Kami telah lama tertarik dengan topik penggunaan Apache Kafka sebagai gudang data, ditinjau dari sudut pandang teoritis, misalnya, di sini . Jauh lebih menarik untuk memberi perhatian Anda terjemahan materi dari blog Twitter (asli - Desember 2020), yang menjelaskan penggunaan Kafka yang tidak konvensional sebagai database untuk memproses dan mereproduksi acara. Kami berharap artikel ini menarik dan akan memberi Anda pemikiran dan solusi segar saat bekerja dengan Kafka .
pengantar
Saat pengembang menggunakan data Twitter publik melalui API Twitter, mereka mengandalkan keandalan, kecepatan, dan stabilitas. Oleh karena itu, beberapa waktu yang lalu, Twitter meluncurkan API Pemutaran Ulang Aktivitas Akun untuk API Aktivitas Akun guna memudahkan pengembang dalam memastikan stabilitas sistemnya. API Pemutaran Ulang Aktivitas Akun adalah alat pemulihan data yang memungkinkan pengembang untuk mengambil acara yang berlangsung hingga lima hari. API ini memulihkan peristiwa yang tidak terkirim karena berbagai alasan, termasuk server mogok yang terjadi saat mencoba mengirim secara real time.
Insinyur Twitter telah berusaha tidak hanya untuk membuat API yang akan diterima dengan baik oleh pengembang, tetapi juga untuk:
- Meningkatkan produktivitas insinyur;
- Buat sistem mudah dirawat. Secara khusus, untuk meminimalkan kebutuhan pengalihan konteks untuk pengembang, insinyur SRE, dan semua orang yang berurusan dengan sistem.
Karena alasan ini, saat bekerja membuat sistem replay yang bergantung pada API, diputuskan untuk menggunakan sistem yang ada untuk bekerja secara real time, yang menjadi dasar dari API Aktivitas Akun. Dengan cara ini, pengembangan yang ada dapat digunakan kembali dan meminimalkan peralihan konteks dan pelatihan, yang akan jauh lebih signifikan jika sistem yang benar-benar baru dibuat untuk pekerjaan yang dijelaskan.
Solusi real-time didasarkan pada arsitektur publish-subscribe. Untuk tujuan ini, dengan mempertimbangkan tugas dan menciptakan tingkat penyimpanan informasi yang akan dibaca, muncul ide untuk memikirkan kembali teknologi streaming terkenal - Apache Kafka.
Konteks
Peristiwa yang terjadi secara real time diproduksi di dua pusat data. Saat peristiwa ini dipicu, mereka ditulis untuk mempublikasikan-berlangganan topik yang direplikasi silang di dua pusat data untuk redundansi.
Tidak semua peristiwa harus dikirimkan, jadi semua peristiwa difilter oleh aplikasi internal yang menggunakan peristiwa dari topik yang relevan, memeriksa masing-masing dengan serangkaian aturan di penyimpanan kunci dan nilai, dan memutuskan apakah peristiwa harus dikirimkan ke pengembang tertentu melalui API publik. Peristiwa dikirimkan melalui webhook, dan setiap URL webhook milik pengembang yang diidentifikasi dengan ID unik.
