
Dengan 12 masalah di belakang kita, sekarang saatnya untuk sedikit mengubah nama dan desain, tetapi di dalam Anda masih menunggu penelitian, demo, model terbuka, dan kumpulan data. Sambutlah angsuran baru dari Machine Learning Toolkit.
DALL E
Aksesibilitas: halaman proyek / akses ke API tertutup melalui daftar tunggu
OpenAI mempresentasikan model bahasa transformator DALL-E baru mereka dengan 12 miliar parameter, dilatih pada pasangan gambar-teks. Model ini didasarkan pada GPT-3 dan digunakan untuk mensintesis gambar dari deskripsi tekstual.
Juni lalu, perusahaan menunjukkan bagaimana model yang dilatih pada urutan piksel dengan deskripsi yang akurat dapat mengisi kekosongan pada gambar yang dimasukkan ke input. Hasilnya sudah mengesankan saat itu, tetapi di sini Open AI melebihi semua harapan. Sama seperti GPT-3 yang mensintesis kalimat lengkap yang koheren, DALL · E membuat gambar yang kompleks.

Model-model tersebut secara mengejutkan ahli dalam objek antropomorfik (lobak berjalan dengan anjing) dan kombinasi objek yang tidak kompatibel (siput dalam bentuk harpa), itulah sebabnya mereka memilih penggabungan dua nama untuk nama tersebut - surealis Spanyol Salvador Dali dan robot Pixar WALL-I.
Jadi, hasil apa yang dibanggakan model itu?
Model tersebut mampu memvisualisasikan kedalaman ruang, sehingga dimungkinkan untuk memanipulasi pemandangan tiga dimensi. Cukup, ketika mendeskripsikan gambar yang diinginkan, untuk menunjukkan dari sudut mana objek harus dilihat dan di bawah pencahayaan apa. Di masa mendatang, ini akan memungkinkan pembuatan representasi 3D yang sebenarnya.
Selain itu, model ini mampu menerapkan efek optik ke pemandangan, misalnya, saat memotret dengan lensa fisheye. Tapi sejauh ini dia tidak mengatasi refleksi dengan baik - kubus di cermin belum disintesis secara meyakinkan. Jadi, dengan berbagai tingkat keandalan, DALL · E melalui bahasa alami mengatasi tugas-tugas yang menggunakan mesin pemodelan 3D di industri. Ini memungkinkannya digunakan untuk membuat tampilan desain ruangan.
Model ini sangat memahami geografi dan landmark ikonik, serta ciri khas masing-masing era. Dia dapat membuat foto dari sebuah telepon tua atau Jembatan Golden Gate di San Francisco.
Dengan semua ini, model tidak memerlukan deskripsi yang sangat akurat - model akan mengisi beberapa celah itu sendiri. Seperti yang dicatat oleh Open AI, semakin akurat deskripsinya, semakin buruk hasilnya.
Ingatlah bahwa GPT-3 adalah model zero-shot, tidak perlu dikonfigurasi dan dilatih tambahan untuk melakukan tugas tertentu. Selain deskripsi, Anda bisa memberi petunjuk agar model menghasilkan jawaban yang diinginkan. DALL · E melakukan hal yang sama dengan rendering dan dapat melakukan berbagai tugas konversi gambar-ke-gambar berdasarkan petunjuknya. Misalnya, Anda dapat memberikan gambar sebagai masukan dan meminta untuk membuatnya dalam bentuk sketsa.
Anehnya, pencipta tidak menetapkan tujuan seperti itu dan tidak menyediakannya dengan cara apa pun saat melatih model. Kemampuan itu terungkap hanya selama pengujian.
Dipandu oleh penemuan ini, penulis mempelajari kemampuan DALL · E untuk memecahkan masalah logis dari tes IQ visual dan menetapkan tugas untuk tidak memilih jawaban yang benar dari opsi yang disajikan, tetapi untuk sepenuhnya memprediksi elemen yang hilang.
Secara umum, model berhasil melanjutkan urutan dengan benar di bagian tugas yang memerlukan pemahaman geometris.
Model tersebut belum dipublikasikan, dan bahkan belum ada gambaran kasar tentang arsitekturnya. Pada tahap ini, Anda dapat meminta akses ke API atau memeriksa implementasi tidak resmi di PyTorch ( versi tidak resmi di TensorFlow juga sedang dikerjakan ).
CLIP (Bahasa Kontrasif - Pra-pelatihan Gambar)
Aksesibilitas: Pembelajaran Mendalam Kode Halaman / Sumber Proyek
telah merevolusi visi komputer, tetapi pendekatan saat ini masih memiliki dua masalah signifikan yang mempertanyakan penggunaan DNN di bidang ini.
