Pembaca kami tidak bisa tidak memperhatikan minat kami yang semakin besar pada bahasa Go. Bersamaan dengan buku dari postingan sebelumnya , kami memiliki banyak hal menarik tentang topik ini . Hari ini kami ingin menawarkan terjemahan materi "untuk para profesional", yang mendemonstrasikan aspek menarik dari manajemen memori manual di Go, serta eksekusi operasi memori secara bersamaan di Go dan C ++.
Dalam bahasa Dgraph Labs Go digunakan sejak didirikan pada 2015. Setelah lima tahun atau 200.000 baris kode di Go, siap dengan senang hati mengumumkan bahwa Go tidak salah. Bahasa ini menginspirasi tidak hanya sebagai alat untuk membuat sistem baru, tetapi bahkan mendorong skrip untuk ditulis dalam Go yang secara tradisional ditulis dalam Bash atau Python. Ternyata Go memungkinkan Anda membuat basis kode yang bersih, dapat dibaca, dan dapat dipelihara yang - yang terpenting - efisien dan mudah ditangani secara bersamaan.
Namun, ada satu masalah dengan Go, yang sudah memanifestasikan dirinya pada tahap awal pekerjaan: manajemen memori... Kami tidak memiliki keluhan apa pun tentang pengumpul sampah Go, tetapi, selain itu, seberapa menyederhanakan kehidupan pengembang, ia memiliki masalah yang sama dengan pengumpul sampah lainnya: ia tidak dapat bersaing dalam efisiensi dengan manajemen memori manual .
Mengelola memori secara manual menghasilkan penggunaan memori yang lebih sedikit, penggunaan memori yang dapat diprediksi, dan menghindari lonjakan penggunaan memori yang berlebihan ketika sebagian besar memori baru dialokasikan secara tajam. Semua masalah di atas dengan manajemen memori otomatis telah diperhatikan saat menggunakan memori di Go.
Bahasa seperti Rust dapat memperoleh pijakan sebagian karena menyediakan manajemen memori manual yang aman. Selamat datang.
Menurut pengalaman saya, mengalokasikan memori secara manual dan melacak potensi kebocoran memori lebih mudah daripada mencoba mengoptimalkan penggunaan memori dengan alat pengumpulan sampah. Pengumpulan sampah manual sepadan dengan kerumitan membuat database yang menawarkan skalabilitas yang hampir tidak terbatas.
Demi kecintaan pada Go dan kebutuhan untuk menghindari pengumpulan sampah menggunakan Go GC, kami harus menemukan cara inovatif untuk mengelola memori secara manual di Go. Tentu saja, sebagian besar pengguna Go tidak perlu mengelola memori secara manual, dan kami menyarankan Anda menghindari melakukan ini kecuali Anda benar-benar perlu. Dan ketika Anda membutuhkannya - Anda perlu tahu bagaimana melakukannya .
Membangun memori dengan Cgo
Bagian ini dimodelkan setelah artikel wiki Cgo tentang mengubah larik C menjadi segmen Go. Kita dapat menggunakan malloc untuk mengalokasikan memori di C dan menggunakan unsafe untuk meneruskannya ke Go, tanpa memerlukan intervensi apa pun dari pengumpul sampah Go.
import "C"
import "unsafe"
...
var theCArray *C.YourType = C.getTheArray()
length := C.getTheArrayLength()
slice := (*[1 << 28]C.YourType)(unsafe.Pointer(theCArray))[:length:length]
Namun, hal di atas dimungkinkan dengan peringatan yang dicatat di golang.org/cmd/cgo.
: . Go nil C ( Go) C, , C Go. , C Go, Go . C, Go.
Oleh karena itu, alih-alih malloc, kami akan menggunakan padanannya yang
calloc
sedikit lebih berat.
calloc
bekerja persis seperti ini
malloc
, dengan peringatan bahwa ia menyetel ulang memori ke nol sebelum mengembalikannya ke pemanggil.
