Analisis teknikal grafik saham ini didasarkan pada hipotesis adanya pola berulang, pola yang dapat mendatangkan keuntungan. Kami melihat dua lilin hitam dan tiga lilin putih dalam urutan tertentu - buka dan dapatkan uang. Tetapi untuk beberapa alasan hanya ada sedikit informasi (atau tidak ada sama sekali) tentang bukti hipotesis ini dan bagaimana dan atas dasar apa yang secara umum dibentuk. Itu. berapa kali pada data historis angka ini atau itu telah bekerja sebagaimana mestinya. Di mana dan siapa yang memutuskan bahwa ada segitiga jatuh, terowongan, kepala dengan bahu, dll. Siapa yang memeriksa profitabilitas mereka pada kuotasi yang terakumulasi selama seluruh keberadaan bursa? Mengapa tidak dua garis sejajar dan paralelepiped atau lingkaran dengan oval? Kami akan berbicara tentang bukti ini di artikel ini, yaitu jalankan skrip python untuk menemukan pola,kami memperoleh data historis dengan menyalin grafik dari ruangan.
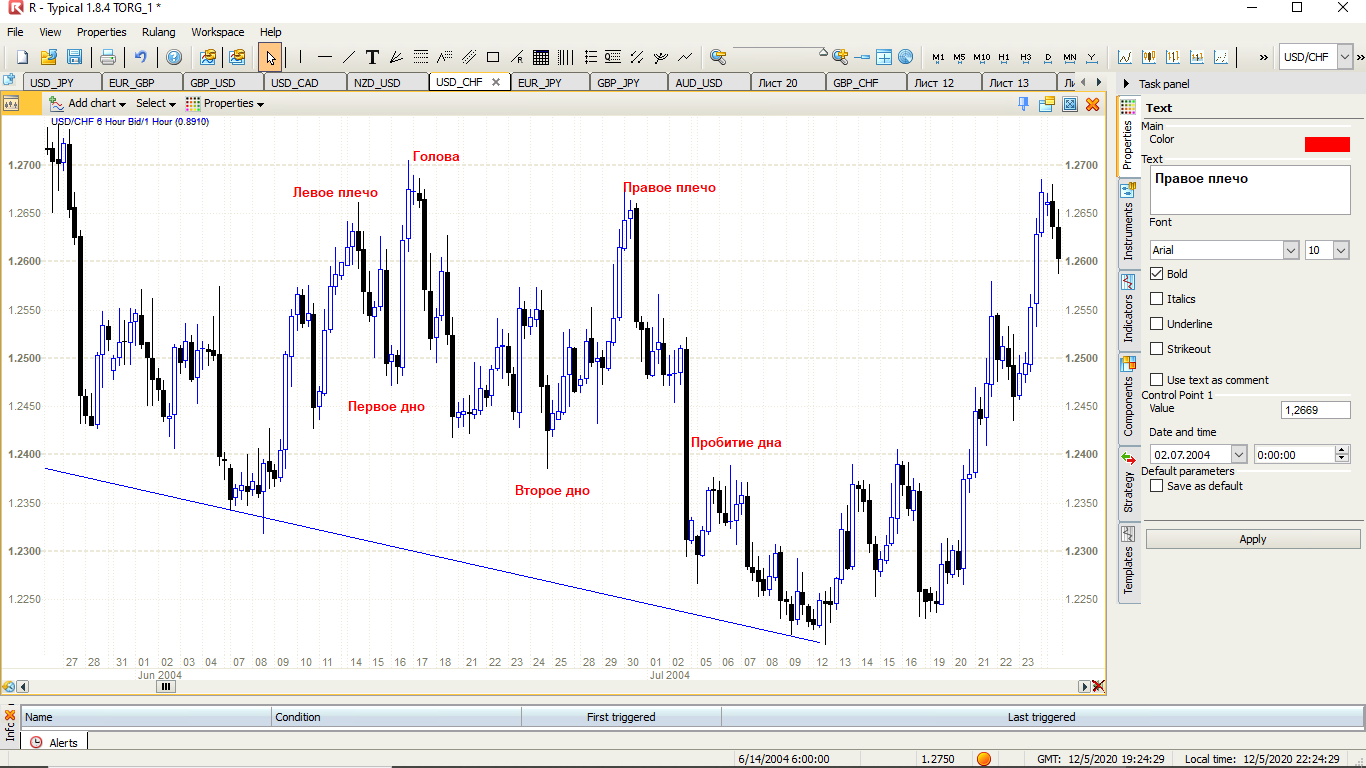
Mari kita mulai dengan salah satu pola paling populer - head and shoulders pada grafik 6 jam untuk 10 pasangan mata uang.
