
Aliran data di tabel ini agak rumit untuk diikuti, jadi berikut adalah bagan ekuivalen yang mewakili tabel sebagai grafik:

Bulatkan biaya burrito super vegi El Farolito menjadi $ 8, begitu seterusnya senilai $ 2, jumlah totalnya menjadi $ 20.
Oh, saya benar-benar lupa! Salah satu teman saya tidak cukup untuk satu burrito, dia butuh dua. Jadi saya sangat ingin memesan tiga. Jika diperbarui
Num Burritos
, mesin lembar bentang yang naif dapat menghitung ulang seluruh dokumen dengan menghitung ulang sel tanpa masukan terlebih dahulu dan kemudian menghitung ulang setiap sel dengan masukan siap hingga sel habis. Dalam kasus ini, pertama-tama kita akan menghitung harga dan kuantitas burrito, lalu harga burrito pengiriman, dan total baru $ 30.

Strategi sederhana untuk menghitung ulang seluruh dokumen ini mungkin tampak sia-sia, tetapi sebenarnya lebih baik daripada VisiCalc, spreadsheet pertama dalam sejarah dan yang disebut sebagai aplikasi pembunuh pertama yang membuat komputer Apple II populer. VisiCalc menghitung ulang sel dari kiri ke kanan dan atas ke bawah berkali-kali, memindai mereka berulang kali, meskipun tidak ada yang berubah. Terlepas dari algoritme yang "menarik" ini, VisiCalc tetap menjadi perangkat lunak spreadsheet yang dominan selama empat tahun. Pemerintahannya berakhir pada tahun 1983, ketika Lotus 1-2-3 mengambil alih pasar penghitungan ulang tatanan alami. Ini adalah bagaimana Tracy Robnett Licklider menggambarkannya di majalah Byte :
Lotus 1-2-3 menggunakan pengurutan alami, meskipun juga mendukung mode baris dan kolom VisiCalc. Penghitungan ulang alami mempertahankan daftar dependensi sel dan sel yang dihitung ulang berdasarkan dependensi.
Lotus 1-2-3 menerapkan hitung ulang semua strategi yang ditunjukkan di atas. Selama dekade pertama pengembangan spreadsheet, ini adalah pendekatan yang paling optimal. Ya, kami menghitung ulang setiap sel dalam dokumen, tetapi hanya sekali.
Tapi bagaimana dengan harga burrito pengiriman
Betulkah. Dalam contoh saya dengan tiga burrito, tidak ada alasan untuk menghitung ulang harga satu burrito dengan pengiriman, karena mengubah jumlah burrito dalam pesanan tidak dapat mempengaruhi harga burrito. Pada tahun 1989, salah satu pesaing Lotus menemukan hal ini dan menciptakan SuperCalc5, mungkin menamainya dengan teori super burrito di balik algoritme. SuperCalc5 menghitung ulang "hanya sel yang bergantung pada sel yang diubah", jadi pembaruan jumlah burrito adalah seperti ini:
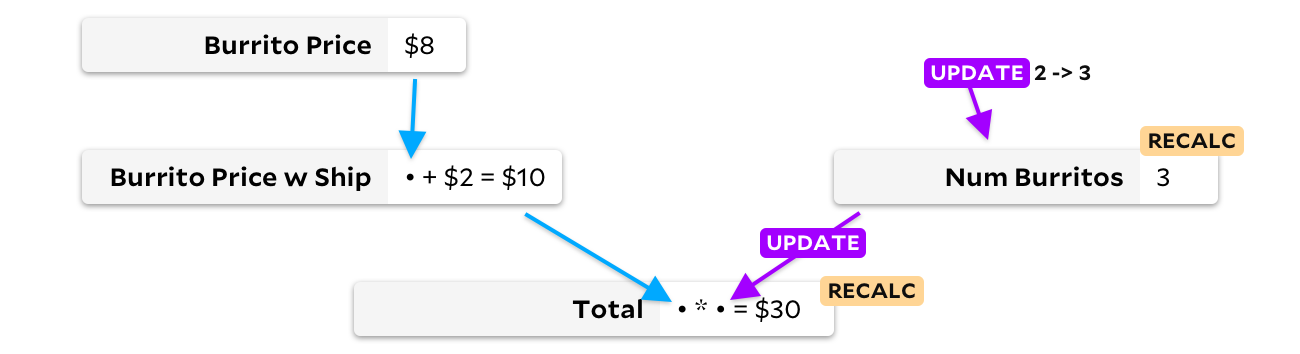
Dengan memperbarui sel hanya ketika data masukan berubah, kita dapat menghindari penghitungan ulang harga burrito dengan pengiriman. Dalam hal ini, kami hanya akan menyimpan satu tambahan, tetapi dalam spreadsheet yang besar, penghematannya bisa jauh lebih signifikan! Sayangnya, kami memiliki masalah yang berbeda sekarang. Katakanlah teman-teman saya sekarang menginginkan burrito daging, yang satu dolar lebih mahal, dan El Farolito menambahkan $ 2 ke pesanan mereka berapa pun jumlah burrito. Sebelum kita menghitung ulang sesuatu, mari kita lihat grafiknya:
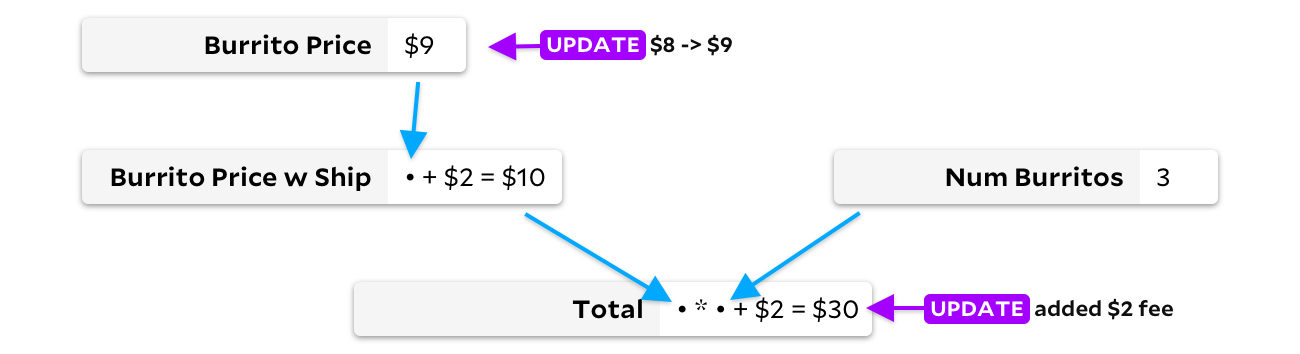
Karena ada dua sel yang diperbarui di sini, kami mengalami masalah. Haruskah Anda menghitung ulang harga satu burrito terlebih dahulu atau totalnya? Idealnya, kita hitung dulu harga burrito, perhatikan perubahannya, lalu hitung ulang harga burrito pengiriman, dan terakhir hitung ulang Totalnya. Namun, jika kita menghitung ulang totalnya terlebih dahulu, sebagai gantinya, kita harus menghitung ulang untuk kedua kalinya setelah harga burrito $ 9 yang baru menyebar ke sel. Jika kita tidak menghitung sel dalam urutan yang benar, algoritme ini tidak lebih baik daripada menghitung ulang seluruh dokumen. Selambat VisiCalc dalam beberapa kasus!