Untuk memulai, kami baru saja mengimplementasikan fungsi Calloc dan Free dalam bentuk yang paling sederhana yang mengalokasikan dan membebaskan segmen byte untuk Go via Cgo. Untuk menguji fitur ini, tes penggunaan memori terus menerus dikembangkan dan diuji. ... Tes ini, dalam bentuk loop tanpa akhir, mengulangi siklus alokasi / rilis memori, di mana fragmen memori berukuran acak pertama dialokasikan hingga total memori yang dialokasikan mencapai 16 GB, dan kemudian fragmen ini dirilis secara bertahap hingga hanya 1 GB memori yang dialokasikan. .
Program C yang setara bekerja seperti yang diharapkan. Kami
htop
melihat bagaimana jumlah memori yang dialokasikan untuk proses (RSS) pertama-tama menjadi 16 GB, lalu turun menjadi 1 GB, lalu tumbuh lagi menjadi 16 GB, dan seterusnya. Namun, program Go menggunakan
Calloc
dan
Free
menggunakan lebih banyak memori setelah setiap loop (lihat diagram di bawah).
Telah disarankan bahwa hal ini disebabkan oleh fragmentasi memori karena kurangnya "kesadaran thread" dalam panggilan
C.calloc
default. Untuk menghindari ini, diputuskan untuk mencoba
jemalloc
.
jemalloc.dll
jemalloc
Merupakan implementasi umummalloc
yang berfokus pada pencegahan fragmentasi dan mempertahankan konkurensi yang dapat diskalakan.jemalloc
pertama kali digunakan di FreeBSD pada tahun 2005 sebagai pengalokasilibc
dan sejak itu ditemukan digunakan di banyak aplikasi karena perilakunya yang dapat diprediksi. - jemalloc.net
Kami mengganti API kami untuk digunakan
jemalloc
dengan panggilan
calloc
dan
free
. Selain itu, opsi ini bekerja dengan sempurna: ini
jemalloc
secara native mendukung streaming hampir tanpa fragmentasi memori. Tes memori, yang menguji alokasi memori dan siklus deallocation, tetap masuk akal, terlepas dari overhead kecil yang terlibat dalam menjalankan tes.
Hanya untuk menegaskan bahwa kami menggunakan jemalloc dan menghindari konflik penamaan, kami menambahkan awalan saat menginstal
je_
sehingga API kami sekarang memanggil
je_calloc
dan
je_free
, bukan
calloc
dan
free
.
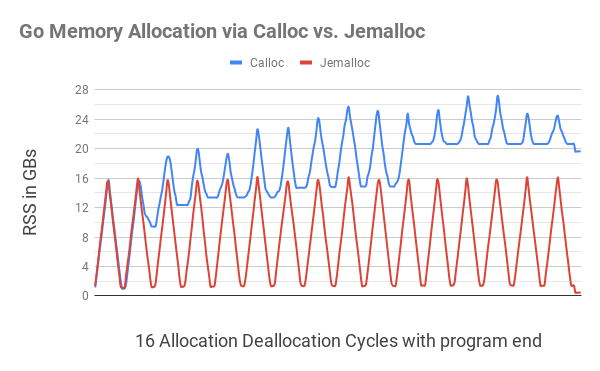
Ilustrasi ini menunjukkan bahwa mengalokasikan memori Go dengan
C.calloc
menyebabkan fragmentasi memori yang serius, yang menyebabkan program menghabiskan hingga 20 GB memori pada siklus ke-11. Kode yang setara
jemalloc
tidak memberikan fragmentasi yang terlihat, cocok di setiap siklus mendekati 1GB.
Mendekati akhir program (riak kecil di tepi kanan), setelah semua memori yang dialokasikan dibebaskan, program
C.calloc
masih mengonsumsi memori kurang dari 20 GB, sementara memori
jemalloc
hanya menghabiskan 400 MB.
Untuk menginstal jemalloc, unduh dari sini dan kemudian jalankan perintah berikut:
./configure --with-jemalloc-prefix='je_' --with-malloc-conf='background_thread:true,metadata_thp:auto' make sudo make install
Seluruh kode
Calloc
terlihat seperti ini:
ptr := C.je_calloc(C.size_t(n), 1)
if ptr == nil {
// NB: throw panic, ,
// . , – , Go,
// .
throw("out of memory")
}
uptr := unsafe.Pointer(ptr)
atomic.AddInt64(&numBytes, int64(n))
// C Go, .
return (*[MaxArrayLen]byte)(uptr)[:n:n]
Kode ini termasuk dalam paket Ristretto . Sebuah tag assembly telah ditambahkan untuk mengaktifkan kode yang dihasilkan untuk beralih ke jemalloc untuk mengalokasikan potongan byte
jemalloc
. Untuk lebih menyederhanakan operasi penerapan, pustaka ditautkan secara statis
jemalloc
ke biner Go apa pun yang dihasilkan dengan menyetel tanda LDFLAGS yang sesuai.
