Terjemahan kami hari ini adalah tentang Ilmu Data. Seorang analis data dari Dublin menceritakan bagaimana dia mencari perumahan di pasar dengan permintaan tinggi dan pasokan rendah.
Saya selalu iri pada para profesional yang dapat menerapkan keterampilan kerja mereka dalam kehidupan sehari-hari . Ambil contoh tukang ledeng, dokter gigi, atau koki: keterampilan mereka tidak hanya berguna di tempat kerja.
Untuk analis data dan insinyur perangkat lunak, manfaat ini biasanya kurang nyata. Tentu saja, saya paham teknologi, tetapi di tempat kerja saya kebanyakan berurusan dengan sektor bisnis, jadi sulit menemukan kasus penggunaan yang menarik untuk keterampilan saya dalam memecahkan masalah keluarga.
Ketika istri saya dan saya memutuskan untuk membeli rumah baru di Dublin, saya segera melihat kesempatan untuk menggunakan pengetahuan itu!
Isi artikel:
- Permintaan tinggi, pasokan rendah
- Mencari data
- Dari ide ke alat
- Data dasar
- Meningkatkan kualitas data
- Google Data Studio
- Beberapa detail implementasi (dan kemudian beralih ke bagian yang menyenangkan)
- Alamat geocoding
- Perhitungan waktu properti di pasar
- Analisis
- temuan
- Kesimpulan
Data di bawah ini tidak dipotong tetapi dibuat dengan skrip ini .
Permintaan tinggi, pasokan rendah
Untuk memahami bagaimana semuanya dimulai, Anda dapat membaca pengalaman pribadi saya membeli real estat di Dublin. Saya harus mengakui bahwa itu tidak mudah: permintaan pasar sangat tinggi (berkat kinerja ekonomi Irlandia yang sangat baik dalam beberapa tahun terakhir), dan perumahan sangat mahal. Irlandia memiliki biaya perumahan tertinggi dibandingkan dengan UE pada 2019, menurut laporan Eurostat (77% di atas rata-rata UE).

Apa maksud diagram ini?
1. Hanya ada sedikit rumah yang sesuai dengan anggaran kita , dan di daerah kota dengan permintaan tinggi bahkan lebih sedikit lagi (dengan infrastruktur transportasi yang kurang lebih normal).
2. Kondisi perumahan sekunder terkadang sangat memprihatinkan, karena tidak menguntungkan bagi pemilik untuk berinvestasi dalam perbaikan sebelum menjual. Rumah yang dijual sering kali memiliki peringkat efisiensi energi yang rendah, pipa ledeng dan peralatan listrik yang buruk, yang berarti pembeli harus menambahkan biaya renovasi ke harga yang sudah tinggi.
3. Penjualan didasarkan pada sistem lelang dan dalam banyak kasus, tawaran pembeli melebihi harga awal. Sejauh yang saya pahami, ini tidak berlaku untuk bangunan baru, tetapi secara signifikan di luar anggaran kami, jadi kami tidak mempertimbangkan segmen ini sama sekali.
Saya rasa banyak orang di seluruh dunia sudah familiar dengan situasi ini, karena, kemungkinan besar, semuanya sama di kota-kota besar.
Seperti orang lain dalam pencarian properti kami, kami ingin menemukan rumah yang sempurna di area yang sempurna dengan harga yang terjangkau. Mari kita lihat bagaimana analitik data membantu kami melakukan ini!
Mencari data
Dalam setiap proyek Ilmu Data ada tahap pengumpulan data, dan untuk kasus khusus ini, saya mencari sumber yang berisi informasi tentang semua perumahan yang tersedia di pasar. Di Irlandia ada dua jenis situs:
- situs web agen real estat,
- agregator.
Kedua opsi tersebut sangat berguna dan membuat hidup lebih mudah bagi penjual dan pembeli. Sayangnya, antarmuka pengguna dan filter yang disarankan tidak selalu memberikan cara paling efisien untuk mengekstrak informasi yang diperlukan dan membandingkan properti yang berbeda. Berikut beberapa pertanyaan yang sulit dijawab dengan mesin pencari seperti Google:
1. Berapa lama waktu yang dibutuhkan untuk mulai bekerja?
2. Berapa banyak properti yang ada di satu area atau lainnya? Anda dapat membandingkan distrik kota di situs klasik, tetapi biasanya mencakup beberapa kilometer persegi. Ini tidak cukup detail untuk dipahami, misalnya, kalimat yang terlalu tinggi di jalan tertentu menunjukkan semacam tipuan. Sebagian besar situs khusus memiliki peta, tetapi tidak informatif seperti yang kami inginkan.
3. Fasilitas apa saja yang ada di dekat rumah?
4. Berapa harga rata-rata yang diminta untuk sekelompok properti?
5. Sudah berapa lama properti itu dijual? Meskipun informasi ini tersedia, tidak selalu dapat diandalkan, karena makelar dapat menghapus iklan dan menempatkannya kembali.
Mendesain ulang antarmuka pengguna untuk keramahan konsumen dan meningkatkan kualitas data membuat menemukan rumah jauh lebih mudah dan memungkinkan kami untuk menarik beberapa wawasan yang sangat menarik.
Dari ide ke alat
Data dasar
Langkah pertama adalah menulis scraper untuk mengumpulkan informasi dasar:
- alamat mentah properti,
- harga penjual saat ini,
- link ke halaman dengan properti,
- karakteristik dasar seperti jumlah kamar, jumlah kamar mandi, peringkat efisiensi energi,
- jumlah tampilan iklan (jika tersedia),
- jenis properti (rumah, apartemen, gedung baru).
Faktanya, ini adalah semua data yang dapat saya temukan di Internet. Untuk analisis yang lebih dalam, saya perlu meningkatkan dataset ini.
