
Dapatkah Anda membayangkan pengklasifikasi gambar yang memecahkan hampir semua masalah dan tidak perlu dilatih sama sekali? Sudahkah Anda mempresentasikannya? Ternyata ini harus menjadi pengklasifikasi universal? Tepat sekali! Ini adalah jaringan saraf CLIP baru dari OpenAI. Parsing CLIP dari judul: Disassembling and Assembling Neural Networks menggunakan Star Wars sebagai contoh!
, ? , , ? — , , , " ", Google? , DALL•E ( ) " "? ? , ImageNet, ImageNet?
" " CLIP OpenAI. . : : .
, « » — - , .
CLIP ""?

, deep learning 1! , , — " ". , ( - ). , () :
10 — Mnist (Modified National Institute of Standards and Technology dataset)
10 100 80 , — CIFAR-10 CIFAR-100 (Canadian Institute For Advanced Research)
1000 ImageNet
— , . . , .
. , , () , , , , linear probe transfer learning. transfer learning , , , , , . linear probe — transfer learning, , , (linear classifier) .
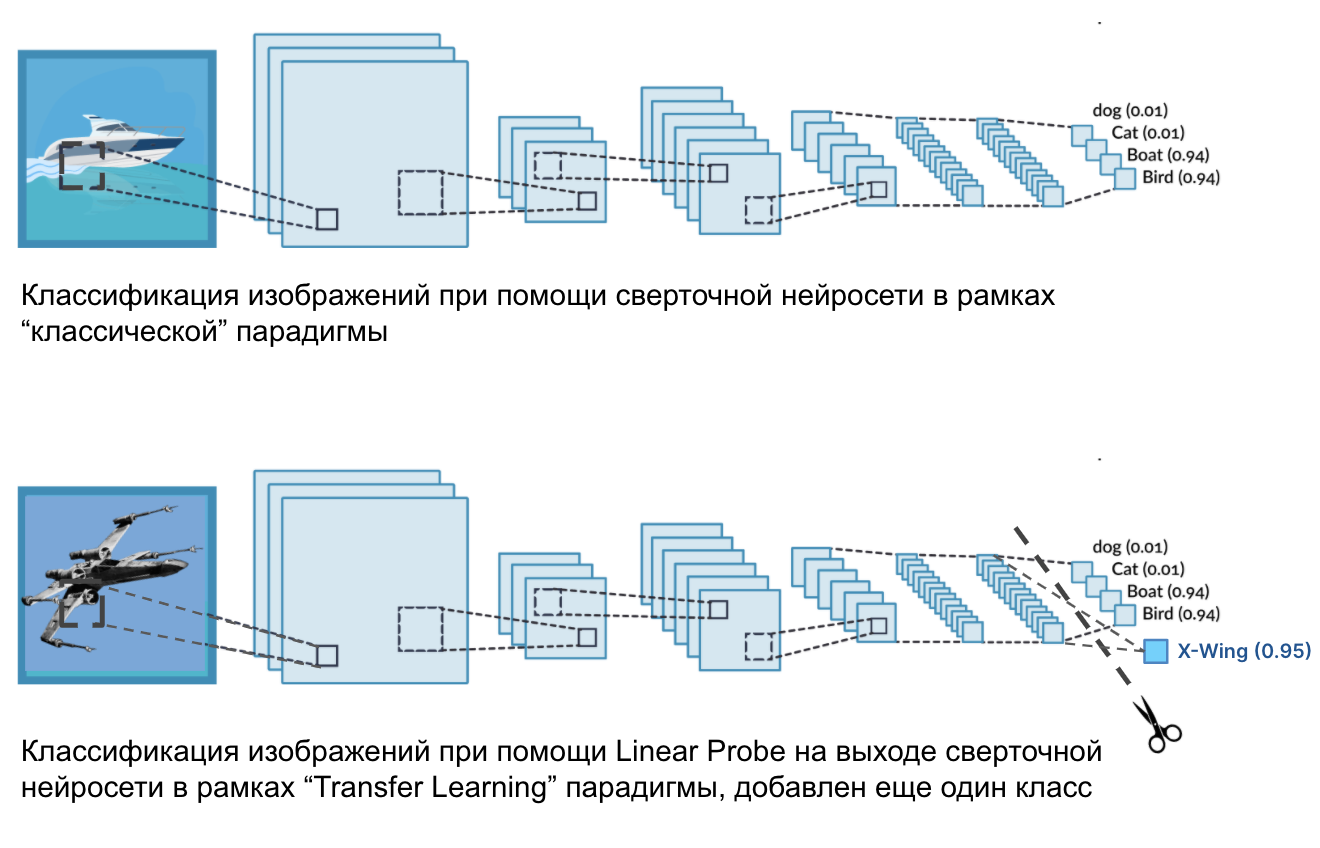
,
, ( ResNet-50 ResNet-101) , 224x224x3. , , , 224 224 , , (red, green, blue). , ( tensorflow ), , , , , ( , , , , , ).
n- . 1280 4096, - ( ). . , , . . , ( ), -. () , : .
, X-Wing, A-wing TIE fighter . . , . , , . , , . ( , ).
, , . , , , A-wing , X-Wing — , TIE fighter — , . linear probe, . few-shot linear probes, . , .
, transfer learning . , , , , , .
, , , few-shot linear probes . , , . .
, , . , ResNet-50 ResNet-101, , ! , , ! , , " " zero-shot transfer learning.
OpenAI , -, — "" . (), , - , (promt) . , , 400 -, . . " ".

