu dikelola dalam sebuah cluster:
- Berapa banyak data mentah (GB) yang akan kami indeks per hari?
- Berapa hari kami akan menyimpan data?
- Berapa hari di zona panas?
- Berapa hari di zona hangat?
- Berapa banyak replika yang akan digunakan?
Dianjurkan untuk meletakkan 5% atau 10% di atas dan agar 15% dari total ruang disk selalu tersedia. Sekarang mari kita coba menghitung kasus ini.
Total ukuran data (GB) = Jumlah data mentah per hari (GB) * Jumlah hari penyimpanan * (Jumlah replika + 1).
Penyimpanan total (GB) = Total data (GB) * (1 + 0,15 ruang penyimpanan + 0,1 penyimpanan tambahan).
Jumlah total node data = OKRVVERH (Ukuran data total (GB) / Ukuran memori per node data / Memori: rasio data). Dalam kasus instalasi besar, lebih baik menyimpan satu node tambahan lagi.
Elastic merekomendasikan rasio memori berikut: data untuk berbagai jenis node: hot → 1:30 (30 GB ruang disk per gigabyte memori), warm → 1: 160, cold → 1: 500). OKRVVERKH - mengelilingi ke bilangan bulat terdekat yang lebih tinggi.
Contoh perhitungan cluster kecil
Anggaplah ~ 1 GB data datang setiap hari, yang perlu disimpan selama 9 bulan.
Total data (GB) = 1 GB x (9 bulan x 30 hari) x 2 = 540 GB
Penyimpanan total (GB) = 540 GB x (1 + 0,15 + 0,1) = 675 GB
Jumlah total node data = 675 GB / 8 GB RAM / 30 = 3 node.
Contoh penghitungan cluster besar
Anda mendapatkan 100 GB per hari, dan Anda akan menyimpan data ini selama 30 hari di zona panas dan 12 bulan di zona hangat. Anda memiliki 64 GB memori per node, 30 GB dialokasikan untuk JVM Heap dan sisanya untuk cache OS. Rasio memori yang disarankan: data untuk zona panas adalah 1:30, untuk zona hangat - 1: 160.
Jadi, jika Anda mendapatkan 100 GB per hari dan perlu menyimpan data ini selama 30 hari, kami mendapatkan:
Jumlah total data (GB) di zona panas = (100 GB x 30 hari * 2) = 6000 GB
Total Penyimpanan Zona Panas (GB) = 6000 GB x (1 + 0,15 + 0,1) = 7500 GB
Total Node Data Zona Panas = OKRVUPH ( 7500 / 64/30) + 1 = 5 node
Total data (GB) di zona hangat= (100 GB x 365 hari * 2) = 73.000 GB
Penyimpanan total (GB) di zona hangat = 73.000 GB x (1 + 0,15 + 0,1) = 91.250 GB
Jumlah total node data di zona hangat = OKRVVERKH (91.250 / 64/160) + 1 = 10 knot
Jadi, kita mendapat 5 knot untuk zona panas dan 10 knot untuk buah hangat. Untuk zona dingin, perhitungannya serupa, tetapi rasio memori: datanya sudah menjadi 1: 500.
Tes kinerja
Setelah ukuran cluster ditentukan, perlu dipastikan bahwa matematika berfungsi di kehidupan nyata.
Pengujian ini menggunakan alat yang sama yang digunakan teknisi Elasticsearch, Rally . Sangat mudah untuk menyebarkan dan menjalankan dan sepenuhnya dapat disesuaikan, sehingga beberapa skenario (trek) dapat diuji.
Untuk mempermudah analisis hasil, pengujian dibagi menjadi dua bagian: pengindeksan dan kueri penelusuran. Pengujian akan menggunakan data dari trek Metricbeat dan log server web .
Pengindeksan
Pengujian menjawab pertanyaan-pertanyaan berikut:
- Berapa throughput maksimum untuk cluster pengindeksan?
- Berapa banyak data yang dapat diindeks per hari?
- Apakah cluster lebih besar atau lebih kecil dari ukuran yang sesuai?
Tes ini menggunakan cluster 3-node dengan konfigurasi berikut untuk setiap node:
- 8 vCPU;
- HDD;
- 32 GB / 16 tumpukan.
Indexing Test # 1
Dataset yang digunakan untuk pengujian adalah data Metricbeat dengan karakteristik sebagai berikut:
- 1.079.600 dokumen;
- Volume data: 1,2 GB;
- Rata-rata ukuran dokumen: 1,17 KB.
Selanjutnya akan dilakukan beberapa pengujian untuk menentukan ukuran paket yang optimal dan jumlah thread yang optimal.
