
Ada banyak pendekatan untuk membuat kode aplikasi untuk menjaga kompleksitas proyek dari waktu ke waktu. Misalnya, pendekatan berorientasi objek dan banyak pola terlampir memungkinkan, jika tidak menjaga kompleksitas proyek pada tingkat yang sama, maka setidaknya tetap di bawah kendali selama pengembangan, dan membuat kode tersedia untuk pemrogram baru dalam tim.
Bagaimana Anda dapat mengelola kompleksitas proyek transformasi ETL di Spark?
Tidak sesederhana itu.
Seperti apa di kehidupan nyata? Pelanggan menawarkan untuk membuat aplikasi yang mengumpulkan etalase. Tampaknya perlu menjalankan kode melalui Spark SQL dan menyimpan hasilnya. Dalam pengembangannya, ternyata dibutuhkan 20 sumber data untuk membangun mart ini, 15 diantaranya mirip, sisanya tidak. Sumber-sumber ini harus digabungkan. Kemudian ternyata untuk setengahnya, Anda perlu menulis prosedur perakitan, pembersihan, dan normalisasi Anda sendiri.
Dan etalase sederhana, setelah deskripsi mendetail, mulai terlihat seperti ini:
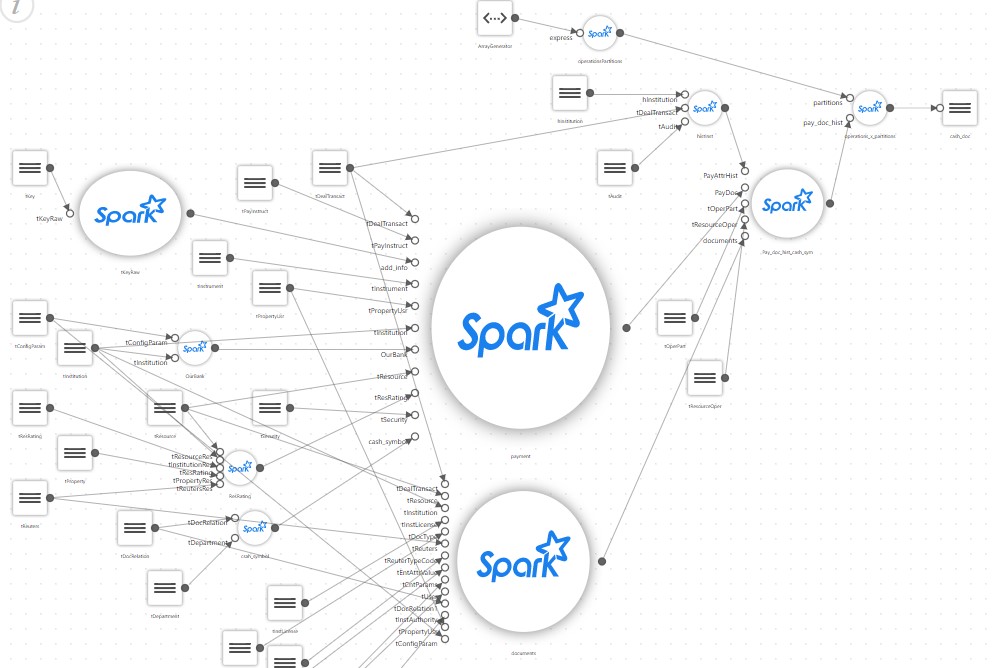
Akibatnya, proyek sederhana yang seharusnya hanya menjalankan skrip SQL yang mengumpulkan etalase di Spark memperoleh konfiguratornya sendiri, blok untuk membaca sejumlah besar file konfigurasi, cabang pemetaannya sendiri, penerjemah beberapa aturan khusus dll.
