
Penanganan duplikat adalah salah satu topik paling menyakitkan dalam pekerjaan seorang analis. Di platform kami, kami mencoba mengotomatiskan proses ini sebanyak mungkin untuk mengurangi beban pada pakar NSI dan meningkatkan produktivitas kolega dengan pemrosesan data. Hari ini kita akan melihat bagaimana platform membantu membentuk satu catatan emas menggunakan contoh salah satu buku referensi yang paling umum dan dasar - direktori "rekanan".
Mari pertimbangkan salah satu skenario yang umum. Misalkan distributor B2B besar menerima barang dari pemasok yang berbeda dan menjualnya ke klien - badan hukum. orang. Jika dalam praktiknya semuanya kurang lebih baik dengan pemeliharaan oleh pemasok, maka pemrosesan basis klien terkadang membutuhkan tim ahli yang berdedikasi. Hal ini disebabkan oleh fakta bahwa biasanya perusahaan menggunakan beberapa sistem-sumber data pelanggan: ERP, CRM, sumber terbuka, dll. Pekerjaan menjadi sangat sulit ketika ada beberapa departemen dalam perusahaan, yang masing-masing mempertahankan basis pelanggannya sendiri di dalamnya. wilayah yang sama ... Dalam kasus ini, bagian dari data pelanggan digandakan dalam redistribusi satu basis, dan juga secara implisit bersinggungan antara basis pelanggan yang berbeda. Dalam sistem ERP, pemrosesan catatan duplikat yang serius diperlukan untuk mendapatkan apa yang disebut catatan induk,yang dapat Anda gunakan untuk bekerja di masa depan. Platform Unidata memiliki mekanisme khusus untuk menemukan dan memproses rekaman duplikat, yang berhasil mengatasi tugas-tugas tersebut.
Mari kita mulai
Platform ini didasarkan pada metamodel dari domain yang digunakan. Domain adalah sekumpulan registri, direktori yang terstruktur. atribut mereka dan hubungan di antara mereka, yang bersama-sama menggambarkan struktur data domain. Kita akan membicarakan metamodel itu sendiri nanti, tetapi sekarang kita akan melihat bagaimana platform memungkinkan Anda untuk bekerja dengan rekaman duplikat dalam model data yang ada. Dalam contoh kami, ada daftar "rekanan", dengan atribut utamanya adalah: nama rekanan (biasanya pendek dan lengkap), NPWP, KPP, alamat resmi dan sebenarnya, alamat pendaftaran badan hukum, dll.
Platform menggunakan mekanisme konsolidasi untuk menangani duplikat. Inti dari konsolidasi adalah kami menetapkan aturan tertentu untuk menemukan duplikat, menentukan sumber data dan untuk setiap sumber data kami menetapkan bobot khusus yang bertanggung jawab untuk tingkat kepercayaan informasi yang diterima dari sistem sumber, dan kemudian duplikat ditemukan oleh sistem digabungkan menjadi satu catatan referensi. Dalam kasus ini, rekaman duplikat menghilang dari hasil pencarian, tetapi tetap ada dalam riwayat rekaman referensi. Semua pengaturan dibuat di antarmuka administrator platform dan tidak memerlukan pemrograman. Jika penggabungan catatan dilakukan karena kesalahan, maka selalu ada kemungkinan untuk membatalkan penggabungan. Jadi, sebagian besar pekerjaan dengan duplikat diambil alih oleh sistem itu sendiri, pengguna hanya dapat mengontrol proses ini.Mari pertimbangkan penerapan mekanisme konsolidasi pada kasus-kasus contoh yang ditunjukkan.
Katakanlah platform Unidata telah dimasukkan ke dalam bus integrasi perusahaan, yang menerima data rekanan dari sistem CRM, sistem ERP, dan sistem penjualan seluler. Platform menghapus duplikat, memperkaya dan menyelaraskan data, dan kemudian mentransfer catatan referensi ke sistem penerima.
