
Masalah ini juga muncul saat merancang agen buatan. Misalnya, agen pembelajaran penguatan dapat menemukan rute terpendek untuk menerima sejumlah besar hadiah tanpa menyelesaikan tugas seperti yang dimaksudkan oleh perancang manusia. Perilaku ini umum dan kami telah mengumpulkan sekitar 60 contoh hingga saat ini (menggabungkan daftar yang ada dan kontribusi terkini dari komunitas AI). Dalam posting ini, kita akan melihat kemungkinan penyebab permainan sesuai dengan spesifikasi, berbagi contoh di mana hal itu terjadi dalam praktiknya, dan juga memperdebatkan perlunya pekerjaan lebih lanjut tentang pendekatan berprinsip untuk mengatasi masalah spesifikasi.
Mari kita lihat contohnya. Dalam tugas konstruksi dengan balok-balok Lego, hasil yang diinginkan adalah balok merah berada di atas balok biru. Agen tersebut diberi penghargaan atas ketinggian permukaan bawah balok merah pada saat dia tidak menyentuh balok ini. Alih-alih melakukan manuver yang relatif sulit untuk mengambil blok merah dan meletakkannya di atas blok biru, agen cukup membalik blok merah untuk mengumpulkan hadiah. Perilaku ini memungkinkan kami untuk mencapai tujuan kami (bagian bawah blok merah tinggi) dengan mengorbankan apa yang benar-benar dipedulikan oleh desainer (membangun di atas blok biru).

Pembelajaran penguatan mendalam untuk manipulasi data yang cekatan.
Kita bisa melihat spesifikasi game dari dua perspektif. Sebagai bagian dari pengembangan algoritma Reinforcement Learning (RL), tujuannya adalah untuk menciptakan agen yang belajar untuk mencapai tujuan tertentu. Misalnya, saat kami menggunakan game Atari sebagai tolok ukur untuk mengajarkan algoritme RL, tujuannya adalah untuk menilai apakah algoritme kami mampu memecahkan masalah yang kompleks. Apakah agen memecahkan masalah, menggunakan celah atau tidak, tidak penting dalam konteks ini. Dari sudut pandang ini, bermain berdasarkan spesifikasi adalah pertanda baik: agen telah menemukan cara baru untuk mencapai tujuan ini. Perilaku ini menunjukkan kecerdikan dan kekuatan algoritme untuk menemukan cara melakukan persis seperti yang kami perintahkan.