Menguraikan Struktur Go menjadi Segmen Byte
Kami sekarang memiliki cara untuk mengalokasikan dan membebaskan segmen byte, dan kemudian kami akan menggunakannya untuk menyusun struktur kami di Go. Anda bisa mulai dengan contoh paling sederhana (kode lengkap).
type node struct {
val int
next *node
}
var nodeSz = int(unsafe.Sizeof(node{}))
func newNode(val int) *node {
b := z.Calloc(nodeSz)
n := (*node)(unsafe.Pointer(&b[0]))
n.val = val
return n
}
func freeNode(n *node) {
buf := (*[z.MaxArrayLen]byte)(unsafe.Pointer(n))[:nodeSz:nodeSz]
z.Free(buf)
}
Dalam contoh di atas, kami meletakkan struktur Go pada memori yang dialokasikan di C menggunakan
newNode
. Kami telah membuat fungsi
freeNode
yang sesuai yang memungkinkan kami untuk membebaskan memori segera setelah kami selesai dengan strukturnya. Struktur dalam bahasa Go berisi tipe data yang paling sederhana
int
dan penunjuk ke struktur node berikutnya, semua ini dapat diatur dalam program, dan kemudian entitas ini dapat diakses. Kami telah memilih objek node 2M dan membuat daftar tertaut dari mereka untuk menunjukkan bahwa fungsi jemalloc seperti yang diharapkan.
Dengan alokasi memori default Go, Anda dapat melihat bahwa 31 MiB dari heap dialokasikan ke daftar tertaut dengan objek 2M, tetapi tidak ada yang dialokasikan
jemalloc
.
$ go run . Allocated memory: 0 Objects: 2000001 node: 0 ... node: 2000000 After freeing. Allocated memory: 0 HeapAlloc: 31 MiB
Dengan menggunakan tag assembly
jemalloc
, kami melihat bahwa 30 MiB byte memori dialokasikan melalui
jemalloc
, dan setelah daftar tertaut dilepaskan, nilai ini turun menjadi nol. Go hanya mengalokasikan 399 KiB dari memori, yang mungkin disebabkan oleh overhead menjalankan program.
$ go run -tags=jemalloc . Allocated memory: 30 MiB Objects: 2000001 node: 0 ... node: 2000000 After freeing. Allocated memory: 0 HeapAlloc: 399 KiB
Amortisasi Biaya Calloc dengan Allocator
Kode di atas melakukan tugas alokasi memori dengan baik di Go. Tapi ini dilakukan dengan mengorbankan penurunan kinerja . Setelah menjalankan kedua salinan dengan
time
, kami melihat bahwa tanpa
jemalloc
program diatasi dalam 1,15 detik. Karena
jemalloc
dia melakukannya 5 kali lebih lambat, dengan lebih dari 5,29.
$ time go run . go run . 1.15s user 0.25s system 162% cpu 0.861 total $ time go run -tags=jemalloc . go run -tags=jemalloc . 5.29s user 0.36s system 108% cpu 5.200 total
Perlambatan ini dapat dikaitkan dengan fakta bahwa panggilan Cgo dibuat untuk setiap alokasi memori, dan setiap panggilan Cgo menimbulkan beberapa overhead. Untuk menangani ini, perpustakaan Allocator ditulis , juga disertakan dalam paket ristretto / z . Library ini mengalokasikan segmen memori yang lebih besar dalam satu panggilan, yang masing-masing dapat menampung banyak objek kecil, sehingga tidak perlu panggilan Cgo yang mahal .