. "" - ( ) (, ) . CLIP (-, , ) () -.
, , () " ", (embedding) , !
OpenAI ResNet-50 ImageNet " ", 1,28 , ResNet-50!
CLIP
, , . , , . "". :
What's in the Box? CLIP, ?
– . -?
. " " ?
. CLIP , ?
Beyond the Infinite. CLIP, ?
What's in the Box?
, , CLIP. , CLIP . , CLIP .
, PyTrorch TensorFlow, , , , GAN. , GAN , , ( ), . — . , ( ) . . GAN, , . . CLIP — , .

, CLIP. , , — , , . (CV NLP), , , , . .
- , 2 . ResNet - ( ), - ResNet', benchmark . , - , . ResNet Vision Transformer2.
- . OpenAI. , GPT. , ( ), , , . CBOW Text Transformer.

CLIP — ! , , ". ", -. , . CLIP — !
–
N, N (image, text) 400 -, . N N (promt) Image Encoder Text Encoder. . , (j, k) cosine similarity j- k- . , (image, text). cosine similarity N , cosine similarity N2-N . . ontrastive pre-training CLIP.

# image_encoder - ResNet or Vision Transformer
# text_encoder - CBOW or Text Transformer
# I[n, h, w, c] - minibatch of aligned images
# T[n, l] - minibatch of aligned texts
# W_i[d_i, d_e] - learned proj of image to embed
# W_t[d_t, d_e] - learned proj of text to embed
# t - learned temperature parameter
# extract feature representations of each modality
I_f = image_encoder(I) #[n, d_i]
T_f = text_encoder(T) #[n, d_t]
# joint multimodal embedding [n, d_e]
I_e = l2_normalize(np.dot(I_f, W_i), axis=1)
T_e = l2_normalize(np.dot(T_f, W_t), axis=1)
# scaled pairwise cosine similarities [n, n]
logits = np.dot(I_e, T_e.T) * np.exp(t)
# symmetric loss function
labels = np.arange(n)
loss_i = cross_entropy_loss(logits, labels, axis=0)
loss_t = cross_entropy_loss(logits, labels, axis=1)
loss = (loss_i + loss_t)/2
— . Numpy-like pseudocode CLIP.
I_f
T_f
— , Image Encoder Text Encoder
I_e
T_e
— ( ) , .
logits
— cosine similarity 3. ? , . outer productI_e
T_e
.
labels
— , cosine similarity. e.g.:np.arange(7) # array([0, 1, 2, 3, 4, 5, 6])
loss_i
loss_t
— , ligits (axis=0 axis=1)
loss
— .

