Untuk beberapa area, seperti NLP, pekerja kerasnya adalah Transformer, yang membutuhkan memori GPU dalam jumlah besar. Model realistis tidak muat dalam memori. Metode terakhir disebut Sharded [lit. 'segmented'] disajikan dalam makalah Microsoft's Zero , di mana mereka mengembangkan metode yang membawa manusia mendekati 1 triliun parameter.
Khususnya untuk memulai kursus baru tentang Machine Learning, bagikan kepada Anda artikel tentang Sharded yang menunjukkan cara menggunakannya dengan PyTorch hari ini untuk melatih model dengan memori dua kali lipat dan hanya dalam beberapa menit. Fitur ini di PyTorch sekarang tersedia melalui kolaborasi antara FairScale Facebook AI Penelitian dan PyTorch Petir tim .

Untuk siapa artikel ini?
Artikel ini untuk siapa saja yang menggunakan PyTorch untuk melatih model. Sharded berfungsi pada model apa pun, apa pun model yang akan dilatih: NLP (transformator), visual (SIMCL, swav, Resnet), atau bahkan model ucapan. Berikut adalah snapshot dari peningkatan performa yang dapat Anda lihat dengan Sharded di semua jenis model.
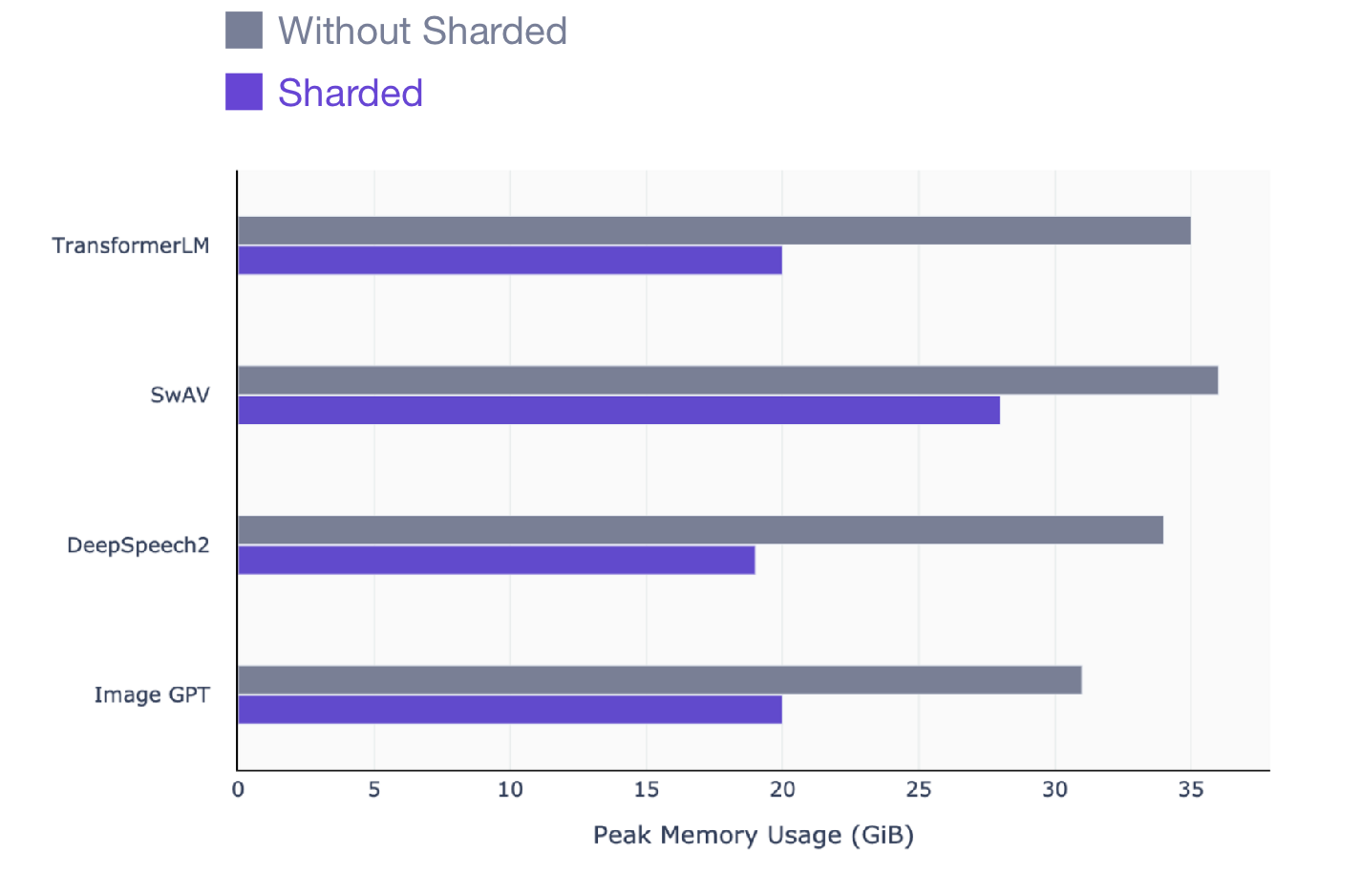
SwAV adalah metode pembelajaran berbasis data yang canggih dalam computer vision.
