
Mari panaskan pelat logam pada GPU
Semua orang tahu bahwa Python tidak bersinar dengan kecepatan dengan sendirinya. Menurut pendapat saya, bahasa ini sangat baik dalam keterbacaannya, tetapi ceruk utama penggunaannya adalah di mana Anda menunggu sebagian besar waktu untuk beberapa input / output data. Sesuai ketentuan, Anda dapat menulis kode berkinerja super di Rust atau C, tetapi 99% waktunya akan menunggu.
Namun, Python juga bagus sebagai perekat sintaksis tingkat tinggi. Dalam hal ini, bagiannya yang ditafsirkan dengan santai memanggil kode berkecepatan tinggi yang ditulis dalam bahasa pemrograman terkompilasi. Biasanya, perpustakaan tradisional seperti NumPy digunakan untuk ini.
Tapi kita akan melangkah lebih jauh, mencoba memparalelkan komputasi di CUDA dan menggunakan hybrid C ++, stdpar, dan compiler nvc ++ yang aneh namun berfungsi dari Nvidia. Nah, pada saat yang sama, mari kita coba mengevaluasi kinerjanya. Mari kita ambil dua masalah: nomor urut dan metode Jacobi, yang akan kita gunakan untuk menghitung pemanasan pelat logam.
Memanggil C ++ dari Python
Kode pengurutan kami akan terlihat seperti ini:
# distutils: language=c++
from libcpp.algorithm cimport sort
def cppsort(int[:] x):
sort(&x[0], &x[-1] + 1)
Di baris pertama, kami secara eksplisit menunjukkan bahwa Cython harus menggunakan C ++, dan bukan default C. Di baris kedua, kami mengimpor fungsi sortir dari C ++, dan kemudian logikanya sendiri mengikuti. Tempatkan kode di file cppsort.pyx. Perhatikan bahwa ekstensi berbeda dari py biasa karena kami akan mengkompilasinya atau menjalankan cythonize dalam terminologi Cython.
Kompilasi dapat dilakukan secara manual atau disertakan dalam setup.py, di mana kami menjelaskan secara lengkap persiapan lingkungan kami.
Di setup.py, terlihat seperti ini:
from setuptools import setup
from Cython.Build import cythonize
setup(
ext_modules = cythonize("cppsort.pyx")
)
Tapi kita bisa melakukan ini di baris perintah:
cythonize -i cppsort.pyx
Di bawah tenda, hal seperti ini akan terjadi:

- Cython akan menerjemahkan kode python ke C ++ dan menghasilkan cppsort.cpp yang valid.
- Compiler C ++ (dalam hal ini g ++) mengkompilasi kode C ++ ke dalam modul ekstensi Python
- Modul ekstensi Python diimpor ke dalam kode sebagai modul Python biasa.
Setelah kompilasi, kita dapat mengimpor dan segera menguji pengurutan:
from cppsort import cppsort
import numpy as np
x = np.array([4, 3, 2, 1], dtype="int32")
print(x)
cppsort(x)
print(x)
Array [4, 3, 2, 1] berhasil diurutkan ke [1, 2, 3, 4] menggunakan C ++ std :: sort.
Ayo pergi ke GPU?
Algoritme pustaka standar C ++ dapat dipanggil dengan argumen kebijakan eksekusi paralel . Argumen ini memberi tahu kompiler bahwa Anda ingin membagi algoritme menjadi proses paralel.
Karena itu, C ++ memiliki beberapa opsi untuk kebijakan ini:
- std :: execution :: seq: Eksekusi berurutan. Paralelisme dilarang.
- std :: execution :: unseq: Eksekusi vectorized dalam thread pemanggil.
- std :: execution :: par: Eksekusi paralel pada satu atau lebih utas.
- std :: execution :: par_unseq: Eksekusi paralel pada satu atau lebih utas. Setiap aliran akan di-vektorisasi jika memungkinkan.
Dalam hal ini, Anda sendiri harus memantau kondisi balapan dan kebuntuan. Kompiler g ++ standar akan mencoba mendistribusikan komputasi ke seluruh inti CPU. Tetapi kita dapat mengambil kompilator berpemilik dari Nvidia - nvc ++ dan memberinya opsi "-stdpar". stdpar adalah Paralelisme Standar C ++ Nvidia dengan eksekusi kode paralel pada GPU.