Diperlukan untuk membawa statistik ke dalam format DataFrame (ini adalah kutipan dari akhir, data pada 10 pasangan mata uang rata-rata 6 jam sejak 2005 akan memakan waktu sekitar 160 ribu baris)
|
|
WAKTU |
BUKA |
TINGGI |
RENDAH |
MENUTUP |
JUDUL |
|---|---|---|---|---|---|
16/09/19 06:00:00 |
1.3213 |
1.3234 |
1.3211 |
1.3232 |
USD_CAD_6H |
16/09/19 12:00:00 |
1.3230 |
1.3265 |
1.3228 |
1.3257 |
USD_CAD_6H |
16/09/19 18:00:00 |
1.3255 |
1.3270 |
1.3231 |
1.3247 |
USD_CAD_6H |
17/09/19 00:00:00 |
1.3248 |
1.3249 |
1.3232 |
1.3239 |
USD_CAD_6H |
17/09/19 06:00:00 |
1.3238 |
1.3253 |
1.3237 |
1.3247 |
USD_CAD_6H |
17/09/19 12:00:00 |
1.3249 |
1.3259 |
1.3240 |
1.3255 |
USD_CAD_6H |
17/09/19 18:00:00 |
1.3256 |
1.3298 |
1.3231 |
1.3247 |
USD_CAD_6H |
18/09/19 00:00:00 |
1.3245 |
1.3252 |
1.3237 |
1.3239 |
USD_CAD_6H |
18/09/19 06:00:00 |
1.3240 |
1.3258 |
1.3238 |
1.3254 |
USD_CAD_6H |
18/09/19 12:00:00 |
1.3252 |
1.3270 |
1.3249 |
1.3250 |
USD_CAD_6H |
18/09/19 18:00:00 |
1.3252 |
1.3285 |
1.3238 |
1.3273 |
USD_CAD_6H |
19/09/19 00:00:00 |
1.3277 |
1.3308 |
1.3267 |
1.3295 |
USD_CAD_6H |
19/09/19 06:00:00 |
1.3297 |
1.3305 |
1.3279 |
1.3282 |
USD_CAD_6H |
19/09/19 12:00:00 |
1.3281 |
1.3292 |
1.3272 |
1.3273 |
USD_CAD_6H |
19/09/19 18:00:00 |
1.3274 |
1.3279 |
1.3238 |
1.3243 |
USD_CAD_6H |
20/09/19 00:00:00 |
1.3244 |
1.3268 |
1.3242 |
1.3257 |
USD_CAD_6H |
20/09/19 06:00:00 |
1.3259 |
1.3271 |
1.3256 |
1.3266 |
USD_CAD_6H |
20/09/19 12:00:00 |
1.3265 |
1.3275 |
1.3256 |
1.3264 |
USD_CAD_6H |
20/09/19 18:00:00 |
1.3262 |
1.3299 |
1.3254 |
1.3255 |
USD_CAD_6H |
21/09/19 00:00:00 |
1.3253 |
1.3278 |
1.3251 |
1.3261 |
USD_CAD_6H |
. , , .. , , .. , , , , , .. , . , , , , - … , "" , .. . . , , ( ). , , .. , , - H&S ( ).
