
Bagaimana cara memastikan bahwa setiap pengembang dapat dengan cepat memberikan solusi untuk masalahnya dan menjamin untuk mengirimkannya ke produksi? Menerapkan aplikasi itu mudah. Menjadikannya produk yang lengkap sehingga lusinan tim menggunakannya pada seratus contoh lebih sulit. Dan jika kita berbicara tentang sistem master untuk beberapa terabyte, maka tingkat kecemasan meningkat, tangan berkeringat, dan pangkalan meledak (mungkin).
Saya ingin berbagi cara untuk menerapkan tanpa waktu henti dan tanpa penolakan layanan. Pipeline Jenkins, tanpa perantara, 500 instance dalam lingkungan produksi dalam 60 menit. Semua ini dalam open source. Untuk detailnya saya mengundang Anda di bawah kucing.
Nama saya Roman Proskin, saya membuat dan mendukung sistem beban tinggi berdasarkan Tarantool di Mail.ru Group. Saya akan memberi tahu Anda bagaimana tim kami membangun penerapan aplikasi Tarantool, yang memperbarui kode di lingkungan produksi tanpa waktu henti atau penolakan layanan. Saya akan menjelaskan masalah yang kami temui dalam prosesnya, dan solusi apa yang kami pilih pada akhirnya. Saya berharap pengalaman kami akan berguna dalam membangun penerapan Anda .
Menerapkan aplikasi itu mudah. Tarantool memiliki utilitas cartridge-cli ( github). Dengan itu, aplikasi berkerumun akan diterapkan di suatu tempat di Docker dalam beberapa menit. Jauh lebih sulit untuk mengubah solusi dari lutut menjadi produk yang lengkap. Ini harus dengan mudah menangani ratusan contoh. Pada saat yang sama, Anda harus diminta oleh lusinan tim dari berbagai tingkat pelatihan.
Ide di balik penerapan kami sangat sederhana:
- Anda mengambil dua server besi.
- Pada setiap Anda meluncurkan satu contoh.
- Gabungkan mereka menjadi satu set replika.
- Anda memperbarui satu per satu.
Tetapi ketika datang ke sistem master dengan beberapa terabyte data, tingkat kecemasan meningkat, tangan berkeringat, dan pangkalan meledak (mungkin).
Setting kondisi awal
Sistem memiliki SLA yang ketat: perlu untuk memastikan ketersediaan 99%, dengan mempertimbangkan pekerjaan yang direncanakan. Ini berarti ada total 87 jam per tahun ketika kami tidak mampu untuk menjawab pertanyaan. Tampaknya 87 jam itu banyak, tapi ...
Proyek ini dirancang untuk volume data sekitar 1,8 TB. Hanya perlu waktu 40 menit untuk memulai ulang! Pembaruan itu sendiri, jika perubahan digulung secara manual, akan menambahkan lebih banyak dari atas. Kami membuat tiga pembaruan per minggu: total 40 * 3 * 52/60 = 104 jam - SLA dilanggar . Dan ini hanya pekerjaan terencana tanpa memperhitungkan kecelakaan yang pasti akan terjadi.
Aplikasi dikembangkan untuk beban pengguna yang tinggi, yang berarti harus memenuhi persyaratan stabilitas. Agar tidak kehilangan data jika terjadi kegagalan node, kami memutuskan untuk membagi cluster kami secara geografis menjadi dua pusat data. Jadi kami memutuskan mekanisme penerapan yang tidak akan melanggar SLA. Biarkan instance diperbarui tidak segera, tetapi dalam kelompok di seluruh pusat data.
Beban dapat ditransfer ke pusat data kedua, kemudian cluster akan tersedia untuk direkam selama pembaruan keseluruhan. Ini adalah penerapan bahu klasik dan salah satu praktik pemulihan bencana standar .
Kemampuan untuk memperbarui di seluruh pusat data adalah salah satu elemen kunci penerapan zero-downtime. Saya akan memberi tahu Anda lebih banyak tentang proses di akhir artikel, tetapi untuk saat ini saya akan membahas fitur-fitur penerapan tidak manusiawi kami dan kesulitan yang kami temui.