Mari tulis ulang kode tersebut, dengan mempertimbangkan kebutuhan untuk membuat salinan lokal dari array, karena GPU tidak akan dapat mengakses array yang terletak di dalam NumPy.
from libcpp.algorithm cimport sort, copy_n
from libcpp.vector cimport vector
from libcpp.execution cimport par
def cppsort(int[:] x):
cdef vector[int] temp
temp.resize(len(x))
copy_n(&x[0], len(x), temp.begin())
sort(par, temp.begin(), temp.end())
copy_n(temp.begin(), len(x), &x[0])

Sekarang ini perlu dikompilasi lagi, tetapi menggunakan nvc ++. Kali ini, mari kita tulis setup.py normal dan menyebutnya:
CC=nvc++ python setup.py build_ext --inplace
Kami mengimpor ke dalam kode dan mencoba memanggil:
x = np.array([4, 3, 2, 1], dtype="int32")
cppsort(x) # GPU
Performa
Secara tradisional, GPU bagus di mana ada banyak jenis komputasi ringan yang sama. Tugas berat, tugas GPU tunggal tidak akan berfungsi. Selain itu, perlu mempertimbangkan volume data Anda. Jika Anda memiliki sedikit data, maka Anda akan mendapatkan overhead yang besar untuk proses paralelisasi, I / O antara CPU dan GPU. Akibatnya, kode tersebut kemungkinan besar akan berjalan paling efisien pada CPU kosong, terkadang bahkan dalam satu inti, jika hanya ada sedikit data. Tetapi pada array besar, GPU pasti akan unggul.
Ada perbandingan yang bagus dalam mengurutkan di sini. Kecepatan NumPy diambil sebagai satu unit, dan kemudian kelipatan peningkatan kecepatan dalam setiap metode dihitung relatif terhadapnya.
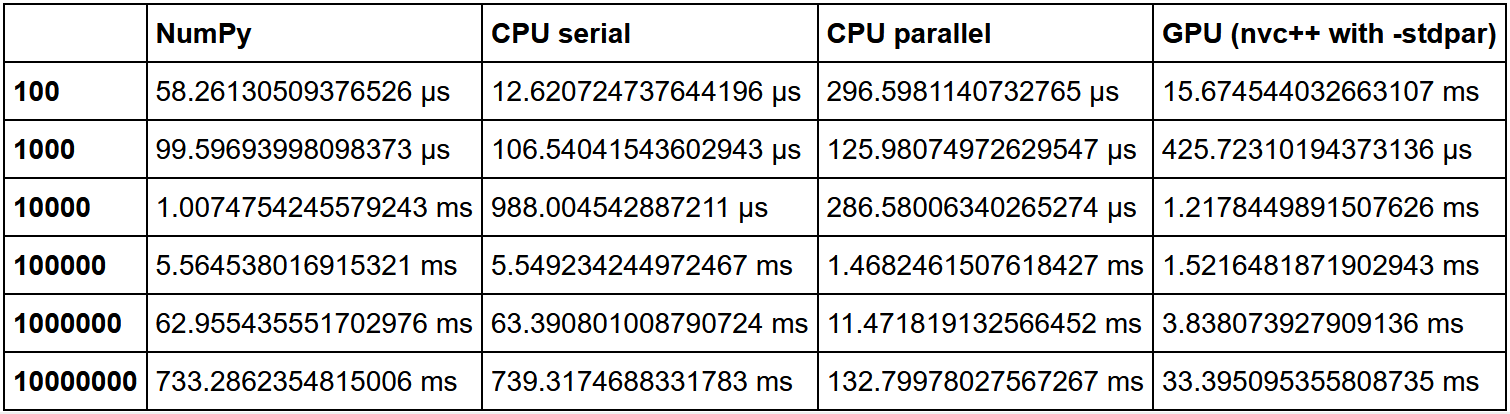
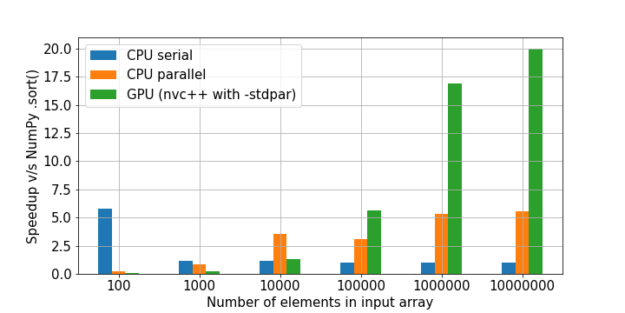
Seperti yang dapat kita lihat, hipotesis bahwa peningkatan penggunaan GPU pada sejumlah besar data terus meningkat.