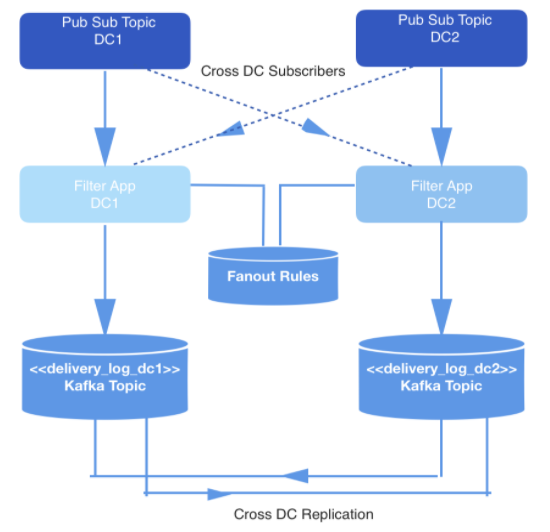
Angka: 1: Pipeline Penghasil Data
Penyimpanan dan segmentasi
Biasanya, saat membangun sistem pemutaran yang membutuhkan gudang data seperti itu, arsitektur yang didasarkan pada Hadoop dan HDFS dipilih. Dalam hal ini, sebaliknya, Apache Kafka dipilih, karena dua alasan:
- Sistem untuk bekerja secara real time menggunakan prinsip publish-subscribe, yang organik ke perangkat Kafka
- Jumlah peristiwa yang perlu disimpan dalam sistem replay tidak dalam petabyte. Kami menyimpan data tidak lebih dari beberapa hari. Selain itu, menangani pekerjaan MapReduce untuk Hadoop lebih mahal dan lebih lambat daripada mengonsumsi data di Kafka, dan opsi pertama tidak memenuhi harapan pengembang.
Dalam hal ini, beban utama berada pada pipeline pemutaran data real-time untuk memastikan bahwa peristiwa yang perlu dikirimkan ke setiap pengembang disimpan di Kafka. Sebut saja topik Kafka delivery_log; akan ada satu topik seperti itu untuk setiap pusat data. Topik ini direplikasi silang untuk redundansi, yang memungkinkan permintaan replikasi dikeluarkan dari satu pusat data. Peristiwa yang disimpan dengan cara ini akan dihapus duplikatnya sebelum dikirimkan.
Dalam topik Kafka ini, kami membuat banyak partisi menggunakan sharding semantik default. Oleh karena itu, partisi sesuai dengan hash webhookId pengembang, dan id ini berfungsi sebagai kunci untuk setiap entri. Itu seharusnya menggunakan sharding statis, tetapi pada akhirnya itu ditinggalkan karena peningkatan risiko bahwa satu partisi akan berisi lebih banyak data daripada yang lain, jika beberapa pengembang menghasilkan lebih banyak acara selama aktivitas mereka daripada yang lain. Sebaliknya, sejumlah partisi tetap dipilih untuk mendistribusikan data, dan strategi partisi dibiarkan di default. Ini mengurangi risiko partisi tidak seimbang dan tidak harus membaca semua partisi di topik Kafka.
Sebaliknya, berdasarkan webhookId tempat permintaan dibuat, layanan replay menentukan partisi tertentu untuk dibaca, dan memunculkan konsumen Kafka baru untuk partisi tersebut. Jumlah partisi dalam topik tidak berubah, karena pencirian kunci dan distribusi peristiwa bergantung padanya.
Untuk meminimalkan ruang penyimpanan, informasi dikompresi menggunakan algoritma snappy , karena diketahui bahwa sebagian besar informasi dalam tugas yang dijelaskan diproses di sisi konsumen. Selain itu, snappy lebih cepat didekompresi dibandingkan algoritme kompresi lain yang didukung oleh Kafka: gzip dan lz4....
Pertanyaan dan pemrosesan
Dalam sistem yang dirancang dengan cara ini, API mengirimkan permintaan pemutaran ulang. Sebagai bagian dari payload dari setiap permintaan yang divalidasi, hadir webhookId dan berbagai data yang peristiwa harus dimainkan. Kueri ini disimpan di MySQL untuk waktu yang lama dan diantrekan sampai diambil oleh layanan replay. Rentang data yang ditentukan dalam permintaan digunakan untuk menentukan offset untuk mulai membaca dari disk. Fungsi
offsetForTimes
objek
Consumer
digunakan untuk mendapatkan offset.
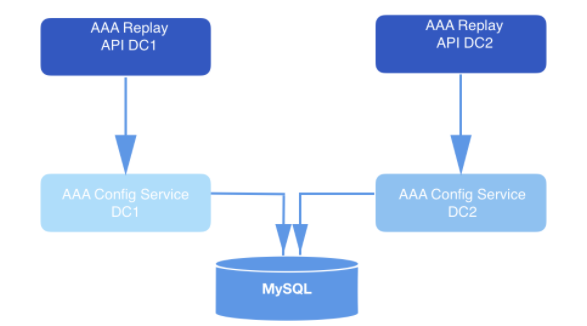
Angka: 2: Sistem pemutaran. Ini menerima permintaan dan mengirimkannya ke layanan konfigurasi (lapisan akses data) untuk penyimpanan jangka panjang lebih lanjut dalam database.