Namun, ketika kami ingin agen benar-benar menghubungkan blok Lego, kecerdikan yang sama dapat menimbulkan masalah. Dalam kerangka yang lebih luas untuk membangun agen yang ditargetkan yang mencapai hasil yang diinginkan di dunia, permainan spesifikasi bermasalah karena melibatkan agen yang mengeksploitasi celah spesifikasi dengan mengorbankan hasil yang diinginkan. Perilaku ini disebabkan oleh pengaturan masalah yang salah, dan bukan oleh kesalahan dalam algoritma RL. Selain merancang algoritme, komponen lain yang diperlukan untuk membangun agen yang ditargetkan adalah desain penghargaan.
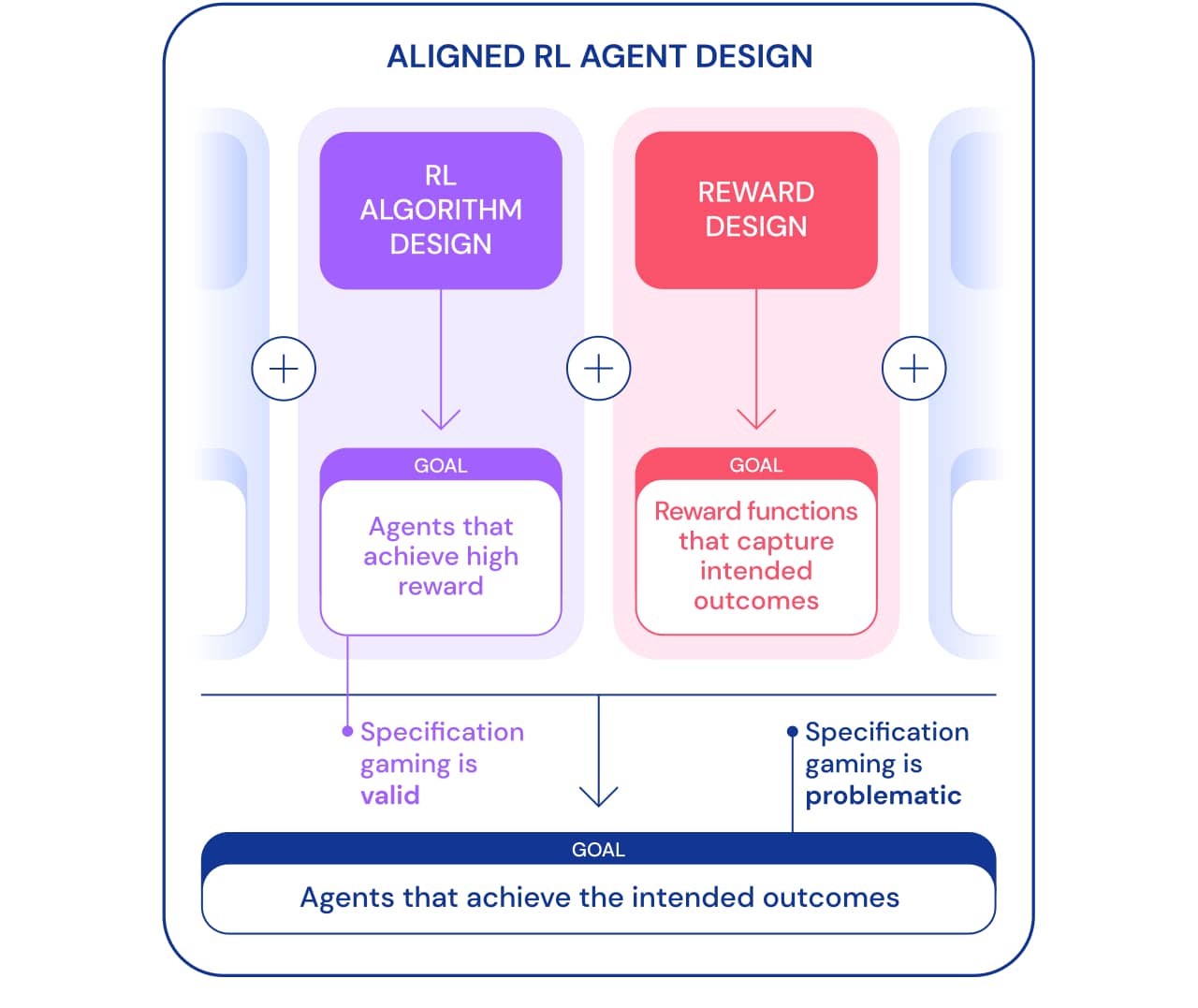
Merancang spesifikasi tugas (fungsi penghargaan, lingkungan, dll.) Yang secara akurat mencerminkan maksud perancang manusia biasanya sulit. Meskipun dengan sedikit kesalahpahaman, algoritme RL yang sangat baik dapat menemukan solusi kompleks yang sangat berbeda dari yang dimaksudkan; bahkan jika algoritma yang lebih lemah tidak dapat menemukan solusi ini dan dengan demikian mendapatkan solusi yang lebih mendekati hasil yang diinginkan. Ini berarti bahwa definisi yang benar dari hasil yang diinginkan mungkin menjadi lebih penting untuk mencapainya seiring dengan peningkatan algoritme RL. Oleh karena itu, penting bahwa kemampuan peneliti untuk mendefinisikan masalah dengan benar tidak boleh ketinggalan dari kemampuan agen untuk menemukan solusi baru.
Kami menggunakan spesifikasi tugas istilah dalam arti luas untuk mencakup banyak aspek dari proses pengembangan agen. Saat menyiapkan RL, spesifikasi tugas tidak hanya mencakup desain reward, tetapi juga pilihan lingkungan pembelajaran dan reward pendukung. Kebenaran pernyataan masalah dapat menentukan apakah kecerdikan agen sesuai dengan hasil yang diinginkan atau tidak. Jika spesifikasinya tepat, kreativitas agen menghasilkan solusi baru yang diinginkan. Inilah yang memungkinkan AlphaGo melakukan langkah ke - 37 yang terkenal .yang mengejutkan para ahli di Go, tetapi memainkan peran kunci dalam pertandingan kedua melawan Lee Sedol. Jika spesifikasinya salah, itu dapat menyebabkan perilaku game yang tidak diinginkan, seperti membalik blok. Solusi semacam itu dimungkinkan, dan kami tidak memiliki cara yang obyektif untuk memperhatikannya.

