Halo! Nama saya Dmitry Shelamov dan saya bekerja di Vivid.Money sebagai pengembang backend di departemen Layanan Pelanggan. Perusahaan kami adalah startup Eropa yang menciptakan dan mengembangkan layanan internet banking untuk negara-negara Eropa. Ini adalah tugas yang ambisius, yang berarti bahwa implementasi teknisnya memerlukan infrastruktur yang dipikirkan dengan matang yang dapat menahan beban dan skala tinggi sesuai dengan kebutuhan bisnis.
Proyek ini didasarkan pada arsitektur layanan mikro, yang mencakup lusinan layanan dalam berbagai bahasa. Ini termasuk Scala, Java, Kotlin, Python, dan Go. Yang terakhir adalah tempat saya menulis kode, jadi contoh praktis dalam seri ini sebagian besar akan menggunakan Go (dan sedikit docker-compose).
Bekerja dengan microservices memiliki ciri khas tersendiri, salah satunya adalah penyelenggaraan komunikasi antar service. Model interaksi dalam komunikasi ini dapat sinkron atau asinkron dan dapat berdampak signifikan pada kinerja dan toleransi kesalahan sistem secara keseluruhan.
Komunikasi asinkron
Jadi, mari kita bayangkan bahwa kita memiliki dua layanan mikro (A dan B). Kami akan berasumsi bahwa komunikasi di antara mereka dilakukan melalui API dan mereka tidak tahu apa-apa tentang implementasi internal satu sama lain, seperti yang ditentukan oleh pendekatan layanan mikro. Format data yang dikirimkan di antara mereka telah disepakati sebelumnya.
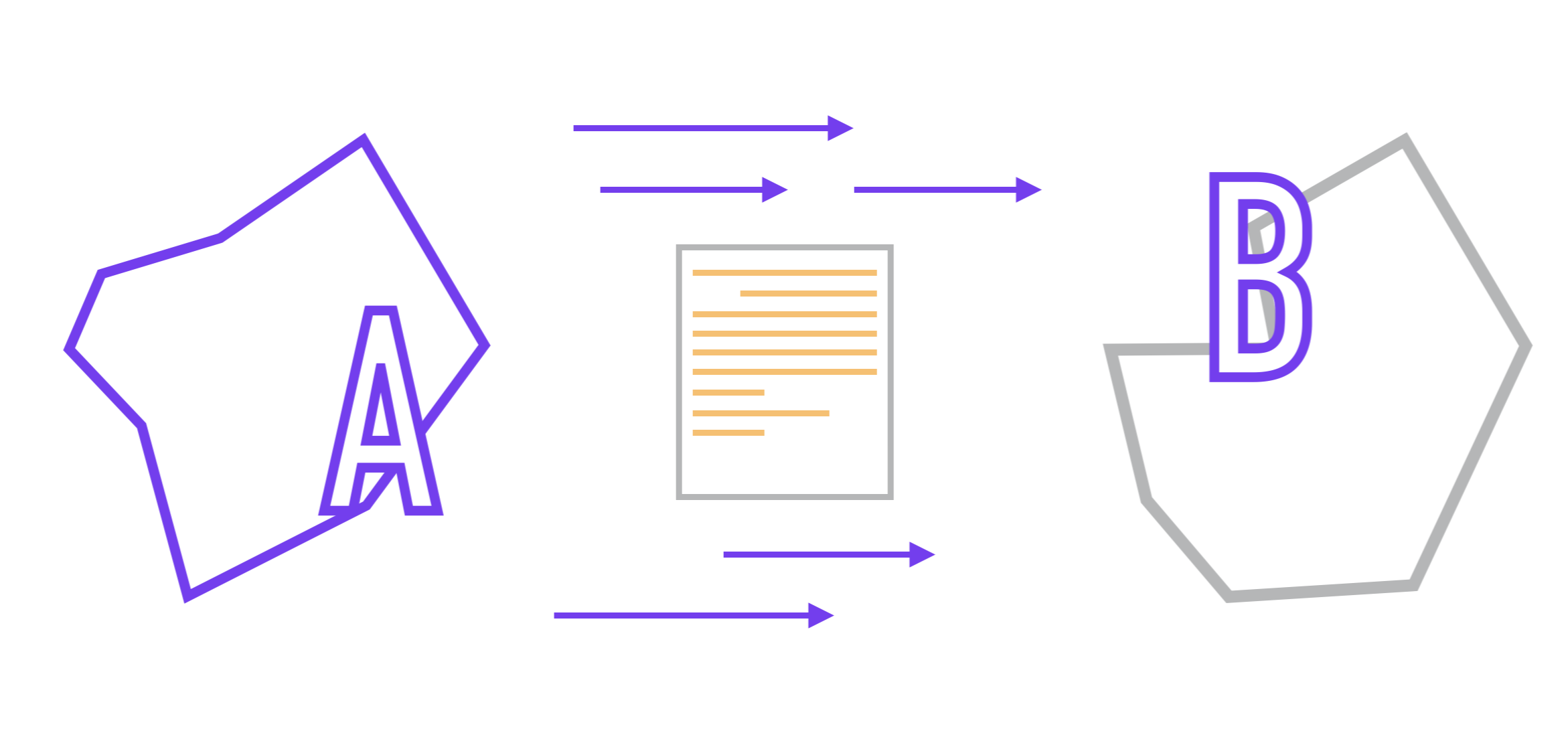
Tugas di hadapan kita adalah sebagai berikut: kita perlu mengatur transfer data dari satu aplikasi ke aplikasi lainnya dan, sebaiknya, dengan penundaan minimal.
Dalam kasus yang paling sederhana, tugas dicapai dengan interaksi sinkron , saat A mengirim permintaan ke aplikasi B, setelah itu layanan B memprosesnya dan, bergantung pada apakah permintaan berhasil atau tidak berhasil diproses, mengirimkan responslayanan A yang mengharapkan tanggapan ini.
