
Sistem untuk mengonversi kueri teks ke SQL
Sistem seperti apa yang seharusnya dapat dilakukan:
- Temukan entitas dalam teks yang sesuai dengan entitas database: tabel, kolom, terkadang nilai.
- Tautkan tabel, filter formulir.
- Tentukan sekumpulan data yang dikembalikan, yaitu membuat daftar pilih.
- Tentukan urutan pengambilan sampel dan jumlah baris.
- Identifikasi, selain yang relatif jelas, beberapa dependensi atau filter yang benar-benar implisit yang tidak tembus pandang bagi siapa pun kecuali desainer skema dasar (lihat ketentuan untuk bidang bonus_type pada gambar di atas)
- Selesaikan ambiguitas saat memilih entitas. "Beri saya data tentang Ivanov" - haruskah Anda meminta informasi tentang rekanan atau karyawan dengan nama belakang itu? Data Karyawan untuk Februari - Batasi sampel berdasarkan tanggal perekrutan atau tanggal penjualan? dll.
Artinya, pada langkah pertama, Anda perlu mengurai kueri, seperti saat bekerja dengan semua sistem NLP lainnya, lalu membuat SQL dengan cepat, atau menemukan beberapa maksud yang paling sesuai, dalam fungsi yang telah disiapkan sebelumnya untuk kueri SQL berparameter. Sekilas, opsi pertama terlihat jauh lebih mengesankan. Mari kita bahas lebih detail.
Keunikan dari sistem tersebut adalah, pada kenyataannya, hanya satu maksud yang terdaftar di dalamnya, yang dipicu untuk segala sesuatu yang setidaknya memiliki beberapa hubungan dengan model, dengan beberapa fungsi super yang menghasilkan SQL untuk semua jenis kueri. SQL dapat dibuat berdasarkan aturan apa pun, secara algoritme atau dengan partisipasi jaringan saraf.
Algoritma dan aturan
Pada pandangan pertama, tugas untuk mengubah kalimat yang diurai menjadi SQL adalah masalah algoritmik murni, yang dapat diselesaikan tanpa masalah. Tampaknya kita memiliki semua yang kita butuhkan untuk mengonversi satu model kuat ke model lain: entitas yang dikenali, referensi, referensi bersama, dll. Namun, sayangnya, nuansa dan ambiguitas, seperti biasa, memperumit segalanya, dan dalam hal ini mereka membuat pendekatan universal 100% hampir tidak berfungsi. Model tidak sempurna (lihat contoh di atas dan selanjutnya di sepanjang artikel), entitas berpotongan, baik dalam nama maupun dalam arti, pertumbuhan kompleksitas dengan peningkatan jumlah entitas dan kompleksitas basis menjadi nonlinier.
Jaringan saraf
Penggunaan jaringan saraf untuk sistem semacam itu adalah area yang berkembang pesat. Dalam kerangka artikel ini, saya akan membatasi diri pada tautan dan kesimpulan singkat.
Saya menyarankan Anda untuk membaca serangkaian artikel singkat: 1 , 2 , 3 , 4 , 5 , berisi cukup banyak teori, cerita tentang bagaimana pelatihan dan pengujian kualitas dilakukan, gambaran singkat solusi. Selain itu, di sini - lebih lanjut tentang SparkNLP. Di sini - tentang solusi Photon dari SalesForce. Menurut referensi satu lagi perwakilan dari komunitas open source - Allennlp. Sini- data tentang kualitas sistem, yaitu tingkat uji. Berikut adalah data tentang penggunaan perpustakaan NLP dan, khususnya, solusi serupa di suatu perusahaan.
Arah ini memiliki masa depan yang cerah, tetapi sekali lagi dengan reservasi - belum untuk semua jenis model. Jika, saat bekerja dengan model, Anda tidak perlu mendapatkan angka yang benar-benar ketat dan hasil yang dijamin akurat, berulang, dan dapat diprediksi (misalnya, Anda perlu menentukan tren, membandingkan indikator, mengidentifikasi ketergantungan, dll.) - semuanya baik-baik saja. Tetapi sifat non-determinisme dan probabilistik dari jawaban memaksakan pembatasan penggunaan pendekatan semacam itu untuk sejumlah sistem.
