
Hari ini kita akan berbicara tentang topik yang tampaknya sederhana seperti data relasional dan terkait.
Terlepas dari semua kesederhanaannya, saya perhatikan bahwa terkadang orang benar-benar bingung tentang mereka - Saya memutuskan untuk memperbaikinya dengan menulis penjelasan singkat dan informal tentang apa itu dan mengapa mereka dibutuhkan.
Kita akan membahas apa itu model relasional dan SQL terkait serta aljabar relasional. Kemudian mari beralih ke contoh data terkait dari Wikidat, lalu RDF, SPARQL dan sedikit berbicara tentang Datalog dan representasi data logis. Pada akhirnya, kesimpulan - kapan menerapkan model relasional, dan kapan model logis terhubung.
Tujuan utama posting adalah untuk menjelaskan kapan hal yang masuk akal untuk diterapkan dan mengapa. Karena ada banyak konsep sulit yang bersatu di satu tempat, tentu dimungkinkan untuk menulis sebuah buku untuk masing-masing - tetapi tugas kita hari ini adalah memberikan gambaran tentang topik tersebut dan kita akan menganalisisnya secara informal menggunakan contoh-contoh sederhana.
Jika Anda ragu tentang bagaimana satu berbeda dari yang kedua dan mengapa Anda membutuhkan data tertaut (LinkedData) sama sekali, maka selamat datang di bawah cat.

Data relasional
Mari kita mulai dengan definisi standar.
Database relasional adalah kumpulan data dengan hubungan yang telah ditentukan sebelumnya. Data ini disusun sebagai satu set tabel yang terdiri dari kolom dan baris. Tabel menyimpan informasi tentang objek yang direpresentasikan dalam database.
Saat diterapkan:
- Pemodelan domain tetap
- Skema data berubah sedikit, atau perubahan tersebut langsung memengaruhi grup record yang signifikan
- Kueri dasar - memfilter kategori berdasarkan bidang catatan utama, agregasi, membuat laporan dan analitik berdasarkan indikator statistik, dll
Dalam situasi ini, unit pemodelan adalah tabel dan hubungan antar tabel (seperti kunci asing). Faktanya, tabel adalah predikat dengan atribut tetap, yaitu. kita selalu tahu arity dari sebuah predikat tabel.
Mari kita ambil kunci asing sebagai contoh hubungan batasan: kunci “p (_, X, _) → q (_, Y, _)”, yang menetapkan batasan dalam bentuk X \ subset Y, di mana X adalah atribut dari relasi p, dan Y atribut hubungan q.

Lebih penting lagi, dalam dunia data relasional, kita memiliki semua tabel! Dan operasi mengambil tabel sebagai input dan mengembalikan tabel, misalnya:

Bahasa Data Relasional: SQL dan Aljabar Relasional
Aljabar relasional (Codd aljabar) pada dasarnya adalah sekumpulan operasi pada tabel yang mengembalikan tabel. Artinya, bagi Anda, elemen sentral pemodelan justru adalah tabel tetap dan transformasinya.
Bahasa SQL adalah superstruktur deklaratif dan implementasi konkret dari ide-ide aljabar relasional.
Contoh kueri sederhana dan operator relasional terkait dari aljabar.

Sejauh ini, semua yang telah kita bahas adalah hal-hal klasik yang kita ketahui dari kursus database mana pun.
Data yang ditautkan dan grafik pengetahuan
Bayangkan saja apa yang akan terjadi jika kita memiliki properti baru dan ini terjadi, mungkin dalam waktu nyata? Artinya, domain tidak tetap - tetapi fleksibel dan dapat diperluas ?
Dalam situasi seperti ini, tentu saja, kita dapat menambahkan tabel dan kolom ke tabel dengan memasukkan NULL atau nilai default. Tetapi selain tidak nyaman secara teknis, ini juga merupakan alat yang tidak sesuai dari sudut pandang pemodelan.
Bayangkan Anda mencontoh kehidupan orang dalam semua aspek yang memungkinkan. Bahkan dua orang yang berbeda akan memiliki sekumpulan properti kunci yang agak berbeda, dan ini benar-benar normal!
