Di dentsu, kami menghadirkan Podcaster, alat analisis untuk mengukur audiens podcast dan merencanakan iklan di dalamnya. Bagaimana kami mulai mengumpulkan data dan memecahkan masalah pengenalan audiens, kesulitan apa yang kami temui dan apa penyebabnya, kami akan memberi tahu Anda di artikel ini.

Latar Belakang
Penjadwalan podcast sekarang didasarkan pada data dari penjual (studio atau agensi spesialis) yang menghubungi penulis podcast dan meminta deskripsi pendengar. Podcaster sendiri menerima data baik dari platform tempat podcast diposting atau dari sistem statistik eksternal. Ada sejumlah batasan dalam pendekatan ini:
- podcast dapat dipilih dari daftar terbatas, yang memiliki perjanjian dengan penjual dan memiliki data tentang audiens podcast;
- tidak ada kemungkinan untuk memilih podcast yang lebih afinitif (afinitas adalah rasio audiens target tertentu di antara pendengar dengan semua pendengar podcast), karena, sebagai aturan, deskripsi inti pendengar tersedia, dan umumnya sama dalam hal usia untuk sebagian besar podcast;
- Podcasters sendiri memiliki data untuk setiap podcast, tetapi baik podcaster maupun penjual tidak tahu bagaimana pendengar tumpang tindih di antara podcast.
Untuk membuat penjadwalan podcast lebih cerdas, kami mencoba membentuk sistem analitik terpadu yang akan didasarkan pada data dari daftar podcast yang ada dan basis pengguna yang mendengarkan podcast ini, serta dimungkinkan untuk menentukan jenis kelamin dan usia pendengar yang sama ini.
Pendekatan
Kami segera menyadari bahwa kami tidak akan bisa mendapatkan audisi khusus pengguna sendiri. Tetapi ada suka / pelanggan podcast: mekanisme serupa berfungsi, misalnya, di Instagram dengan blogger, ketika seseorang berlangganan blogger untuk melihat beritanya. Kami berasumsi bahwa cerita yang sama terjadi dengan podcast - pendengar berlangganan podcast favorit mereka sehingga mereka dapat mengakses dengan cepat dan dapat mengikuti episode baru.
Kami memutuskan untuk menguji hipotesis ini menggunakan platform populer yang digunakan audiens untuk mendengarkan podcast. Menurut Tiburon, Yandex.Music adalah pemimpin dalam mendengarkan podcast.
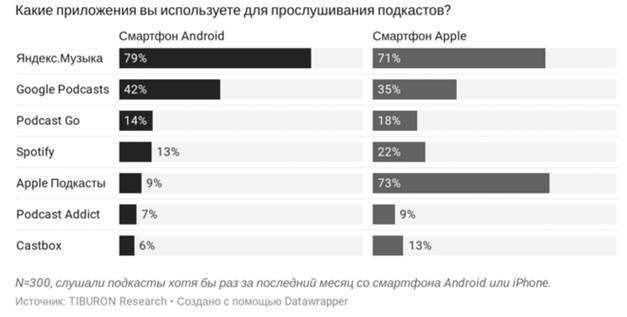
Untungnya, Ya Music memiliki halaman pengguna yang menyediakan informasi tentang langganan podcast.
Contoh profil dengan foto dan langganan podcast
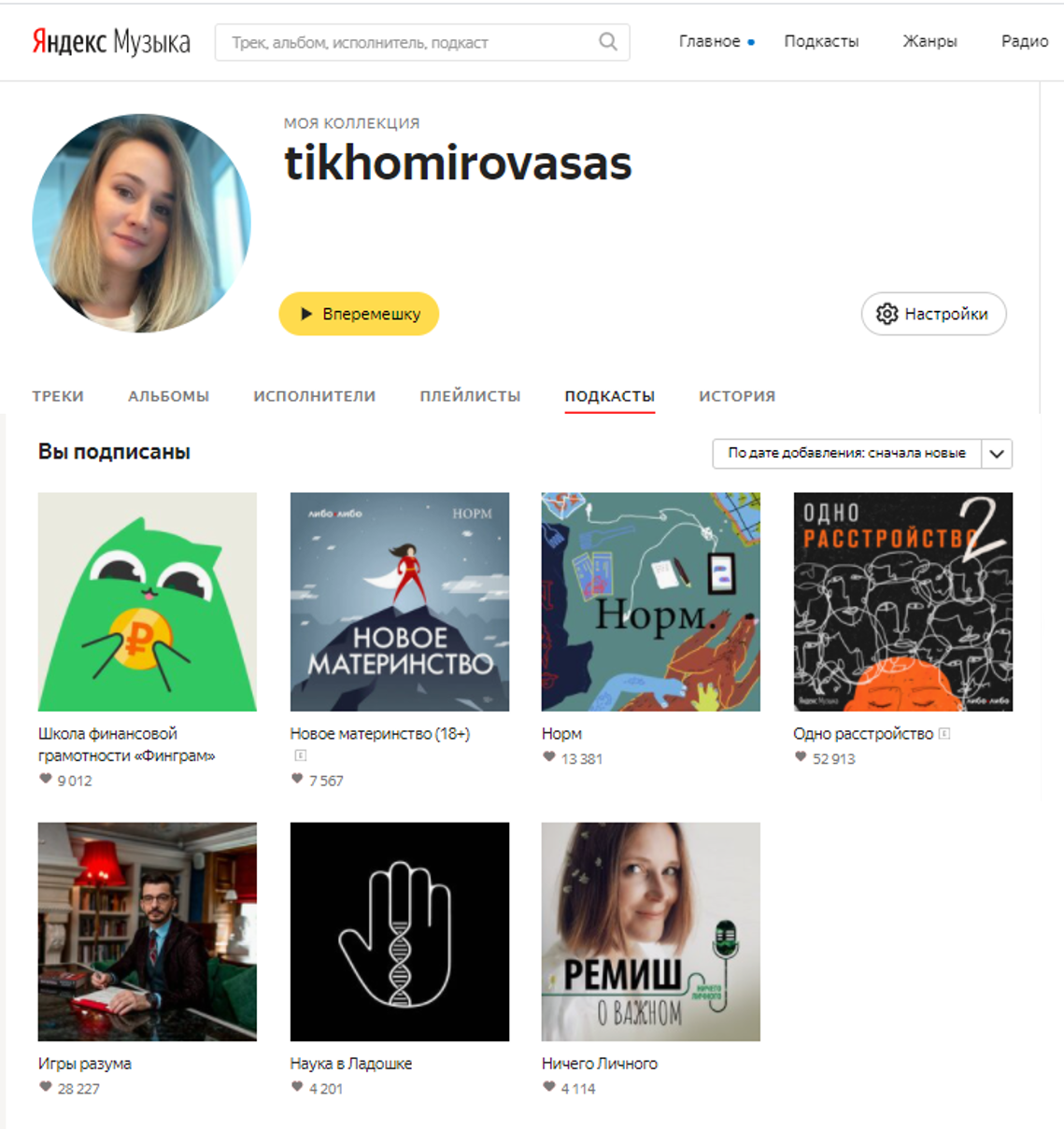