Jika respons terhadap permintaan belum diterima (misalnya, B memutus koneksi sebelum mengirim respons, atau A jatuh karena batas waktu), layanan A dapat mengulangi permintaannya ke B.
Di satu sisi, model interaksi seperti itu memberikan kepastian status pengiriman data untuk setiap permintaan ketika pengirim mengetahui dengan pasti apakah data telah diterima oleh penerima dan tindakan selanjutnya apa yang perlu dia lakukan tergantung dari responnya.
Di sisi lain, harga yang harus dibayar sedang menunggu. Setelah mengirim permintaan, layanan A (atau utas tempat permintaan dijalankan) diblokir hingga menerima respons atau menganggap permintaan tidak berhasil sesuai dengan logika internalnya, setelah itu ia mengambil tindakan lebih lanjut.
Masalahnya bukan hanya menunggu dan waktu henti berlangsung, tetapi penundaan dalam komunikasi jaringan tidak bisa dihindari. Masalah utamanya adalah keterlambatan ini tidak dapat diprediksi. Peserta komunikasi dalam pendekatan microservice tidak mengetahui detail implementasi masing-masing, oleh karena itu, tidak selalu jelas bagi pihak yang meminta apakah permintaannya sedang diproses secara normal atau apakah datanya perlu dikirim ulang.
Semua yang tersisa dengan model interaksi ini hanyalah menunggu. Mungkin nanodetik, mungkin satu jam. Dan angka ini cukup nyata jika B, dalam proses pemrosesan data, melakukan operasi berat, seperti pemrosesan video.
Mungkin masalahnya tampaknya tidak signifikan bagi Anda - satu besi menunggu jawaban yang lain, apakah kerugiannya besar?
Untuk membuat masalah ini lebih pribadi, misalkan layanan A adalah aplikasi yang berjalan di ponsel Anda dan sementara menunggu respons dari B, Anda melihat animasi memuat di layar. Anda tidak dapat terus menggunakan aplikasi hingga layanan B merespons, dan Anda harus menunggu. Jumlah waktu yang tidak diketahui. Mengingat bahwa waktu Anda jauh lebih berharga daripada waktu menjalankan sepotong kode.
Kekasaran tersebut diselesaikan sebagai berikut - Anda membagi peserta interaksi menjadi dua "kamp": beberapa tidak dapat bekerja lebih cepat, tidak peduli bagaimana Anda mengoptimalkannya (pemrosesan video), sementara yang lain tidak dapat menunggu lebih lama dari waktu tertentu (antarmuka aplikasi di ponsel Anda).
Kemudian Anda mengganti sinkronisasiinteraksi di antara mereka (ketika satu bagian dipaksa untuk menunggu yang lain untuk memastikan bahwa data telah dikirim dan diproses oleh layanan penerima) ke asynchronous , yaitu, model kerja kirim-dan-lupakan - dalam hal ini, layanan A akan melanjutkan pekerjaannya tanpa menunggu respons dari B.
Tetapi bagaimana Anda dapat memastikan bahwa transfer berhasil dalam kasus ini? Anda tidak dapat, misalnya, setelah mengupload video ke layanan hosting video, menampilkan pesan kepada pengguna: "video Anda mungkin diproses, tetapi mungkin tidak," karena layanan yang mendownload video tidak menerima konfirmasi dari prosesor layanan bahwa video tersebut mencapai dia tanpa insiden.
Sebagai salah satu solusi untuk masalah ini, kami dapat menambahkan lapisan antara layanan A dan B, yang akan bertindak sebagai penyimpanan sementara dan penjamin pengiriman data dengan kecepatan yang nyaman bagi pengirim dan penerima. Dengan demikian, kami akan dapat memisahkan layanan, interaksi sinkron yang berpotensi menimbulkan masalah:
- Data yang hilang ketika layanan penerima berakhir secara tidak normal sekarang dapat diambil dari penyimpanan pementasan lagi sementara layanan pengiriman terus melakukan tugasnya. Dengan demikian, kami mendapatkan mekanisme jaminan pengiriman ;
- Lapisan ini juga melindungi penerima dari lonjakan beban, karena penerima menerima data saat diproses, dan bukan saat diterima;
- Permintaan untuk operasi kelas berat (seperti rendering video) sekarang dapat diteruskan melalui lapisan ini, sehingga menyediakan lebih sedikit konektivitas antara bagian aplikasi yang cepat dan lambat.
DBMS biasa sangat cocok untuk persyaratan di atas. Data di dalamnya dapat disimpan dalam waktu yang lama tanpa perlu khawatir kehilangan informasi. Penerima yang kelebihan beban juga dikecualikan, karena mereka bebas memilih kecepatan dan volume pembacaan catatan yang ditujukan untuk mereka. Konfirmasi pemrosesan dapat diwujudkan dengan menandai catatan yang telah dibaca di tabel yang sesuai.
Namun, memilih DBMS sebagai alat pertukaran data dapat menyebabkan masalah kinerja karena beban kerja meningkat. Ini karena sebagian besar database tidak dirancang untuk kasus penggunaan ini. Selain itu, banyak DBMS tidak memiliki kemampuan untuk membagi klien yang terhubung menjadi penerima dan pengirim (Pub / Sub) - dalam hal ini, logika pengiriman data harus diterapkan di sisi klien.
Kami mungkin membutuhkan sesuatu yang lebih terspesialisasi daripada database.
Makelar pesan
Makelar pesan (antrian pesan) adalah layanan terpisah yang bertanggung jawab untuk menyimpan dan mengirimkan data dari layanan pengirim ke layanan penerima menggunakan model Pub / Sub.
Model ini mengasumsikan bahwa komunikasi asinkron mengikuti logika dua peran berikut:
- Penerbit menerbitkan informasi baru sebagai pesan yang dikelompokkan berdasarkan beberapa atribut;
- Pelanggan berlangganan aliran pesan dengan atribut tertentu dan memprosesnya.
Atribut pengelompokan pesan adalah antrian , yang diperlukan untuk memisahkan aliran data, sehingga penerima dapat berlangganan hanya ke grup pesan yang menarik bagi mereka.
