
Foto oleh Richard Jacobs di Unsplash
Pada November 2020, kami memulai migrasi besar-besaran untuk memutakhirkan klaster PostgreSQL kami dari 9.6 menjadi 12.4. Dalam posting ini, saya akan memberi Anda gambaran umum singkat tentang arsitektur kami di Coffee Meets Bagel, menjelaskan bagaimana waktu henti pemutakhiran dikurangi menjadi di bawah 30 menit, dan membagikan apa yang kami pelajari selama proses tersebut.
Arsitektur
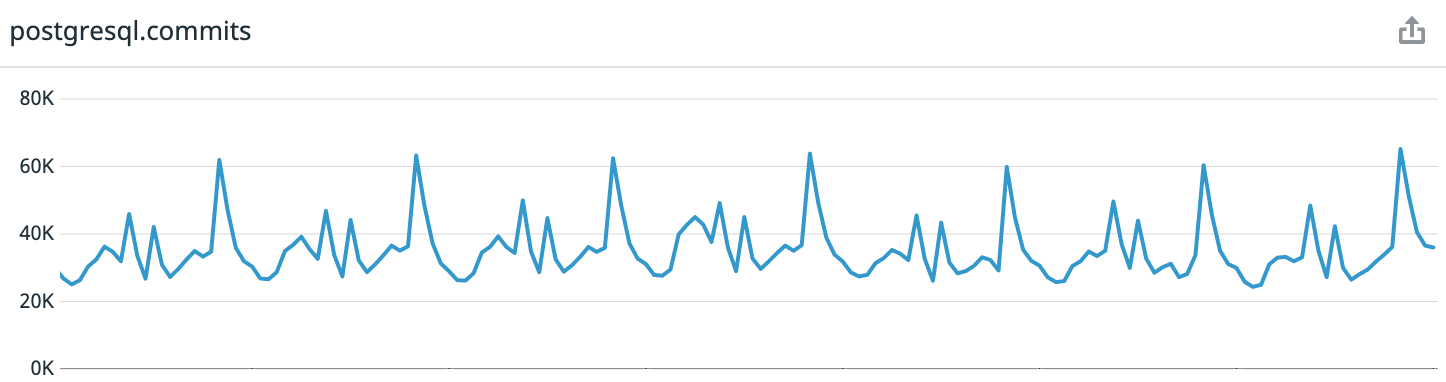
Sebagai referensi: Coffee Meets Bagel adalah aplikasi kencan romantis dengan sistem kurasi. Setiap hari, pengguna kami menerima sejumlah terbatas kandidat berkualitas tinggi pada siang hari dalam zona waktu mereka. Ini mengarah pada pola beban yang sangat dapat diprediksi. Jika Anda melihat data selama seminggu terakhir dari saat menulis artikel, kami mendapatkan rata-rata 30 ribu transaksi per detik, di puncak - hingga 65 ribu.
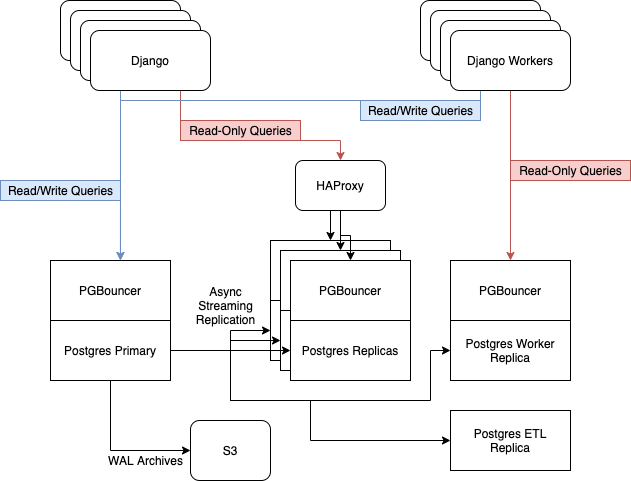
Sebelum pembaruan, kami memiliki 6 server Postgres yang berjalan pada instans i3.8xlarge di AWS. Mereka berisi satu node master, tiga replika untuk melayani lalu lintas web hanya-baca, diimbangi dengan HAProxy, satu server untuk pekerja asinkron, dan satu server untuk ETL [ Ekstrak, Transformasi, Muat ] dan Business Intelligence....