Selain langganan itu sendiri, ada nama panggilan dan avatar pengguna di domain publik. Ini sudah sesuatu, karena sebenarnya kita melihat inti dari pendengar podcast, yaitu mereka yang rutin mendengarkannya. Juga di sini kami memiliki tautan podcast-pengguna yang ingin kami temukan.
Mekanika
Kami mulai mengumpulkan data yaitu pengguna dan podcast yang menjadi langganan pendengar. Awalnya, kami menemukan pengguna Y.Muzyka dengan podcast pada data karyawan dentsu yang menyediakan kotak surat mereka di Yandex. Tidak sulit untuk mengukur skala proyek, karena kami telah bekerja dengan data publik selama beberapa tahun.
Kabar baiknya adalah basis pelanggan podcast berkumpul dengan sangat cepat - hanya dalam satu setengah bulan kami mendapatkan lebih dari 10.000 pengguna yang berlangganan setidaknya satu podcast.
Tetapi ada juga berita buruk - tidak selalu mungkin untuk menentukan jenis kelamin dan usia berdasarkan foto dan nama panggilan, atau lebih tepatnya, tidak mungkin sama sekali. Bagi kami, untuk dapat memilih podcast yang relevan untuk audiens yang berbeda, kami tidak dapat melakukannya tanpa jenis kelamin dan usia. Jaringan saraf kami
mengatasi tugas ini untuk menentukan jenis kelamin dan usia dari sebuah foto , yang akurasinya 96%. Algoritmanya sederhana: kami mengambil foto pengguna J. Musik, mencari wajah, dan menggunakannya untuk menentukan jenis kelamin dan usia. Wajah ditemukan oleh perpustakaan pengenalan wajah
menggunakan dlib. Dan inti dari jaringan neural kami adalah model VGGFace terlatih berdasarkan arsitektur ResNet-50, yang telah kami latih pada foto pengguna VK yang tersedia melalui API publik. Dataset terdiri dari satu juta foto yang telah ditambahkan melalui albumentation. Perlu dicatat bahwa kami tidak menganggap foto pengguna berusia di bawah 12 tahun ke atas 65 untuk tujuan pelatihan.
hasil
Setelah pelatihan, kami menyadari bahwa di sekitar 45% profil pengguna dengan podcast, kami dapat menentukan jenis kelamin dan usia, karena ada banyak profil tanpa foto atau gambar, simbol, atau hanya foto berkualitas buruk. Tetapi bahkan hasil ini cocok untuk kita.
Dengan mempertimbangkan dinamika pencarian profil yang berlangganan podcast, kami berharap dalam beberapa bulan basis pendengar akan menjadi 50.000 profil, dan 22.500 di antaranya akan memiliki jenis kelamin dan usia.
Contoh profil yang tidak dapat kami tentukan jenis kelamin dan usianya.
Perkembangan saat ini memungkinkan kami membuat sampel podcast afinitif untuk berbagai kelompok audiens.
Pilihan podcast untuk 20-50 topik yang relevan dengan merek