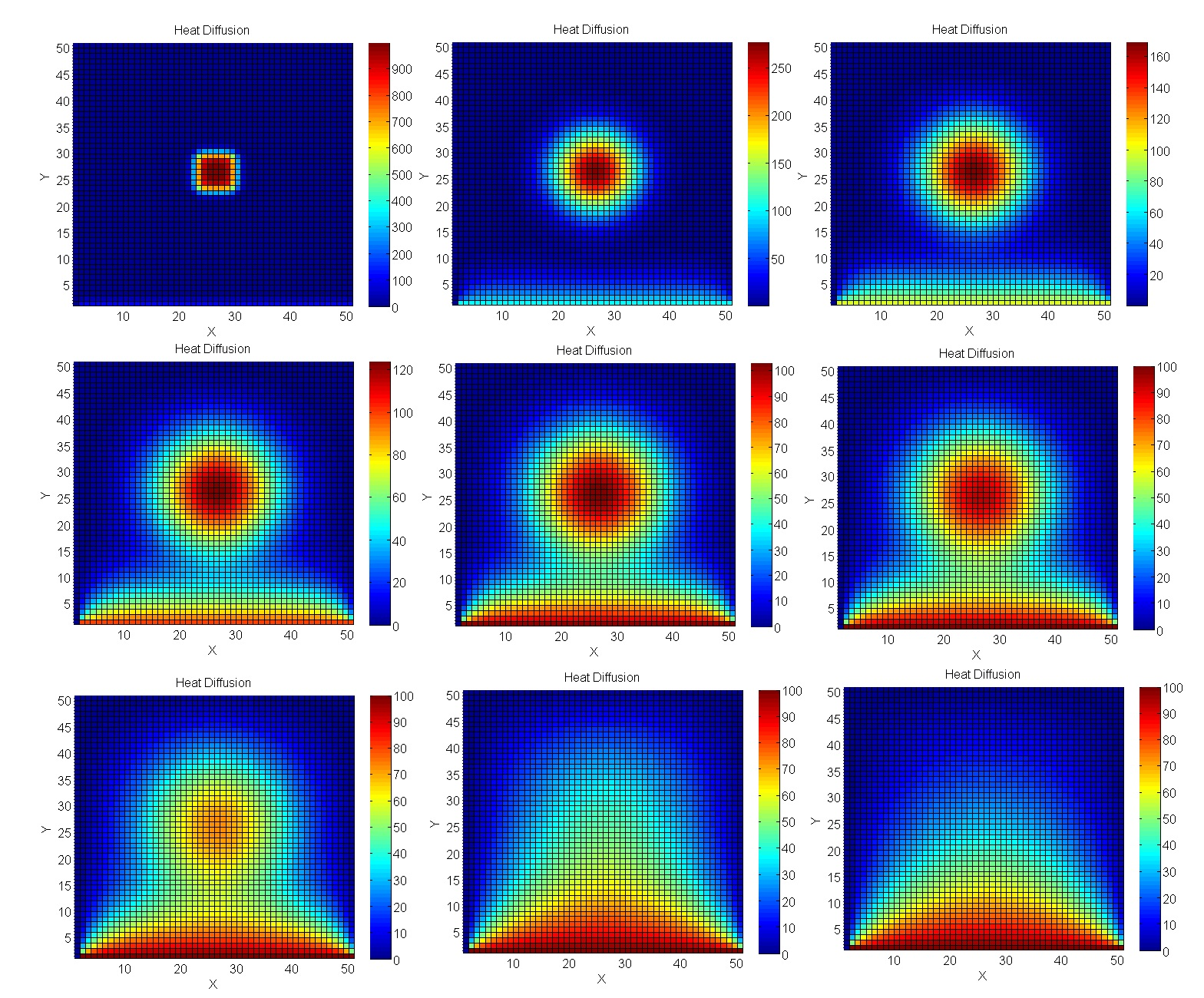
Kami menghitung pemanasan pelat
Mari kita bawa masalah lebih dekat ke pemodelan rekayasa nyata - perhitungan menggunakan metode Jacobi. Secara khusus, mereka sangat baik untuk menghitung proses suhu dalam ruang 2D.
Kode simulasi
"""
simulates heat equation on rectangle returning a heat map at a number of times
boundary and initial conditions are 0, source represents burner on a stove
This program is based on the script FEniCS tutorial demo program: Diffusion of a Gaussian hill.
u'= Laplace(u) + f in a square domain
u = u_D = 0 on the boundary
u = u_0 = 0 at t = 0
u_D = f = stove burner flame
This program succesfully runs in the fenics docker image, see the book Solving PDEs in Python.