Meningkatkan kualitas data
Saat memilih rumah, argumen utama saya yang mendukung pembelian adalah jalan yang nyaman untuk bekerja, bagi saya tidak lebih dari 50 menit untuk seluruh perjalanan dari pintu ke pintu. Untuk perhitungan ini, saya memutuskan untuk menggunakan Google Cloud Platform:
1. Dengan menggunakan Geocoding API, saya mendapatkan koordinat lintang dan bujur menggunakan alamat properti.
2. Dengan menggunakan Directions API, saya menghitung waktu yang dibutuhkan untuk pergi dari rumah ke tempat kerja dengan berjalan kaki dan dengan transportasi umum. Catatan: Bersepeda sekitar 3 kali lebih cepat daripada berjalan kaki.
3. Menggunakan tempat API (Places API)Saya telah menerima informasi tentang fasilitas di sekitar setiap properti. Secara khusus, kami tertarik pada apotek, supermarket, dan restoran. Catatan: Places API sangat mahal: dengan database 4.000 properti, Anda perlu menjalankan 12.000 kueri untuk menemukan informasi tentang tiga jenis fasilitas. Oleh karena itu, saya mengecualikan data ini dari dasbor terakhir.
Selain letak geografis, saya tertarik dengan pertanyaan lain: sudah berapa lama properti itu ada di pasaran? Jika properti tidak dijual terlalu lama, ini adalah peringatan: mungkin ada sesuatu yang salah dengan area atau rumahnya, atau harga yang diminta terlalu tinggi.
Sebaliknya, jika properti baru saja disiapkan untuk dijual, perlu diingat bahwa pemilik tidak akan menyetujui tawaran pertama yang diterima. Sayangnya, informasi ini cukup mudah disembunyikan. Dengan menggunakan pembelajaran mesin dasar, saya memperkirakan aspek ini menggunakan jumlah tampilan iklan dan beberapa metrik lainnya.
Terakhir, saya meningkatkan dataset dengan beberapa bidang layanan untuk mempermudah pemfilteran (misalnya dengan menambahkan kolom dengan kisaran harga).
Google Data Studio
Dengan kumpulan data yang ditingkatkan yang tidak masalah bagi saya, saya akan membuat dasbor yang kuat . Saya memilih Google Data Studio sebagai alat visualisasi data untuk tugas ini. Layanan ini memiliki beberapa kelemahan (kemampuannya sangat-sangat terbatas), tetapi ada juga kelebihannya: gratis, memiliki versi web dan dapat membaca data dari Google Sheets. Di bawah ini adalah diagram yang menjelaskan seluruh alur kerja.

Beberapa detail implementasi
Sejujurnya, penerapannya cukup mudah dan tidak ada yang baru atau istimewa di sini: hanya sekumpulan skrip untuk mengumpulkan data dan beberapa transformasi dasar Pandas. Kecuali bahwa interaksi dengan Google API dan kalkulasi waktu selama properti itu ada di pasar perlu diperhatikan.
Data di bawah ini tidak dipotong tetapi dibuat dengan skrip ini .
Mari kita lihat data mentahnya.
Seperti yang saya harapkan, file tersebut berisi kolom berikut:
id
: ID Iklan._address
: Alamat properti._d_code
: . D<>. <> , (, ), — ._link
: , ._price
: .type
: (, , )._bedrooms
: ()._bathrooms
: ._ber_code
: , : «», ._views
: ( )._latest_update
: ( ).days_listed
: — , ,_last_update
.
Intinya adalah membawa semua ini ke peta dan memanfaatkan kekuatan data geolokalisasi. Untuk melakukan ini, mari kita lihat cara mendapatkan lintang dan bujur menggunakan Google API.
Untuk melakukannya, Anda memerlukan akun dengan Google Cloud Platform, lalu Anda dapat mengikuti tutorial di link untuk mendapatkan kunci API dan mengaktifkan API yang sesuai. Seperti yang saya tulis sebelumnya, untuk proyek ini saya menggunakan API Geocoding, API Arah, dan API Tempat (jadi Anda perlu mengaktifkan API khusus ini saat membuat kunci API). Di bawah ini adalah cuplikan kode untuk berinteraksi dengan Google Cloud Platform.