Kami mengandalkan replikasi streaming bawaan Postgres untuk menjaga armada replika kami tetap mutakhir.
Alasan peningkatan
Selama beberapa tahun terakhir kami telah mengabaikan lapisan data kami, dan akibatnya, lapisan tersebut agak ketinggalan zaman. Terutama banyak "kruk" yang diambil oleh server utama kami - telah online selama 3,5 tahun. Kami menambal berbagai pustaka dan layanan sistem tanpa menghentikan server.

Kandidat saya untuk subreddit r / uptimeporn
Sebagai hasilnya, banyak keanehan telah terakumulasi yang membuat Anda gugup. Misalnya, layanan baru
systemd
tidak dimulai. Saya harus mengkonfigurasi peluncuran agen
datadog
dalam sesi tersebut
screen
. Terkadang SSH berhenti merespons ketika beban prosesor di atas 50%, dan server itu sendiri secara teratur mengirim permintaan database.
Dan juga ruang kosong pada disk mulai mendekati nilai berbahaya. Seperti yang saya sebutkan di atas, Postgres berjalan pada instans i3.8xlarge di EC2 yang memiliki penyimpanan NVMe 7,6TB. Tidak seperti EBS, ukuran disk tidak dapat diubah secara dinamis di sini - apa yang awalnya akan ditetapkan. Dan kami mengisi sekitar 75% dari disk. Jelas bahwa ukuran instans perlu diubah untuk mendukung pertumbuhan di masa mendatang.
Persyaratan kami
- Waktu henti minimum. Kami telah menetapkan target total waktu henti selama 4 jam, termasuk pemadaman yang tidak direncanakan yang disebabkan oleh kesalahan peningkatan.
- Bangun cluster database baru pada instance baru untuk menggantikan armada server yang sudah tua.
- Buka i3.16xlarge untuk ruang tumbuh.
Kami mengetahui tiga cara untuk meningkatkan Postgres: mencadangkan dan memulihkan darinya, pg_upgrade, dan replikasi logis pglogical.
Kami segera meninggalkan metode pertama, memulihkan dari cadangan: untuk dataset 5,7 TB kami, itu akan memakan waktu terlalu lama. Pada kecepatannya, pg_upgrade tidak memenuhi persyaratan 2 dan 3: ini adalah alat migrasi pada mesin yang sama. Oleh karena itu, kami memilih replikasi logis.
Proses kami
Cukup banyak yang telah ditulis tentang fitur-fitur utama pglogical. Oleh karena itu, alih-alih mengulang kebenaran umum, saya hanya akan memberikan artikel yang ternyata bermanfaat bagi saya:
- Peningkatan versi mayor dengan waktu henti minimal ;
- Meningkatkan PostgreSQL dari 9.4 menjadi 10.3 dengan pglogical ;
- Demystifying pglogical - Tutorial .
Kami membuat server Postgres 12 primer baru dan menggunakan pglogical untuk menyinkronkan semua data kami. Ketika itu disinkronkan dan pindah untuk mereplikasi perubahan yang masuk, kami mulai menambahkan replika streaming untuknya. Setelah menyiapkan replika streaming baru, kami memasukkannya ke dalam HAProxy, dan menghapus salah satu versi lama 9.6.
Proses ini berlanjut sampai server Postgres 9.6 benar-benar mati kecuali untuk master. Konfigurasi tersebut mengambil bentuk berikut.

Kemudian giliran cluster switching (failover), yang kami minta jendela pemeliharaan. Proses peralihan juga didokumentasikan dengan baik di Internet, jadi saya hanya akan berbicara tentang langkah-langkah umum:
- Transfer situs ke mode kerja teknis;
- Mengubah data DNS master ke server baru;
- Sinkronisasi paksa dari semua urutan kunci utama;
- Manual mulai dari checkpoint (
CHECKPOINT
) pada master lama. - Di wizard baru - melakukan beberapa validasi data dan prosedur pengujian;
- Mengaktifkan situs.