Contoh bekerja dengan sistem berdasarkan jaringan saraf
Seringkali, perusahaan yang menyediakan layanan semacam ini menunjukkan hasil yang sangat baik pada video yang dibuat dengan baik dan kemudian menawarkan untuk menghubungi mereka untuk percakapan yang mendetail. Tetapi ada juga demo online yang tersedia di internet. Sangat mudah untuk bereksperimen dengan Foton , karena dalam hal ini diagram dasar ada tepat di depan mata Anda. Demo kedua yang saya lihat di domain publik adalah dari Allennlp. Penguraian beberapa kueri mengejutkan dalam kecanggihannya, beberapa opsi sedikit kurang berhasil. Kesan keseluruhan beragam, coba mainkan dengan demo ini jika Anda tertarik dan bentuk opini Anda sendiri.
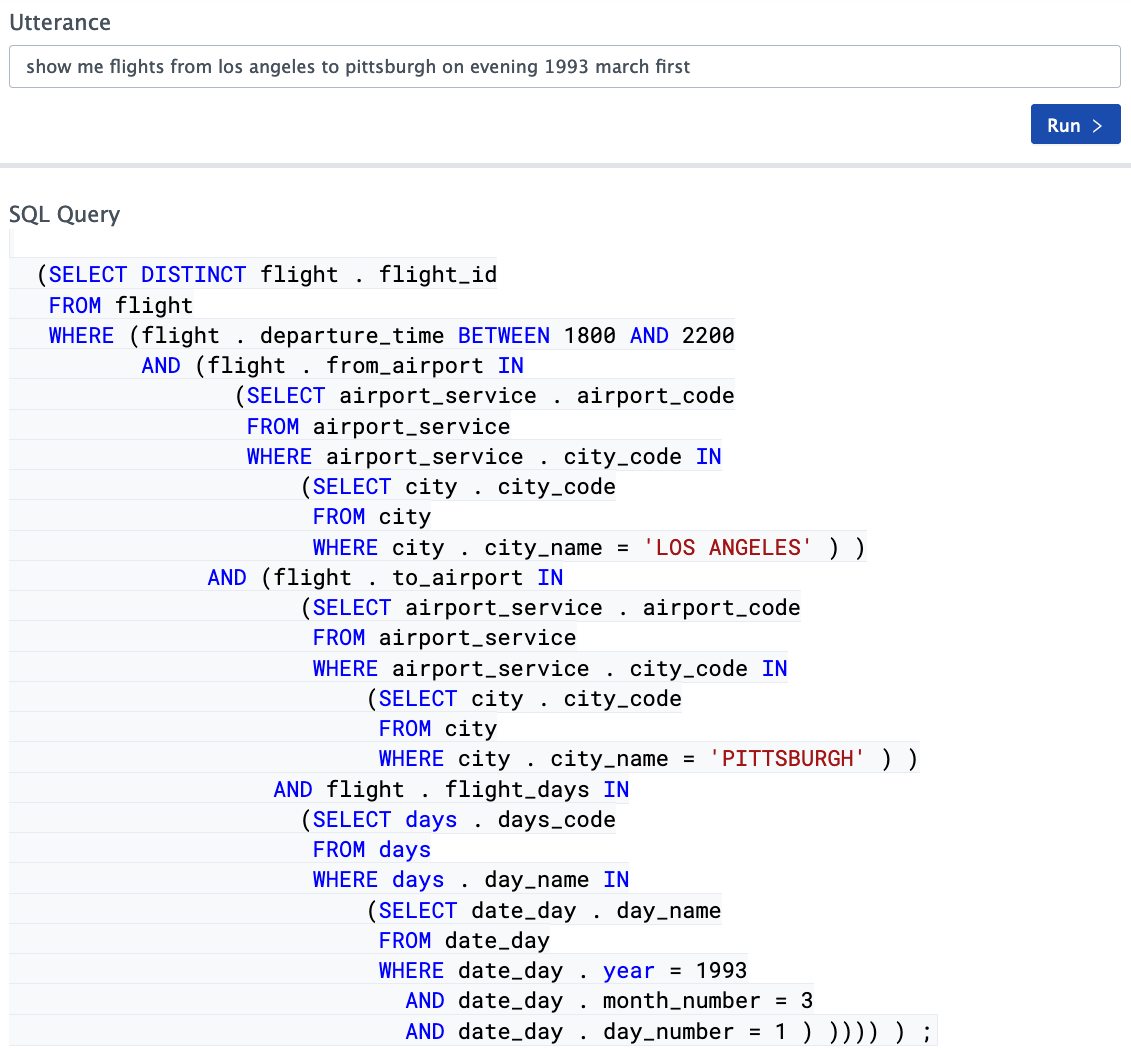
Secara umum, situasinya cukup menarik. Sistem untuk terjemahan otomatis dari kueri tidak terstruktur tekstual ke dalam SQL berdasarkan jaringan neural semakin baik dan lebih baik, kualitas set pengujian yang lulus semakin tinggi dan lebih tinggi, tetapi nilainya tidak melebihi 70% ( kumpulan data laba-laba - sekitar 69% saat ini) hari). Apakah hasil ini bisa dianggap bagus? Dari sudut pandang pengembangan sistem semacam itu, ya, tentu saja, hasilnya sangat mengesankan, tetapi jauh dari mungkin untuk menggunakannya dalam sistem nyata tanpa modifikasi untuk semua jenis tugas.