Allocator dimulai dengan buffer dan, segera setelah digunakan, membuat buffer baru dua kali ukuran buffer pertama. Ini memelihara daftar internal dari semua buffer yang dialokasikan. Akhirnya, saat pengguna selesai dengan data, kita bisa memanggil Release untuk melepaskan semua buffer ini dalam satu gerakan. Catatan: Allocator tidak memindahkan memori sama sekali. Ini memastikan bahwa semua petunjuk yang kita miliki ke struct terus berfungsi.
Meskipun manajemen memori seperti itu dapat terlihat janggal dan dibandingkan dengan cara mengoperasikannya
tcmalloc
dan
jemalloc
, pendekatan ini jauh lebih sederhana. Setelah Anda mengalokasikan memori, Anda tidak dapat membebaskan hanya satu struktur. Anda hanya dapat membebaskan semua memori yang digunakan oleh Allocator sekaligus.
Apa yang benar-benar bagus dari Allocator adalah mengalokasikan jutaan struktur dengan murah dan kemudian membebaskannya ketika pekerjaan selesai tanpa harus melibatkan banyak Go untuk melakukan pekerjaan itu . Menjalankan program di atas dengan build tag pengalokasi baru akan berjalan lebih cepat daripada versi memori Go.
$ time go run -tags="jemalloc,allocator" . go run -tags="jemalloc,allocator" . 1.09s user 0.29s system 143% cpu 0.956 total
Di Go 1.14 dan yang lebih baru, bendera
-race
mengaktifkan pemeriksaan penyelarasan struktur dalam memori. Allocator memiliki metode
AllocateAligned
yang mengembalikan memori, dan penunjuk harus disejajarkan dengan benar untuk lulus pemeriksaan ini. Jika strukturnya besar, maka beberapa memori mungkin hilang, tetapi instruksi CPU mulai bekerja lebih efisien karena pembatasan kata yang benar.
Ada masalah lain dengan manajemen memori. Kebetulan memori dialokasikan di satu tempat, dan dilepaskan di tempat yang sama sekali berbeda. Semua komunikasi antara dua titik ini dapat dilakukan melalui struktur, dan mereka hanya dapat dibedakan dengan mentransfer objek tertentu
Allocator
. Untuk menangani ini, kami menetapkan ID unik untuk setiap objek.
Allocator
yang disimpan objek ini dalam referensi
uint64
. Setiap objek baru
Allocator
disimpan dalam kamus global dengan referensi ke referensi itu sendiri. Objek Allocator kemudian dapat dipanggil kembali menggunakan referensi ini dan dirilis saat data tidak lagi diperlukan.
Atur tautan dengan kompeten
JANGAN merujuk Go memori yang dialokasikan dari memori yang dialokasikan secara manual.
Saat mengalokasikan struktur secara manual seperti yang ditunjukkan di atas, penting untuk memastikan bahwa tidak ada referensi ke memori yang dialokasikan oleh Go dalam struktur itu. Mari kita ubah sedikit struktur di atas:
type node struct {
val int
next *node
buf []byte
}
Mari gunakan fungsi yang
root := newNode(val)
ditentukan di atas untuk memilih node secara manual. Jika kita kemudian menginstal
root.next = &node{val: val}
, sehingga mengalokasikan semua node lain dalam daftar tertaut melalui memori Go, kita pasti mendapatkan kesalahan sharding berikut:
$ go run -race -tags="jemalloc" . Allocated memory: 16 B Objects: 2000001 unexpected fault address 0x1cccb0 fatal error: fault [signal SIGSEGV: segmentation violation code=0x1 addr=0x1cccb0 pc=0x55a48b]
Memori yang dialokasikan oleh Go tunduk pada pengumpulan sampah karena tidak ada struktur Go yang valid yang menunjuk padanya. Referensi hanya dari memori yang dialokasikan di C, dan heap Go tidak berisi referensi yang sesuai, yang memicu kesalahan di atas. Jadi, jika Anda membuat struktur dan mengalokasikan memori untuknya secara manual, penting untuk memastikan bahwa semua bidang yang dapat diakses secara rekursif juga dialokasikan secara manual.