to animate: convert -delay 4 -loop 100 heatequation10*.png heatstovelinn.gif
to crop:convert heatstovelinn.gif -coalesce -repage 0x0 -crop 810x810+95+15 +repage heatstovelin.gif
"""
from fenics import *
import time
import matplotlib.pyplot as plt
from matplotlib import cm
# Create mesh and define function space
nx = ny = 100
mesh = RectangleMesh(Point(-2, -2), Point(2, 2), nx, ny)
V = FunctionSpace(mesh, 'P', 1)
# Define boundary, source, initial
def boundary(x, on_boundary):
return on_boundary
bc = DirichletBC(V, Constant(0), boundary)
u_0 = interpolate(Constant(0), V)
f = Expression('exp(-sqrt(pow((a*pow(x[0], 2) + a*pow(x[1], 2)-a*1),2)))', degree=2, a=5) #steep guassian centred on the unit sphere
final_time = 0.035
num_pics = 72
for i in range(num_pics):
T = final_time*(i+1.0)/(num_pics+1) #solve time even space
#T = final_time*1.1**(i-num_pics+1) #solve time log space
num_steps = 30
dt = T / num_steps # time step size
# Define variational problem
u = TrialFunction(V)
v = TestFunction(V)
F = u*v*dx + dt*dot(grad(u), grad(v))*dx - (u_0 + dt*f)*v*dx
a, L = lhs(F), rhs(F)
# Time-stepping
u = Function(V)
t = 0
for n in range(num_steps):
t += dt #step
solve(a == L, u, bc) #solve
u_0.assign(u) #update
#plot solution
plot(u,cmap=cm.hot,vmin=0,vmax=0.07)
plt.axis('off')
plt.savefig('heatequation10%s.png'%(i+10),figsize=(8, 8), dpi=220,bbox_inches='tight', pad_inches=0,transparent=True)
Mari tulis pemecah serupa di Cython untuk kompilasi selanjutnya menggunakan CUDA:
# distutils: language=c++
# cython: cdivision=True
from libcpp.algorithm cimport swap
from libcpp.vector cimport vector
from libcpp cimport bool, float
from libc.math cimport fabs
from algorithm cimport for_each, any_of, copy
from execution cimport par, seq
cdef cppclass avg:
float *T1
float *T2
int M, N
avg(float* T1, float *T2, int M, int N):
this.T1, this.T2, this.M, this.N = T1, T2, M, N
inline void call "operator()"(int i):
if (i % this.N != 0 and i % this.N != this.N-1):
this.T2[i] = (
this.T1[i-this.N] + this.T1[i+this.N] + this.T1[i-1] + this.T1[i+1]) / 4.0
cdef cppclass converged:
float *T1
float *T2
float max_diff
converged(float* T1, float *T2, float max_diff):
this.T1, this.T2, this.max_diff = T1, T2, max_diff
inline bool call "operator()"(int i):
return fabs(this.T2[i] - this.T1[i]) > this.max_diff
def jacobi_solver(float[:, :] data, float max_diff, int max_iter=10_000):
M, N = data.shape[0], data.shape[1]
cdef vector[float] local
cdef vector[float] temp
local.resize(M*N)
temp.resize(M*N)
cdef vector[int] indices = range(N+1, (M-1)*N-1)
copy(seq, &data[0, 0], &data[-1, -1], local.begin())
copy(par, local.begin(), local.end(), temp.begin())
cdef int iterations = 0
cdef float* T1 = local.data()
cdef float* T2 = temp.data()
keep_going = True
while keep_going and iterations < max_iter:
iterations += 1
for_each(par, indices.begin(), indices.end(), avg(T1, T2, M, N))
keep_going = any_of(par, indices.begin(), indices.end(), converged(T1, T2, max_diff))
swap(T1, T2)
if (T2 == local.data()):
copy(seq, local.begin(), local.end(), &data[0, 0])
else:
copy(seq, temp.begin(), temp.end(), &data[0, 0])
return iterations
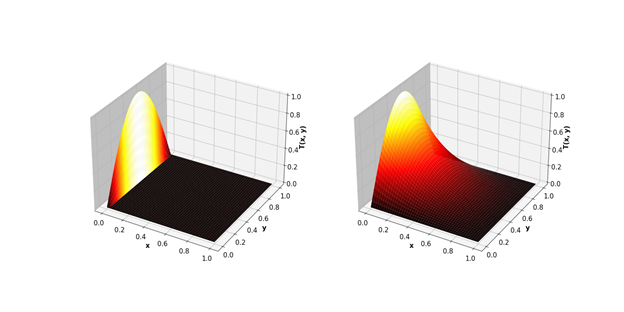

Hasilnya, celah GPU menjadi lebih signifikan.
Minus
- Menulis kode semacam ini agak lebih rumit daripada versi Python murni dan membutuhkan pemahaman tentang cara kerja komputasi paralel pada GPU.
- Diperlukan untuk menyalin data ke array terpisah untuk ditransfer ke GPU, di mana kartu video tidak memiliki akses. Ini bisa menjadi masalah saat menangani array yang sangat besar.