Alat Apache NlpCraft
Bagaimana proyek Apache NlpCraft membantu membangun dan mengatur sistem seperti itu? Jika tidak ada pertanyaan tentang bagian pertama tugas (parsing kueri teks), semuanya seperti biasa, lalu untuk bagian kedua (pembentukan kueri SQL berdasarkan data NLP), NlpCraft tidak memberikan solusi lengkap 100%, tetapi hanya sebuah toolkit yang membantu dalam menyelesaikan masalah ini sendiri ...
Mulai dari mana? Jika kita ingin mengotomatiskan proses pengembangan sebanyak mungkin, metadata dari skema database dan datanya sendiri akan membantu kita. Kami akan membuat daftar informasi apa yang dapat kami ekstrak dari database dan untuk kesederhanaan kami akan membatasi diri pada tabel, kami tidak akan mencoba menganalisis pemicu, prosedur tersimpan, dll.
- — . , .
- (null / not null) (where clause).
- , foreign keys , 1:1, 1:0, 1:n, n:m. joins.
- . , , .. , select list.
- . . - — , — enumeration, . .
- . , . .
- Primary and unique keys — , , , .
- (, , Oracle) — .
- Periksa batasan - pengetahuan tentang batasan dapat membantu dalam membangun semua filter yang sama pada kolom ini.
Jadi, jika Anda sudah mendapatkan metadata, Anda sudah tahu banyak tentang entitas model. Jadi, misalnya, di beberapa dunia ideal, Anda tahu hampir semua tentang tabel di bawah ini:
CREATE TABLE users (
id number primary key,
first_name varchar(32) not null,
last_name varchar(64) not null unique,
birthday date null,
salary_level_id number not null foreign key on salary_level(id)
);
Pada kenyataannya, semuanya tidak akan begitu indah, nama akan disingkat dan tidak dapat dibaca, tipe data akan sering berubah menjadi sama sekali tidak terduga, dan bidang yang dinormalisasi dan tabel yang ditambahkan dengan tergesa-gesa seperti 1: 0 akan tersebar di sana-sini. Akibatnya, agar realistis, sebagian besar database yang telah diproduksi dalam waktu lama hanya dapat digunakan dengan sangat sulit untuk mengenali entitas tanpa persiapan awal. Ini berlaku untuk sistem apa pun, dan berdasarkan jaringan saraf, bahkan mungkin lebih dari yang lain.
Dalam situasi ini, disarankan untuk memberikan modul NLP akses ke skema yang agak disempurnakan - kumpulan tampilan yang telah disiapkan sebelumnya, dengan nama bidang yang benar, kumpulan tabel dan kolom yang diperlukan dan memadai, masalah keamanan, dll.