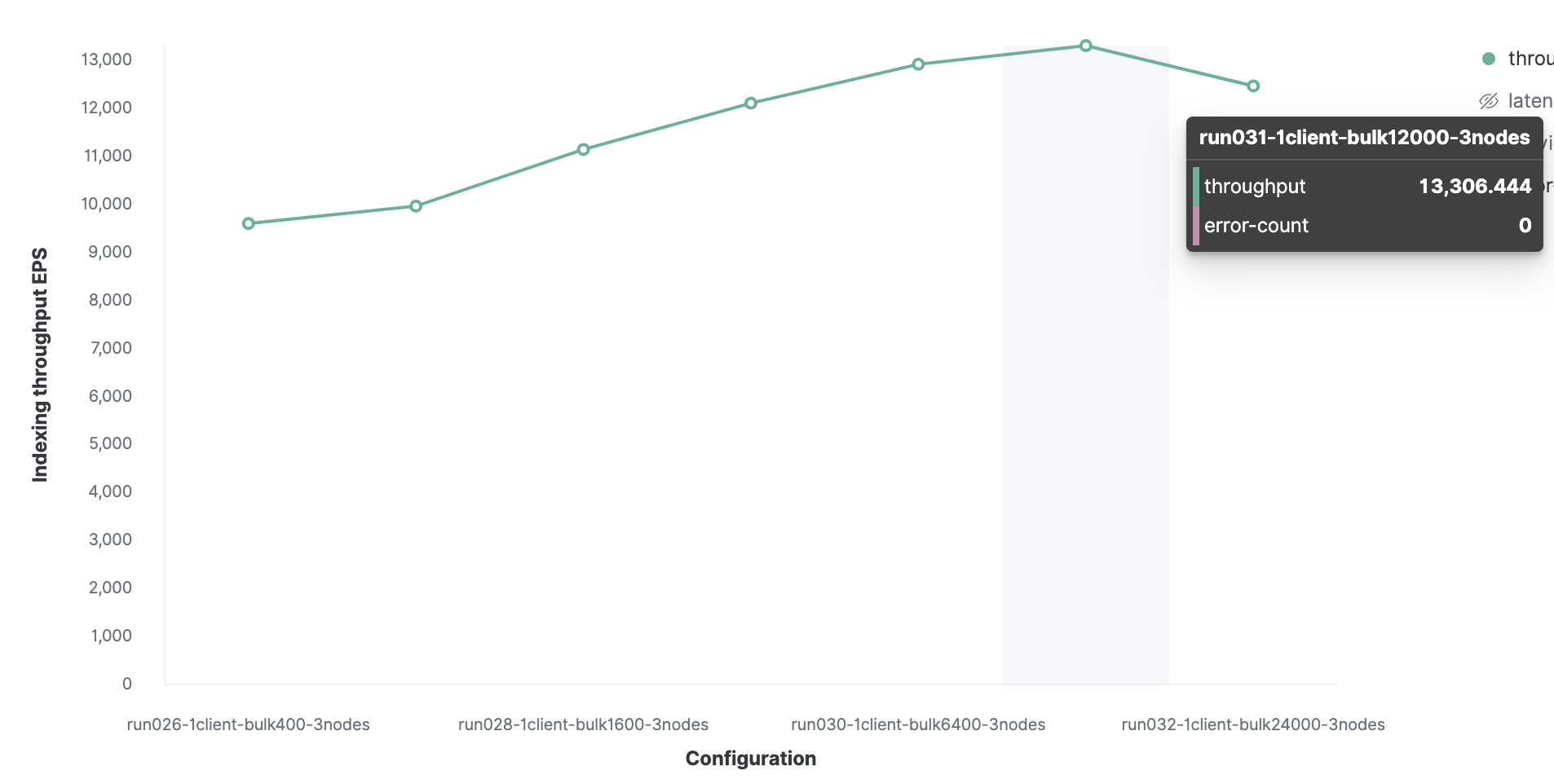
Semuanya dimulai dengan 1 klien Rally untuk menemukan ukuran paket yang optimal. Awalnya, 100 dokumen dimuat, lalu jumlahnya berlipat ganda pada peluncuran berikutnya. Hasilnya adalah ukuran batch optimal dari 12.000 dokumen (sekitar 13,7 MB). Seiring dengan bertambahnya ukuran paket, kinerja mulai menurun.