DeepSpeech2 adalah teknik modern untuk model ucapan.
Image GPT adalah metode lanjutan untuk model visual.
Transformer adalah teknik pemrosesan bahasa alami tingkat lanjut.
Cara menggunakan Sharded dengan PyTorch
Bagi mereka yang tidak punya banyak waktu untuk membaca penjelasan intuitif tentang cara kerja Sharded, saya akan langsung menjelaskan cara menggunakan Sharded dengan kode PyTorch Anda. Tapi saya mendorong Anda untuk membaca akhir artikel untuk memahami cara kerja Sharded.
Sharded dirancang untuk digunakan dengan beberapa GPU untuk memanfaatkan sepenuhnya manfaat yang tersedia. Namun pelatihan pada beberapa GPU bisa jadi menakutkan dan sangat menyakitkan untuk disiapkan.
Cara termudah untuk mengisi kode Anda dengan Sharded adalah mengonversi model Anda ke PyTorch Lightning (ini hanya refactoring). Berikut adalah video 4 menit yang menunjukkan cara mengubah kode PyTorch Anda ke Lightning.
Setelah Anda selesai melakukannya, mengaktifkan Sharded pada 8 GPU semudah mengubah satu bendera: tidak diperlukan perubahan pada kode Anda.

Jika model Anda berasal dari pustaka deep learning lain, model tersebut akan tetap berfungsi dengan Lightning (NVIDIA Nemo, fast.ai, Hugging Face). Yang perlu Anda lakukan adalah mengimpor model ke LightningModule dan mulai belajar.
from argparse import ArgumentParser
import torch
import torch.nn as nn
import pytorch_lightning as pl
from pytorch_lightning.metrics.functional import accuracy
from transformers import BertModel
class LitBertClassifier(pl.LightningModule):
def __init__(self, n_classes, pretrained_model_name='bert-base-uncased'):
super().__init__()
self.save_hyperparameters()
self.bert = BertModel.from_pretrained(pretrained_model_name)
self.drop = nn.Dropout(p=0.3)
self.out = nn.Linear(self.bert.config.hidden_size, n_classes)
self.loss_fn = nn.CrossEntropyLoss()
def forward(self, input_ids, attention_mask):
outputs = self.bert(
input_ids=input_ids,
attention_mask=attention_mask,
return_dict=False
)
pooled_output = outputs[1]
output = self.drop(pooled_output)
return self.out(output)
def training_step(self, batch, batch_idx):
loss, acc = self._shared_step(batch, batch_idx)
self.log("acc", acc)
return loss
def validation_step(self, batch, batch_idx):
_, acc = self._shared_step(batch, batch_idx)
self.log("val_acc", acc)
def _shared_step(self, batch, batch_idx):
input_ids = batch["input_ids"]
attention_mask = batch["attention_mask"]
targets = batch["targets"]
outputs = self.forward(
input_ids=input_ids,
attention_mask=attention_mask
)
_, preds = torch.max(outputs, dim=1)
loss = self.loss_fn(outputs, targets)
acc = accuracy(preds, targets)
return loss, acc
def configure_optimizers(self):
return torch.optim.AdamW(self.parameters(), lr=2e-5)
if __name__ == '__main__':
# TODO: add your own dataset
train_dataloader = ...