.
ResNet Vision Transformers. ResNet' ResNet-50, ResNet-101, 3 , EfficientNet, 4, 16 64 , ResNet-50. RN50x4, RN50x16 RN50x64 . Vision Transformers ViT-B / 32, ViT-B / 16 ViT-L / 14.
32 . Adam, decoupled weight decay regularization learning rate decay, (lr_scheduler). - 32 768 ( - ), mixed-precision. , ( cosine similarity) . , , "-" .
ResNet: RN50x64 592 V100, 18 , Vision Transformer 12 256 V100.
, zero-shot learning, , , . OpenAI , CLIP , . zero-shot learning . deep learning — . , . , ?
, , , . . , CLIP . , . , : a photo of a plane, a photo of a car, a photo of a dog, ..., a photo of a bird. CLIP , , a photo of a dog. , , (, ) , . , ?

, ! CLIP, Text Encoder, . , . .
, -, , , , ! ? ? ? ? ? ? ? ? ? , CLIP . , : " " " ".
, CLIP . , CLIP , . , : photo of a ____ a centered satellite photo of ____. , . , ! — .

, , CLIP . , , . . transfer learning . :
-, -, ? — , CLIP!
, ? — , CLIP!
— , , , " ", Google? — CLIP!
? — CLIP. , .
. .
— ? , - , CLIP , CLIP ?
— .. .. Mnist , , . StanfordCars , . ImageNet ..
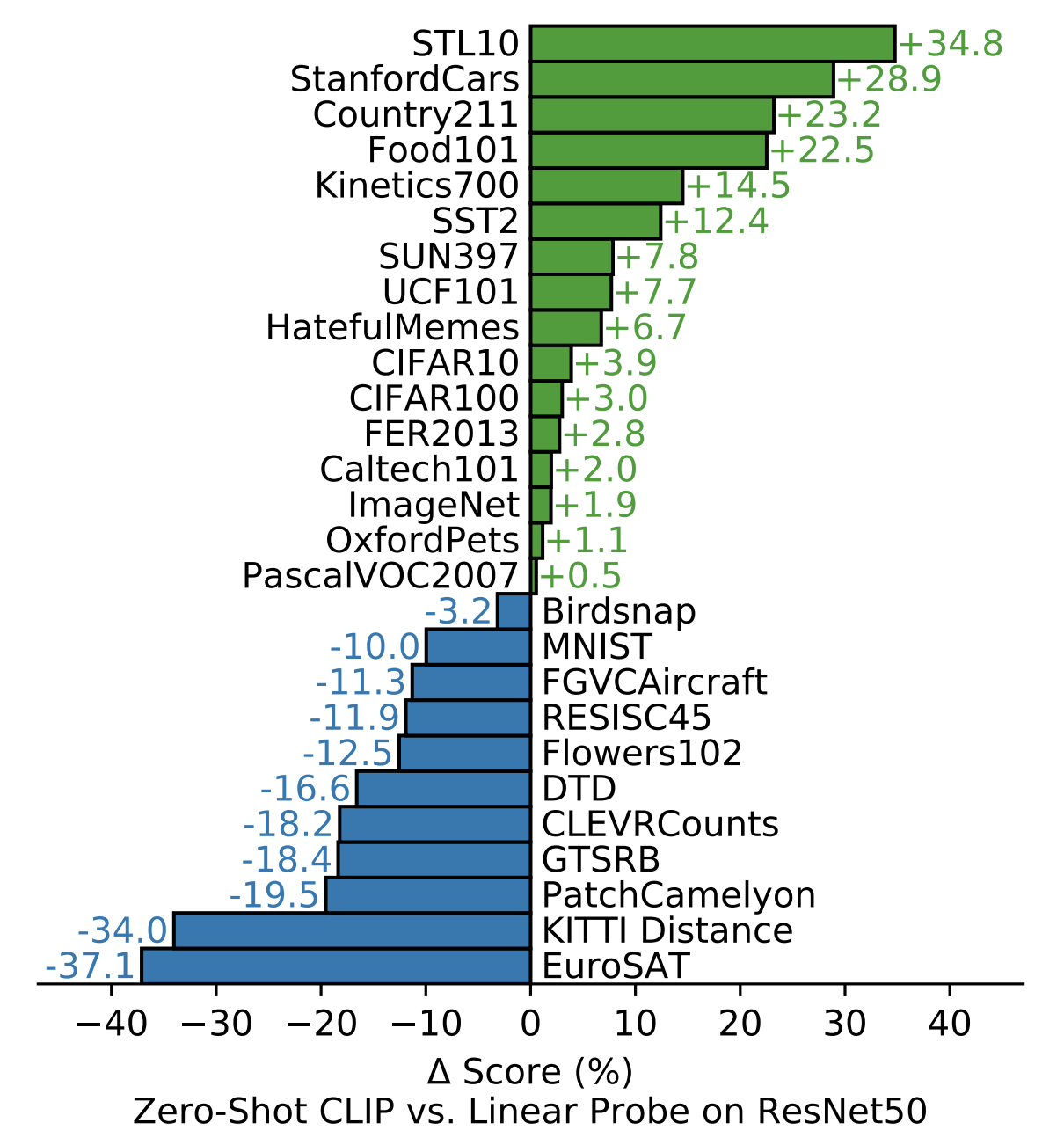
CLIP baseline, . 27 . CLIP baseline , 16 27 , ImageNet! - ResNet-50. , CLIP baseline Kinetics700 UCF101 " ". , .
— ImageNet , - ResNet-50, linear probe, ?
— . .
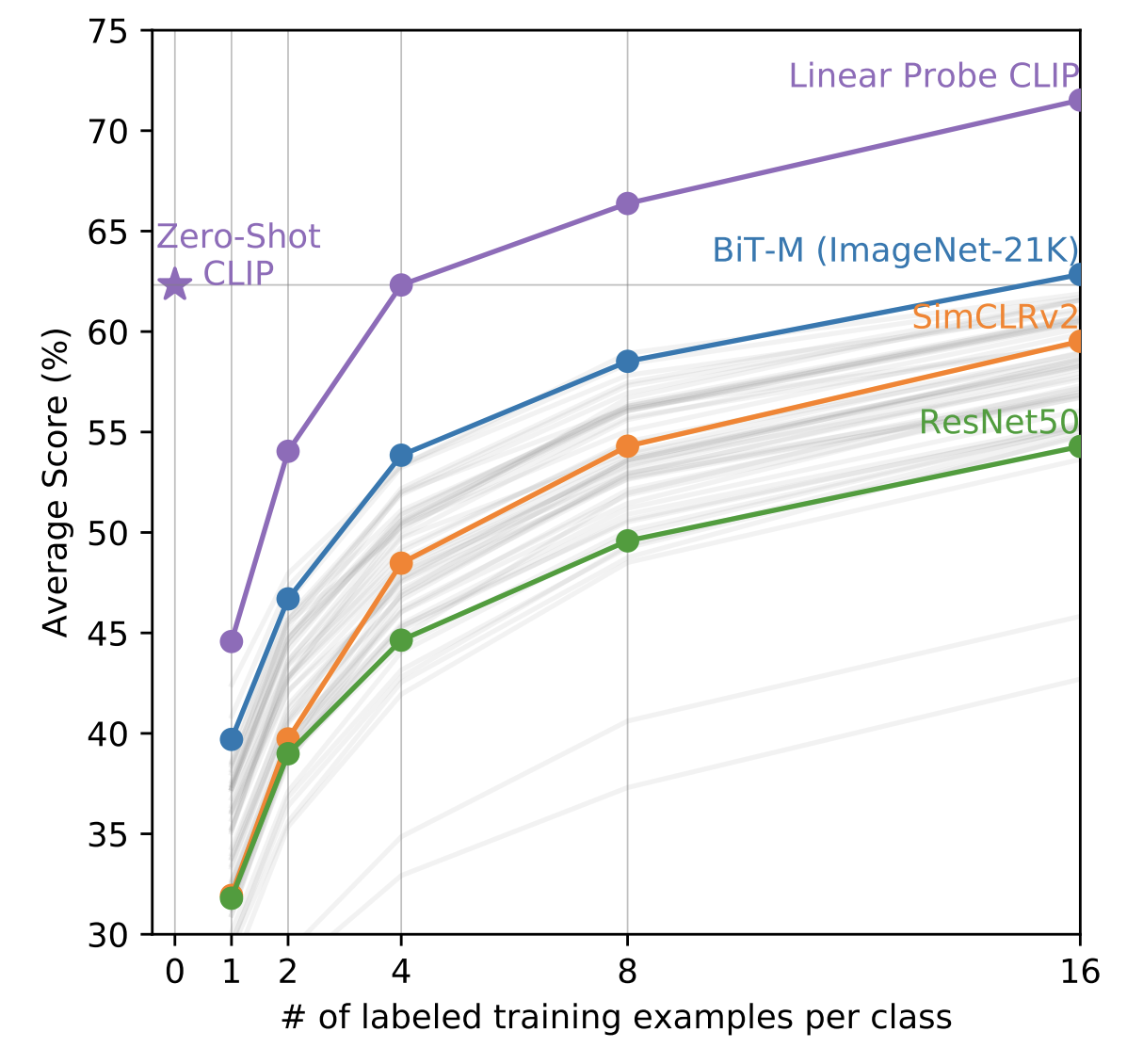
Zero-shot CLIP few-shot linear probes! CLIP , CLIP, Image Encoder -, (4-shot linear probes), 4 . Zero-shot CLIP BiT-M 16-shot linear probes. , few-shot learning CLIP, , linear probes .
— , , , , ?
— , . , . , , . , ( ). , , CLIP .