Secara keseluruhan, transisi berjalan dengan baik. Meskipun terjadi perubahan besar dalam infrastruktur kami, tidak ada waktu henti yang tidak direncanakan.
Pelajaran yang dipelajari
Dengan keberhasilan keseluruhan operasi, beberapa masalah ditemui di sepanjang jalan. Yang terburuk dari mereka hampir membunuh master Postgres 9.6 kami ...
Pelajaran # 1: Sinkronisasi Lambat Bisa Berbahaya
Mari kita mulai dengan konteks: bagaimana pglogical bekerja? Proses pengirim pada penyedia (dalam hal ini wizard lama kami 9.6) mendekode log WAL depan tulis, mengambil perubahan logis dan mengirimkannya ke pelanggan.
Jika pelanggan tertinggal maka provider akan menyimpan segmen WAL sehingga saat pelanggan mengejar, tidak ada data yang hilang.
Pertama kali tabel ditambahkan ke aliran replikasi, pglogical harus menyinkronkan data tabel terlebih dahulu. Ini dilakukan dengan perintah Postgres
COPY
. Setelah itu, segmen WAL mulai terakumulasi di provider sehingga berubah selama operasi
COPY
ternyata akan ditransfer ke pelanggan setelah sinkronisasi awal, memastikan tidak ada kehilangan data.
Dalam praktiknya, ini berarti bahwa saat menyinkronkan tabel besar pada sistem dengan beban tulis / perubahan yang berat, Anda harus memantau penggunaan disk dengan cermat. Pada upaya pertama untuk menyinkronkan tabel terbesar kami (4 TB), tim dan operator
COPY
bekerja selama lebih dari satu hari. Selama waktu ini, node vendor telah mengumpulkan lebih dari satu terabyte log WAL proaktif.