Mirip dengan langganan di berbagai platform konten - dengan berlangganan penulis tertentu, Anda dapat memfilter konten dengan memilih untuk menonton hanya yang menarik minat Anda.

Antrian dapat dianggap sebagai saluran komunikasi yang membentang antara penulis dan pembaca. Penulis meletakkan pesan pada antrian, setelah itu pesan tersebut "didorong" ke pembaca yang telah berlangganan antrian tersebut. Satu pembaca menerima satu pesan pada satu waktu, setelah itu menjadi tidak dapat diakses oleh pembaca lain.
Pesan, di sisi lain, adalah unit data, biasanya terdiri dari badan pesan dan metadata perantara.
Secara umum, body adalah kumpulan byte dalam format tertentu.
Penerima harus mengetahui format ini agar dapat melakukan deserialisasi pada tubuhnya untuk diproses lebih lanjut setelah menerima pesan.
Anda dapat menggunakan format apa pun yang nyaman, namun penting untuk diingat tentang kompatibilitas mundur, yang didukung, misalnya, oleh biner Protobuf dan kerangka kerja Apache Avro.
Sebagian besar broker pesan berdasarkan AMQP (Advanced Message Queuing Protocol) bekerja sesuai dengan prinsip ini, protokol yang menjelaskan standar untuk pesan toleransi kesalahan melalui antrian.
Pendekatan ini memberi kami beberapa keuntungan penting:
- Kohesi yang lemah. Hal ini dicapai melalui transmisi pesan asinkron: yaitu, pengirim menjatuhkan data dan terus bekerja tanpa menunggu tanggapan dari penerima, dan penerima membaca dan memproses pesan jika diinginkan, dan bukan saat dikirim. Dalam hal ini, antrean dapat dibandingkan dengan kotak surat tempat tukang pos meletakkan surat-surat Anda, dan Anda mengambilnya jika Anda mau.
- . , ( , ), - .
, . - . - . , , : , , , -, .
- . “at least once” “at most once”.
Paling banyak menghilangkan pemrosesan ulang pesan, tetapi memungkinkan pesan hilang. Dalam hal ini, broker akan mengirimkan pesan kepada penerima dengan basis kirim-dan-lupakan. Jika penerima tidak dapat karena alasan tertentu untuk memproses pesan pada upaya pertama, broker tidak akan mengirimnya kembali.
Di sisi lain, setidaknya sekali , menjamin bahwa penerima akan menerima pesan tersebut, tetapi ada kemungkinan untuk memproses ulang pesan yang sama.
Seringkali jaminan ini dicapai dengan menggunakan mekanisme Ack / Nack (pengakuan / pengakuan negatif) , yang mengatur untuk mengirim ulang pesan jika penerima, karena alasan tertentu, tidak dapat memprosesnya.
Jadi, untuk setiap pesan yang dikirim oleh broker (tetapi belum diproses), ada tiga status terakhir - penerima mengembalikan Ack (pemrosesan berhasil), mengembalikan Nack (pemrosesan tidak berhasil), atau memutuskan koneksi. Dua skenario terakhir menghasilkan pengiriman ulang dan pemrosesan ulang pesan.
Namun, broker dapat mengirim ulang pesan tersebut meskipun penerima berhasil memproses pesan tersebut. Misalnya, jika penerima memproses pesan, tetapi keluar tanpa mengirim sinyal Ack ke broker.
Dalam hal ini, broker akan memasukkan pesan ke dalam antrian lagi, setelah itu akan diproses lagi, yang dapat menyebabkan kesalahan dan kerusakan data jika pengembang belum menyediakan mekanisme untuk menghilangkan duplikat di sisi penerima.
Perlu dicatat bahwa ada jaminan pengiriman lain yang disebut "tepat sekali" . Ini sulit dicapai dalam sistem terdistribusi, tetapi juga yang paling diinginkan.
Dalam hal ini, Apache Kafka, yang akan kita bicarakan nanti, menonjol dengan latar belakang banyak solusi yang tersedia di pasar. Sejak versi 0.11, Kafka memberikan jaminan pengiriman satu kalidalam cluster dan transaksi, sementara broker AMQP tidak dapat memberikan jaminan seperti itu. Transaksi di Kafka adalah topik posting tersendiri, hari ini kita akan mulai mengenal Apache Kafka.
Apache Kafka
Bagi saya tampaknya akan berguna untuk pemahaman untuk memulai cerita tentang Kafka dengan representasi skematis dari perangkat cluster.