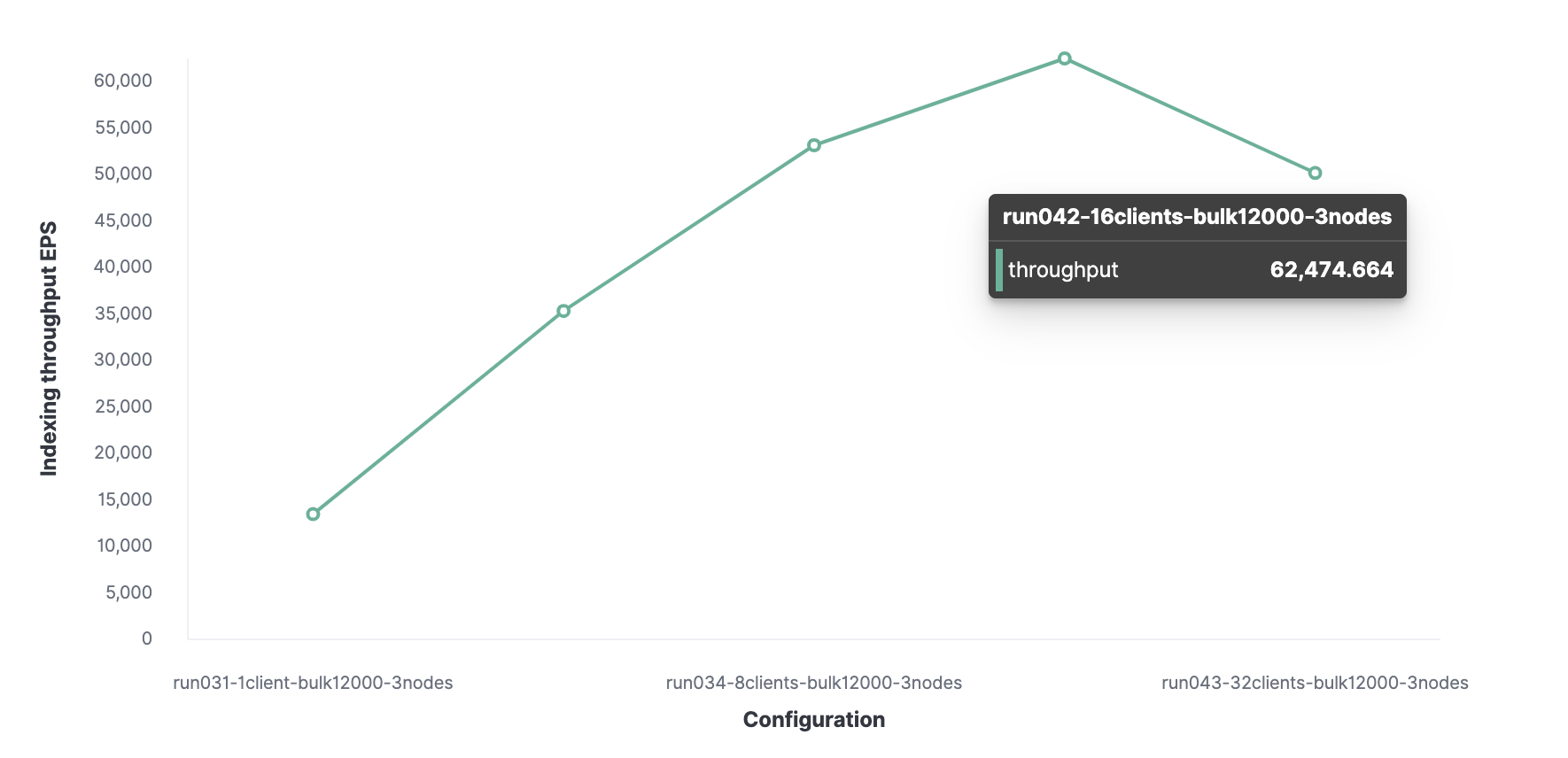
Kemudian, dengan menggunakan metode serupa, 16 adalah jumlah klien optimal untuk mencapai 62.000 peristiwa yang diindeks per detik.
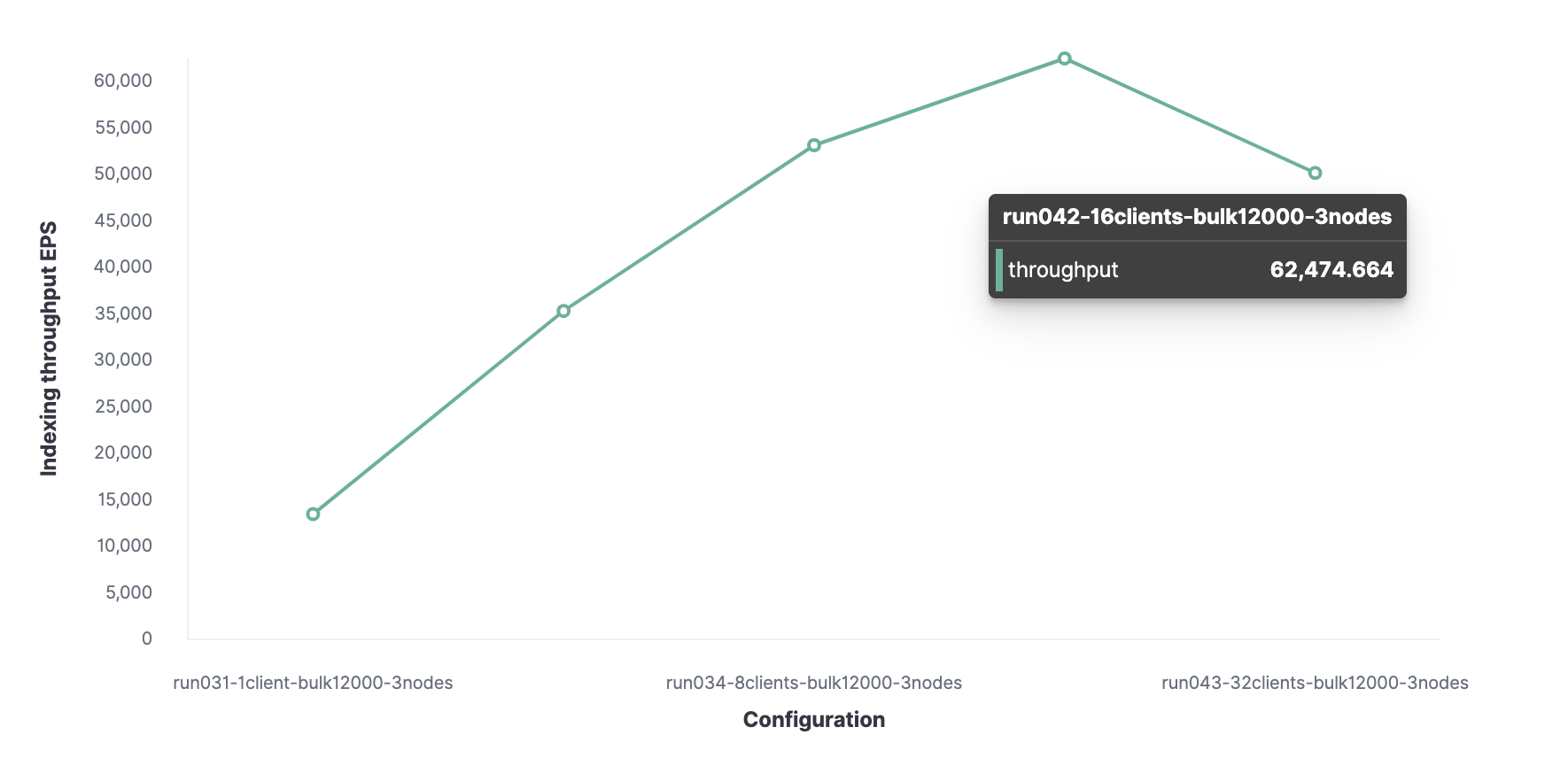
Secara total, cluster dapat memproses maksimal 62.000 acara per detik tanpa mengorbankan kinerja. Untuk menambah jumlah ini, Anda perlu menambahkan node baru.
