
Simulator Injeksi Kesalahan (FIS) AWS- alat yang memungkinkan Anda menerapkan skenario kegagalan sistem internal yang diketahui sebelumnya dalam layanan AWS. Untuk apa? - sehingga tim dapat menyusun skenario untuk eliminasi mereka dan, secara umum, mengevaluasi perilaku produk mereka dalam kondisi yang diusulkan Sistem akan segera menawarkan beberapa template dengan skenario kegagalan, misalnya server melambat, kegagalannya, kesalahan dalam mengakses database atau crash. Pada saat yang sama, FIS akan memastikan bahwa percobaan tidak berjalan terlalu jauh dan ketika parameter tertentu tercapai, pengujian akan dihentikan, dan sistem akan kembali normal. Slogan utama dari produk baru raksasa cloud ini adalah "meningkatkan ketahanan dan kinerja menggunakan teknologi chaos yang terkontrol". Rilis sistem pengujian baru dijadwalkan pada tahun 2021.
AWS juga menawarkan pengujian dan sistem virtual terdistribusi yang kurang bergantung pada satu host. Kekhususan kegagalan dalam sistem terdistribusi adalah bahwa masalahnya dapat bersifat siklis dan memiliki struktur yang lebih kompleks. Fitur AWS baru akan memungkinkan Anda mencari kerentanan tidak hanya di infrastruktur monolit, tetapi juga di sistem dan aplikasi terdistribusi.
Mari kita lihat mengapa ini penting dan keren.
Rekayasa chaos adalah proses pengujian simulasi di mana serangan utama ke sistem berasal dari dalam dan memengaruhi infrastruktur proyek. Tim mensimulasikan situasi di mana bagian infrastruktur dari proyek dihadapkan pada masalah teknis dan masalah lainnya, misalnya, dengan titik atau penurunan sistemik dalam kinerja pada instans. Ini juga dapat mencakup kerusakan server, kegagalan API, dan mimpi buruk lain dari backend yang mungkin ditemui tim kapan saja atau, lebih buruk lagi, pada hari versi berikutnya dirilis.
Belum ada definisi yang jelas tentang chaos engineering, jadi berikut adalah beberapa yang paling populer dan, menurut kami, opsi yang akurat. Rekayasa chaos adalah: "suatu pendekatan untuk bereksperimen dengan sistem produksi untuk memastikannya dapat menahan berbagai jenis gangguan selama operasi" dan "eksperimen untuk mengurangi efek gangguan".
Mengapa AWS Fault Injection Simulator dibutuhkan sama sekali
Pengembang alat mengutip beberapa alasan mengapa FIS akan berguna bagi tim saat menguji dan menyiapkan sistem mereka.
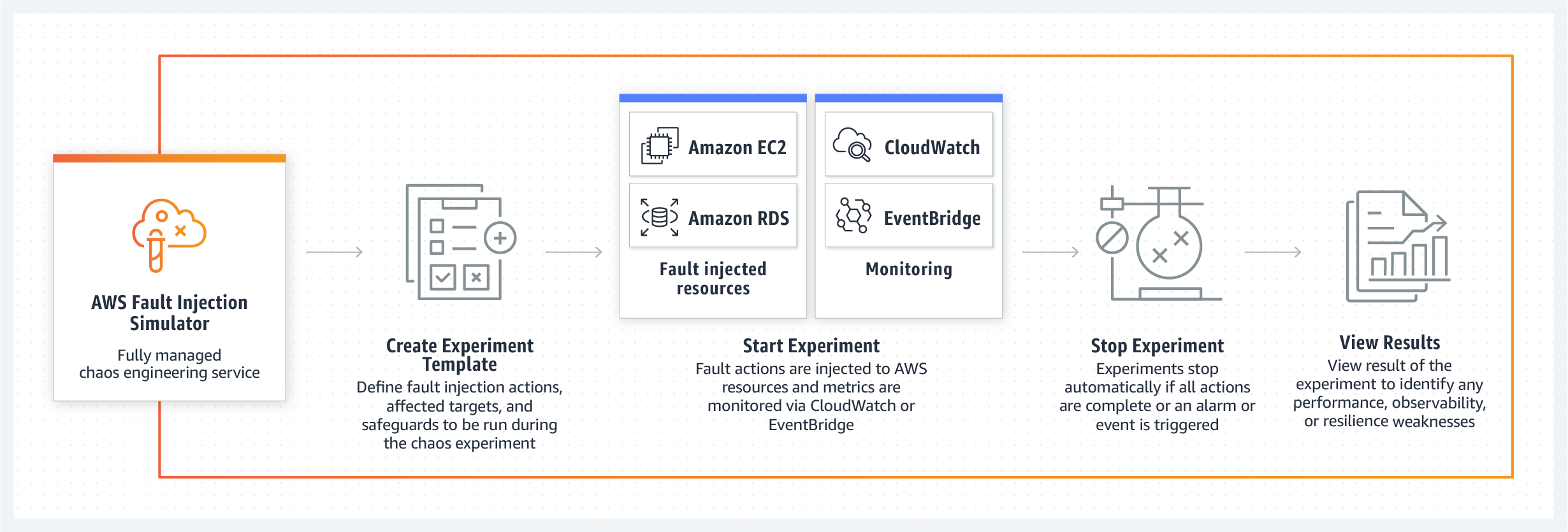
Kinerja sistem, ketahanan, dan transparansi adalah salah satu pesan inti tim AWS FIS.