Masalah
Kami mentransfer lalu lintas di seberang jalan
Ada beberapa pusat data dan permintaan dapat dikirim ke salah satunya. Perjalanan ke pusat data terdekat untuk mendapatkan data akan meningkatkan waktu respons sebesar 1-100 md. Untuk menghindari lalu lintas silang, kami memberikan pusat data kami aktif dan tag siaga . Penyeimbang (nginx) dikonfigurasi sehingga lalu lintas selalu mengalir ke pusat data aktif. Jika Tarantool crash atau menjadi tidak tersedia di pusat data aktif, secara otomatis akan beralih ke cadangan.
Setiap permintaan pengguna itu penting, jadi Anda memerlukan cara untuk memastikan bahwa koneksi tetap terjaga. Untuk ini, kami menulis pedoman terpisah yang memungkinkan yang mengalihkan lalu lintas antar pusat data. Switching diimplementasikan menggunakan arahan
backup
dalam deskripsi
upstream
untuk server. Hulu dipilih oleh batas, yang akan menjadi aktif. Sisanya ditentukan
backup
: nginx akan membiarkan lalu lintas hanya jika semua yang aktif tidak tersedia. Saat mengubah konfigurasi, koneksi terbuka tidak ditutup, dan permintaan baru akan masuk ke router yang tidak dapat dimulai ulang.
Apa yang dapat dilakukan jika infrastruktur tidak memiliki penyeimbang beban eksternal? Tulis mini-balancer Anda sendiri di Java yang akan memantau ketersediaan instance Tarantool. Tetapi subsistem terpisah ini juga akan membutuhkan penerapannya sendiri. Pilihan lainnya adalah membangun mekanisme switching di dalam router. Satu hal tetap tidak berubah: lalu lintas HTTP perlu dikontrol.
Kami menyelesaikannya dengan nginx, tetapi masalahnya tidak berakhir di sana. Peralihan juga harus dilakukan untuk master dalam set replika. Seperti yang saya sebutkan, data harus disimpan dekat dengan router untuk menghindari perjalanan jaringan yang tidak perlu. Selain itu, saat master saat ini (yaitu, penyimpanan dengan akses tulis) lumpuh, mekanisme failover tidak langsung bekerja. Meskipun kluster membuat keputusan umum tentang tidak tersedianya instans, semua permintaan untuk bagian data yang terpengaruh akan keliru. Untuk mengatasi masalah ini, kami juga perlu menyusun pedoman, di mana kami menggunakan kueri GraphQL ke API cluster.
Mekanisme untuk mengubah wizard dan mengalihkan lalu lintas pengguna adalah elemen kunci terakhir dari penerapan tanpa waktu henti. Penyeimbang beban terkontrol menghindari hilangnya koneksi dan kesalahan dalam pemrosesan permintaan pengguna, dan mengubah master - kesalahan dengan akses data. Bersama dengan pembaruan di pundak ketiga pilar ini, penerapan toleransi kesalahan diperoleh, yang selanjutnya kami otomatiskan.
Memerangi warisan
Pelanggan sudah memiliki mekanisme peluncuran yang siap pakai: peran yang menerapkan dan mengonfigurasi instance selangkah demi selangkah. Lalu kami datang dengan magic ansible-cartridge ( github) yang akan menyelesaikan semua masalah. Kami tidak hanya memperhitungkan bahwa ansible-cartridge itu sendiri adalah monolit - satu peran besar, tahapan yang berbeda dipisahkan oleh label dan tugas terpisah. Untuk memanfaatkannya sepenuhnya, perlu mengubah proses pengiriman artefak, merevisi struktur direktori pada mesin target, mengubah orchestrator, dan banyak lagi. Saya menghabiskan satu bulan menyempurnakan penerapan menggunakan kartrid yang memungkinkan. Peran monolitik tidak cocok dengan buku pedoman yang sudah selesai. Ini tidak berhasil dalam bentuk ini, dan saya dihentikan oleh pertanyaan yang adil dari seorang kolega: "Apakah kita membutuhkannya?"
Kami tidak menyerah - kami memisahkan konfigurasi cluster dari satu bagian, yaitu:
- menggabungkan contoh penyimpanan ke dalam set replika;
- bootstrap vshard (mekanisme sharding data cluster);
- menyiapkan failover (peralihan otomatis master jika jatuh).
Ini adalah tahap terakhir penerapan, saat semua instance sudah aktif dan berjalan. Sayangnya, semua langkah lainnya harus dibiarkan begitu saja.