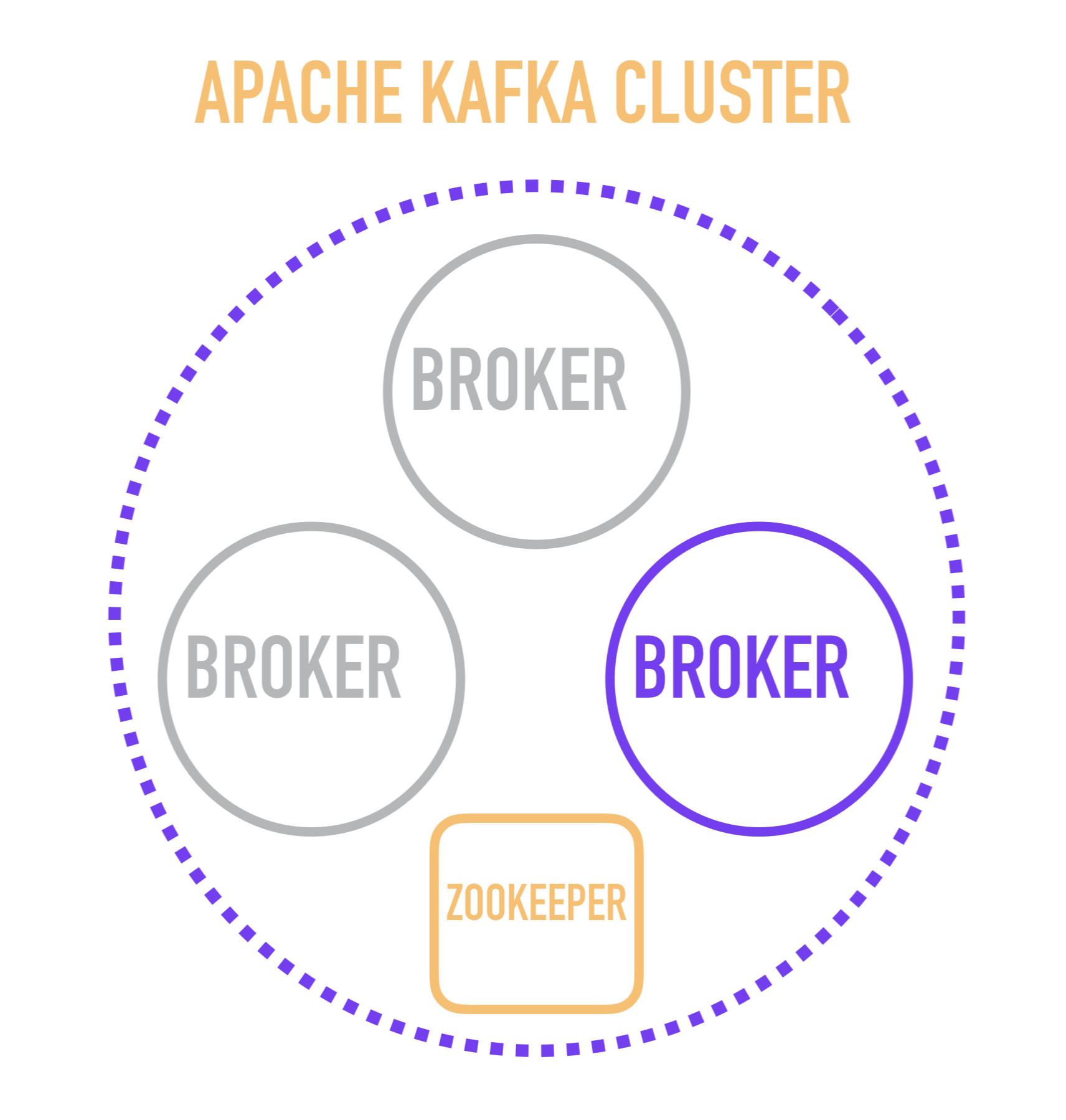
Server Kafka yang terpisah disebut broker . Pialang membentuk cluster di mana salah satu dari pialang ini bertindak sebagai pengontrol yang mengambil alih beberapa operasi administratif (ditandai dengan warna ungu).
Pilihan pengontrol broker, pada gilirannya, adalah tanggung jawab layanan terpisah - ZooKeeper, yang juga melakukan penemuan layanan broker, menyimpan konfigurasi dan mengambil bagian dalam distribusi pembaca baru di antara broker, dan dalam kebanyakan kasus menyimpan informasi tentang pesan yang dibaca terakhir untuk masing-masing pembaca. Ini adalah poin penting, studi yang mengharuskan Anda turun satu tingkat dan mempertimbangkan bagaimana broker individu bekerja secara internal.
Log komitmen
Struktur data yang mendasari Kafka disebut log komit, atau log komit.

Item baru yang ditambahkan ke log komit ditempatkan tepat di akhir, dan urutannya setelah itu tidak diubah, sehingga di setiap item log selalu terdaftar dalam urutan penambahannya.
Properti pemesanan dari log komit memungkinkannya untuk digunakan, misalnya, untuk replikasi sesuai dengan prinsip konsistensi akhir antara replika database: mereka menyimpan log perubahan yang dibuat pada data di node master, aplikasi sekuensial yang pada node slave memungkinkan Anda untuk membawa data di dalamnya ke yang disepakati dengan master pikiran.
Di Kafka, log ini disebut partisi , dan data yang disimpan di dalamnya disebut pesan .
Apa itu pesan? Ini adalah unit dasar data di Kafka dan hanyalah kumpulan byte tempat Anda dapat menyampaikan informasi sewenang-wenang - konten dan strukturnya tidak relevan dengan Kafka. Pesan dapat berisi kunci, yang juga merupakan sekumpulan byte. Kuncinya memungkinkan Anda untuk mendapatkan kontrol lebih besar atas mekanisme pendistribusian pesan ke partisi.
Partisi dan topik
Mengapa ini penting? Faktanya adalah bahwa partisi tidak dapat dianalogikan dengan antrian di Kafka, seperti yang terlihat pada pandangan pertama. Izinkan saya mengingatkan Anda bahwa, secara teknis, antrean pesan adalah sarana pengelompokan dan pengelolaan aliran pesan, yang memungkinkan pembaca tertentu untuk berlangganan hanya ke aliran data tertentu.
