
Sudah ada cukup banyak publikasi tentang koprosesor Matriks Apple (AMX). Tetapi sebagian besar tidak begitu jelas bagi semua orang. Saya akan mencoba menjelaskan nuansa koprosesor dalam bahasa yang dapat dimengerti.
Mengapa Apple tidak terlalu banyak membicarakan koprosesor ini? Apa rahasianya? Dan jika Anda telah membaca tentang Neural Engine di SoC M1, Anda mungkin kesulitan memahami apa yang tidak biasa tentang AMX.
Tapi pertama-tama, mari kita ingat hal-hal dasar ( jika Anda tahu betul apa itu matriks, dan saya yakin ada sebagian besar pembaca di Habré, maka Anda dapat melewati bagian pertama, - kira-kira. Terjemahan ).
Apa itu matriks?
Sederhananya, ini adalah tabel dengan angka. Jika Anda pernah bekerja di Microsoft Excel, maka itu berarti Anda telah berurusan dengan kemiripan matriks. Perbedaan utama antara matriks dan tabel biasa dengan angka terletak pada operasi yang dapat dilakukan dengannya, serta dalam esensi spesifiknya. Matriks dapat dipikirkan dalam berbagai bentuk. Misalnya sebagai string, maka itu adalah vektor baris. Atau sebagai kolom, maka secara logis, itu adalah vektor kolom.

Kita dapat menambah, mengurangi, menskalakan dan mengalikan matriks. Penambahan adalah operasi yang paling sederhana. Anda hanya menambahkan setiap item secara terpisah. Perkaliannya sedikit lebih rumit. Berikut contoh sederhananya.
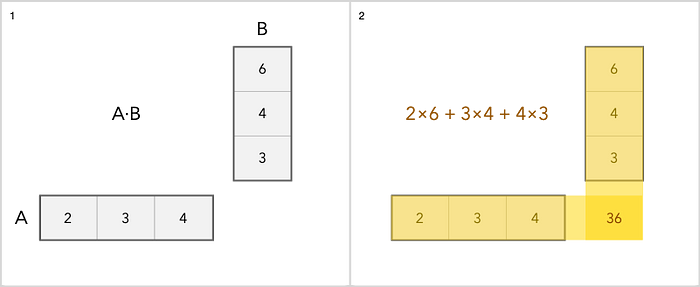
Sedangkan untuk operasi lain dengan matriks, Anda dapat membacanya di sini .
Mengapa kita bahkan berbicara tentang matriks?
Faktanya adalah bahwa mereka banyak digunakan dalam:
• Pemrosesan gambar.
• Pembelajaran mesin.
• Tulisan tangan dan pengenalan ucapan.
• Kompresi.
• Bekerja dengan audio dan video.
Dalam hal pembelajaran mesin, teknologi ini membutuhkan prosesor yang kuat. Dan hanya menambahkan beberapa inti ke dalam chip bukanlah suatu pilihan. Sekarang kernel "diasah" untuk tugas-tugas tertentu.