Pertama, membuat kumpulan data tetap sangat mahal, tetapi pada saat yang sama, sebagai hasilnya, ini memungkinkan pengenalan kumpulan gambar visual yang sangat terbatas dan cocok untuk tugas-tugas yang sempit. Misalnya, saat menyiapkan kumpulan data ImageNet, dibutuhkan 25.000 orang untuk membuat deskripsi dari 14 juta gambar untuk 22.000 kategori objek. Pada saat yang sama, model ImageNet baik untuk memprediksi hanya kategori yang diwakili dalam kumpulan data, dan jika ada tugas lain yang diperlukan, spesialis harus membuat kumpulan data baru dan menyelesaikan pelatihan model.
Kedua, model yang berkinerja baik dalam tolok ukur gagal dalam lingkungan alaminya. Model yang digunakan di dunia nyata tidak berfungsi sebaik di lingkungan laboratorium. Dengan kata lain, model tersebut dioptimalkan untuk lulus tes tertentu saat siswa menjejalkan soal ujian sebelumnya.
CLIP jaringan neural terbuka OpenAI bertujuan untuk memecahkan masalah ini. Model ini dilatih tentang sejumlah besar gambar dan deskripsi teks yang tersedia di Internet dan menerjemahkannya ke dalam representasi vektor, embeddings. Representasi ini dibandingkan sehingga jumlah prasasti dan gambar yang sesuai akan mendekati.
CLIP dapat langsung diuji pada tolok ukur yang berbeda tanpa melatih datanya. Model tersebut melakukan pengujian klasifikasi tanpa pengoptimalan langsung. Misalnya, tes ObjectNet menguji kemampuan model untuk mengenali objek di lokasi yang berbeda dan dengan latar belakang yang berubah, sementara ImageNet Rendition dan ImageNet Sketch menguji kemampuan model untuk mengenali gambar objek yang lebih abstrak (bukan hanya pisang, tapi pisang yang diiris. atau sketsa pisang). CLIP bekerja sama baiknya pada semuanya.
CLIP dapat diadaptasi untuk melakukan berbagai tugas klasifikasi visual tanpa contoh pelatihan tambahan. Untuk menerapkan CLIP ke masalah baru, Anda hanya perlu memberi encoder nama-nama representasi visual, dan itu akan menghasilkan pengklasifikasi linier dari representasi ini, yang tidak kalah akurasinya dengan model yang dilatih dengan guru.
Github sudah memiliki implementasi untuk foto dengan Unsplash, yang menunjukkan seberapa baik model mengelompokkan gambar. Desainer sudah bisa menggunakannya untuk mendesain papan mood.
DeBERTa oleh Microsoft
Ketersediaan: Sumber / Halaman Proyek
Seperti biasa, berita dari OpenAI membayangi pengumuman lainnya, meskipun ada acara lain yang aktif dibahas di masyarakat. Model DeBERTa Microsoft mengungguli standar manusia pada tes SuperGLUE Natural Language Comprehension (NLU).
Tolok ukur yang didasarkan pada 10 parameter menentukan apakah algoritme "memahami" apa yang telah dibaca dan membuat peringkat. Skor rata-rata untuk non-ahli adalah 89,8 poin, dan masalah yang perlu diselesaikan oleh model sebanding dengan ujian bahasa Inggris. DeBERTa menunjukkan 90,3, diikuti oleh Google T5 + Meena.
Dengan demikian, model tersebut berhasil menyalip manusia untuk kedua kalinya, tetapi perlu dicatat bahwa DeBERTa memiliki 1,5 miliar parameter pelatihan, 8 kali lebih kecil dari T5.
Model ini merepresentasikan mekanisme perhatian terbagi yang baru, berbeda dari transformator asli, di mana setiap token dikodekan oleh vektor konten dan posisi yang tidak dijumlahkan menjadi satu vektor, matriks terpisah bekerja dengannya.