Instance layanan pemutaran ulang menangani setiap permintaan pemutaran ulang. Instance dikoordinasikan satu sama lain menggunakan MySQL untuk memproses playhead berikutnya yang disimpan dalam database. Setiap proses pekerja replay secara berkala melakukan polling MySQL untuk melihat apakah ada pekerjaan yang harus diproses. Permintaan berpindah dari satu negara bagian ke negara bagian lain. Permintaan yang belum diambil untuk diproses dalam status TERBUKA. Permintaan yang baru saja diantrekan berada dalam status MULAI. Permintaan yang saat ini sedang diproses dalam status TERLALU. Permintaan yang telah menjalani semua transisi berada dalam status SELESAI. Alur kerja pemutaran ulang hanya mengambil permintaan yang belum mulai diproses (yaitu, permintaan dalam status OPEN).
Secara berkala, setelah proses pekerja menghapus permintaan dari antrian untuk diproses, itu diketuk ke dalam tabel MySQL, meninggalkan cap waktu dan dengan demikian menunjukkan bahwa pekerjaan replay masih diproses. Jika contoh alur kerja yang mereproduksi mati sebelum selesai memproses permintaan, pekerjaan ini akan dimulai ulang. Akibatnya, proses mereproduksi tidak hanya mendequeue permintaan dalam status OPEN, tetapi juga mengambil permintaan yang ditransfer ke status STARTED atau ONGOING, tetapi tidak menerima umpan balik apa pun dalam database setelah beberapa menit yang ditentukan.
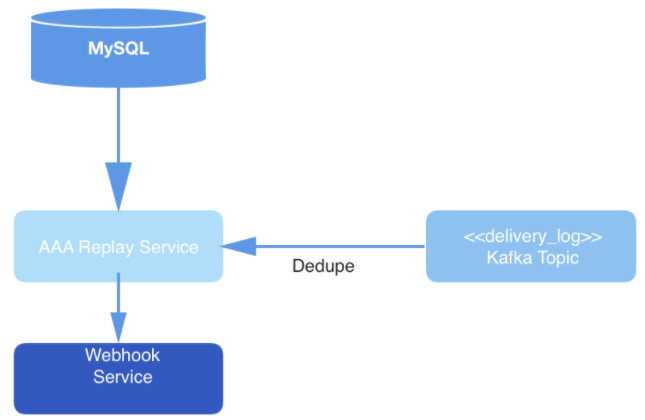
Angka: 3: Lapisan pengiriman data: layanan replay mengumpulkan data dari MySQL untuk tugas pemrosesan permintaan baru, menggunakan permintaan dari topik Kafka, dan mengirimkan acara melalui layanan Webhook.
Akhirnya, peristiwa dari topik tersebut dihapus duplikatnya dalam proses pembacaan, dan kemudian dipublikasikan ke URL webhook pengguna tertentu. Deduplikasi dilakukan dengan mempertahankan cache peristiwa baca, yang kemudian di-hash. Jika acara dengan hash yang identik dengan yang sudah ada di hash muncul, maka acara tersebut tidak akan dikirimkan.
Secara umum, penggunaan Kafka ini tidak tradisional. Namun dalam kerangka sistem yang dijelaskan, Kafka berhasil berfungsi sebagai penyimpan data dan berpartisipasi dalam pekerjaan API, yang berkontribusi baik pada kegunaan dan kemudahan akses ke data saat memulihkan peristiwa. Kekuatan sistem untuk operasi waktu nyata sangat berguna dalam kerangka solusi semacam itu. Selain itu, tingkat pemulihan data dalam sistem seperti itu sepenuhnya memenuhi harapan pengembang.