Sekarang mari kita lihat kemungkinan alasan untuk permainan spesifikasi. Salah satu sumber kesalahan identifikasi fungsi reward adalah pembuatan reward yang dirancang dengan buruk. Pembentukan hadiah memudahkan untuk mengasimilasi tujuan tertentu dengan memberi agen beberapa hadiah dalam perjalanan untuk memecahkan masalah, daripada hanya memberi penghargaan untuk hasil akhir. Namun, pembentukan reward dapat mengubah kebijakan yang optimal jika tidak didasarkan pada perspektif . Pertimbangkan agen yang menjalankan perahu di Coast Runnersdimana tujuan yang dimaksud adalah menyelesaikan balapan secepat mungkin. Agen menerima hadiah formatif karena bertabrakan dengan blok hijau di sepanjang trek balap, yang mengubah kebijakan optimal untuk berputar-putar dan bertabrakan dengan blok hijau yang sama berulang kali.

Fungsi hadiah yang salah sedang beraksi.
Menentukan hadiah yang secara akurat mencerminkan hasil akhir yang diinginkan bisa menjadi tugas yang menakutkan. Dalam masalah menghubungkan balok-balok Lego, tidak cukup untuk menunjukkan bahwa tepi bawah balok merah harus berada jauh dari lantai, karena agen dapat dengan mudah membalik balok merah untuk mencapai tujuan ini. Spesifikasi yang lebih lengkap dari hasil yang diinginkan juga mencakup bahwa permukaan atas kotak merah harus lebih tinggi dari permukaan bawah dan bahwa permukaan bawah sejajar dengan permukaan atas kotak biru. Sangat mudah untuk mengabaikan salah satu kriteria ini saat menentukan hasil, yang membuat spesifikasinya terlalu luas dan berpotensi lebih mudah dipenuhi dengan solusi yang merosot.