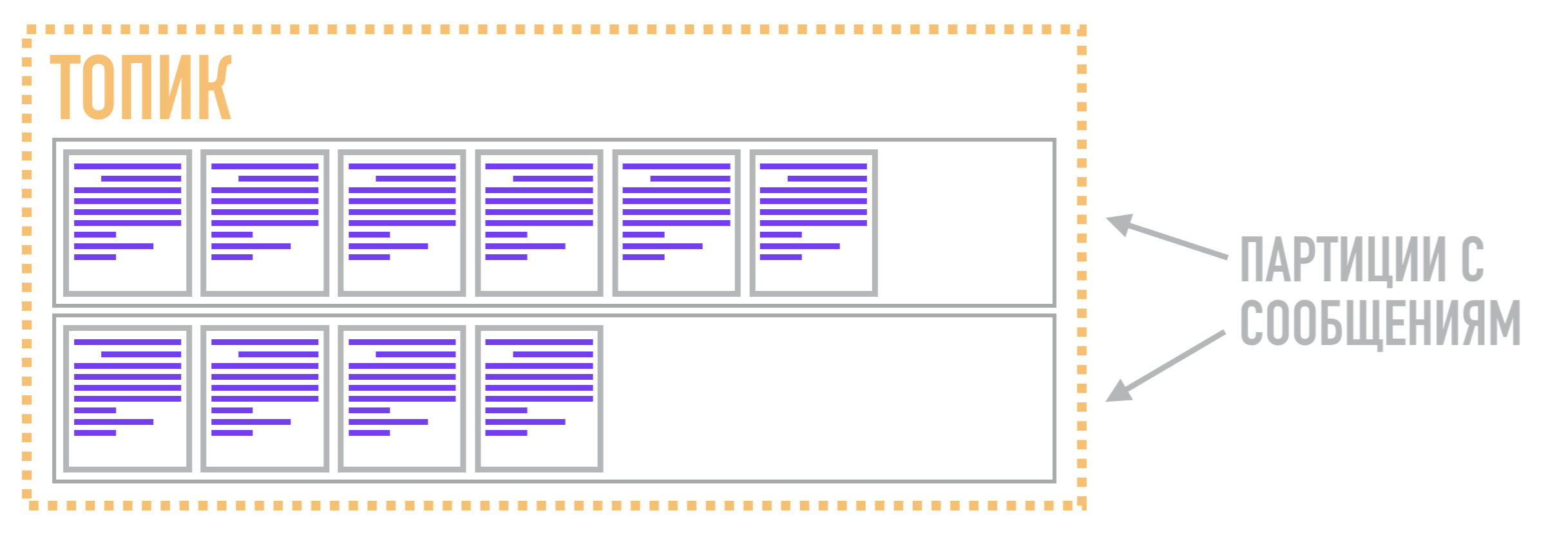
Jadi di Kafka, fungsi antrian dilakukan bukan oleh partisi, melainkan oleh topiknya . Diperlukan untuk menggabungkan beberapa partisi menjadi aliran umum. Partisi itu sendiri, seperti yang kita katakan sebelumnya, menyimpan pesan dalam bentuk terurut sesuai dengan struktur data log komit. Dengan demikian, pesan yang terkait dengan satu topik dapat disimpan dalam dua partisi berbeda, dari mana pembaca dapat menariknya berdasarkan permintaan.
Oleh karena itu, unit paralelisme di Kafka bukanlah topik (atau antrian di broker AMQP), tetapi partisi. Oleh karena itu, Kafka dapat memproses pesan yang berbeda terkait dengan topik yang sama di beberapa broker pada saat yang sama, dan juga mereplikasi tidak seluruh topik secara keseluruhan, tetapi hanya partisi individual, memberikan fleksibilitas dan skalabilitas tambahan dibandingkan dengan broker AMQP.
Tarik dan Dorong
Perhatikan bahwa saya tidak sengaja menggunakan kata "menarik" dalam kaitannya dengan pembaca.
Di broker yang dijelaskan sebelumnya, pesan dikirim dengan mendorongnya ( push ) ke penerima melalui pipa bersyarat dalam bentuk antrian.
Dalam proses penyampaian Kafka sendiri tidak: setiap pembaca sendiri bertanggung jawab untuk menarik ( menarik ) pesan dari partisi yang dibacanya.
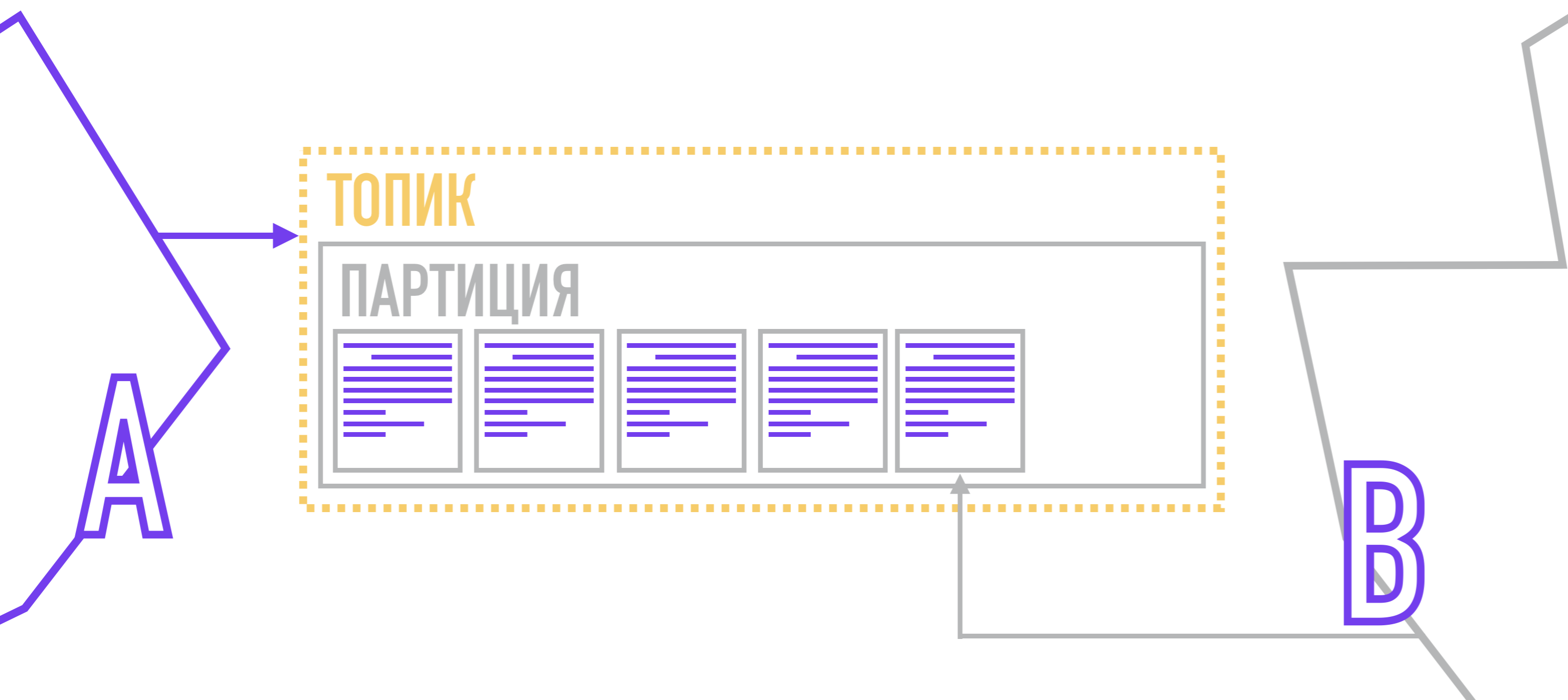
Produsen, membentuk pesan, melampirkan kunci dan nomor partisi padanya. Nomor partisi dapat dipilih secara acak (round-robin) jika pesan tidak memiliki kunci.