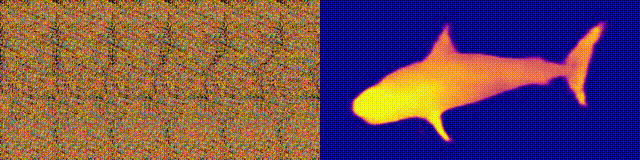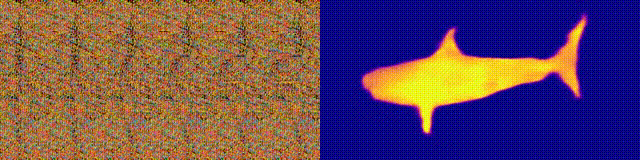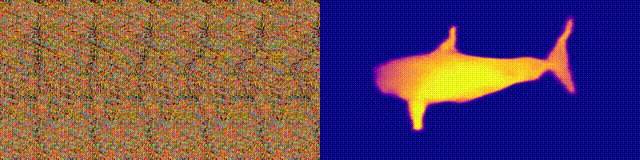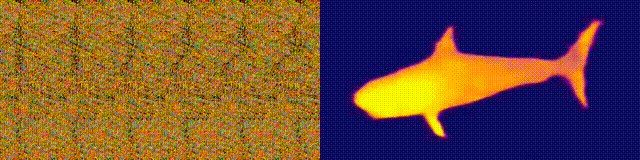
NeuralMagicEye
Aksesibilitas: halaman proyek / kode / kolom
Ingat album Magic Eye dengan stereogram? Berikut ini adalah sesuatu yang serupa, hanya untuk autostereograms, di mana kedua bagian stereopair berada pada gambar yang sama dan dikodekan dalam struktur raster, sehingga dapat menciptakan ilusi visual tiga dimensi.
Penulis penelitian melatih model CNN untuk merekonstruksi kedalaman autostereogram dan memahami isinya. Untuk mencapai efek stereo, model harus dilatih untuk mendeteksi dan mengevaluasi ketidakcocokan tekstur kuasi-periodik. Model dilatih pada kumpulan data dari model 3D, tanpa pengajar.
Metode ini memungkinkan Anda memulihkan kedalaman autostereogram secara akurat. Para peneliti berharap ini akan membantu orang-orang tunanetra, dan stereogram dapat digunakan sebagai tanda air pada gambar.
StyleFlow

Aksesibilitas: Kode Sumber
Seperti yang telah kita lihat lebih dari sekali, GAN tanpa syarat (seperti StyleGAN) dapat membuat gambar fotorealistik berkualitas tinggi. Namun, sangat jarang mungkin untuk mengelola proses pembangkitan menggunakan atribut semantik dengan tetap menjaga kualitas keluaran. Karena latensi GAN yang kompleks dan membingungkan, mengedit satu atribut sering kali mengakibatkan perubahan yang tidak diinginkan pada atribut lainnya. Model ini membantu memecahkan masalah ini. Misalnya, Anda dapat mengubah sudut pandang, variasi pencahayaan, ekspresi, rambut wajah, jenis kelamin, dan usia.
Menjinakkan Transformers
Aksesibilitas: halaman proyek / kode sumber
Transformers mampu memberikan hasil yang sangat baik dalam berbagai aplikasi. Namun dalam hal daya komputasi, mereka sangat menuntut, sehingga tidak cocok untuk bekerja dengan gambar resolusi tinggi. Penulis studi menggabungkan transformator dengan jaringan konvolusional yang dipindahkan secara induktif dan mampu mengambil gambar dengan resolusi tinggi.
POse EMbedding

Aksesibilitas: Source Code
Kegiatan sehari-hari, baik berlari maupun membaca buku, dapat dianggap sebagai urutan postur tubuh, terdiri dari posisi dan orientasi tubuh seseorang di dalam ruang. Pengenalan pose membuka sejumlah kemungkinan dalam AR, kontrol gerakan, dll. Namun, data yang diperoleh dari gambar 2D berbeda-beda, bergantung pada sudut pandang kamera. Algoritme dari Google AI ini mengenali kemiripan pose dari berbagai sudut, mencocokkan poin-poin utama tampilan 2D dari pose dengan penyematan view-invariant.
Belajar untuk Belajar
Aksesibilitas: Kode Sumber
Untuk mempelajari cara mengambil atau meletakkan botol di atas meja, kita hanya perlu melihat orang lain melakukannya. Untuk mempelajari cara mengoperasikan objek seperti itu, mesin memerlukan reward yang diprogram secara manual agar berhasil menyelesaikan blok bangunan suatu tugas. Sebelum robot dapat belajar meletakkan botol di atas meja, ia perlu diberi penghargaan untuk belajar memindahkan botol secara vertikal. Hanya setelah serangkaian pengulangan seperti itu, dia akan belajar menempatkan botol. Facebook memperkenalkan metode yang melatih mesin dalam beberapa sesi observasi manusia.
Ini adalah betapa cerahnya bulan pertama tahun ini. Terima kasih telah membaca, dan nantikan rilis mendatang!