Jumlah transistor pada processor dibatasi, sehingga jumlah tugas / modul yang dapat ditambahkan ke dalam chip juga dibatasi. Secara umum, Anda bisa menambahkan lebih banyak core ke prosesor, tetapi itu hanya akan mempercepat komputasi standar yang sudah cepat. Jadi Apple memutuskan untuk mengambil rute yang berbeda dan menyorot modul untuk pemrosesan gambar, dekode video, dan tugas pembelajaran mesin. Modul ini adalah koprosesor dan akselerator.
Apa perbedaan antara koprosesor Matriks Apple dan Neural Engine?
Jika Anda tertarik dengan Neural Engine, Anda mungkin tahu bahwa Neural Engine juga menjalankan operasi matriks untuk menangani masalah pembelajaran mesin. Tetapi jika demikian, lalu mengapa Anda juga membutuhkan koprosesor Matrix? Mungkinkah itu hal yang sama? Apakah saya membingungkan? Izinkan saya mengklarifikasi situasinya dan memberi tahu Anda apa perbedaannya, menjelaskan mengapa kedua teknologi itu dibutuhkan.
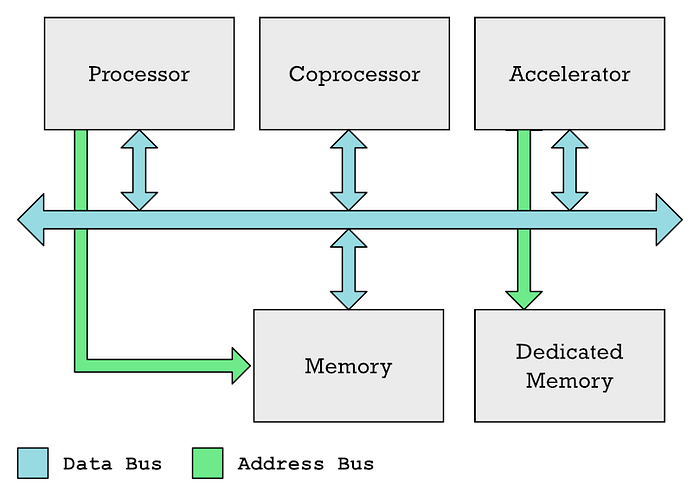
Unit pemrosesan utama (CPU), koprosesor, dan akselerator biasanya dapat berkomunikasi melalui bus data umum. CPU biasanya mengontrol akses ke memori, sementara akselerator seperti GPU sering kali memiliki memori khusus.
Saya akui bahwa dalam artikel saya sebelumnya, saya telah menggunakan istilah "coprocessor" dan "akselerator" secara bergantian, meskipun keduanya bukan hal yang sama. Jadi, GPU dan Neural Engine adalah jenis akselerator yang berbeda.
Dalam kedua kasus, Anda memiliki area memori khusus yang harus diisi CPU dengan data yang ingin diproses, ditambah area memori lain yang diisi CPU dengan daftar instruksi yang harus dijalankan oleh akselerator. Prosesor membutuhkan waktu untuk menyelesaikan tugas ini. Anda harus mengoordinasikan semua ini, mengisi datanya, lalu menunggu hasilnya diterima.
Dan mekanisme seperti itu cocok untuk tugas skala besar, tetapi untuk tugas kecil ini berlebihan.

Ini adalah keunggulan koprosesor dibandingkan akselerator. Koprosesor duduk dan mengamati aliran instruksi kode mesin yang datang dari memori (atau khususnya cache) ke CPU. Coprocessor dipaksa untuk menanggapi instruksi spesifik yang dipaksa untuk diproses. Sementara itu, sebagian besar CPU mengabaikan petunjuk ini atau membantu membuatnya lebih mudah ditangani oleh koprosesor.
Keuntungannya adalah bahwa instruksi yang dijalankan oleh koprosesor dapat dimasukkan dalam kode biasa. Dalam kasus GPU, semuanya berbeda - program shader ditempatkan di buffer memori terpisah, yang kemudian harus ditransfer secara eksplisit ke GPU. Anda tidak akan dapat menggunakan kode biasa untuk ini. Dan itulah mengapa AMX sangat bagus untuk tugas pemrosesan matriks sederhana.
Triknya di sini adalah Anda perlu menentukan instruksi dalam arsitektur set instruksi (ISA) mikroprosesor Anda. Jadi, saat menggunakan koprosesor, ada integrasi yang lebih erat dengan prosesor daripada saat menggunakan akselerator.
Ngomong-ngomong, pembuat ARM telah lama menolak menambahkan instruksi khusus ke ISA. Dan inilah salah satu keunggulan RISC-V. Namun pada tahun 2019, pengembang menyerah, dengan menyatakan hal berikut: “Instruksi baru digabungkan dengan instruksi ARM standar. Untuk menghindari fragmentasi software dan memelihara lingkungan pengembangan software yang konsisten, ARM mengharapkan klien untuk menggunakan instruksi khusus terutama dalam panggilan perpustakaan. "
Ini mungkin penjelasan yang bagus untuk kurangnya deskripsi instruksi AMX di dokumentasi resmi. ARM hanya mengharapkan Apple untuk memasukkan instruksi di perpustakaan yang disediakan oleh pelanggan (dalam hal ini Apple).
Apa perbedaan antara matriks koprosesor dan SIMD vektor?
Secara umum, tidaklah terlalu sulit untuk mengacaukan koprosesor matriks dengan teknologi SIMD vektor, yang ditemukan di sebagian besar prosesor modern, termasuk ARM. SIMD adalah singkatan dari Single Instruction Multiple Data.

SIMD memungkinkan Anda untuk meningkatkan kinerja sistem saat Anda perlu melakukan operasi yang sama pada beberapa elemen, yang berkaitan erat dengan matriks. Secara umum, instruksi SIMD, termasuk instruksi ARM Neon atau Intel x86 SSE atau AVX, sering digunakan untuk mempercepat perkalian matriks.
Tetapi mesin vektor SIMD adalah bagian dari inti mikroprosesor, sama seperti ALU (Arithmetic Logic Unit) dan FPU (Floating Point Unit) adalah bagian dari CPU. Nah, dekoder instruksi di mikroprosesor sudah "memutuskan" blok fungsional mana yang akan diaktifkan.