Jika Anda membutuhkan lebih banyak kontrol, Anda dapat melampirkan kunci ke pesan, dan kemudian menggunakan fungsi hash atau tulis algoritma Anda sendiri yang partisi untuk pesan akan dipilih. Setelah pembentukan, produser mengirim pesan ke Kafka, yang menyimpannya ke disk, mencatat di partisi mana ia berada.
Setiap penerima ditugaskan ke partisi tertentu (atau beberapa partisi) dalam topik yang diminati, dan ketika pesan baru muncul, dia menerima sinyal untuk membaca item berikutnya di log komit, sambil mencatat pesan terakhir yang dia baca. Jadi, saat menyambungkan kembali, dia akan tahu pesan mana yang harus dibaca selanjutnya.
Apa keuntungan dari pendekatan ini?
- . , , . , ( Retention Policy, ), .
- Message Replay. , . , , .
- . , ( ) – , .
- . (batch) , , . : (1 ), .
Kerugian dari pendekatan ini termasuk menangani pesan masalah. Tidak seperti broker klasik, pesan yang rusak (yang tidak dapat diproses dengan mempertimbangkan logika penerima yang ada atau karena masalah dengan deserialisasi) tidak dapat diantrekan ulang tanpa batas sampai penerima belajar untuk memprosesnya dengan benar.
Di Kafka, secara default, membaca pesan dari partisi berhenti ketika penerima mencapai pesan yang rusak, dan sampai pesan itu dilewati dan dilempar ke antrian "karantina" (juga disebut " antrian surat mati ") untuk diproses lebih lanjut, lanjutkan membaca partisi tidak akan berfungsi.
Juga di Kafka lebih sulit (dibandingkan dengan broker AMQP) untuk mengimplementasikan prioritas pesan. Ini secara langsung mengikuti fakta bahwa pesan dalam partisi disimpan dan dibaca secara ketat sesuai urutan penambahannya. Salah satu cara untuk menyiasati batasan ini di Kafka adalah dengan membuat beberapa topik untuk pesan dengan prioritas berbeda (topik hanya akan berbeda namanya), misalnya, events_low, events_medium, events_high , dan kemudian menerapkan logika pembacaan prioritas dari topik yang terdaftar di sisi aplikasi konsumen.
Kelemahan lain dari pendekatan ini terkait dengan kenyataan bahwa perlu menyimpan catatan pesan yang terakhir dibaca di partisi oleh masing-masing pembaca. Karena kesederhanaan struktur partisi, informasi ini disajikan dalam bentuk nilai integer yang disebut offset (offset). Offset memungkinkan Anda untuk menentukan posting mana yang saat ini sedang dibaca oleh masing-masing pembaca. Analogi terdekat untuk offset adalah indeks elemen dalam larik, dan proses membaca mirip dengan berjalan melalui larik dalam satu lingkaran menggunakan iterator sebagai indeks elemen.
Namun, kelemahan ini diimbangi oleh fakta bahwa Kafka, mulai dari versi 0.9, menyimpan offset untuk setiap pengguna dalam topik khusus __consumer_offsets (hingga versi 0.9, offset disimpan di Zookeeper).
Selain itu, Anda dapat melacak offset langsung di sisi penerima.

Penskalaan juga menjadi lebih rumit: izinkan saya mengingatkan Anda bahwa di broker AMQP, untuk mempercepat pemrosesan aliran pesan, Anda hanya perlu menambahkan beberapa contoh layanan pembaca dan berlangganan ke satu antrian, dan Anda tidak perlu melakukan perubahan apa pun pada konfigurasi broker itu sendiri.
Namun, penskalaan sedikit lebih rumit di Kafka daripada di broker AMQP. Misalnya, jika Anda menambahkan instance lain dari pembaca dan mengaturnya di partisi yang sama, Anda tidak akan mendapatkan efisiensi, karena dalam kasus ini kedua instance akan membaca kumpulan data yang sama.
Oleh karena itu, aturan dasar untuk penskalaan Kafka adalah bahwa jumlah pembaca kompetitif (yaitu, sekelompok layanan yang menerapkan logika pemrosesan (replika) yang sama) dari suatu topik tidak boleh melebihi jumlah partisi dalam topik ini, jika tidak, beberapa pasangan pembaca akan memproses kumpulan data yang sama.
Grup Konsumen
Untuk menghindari situasi dengan pembacaan satu partisi oleh pembaca kompetitif, adalah kebiasaan di Kafka untuk menggabungkan beberapa replika dari satu layanan dalam grup konsumen , di mana Zookeeper tidak akan menetapkan lebih dari satu pembaca ke satu partisi.
Karena pembaca terikat langsung ke partisi (sementara pembaca biasanya tidak tahu apa-apa tentang jumlah partisi dalam topik), Zookeeper, saat pembaca baru tersambung, mendistribusikan ulang peserta dalam Grup Konsumen sehingga setiap partisi memiliki satu dan hanya satu pembaca.
Pembaca menunjuk Kelompok Konsumen mereka saat terhubung ke Kafka.