Di bawah ini adalah pengujian yang sama dengan paket 12.000 peristiwa, tetapi sebagai perbandingan, data bandwidth diberikan untuk 1 node, 2 dan 3 node.
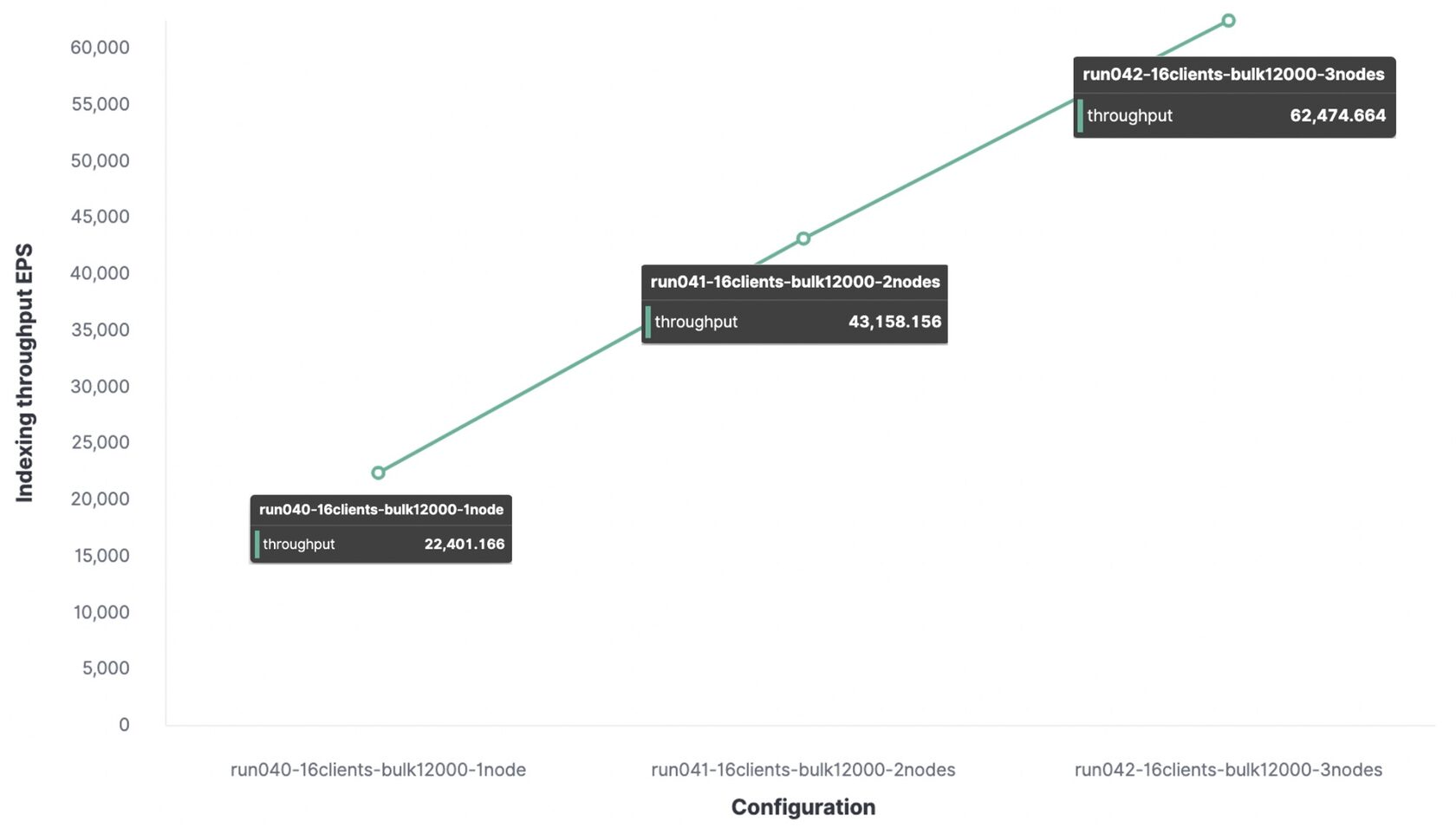
Untuk lingkungan pengujian, throughput pengindeksan maksimum adalah:
- Dengan 1 node dan 1 pecahan, 22.000 peristiwa per detik telah diindeks;
- Dengan 2 node dan 2 pecahan, 43.000 peristiwa per detik telah diindeks;
- Dengan 3 node dan 3 pecahan, 62.000 peristiwa per detik telah diindeks.