Memilih orkestrator
Kode pada server tidak berguna jika tidak dapat dijalankan. Kami membutuhkan utilitas untuk memulai dan menghentikan instance Tarantool. Kartrid-ansible mencakup tugas-tugas untuk membuat file layanan systemctl dan bekerja dengan paket rpm. Tetapi kekhususan tugas kami adalah adanya sirkuit tertutup di pelanggan dan tidak adanya hak sudo. Ini berarti kami tidak dapat menggunakan systemctl.
Segera kami menemukan orkestrator yang tidak memerlukan hak akses root permanen - supervisord... Saya harus menginstalnya terlebih dahulu di semua server, dan juga menyelesaikan masalah lokal dengan akses ke file soket. Peran baru yang memungkinkan tampaknya bekerja dengan supervisord: ini mencakup tugas untuk membuat file konfigurasi, memperbarui konfigurasi, memulai dan menghentikan instance. Itu cukup untuk membuatnya menjadi produksi.
Demi percobaan, kami menambahkan kemampuan untuk menjalankan aplikasi menggunakan supervisord di ansible-cartridge. Cara ini ternyata kurang fleksibel dan masih menunggu penyelesaian di cabang tersendiri.
Mengurangi waktu pemuatan
Orkestrator mana pun yang kami gunakan, kami tidak dapat menunggu satu jam hingga instance diluncurkan. Ambang batasnya adalah 20 menit. Jika instans tidak tersedia lebih lama dari ambang batas ini, crash otomatis akan dipicu dan dicatat dalam sistem akuntansi. Kecelakaan yang sering terjadi mempengaruhi kinerja utama tim dan dapat merusak rencana pengembangan sistem. Saya tidak ingin kehilangan premi sama sekali karena penyebaran yang diperlukan secara dangkal. Bagaimanapun, Anda harus menyimpannya dalam 20 menit.
Fakta: Waktu download secara langsung tergantung pada jumlah data. Semakin banyak Anda perlu meningkatkan dari log ke RAM, semakin lama instance dimulai setelah pembaruan. Anda juga perlu mempertimbangkan bahwa instance penyimpanan pada mesin yang sama akan bersaing untuk mendapatkan sumber daya: Tarantool menggunakan semua inti prosesor untuk membuat indeks.
Berdasarkan pengamatan kami, ukuran
memtx_memory
per instance tidak boleh melebihi 40 GB. Nilai ini optimal untuk pemulihan instance yang membutuhkan waktu kurang dari 20 menit. Jumlah instance di satu server dihitung secara terpisah dan terkait erat dengan infrastruktur proyek.
Kami menghubungkan pemantauan
Sistem apa pun perlu dipantau, dan Tarantool tidak terkecuali. Pemantauan kami tidak segera muncul. Seluruh blok dihabiskan untuk mendapatkan akses yang diperlukan, persetujuan, dan pengaturan lingkungan.
Dalam proses pengembangan aplikasi dan penulisan pedoman, kami sedikit memodifikasi modul metrik ( github ). Sekarang Anda dapat membagi metrik dengan nama instance tempat mereka terbang - membuat label global. Sebagai hasil dari integrasi dengan sistem pemantauan, peran keseluruhan telah muncul untuk aplikasi cluster. Jenis baru dari kuantil metrik juga muncul dari generalisasi persyaratan untuk sistem kami.
Sekarang kita melihat jumlah permintaan saat ini ke sistem, ukuran memori yang digunakan, replikasi lag dan banyak metrik utama lainnya. Selain itu, mereka dikonfigurasi dengan pemberitahuan dalam obrolan. Masalah yang paling kritis jatuh ke dalam sistem umum kecelakaan mobil dan memiliki SLA yang jelas untuk dieliminasi.
Sedikit tentang alatnya. Penjelasan rinci tentang di mana, apa dan bagaimana cara mendapatkannya dikumpulkan di etcd , dari mana agen telegraf menerima instruksinya. Metrik berformat JSON disimpan di InfluxDB . Kami menggunakan Grafana sebagai visualisator , yang bahkan kami membuat dasbor templat . Dan terakhir, peringatan dikonfigurasi melalui kapasitor .
Tentu saja, ini bukan satu-satunya pilihan untuk melaksanakan pemantauan. Anda dapat menggunakan Prometheus , dan metrik hanya tahu cara memberi nilai dalam format yang diperlukan. Untuk peringatan, zabbix juga bisa berguna , misalnya.