# The Google Maps library
import googlemaps
# Date time for easy computations between dates
from datetime import datetime
# JSON handling
import json
# Pandas
import pandas as pd
# Regular expressions
import re
# TQDM for fancy loading bars
from tqdm import tqdm
import time
import random
# !!! Define the main access point to the Google APIs.
# !!! This object will contain all the functions needed
geolocator = googlemaps.Client(key="<YOUR API KEY>")
WORK_LAT_LNG = (<LATITUDE>, <LONGITUDE>)
# You can set this parameter to decide the time from which
# Google needs to calculate the directions
# Different times affect public transport
DEPARTURE_TIME = datetime.now
# Load the source data
data = pd.read_csv("/path/to/raw/data/data.csv")
# Define the columns that we want in the geocoded dataframe
geo_columns = [
"_link",
"lat",
"lng",
"_time_to_work_seconds_transit",
"_time_to_work_seconds_walking"
]
# Create an array where we'll store the geocoded data
geo_data = []
# For each element of the raw dataframe, start the geocoding
for index,
in tqdm(data.iterrows()):
# Google Geo coding
_location = ""
_location_json = ""
try:
# Try to retrieve the base location,
# i.e. the Latitude and Longitude given the address
_location = geolocator.geocode(row._address)
_location_json = json.dumps(_location[0])
except:
pass
_time_to_work_seconds_transit = 0
_directions_json = ""
_lat_lon = {"lat": 0, "lng": 0}
try:
# Given the work latitude and longitude, plus the property latitude and longitude,
# retrieve the distance with PUBLIC TRANSPORT (`mode=transit`)
_lat_lon = _location[0]["geometry"]["location"]
_directions = geolocator.directions(WORK_LAT_LNG,
(_lat_lon["lat"], _lat_lon["lng"]), mode="transit")
_time_to_work_seconds_transit = _directions[0]["legs"][0]["duration"]["value"]
_directions_json = json.dumps(_directions[0])
except:
pass
_time_to_work_seconds_walking = 0
try:
# Given the work latitude and longitude, plus the property latitude and longitude,
# retrieve the WALKING distance (`mode=walking`)
_lat_lon = _location[0]["geometry"]["location"]
_directions = geolocator.directions(WORK_LAT_LNG, (_lat_lon["lat"], _lat_lon["lng"]), mode="walking")
_time_to_work_seconds_walking = _directions[0]["legs"][0]["duration"]["value"]
except:
pass
# This block retrieves the number of SUPERMARKETS arount the property
'''
_supermarket_nr = 0
_supermarket = ""
try:
# _supermarket = geolocator.places_nearby((_lat_lon["lat"],_lat_lon["lng"]), radius=750, type="supermarket")
_supermarket_nr = len(_supermarket["results"])
except:
pass
'''
# This block retrieves the number of PHARMACIES arount the property
'''
_pharmacy_nr = 0
_pharmacy = ""
try:
# _pharmacy = geolocator.places_nearby((_lat_lon["lat"],_lat_lon["lng"]), radius=750, type="pharmacy")
_pharmacy_nr = len(_pharmacy["results"])
except:
pass
'''
# This block retrieves the number of RESTAURANTS arount the property
'''
_restaurant_nr = 0
_restaurant = ""
try:
# _restaurant = geolocator.places_nearby((_lat_lon["lat"],_lat_lon["lng"]), radius=750, type="restaurant")
_restaurant_nr = len(_restaurant["results"])
except:
pass
'''
geo_data.append([row._link, _lat_lon["lat"], _lat_lon["lng"], _time_to_work_seconds_transit,
_time_to_work_seconds_walking])
geo_data_df = pd.DataFrame(geo_data)
geo_data_df.columns = geo_columns
geo_data_df.to_csv("geo_data_houses.csv", index=False)
Perhitungan waktu properti di pasar
Mari kita lihat lebih dekat datanya :
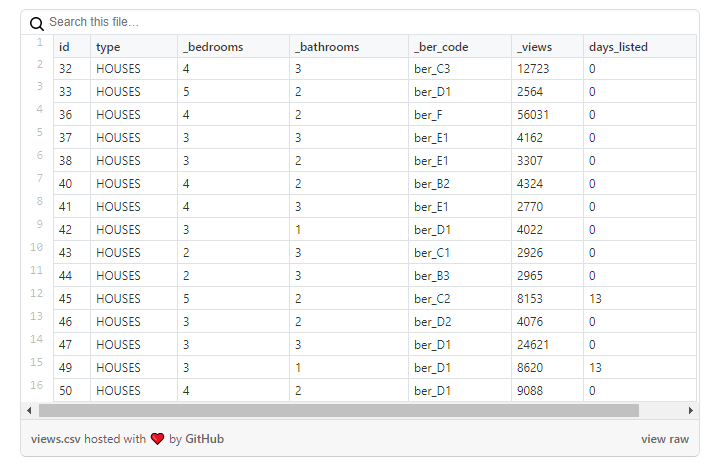
Seperti yang Anda lihat dalam contoh ini, jumlah tampilan properti tidak tercermin dalam jumlah hari selama iklan aktif: misalnya, rumah dengan id = 47 memiliki ~ 25 seribu kali dilihat, tetapi muncul pada hari itu ketika saya memuat data.
Namun, masalah ini tidak umum untuk semua properti. Pada contoh di bawah ini , jumlah tampilan lebih sebanding dengan jumlah hari iklan itu aktif:

Bagaimana kami dapat menggunakan informasi di atas? Mudah! Kita bisa menggunakan dataset kedua sebagai set pelatihan untuk model, yang kemudian bisa kita terapkan ke dataset pertama.
Saya menguji dua pendekatan:
1. Ambil kumpulan data "yang sebanding" dan hitung jumlah rata-rata penayangan per hari, lalu terapkan nilai itu ke kumpulan data pertama. Pendekatan ini bukan tanpa akal sehat, tetapi memiliki masalah berikut: semua properti digabungkan menjadi satu grup, dan kemungkinan besar iklan untuk penjualan rumah senilai 10 juta euro akan menerima lebih sedikit tampilan per hari, karena anggaran tersedia untuk sekelompok kecil orang.