Misalnya, jika struktur di atas menggunakan segmen byte, maka kami mengalokasikan segmen tersebut menggunakan Allocator, dan juga menghindari pencampuran memori Go dengan memori C.
b := allocator.AllocateAligned(nodeSz)
n := (*node)(unsafe.Pointer(&b[0]))
n.val = -1
n.buf = allocator.Allocate(16) // 16
rand.Read(n.buf)
Bagaimana menangani gigabyte memori khusus
Allocator
bagus untuk memilih jutaan struktur secara manual. Tetapi ada juga kasus ketika Anda perlu membuat miliaran benda kecil dan menyortirnya. Untuk melakukan ini di Go, bahkan dengan bantuan
Allocator
, Anda perlu menulis kode seperti ini:
var nodes []*node
for i := 0; i < 1e9; i++ {
b := allocator.AllocateAligned(nodeSz)
n := (*node)(unsafe.Pointer(&b[0]))
n.val = rand.Int63()
nodes = append(nodes, n)
}
sort.Slice(nodes, func(i, j int) bool {
return nodes[i].val < nodes[j].val
})
// .
Semua node 1B ini dialokasikan secara manual
Allocator
, yang mahal. Anda juga harus mengeluarkan uang untuk setiap segmen memori di Go, yang harganya cukup mahal, karena kami memerlukan memori 8GB (8 byte per penunjuk node).
Untuk menangani situasi praktis ini,
z.Buffer
file yang dipetakan memori telah dibuat, sehingga memungkinkan Linux untuk menukar dan membersihkan halaman memori sesuai kebutuhan sistem. Itu mengimplementasikan
io.Writer
dan memungkinkan kita untuk tidak bergantung
bytes.Buffer
.
Lebih penting lagi, ini
z.Buffer
memberikan cara baru untuk menyoroti segmen data yang lebih kecil. Saat Anda menelepon
SliceAllocate(n)
,
z.Buffer
akan mencatat panjang segmen yang akan dipilih
(n)
, dan kemudian memilih segmen tersebut. Ini membuatnya
z.Buffer
lebih mudah untuk memahami batas segmen dan melakukan iterasi pada segmen dengan benar
SliceIterate
.
Menyortir data panjang variabel
Untuk pengurutan, awalnya kami mencoba mendapatkan offset segmen dari
z.Buffer
, merujuk ke segmen untuk perbandingan, tetapi hanya mengurutkan offset. Setelah menerima offsetnya, ia
z.Buffer
dapat membacanya, mencari panjang segmen dan mengembalikan segmen ini. Jadi, sistem seperti itu memungkinkan Anda mengembalikan segmen dalam bentuk yang diurutkan tanpa menggunakan pengacakan memori apa pun. Meskipun inovatif, mekanisme ini memberikan tekanan yang signifikan pada memori, karena kami masih harus membayar penalti memori 8GB hanya untuk mendorong offset yang menarik ke memori Go.
Faktor terpenting yang membatasi pekerjaan kami adalah bahwa ukurannya tidak sama untuk semua segmen. Selain itu, kami hanya dapat mengakses segmen ini secara berurutan, dan tidak secara terbalik atau acak, tidak dapat menghitung dan menyimpan offset sebelumnya. Sebagian besar algoritme untuk pengurutan mengasumsikan bahwa semua nilai memiliki ukuran yang sama, dapat diakses dalam urutan apa pun, dan tidak ada yang mencegahnya untuk ditukar.
sort.Slice
di Go bekerja dengan cara yang sama, dan oleh karena itu kurang cocok untuk
z.Buffer
.
Dengan keterbatasan ini, disimpulkan bahwa algoritma pengurutan gabungan paling cocok untuk tugas yang sedang dikerjakan. Dengan merge sort, Anda dapat bekerja dalam buffer, melakukan operasi secara berurutan, dengan overhead memori tambahan hanya setengah dari ukuran buffer. Ternyata tidak hanya lebih murah daripada memindahkan indentasi ke dalam memori, tetapi juga secara signifikan meningkatkan prediktabilitas dalam hal overhead memori (setengah ukuran buffer). Lebih baik lagi, overhead yang diperlukan untuk melakukan pengurutan penggabungan itu sendiri dipetakan ke memori.