Kolega saya memberi tahu saya lebih lanjut tentang menyiapkan pemantauan untuk Tarantool di artikel " Memantau Tarantool: Log, Metrik, dan Pemrosesannya ".
Menyiapkan logging
Anda tidak dapat membatasi diri Anda sendiri pada pemantauan. Untuk mendapatkan gambaran lengkap tentang apa yang terjadi dengan sistem, semua diagnostik harus dikumpulkan, dan ini juga termasuk log. Selain itu, semakin tinggi level logging, semakin banyak informasi debugging dan semakin besar file log.
Ruang disk tidak terbatas. Aplikasi kami dapat menghasilkan hingga 1 TB log per hari pada beban puncak. Dalam situasi seperti itu, Anda dapat menambahkan disk, tetapi cepat atau lambat ruang kosong atau anggaran proyek akan habis. Tetapi Anda juga tidak ingin kehilangan informasi debugging tanpa jejak! Apa yang harus dilakukan?
Salah satu tahapan penerapan, kami menambahkan pengaturan logrotate: simpan beberapa file 100MB mentah dan kompres beberapa lagi. Dalam operasi normal, ini cukup untuk menemukan masalah lokal dalam waktu 24 jam. Log disimpan dalam direktori yang ditentukan secara ketat dalam format JSON. Semua server menjalankan daemon filebeat , yang mengumpulkan log aplikasi dan mengirimkannya untuk penyimpanan jangka panjang ke ElasticSearch . Pendekatan ini menyelamatkan Anda dari kesalahan luapan disk dan memungkinkan Anda menganalisis kinerja sistem jika terjadi masalah jangka panjang. Dan pendekatan ini cocok dengan penerapan.
Kami mengukur solusinya
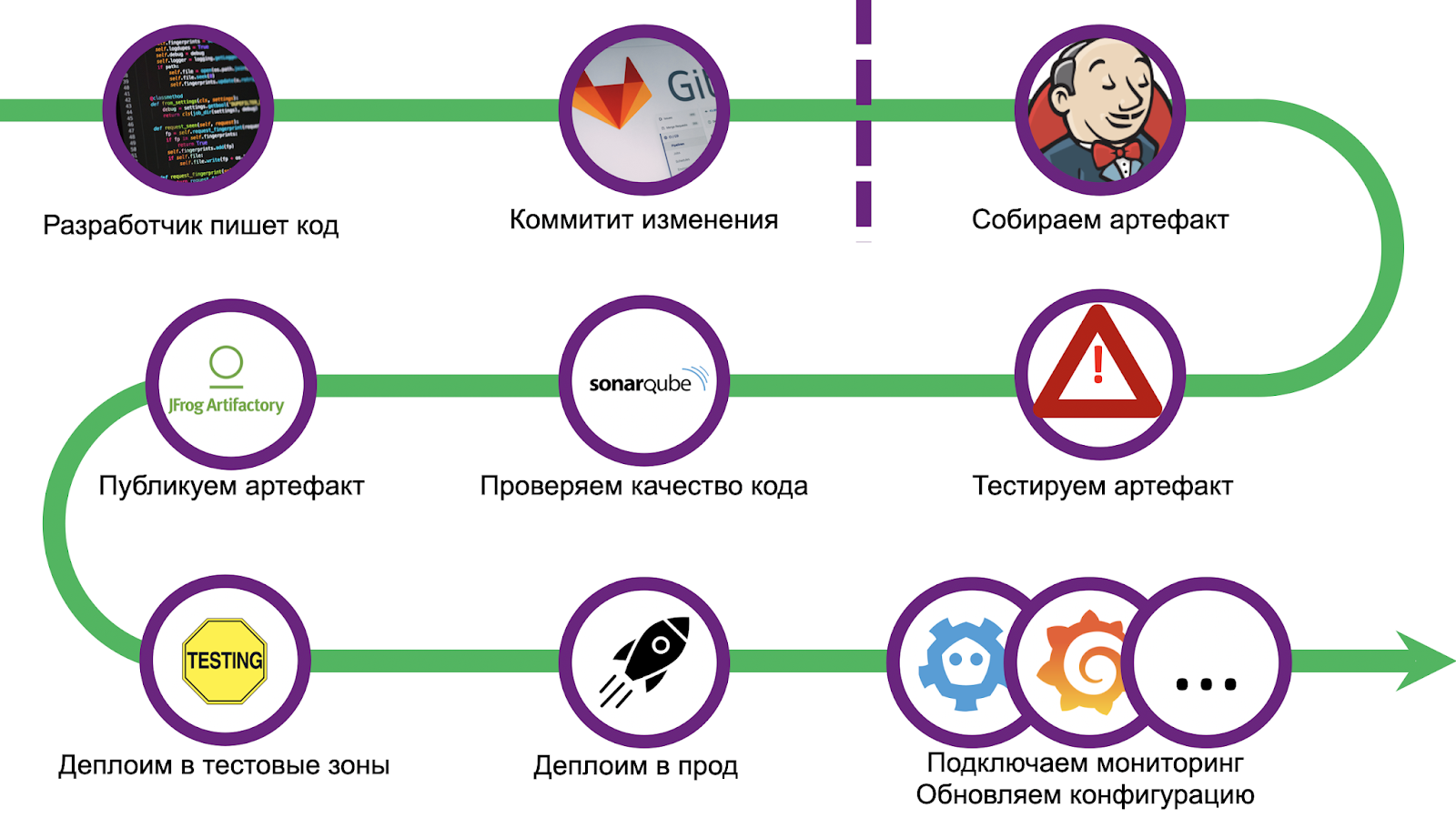
Jalannya panjang dan berduri, kami mendapat jumlah kerucut yang lumayan. Agar tidak mengulangi kesalahan, kami menstandarkan penerapan dan menggunakan bundel CI / CD - Gitlab + Jenkins. Penskalaan juga menyebabkan sejumlah masalah, men-debug solusi tersebut membutuhkan waktu lebih dari satu bulan. Tetapi kami telah mengatasinya, dan sekarang kami siap untuk berbagi pengalaman kami dengan Anda. Mari kita ikuti langkah-langkahnya.