Zero-shot CLIP , ImageNet.
. . CLIP (ViT-L / 14 @ 336p) , ResNet-101, ImageNet. , . . , ImageNet. , , ObjectNet ImageNet-A. . , CLIP.

( ) ImageNet . CLIP , ImageNet, , . , CLIP , , , -, . NLP, CV.
CLIP — DALL·E?
DALL·E, , . , , .

Image Captioning ( ), DALL·E () — .

. DALL·E : a living room with two black armchairs and a painting of darth vader. the painting is mounted above a coffee table.
OpenAI , , DALL·E. , DALL·E, , ?
, , . DALL·E , .
OpenAI . 32 512- DALL·E, CLIP. , , CLIP , , (promt) .

, CLIP, , . , CLIP, .
, CLIP — NLP CV. , , , , "" . , , NLP, : Vision Transformers. few-shot zero-shot learning nlp cv . , , !
? CLIP — , , DALL·E!
, , :
TensorFlow: Advanced Techniques deeplearning ai, Andrew Ng
, Andrej Karpathy 95% top-5 ImageNet. 2021 98.8% top-5 (EfficientNet-L2) ImageNet.
Vision Transformers . . CLIP CLIP-ViT Vision Transformer'. 224x224 : ViT-B/32, ViT-B/16, ViT-L/14, ViT-L/14, fine-tune 336336.
, cosine similarity τ
np.exp(t)
, . τ, logits softmax.
! , . !
CLIP? " "? , -, ? ? - ? " "? ? !