Daripada mencoba membuat spesifikasi yang mencakup semua kemungkinan kasus sudut, kita dapat mempelajari fungsi penghargaan dari umpan balik manusia . Seringkali lebih mudah untuk menilai apakah suatu hasil telah dicapai daripada menyatakannya secara eksplisit. Namun, pendekatan ini juga dapat mengalami masalah spesifikasi game jika model reward tidak mempelajari fungsi reward sebenarnya yang mencerminkan preferensi desainer. Salah satu kemungkinan sumber ketidakakuratan adalah umpan balik manusia yang digunakan untuk melatih model penghargaan. Misalnya, agen yang melakukan tugas pengambilan telah belajar untuk mengelabui evaluator dengan mengarahkan kursor di antara kamera dan objek.

Perkuat pembelajaran mendalam berdasarkan preferensi manusia.
Model penghargaan terlatih juga dapat salah didefinisikan karena alasan lain, seperti generalisasi yang buruk. Masukan tambahan dapat digunakan untuk memperbaiki upaya agen untuk mengeksploitasi ketidakakuratan dalam model penghargaan.
Kelas spesifikasi game lainnya berasal dari agen yang mengeksploitasi bug simulator. Misalnya, simulasi robot yang harus belajar berjalan muncul dengan ide untuk mengunci kedua kakinya dan meluncur di tanah.
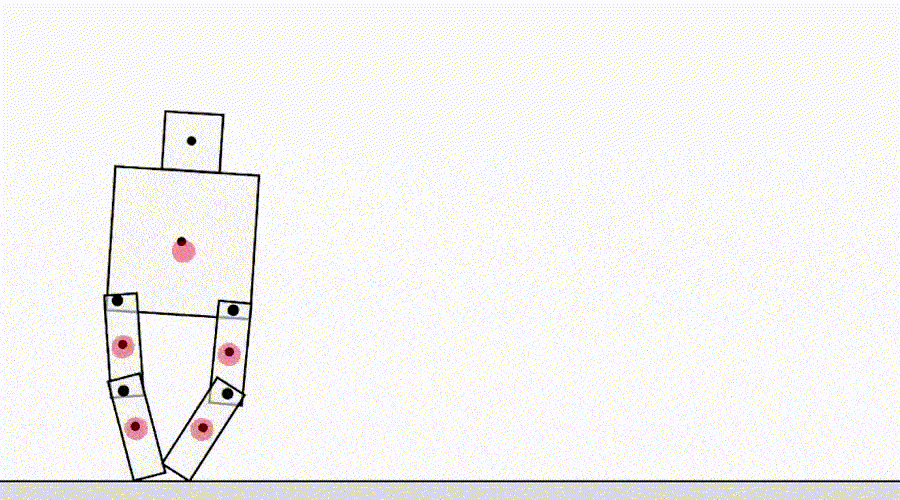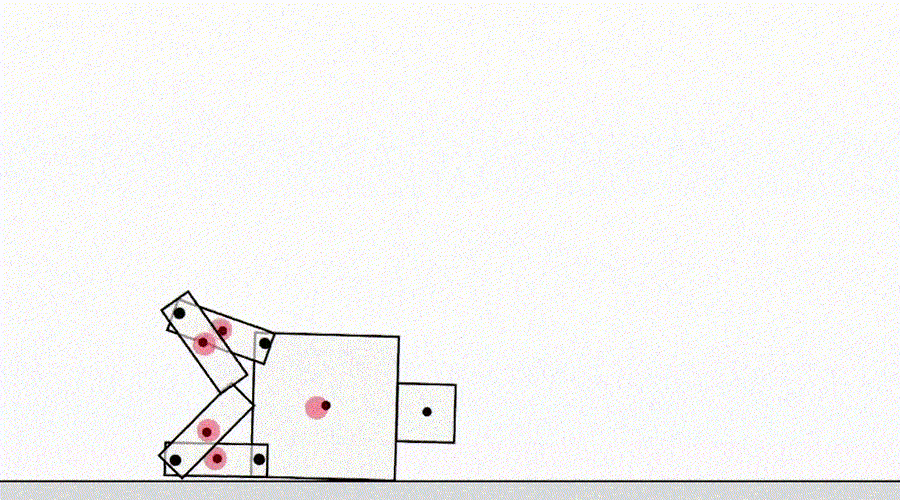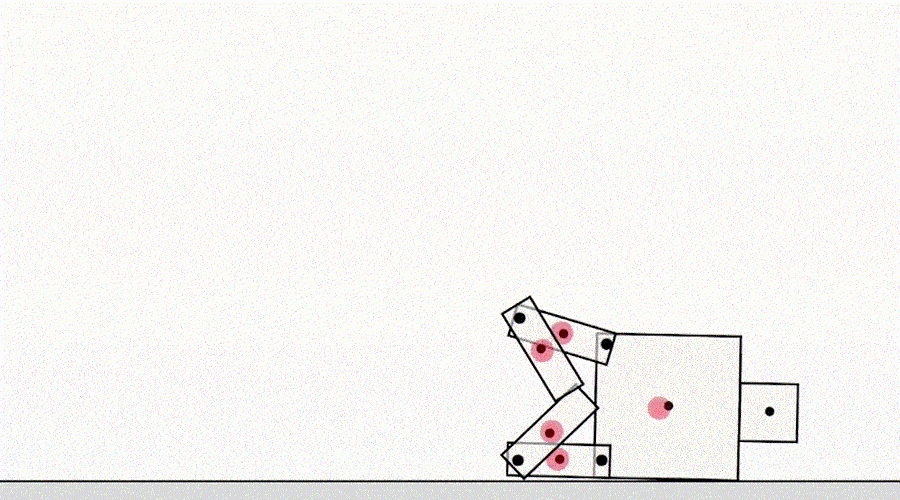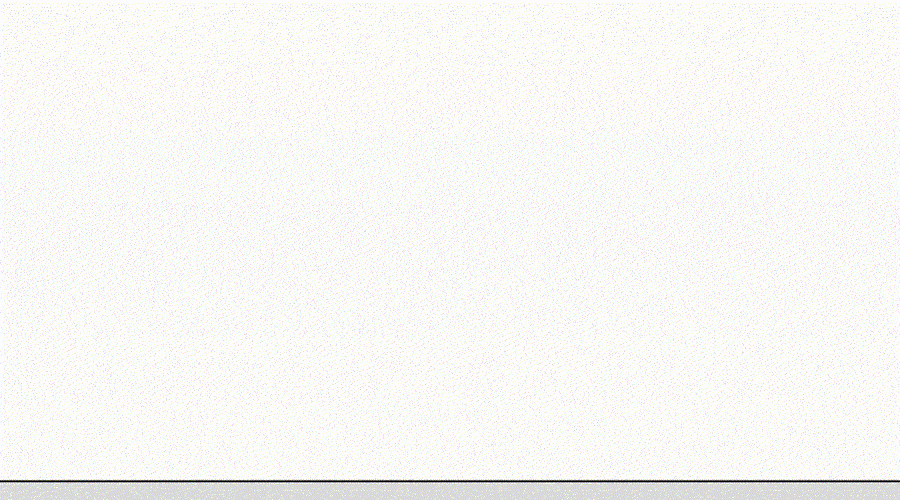
AI belajar berjalan.