Ada satu lagi efek yang sangat positif menggunakan jenis gabungan. Pengurutan offset harus menyimpan offset dalam memori sementara kita mengulanginya dan memproses buffer, yang hanya meningkatkan tekanan pada memori. Dengan merge sort, semua memori tambahan yang kami butuhkan dibebaskan pada saat pencacahan dimulai, yang berarti kami akan memiliki lebih banyak memori untuk memproses buffer.
z. Buffer juga mendukung alokasi memori
Calloc
, serta pemetaan memori otomatis setelah melebihi batas tertentu yang ditentukan oleh pengguna. Oleh karena itu, alat ini berfungsi baik dengan data dalam berbagai ukuran.
buffer := z.NewBuffer(256<<20) // 256MB Calloc.
buffer.AutoMmapAfter(1<<30) // mmap 1GB.
for i := 0; i < 1e9; i++ {
b := buffer.SliceAllocate(nodeSz)
n := (*node)(unsafe.Pointer(&b[0]))
n.val = rand.Int63()
}
buffer.SortSlice(func(left, right []byte) bool {
nl := (*node)(unsafe.Pointer(&left[0]))
nr := (*node)(unsafe.Pointer(&right[0]))
return nl.val < nr.val
})
// .
buffer.SliceIterate(func(b []byte) error {
n := (*node)(unsafe.Pointer(&b[0]))
_ = n.val
return nil
})
Menangkap kebocoran memori
Seluruh diskusi ini tidak akan lengkap tanpa menyentuh topik kebocoran memori. Lagi pula, jika kita mengalokasikan memori secara manual, kebocoran memori tidak akan terhindarkan dalam semua kasus tersebut ketika kita lupa untuk membebaskan memori. Bagaimana Anda bisa menangkap mereka?
Kami telah lama menggunakan solusi sederhana - kami menggunakan penghitung atom yang melacak jumlah byte yang dialokasikan selama panggilan tersebut. Dalam hal ini, Anda dapat dengan cepat mengetahui berapa banyak memori yang telah kami alokasikan secara manual dalam program yang digunakan
z.NumAllocBytes()
. Jika pada akhir pengujian memori kami masih memiliki sisa memori tambahan, itu berarti ada kebocoran.
Ketika kami berhasil menemukan kebocoran, pertama-tama kami mencoba menggunakan profiler memori jemalloc. Tetapi segera menjadi jelas bahwa ini tidak membantu - dia tidak melihat seluruh tumpukan panggilan, karena dia menabrak perbatasan Cgo. Semua yang dilihat profiler adalah alokasi memori dan tindakan rilis dari panggilan yang sama
z.Calloc
dan
z.Free
.
Berkat runtime Go, kami dengan cepat dapat membangun sistem sederhana untuk menangkap penelepon
z.Calloc
dan memetakannya ke panggilan
z.Free
. Sistem ini memerlukan kunci mutex, jadi kami memutuskan untuk tidak mengaktifkannya secara default. Sebagai gantinya, kami menggunakan bendera build
leak
untuk mengaktifkan pesan debug untuk kebocoran di majelis pengembang. Dengan demikian, kebocoran secara otomatis terdeteksi dan ditampilkan ke konsol persis di mana asalnya.
// .
pc, _, l, ok := runtime.Caller(1)
if ok {
dallocsMu.Lock()
dallocs[uptr] = &dalloc{
pc: pc,
no: l,
sz: n,
}
dallocsMu.Unlock()
}
// , , .
// ,
// , .
$ go test -v -tags="jemalloc leak" -run=TestCalloc
...
LEAK: 128 at func: github.com/dgraph-io/ristretto/z.TestCalloc 91
Keluaran
Dengan bantuan teknik yang dijelaskan, mean emas tercapai. Kami dapat mengalokasikan memori secara manual di jalur kode penting yang sangat bergantung pada memori yang tersedia. Pada saat yang sama, kita dapat memanfaatkan pengumpulan sampah otomatis dengan cara yang tidak terlalu kritis. Walaupun Anda tidak pandai menangani Cgo atau jemalloc, Anda dapat menggunakan teknik ini dengan potongan memori yang relatif besar di Go - efeknya akan sebanding.
Semua pustaka yang disebutkan di atas tersedia di bawah lisensi Apache 2.0 dalam paket Ristretto / z . Tes memori dan kode demo ada di folder contrib .