Seperti yang mungkin Anda ingat dari apa yang dikatakan, server database lama kami hanya memiliki dua terabyte ruang disk kosong yang tersisa. Kami memperkirakan dari kepenuhan disk server pelanggan bahwa hanya seperempat tabel yang disalin. Oleh karena itu, proses sinkronisasi harus segera dihentikan - disk pada master akan berakhir lebih awal.
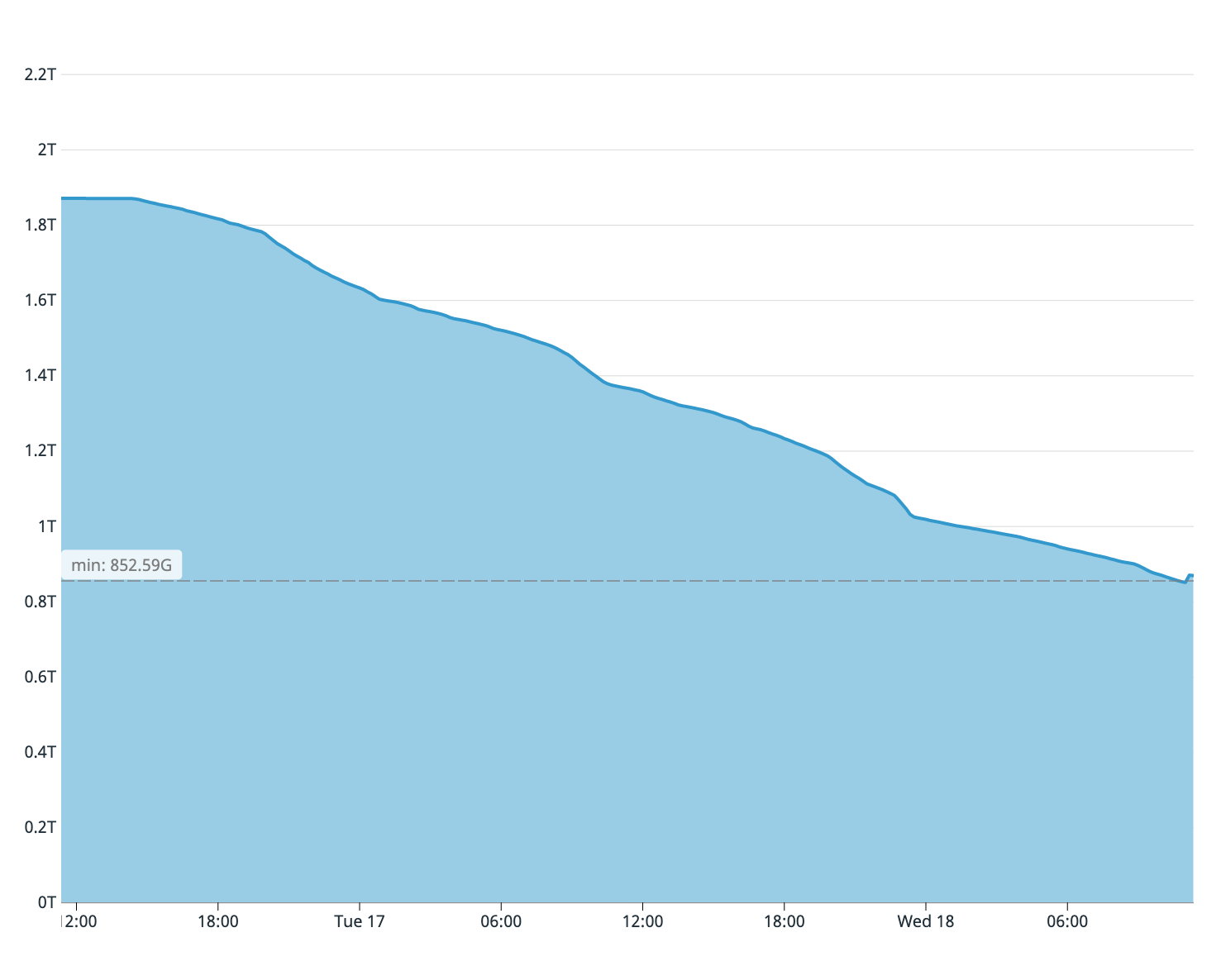
Ruang disk yang tersedia di wizard lama pada upaya sinkronisasi pertama
Untuk mempercepat proses sinkronisasi, kami membuat perubahan berikut ke database pelanggan:
- Menghapus semua indeks pada tabel yang disinkronkan;
fsynch
beralih keoff
;- Berubah
max_wal_size
menjadi50GB
; - Berubah
checkpoint_timeout
menjadi1h
.
Keempat langkah ini secara signifikan mempercepat proses sinkronisasi di Pelanggan, dan upaya kedua kami pada sinkronisasi tabel selesai dalam 8 jam.
Pelajaran # 2: Setiap perubahan baris dicatat sebagai konflik
Saat pglogical mendeteksi konflik, aplikasi meninggalkan entri "
CONFLICT: remote UPDATE on relation PUBLIC.foo. Resolution: apply_remote
" di log .
Namun, ternyata setiap perubahan baris yang diproses oleh Pelanggan dicatat sebagai konflik. Dalam beberapa jam replikasi, database pelanggan meninggalkan file log yang bentrok dalam beberapa gigabyte.
Masalah ini diselesaikan dengan mengatur parameter
pglogical.conflict_log_level = DEBUG
di file
postgresql.conf
.
tentang Penulis
 Tommy Lee adalah Insinyur Perangkat Lunak Senior di Coffee Meets Bagel. Sebelumnya, dia bekerja untuk Microsoft dan Wave HQ, produsen sistem otomasi akuntansi Kanada.
Tommy Lee adalah Insinyur Perangkat Lunak Senior di Coffee Meets Bagel. Sebelumnya, dia bekerja untuk Microsoft dan Wave HQ, produsen sistem otomasi akuntansi Kanada.