Pendekatan dominan untuk pemodelan bahasa saat ini didasarkan pada jaringan saraf berulang. Keberhasilan mereka dalam pemodelan sering kali terkait dengan kemampuan jaringan tersebut untuk menangani konteks yang tidak terbatas. Dalam artikel ini, kami mengembangkan pendekatan konteks terbatas menggunakan konvolusi bertumpuk (komposit), yang bisa lebih efisien karena memungkinkan potongan data berurutan untuk diparalelkan. Kami mengusulkan mekanisme terpandu saraf baru yang disederhanakan yang lebih unggul dari yang diusulkan oleh Oord et al. (2016b) [26]dan menyelidiki dampak keputusan arsitektur kunci untuk itu. Pendekatan yang diusulkan mencapai hasil yang paling signifikan pada tolok ukur WikiText103, meskipun ini ditandai dengan ketergantungan jangka panjang, serta hasil yang sebanding pada tolok ukur Google Billion Words. Model kami mengurangi latensi dalam mengevaluasi proposal berdasarkan urutan besarnya, dibandingkan dengan nilai dasar berulang. Sejauh yang kami tahu, ini adalah pertama kalinya pendekatan non-periodik bersaing dengan model berulang yang kuat dalam masalah bahasa berskala besar.
1. Perkenalan
Model bahasa statistik memperkirakan distribusi probabilitas dari urutan kata dengan memodelkan probabilitas kata berikutnya yang diberikan kata-kata sebelumnya, yaitu

wi - . (Yu & Deng, 2014)[34] (Koehn, 2010) [17].
, (Bengio et al., 2003 [1]; Mikolov et al., 2010 [2]; Jozefowicz et al., 2016 [14]) n- (Kneser & Ney, 1995 [16]; Chen & Goodman, 1996 [3]). , , , . , . (LSTM; Hochreiter et al., 1997[12]), .
. (LeCun & Bengio, 1995 [19]). ,

N k. ,

, , , , (Manning & Schutze, 1999 [20]; Steedman, 2002 [31]). , , (Glorot & Bengio, 2010 [6]).
. ( ) , . , , ( 2).
, (Jozefowicz et al., 2016 [14]). (GLU) , ( 5.2).
, , , , LSTM, Google Billion Word Benchmark (Chelba et al., 2013 [2]). WikiText-103, , , (Merity et al., 2016 [21]). , , (GLU) , LSTM- Oord et al. (2016 [26]; 4, 5).
2.
, , , . (Bengio et al., 2003 [1])
![H = [h_0,. ... ... , h_N]](https://habrastorage.org/getpro/habr/upload_files/b27/171/209/b271712099a686b5bd272588a5bbb215.svg)


f H

, i ( ).

, , , . . , , , , ( 5).
1 . ,


![E = [H_ {w0},. ... ... , H_ {wN}].](https://habrastorage.org/getpro/habr/upload_files/539/eca/1d3/539eca1d3a11c3bbd3cafa472e93aa44.svg)


m, n – , , k - ,

( , ),


,

. , (Oord et al., 2016a [25]). ,

, - , ,



LSTM,

, . (GLU). E

(GLU) , (He et al., 2015a [10]). , 5 ().
- softmax, , , (Gutmann & Hyvarinen [9]) softmax (Morin & Bengio, 2005 [24]). , softmax. ( , ) – (Grave et al., 2016a [7]). – , .
3.
, , (Hochreiter & Schmidhuber, 1997 [12]). LSTMs , () . . . , , , () .
, , , . , , , . Oord et al. (2016b [26]) LSTM

. Kalchbrenner et al. (2016 [15]) .
(GLU) - , Dauphin & Grangier (2015) [35] , . , . LSTM, gated tanh unit (GTU),
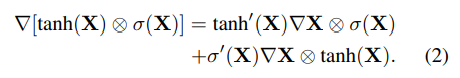
, ( , ) -

, (GLU)


σ (X). , . §5.2 , (GLU) .
4.
4.1
. -, Google Billion Word (Chelba et al., 2013 [2]) , , 800 . . , 3 , . 30 301 028 , . -, WikiText-103 - , 100 . , 200 . (Merity et al., 2016 [21]). GBW, , , . <S> </S> . Google Billion Word , WikiText-103 . <S> </ S> , </S>. ,

.
4.2
Torch (Collobert et al., 2011 [5]) Tesla M40. , . 8 , , 1/8 . Nvidia NCCL. .
, (Sutskever et al., 2013 [32]). , . (Pascanu et al., 2013 [27]) (Salimans & Kingma, 2016 [28]).
![1. . [k, n]. «B» .](https://habrastorage.org/getpro/habr/upload_files/879/e3c/bf4/879e3cbf49c176fcc35e52d3b84aff1d.PNG "1. . [k, n]. «B» .")
. (2013) [27] , , RNN. RNN, .

, . , , 1.
4.3
. {1,. . . , 10}, {128,. . . , 256}, {128,. . . , 2048}, - {3,. . . , 5}. , , , , . , ( ., 2015b [11]), [1., 2.], 0,99 0,1. , .
5.
LSTM . LSTM RNN .
, GCNN LSTM Google . , softmax (Grave et al., 2016a [7]), . GCNN 38,1 , LSTM 39,8 ( 2).