2. Latih model Random Forest pada dataset kedua dan kemudian terapkan pada dataset pertama.
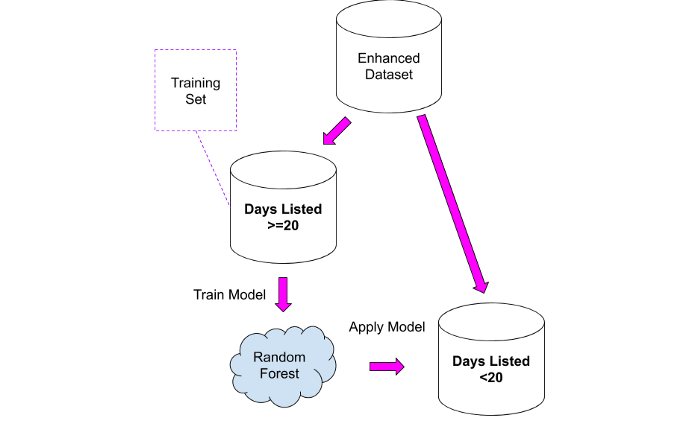
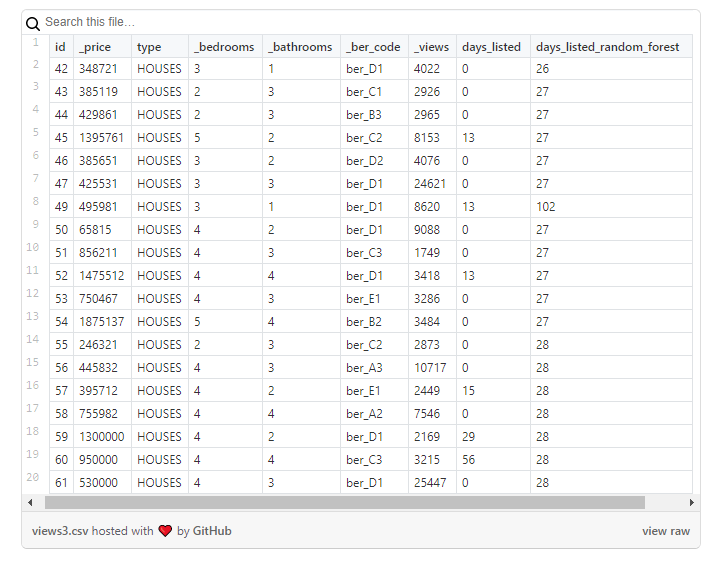
Hasilnya harus dilihat dengan sangat hati-hati, mengingat bahwa kolom baru hanya akan berisi nilai perkiraan: Saya menggunakannya sebagai titik awal untuk menganalisis properti secara lebih detail di mana ada sesuatu yang tampak aneh.
Analisis
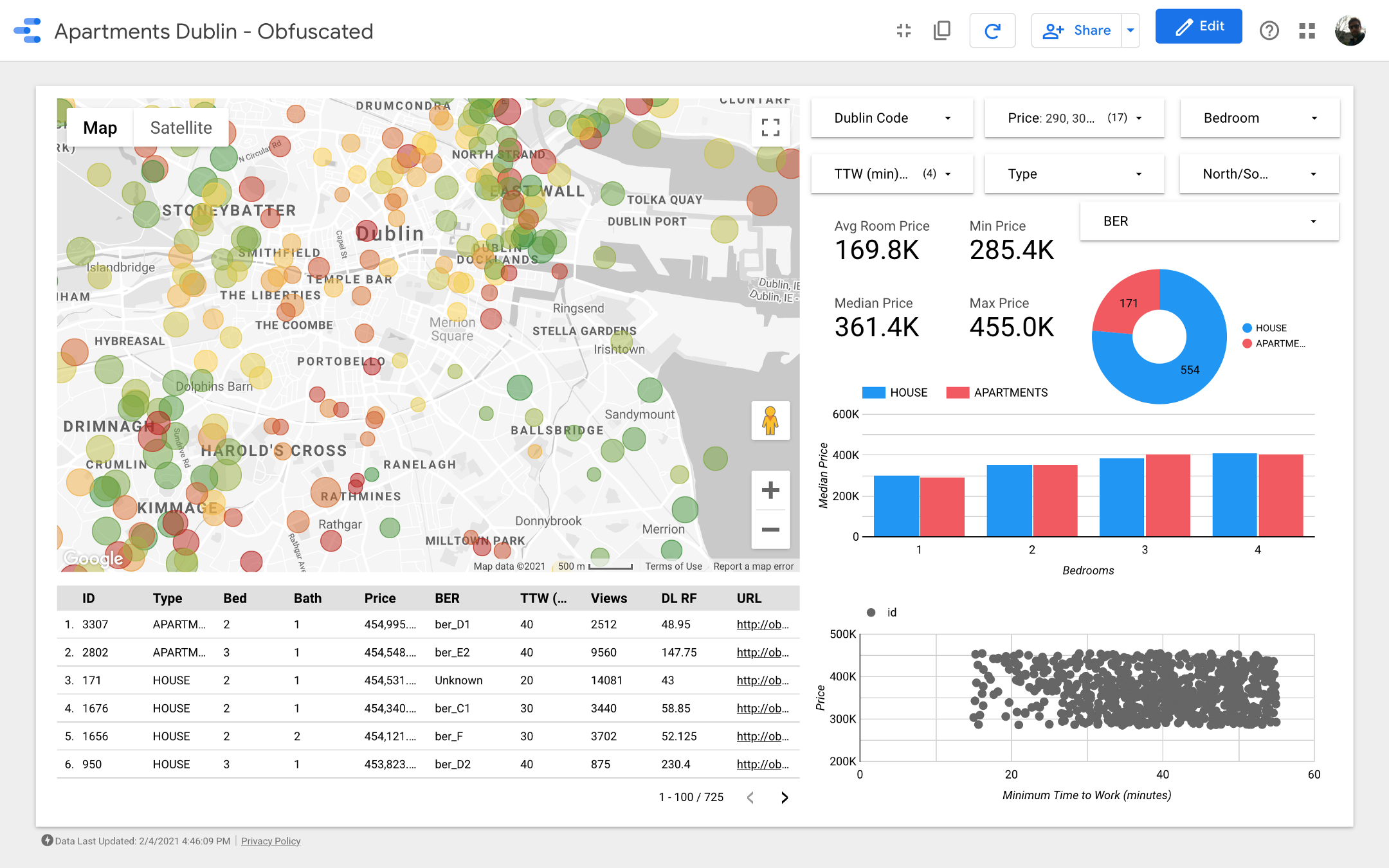
Hadirin sekalian, saya persembahkan untuk perhatian Anda dasbor terakhir . Jika Anda ingin menggalinya, ikuti tautannya .
Catatan: Sayangnya, modul Google Maps tidak berfungsi saat disematkan dalam artikel, jadi saya harus menggunakan tangkapan layar.