#,
list_H_AND_S=[]
# ( , , )
list_NOT_H_AND_S=[]
for i in range(600,len(df_ALL['CLOSE'])-600):
# , ..
if max(df_ALL['HIGH'][i-30:i+15])==df_ALL['HIGH'][i]:
# 15,
for z in range (15,200,15):
left_shoulder=max(df_ALL['HIGH'][i-30:i+15])
#
left_shoulder_index=df_ALL['HIGH'][i-30:i+15].idxmax()
# ,
if max(df_ALL['HIGH'][df_ALL['LOW'][left_shoulder_index:left_shoulder_index+z+1].idxmin():left_shoulder_index+z+1])>left_shoulder and\
(left_shoulder-min(df_ALL['LOW'][left_shoulder_index:left_shoulder_index+z+1]))/((max(df_ALL['HIGH'][df_ALL['LOW'][left_shoulder_index:left_shoulder_index+z+1].idxmin():left_shoulder_index+z+1])-min(df_ALL['LOW'][left_shoulder_index:left_shoulder_index+z+1])))>=0.6:
head=max(df_ALL['HIGH'][df_ALL['LOW'][left_shoulder_index:left_shoulder_index+z+1].idxmin():left_shoulder_index+z+1])
#
head_index=df_ALL['HIGH'][df_ALL['LOW'][left_shoulder_index:left_shoulder_index+z+1].idxmin():left_shoulder_index+z+1].idxmax()
for b in range (15,200,15):
# , ..
first_bottom= min(df_ALL['LOW'][left_shoulder_index:head_index+1])
# 1-
first_bottom_index=df_ALL['LOW'][left_shoulder_index:head_index+1].idxmin()
#
if min(df_ALL['LOW'][head_index:head_index+b])<first_bottom and \
(head-first_bottom)/(head-min(df_ALL['LOW'][head_index:head_index+b]))>=0.5:
second_bottom= min(df_ALL['LOW'][head_index:head_index+b])
# 2-
second_bottom_index=df_ALL['LOW'][head_index:head_index+b].idxmin()
for o in range(2,300):
# max(df_ALL['HIGH'][second_bottom_index:second_bottom_index+o+1]) -
if max(df_ALL['HIGH'][second_bottom_index:second_bottom_index+o+1])>=left_shoulder and \
max(df_ALL['HIGH'][second_bottom_index:second_bottom_index+o+1])<head and \
second_bottom_index+o-df_ALL['HIGH'][second_bottom_index:second_bottom_index+o+1].idxmax()>0 and \
(second_bottom_index+o+1)-df_ALL['LOW'][df_ALL['HIGH'][second_bottom_index:second_bottom_index+o+1].idxmax()]>2 and \
min(df_ALL['LOW'][df_ALL['HIGH'][second_bottom_index:second_bottom_index+o+1].idxmax():second_bottom_index+o+1])==df_ALL['LOW'][second_bottom_index+o] and \
min(df_ALL['LOW'][df_ALL['HIGH'][second_bottom_index:second_bottom_index+o+1].idxmax():second_bottom_index+o])>second_bottom and \
df_ALL['CLOSE'][second_bottom_index+o]<second_bottom and \
min(df_ALL['LOW'][second_bottom_index:df_ALL['HIGH'][second_bottom_index:second_bottom_index+o+1].idxmax()+1])==second_bottom and \
min(df_ALL['LOW'][left_shoulder_index:head_index])==first_bottom and \
max(df_ALL['HIGH'][first_bottom_index:second_bottom_index+1])==head and \
df_ALL['CLOSE'][second_bottom_index+o]-df_ALL['OPEN'][second_bottom_index+o]<=0:
# , H$S
for x in range (2,300):
# ,
# , (- )*2. ,
# -
if max(df_ALL['HIGH'][second_bottom_index+o:second_bottom_index+o+x+1])<=max(df_ALL['HIGH'][second_bottom_index:second_bottom_index+o+1]) and \
min(df_ALL['LOW'][second_bottom_index+o:second_bottom_index+o+x+1])<=second_bottom-(head-second_bottom)*2:
if (df_ALL['TIME'][left_shoulder_index]+' '+ df_ALL['TIME'][head_index]+' '+df_ALL['TIME'][second_bottom_index]+' '+df_ALL['TIME'][second_bottom_index+o]+' '+df_ALL['TITLE'][i]+' '+df_ALL['TITLE'][second_bottom_index+o]+' '+str(df_ALL['CLOSE'][o+second_bottom_index]-df_ALL['OPEN'][o+second_bottom_index])) not in list_H_AND_S:
list_H_AND_S.append(df_ALL['TIME'][left_shoulder_index]+' '+ df_ALL['TIME'][head_index]+' '+df_ALL['TIME'][second_bottom_index]+' '+df_ALL['TIME'][second_bottom_index+o]+' '+df_ALL['TITLE'][i]+' '+df_ALL['TITLE'][second_bottom_index+o]+' '+str(df_ALL['CLOSE'][o+second_bottom_index]-df_ALL['OPEN'][o+second_bottom_index]))
elif max(df_ALL['HIGH'][second_bottom_index+o:second_bottom_index+o+x+1])>max(df_ALL['HIGH'][second_bottom_index:second_bottom_index+o+1]) and \
min(df_ALL['LOW'][second_bottom_index+o:second_bottom_index+o+x+1])>first_bottom-(head-second_bottom):
if (df_ALL['TIME'][left_shoulder_index]+' '+ df_ALL['TIME'][head_index]+' '+df_ALL['TIME'][second_bottom_index]+' '+df_ALL['TIME'][second_bottom_index+o]+' '+df_ALL['TITLE'][i]+' '+df_ALL['TITLE'][second_bottom_index+o]+' '+str(df_ALL['CLOSE'][o+second_bottom_index]-df_ALL['OPEN'][o+second_bottom_index])) not in list_NOT_H_AND_S and \
(df_ALL['TIME'][left_shoulder_index]+' '+ df_ALL['TIME'][head_index]+' '+df_ALL['TIME'][second_bottom_index]+' '+df_ALL['TIME'][second_bottom_index+o]+' '+df_ALL['TITLE'][i]+' '+df_ALL['TITLE'][second_bottom_index+o]+' '+str(df_ALL['CLOSE'][o+second_bottom_index]-df_ALL['OPEN'][o+second_bottom_index])) not in list_H_AND_S:
list_NOT_H_AND_S.append(df_ALL['TIME'][left_shoulder_index]+' '+ df_ALL['TIME'][head_index]+' '+df_ALL['TIME'][second_bottom_index]+' '+df_ALL['TIME'][second_bottom_index+o]+' '+df_ALL['TITLE'][i]+' '+df_ALL['TITLE'][second_bottom_index+o]+' '+str(df_ALL['CLOSE'][o+second_bottom_index]-df_ALL['OPEN'][o+second_bottom_index]))
len(list_H_AND_S),len(list_NOT_H_AND_S)
1/6 ( ), ( -) , . . , , , - H&S , …
(/)
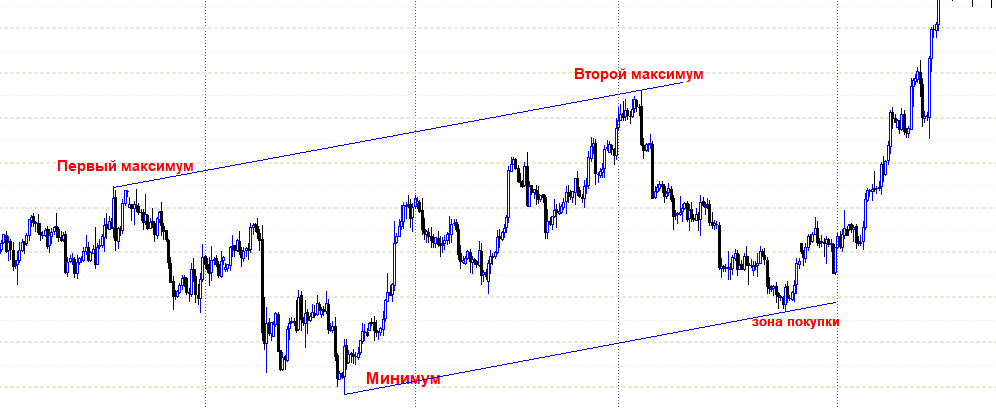
, , . 1 10, . ,
#
list_vimpel=[]
#
list_NOT_vimpel=[]
for i in range(600,len(df_ALL['CLOSE'])-1000):
if max(df_ALL['HIGH'][i-15:i+15])==df_ALL['HIGH'][i]:
for z in range (15,300,15):
#
first_max=max(df_ALL['HIGH'][i-15:i+15])
# 1-
first_max_index=df_ALL['HIGH'][i-15:i+15].idxmax()
if (first_max-min(df_ALL['LOW'][first_max_index:first_max_index+z+1]))>0 and \
max(df_ALL['HIGH'][df_ALL['LOW'][first_max_index:first_max_index+z+1].idxmin():first_max_index+z+1])>first_max and \
(max(df_ALL['HIGH'][df_ALL['LOW'][first_max_index:first_max_index+z+1].idxmin():first_max_index+z+1])-min(df_ALL['LOW'][first_max_index:first_max_index+z+1]))/(first_max-min(df_ALL['LOW'][first_max_index:first_max_index+z+1]))<=2.2 and \
(max(df_ALL['HIGH'][df_ALL['LOW'][first_max_index:first_max_index+z+1].idxmin():first_max_index+z+1])-min(df_ALL['LOW'][first_max_index:first_max_index+z+1]))/(first_max-min(df_ALL['LOW'][first_max_index:first_max_index+z+1]))>=1.3:
second_max=max(df_ALL['HIGH'][df_ALL['LOW'][first_max_index:first_max_index+z+1].idxmin():first_max_index+z+1])
second_max_index=df_ALL['HIGH'][df_ALL['LOW'][first_max_index:first_max_index+z+1].idxmin():first_max_index+z+1].idxmax()
# ,
first_min= min(df_ALL['LOW'][first_max_index:second_max_index+1])
# 1-
first_min_index=df_ALL['LOW'][first_max_index:second_max_index+1].idxmin()
for o in range(2,300):
if (second_max_index-first_min_index)>=25 and \
min(df_ALL['LOW'][second_max_index:second_max_index+o+1])==df_ALL['LOW'][o+second_max_index] and \
df_ALL['LOW'][o+second_max_index]>first_min and \
df_ALL['HIGH'][o+second_max_index]<second_max and \
(second_max_index-first_min_index)>=25 and \
max(df_ALL['HIGH'][first_min_index:o+second_max_index+1])==second_max and \
min(df_ALL['LOW'][first_min_index:second_max_index+1])==df_ALL['LOW'][first_min_index] and \
max(df_ALL['HIGH'][first_max_index:first_min_index+1])==first_max and \
(o+second_max_index)-second_max_index>=16 and \
df_ALL['LOW'][o+second_max_index]<=(first_min+((second_max-first_max)*(((o+second_max_index)-first_min_index)/(second_max_index-first_max_index)))) and \
df_ALL['CLOSE'][o+second_max_index]>=(first_min+((second_max-first_max)*(((o+second_max_index)-first_min_index)/(second_max_index-first_max_index)))):
for x in range (2,300):
if min(df_ALL['LOW'][o+second_max_index:o+second_max_index+x+1])==df_ALL['LOW'][o+second_max_index] and \
max(df_ALL['HIGH'][o+second_max_index:o+second_max_index+x+1])>=second_max:
if (df_ALL['TIME'][first_max_index]+' '+ df_ALL['TIME'][second_max_index]+' '+df_ALL['TIME'][second_max_index+o]+' '+df_ALL['TITLE'][i]+' '+df_ALL['TITLE'][second_max_index+o]+' '+str(df_ALL['CLOSE'][o+second_max_index]-df_ALL['OPEN'][o+second_max_index])+' '+str((second_max-first_min)/(first_max-first_min))+' '+str((second_max_index-first_min_index)/(first_min_index-first_max_index))+' '+str(((second_max-first_min)/(first_max-first_min))/((second_max-df_ALL['LOW'][o+second_max_index])/(second_max-first_min)))+' '+str(df_ALL['WeekDay'][o+second_max_index])+' '+str((second_max_index-first_max_index)/((o+second_max_index)-second_max_index))) not in list_vimpel:
list_vimpel.append(df_ALL['TIME'][first_max_index]+' '+ df_ALL['TIME'][second_max_index]+' '+df_ALL['TIME'][second_max_index+o]+' '+df_ALL['TITLE'][i]+' '+df_ALL['TITLE'][second_max_index+o]+' '+str(df_ALL['CLOSE'][o+second_max_index]-df_ALL['OPEN'][o+second_max_index])+' '+str((second_max-first_min)/(first_max-first_min))+' '+str((second_max_index-first_min_index)/(first_min_index-first_max_index))+' '+str(((second_max-first_min)/(first_max-first_min))/((second_max-df_ALL['LOW'][o+second_max_index])/(second_max-first_min)))+' '+str(df_ALL['WeekDay'][o+second_max_index])+' '+str((second_max_index-first_max_index)/((o+second_max_index)-second_max_index)))
elif min(df_ALL['LOW'][o+second_max_index:o+second_max_index+x+1])<df_ALL['LOW'][o+second_max_index] and \