Kasus 1. Pencocokan NPWP dan KPP
Cara termudah untuk menemukan duplikat rekanan adalah dengan membandingkannya dengan TIN dan KPP, dalam banyak kasus bahkan satu NPWP sudah cukup. Untuk menerapkan aturan seperti itu untuk mencari rekaman duplikat, cukup dengan menyiapkan aturan pencocokan tepat untuk atribut INN dan KPP.
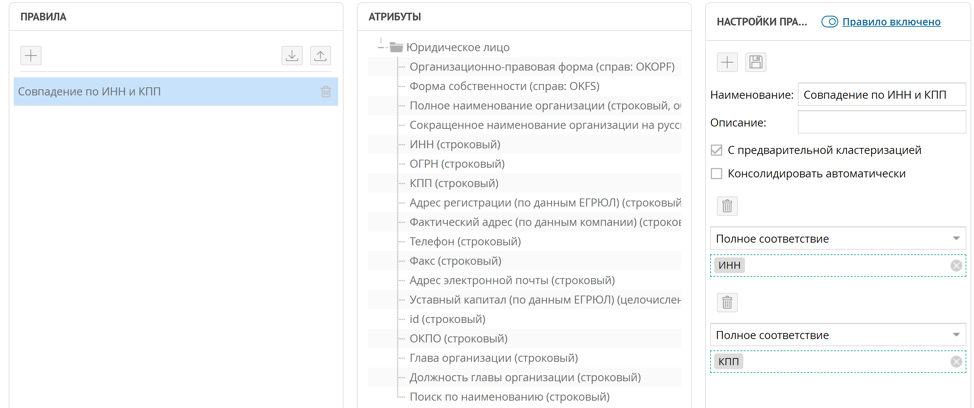
Menurut aturan ini, ketika catatan baru tiba di platform, aturan pencarian duplikat yang dikonfigurasi secara otomatis diluncurkan jika aturan disetel ke "pra-pengelompokan". Semua tuple record yang ditemukan secara kebetulan INN dan KPP dikumpulkan dalam cluster duplikat. Di jendela cluster duplikat, Unidata memungkinkan Anda membuat catatan master dari catatan duplikat.
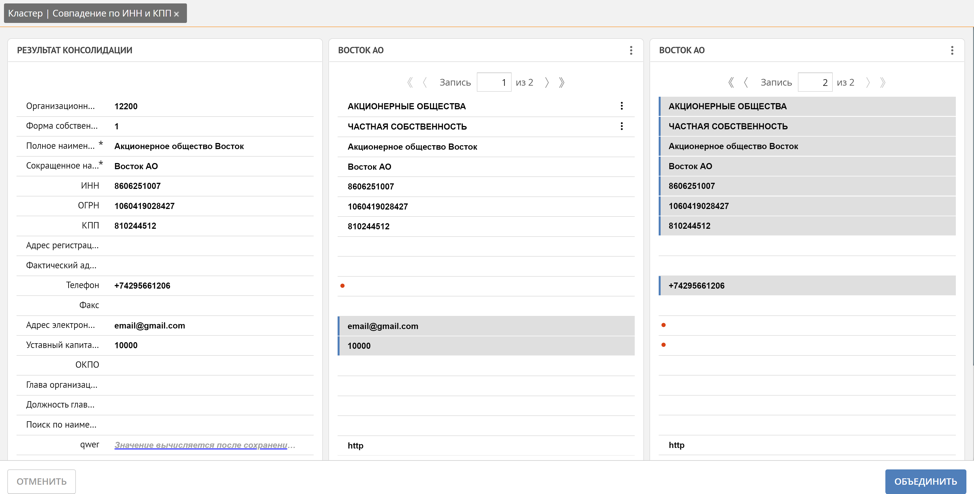
Di sini pengguna dapat secara manual melacak rekaman mana yang secara otomatis menjadi referensi dan, jika perlu, memperbaikinya dengan secara manual menandai nilai atribut rekaman duplikat yang harus disertakan dalam rekaman referensi, atau dengan menandai seluruh rekaman. Selain itu, Unidata mendukung mekanisme untuk memperkaya nilai yang hilang berdasarkan catatan serupa. Misalnya, telepon, surat dan modal saham secara otomatis diperoleh dari 2 catatan duplikat yang berbeda.