val_dataloader = ...
bert = LitBertClassifier()
trainer = pl.Trainer(gpus=8, plugins='ddp_sharded')
trainer.fit(bert, train_dataloader)
Penjelasan intuitif tentang cara kerja Sharded
Beberapa pendekatan digunakan untuk melatih secara efektif pada sejumlah besar GPU. Dalam satu pendekatan (DP), setiap paket dibagi di antara GPU. Berikut adalah ilustrasi DP di mana setiap bagian paket dikirim ke GPU yang berbeda dan model disalin berkali-kali ke masing-masing.

Pelatihan DP
Pendekatan ini buruk, karena bobot model dikirimkan melalui perangkat. Selain itu, GPU pertama mendukung semua status pengoptimal. Misalnya, Adam menyimpan salinan lengkap tambahan dari bobot model Anda.
Dalam teknik lain (Data Parallel Distribution, DDP), setiap GPU dilatih pada subset data dan gradien disinkronkan antara GPU. Metode ini juga berfungsi pada banyak mesin (node). Dalam gambar ini, setiap GPU menerima subset data dan menginisialisasi bobot model yang sama untuk semua GPU. Kemudian, setelah back pass, semua gradien disinkronkan dan diperbarui.
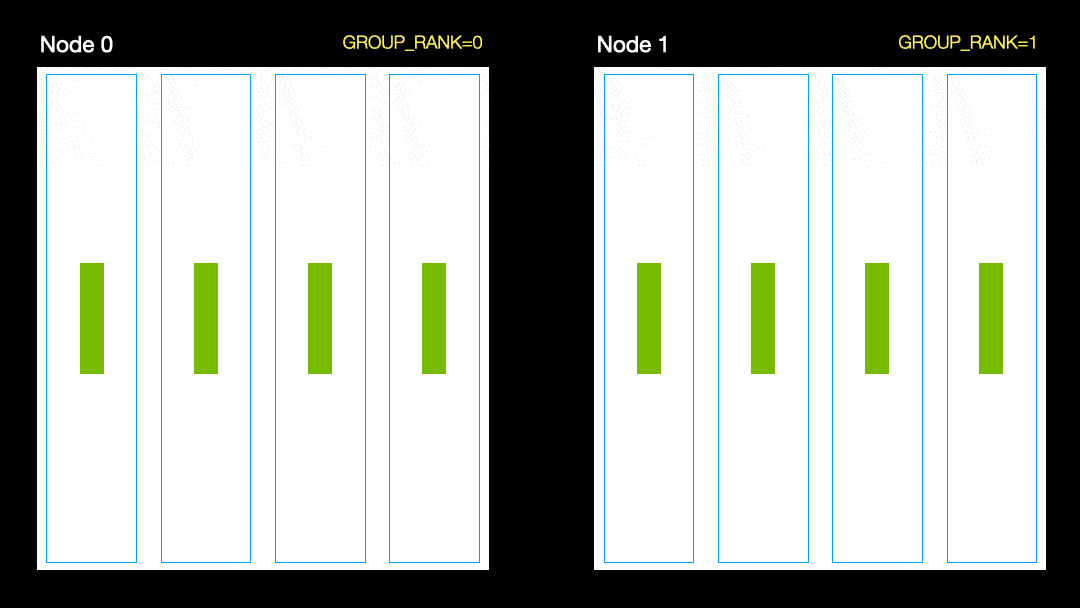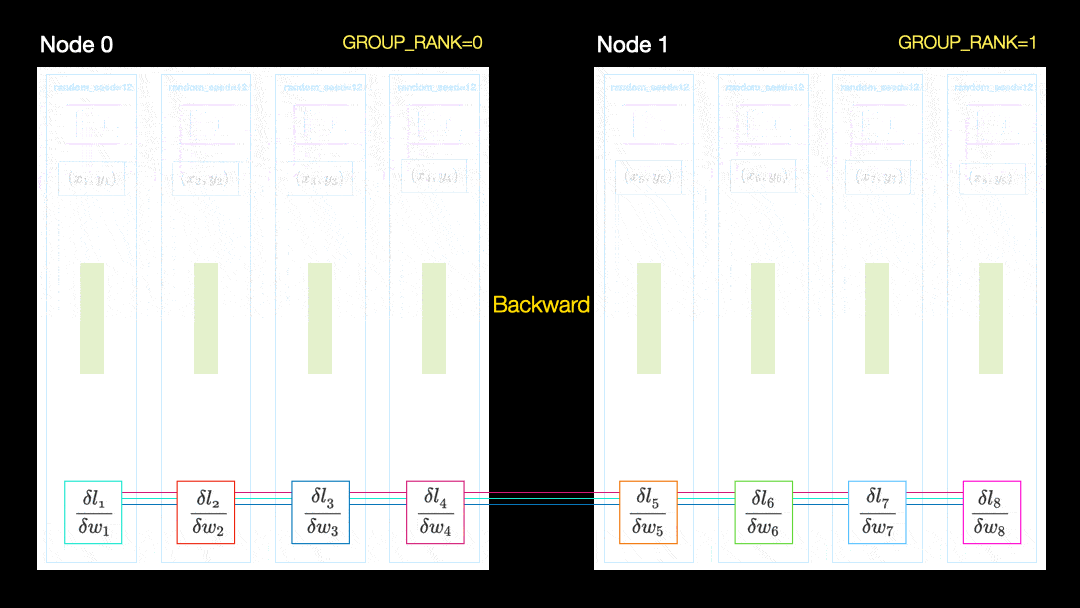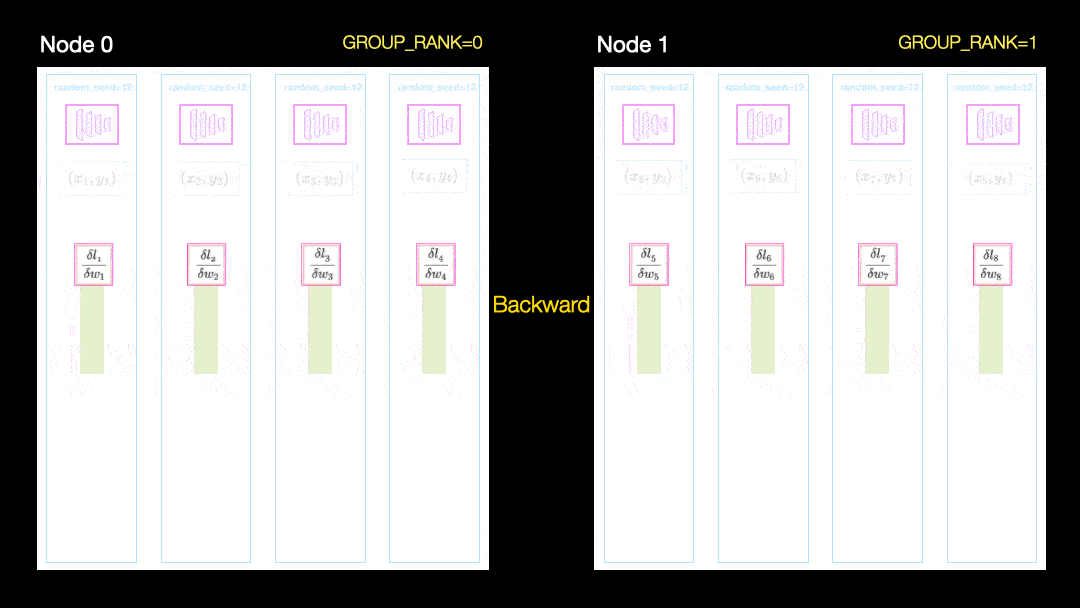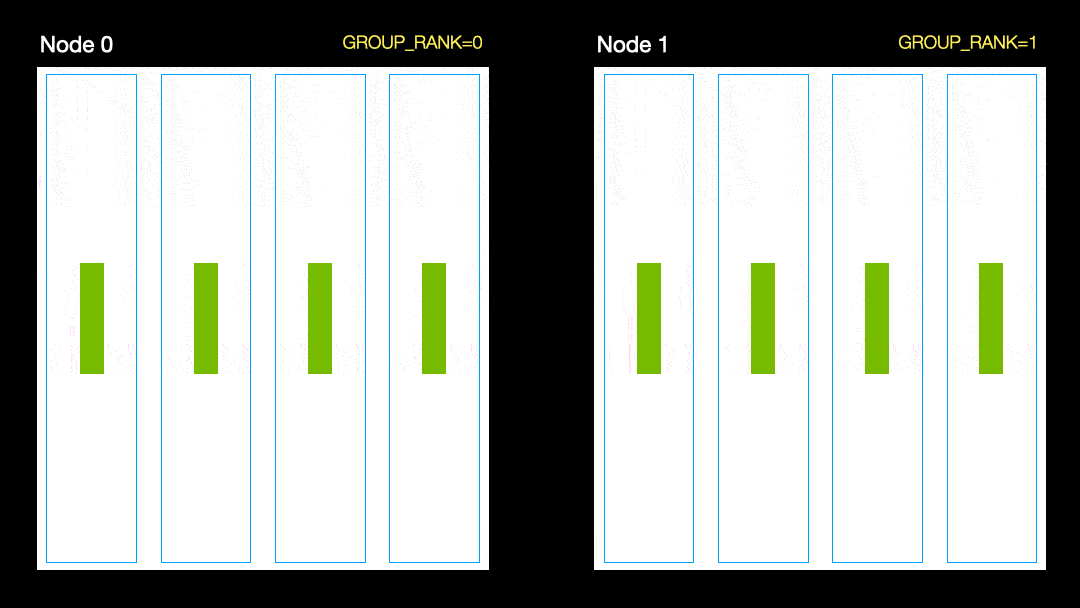
Distribusi data paralel
Namun, metode ini masih memiliki masalah, yaitu setiap GPU harus menyimpan salinan semua status pengoptimal (sekitar 2-3 kali parameter model), serta semua aktivasi maju dan mundur.
Sharded menghapus redundansi ini. Ini bekerja dengan cara yang sama seperti DDP, kecuali bahwa semua overhead (gradien, status pengoptimal, dll.) Dihitung hanya untuk sebagian kecil dari total parameter, dan dengan demikian kami menghilangkan redundansi untuk menyimpan gradien dan status yang sama pengoptimal di semua GPU. Dengan kata lain, setiap GPU hanya menyimpan subset aktivasi, parameter pengoptimal, dan penghitungan gradien.
Menggunakan beberapa jenis mode terdistribusi

Dalam PyTorch Lightning, mengganti mode distribusi itu sepele.
Seperti yang Anda lihat, dengan salah satu pendekatan pengoptimalan ini, ada banyak cara untuk mendapatkan hasil maksimal dari pembelajaran terdistribusi.
Kabar baiknya adalah semua mode ini tersedia di PyTorch Lightning tanpa perlu perubahan kode. Anda dapat mencoba salah satunya dan menyesuaikan jika perlu untuk model spesifik Anda.
Salah satu metode yang tidak ada adalah model paralel. Namun, metode ini harus diperingatkan karena terbukti kurang efektif daripada pelatihan tersegmentasi dan harus digunakan dengan hati-hati. Ini mungkin berhasil dalam beberapa kasus, tetapi secara umum yang terbaik adalah menggunakan sharding.
Manfaat menggunakan Lightning adalah Anda tidak akan pernah ketinggalan kemajuan terbaru dalam penelitian AI! Tim dan komunitas open source berkomitmen untuk membagikan kemajuan terbaru dengan Lightning melalui Lightning.

Profesi dan kursus lainnya