Afinitas = target audiens di antara pendengar podcast / semua pendengar podcast) / (semua pendengar podcast / semua orang dengan podcast)
Kami juga dapat menganalisis podcast tertentu jika pengiklan tertarik padanya.
Dengan melihat berapa banyak orang yang berlangganan podcast, kami dapat membuat rekomendasi tentang paket podcast yang akan membangun jangkauan terbesar.
Kurva cakupan untuk 50 podcast yang dipilih
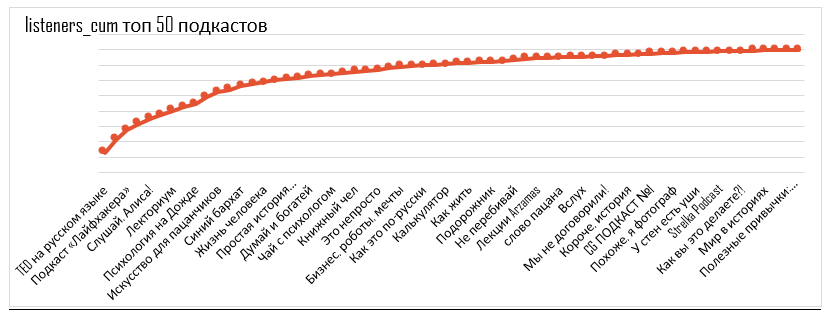
Setiap poin +1 podcast per campuran. Titik pertama adalah podcast dengan audiens unik terbesar, titik terakhir adalah podcast dengan audiens unik terkecil.
Mekanika kurva dan model matematika
Pertama, kita ambil podcast yang memiliki audiens lebih banyak, dalam kasus kita podcast 3. Di bawah ini adalah tabel di mana logika brute force terungkap, yaitu prinsip mendistribusikan konsiliator di antara podcast.

Selanjutnya, kami mencoret pendengar yang kami jangkau dengan podcast 3, dan sekali lagi memilih podcast dengan audiens paling unik (podcast 4). Ini adalah podcast yang memberi kami 2 pendengar unik baru, jadi sebaiknya tempatkan berikutnya.

Kami ulangi latihannya, dan ternyata kami tidak akan mencakup lebih banyak pendengar yang unik, yaitu penempatan di 2 dari 6 podcast sudah cukup untuk mencakup semua audiens unik yang memungkinkan.

kesimpulan
Kami tidak menjawab semua pertanyaan, jadi kami terus mencari data. Misalnya, baru-baru ini Ya.Muzyka mulai menerbitkan informasi tentang jumlah penonton yang berlangganan untuk setiap podcast. Sekarang kami memahami volume pendengar yang dikumpulkan dari total.
Kami sedang mengerjakan mekanisme menggabungkan data langganan dengan data dari situs dan podcaster untuk menyempurnakan model guna memperkirakan jumlah dan komposisi pendengar. Tapi sekarang, pendekatan kami membantu mengubah penjadwalan integrasi iklan di podcast dan melanjutkan bukan dari data agregat penjual atau intuisi pengiklan tentang audiens podcast, tetapi dari audiens merek. Dan juga untuk membuat paket podcast yang relevan secara khusus untuk audiens merek ini dan membangun jangkauan maksimum untuknya.
Penulis Sasha_Kopylova