Seperti yang telah kita catat, platform, saat membentuk kluster duplikat, secara otomatis menentukan bagaimana record referensi akan dibentuk. Ini karena bobot kepercayaan yang disebutkan sebelumnya dari sistem sumber. Semakin tinggi bobot sistem dari mana record berasal, semakin signifikan nilai atributnya untuk record referensi tersebut. Tetapi seringkali ada situasi ketika nilai atribut tertentu untuk sistem sumber tertentu harus menang di atas yang lainnya, misalnya, kami mempercayai alamat pengiriman aktual klien terutama kepada agen yang secara langsung bernegosiasi di wilayah klien dan mengetahui alamatnya dengan tepat, yang berarti dalam contoh sistem penjualan seluler kami. Untuk mengatasi masalah tersebut, platform memiliki kemampuan untuk menetapkan bobot tidak hanya untuk sumber data, tetapi juga untuk atribut record dalam konteks setiap sumber data.Kombinasi bobot ini memungkinkan Anda mengonfigurasi aturan secara fleksibel untuk menghasilkan rekaman referensi.

Kasus 2. Korespondensi fuzzy dengan nama badan hukum
Meskipun TIN adalah atribut wajib, mari kita asumsikan bahwa informasi pada klien belum diperbarui untuk waktu yang lama, ia telah mengubah bentuk organisasi dan hukumnya. Dalam hal ini, entri dengan TIN yang berbeda akan masuk ke platform dan pertandingan TIN tidak akan berfungsi. Dalam hal ini, platform memungkinkan Anda untuk membentuk aturan kecocokan fuzzy berdasarkan nilai atribut, dalam hal ini dengan nama badan hukum.

Pencarian fuzzy tidak memiliki pengelompokan awal, karena operasi ini cukup intensif sumber daya, yang berarti bahwa aturan ini tidak akan langsung berfungsi saat record baru ditambahkan. Untuk memulai aturan pencarian fuzzy, operasi khusus untuk menemukan duplikat digunakan, yang dimulai secara manual oleh administrator atau oleh sistem sesuai jadwal. Setelah duplikat ditemukan, cluster yang terbentuk dapat dilihat di bagian khusus antarmuka operator data.
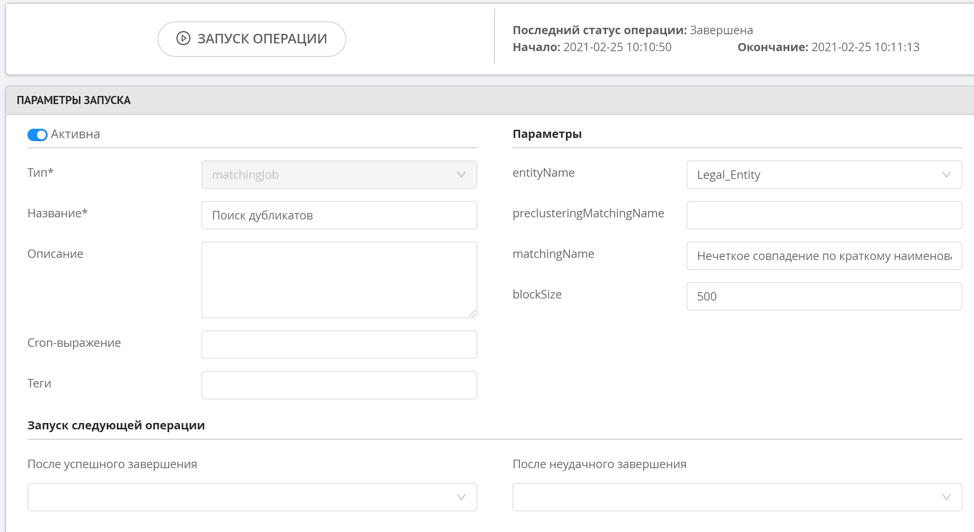

Pencarian duplikat fuzzy bekerja sedemikian rupa sehingga kami menentukan nilai string serupa yang berbeda 1-2 karakter atau tidak memerlukan lebih dari dua permutasi (jarak Levenshtein), ada juga kemungkinan untuk mencari dalam n-gram. Pendekatan ini memungkinkan Anda untuk menemukan rekaman serupa dengan akurasi tinggi, sementara tidak memuat sumber daya untuk menghitung semua kemungkinan manipulasi string jika string sangat berbeda satu sama lain.