Bagaimana cara memastikan bahwa setiap pengembang dapat dengan cepat memberikan solusi untuk masalahnya dan menjamin untuk mengirimkannya ke produksi? Singkirkan Jenkinsfile darinya! Perlu untuk menguraikan batasan yang tegas, melampaui yang berarti ketidakmungkinan penerapan, dan mengarahkan pengembang di sepanjang jalur ini.
Kami membuat aplikasi sampel lengkap, yang diluncurkan dengan cara yang sama dan merupakan titik awal yang lengkap. Namun kami melangkah lebih jauh dengan pelanggan: kami menulis utilitas untuk secara otomatis membuat template yang menyiapkan repositori git dan tugas Jenkins. Pengembang akan membutuhkan kurang dari satu jam untuk segala sesuatu tentang segala hal, dan proyek tersebut akan diproduksi.
Pipeline dimulai dengan pemeriksaan kode standar dan penyiapan lingkungan. Selain itu, kami menempatkan inventaris untuk penerapan selanjutnya di beberapa zona uji fungsional dan prod. Kemudian tibalah tahap pengujian unit.
Kerangka uji Tarantool standar yang paling baru ( github). Anda dapat menulis tes unit dan integrasi di dalamnya, ada modul tambahan untuk menjalankan dan mengkonfigurasi Kartrid Tarantool . Juga dalam versi terbaru Anda dapat mengaktifkan cakupan . Kami memulainya dengan perintah sederhana:
.rocks/bin/luatest --coverage
Di akhir pengujian, statistik yang dikumpulkan dikirim ke SonarQube - perangkat lunak untuk mengevaluasi kualitas dan keamanan kode. Di dalam, kami telah mengkonfigurasi Gerbang Kualitas. Kode apa pun dalam aplikasi, apa pun bahasanya (Lua, Python, SQL, dll.), Divalidasi. Namun, tidak ada penangan bawaan untuk Lua, jadi untuk merepresentasikan cakupan dalam format umum, kami memiliki plugin yang diinstal sebelum pengujian dimulai.
tarantoolctl rocks install luacov 0.13.0-1 # coverage
tarantoolctl rocks install luacov-reporters 0.1.0-1 #
Versi konsol sederhana dapat dilihat seperti ini:
.rocks/bin/luacov -r summary . && cat ./luacov.report.out
Laporan untuk SonarQube dibuat dengan perintah:
.rocks/bin/luacov -r sonar
Setelah cakupan muncul tahap linter. Kami menggunakan luacheck ( github ), yang juga merupakan salah satu plugin Tarantool.