Setiap permintaan indeks tambahan akan diantrekan dan ketika sudah penuh node akan merespon dengan menolak permintaan indeks.
Harap diperhatikan bahwa kumpulan data memengaruhi kinerja cluster, jadi penting untuk menjalankan Rally track dengan data Anda sendiri.
Tes pengindeksan # 2
Untuk langkah berikutnya, trek data log server HTTP dengan konfigurasi berikut akan digunakan:
- 247 249 096 dokumen;
- Volume data: 31,1 GB;
- Ukuran dokumen rata-rata: 0,8 KB.
Ukuran paket optimal adalah 16.000 dokumen.
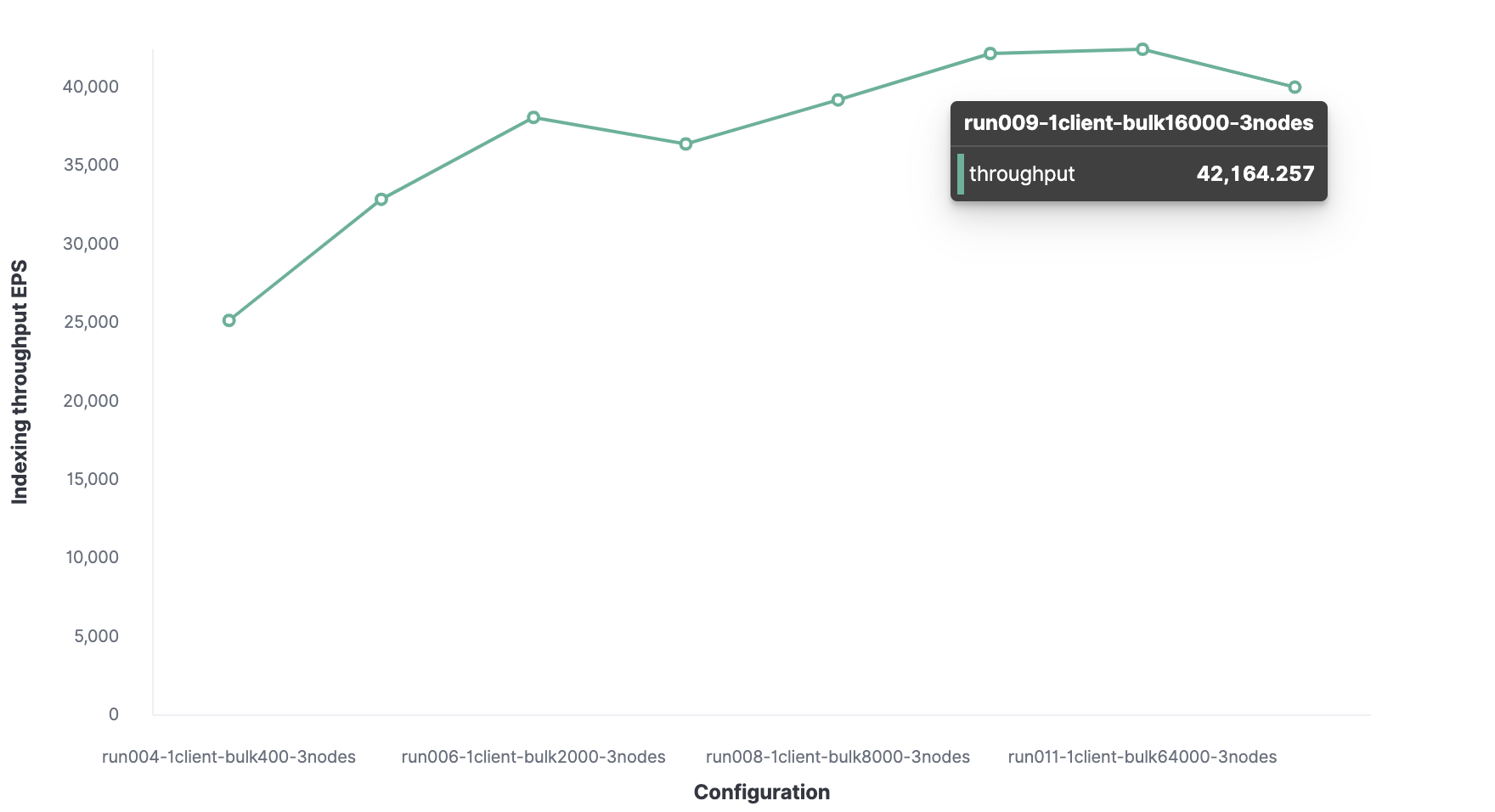
Jumlah klien optimal adalah 32.