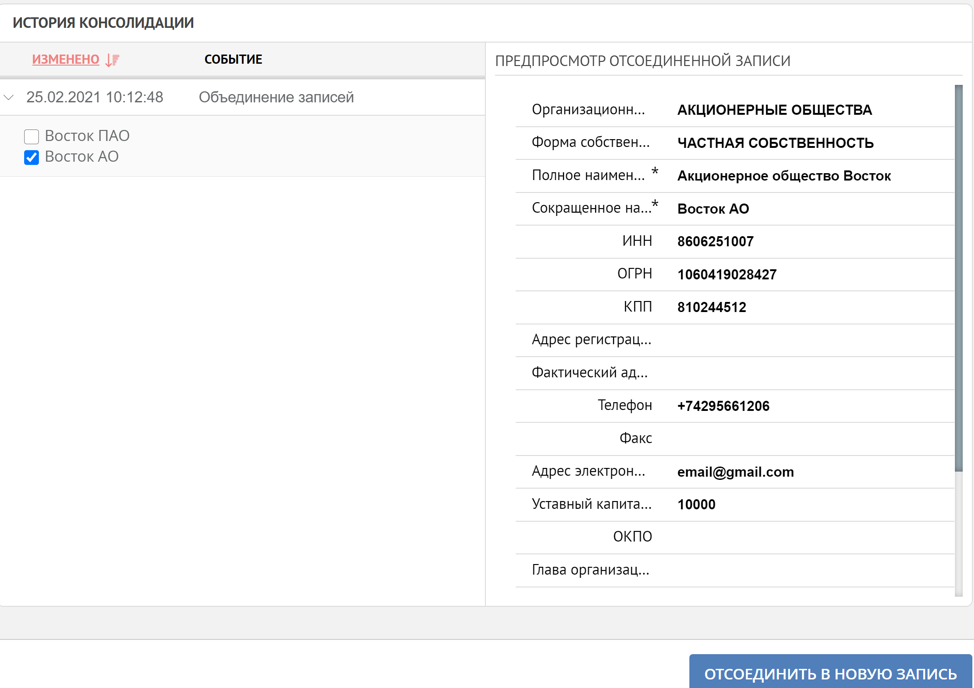
Jadi, kami telah mendemonstrasikan dalam kasus tipikal sederhana prinsip-prinsip platform saat bekerja dengan rekaman duplikat. Pemrosesan duplikat dapat dilakukan sepenuhnya di bawah kendali pengguna atau secara otomatis. Jika konsolidasi data terjadi karena kesalahan, maka, seperti yang disebutkan di awal, sistem selalu memiliki kesempatan untuk melihat riwayat pembentukan catatan referensi dan, jika perlu, memulai proses sebaliknya.
Kami tidak berhenti di situ, kami meneliti algoritme dan pendekatan baru saat bekerja dengan duplikat, kami berusaha keras untuk memastikan kualitas data maksimum dalam berbagai sistem perusahaan.