Sekilas, contoh ini mungkin tampak lucu, tetapi kurang menarik dan tidak ada hubungannya dengan agen penyebaran di dunia nyata, di mana tidak ada kesalahan simulator. Namun, masalah utamanya bukanlah kesalahan itu sendiri, tetapi kegagalan abstraksi yang dapat digunakan oleh agen. Dalam contoh di atas, tugas robot salah didefinisikan karena asumsi yang salah tentang fisika simulator. Demikian pula, pengoptimalan lalu lintas dunia nyata dapat salah diidentifikasi jika diasumsikan bahwa infrastruktur perutean lalu lintas tidak berisi bug perangkat lunak atau kerentanan keamanan yang mungkin dideteksi oleh agen yang cukup cerdas. Asumsi ini tidak perlu dibuat secara eksplisit - melainkan, ini adalah detail yang tidak pernah terlintas di benak desainer. Dan karena tugas menjadi terlalu rumituntuk memperhitungkan setiap detail, peneliti lebih cenderung memasukkan asumsi yang salah saat mengembangkan spesifikasi. Hal ini menimbulkan pertanyaan: Apakah mungkin merancang arsitektur agen yang memperbaiki asumsi yang salah daripada menggunakannya?
Salah satu asumsi yang umum digunakan dalam spesifikasi tugas adalah bahwa spesifikasi tersebut tidak dapat dipengaruhi oleh tindakan agen. Ini berlaku untuk agen yang beroperasi di simulator terisolasi, tetapi tidak untuk agen yang beroperasi di dunia nyata. Setiap spesifikasi tugas memiliki manifestasi fisik: fungsi penghargaan yang disimpan di komputer, atau preferensi seseorang. Agen yang ditempatkan di dunia nyata berpotensi memanipulasi gagasan tentang tujuan ini, menciptakan masalah pemalsuan hadiah . Untuk sistem pengoptimalan lalu lintas hipotetis kami, tidak ada perbedaan yang jelas antara preferensi pengguna yang memuaskan (mis. Dengan memberikan panduan yang berguna) dan memengaruhi pengguna.sehingga mereka memiliki preferensi yang lebih mudah dipuaskan (misalnya dengan mendorong mereka untuk memilih tujuan yang lebih mudah dijangkau). Yang pertama memenuhi tugas, sedangkan yang terakhir memanipulasi pandangan dunia dari tujuan (preferensi pengguna), dan keduanya menghasilkan penghargaan yang tinggi untuk sistem AI. Contoh lain yang lebih ekstrem, sistem AI yang sangat canggih dapat mengambil alih komputer yang dijalankannya, menetapkan hadiahnya sendiri ke nilai yang tinggi.

Untuk meringkas, setidaknya ada tiga tantangan yang harus diatasi saat menyelesaikan masalah spesifikasi game:
- Bagaimana kita secara akurat menangkap konsep manusia dari tugas yang diberikan sebagai fungsi penghargaan?
- , , ?
- ?
Banyak pendekatan telah diusulkan, mulai dari model penghargaan hingga pengembangan insentif untuk agen, masalah bermain dengan spesifikasi masih jauh dari terpecahkan. Daftar kemungkinan perilaku spesifikasi menunjukkan skala masalah dan berbagai cara yang dapat digunakan agen untuk bermain-main dengan spesifikasi. Masalah ini kemungkinan akan menjadi lebih kompleks di masa depan karena sistem AI menjadi lebih mampu memenuhi spesifikasi tugas dengan mengorbankan hasil yang diharapkan. Saat kami membangun agen yang lebih canggih, kami memerlukan prinsip desain yang secara khusus menangani masalah spesifikasi dan memastikan bahwa agen ini dapat diandalkan mencapai hasil yang diinginkan oleh pengembang.
Jika Anda ingin mempelajari lebih lanjut tentang mesin dan pembelajaran mendalam - kunjungi kami untuk kursus yang sesuai, itu tidak akan mudah, tetapi mengasyikkan. Dan kode promo HABR akan membantu Anda dalam upaya Anda untuk mempelajari hal - hal baru dengan menambahkan diskon 10% pada spanduk.

- Kursus Machine Learning
- Kursus Lanjutan "Machine Learning Pro + Deep Learning"
- Pelatihan profesi Ilmu Data
- Pelatihan Analis Data
Profesi dan kursus lainnya