Di tengah proyek, ternyata hanya penulis yang dapat mendukung kode yang dihasilkan. Dan dia menghabiskan sebagian besar waktunya untuk berpikir. Sementara itu, pelanggan meminta untuk mengumpulkan beberapa pajangan lagi, sekali lagi berdasarkan ratusan sumber. Pada saat yang sama, kita harus ingat bahwa Spark umumnya tidak terlalu cocok untuk membuat kerangka kerja Anda sendiri.
Misalnya, Spark dirancang untuk membuat kodenya terlihat seperti ini (pseudocode):
park.sql(“select table1.field1 from table1, table2 where table1.id = table2.id”).write(...pathToDestTable)
Sebaliknya, Anda harus melakukan sesuatu seperti ini:
var Source1 = readSourceProps(“source1”) var sql = readSQL(“destTable”) writeSparkData(source1, sql)
Artinya, mengambil blok kode ke dalam prosedur terpisah dan mencoba menulis sesuatu milik Anda sendiri, universal, yang dapat disesuaikan dengan pengaturan.
Pada saat yang sama, kompleksitas proyek tetap pada tingkat yang sama, tentu saja, tetapi hanya untuk pembuat proyek, dan hanya untuk waktu yang singkat. Setiap programmer yang diundang akan membutuhkan waktu lama untuk menguasainya, dan yang utama adalah tidak mungkin menarik orang yang hanya tahu SQL ke proyek.
Hal ini sangat disayangkan, karena Spark sendiri merupakan cara yang bagus untuk mengembangkan aplikasi ETL bagi mereka yang hanya mengetahui SQL.
Dan dalam perjalanan pengembangan proyek, ternyata hal yang sederhana berubah menjadi yang kompleks.
Sekarang bayangkan sebuah proyek nyata, di mana terdapat lusinan, atau bahkan ratusan, etalase seperti pada gambar, dan mereka menggunakan teknologi yang berbeda, misalnya, beberapa dapat didasarkan pada penguraian data XML, dan beberapa pada data streaming.
Saya ingin menjaga kompleksitas proyek pada tingkat yang dapat diterima. Bagaimana ini bisa dilakukan?
Solusinya mungkin dengan menggunakan alat dan pendekatan kode rendah, ketika lingkungan pengembangan memutuskan untuk Anda, yang mengambil semua kompleksitas, menawarkan beberapa pendekatan yang nyaman, seperti, misalnya, dijelaskan dalam artikel ini .
Artikel ini menjelaskan pendekatan dan manfaat menggunakan alat untuk memecahkan masalah semacam ini. Secara khusus, Neoflex menawarkan solusinya sendiri Neoflex Datagram, yang berhasil digunakan oleh pelanggan yang berbeda.
Tetapi tidak selalu mungkin untuk menggunakan aplikasi seperti itu.
Apa yang harus dilakukan?
Dalam hal ini, kami menggunakan pendekatan yang secara konvensional disebut Orc - Object Spark, atau Orka, sesuka Anda.
Data awal adalah sebagai berikut:
Ada pelanggan yang menyediakan tempat kerja yang memiliki seperangkat alat standar, yaitu: Hue untuk mengembangkan kode Python atau Scala, editor Hue untuk debugging SQL melalui Hive atau Impala, dan Editor alur kerja Oozie. Ini tidak banyak, tapi cukup untuk memecahkan masalah. Tidak mungkin menambahkan sesuatu ke lingkungan, tidak mungkin memasang alat baru, karena berbagai alasan.
Jadi, bagaimana Anda mengembangkan aplikasi ETL yang, seperti biasa, akan tumbuh menjadi proyek besar, di mana ratusan tabel sumber data dan lusinan target mart akan terlibat, tanpa tenggelam dalam kerumitan dan tidak terlalu banyak menulis?
Sejumlah ketentuan digunakan untuk menyelesaikan masalah tersebut. Mereka bukan penemuan mereka sendiri, tetapi seluruhnya didasarkan pada arsitektur Spark itu sendiri.