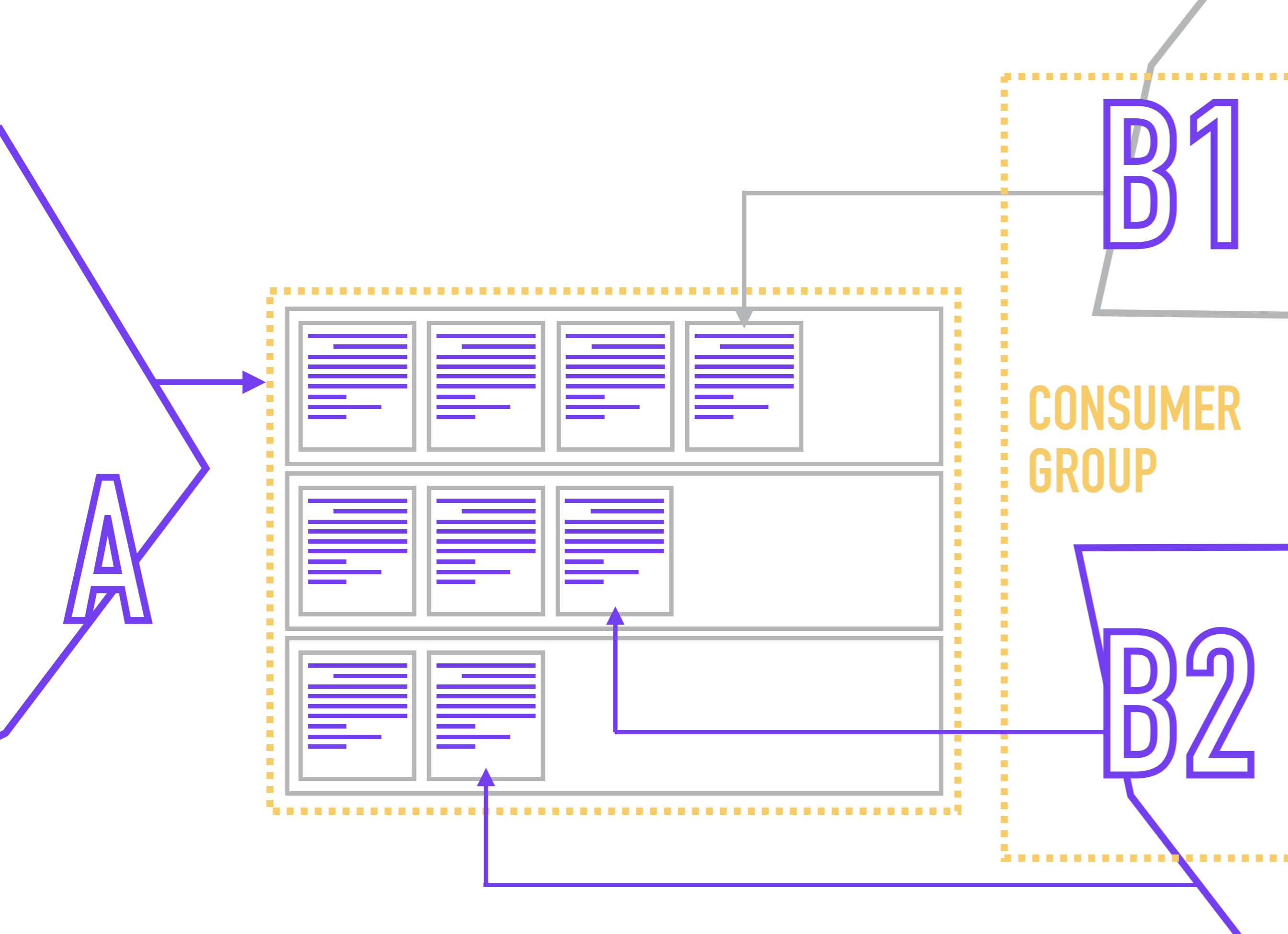
Pada saat yang sama, tidak ada yang menghalangi Anda untuk menggantung beberapa pembaca dengan logika pemrosesan yang berbeda pada satu partisi. Misalnya, Anda menyimpan dalam sebuah topik daftar kejadian menurut tindakan pengguna dan ingin menggunakan kejadian ini untuk menghasilkan beberapa tampilan data yang sama (misalnya, untuk analis bisnis, analis produk, analis sistem, dan paket Yarovaya) dan kemudian mengirimkannya ke repositori yang sesuai.
Namun di sini kita bisa menghadapi masalah lain, yang disebabkan oleh fakta bahwa Kafka menggunakan struktur topik dan partisi. Izinkan saya mengingatkan Anda bahwa Kafka tidak menjamin pengurutan pesan dalam suatu topik, hanya dalam partisi, yang dapat menjadi penting, misalnya, saat membuat laporan tentang tindakan pengguna dan mengirimkannya ke penyimpanan apa adanya.