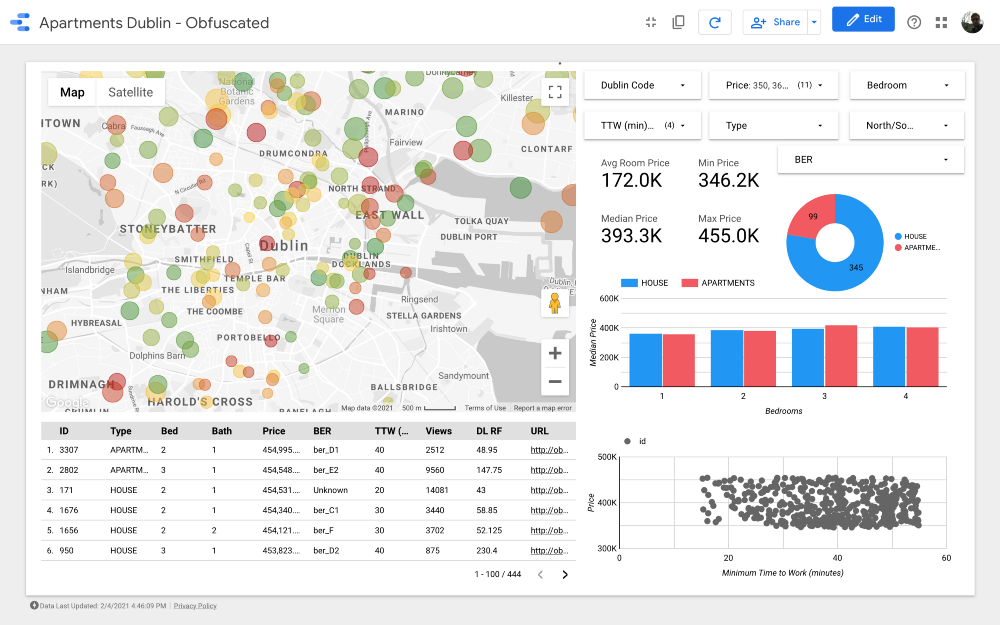
https://datastudio.google.com/s/qKDxt8i2ezE
Peta adalah bagian terpenting dari dashboard. Warna gelembung tergantung pada harga rumah / apartemen, dan pewarnaan hanya memperhitungkan properti yang tersedia (sesuai dengan pengaturan filter di sudut kanan atas); ukuran gelembung menunjukkan jarak untuk bekerja: semakin kecil, semakin pendek jalannya.
Diagram memungkinkan Anda menganalisis bagaimana harga yang diminta berubah tergantung pada beberapa karakteristik (misalnya, jenis bangunan atau jumlah kamar), dan diagram sebar membandingkan jarak ke tempat kerja dan harga yang diminta.
Terakhir, tabel data mentah (
DL RF
singkatan dari Days Listed Random Forest dan menunjukkan jumlah hari iklan aktif, model Random Forest).
temuan
Mari selami analisisnya dan lihat kesimpulan apa yang bisa kita tarik dari dasbor.
Kumpulan data mencakup sekitar 4.000 rumah dan apartemen: tentu saja, kami tidak dapat melihat semuanya, jadi tugas kami adalah mengidentifikasi subset catatan yang berisi satu atau beberapa properti yang siap kami pertimbangkan untuk dibeli.
Pertama, kita perlu memperjelas kriteria pencarian. Misalnya, kita mencari properti yang memenuhi karakteristik berikut:
1. Jenis properti: Rumah.
2. Jumlah kamar (kamar tidur): 3.
3. Jarak ke tempat kerja: kurang dari 60 menit.
4. Peringkat efisiensi energi: A, B, C, atau D.
5. Harga: dari 250 hingga 540 ribu euro.
Mari terapkan semua filter kecuali harga dan lihat peta (hanya filter yang lebih mahal dari 1 juta dan kurang dari 200 ribu euro).
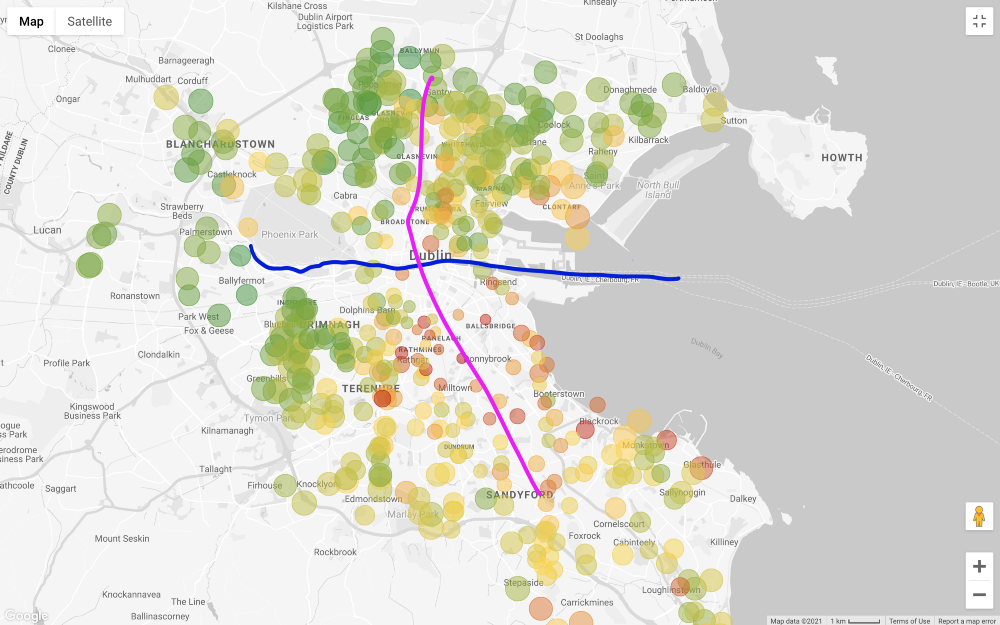
Secara umum, harga yang diminta untuk properti di selatan Liffey jauh lebih tinggi daripada di utara, dengan beberapa pengecualian di barat daya kota. Bahkan "wilayah terluar" di utara, yaitu timur laut dan barat laut, tampak lebih murah daripada di utara pusat kota. Salah satu alasan penetapan harga ini adalah Jalur Trem Utama Dublin (LUAS) melintasi kota dari utara ke selatan dalam garis lurus (ada jalur lain yang membentang dari barat ke timur, tetapi tidak melewati semua distrik bisnis).