Tetapi koprosesor adalah modul fisik yang terpisah, dan bukan bagian dari inti mikroprosesor. Sebelumnya, misalnya, Intel 8087 adalah chip terpisah yang dimaksudkan untuk mempercepat operasi floating point.

Anda mungkin merasa aneh bahwa seseorang akan mengembangkan sistem yang sedemikian kompleks, dengan chip terpisah yang memproses data dari memori ke prosesor untuk mendeteksi instruksi floating point.
Tapi peti itu terbuka dengan sederhana. Faktanya adalah prosesor 8086 asli hanya memiliki 29.000 transistor. 8087 sudah memiliki 45.000 di antaranya. Akhirnya, teknologi memungkinkan integrasi FPU ke dalam chip utama, menyingkirkan koprosesor.
Tetapi mengapa AMX bukan bagian dari inti M1 Firestorm masih belum jelas. Mungkin Apple baru saja memutuskan untuk memindahkan elemen ARM non-standar di luar prosesor utama.
Tapi kenapa AMX tidak banyak dibicarakan?
Jika AMX tidak dijelaskan dalam dokumentasi resmi, bagaimana kita bisa mengetahuinya? Terima kasih kepada pengembang Dougall Johnson, yang melakukan rekayasa balik yang luar biasa pada M1 dan menemukan koprosesornya. Karyanya dijelaskan di sini . Ternyata, Apple membuat pustaka dan / atau kerangka kerja khusus seperti Accelerate untuk operasi matematika yang terkait dengan matriks . Semua ini mencakup elemen berikut:
• vImage - pemrosesan gambar tingkat yang lebih tinggi, seperti mengonversi antar format, memanipulasi gambar.
• BLASAdalah sejenis standar industri untuk aljabar linier (yang kita sebut matematika yang berhubungan dengan matriks dan vektor).
• BNNS - digunakan untuk menjalankan jaringan saraf dan melatih.
• vDSP - pemrosesan sinyal digital. Transformasi Fourier, konvolusi. Ini adalah operasi matematika yang dilakukan saat memproses gambar atau sinyal apa pun yang mengandung suara.
• LAPACK - Fungsi aljabar linier tingkat tinggi , seperti memecahkan persamaan linier.
Johnson memahami bahwa pustaka ini akan menggunakan koprosesor AMX untuk mempercepat komputasi. Oleh karena itu, ia mengembangkan perangkat lunak khusus untuk menganalisis dan memantau tindakan perpustakaan. Akhirnya, dia dapat menemukan instruksi kode mesin AMX yang tidak terdokumentasi.
Dan Apple tidak mendokumentasikan semua ini karena ARM LTD. mencoba untuk tidak mengiklankan terlalu banyak informasi. Faktanya adalah jika fungsi kustom benar-benar digunakan secara luas, ini dapat menyebabkan fragmentasi ekosistem ARM, seperti yang dibahas di atas.
Apple memiliki kesempatan, tanpa benar-benar mengiklankan semua ini, nanti untuk mengubah pengoperasian sistem jika perlu - misalnya, menghapus atau menambahkan instruksi AMX. Untuk pengembang, platform Akselerasi sudah cukup, sistem akan melakukan sisanya sendiri. Dengan demikian, Apple dapat mengontrol perangkat keras dan perangkat lunak untuk itu.
Manfaat koprosesor Matriks Apple
Ada banyak hal di sini, gambaran umum yang luar biasa tentang kemampuan elemen dibuat oleh Nod Labs, yang berspesialisasi dalam pembelajaran mesin, kecerdasan, dan persepsi. Secara khusus, mereka melakukan tes kinerja komparatif antara AMX2 dan NEON.
Ternyata, AMX melakukan operasi yang diperlukan untuk menjalankan operasi dengan matriks dua kali lebih cepat. Ini tidak berarti, tentu saja, bahwa AMX adalah yang terbaik, tetapi untuk pembelajaran mesin dan komputasi kinerja tinggi - ya.
Intinya adalah bahwa koprosesor Apple adalah teknologi mengesankan yang memberikan keunggulan Apple ARM dalam pembelajaran mesin dan komputasi kinerja tinggi.