, GCNN . 2 , , softmax softmax. softmax, GCNN . GCNN , LSTM Jozefowicz et al. (2016 [14]), , softmax. , , , 31,9 30,6 , 2 8 3 32 LSTM. , , (Shazeer et al., 2017 [30]), .
![2. (Jozefowicz et al., 2016 [14]), softmax, softmax , .](https://habrastorage.org/getpro/habr/upload_files/571/bf3/46b/571bf346be581abdec8d1c71eff67e53.PNG "2. (Jozefowicz et al., 2016 [14]), softmax, softmax , .")
, GCNN . Google Billion Word - 20 . WikiText-103, , , . WikiText-103 , , 4000 . GCNN LSTM ( 3). GCNN-8 8 800 , LSTM - 1024 . , GCNN .

Gigaword Chen et al. (2016 [4]) . , , , 55,6 29,4. Penn tree. , GCNN LSTM : 108,7 109,3 . , , . LSTM, , GCNN , , .
5.1
. . , . , () . , () - , . , , , , . , . , , .
, 43,9 Google Billion Word. LSTM 2048 2, GCNN-8Bottleneck 7 Resnet, , (He et al., 2015a [10]), GCNN-8 . () k > 1 k = 1. k = 1 , . , .

LSTM 750 20, 15 000 . - 15 000 . 4 , LSTM GCNN . LSTM , 750 . , LSTM cuDNN, cuDNN , . , 1- cuDNN. LSTM, GCNN , , GCNN 20 .
 Google Billion Word () . (GLU) .")
5.2 ()
, . (GTU) LSTM

(Oord et al., 2016b [17]) , ReLU Tanh. , . 3 () , GLU , WikiText-103. , ReLU , . ReLU, GLU. , Tanh, GTU , , . GTU , , .
GTU Tanh , Tanh GTU . ( 3, ) , , GTU Tanh. , ReLU GLU,

, . GLU .
3 () Google Billion Words. 100 - , . WikiText-103, . 5 GLU ReLU, LSTM RNN, (Jozefowicz et al., 2016 [14]) .
5.3
, , , . GLU , , GLU. (Manning & Schutze, 1999 [20]). , GLU

- , softmax, -. GLU - (Mnih & Hinton, 2007 [23]),

 Wiki-103 (). , , 20.")
5 , GLU, , . 40 , GLU 20 . (115) 67,6 5- -, . , , 61 Google Billion Word, 5- -, (Ji et al., 2015 [13]).
5.4

4 CNN. . , , , 40 , WikiText-103, . , , , . , , 40 . 4 , WikiText-103 , Google Billion Word, . WikiText-103 , Google Billion Word, 20. , 4000 , , 30 .
5.5
. , . - . 6 , . , . (1 0,01), . , , , .