Jelas, penting bagi kami untuk menentukan urutan yang benar dalam memperbarui sel. Secara umum, ada dua solusi untuk masalah ini: penandaan kotor dan penyortiran topologis.
Solusi pertama melibatkan pelabelan semua sel di hilir sel yang diperbarui. Mereka ditandai sebagai kotor. Misalnya, saat kami memperbarui harga burrito, kami menandai sel hilir
Burrito Price w Ship
dan
Total
, sebelum melakukan penghitungan ulang apa pun:
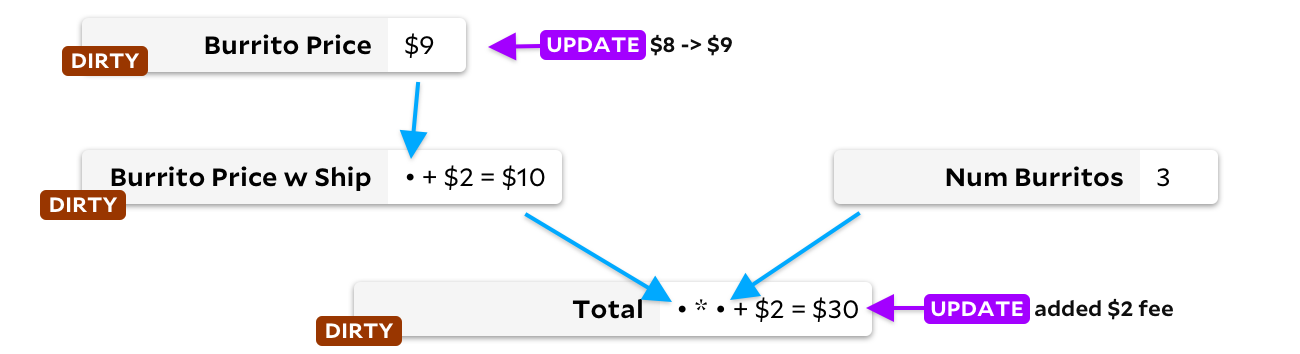
Kemudian, dalam satu putaran, kami menemukan sel kotor tanpa masukan kotor - dan menghitung ulang. Ketika tidak ada sel kotor yang tersisa, kita selesai! Ini memecahkan masalah ketergantungan kita. Namun, ada satu kelemahan - jika sel dihitung ulang dan kami menemukan bahwa hasil baru sama dengan yang sebelumnya, kami masih akan menghitung ulang sel subordinat! Sedikit logika tambahan akan membantu menghindari masalah, tetapi sayangnya kami masih menghabiskan waktu untuk menandai sel dan menghapus tanda.
Solusi kedua adalah jenis topologi. Jika sel tidak memiliki input, kami menandai tingginya sebagai 0. Jika ya, kami menandai tinggi sebagai maksimum sel input ditambah satu. Ini memastikan bahwa setiap sel memiliki nilai ketinggian yang lebih besar daripada sel yang masuk, jadi kami hanya melacak semua sel dengan masukan yang diubah, selalu memilih sel dengan ketinggian terendah untuk dihitung ulang terlebih dahulu:
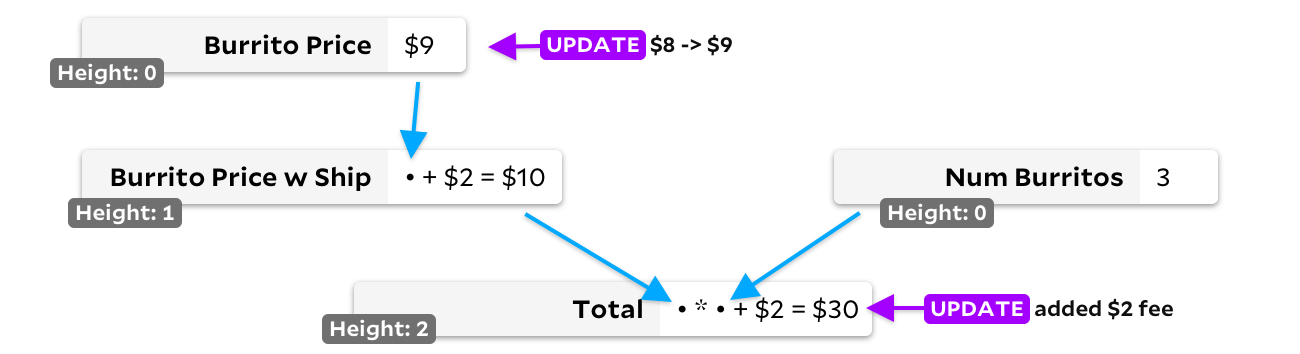
Dalam contoh pembaruan ganda kami, harga burrito dan jumlah total awalnya akan ditambahkan ke heap konversi. Harga burrito lebih murah dan akan dihitung ulang terlebih dahulu. Karena hasilnya berubah, kami akan menambahkan harga burrito pengiriman ke heap penghitungan ulang, dan karena tingginya juga lebih pendek daripada
Total
kemudian akan dihitung ulang sebelum akhirnya kami menghitung ulang
Total
.