- Semua gabungan, penghitungan, dan transformasi yang kompleks dilakukan melalui Spark SQL. Pengoptimal Spark SQL meningkat dengan setiap rilis dan bekerja dengan sangat baik. Oleh karena itu, kami memberikan semua pekerjaan penghitungan Spark SQL kepada pengoptimal. Artinya, kode kita bergantung pada rantai SQL, di mana langkah 1 menyiapkan data, langkah 2 bergabung, langkah 3 menghitung, dan seterusnya.
- Spark, Spark SQL. (DataFrame) Spark SQL.
- Spark Directed Acicled Graph, , , , , 2, 2.
- Spark lazy, , , .
Hasilnya, seluruh aplikasi bisa dibuat sangat sederhana.
Cukup membuat file konfigurasi untuk menentukan daftar sumber data tingkat tunggal. Daftar sumber data berurutan ini adalah objek yang mendeskripsikan logika seluruh aplikasi.
Setiap sumber data berisi link ke SQL. Dalam SQL untuk sumber saat ini, Anda dapat menggunakan sumber yang tidak ada di Hive, tetapi dijelaskan dalam file konfigurasi di atas yang sekarang.
Misalnya, sumber 2, ketika diterjemahkan ke dalam kode Spark, terlihat seperti ini (kodesemu):
var df = spark.sql(“select * from t1”); df.saveAsTempTable(“source2”);
Dan sumber 3 mungkin sudah terlihat seperti ini:
var df = spark.sql(“select count(*) from source2”) df.saveAsTempTable(“source3”);
Artinya, sumber 3 melihat semua yang telah dihitung sebelumnya.
Dan untuk sumber yang merupakan showcase target, Anda harus menentukan parameter untuk menyimpan showcase target ini.
Hasilnya, file konfigurasi aplikasi terlihat seperti ini:
[{name: “source1”, sql: “select * from t1”}, {name: “source2”, sql: “select count(*) from source1”}, ... {name: “targetShowCase1”, sql: “...”, target: True, format: “PARQET”, path: “...”}]
Dan kode aplikasinya terlihat seperti ini:
List = readCfg(...) For each source in List: df = spark.sql(source.sql).saveAsTempTable(source.name) If(source.target == true) { df.write(“format”, source.format).save(source.path) }
Ini sebenarnya adalah keseluruhan aplikasi. Tidak ada lagi yang dibutuhkan kecuali satu saat.
Bagaimana cara men-debug semua ini?
Bagaimanapun, kode itu sendiri dalam kasus ini sangat sederhana, apa yang ada untuk di-debug, tetapi logika dari apa yang sedang dilakukan akan bagus untuk diperiksa. Debugging sangat sederhana - Anda harus melalui semua aplikasi ke sumber yang diperiksa. Untuk melakukannya, tambahkan parameter ke alur kerja Oozie yang memungkinkan Anda menghentikan aplikasi di sumber data yang diperlukan dengan mencetak skema dan kontennya ke log.
Kami menyebut pendekatan ini Object Spark dalam arti bahwa semua logika aplikasi dipisahkan dari kode Spark dan disimpan dalam satu file konfigurasi yang cukup sederhana, yang merupakan objek deskripsi aplikasi.
Kode tetap sederhana, dan setelah dibuat, bahkan etalase yang kompleks dapat dikembangkan menggunakan pemrogram yang hanya tahu SQL.
Proses pengembangannya sangat sederhana. Pada awalnya, programmer Spark berpengalaman terlibat, yang membuat kode universal, dan kemudian file konfigurasi aplikasi diedit dengan menambahkan sumber baru di sana.
Apa yang diberikan pendekatan ini:
- Anda dapat melibatkan pemrogram SQL dalam pengembangan;
- Dengan adanya parameter di Oozie, men-debug aplikasi seperti itu menjadi mudah dan sederhana. Ini sedang men-debug langkah perantara apa pun. Aplikasi akan mengerjakan semuanya ke sumber yang diinginkan, menghitungnya, dan berhenti;
- ( … ), , , , , . , Object Spark;
- , . . , , , XML JSON, -. , ;
- . , , , , .