Harap diperhatikan bahwa saya membuat pertimbangan ini hanya berdasarkan inspeksi visual. Pendekatan yang lebih menyeluruh memerlukan pengujian korelasi antara harga rumah dan jaraknya dari rute angkutan umum, tetapi kami tidak tertarik untuk membuktikan hubungan ini.
Situasinya menjadi lebih menarik, jika Anda menetapkan harga filter sesuai dengan anggaran kami (jangan lupa bahwa pada peta di atas menunjukkan rumah dengan 3 kamar tidur, dan mulai bekerja dalam waktu kurang dari 60 menit, dan pada peta di bawah ditambahkan hanya memfilter menurut harga):
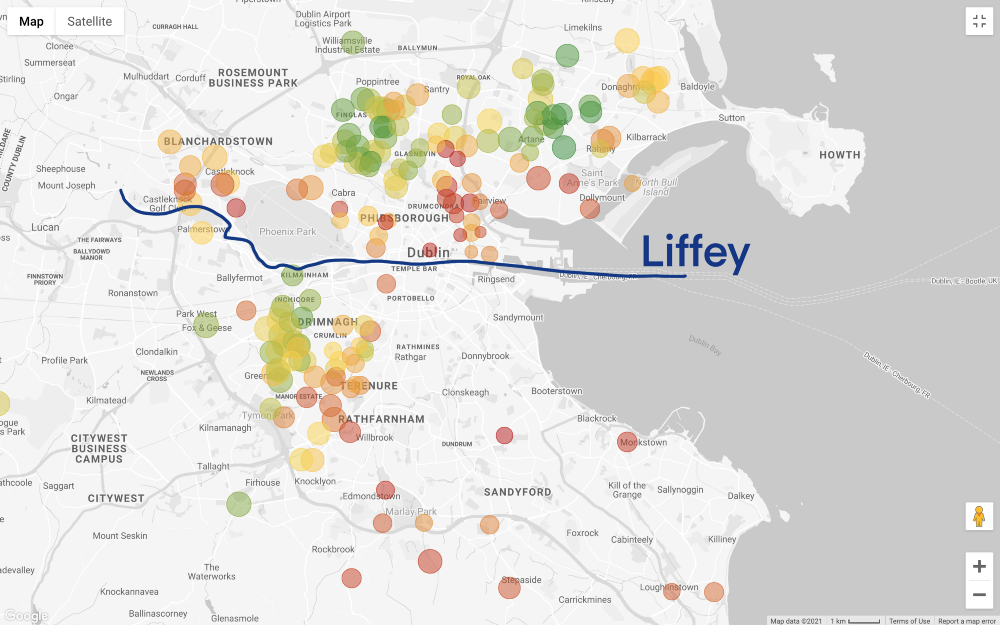
Mari mundur selangkah. Kami memiliki gambaran umum tentang area yang kami mampu, tetapi sekarang hal yang paling sulit ada di depan - pencarian kompromi! Apakah kami ingin mencari opsi anggaran yang lebih banyak? Atau apakah kita menganggap rumah terbaik yang bisa dibeli dengan tabungan hasil jerih payah kita? Sayangnya, analisis data tidak dapat menjawab pertanyaan-pertanyaan ini, ini adalah keputusan bisnis (dan sangat pribadi).
Misalkan kita memilih opsi kedua: kita memprioritaskan kualitas rumah atau area daripada harga yang lebih rendah.
Dalam hal ini, kami perlu mempertimbangkan opsi-opsi berikut:
1. Area dengan konsentrasi proposal yang rendah - rumah yang terisolasi di peta dapat menunjukkan bahwa tidak banyak penawaran di area tersebut, yang berarti bahwa pemiliknya tidak terburu-buru untuk berpisah dengan rumah mereka di area yang bagus ...
2. Rumah yang terletak di sekumpulan properti mahal - jika semua properti lain di dekat rumah tertentu mahal, ini mungkin berarti area tersebut memiliki permintaan tinggi. Ini hanyalah catatan tambahan, tetapi kita bisa mengukur fenomena ini menggunakan autokorelasi spasial (misalnya, dengan menghitung Moran's I ).
Bahkan jika opsi pertama tampak menarik, harus diingat bahwa harga properti yang sangat rendah dibandingkan dengan penawaran lain di area yang sama mungkin menyiratkan semacam tangkapan di rumah itu sendiri (misalnya, kamar kecil atau biaya renovasi yang sangat tinggi. ). Untuk alasan ini, kami akan melanjutkan analisis kami dengan fokus pada opsi kedua, yang menurut saya, paling menjanjikan mengingat tujuan kami.
Mari kita lihat lebih dekat apa saja yang ada proposal di area tersebut:

Kami telah mengurangi opsi kami dari 4.000 menjadi kurang dari 200, dan sekarang kami perlu memecahkan poin dan membandingkan cluster dengan lebih baik.