tarantoolctl rocks install luacheck 0.26.0-1
Hasil Linter juga dikirim ke SonarQube:
.rocks/bin/luacheck --config .luacheckrc --formatter sonar *.lua
Statistik cakupan kode dan linter dihitung bersama. Untuk melewati Gerbang Kualitas, semua persyaratan harus dipenuhi:
- cakupan kode dengan tes harus minimal 80%;
- perubahan seharusnya tidak menimbulkan bau baru;
- jumlah masalah kritis adalah 0;
- jumlah total saham tidak kritis kurang dari 5.
Setelah melewati Gerbang Kualitas, Anda perlu memanggang artefak. Karena kami memutuskan bahwa semua aplikasi akan menggunakan Kartrid Tarantool, kami menggunakan kartrid-cli ( github ) untuk membangun . Ini adalah utilitas kecil untuk menjalankan (pada kenyataannya, mengembangkan) aplikasi Tarantool berkerumun secara lokal. Dia juga tahu cara membuat gambar dan arsip Docker dengan kode aplikasi, baik secara lokal maupun di Docker (misalnya, jika Anda perlu membangun artefak untuk arsitektur yang berbeda). Perakitan
tar.gz
dilakukan dengan perintah:
cartridge pack tgz --name <nme> --version <vrsion>
Arsip yang dihasilkan kemudian diunggah ke repositori apa pun, misalnya, ke Artifactory atau Mail.ru Cloud Storage .
Terapkan tanpa waktu henti
Dan langkah terakhir dari pipeline adalah penerapannya sendiri. Bergantung pada status pengeditan, pengguliran dilakukan ke zona uji yang berbeda. Satu zona dialokasikan untuk bersin apa pun: setiap push ke repositori meluncurkan seluruh pipeline. Ada juga beberapa area fungsional tempat Anda dapat menguji interaksi dengan sistem eksternal, untuk ini Anda perlu membuat permintaan penggabungan di cabang master repositori. Namun dalam produksi, penggulungan diluncurkan hanya setelah perubahan diterima dan tombol gabung ditekan.