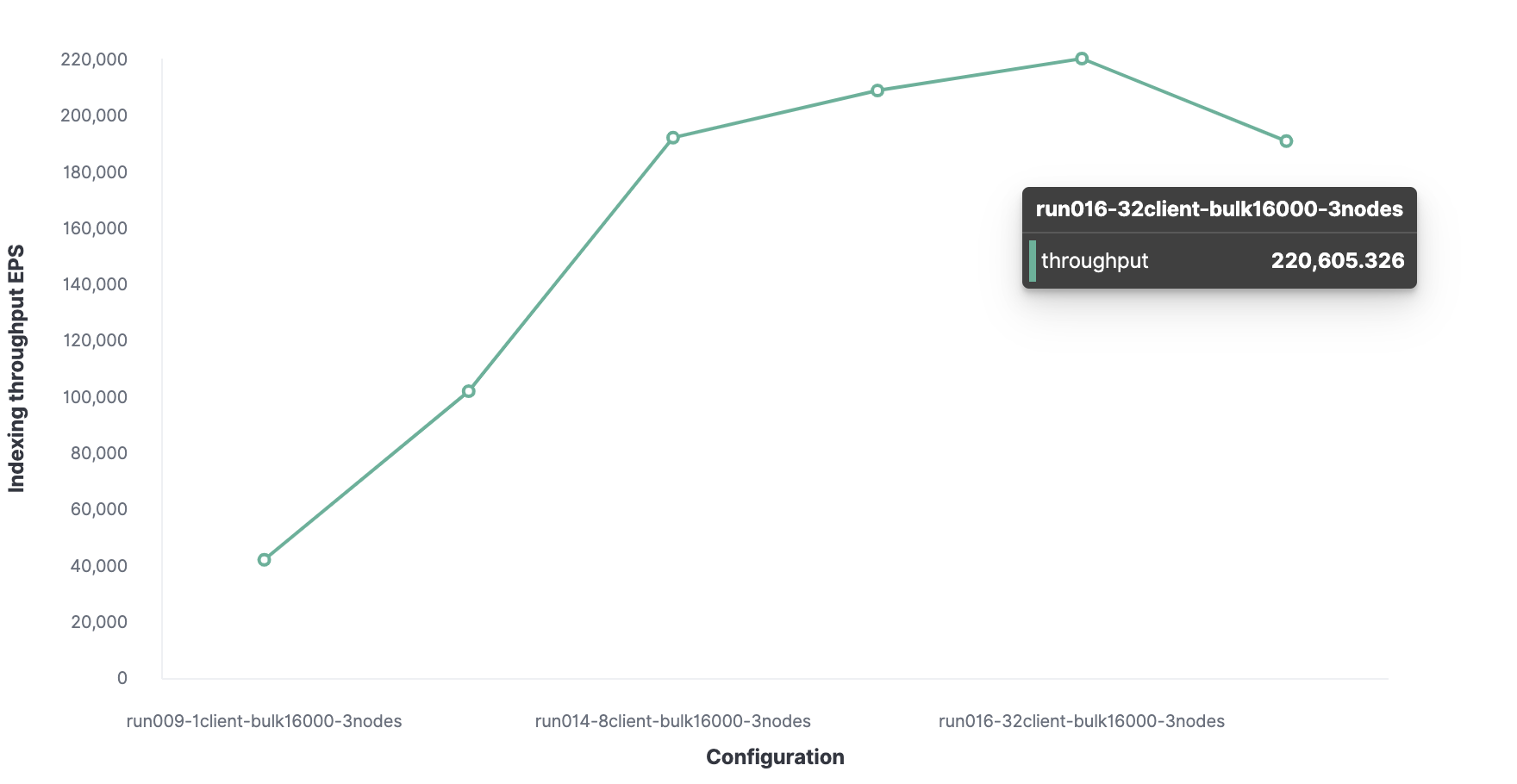
Oleh karena itu, throughput pengindeksan maksimum di Elasticsearch adalah 220.000 peristiwa per detik.
Cari
Throughput pencarian akan diperkirakan berdasarkan 20 klien dan 1000 operasi per detik. Tiga tes akan dilakukan untuk pencarian.