Ini jauh lebih baik daripada solusi pertama: tidak ada sel yang ditandai kotor kecuali salah satu sel yang masuk benar-benar berubah. Namun, ini membutuhkan sel untuk disimpan dalam urutan yang diurutkan menunggu penghitungan ulang. Ketika digunakan di heap, ini menyebabkan perlambatan
O(n log n)
, yang secara asimtotik lebih lambat dalam kasus terburuk daripada strategi perhitungan ulang Lotus 1-2-3.
Excel modern menggunakan kombinasi kontaminasi dan penyortiran topologis , lihat dokumentasinya untuk detailnya.
Evaluasi malas
Kami sekarang kurang lebih mencapai algoritme konversi dalam spreadsheet modern. Saya curiga, pada prinsipnya, tidak ada alasan bisnis untuk perbaikan lebih lanjut, sayangnya. Orang-orang telah menulis cukup banyak rumus Excel untuk membuat migrasi ke platform lain tidak mungkin dilakukan. Untungnya, saya tidak paham bisnis, jadi kami akan mempertimbangkan perbaikan lebih lanjut.
Selain dari caching, salah satu aspek menarik dari grafik komputasi bergaya spreadsheet adalah kita hanya dapat menghitung sel yang kita minati. Ini terkadang disebut sebagai evaluasi malas atau komputasi berdasarkan permintaan. Sebagai contoh yang lebih spesifik, berikut adalah grafik spreadsheet burrito yang sedikit diperluas. Contohnya sama seperti sebelumnya, tetapi kami telah menambahkan apa yang paling baik dijelaskan sebagai "perhitungan salsa". Setiap burrito mengandung 40 gram salsa dan kami melakukan perkalian cepat untuk mengetahui berapa banyak salsa yang ada di seluruh pesanan. Karena kami memesan tiga burrito, akan ada total 120 gram salsa.

Tentu saja, para pembaca yang cerdas telah memperhatikan masalah ini: berat total salsa dalam satu pesanan adalah metrik yang tidak berguna. Siapa yang peduli jika 120 gram? Apa yang harus saya lakukan dengan informasi ini? Sayangnya, spreadsheet biasa akan menghabiskan siklus untuk penghitungan salsa, bahkan jika kita tidak membutuhkan penghitungan tersebut hampir sepanjang waktu.
Di sinilah penghitungan ulang malas dapat membantu. Jika kita entah bagaimana menunjukkan bahwa kita hanya tertarik pada hasilnya
Total
, kita dapat menghitung ulang sel ini, ketergantungannya dan tidak menyentuh salsa. Mari kita sebut itu sel yang
Total
diamati saat kita mencoba melihat hasilnya. Kita juga dapat memanggil
Total
tiga dari ketergantungannya yang diperlukan.sel, karena mereka diperlukan untuk menghitung beberapa sel yang diamati.
Salsa In Order
dan
Salsa Per Burrito
menyebutnya tidak perlu .
Untuk mengatasi masalah ini, beberapa rekan tim Rust membuat kerangka Salsa , secara eksplisit menamainya setelah penghitungan salsa yang tidak perlu yang menyia-nyiakan siklus komputer mereka. Tentunya mereka bisa menjelaskan lebih baik dari saya bagaimana cara kerjanya. Secara kasar, kerangka kerja menggunakan nomor revisi untuk melacak apakah sel perlu penghitungan ulang. Mutasi apa pun dalam rumus atau input meningkatkan nomor revisi global, dan setiap sel melacak dua revisi:
verified_at
untuk revisi yang hasilnya diperbarui dan
changed_at
untuk revisi yang hasilnya benar-benar diubah.
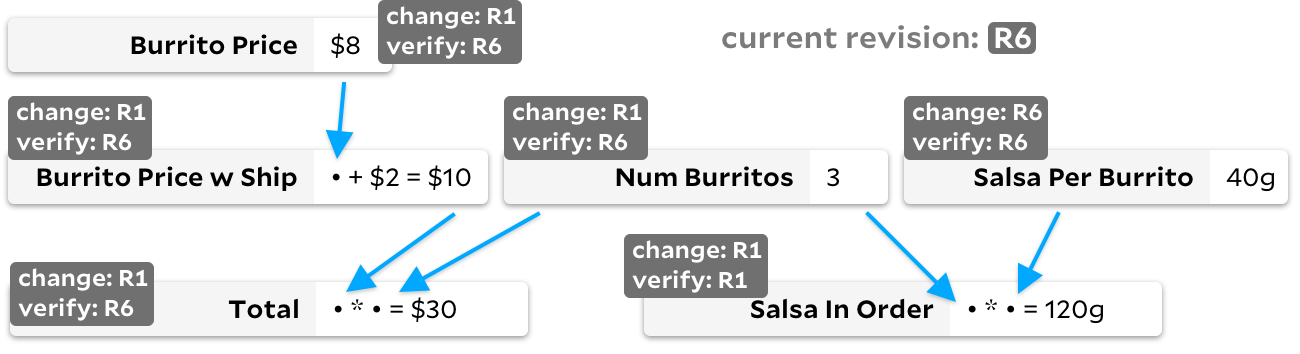
Saat pengguna menunjukkan bahwa dia membutuhkan nilai baru
Total
, pertama-tama kami menghitung ulang secara rekursif semua sel yang diperlukan untuk itu
Total
, melewati sel yang revisinya
last_updated
sama dengan revisi global. Setelah dependensi
Total
diperbarui, kami menjalankan kembali rumus sebenarnya
Total
hanya jika Burrito Price w Ship atau memiliki
Num Burrito
revisi yang
changed_at
lebih besar dari revisi yang diperiksa
Total
... Ini bagus untuk Salsa dalam penganalisis karat, di mana kesederhanaan penting dan setiap sel menghabiskan waktu untuk menghitungnya. Namun, pada grafik dengan burrito di atas, Anda dapat melihat kekurangannya - jika
Salsa Per Burrito
terus berubah, angka revisi global kami akan sering meningkat. Akibatnya, setiap pengamatan
Total
membutuhkan tiga sel, bahkan jika tidak ada yang berubah. Tidak ada rumus yang akan dihitung ulang, tetapi jika grafiknya besar, pengulangan semua dependensi sel dapat memakan biaya.