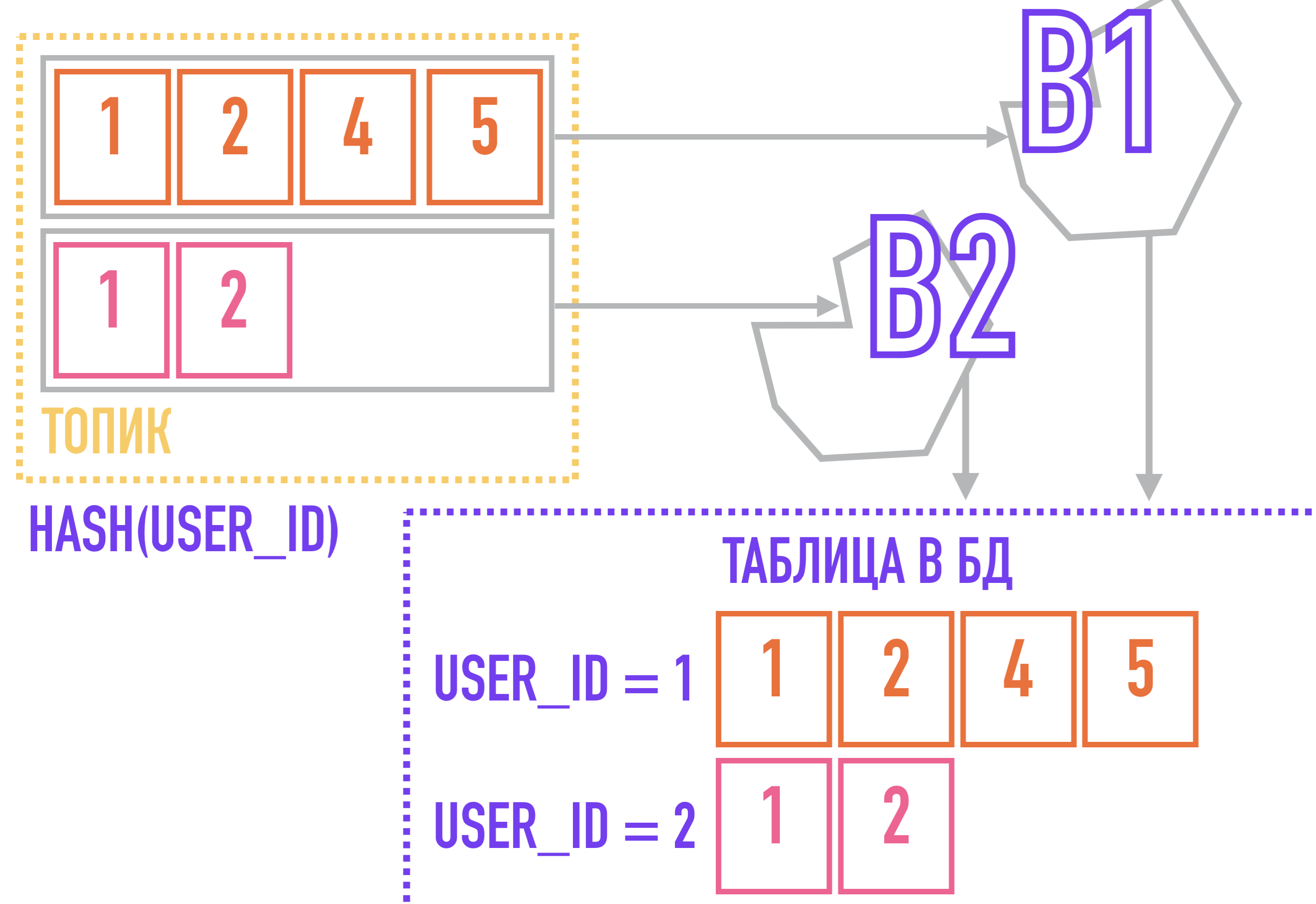
Untuk mengatasi masalah ini, kita bisa melakukan sebaliknya: jika semua peristiwa yang terkait dengan satu entitas (misalnya, semua tindakan yang terkait dengan user_id yang sama) akan selalu ditambahkan ke partisi yang sama, mereka akan diurutkan dalam topik hanya karena berada di partisi yang sama, urutan di dalamnya dijamin oleh Kafka.
Untuk melakukan ini, kita memerlukan kunci untuk pesan: misalnya, jika kita menggunakan algoritme yang menghitung hash dari kunci untuk memilih partisi tempat pesan akan ditambahkan, maka pesan dengan kunci yang sama akan dijamin masuk ke dalam satu partisi, dan oleh karena itu menarik penerima pesan dengan kunci yang sama agar ditambahkan ke topik.
Dalam kasus dengan aliran peristiwa tentang tindakan pengguna, kunci partisi bisa menjadi user_id.
Kebijakan retensi
Sekarang saatnya berbicara tentang Kebijakan Retensi.
Ini adalah pengaturan yang bertanggung jawab untuk menghapus pesan dari disk ketika ambang batas untuk tanggal penambahan ( Kebijakan Retensi Berbasis Waktu ) atau ruang yang ditempati pada disk ( Kebijakan Penyimpanan Berbasis Ukuran ) terlampaui .
- Jika Anda mengkonfigurasi TBRP selama 7 hari, maka semua pesan yang lebih lama dari 7 hari akan ditandai untuk dihapus nanti. Dengan kata lain, pengaturan ini memastikan bahwa pesan di bawah ambang batas usia tersedia untuk dibaca pada waktu tertentu. Dapat diatur dalam jam, menit, dan milidetik.
- SBRP bekerja dengan cara yang sama: ketika ambang ruang disk terlampaui, pesan akan ditandai untuk dihapus dari akhir (lebih lama). Ini harus diingat: karena penghapusan pesan tidak seketika, ruang disk yang digunakan akan selalu sedikit lebih dari yang ditentukan dalam pengaturan. Setel dalam byte.
Kebijakan Retensi dapat dikonfigurasi baik untuk seluruh cluster dan untuk topik individu: misalnya, pesan dalam topik untuk melacak tindakan pengguna dapat disimpan selama beberapa hari, sedangkan pemberitahuan push dapat disimpan selama beberapa jam. Dengan menghapus data sesuai dengan relevansinya, kami menghemat ruang disk, yang bisa jadi penting saat memilih SSD sebagai penyimpanan disk utama.
Kebijakan Pemadatan
Cara lain untuk mengoptimalkan ruang disk adalah dengan menggunakan Kebijakan Pemadatan - pengaturan ini memungkinkan Anda untuk menyimpan hanya pesan terakhir untuk setiap kunci, menghapus semua pesan sebelumnya. Ini bisa berguna jika kita hanya tertarik pada perubahan terbaru.
Kasus penggunaan Kafka
- . : . , , , (Clickhouse !) .
Customer Care Vivid.Money CRM. - . , . , - ( ) , , .
, ( ) . , , , , . - . , .
- (commit log). , - / .
, , «» .
Customer Care CRM- .
Kafka
- – , ;
- – (pull) , . (, ) Consumer Group, ZooKeeper, , , , ;
- . , , , . , () ;
- , , AMQP , – . , ;
- . , , --, – .