AWS Fault Injection Simulator , , «» , .
Faktanya, metode pengujian yang biasa, pertama-tama, adalah simulasi beban eksternal pada sistem. Misalnya, simulasi efek habra atau serangan DDoS eksternal pada sistem atau layanan. Paling sering, semua sistem pemantauan utama terikat secara tepat ke node ini, sementara pelacakan perilaku infrastruktur internal, seringkali, terbatas hanya untuk menerima data dalam gaya "turun / turun" atau beban pada CPU. Pada saat yang sama, kerusakan terbesar dan kegagalan paling kuat dalam beberapa tahun terakhir justru dikaitkan dengan kegagalan internal atau kesalahan infrastruktur. Cukuplah untuk mengingat crash CloudFlare tahun lalu, ketika, karena sejumlah kegagalan dan kesalahan, pengembang benar-benar memaksa setengah dari Internet untuk "berbaring" dengan tangan mereka sendiri.
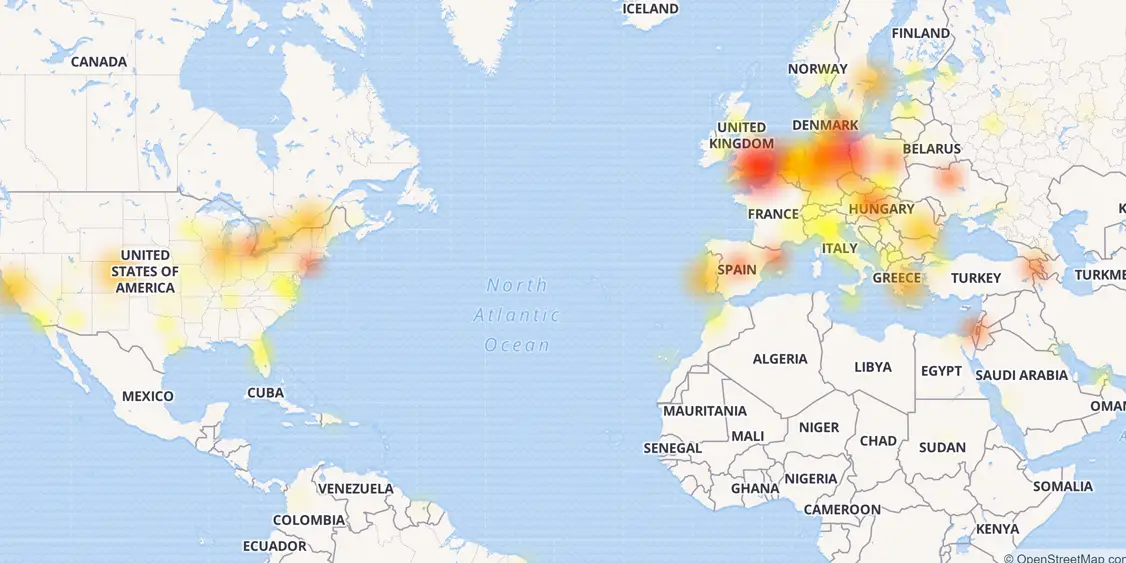
Peta kegagalan CloudFlare itu
Alat baru ini mampu mengerjakan template siap pakai untuk skenario kegagalan database, API, atau penurunan performa, serta membuat kondisi uji buta acak di mana masalah akan muncul dalam urutan arbitrer di node yang berbeda.
Poin kuat lainnya dari toolkit AWS baru adalah kemampuan kontrol dari kekacauan yang dibuat oleh tim dalam sistem. Insinyur memastikan bahwa dengan bantuan panel kontrol mereka, pengembang dapat menghentikan skenario kegagalan terkontrol kapan saja dan mengembalikan sistem ke kondisi kerja semula. Simulator Injeksi Kesalahan mendukung Amazon CloudWatch dan alat pemantauan pihak ketiga yang terhubung melalui Amazon EventBridge, sehingga pengembang dapat menggunakan metrik mereka untuk memantau eksperimen kekacauan terkontrol. Dan, tentu saja, setelah menghentikan pengujian, administrator akan menerima laporan lengkap tentang node mana dari sistem dan dalam urutan apa yang terpengaruh oleh kegagalan, yang di masa mendatang akan membantu mengembangkan serangkaian tindakan dan prosedur untuk melokalkan dan menghilangkan masalah.