Opsi lebih cepat untuk evaluasi malas
Alih-alih menciptakan algoritme malas baru, mari coba dua algoritme spreadsheet klasik yang disebutkan sebelumnya: pelabelan dan pengurutan topologis. Seperti yang dapat Anda bayangkan, model malas memperumit kedua tugas ini, tetapi keduanya masih dapat dijalankan.
Mari kita lihat tandanya dulu. Seperti sebelumnya, saat kami mengubah rumus sel, kami menandai semua sel hilir sebagai kotor. Jadi saat memperbarui,
Salsa Per Burrito
akan terlihat seperti ini:

Namun alih-alih segera menghitung ulang semua sel kotor, kami menunggu hingga pengguna mengamati sel tersebut. Kemudian kami menjalankan algoritme Salsa di atasnya, tetapi bukannya memeriksa ulang dependensi dengan nomor versi yang kedaluwarsa
verified_at
, kami hanya memeriksa ulang sel yang ditandai kotor. Adapton menggunakan teknik ini . Dalam situasi seperti itu, mengamati sel
Total
mengungkapkan bahwa itu tidak kotor, dan oleh karena itu kita dapat melewati lintasan grafik yang akan dilakukan Salsa!
Jika Anda mengamatinya
Salsa In Order
, maka itu ditandai sebagai kotor, dan oleh karena itu kami akan memeriksa ulang dan menghitung ulang dan
Salsa Per Burrito
, dan
Salsa In Order
. Bahkan di sini, ada keuntungan dibandingkan hanya menggunakan nomor revisi, karena kita dapat melewati sel yang masih kosong secara rekursif
Num Burritos
.
Pelabelan malas kotor bekerja sangat baik pada seringnya mengubah set sel yang kita coba amati. Sayangnya, ini memiliki kelemahan yang sama dengan algoritma penandaan kotor sebelumnya. Jika sel dengan banyak sel hilir berubah, maka kita menghabiskan banyak waktu untuk menandai sel dan menghapus tanda, bahkan jika masukan tidak benar-benar berubah saat kita pergi ke penghitungan ulang. Dalam kasus terburuk, setiap perubahan mengarah pada fakta bahwa kami menandai seluruh grafik sebagai kotor, yang memberi kami urutan kinerja yang kira-kira sama dengan algoritme Salsa.
Selain pelabelan yang berantakan, kami juga dapat menyesuaikan pengurutan topologis untuk evaluasi malas. Metode ini menggunakan pustaka Incrementaldari Jane Street, dan dibutuhkan beberapa trik serius untuk membuatnya berfungsi dengan baik. Sebelum menerapkan evaluasi malas, algoritme pengurutan topologis kami menggunakan heap untuk menentukan sel mana yang akan dihitung ulang selanjutnya. Tapi sekarang kami ingin menghitung ulang hanya sel-sel yang dibutuhkan. Bagaimana? Kami tidak ingin berjalan di seluruh pohon dari sel yang diamati seperti Adapton, karena perjalanan penuh melalui pohon menghancurkan seluruh tujuan jenis topologi dan memberi kami karakteristik kinerja yang mirip dengan Adapton.
Sebagai gantinya, Incremental mempertahankan satu set sel yang telah ditandai pengguna sebagai telah diawasi, serta sekumpulan sel yang diperlukan untuk setiap sel yang diawasi. Setiap kali sel ditandai sebagai dapat diamati atau tidak dapat diamati, Inkremental berjalan melalui dependensi sel tersebut untuk memastikan bahwa label yang diperlukan diterapkan dengan benar. Kemudian kami menambahkan sel ke heap penghitungan ulang hanya jika mereka ditandai sesuai kebutuhan. Dalam grafik burrito kami, selama itu
Total
adalah bagian dari himpunan yang dapat diamati, perubahan
Salsa in Order
tidak akan menghasilkan lintasan apa pun melalui grafik, karena hanya sel yang diperlukan yang dihitung ulang:

Ini menyelesaikan masalah kami tanpa berjalan cepat melalui grafik untuk menandai sel sebagai kotor! Kita harus tetap ingat sel itu
Salsa per Burrito
berantakan untuk diceritakan nanti jika perlu. Tetapi tidak seperti algoritme Adapton, kita tidak perlu mendorong label kotor tunggal itu ke seluruh grafik.
Jangkar, solusi hibrida
Baik Adapton dan Incremental melintasi grafik meskipun mereka tidak menghitung ulang sel. Inkremental berjalan menaiki grafik saat kumpulan sel yang diamati berubah, dan Adapton berjalan menuruni grafik saat rumus berubah. Dengan grafik kecil, mahalnya biaya pass ini mungkin tidak langsung terlihat. Tetapi jika grafiknya besar dan sel-selnya relatif murah untuk dihitung - sering kali ini terjadi pada spreadsheet - Anda akan menemukan bahwa sebagian besar penghitungan terbuang percuma karena berjalan-jalan di sekitar grafik yang tidak perlu! Ketika sel harganya murah, memberi tanda sedikit pada sel bisa biayanya hampir sama dengan menghitung ulang sel dari awal. Oleh karena itu, idealnya, jika kita ingin algoritme kita menjadi lebih cepat secara signifikan daripada penghitungan sederhana, kita harus menghindari berjalan-jalan di grafik sebanyak mungkin.