max(df_ALL['HIGH'][o+second_max_index:o+second_max_index+x+1])<second_max:
if (df_ALL['TIME'][first_max_index]+' '+ df_ALL['TIME'][second_max_index]+' '+df_ALL['TIME'][second_max_index+o]+' '+df_ALL['TITLE'][i]+' '+df_ALL['TITLE'][second_max_index+o]+' '+str(df_ALL['CLOSE'][o+second_max_index]-df_ALL['OPEN'][o+second_max_index])+' '+str((second_max-first_min)/(first_max-first_min))+' '+str((second_max_index-first_min_index)/(first_min_index-first_max_index))+' '+str(((second_max-first_min)/(first_max-first_min))/((second_max-df_ALL['LOW'][o+second_max_index])/(second_max-first_min)))+' '+str(df_ALL['WeekDay'][o+second_max_index])+' '+str((second_max_index-first_max_index)/((o+second_max_index)-second_max_index))) not in list_NOT_vimpel and \
(df_ALL['TIME'][first_max_index]+' '+ df_ALL['TIME'][second_max_index]+' '+df_ALL['TIME'][second_max_index+o]+' '+df_ALL['TITLE'][i]+' '+df_ALL['TITLE'][second_max_index+o]+' '+str(df_ALL['CLOSE'][o+second_max_index]-df_ALL['OPEN'][o+second_max_index])+' '+str((second_max-first_min)/(first_max-first_min))+' '+str((second_max_index-first_min_index)/(first_min_index-first_max_index))+' '+str(((second_max-first_min)/(first_max-first_min))/((second_max-df_ALL['LOW'][o+second_max_index])/(second_max-first_min)))+' '+str(df_ALL['WeekDay'][o+second_max_index])+' '+str((second_max_index-first_max_index)/((o+second_max_index)-second_max_index))) not in list_vimpel:
list_NOT_vimpel.append(df_ALL['TIME'][first_max_index]+' '+ df_ALL['TIME'][second_max_index]+' '+df_ALL['TIME'][second_max_index+o]+' '+df_ALL['TITLE'][i]+' '+df_ALL['TITLE'][second_max_index+o]+' '+str(df_ALL['CLOSE'][o+second_max_index]-df_ALL['OPEN'][o+second_max_index])+' '+str((second_max-first_min)/(first_max-first_min))+' '+str((second_max_index-first_min_index)/(first_min_index-first_max_index))+' '+str(((second_max-first_min)/(first_max-first_min))/((second_max-df_ALL['LOW'][o+second_max_index])/(second_max-first_min)))+' '+str(df_ALL['WeekDay'][o+second_max_index])+' '+str((second_max_index-first_max_index)/((o+second_max_index)-second_max_index)))
len(list_vimpel),len(list_NOT_vimpel)
Tujuan artikel ini bukan untuk mengurangi analisis teknis menjadi teori-semu, melainkan untuk menunjukkan sifat tidak ilmiah dari banyak artikel dan buku teks yang mengklaim bahwa pola populer berfungsi karena kurangnya jawaban untuk pertanyaan utama - mengapa kombinasi lilin ini berfungsi? Darimana informasi ini berasal? Berdasarkan pengalaman pribadi, bagaimana kepercayaan pada pencipta terbukti dalam Scientology sebagai sains? Mungkin seseorang menemukan (bukan tanpa bukti, tentu saja) pola yang setidaknya menghasilkan keuntungan, seperti yang mereka katakan, tulis di komentar. Pendapat perwakilan dari lingkungan pertukaran sangat diterima. Terima kasih atas perhatiannya!
PS Penulis memahami bahwa kode mungkin tidak ditulis dengan sempurna, tidak dioptimalkan, dll.