Bagaimana Lord of Chaos terbentuk
Jelas, pengujian tekanan sistem seperti itu paling logis untuk dilakukan dalam periode pra-rilis untuk memastikan bahwa infrastruktur yang ada di AWS akan tahan terhadap tambalan baru. Namun, pada kenyataannya, teknik rekayasa chaos kembali ke praktik lama, yang pendirinya adalah salah satu pengelola Amazon di tahun 2000-an, Jesse Robbins. Posisinya secara resmi disebut "Master of Disaster", yang dalam terjemahan yang menyedihkan bisa disalahartikan sebagai "Lord of Disasters", dan dalam versi gratis posisinya terdengar seperti "Master Lomaster".
 Itu adalah Robbins, mantan petugas pemadam kebakaran penyelamat, yang
menerapkan GameDay ke Amazon.... Tujuan dari inisiatif Robbins sangat sederhana - untuk memberi tim teknik pemahaman intuitif tentang cara menangani bencana, seperti perasaan yang dilatihkan dalam pemadam kebakaran. Untuk inilah metode simulasi global dari total chaos dipilih: semuanya rusak dari semua sisi, secara bersamaan atau berurutan, dan setiap upaya untuk mengatasi kegagalan mengarah pada masalah baru dan baru.
Itu adalah Robbins, mantan petugas pemadam kebakaran penyelamat, yang
menerapkan GameDay ke Amazon.... Tujuan dari inisiatif Robbins sangat sederhana - untuk memberi tim teknik pemahaman intuitif tentang cara menangani bencana, seperti perasaan yang dilatihkan dalam pemadam kebakaran. Untuk inilah metode simulasi global dari total chaos dipilih: semuanya rusak dari semua sisi, secara bersamaan atau berurutan, dan setiap upaya untuk mengatasi kegagalan mengarah pada masalah baru dan baru.
Ketika orang yang tidak siap dihadapkan dengan kerusuhan elemen, dia, paling sering, jatuh pingsan atau panik. Sebagian besar pengembang dan insinyur tidak siap secara psikologis untuk situasi di mana penyelesaian masalah harus memakan waktu tiga hari, dan tingkat stres di sekitarnya tidak sesuai skala.
Robbins menyebut hasil paling penting dari GameDay sebagai efek psikologis dari latihan semacam itu: mereka mengembangkan kemampuan untuk menerima fakta bahwa gangguan skala besar terjadi . Ini adalah penerimaan fakta bahwa segala sesuatu di sekitar terbakar dan runtuh, dia menyebutnya sangat penting bagi insinyur, sehingga dia dapat mengumpulkan pikirannya dan akhirnya mulai "memadamkan api." Orang yang tidak terlatih akan, paling banter, berputar-putar dan meneriakkan "semuanya hilang".
Setelah pengenalan praktik GameDay, ternyata latihan semacam itu dengan sempurna mengungkap masalah arsitektur dan hambatan yang tidak diperhatikan selama pengujian dan verifikasi klasik.
Perbedaan signifikan lainnya antara GameDay dan latihan "pelatihan dan ketertiban" kami yang biasa adalah hanya sedikit orang yang mengetahui skenario spesifik dan apa yang akan terjadi secara umum. Informasi mengenai "games" yang akan datang diberikan sangat umum dan samar-samar, sehingga peserta tidak bisa sepenuhnya mempersiapkan acara ini. Idealnya, mengumumkan hanya tanggal "permainan hari" berikutnya tanpa klarifikasi sama sekali, agar peserta tidak salah mengira itu sebagai kecelakaan nyata. Tentu saja, metodologi ini tidak berlaku untuk perusahaan besar, misalnya, GameDay tidak dapat dilakukan di seluruh Yandex atau Microsoft sekaligus.
Hasilnya, praktik tersebut dimodernisasi menjadi GameDay lokal dan diperkenalkan di semua perusahaan IT besar yang ada, misalnya, di Google, Flickr, dan banyak lainnya. Ia memiliki Master of Disasters-nya sendiri (well, atau Master-Lommasters, sesuka Anda), yang mengatur kegagalan pelatihan dan kemudian menganalisis hasil yang diperoleh pada proyek tertentu.
Kesulitan utama dalam menerapkan praktik ini di mana-mana terletak pada dua aspek: bagaimana mengaturnya dan bagaimana mengumpulkan data agar GameDay tidak sia-sia. Itulah sebabnya, di perusahaan kecil, teknik ini tidak banyak digunakan hingga saat ini (jika digunakan sama sekali). Alih-alih GameDay dan simulasi bencana, bisnis lebih berfokus pada jenis pengujian yang berbeda, CI / CD, dan metodologi lain untuk pengembangan yang teratur dan konsisten. Yaitu, untuk mencegah terjadinya malapetaka.
Perangkat AWS yang baru akan memungkinkan Anda menangani sisi lain gangguan: alih-alih pencegahan, yang tidak diragukan lagi penting, FIS akan memungkinkan tim teknik dari semua ukuran untuk berlatih secara efektif dalam menyelesaikan kegagalan infrastruktur global. Lagi pula, hal utama yang dicatat Robbins adalah bahwa bencana tetap terjadi: mereka tidak dapat dihindari.