Mari mulai mendesain
Ide utama dan sangat sederhana adalah hampir tidak mungkin untuk mencakup semua permintaan pengguna. Jika pengguna menetapkan tujuan untuk menipu sistem dan ingin mengajukan pertanyaan yang akan membingungkannya, dia akan dengan mudah melakukannya. Tugas pengembang adalah mencapai keseimbangan antara kapabilitas sistem yang dikembangkan dan kompleksitas implementasinya. Karenanya, juga, saran yang sangat sederhana - jangan mencoba mendukung satu maksud universal yang menjawab semua pertanyaan, dengan satu metode universal yang menghasilkan SQL untuk semua opsi ini. Cobalah untuk melepaskan 100% keserbagunaan, itu akan membuat proyek sedikit kurang berwarna, tetapi lebih dapat diwujudkan.
- Tanya pengguna dan tuliskan 30-40 jenis pertanyaan yang paling umum.
- , , , ..
- . SQL, 20-30 . , . SQL ML text2Sql, .
- . — , , , . — SQL . C — , .
Dengan volume pekerjaan dan sumber daya yang cukup, waktu yang dibutuhkan untuk menyelesaikan masalah diukur dalam hitungan hari, dan pada akhirnya Anda memiliki cakupan 80% dari kebutuhan pengguna, dan dengan kualitas kinerja yang cukup tinggi. Lalu kembali ke poin pertama dan tambahkan lebih banyak maksud.
Cara termudah untuk menjelaskan mengapa perlu mendukung banyak maksud adalah dengan sebuah contoh. Hampir selalu, pengguna tertarik pada sejumlah laporan yang sangat tidak standar, sesuatu seperti "bandingkan saya ini dan itu untuk periode ini dan itu, tetapi tidak termasuk dalam periode ini dan itu dan pada waktu yang sama ...". Tidak ada sistem yang dapat segera menghasilkan SQL untuk kueri semacam itu, Anda harus melatihnya, atau memilih dan memprogram kasus semacam itu secara terpisah. Mampu menanggapi rentang terbatas kueri rumit sangat penting bagi pengguna Anda. Cari keseimbangan lagi, bukan fakta bahwa akan ada cukup sumber daya untuk memenuhi semua permintaan semacam itu, tetapi mengabaikan sepenuhnya keinginan seperti itu berarti mempersempit fungsionalitas sistem ke tingkat yang tidak dapat diterima. Jika Anda menemukan rasio yang tepat,sistem Anda akan memerlukan waktu pengembangan yang terbatas dan tidak akan menjadi mainan yang menyenangkan selama beberapa hari, menyebabkan gangguan daripada kegunaan di kemudian hari. Poin yang sangat penting adalah Anda dapat menambahkan maksud untuk permintaan rumit tidak langsung, tetapi dalam prosesnya, satu per satu. Kami memiliki MVP dengan hanya satu tujuan universal sekaligus.
Toolkit dan API
Apache NlpCraft menawarkan toolkit untuk menyederhanakan manipulasi database.
Prosedur pelaksanaan:
- Buat template model dari database jdbc url. Seperti yang saya sebutkan di atas, terkadang lebih baik menyiapkan sekumpulan tampilan dengan representasi data yang lebih "benar" dan memberikan akses ke kumpulan itu. Cara termudah untuk membuat template adalah dengan menggunakan utilitas CLI . Kami meluncurkan utilitas, menentukan skema database, driver jdbc, daftar tabel yang digunakan dan diabaikan serta parameter lain sebagai parameter, lihat dokumentasi untuk lebih jelasnya .
- JSON YAML , , , , .., , .
:
- id: "tbl:orders" groups: - "table" synonyms: - "orders" metadata: sql:name: "orders" sql:defaultselect: - "order_id" - "customer_id" - "employee_id" sql:defaultsort: - "orders.order_id#desc" sql:extratables: - "customers" - "shippers" - "employees" description: "Auto-generated from 'orders' table." ..... - id: "col:orders_order_id" groups: - "column" synonyms: - "{order_id|order <ID>}" - "orders {order_id|order <ID>}" - "{order_id|order <ID>} <OF> orders" metadata: sql:name: "order_id" sql:tablename: "orders" sql:datatype: 4 sql:isnullable: false sql:ispk: true description: "Auto-generated from 'orders.order_id' column."
- — , , . , . , , , , , , .. .
- Berdasarkan model kaya, pengembang bisa menggunakan API kompak yang sangat memfasilitasi pembuatan kueri SQL dalam fungsi maksud - lihat contoh mendetail .
