Tapi, karena orang bukan komputer, mereka mencari sesuatu seperti " sesuatu seperti itu dari Ivanov atau dari Ivanovsky ... tidak, bukan itu, sebelumnya, bahkan lebih awal ... ini dia! "
Tapi ini mengancam pengembang dengan masalah yang mengerikan - lagipula, untuk pencarian FTS di PostgreSQL , tipe "spasial" indeks GIN dan GiST digunakan , yang tidak menyediakan "slip" data tambahan, kecuali untuk vektor teks.
Tetap sedih hanya untuk membaca semua catatan dengan pencocokan awalan (ribuan dari mereka!) Dan urutkan atau, sebaliknya, lihat indeks tanggal dan filtersemua entri yang ditemukan untuk prefiks cocok sampai kami menemukan entri yang cocok (seberapa cepat akan ada "omong kosong"? ..).
Keduanya tidak terlalu menyenangkan untuk kinerja kueri. Atau masih dapatkah Anda memikirkan sesuatu untuk pencarian cepat?
Pertama, mari buat "teks-to-date" kami:
CREATE TABLE corpus AS
SELECT
id
, dt
, str
FROM
(
SELECT
id::integer
, now()::date - (random() * 1e3)::integer dt -- - 3
, (random() * 1e2 + 1)::integer len -- "" 100
FROM
generate_series(1, 1e6) id -- 1M
) X
, LATERAL(
SELECT
string_agg(
CASE
WHEN random() < 1e-1 THEN ' ' -- 10%
ELSE chr((random() * 25 + ascii('a'))::integer)
END
, '') str
FROM
generate_series(1, len)
) Y;
Pendekatan naif # 1: gist + btree
Mari kita coba menggulung indeks untuk FTS dan untuk mengurutkan berdasarkan tanggal - bagaimana jika mereka membantu:
CREATE INDEX ON corpus(dt);
CREATE INDEX ON corpus USING gist(to_tsvector('simple', str));
Kami akan mencari semua dokumen yang berisi kata-kata yang dimulai dengan
'abc...'
. Dan, pertama-tama, mari kita periksa apakah ada beberapa dokumen seperti itu, dan indeks FTS digunakan secara normal:
SELECT
*
FROM
corpus
WHERE
to_tsvector('simple', str) @@ to_tsquery('simple', 'abc:*');
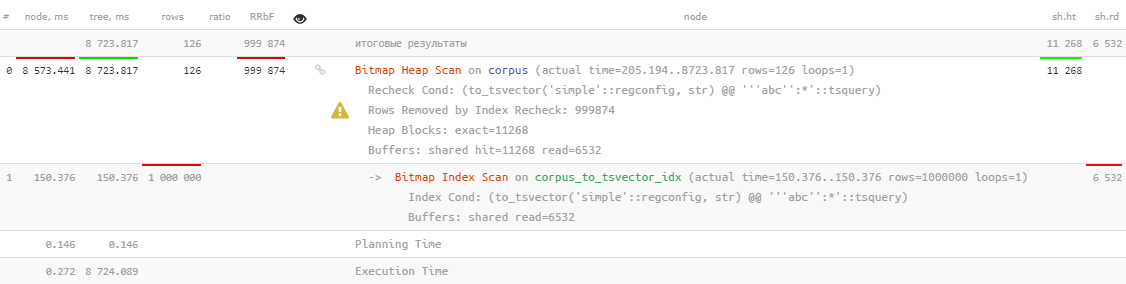
Ya ... ini, tentu saja, digunakan, tetapi membutuhkan lebih dari 8 detik , yang jelas bukan yang kami ingin habiskan untuk mencari 126 rekaman.
Mungkin jika Anda menambahkan pengurutan berdasarkan tanggal dan hanya mencari 10 catatan terakhir - itu menjadi lebih baik?
SELECT
*
FROM
corpus
WHERE
to_tsvector('simple', str) @@ to_tsquery('simple', 'abc:*')
ORDER BY
dt DESC
LIMIT 10;

Tapi tidak, hanya penyortiran yang ditambahkan di atas.
Pendekatan naif # 2: btree_gist
Tetapi ada ekstensi luar biasa
btree_gist
yang memungkinkan Anda untuk "menyelipkan" nilai skalar ke dalam indeks GiST, yang memungkinkan kita untuk segera menggunakan pengurutan indeks menggunakan operator jarak
<->
, yang dapat digunakan untuk pencarian kNN :
CREATE EXTENSION btree_gist;
CREATE INDEX ON corpus USING gist(to_tsvector('simple', str), dt);
SELECT
*
FROM
corpus
WHERE
to_tsvector('simple', str) @@ to_tsquery('simple', 'abc:*')
ORDER BY
dt <-> '2100-01-01'::date DESC -- ""
LIMIT 10;
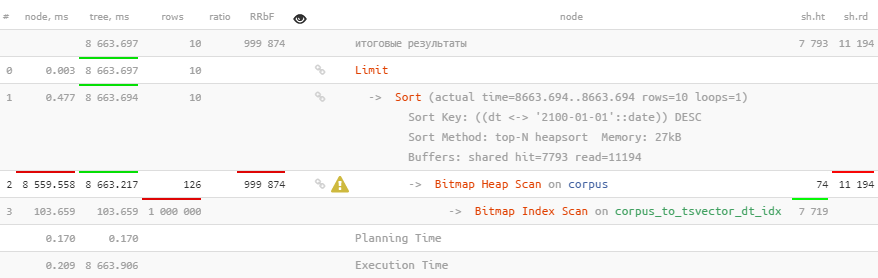
Sayangnya, ini tidak membantu sama sekali.
Geometri untuk menyelamatkan!
Tapi masih terlalu dini untuk putus asa! Mari kita lihat daftar kelas operator GiST built-in - operator jarak hanya
<->
tersedia untuk "geometris"
circle_ops, point_ops, poly_ops
, dan sejak PostgreSQL 13 - untuk
box_ops
.
Jadi, mari kita coba menerjemahkan tugas kita "menjadi pesawat" - kita akan menetapkan koordinat dari beberapa titik ke pasangan
(, )
kita yang digunakan untuk pencarian sehingga kata "awalan" dan tanggal yang tidak jauh menjadi sedekat mungkin:

Kami memecah teks menjadi kata-kata
Tentu saja pencarian kita tidak akan full text, dalam artian anda tidak bisa menetapkan kondisi untuk beberapa kata pada waktu yang bersamaan. Tapi itu pasti akan menjadi awalan!
Mari kita bentuk tabel kamus tambahan:
CREATE TABLE corpus_kw AS
SELECT
id
, dt
, kw
FROM
corpus
, LATERAL (
SELECT
kw
FROM
regexp_split_to_table(lower(str), E'[^\\-a-z-0-9]+', 'i') kw
WHERE
length(kw) > 1
) T;
Dalam contoh kami, ada 4,8 juta "kata" per 1 juta "teks".
Menaruh kata-kata
Untuk menerjemahkan sebuah kata menjadi "koordinat" -nya, mari kita bayangkan bahwa ini adalah angka yang ditulis dalam notasi dasar
2^16
(bagaimanapun, kami juga ingin mendukung karakter UNICODE). Kami hanya akan menuliskannya mulai dari posisi tetap ke-47:
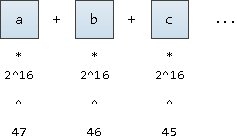
Dimungkinkan untuk memulai dari posisi ke-63, ini akan memberi kami nilai sedikit lebih kecil dari nilai
1E+308
batasnya
double precision
, tetapi kemudian akan terjadi luapan saat membangun indeks.
Ternyata pada sumbu koordinat semua kata akan diurutkan:

ALTER TABLE corpus_kw ADD COLUMN p point;
UPDATE
corpus_kw
SET
p = point(
(
SELECT
sum((2 ^ 16) ^ (48 - i) * ascii(substr(kw, i, 1)))
FROM
generate_series(1, length(kw)) i
)
, extract('epoch' from dt)
);
CREATE INDEX ON corpus_kw USING gist(p);
Kami membentuk permintaan pencarian
WITH src AS (
SELECT
point(
( --
SELECT
sum((2 ^ 16) ^ (48 - i) * ascii(substr(kw, i, 1)))
FROM
generate_series(1, length(kw)) i
)
, extract('epoch' from dt)
) ps
FROM
(VALUES('abc', '2100-01-01'::date)) T(kw, dt) --
)
SELECT
*
, src.ps <-> kw.p d
FROM
corpus_kw kw
, src
ORDER BY
d
LIMIT 10;

Sekarang kami memiliki
id
dokumen yang diperlukan, sudah diurutkan dalam urutan yang benar - dan butuh waktu kurang dari 2ms, 4000 kali lebih cepat !
Seekor lalat kecil di salep
Operator
<->
tidak tahu apa-apa tentang pengurutan kami sepanjang dua sumbu, jadi data yang kami butuhkan hanya terletak di salah satu tempat yang tepat, tergantung pada pengurutan yang diperlukan berdasarkan tanggal:

Ya, kami masih ingin memilih teks-dokumen itu sendiri, dan bukan kata kuncinya, jadi kita membutuhkan indeks yang sudah lama terlupakan:
CREATE UNIQUE INDEX ON corpus(id);
Mari selesaikan permintaan:
WITH src AS (
SELECT
point(
(
SELECT
sum((2 ^ 16) ^ (48 - i) * ascii(substr(kw, i, 1)))
FROM
generate_series(1, length(kw)) i
)
, extract('epoch' from dt)
) ps
FROM
(VALUES('abc', '2100-01-01'::date)) T(kw, dt) --
)
, dc AS (
SELECT
(
SELECT
dc
FROM
corpus dc
WHERE
id = kw.id
)
FROM
corpus_kw kw
, src
WHERE
p[0] >= ps[0] AND -- kw >= ...
p[1] <= ps[1] -- dt DESC
ORDER BY
src.ps <-> kw.p
LIMIT 10
)
SELECT
(dc).*
FROM
dc;

Mereka menambahkan sedikit kepada kami
InitPlan
dengan perhitungan konstanta x / y, tetapi tetap kami tetap dalam 2 md yang sama !
Terbang di salep # 2
Tidak ada yang gratis:
SELECT relname, pg_size_pretty(pg_total_relation_size(oid)) FROM pg_class WHERE relname LIKE 'corpus%';
corpus | 242 MB -- corpus_id_idx | 21 MB -- PK corpus_kw | 705 MB -- corpus_kw_p_idx | 403 MB -- GiST-
242 MB "teks" menjadi 1,1 GB "indeks penelusuran".
Tapi bagaimanapun juga,
corpus_kw
tanggal dan kata itu sendiri ada di dalamnya, yang belum pernah kita gunakan dalam pencarian - jadi mari kita hapus:
ALTER TABLE corpus_kw
DROP COLUMN kw
, DROP COLUMN dt;
VACUUM FULL corpus_kw;
corpus_kw | 641 MB -- id point
Agak - tapi bagus. Itu tidak membantu terlalu banyak, tetapi tetap 10% dari volume dimenangkan kembali.