6.
. , , , () . , , , . , WikiText-103. Google Billion Word , .
Spoiler
Bengio, Yoshua, Ducharme, Rejean, Vincent, Pascal, and Jauvin, Christian. A neural probabilistic language model. journal of machine learning research, 3(Feb):1137–1155, 2003.
Chelba, Ciprian, Mikolov, Tomas, Schuster, Mike, Ge, Qi, Brants, Thorsten, Koehn, Phillipp, and Robinson, Tony. One billion word benchmark for measuring progress in statistical language modeling. arXiv preprint arXiv:1312.3005, 2013.
Chen, Stanley F and Goodman, Joshua. An empirical study of smoothing techniques for language modeling. In Proceedings of the 34th annual meeting on Association for Computational Linguistics, pp. 310–318. Association for Computational Linguistics, 1996.
Chen, Wenlin, Grangier, David, and Auli, Michael. Strategies for training large vocabulary neural language models. CoRR, abs/1512.04906, 2016.
Collobert, Ronan, Kavukcuoglu, Koray, and Farabet, Clement. Torch7: A Matlab-like Environment for Machine Learning. In BigLearn, NIPS Workshop, 2011. URL http://torch.ch.
Glorot, Xavier and Bengio, Yoshua. Understanding the difficulty of training deep feedforward neural networks. The handbook of brain theory and neural networks, 2010.
Grave, E., Joulin, A., Cisse, M., Grangier, D., and Jegou, H. Efficient softmax approximation for GPUs. ArXiv e-prints, September 2016a.
Grave, E., Joulin, A., and Usunier, N. Improving Neural Language Models with a Continuous Cache. ArXiv e-prints, December 2016b.
Gutmann, Michael and Hyvarinen, Aapo. Noise-contrastive estimation: A new estimation principle for unnormalized statistical models.
He, Kaiming, Zhang, Xiangyu, Ren, Shaoqing, and Sun, Jian. Deep residual learning for image recognition. arXiv preprint arXiv:1512.03385, 2015a.
He, Kaiming, Zhang, Xiangyu, Ren, Shaoqing, and Sun, Jian. Delving deep into rectifiers: Surpassing human-level performance on imagenet classification. In Proceedings of the IEEE International Conference on Computer Vision, pp. 1026–1034, 2015b.
Hochreiter, Sepp and Schmidhuber, Jurgen. Long short-term memory. Neural computation, 9(8):1735–1780, 1997.
Ji, Shihao, Vishwanathan, SVN, Satish, Nadathur, Anderson, Michael J, and Dubey, Pradeep. Blackout: Speeding up recurrent neural network language models with very large vocabularies. arXiv preprint arXiv:1511.06909, 2015.
Jozefowicz, Rafal, Vinyals, Oriol, Schuster, Mike, Shazeer, Noam, and Wu, Yonghui. Exploring the limits of language modeling. arXiv preprint arXiv:1602.02410, 2016.
Kalchbrenner, Nal, Espeholt, Lasse, Simonyan, Karen, van den Oord, Aaron, Graves, Alex, and Kavukcuoglu, Koray. Neural Machine Translation in Linear Time. arXiv, 2016.
Kneser, Reinhard and Ney, Hermann. Improved backing-off for m-gram language modeling. In Acoustics, Speech, and Signal Processing, 1995. ICASSP-95., 1995 International Conference on, volume 1, pp. 181–184. IEEE, 1995.
Koehn, Philipp. Statistical Machine Translation. Cambridge University Press, New York, NY, USA, 1st edition, 2010. ISBN 0521874157, 9780521874151.
Kuchaiev, Oleksii and Ginsburg, Boris. Factorization tricks for LSTM networks. CoRR, abs/1703.10722, 2017. URL http://arxiv.org/abs/1703.10722.
LeCun, Yann and Bengio, Yoshua. Convolutional networks for images, speech, and time series. The handbook of brain theory and neural networks, 3361(10):1995, 1995.
Manning, Christopher D and Schutze, Hinrich. Foundations of statistical natural language processing, 1999.
Merity, S., Xiong, C., Bradbury, J., and Socher, R. Pointer Sentinel Mixture Models. ArXiv e-prints, September 2016.
Mikolov, Toma´s, Martin, Karafiat, Burget, Lukas, Cernocky, Jan, and Khudanpur, Sanjeev. Recurrent Neural Network based Language Model. In Proc. of INTERSPEECH, pp. 1045–1048
Mnih, Andriy and Hinton, Geoffrey. Three new graphical models for statistical language modelling. In Proceedings of the 24th international conference on Machine learning, pp. 641–648. ACM, 2007.
Morin, Frederic and Bengio, Yoshua. Hierarchical probabilistic neural network language model. In Aistats, volume 5, pp. 246–252. Citeseer, 2005.
Oord, Aaron van den, Kalchbrenner, Nal, and Kavukcuoglu, Koray. Pixel recurrent neural networks. arXiv preprint arXiv:1601.06759, 2016a.
Oord, Aaron van den, Kalchbrenner, Nal, Vinyals, Oriol, Espeholt, Lasse, Graves, Alex, and Kavukcuoglu, Koray. Conditional image generation with pixelcnn decoders. arXiv preprint arXiv:1606.05328, 2016b.
Pascanu, Razvan, Mikolov, Tomas, and Bengio, Yoshua. On the difficulty of training recurrent neural networks. In Proceedings of The 30th International Conference on Machine Learning, pp. 1310–1318, 2013.
Salimans, Tim and Kingma, Diederik P. Weight normalization: A simple reparameterization to accelerate training of deep neural networks. arXiv preprint arXiv:1602.07868, 2016.
Shazeer, Noam, Pelemans, Joris, and Chelba, Ciprian. Skip-gram language modeling using sparse non-negative matrix probability estimation. arXiv preprint arXiv:1412.1454, 2014.
Shazeer, Noam, Mirhoseini, Azalia, Maziarz, Krzysztof, Davis, Andy, Le, Quoc V., Hinton, Geoffrey E., and Dean, Jeff. Outrageously large neural networks: The sparsely-gated mixtureof-experts layer. CoRR, abs/1701.06538, 2017. URL http://arxiv.org/abs/1701.06538.
Steedman, Mark. Proses sintaksis. 2002.
Sutskever, Ilya, Martens, James, Dahl, George E, dan Hinton, Geoffrey E. Tentang pentingnya inisialisasi dan momentum dalam pembelajaran yang mendalam. 2013.
Wang, Mingxuan, Lu, Zhengdong, Li, Hang, Jiang, Wenbin, dan Liu, Qun. gencnn: Arsitektur konvolusional untuk prediksi urutan kata. CoRR, abs / 1503.05034, 2015. URL http://arxiv.org/abs/1503.05034 .
Yu, Dong dan Deng, Li. Pengenalan Ucapan Otomatis: Pendekatan Pembelajaran Mendalam. Springer Publishing Company, Incorporated, 2014. ISBN 1447157788, 9781447157786.
Dauphin, Yann N dan Grangier, David. Memprediksi distribusi dengan jaringan kepercayaan linier. pracetak arXiv arXiv: 1511.05622, 2015.