Semakin saya memikirkan masalah ini, semakin saya menyadari bahwa mereka membuang-buang waktu untuk melintasi grafik dalam situasi yang kira-kira berlawanan. Dalam grafik burrito kita, mari kita bayangkan rumus sel jarang berubah, tapi kita beralih dengan cepat, mengamati dulu
Total
dan kemudian
Salsa in Order
.
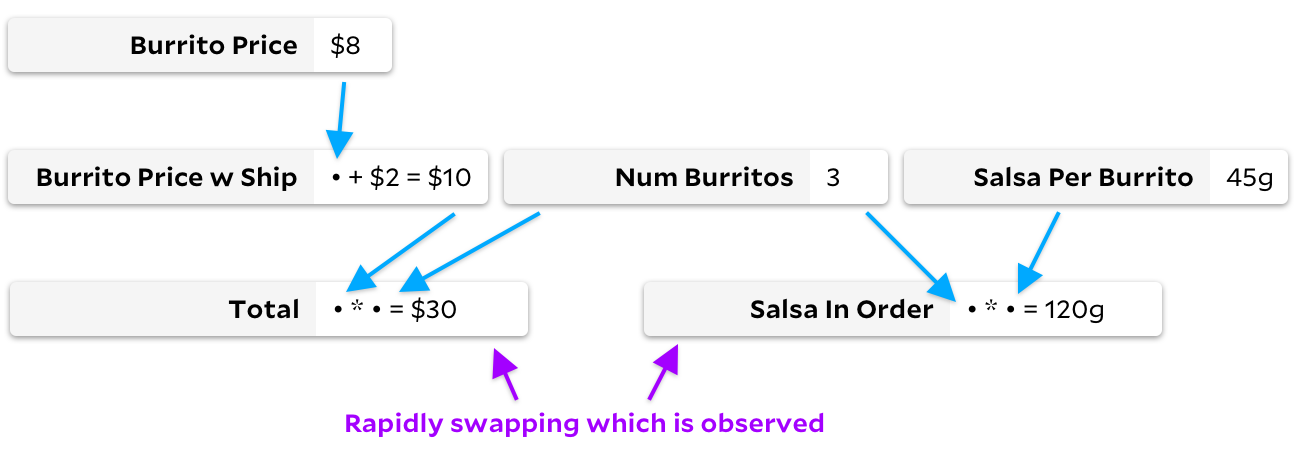
Dalam hal ini, Adapton tidak akan berjalan di pohon. Tidak ada data masukan yang berubah dan oleh karena itu kami tidak perlu menandai sel apa pun. Karena tidak ada yang ditandai, setiap observasi menjadi murah karena kita bisa langsung mengembalikan nilai yang di-cache dari sel kosong. Namun, Incremental tidak bekerja dengan baik dalam contoh ini. Meskipun tidak ada nilai yang dihitung ulang, Incremental akan berulang kali menandai dan menghapus centang banyak sel sesuai kebutuhan atau tidak perlu.
Jika tidak, bayangkan grafik di mana rumus kami berubah dengan cepat, tetapi kami tidak mengubah daftar sel yang diamati. Misalnya, kita mungkin membayangkan diri kita sedang menonton
Total
dengan mengubah harga burrito dengan cepat dari
4+4
menjadi
2*4
.
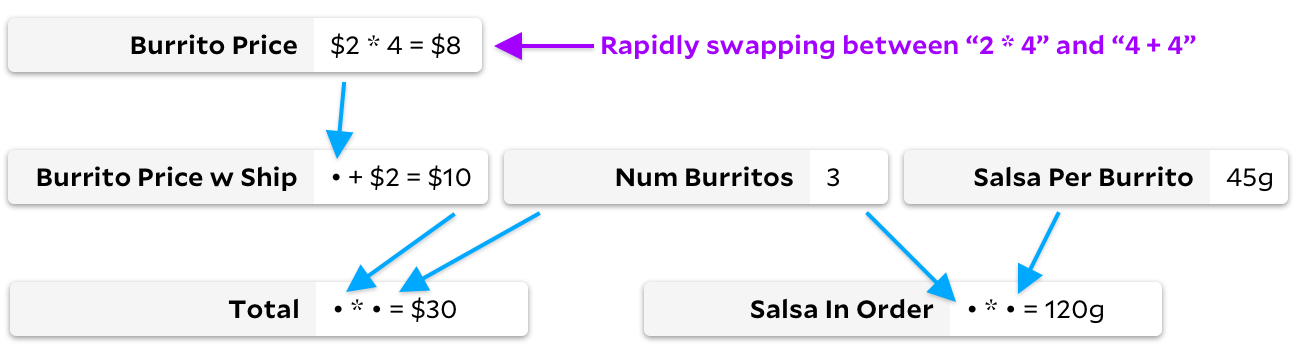
Seperti pada contoh sebelumnya, kami tidak benar-benar menghitung ulang banyak sel:
4+4
dan
2*4
sama dengan
8
, jadi idealnya kami hanya menghitung ulang aritmatika ini saat pengguna melakukan perubahan ini. Namun tidak seperti contoh sebelumnya, Incremental sekarang menghindari berjalan di pohon. Dengan Incremental, kami telah menyimpan fakta bahwa harga burrito adalah sel yang diperlukan, jadi jika berubah, kami dapat menghitung ulang tanpa melalui grafik. Dengan Adapton, kami membuang-buang waktu untuk menandai
Burrito Price w Ship
dan
Total
betapa berantakannya, meskipun hasilnya
Burrito Price
tidak berubah.