Tes Pencarian # 1
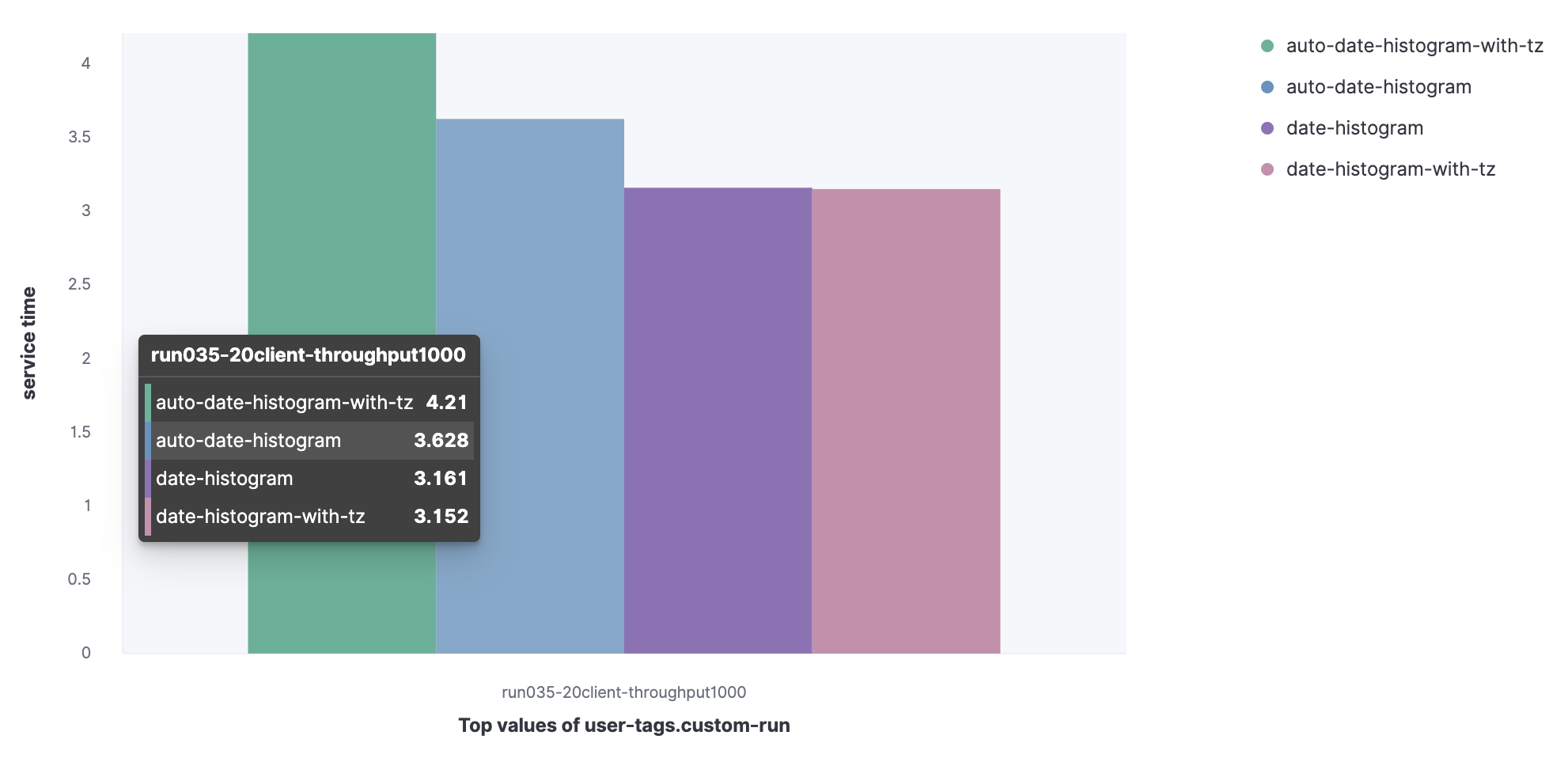
Membandingkan waktu layanan (atau lebih tepatnya persentil ke-90) untuk satu set kueri.
Set data dari Metricbeat:
- Histogram tanggal agregat dengan interval otomatis (auto-date-historgram);
- Histogram tanggal teragregasi dengan zona waktu dengan interval otomatis (auto-date-histogram-with-tz);
- Histogram tanggal agregat (tanggal-histogram);
- Histogram tanggal agregat dengan zona waktu (tanggal-histogram-dengan-tz).
Anda dapat melihat bahwa permintaan auto-date-histogram-with-tz memiliki waktu layanan terlama di cluster.