Di bawah ini adalah potongan kode untuk kejelasan:
@NCIntent(
"intent=commonReport " +
"term(tbls)~{groups @@ 'table'}[0,7] " +
"term(cols)~{
id == 'col:date' ||
id == 'col:num' ||
id == 'col:varchar'
}[0,7] " +
"term(condNums)~{id == 'condition:num'}[0,7] " +
"term(condVals)~{id == 'condition:value'}[0,7] " +
"term(condDates)~{id == 'condition:date'}[0,7] " +
"term(condFreeDate)~{id == 'nlpcraft:date'}? " +
"term(sort)~{id == 'nlpcraft:sort'}? " +
"term(limit)~{id == 'nlpcraft:limit'}?"
)
def onCommonReport(
ctx: NCIntentMatch,
@NCIntentTerm("tbls") tbls: Seq[NCToken],
@NCIntentTerm("cols") cols: Seq[NCToken],
@NCIntentTerm("condNums") condNums: Seq[NCToken],
@NCIntentTerm("condVals") condVals: Seq[NCToken],
@NCIntentTerm("condDates") condDates: Seq[NCToken],
@NCIntentTerm("condFreeDate") freeDateOpt: Option[NCToken],
@NCIntentTerm("sort") sortTokOpt: Option[NCToken],
@NCIntentTerm("limit") limitTokOpt: Option[NCToken]
): NCResult = {
val ext = NCSqlExtractorBuilder.build(SCHEMA, ctx.getVariant)
val query =
SqlBuilder(SCHEMA).
withTables(tbls.map(ext.extractTable): _*).
withAndConditions(extractValuesConditions(ext, condVals): _*).
...
// SQL
// .
}
Berikut adalah fragmen dari fungsi maksud default yang bereaksi terhadap elemen dasar apa pun yang ditentukan dalam permintaan dan dipicu jika tidak ada kecocokan yang lebih ketat yang ditemukan selama proses pencocokan. Ini mendemonstrasikan penggunaan API ekstraktor elemen SQL, yang terlibat dalam pembuatan kueri SQL, serta bekerja dengan contoh pembuat SQL.
Sekali lagi, saya ingin menekankan bahwa Apache NlpCraft tidak menyediakan alat yang sudah jadi untuk menerjemahkan kueri teks yang diurai ke dalam SQL, tugas ini berada di luar cakupan proyek, setidaknya dalam versi saat ini. Kode pembuat kueri tersedia dalam contoh, bukan di API, memiliki batasan yang signifikan, tetapi juga hanya terdiri dari 500 baris kode dengan komentar, atau sekitar 300 tanpa komentar. Pada saat yang sama, terlepas dari semua kesederhanaan dan bahkan keterbatasannya, implementasi yang paling sederhana ini pun mampu menghasilkan SQL yang diperlukan untuk sejumlah besar jenis kueri pengguna yang paling beragam. Dalam versi ini, kami menyarankan pengguna kami yang tertarik membangun sistem serupa untuk menggunakan contoh inisebagai template dan kembangkan sesuai dengan kebutuhan Anda. Ya, ini bukan tugas untuk satu malam, tetapi Anda akan mendapatkan hasil dengan kualitas yang jauh lebih tinggi daripada saat menggunakan solusi universal secara langsung.
Saya ulangi bahwa dalam fungsi maksud default, Anda dapat memodifikasi contoh dari contoh (menurut ulasan, fungsinya mungkin cukup), atau menggunakan solusi dengan jaringan saraf.
Kesimpulan
Membangun sistem untuk mengakses database bukanlah tugas yang mudah, tetapi Apache NlpCraft telah mengambil alih sebagian besar pekerjaan rutin, dan sebagian besar karena ini, pengembangan sistem kualitas yang layak akan membutuhkan waktu dan sumber daya yang dapat diukur. Apakah komunitas Apache NlpCraft akan mengembangkan arah untuk mengotomatiskan terjemahan kueri teks ke dalam SQL dan memperluas contoh SQL sederhana ini ke API lengkap - waktu dan permintaan pengguna yang membentuk rencana dan arah proyek akan ditampilkan.