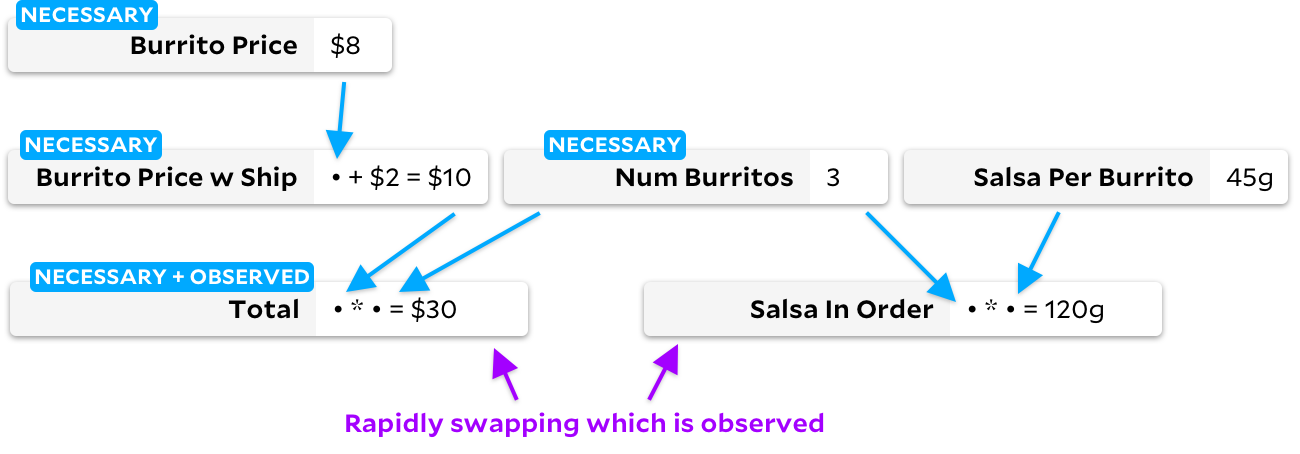
Mengingat bahwa setiap algoritme bekerja dengan baik dalam kasus-kasus yang merosot dari yang lain, mengapa tidak idealnya mendeteksi kasus-kasus yang merosot tersebut dan beralih ke algoritme yang lebih cepat? Inilah yang saya coba terapkan di perpustakaan saya sendiri Jangkar . Ini menjalankan kedua algoritma secara bersamaan pada grafik yang sama! Jika kedengarannya gila, tidak perlu, dan terlalu rumit, mungkin memang begitu.
Dalam banyak kasus, Anchor mengikuti algoritma Incremental dengan tepat, sehingga menghindari kasus Adapton yang merosot di atas. Tetapi ketika sel ditandai sebagai tidak dapat diamati, perilakunya sedikit berbeda. Mari kita lihat apa yang terjadi. Mari kita mulai dengan menandainya
Total
sebagai sel yang diamati:
Jika Anda kemudian menandainya
Total
sebagai sel yang tidak dapat diamati, dan
Salsa in Order
sebagai yang dapat diamati, algoritme Inkremental tradisional akan mengubah grafik, melalui semua sel dalam prosesnya:
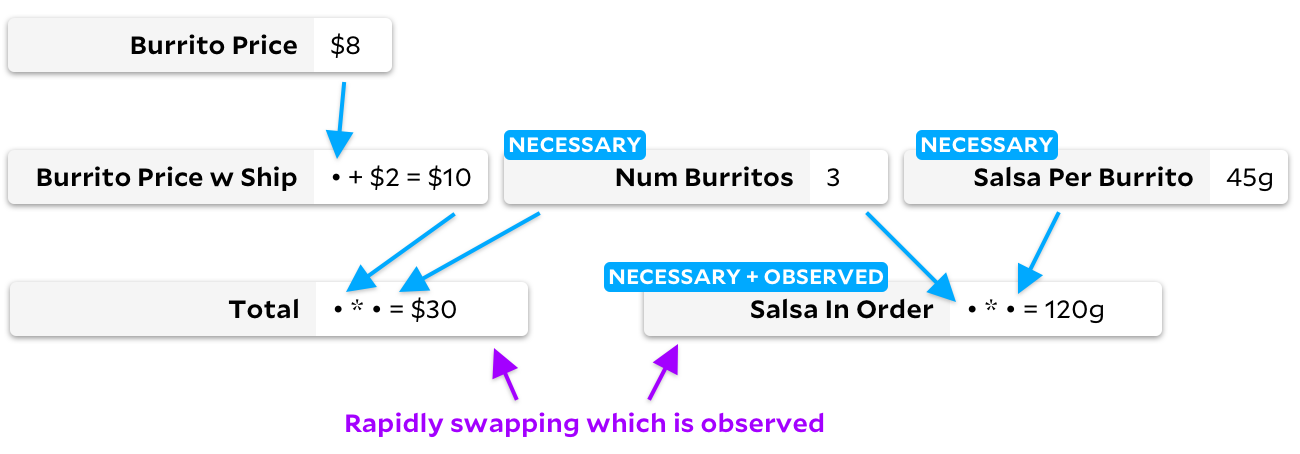
Jangkar untuk perubahan ini juga melintasi semua sel, tetapi membuat grafik lain:
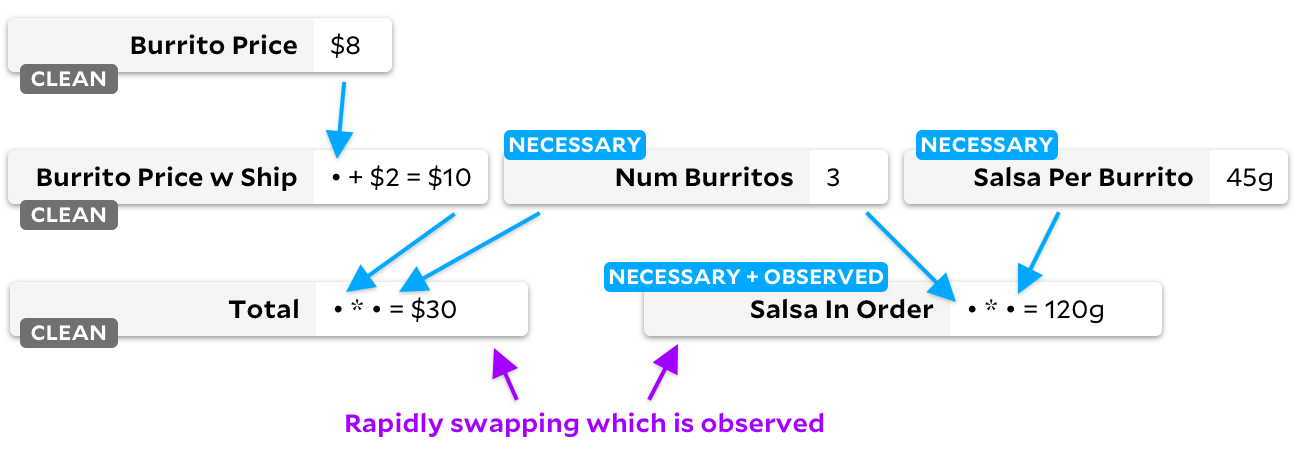
Perhatikan bendera sel "bersih"! Saat sel tidak lagi dibutuhkan, kami menandainya sebagai kosong. Mari kita lihat apa yang terjadi jika kita beralih dari pengamatan
Salsa in Order
ke
Total
:
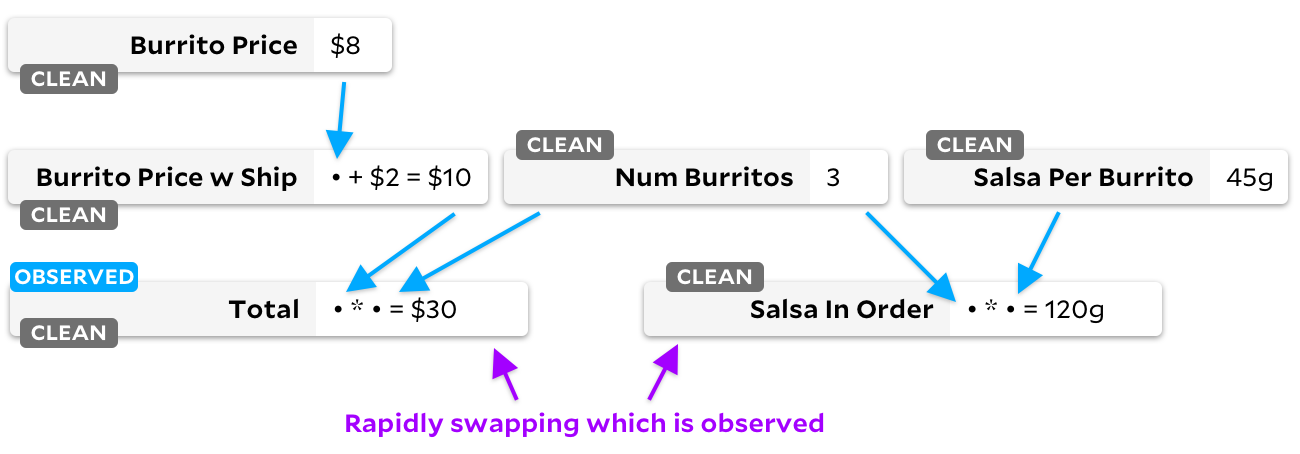