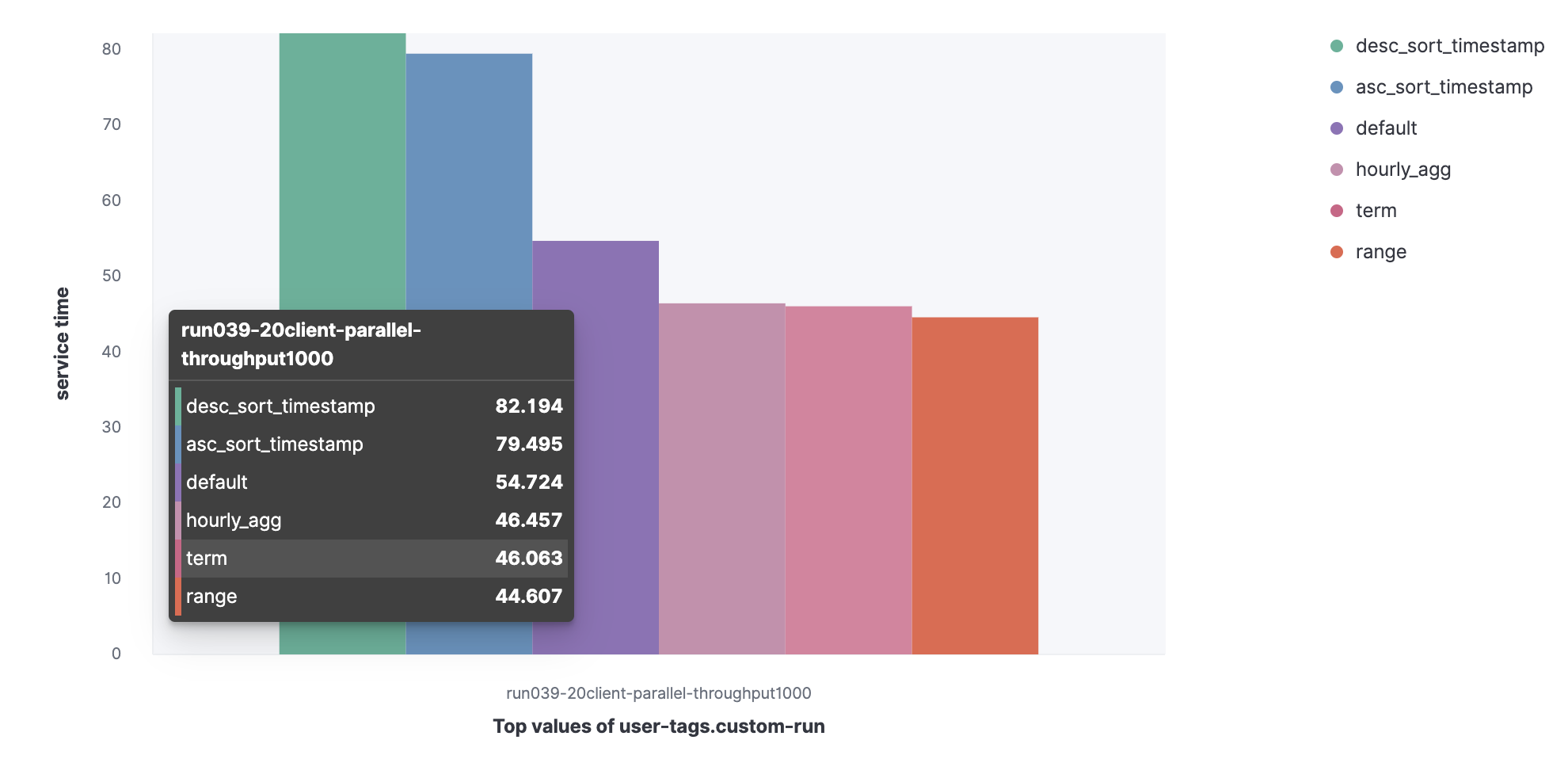
Kumpulan data dari log server HTTP:
- Default;
- Istilah;
- Jarak;
- Tag_jam;
- Desc_sort_timestamp;
- Asc_sort_timestamp.
Anda dapat melihat bahwa permintaan desc_sort_timestamp dan desc_sort_timestamp memiliki masa pakai yang lebih lama.

Tes pencarian # 2
Sekarang mari kita lihat kueri paralel. Mari kita lihat bagaimana waktu layanan persentil ke-90 meningkat jika kueri dijalankan secara paralel.
Tes pencarian # 3
Pertimbangkan kecepatan pengindeksan dan waktu layanan permintaan pencarian di hadapan pengindeksan paralel.
Mari kita jalankan pengindeksan paralel dan tugas pencarian untuk melihat kecepatan pengindeksan dan waktu layanan kueri.

Mari kita lihat bagaimana waktu layanan kueri persentil ke-90 meningkat saat melakukan penelusuran secara paralel dengan operasi pengindeksan.

Secara total, memiliki 32 klien untuk pengindeksan dan 20 pengguna untuk mencari:
- Throughput pengindeksan adalah 173.000 peristiwa per detik, yang kurang dari 220.000 diperoleh dalam percobaan sebelumnya;
- Bandwidth pencarian adalah 1000 peristiwa per detik.
Rally adalah alat pembandingan yang kuat, tetapi Anda harus menggunakannya hanya dengan data yang juga akan digunakan untuk produksi di masa mendatang.
Beberapa iklan:
Kami telah mengembangkan kursus pelatihan tentang dasar-dasar bekerja dengan Elastic Stack , yang disesuaikan dengan kebutuhan spesifik pelanggan. Program pelatihan terperinci berdasarkan permintaan.
Kami mengundang Anda untuk mendaftar pada Elastic Day di Rusia dan CIS 2021, yang akan diadakan secara online pada 3 Maret mulai pukul 10 pagi hingga 1 siang.
Baca artikel kami yang lain:
- Mengukur Elasticsearch
- Bagaimana lisensi Elastic Stack (Elasticsearch) dilisensikan dan berbeda
- Memahami Pembelajaran Mesin di Tumpukan Elastis (alias Elasticsearch, alias ELK)
- Elastis di bawah kunci: mengaktifkan opsi keamanan untuk cluster Elasticsearch untuk akses dari dalam dan luar
Jika Anda tertarik dengan administrasi dan layanan dukungan untuk instalasi Elasticsearch, Anda dapat meninggalkan permintaan dalam formulir umpan balik di halaman khusus.
Berlangganan ke grup Facebook dan saluran Youtube kami .