Izinkan saya mengingatkan Anda tentang elemen kunci penerapan tanpa waktu henti kami:
- pembaruan untuk pusat data;
- mengganti master dalam set replika;
- menyiapkan penyeimbang untuk pusat data aktif.
Saat meningkatkan, Anda perlu memantau kompatibilitas versi dan skema data. Pembaruan akan berhenti jika terjadi kesalahan di salah satu langkah.
Pembaruan dapat direpresentasikan secara skematis sebagai berikut:
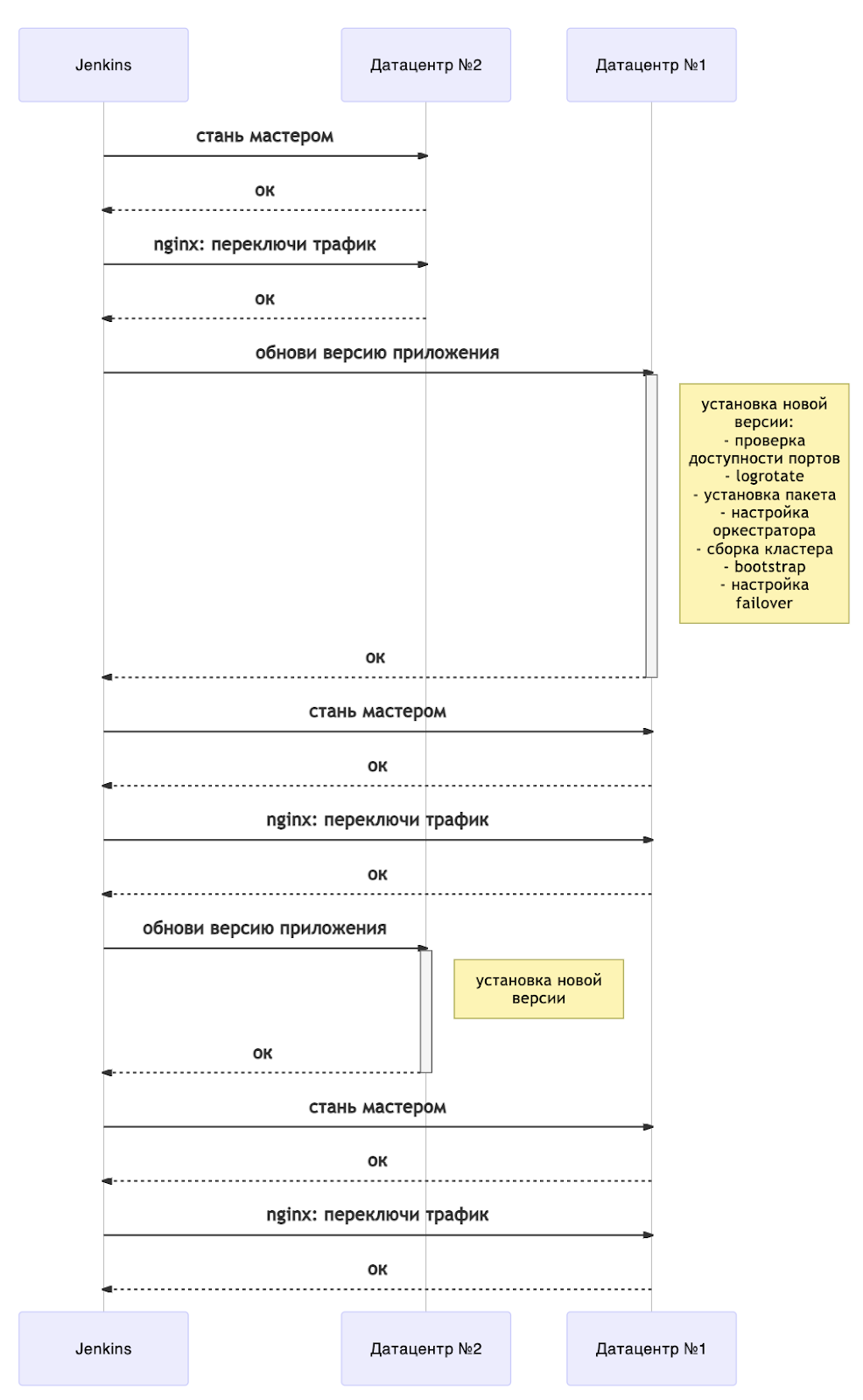
Sekarang pembaruan apa pun disertai dengan restart server. Untuk memahami kapan Anda dapat terus menerapkan, kami memiliki pedoman terpisah untuk menunggu status instance. Kartrid Tarantool memiliki mesin status, dan kami menunggu status RolesConfigured , yang berarti instans telah dikonfigurasi sepenuhnya (dan bagi kami, ia siap untuk menerima permintaan). Jika aplikasi di-deploy untuk pertama kali, Anda harus menunggu hingga status Unconfigured .
Secara keseluruhan, diagram menunjukkan gambaran umum penerapan tanpa waktu henti. Ini mudah diskalakan ke lebih banyak pusat data. Bergantung pada kebutuhan Anda, Anda dapat memperbarui semua "lengan" cadangan segera setelah mengubah master (yaitu, bersama dengan pusat data # 1) atau satu per satu.
Tentu saja, kami tidak bisa tidak membawa perkembangan kami ke open source. Sejauh ini, mereka tersedia di garpu ansible-cartridge saya ( opomuc / ansible-cartridge ), tetapi ada rencana untuk memindahkan ini ke cabang master dari repositori utama.
Contoh dapat ditemukan di sini ( contoh ). Agar berfungsi dengan benar, server harus dikonfigurasi
supervisord
untuk pengguna
tarantool
. Perintah konfigurasi dapat ditemukan di sini . Arsip dengan aplikasi juga harus berisi binar
tarantool
.