Otomatisasi pencarian cluster tidak akan menambahkan banyak hal pada analisis ini, tetapi mari tetap menerapkan algoritma DBSCAN.... Kami menggunakan DBSCAN karena beberapa grup mungkin non-globular (misalnya, k-means tidak akan berfungsi dengan baik di database ini). Secara teori, kita perlu menghitung jarak geografis antara titik-titik, tetapi kita akan menggunakan sistem Euclidean, karena ini memberikan perkiraan yang baik:
import pandas as pd
from sklearn.cluster import DBSCAN
data = pd.read_csv("data.csv")
data["labels"] = DBSCAN(eps=0.01, min_samples=3).fit(data[["lat","lng"]].values).labels_
print(data["labels"].unique())
data.to_csv("out.csv")

Algoritme menunjukkan hasil yang cukup bagus, tetapi saya akan merevisi cluster sebagai berikut (dengan mempertimbangkan pengetahuan distrik bisnis Dublin):

Kami menolak daerah dengan harga lebih rendah, karena kami memprioritaskan kualitas maksimum perumahan dan jalan yang nyaman untuk bekerja di dalamnya anggaran kami sehingga Kluster 2, 3, 4, 6, dan 9 dapat dikecualikan. Perhatikan bahwa Kluster 2, 3, dan 4 terletak di beberapa area yang paling ramah anggaran di Dublin utara (mungkin karena infrastruktur transportasi umum yang kurang berkembang). Cluster 11 menyajikan opsi mahal yang terletak jauh dari kantor, jadi kami juga dapat mengecualikannya.
Melihat cluster yang lebih mahal, nomor 7 adalah salah satu yang terbaik dalam hal jarak untuk bekerja. saya t Drumcondra , daerah pemukiman yang indah di utara Dublin; terlepas dari kenyataan bahwa lokasinya tidak terlalu strategis dibandingkan dengan jalur trem, rute bus melewatinya; di cluster 8, harga rumah dan jarak ke tempat kerja sama dengan di Drumkondra. Cluster lain yang layak dianalisis adalah nomor 10: tampaknya berada di daerah dengan pasokan lebih sedikit, yang berarti orang di sini mungkin jarang menjual perumahan, dan daerah tersebut juga cukup strategis untuk dilalui angkutan umum. Transportasi (asalkan semua daerah memiliki jalur yang sama kepadatan penduduk).
Terakhir, cluster 1 dan 5, terletak di sebelah Phoenix Park, taman umum berpagar terbesar .
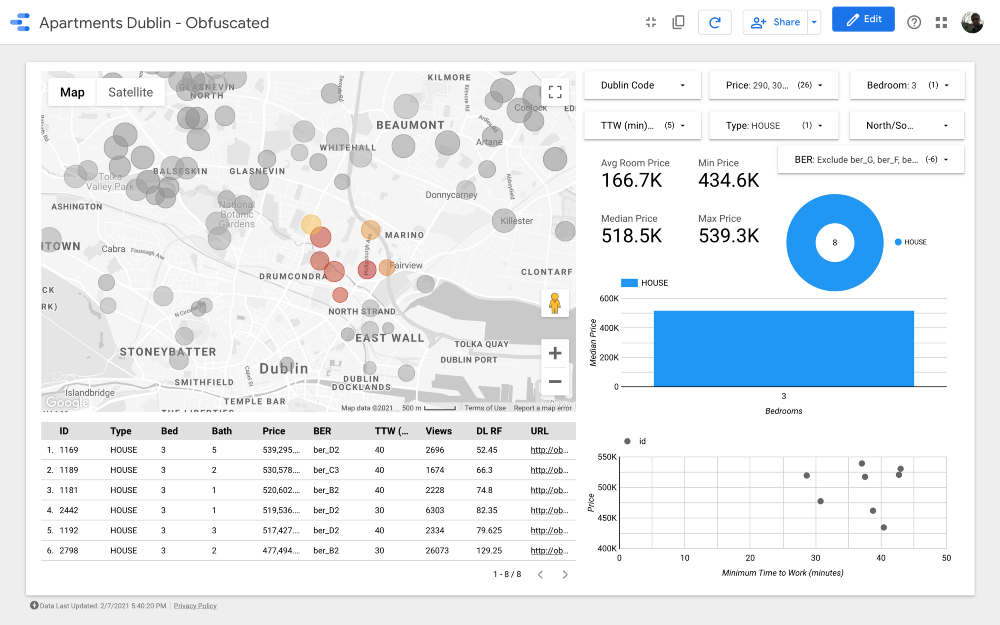
Kelompok 7

Gugus 8
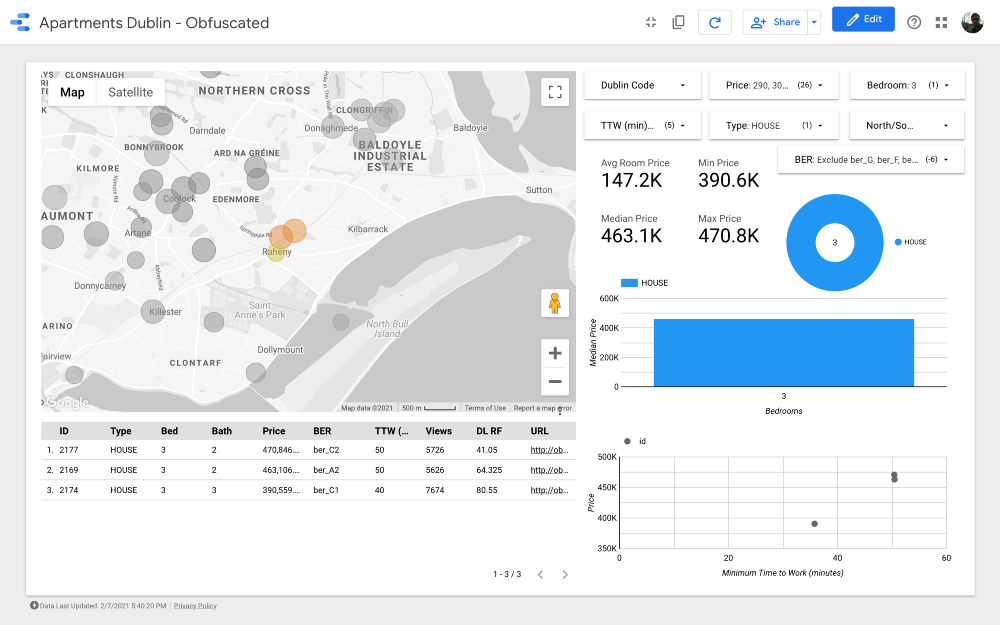
Gugus 10
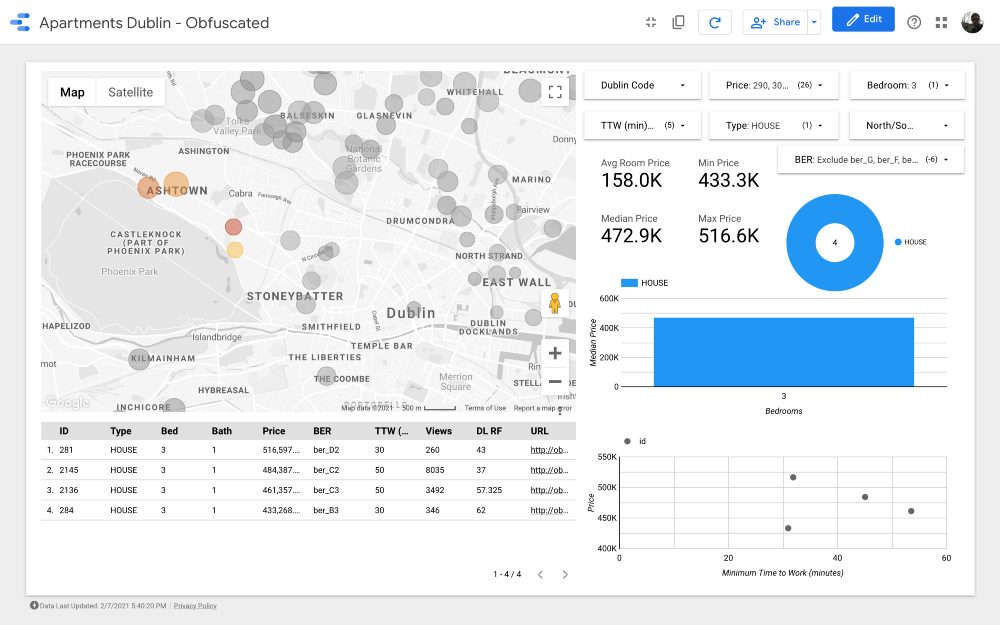
Gugus 1

Gugus 5
Hebat! Kami menemukan 26 properti yang layak dilihat pertama kali. Sekarang kita dapat dengan cermat menganalisis setiap penawaran dan, pada akhirnya, mengatur penayangan dengan makelar!