Kanan - grafik kita sekarang tidak memiliki sel yang "perlu". Jika sel memiliki bendera "bersih", kami tidak pernah menandainya sebagai dapat diamati. Mulai sekarang, tidak peduli sel mana yang kita tandai sebagai dapat diamati atau tidak dapat diamati, Penanda tidak akan pernah membuang waktu untuk berjalan di grafik - dia tahu bahwa tidak ada masukan yang berubah.
Sepertinya El Farolito telah mengumumkan diskon! Mari kita potong harga burrito satu dolar. Bagaimana Anchors tahu cara menghitung ulang jumlahnya? Sebelum penghitungan ulang apa pun, mari kita lihat bagaimana Jangkar melihat grafik segera setelah harga burrito berubah:

Jika sel memiliki bendera yang jelas, kami menjalankan algoritme Adapton tradisional di atasnya, dengan sukarela menandai sel hilir sebagai kotor. Ketika kita kemudian menjalankan algoritma Incremental, kita dapat dengan cepat mengetahui bahwa ada sel yang dapat diamati yang ditandai kotor, dan kita tahu bahwa kita perlu menghitung ulang ketergantungannya. Grafik terakhir akan terlihat seperti ini:
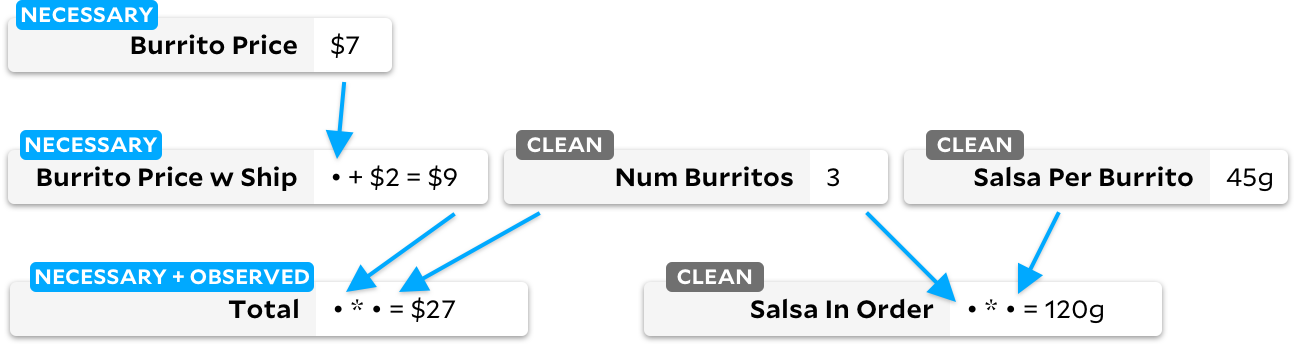
Kami menghitung ulang sel hanya jika diperlukan, jadi setiap kali kami menghitung ulang sel kotor, kami juga menandainya sesuai kebutuhan. Pada level tinggi, Anda dapat menganggap ketiga status sel ini sebagai mesin status siklik:

Pada sel yang diperlukan, jalankan algoritme pengurutan topologis inkremental. Selebihnya, kami menjalankan algoritma Adapton.