Urutan perintah untuk memulai penyebaran bahu:
# ( )
ansible-playbook -i hosts.yml playbook.yml \
-b --become-user tarantool \
--extra-vars 'base_dir=/data/tarantool' \
--extra-vars 'cartridge_package_path=./getting-started-app-1.0.0-0.tar.gz' \
--extra-vars 'app_version=1.0.0' \
--tags supervisor
# 1.2.0
# dc2
ansible-playbook -i hosts.yml master.yml \
-b --become-user tarantool \
--extra-vars 'base_dir=/data/tarantool' \
--extra-vars 'cartridge_package_path=./getting-started-app-1.2.0-0.tar.gz' \
--limit dc2
# — dc1
ansible-playbook -i hosts.yml playbook.yml \
-b --become-user tarantool \
--extra-vars 'base_dir=/data/tarantool' \
--extra-vars 'cartridge_package_path=./getting-started-app-1.2.0-0.tar.gz' \
--extra-vars 'app_version=1.2.0' \
--tags supervisor \
--limit dc1
# dc1
ansible-playbook -i hosts.yml master.yml \
-b --become-user tarantool \
--extra-vars 'base_dir=/data/tarantool' \
--extra-vars 'cartridge_package_path=./getting-started-app-1.2.0-0.tar.gz' \
--limit dc1
# — dc2
ansible-playbook -i hosts.yml playbook.yml \
-b --become-user tarantool \
--extra-vars 'base_dir=/data/tarantool' \
--extra-vars 'cartridge_package_path=./getting-started-app-1.2.0-0.tar.gz' \
--extra-vars 'app_version=1.2.0' \
--tags supervisor \
--limit dc2
# , dc1
ansible-playbook -i hosts.yml master.yml \
-b --become-user tarantool \
--extra-vars 'base_dir=/data/tarantool' \
--extra-vars 'cartridge_package_path=./getting-started-app-1.2.0-0.tar.gz' \
--limit dc1
Parameter
base_dir
menunjukkan jalur ke direktori "home" dari proyek tersebut. Setelah diluncurkan, subdirektori akan dibuat:
<base_dir>/run
- untuk soket kontrol dan file pid;<base_dir>/data
- untuk file .snap dan .xlog, serta konfigurasi Kartrid Tarantool;<base_dir>/conf
- untuk pengaturan aplikasi dan contoh tertentu;<base_dir>/releases
- untuk pembuatan versi dan kode sumber;<base_dir>/instances
- untuk tautan ke versi saat ini untuk setiap contoh aplikasi.
Parameter
cartridge_package_path
berbicara sendiri, tetapi ada kekhasan:
- jika jalur dimulai dengan
http://
atauhttps://
, maka artefak akan dimuat sebelumnya dari jaringan (misalnya, dari artifaktori yang muncul di sebelahnya). - dalam kasus lain, file tersebut dicari secara lokal
Parameter
app_version
akan digunakan untuk membuat versi di folder
<base_dir>/releases
. Standarnya adalah
latest
.
Tag
supervisor
berarti akan digunakan sebagai orkestrator
supervisord
.
Ada banyak opsi untuk memulai penerapan, tetapi yang paling andal adalah yang lama
Makefile
. Perintah bersyarat
make deploy
dapat dimasukkan ke dalam CI \ CD mana pun dan semuanya akan bekerja sama persis.
Hasil
Itu saja! Kami sekarang memiliki saluran pipa yang sudah jadi di Jenkins, kami menyingkirkan perantara, dan kecepatan pengiriman perubahan menjadi gila. Jumlah pengguna terus bertambah, dalam lingkungan produksi sudah ada 500 instans yang diterapkan secara eksklusif menggunakan solusi kami. Kami memiliki ruang untuk berkembang.
Dan meskipun proses penerapan itu sendiri jauh dari ideal, ini memberikan dasar yang kokoh untuk pengembangan proses DevOps lebih lanjut. Anda dapat menggunakan penerapan kami dengan aman untuk mengirimkan sistem ke produksi dengan cepat dan tidak takut untuk sering melakukan pengeditan.
Dan itu juga akan menjadi pelajaran bagi kita bahwa tidak mungkin membawa monolit dan harapan untuk digunakan secara luas: kita memerlukan dekomposisi buku pedoman, alokasi peran untuk setiap tahap instalasi, cara yang fleksibel dalam menyajikan inventaris. Suatu saat nanti perkembangan kita akan masuk dalam master, dan semuanya akan menjadi lebih baik!
Tautan
- Panduan langkah demi langkah untuk kartrid yang mungkin:
- Anda dapat membaca tentang Tarantool Cartridge di sini .
- Tentang penerapan ke Kubernetes:
- Pemantauan Tarantool: log, metrik, dan pemrosesannya .
- Untuk bantuan, hubungi obrolan Telegram .