Kesimpulan
Kami memulai pencarian kami, secara praktis tidak mengetahui apa-apa tentang Dublin, dan pada akhirnya kami mendapatkan pemahaman yang baik tentang area kota mana yang paling diminati saat membeli rumah.
Perhatikan, kami bahkan tidak melihat gambar rumah-rumah ini dan tidak membaca apa pun tentangnya! Hanya dengan melihat dasbor yang terorganisir dengan baik, kami mendapatkan beberapa kesimpulan berguna yang tidak dapat kami capai pada awalnya!
Data ini tidak lagi berguna, dan beberapa integrasi dapat dilakukan untuk meningkatkan analisis. Beberapa pemikiran:
1. Kami tidak mengintegrasikan dataset amenities (yang kami kumpulkan menggunakan Places API) ke dalam penelitian. Dengan anggaran yang lebih besar untuk layanan cloud, kami dapat dengan mudah menambahkan informasi ini ke dasbor.
2. Di Irlandia, banyak data menarik dipublikasikan di situs web kantor statistik : misalnya, Anda dapat menemukan informasi tentang jumlah panggilan ke setiap kantor polisi menurut kuartal dan menurut jenis kejahatan. Dengan demikian, kami dapat mengetahui di area mana yang paling banyak terjadi pencurian. Karena dimungkinkan untuk memperoleh data sensus untuk setiap TPS, kami juga dapat menghitung tingkat kejahatan per kapita. Harap dicatat bahwa untuk fitur-fitur canggih seperti itu, kami memerlukan sistem informasi geografis yang sesuai (misalnya QGIS ) atau database yang dapat menangani data geografis (misalnya PostGIS ).
3. Irlandia memiliki database harga rumah sebelumnya yang disebut Register Properti Residensial . Situs web mereka berisi informasi tentang setiap properti hunian yang dibeli di Irlandia sejak 1 Januari 2010, termasuk tanggal penjualan, harga, dan alamat. Dengan membandingkan harga rumah saat ini dengan harga rumah sebelumnya, Anda dapat melihat bagaimana permintaan berubah seiring waktu.
4. Harga asuransi rumah sangat tergantung pada lokasi rumah. Dengan sedikit upaya, kami dapat membatalkan situs perusahaan asuransi untuk mengintegrasikan "model faktor risiko" mereka ke dalam dasbor kami.
Di pasar seperti Dublin, menemukan rumah baru bisa menjadi tugas yang menakutkan, terutama bagi seseorang yang baru saja pindah ke kota dan tidak terlalu mengenalnya.
Berkat alat ini, istri saya dan saya menghemat waktu kami (dan makelar): kami menonton 4 kali, menawarkan harga kepada 3 penjual, dan salah satu dari mereka menerima tawaran kami.