Sintaks Burrito
Sebagai kesimpulan, saya ingin menjawab pertanyaan terakhir: sejauh ini, kita telah membahas banyak masalah yang disebabkan oleh model malas untuk strategi penghitungan ulang tabel kita. Tetapi masalahnya tidak hanya pada algoritma: ada juga masalah sintaksis. Sebagai contoh, mari buat tabel untuk memilih burrito emoji untuk klien kita. Kami ingin menulis pernyataan
IF
dalam tabel seperti ini:

Karena spreadsheet tradisional tidak malas, kami dapat menghitung
B1
,
B2
dan
B3
dalam urutan apa pun, lalu menghitung sel
IF
... Namun, di dunia malas, jika kita dapat menghitung nilai B1 terlebih dahulu, kita dapat melihat hasilnya untuk mengetahui nilai mana yang perlu dihitung ulang - B2 atau B3. Sayangnya, spreadsheet tradisional
IF
tidak dapat mengungkapkan ini!
Masalah:
B2
secara bersamaan mereferensikan sel
B2
dan mengambil nilainya. Sebagian besar pustaka malas yang disebutkan dalam artikel malah secara eksplisit membedakan antara referensi sel dan tindakan mengambil nilai sebenarnya. Di Jangkar kita menyebut jangkar referensi sel ini. Sama seperti dalam kehidupan nyata, burrito membungkus banyak bahan menjadi satu, satu jenis
Anchor<T>
membungkus
T
. Jadi saya rasa sel burrito vegan kita menjadi
Anchor<Burrito>
, semacam burrito burrito yang konyol. Fungsi dapat mentransfer milik kita
Anchor<Burrito>
sebanyak yang mereka inginkan. Tetapi ketika mereka benar-benar membuka burrito untuk mengakses bagian
Burrito
dalamnya, kami membuat tepi ketergantungan di grafik kami, yang menunjukkan ke algoritme penghitungan ulang bahwa sel tersebut mungkin diperlukan dan perlu penghitungan ulang.
Pendekatan yang diambil oleh Salsa dan Adapton adalah dengan menggunakan pemanggilan fungsi dan aliran kontrol normal sebagai cara untuk memperluas nilai-nilai ini. Misalnya, di Adapton, kita dapat menulis sel Burrito untuk Pelanggan seperti ini:
let burrito_for_customer = cell!({
if get!(is_vegetarian) {
get!(vegi_burrito)
} else {
get!(meat_burrito)
}
});
Dengan membedakan antara referensi sel (di sini
vegi_burrito
) dan tindakan memperluas nilainya (
get!
), Adapton dapat berjalan di atas pernyataan aliran kontrol Rust seperti
if
. Ini adalah solusi yang bagus! Namun, dibutuhkan sedikit status global ajaib untuk menyambungkan panggilan
get!
ke sel dengan benar
cell!
saat berubah
is_vegetarian
. Pustaka Jangkar yang dipengaruhi Inkremental menggunakan pendekatan yang tidak terlalu ajaib. Seperti async-pre / await
Future
, Anchors memungkinkan peluncuran
Anchor<T>
operasi seperti
map
dan
then
. Jadi, contoh di atas akan terlihat seperti ini:
let burrito_for_customer: Anchor<Burrito> = is_vegetarian.then(|is_vegetarian: bool| -> Anchor<Burrito> {
if is_vegetarian {
vegi_burrito
} else {
meat_burrito
}
});
Bacaan lebih lanjut
Dalam artikel yang sudah panjang dan berbunga-bunga ini, tidak ada cukup ruang untuk begitu banyak topik. Semoga sumber daya ini dapat menjelaskan lebih banyak tentang masalah yang sangat menarik ini.
- Tujuh implementasi Incremental , tampilan mendalam yang bagus pada internal Incremental, serta sekumpulan pengoptimalan seperti ketinggian yang terus meningkat yang tidak sempat saya bicarakan, ditambah cara cerdas untuk menangani sel pengubah ketergantungan. Juga layak dibaca dari Ron Minsky: FRP Parsing .
- Video yang menjelaskan cara kerja Salsa.
- Ini adalah tiket Salsa di mana Matthew Hammer, pencipta Adapton, dengan sabar menjelaskan batasan tersebut kepada beberapa pejalan kaki acak (saya) yang tidak tahu cara kerjanya.
- Rustlab . , « » «: DX CS» — .
- , « », Materialize. , . , (!) « », , . Noira .
- Adapton .
- Ternyata cara berpikir ini juga berlaku untuk membangun sistem . Ini adalah salah satu artikel ilmiah pertama tentang kesamaan antara sistem build dan spreadsheet.
- Tracing Sinar Sedikit Inkremental adalah pelacak sinar sedikit tambahan yang ditulis dalam Ocaml.
- Baru saja melihat "Keadaan Parsial dalam Tampilan Terwujud Berdasarkan Aliran Data" dan tampaknya relevan.
- Lewati dan Imp juga terlihat sangat menarik.
Dan tentu saja, Anda selalu dapat memeriksa kerangka Jangkar saya .