Anda tidak memiliki daftar tetap tentang bagaimana karakter tertentu akan dideskripsikan Penulis dan Pemain Sepak Bola adalah dua Orang yang memiliki banyak properti penting, tetapi, bagaimanapun, berbeda.
Mari kita mulai dengan penulis Douglas Adams - properti teratas cukup umum untuk semua orang - di sini dan selanjutnya kita menggunakan Wikidata sebagai contoh LinkedData.
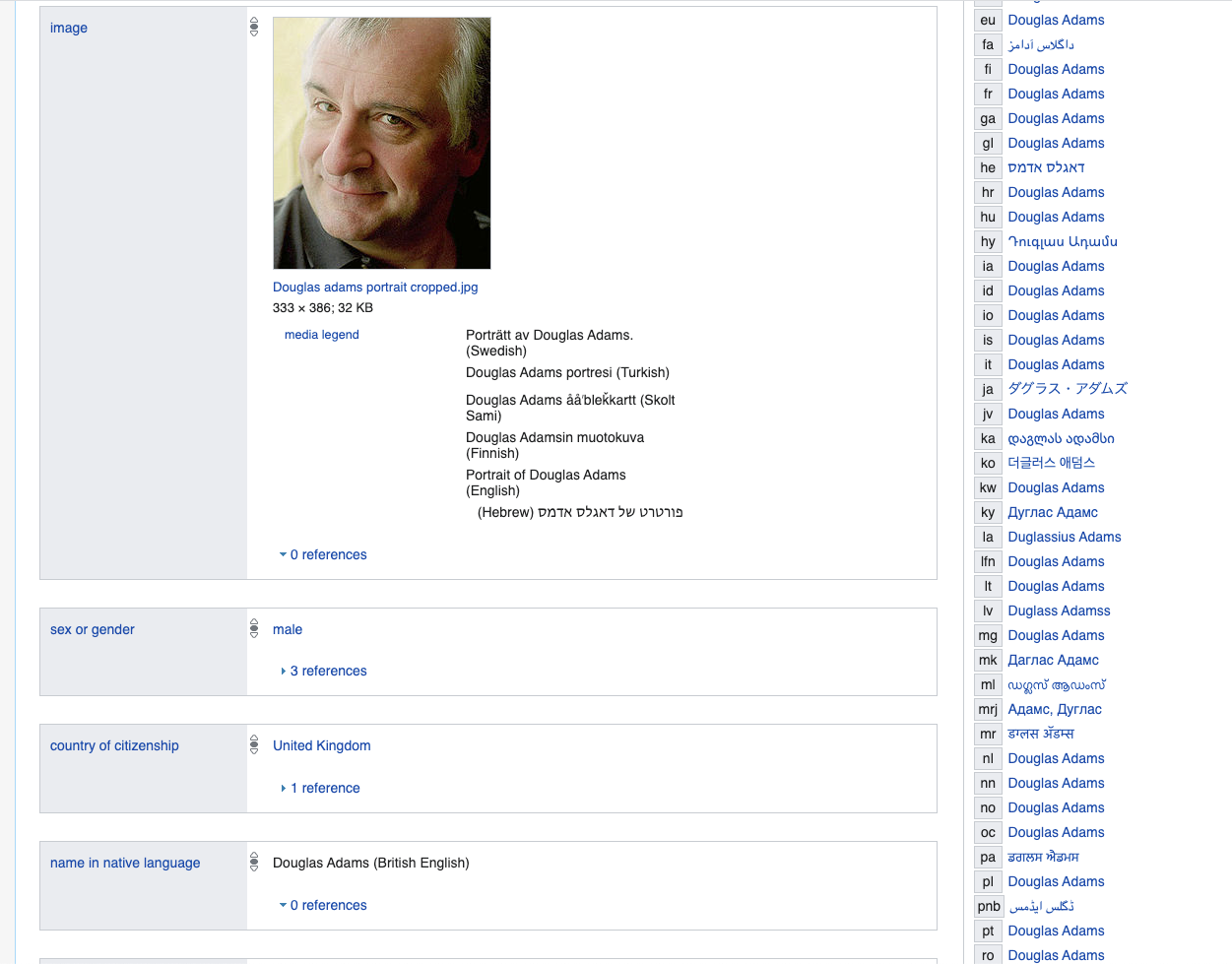
www.wikidata.org/wiki/Q42
Namun mari kita gali lebih dalam dan
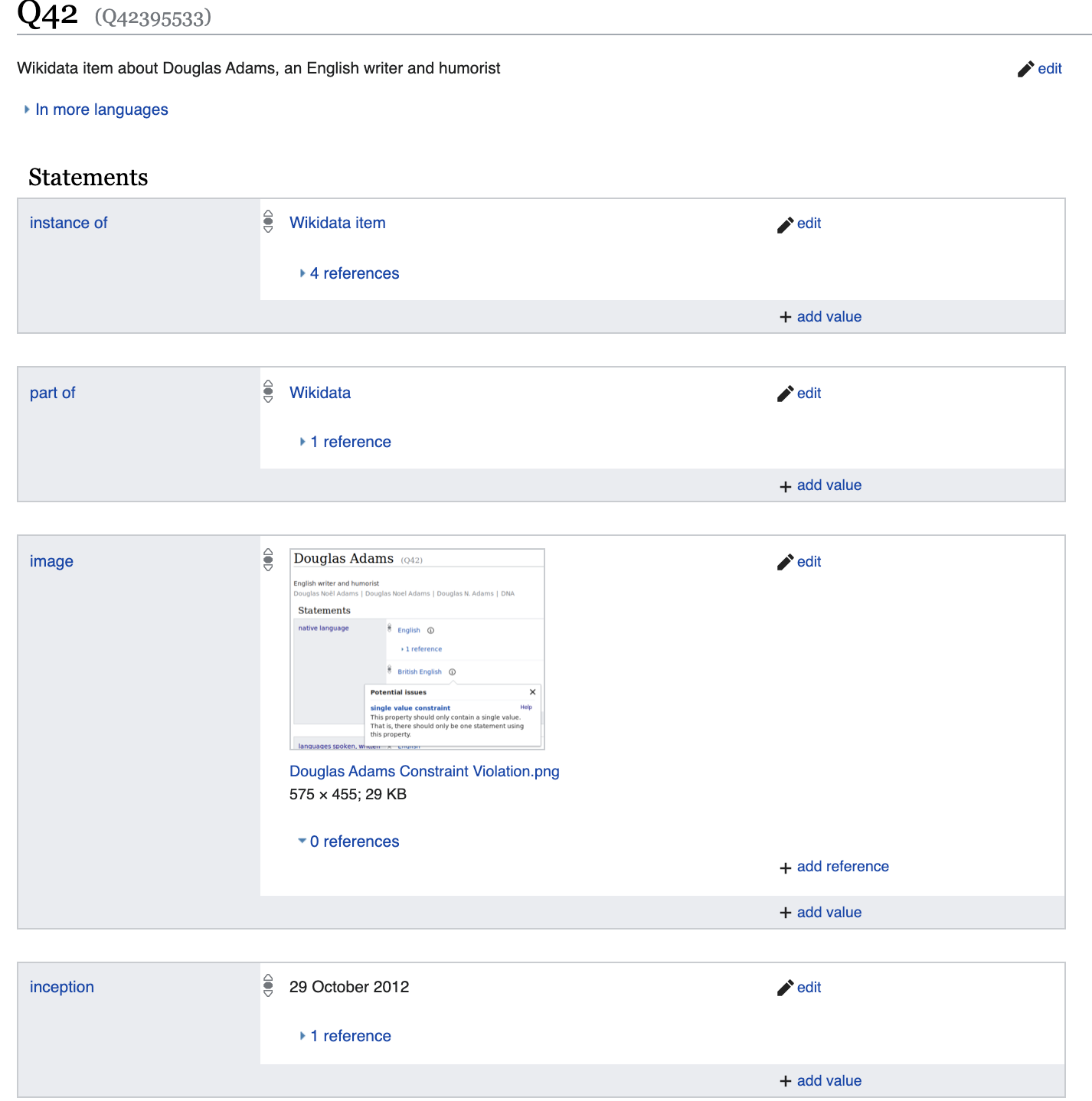
lihat sekumpulan properti yang akan berbeda secara signifikan dari, misalnya, Diego Maradonna.
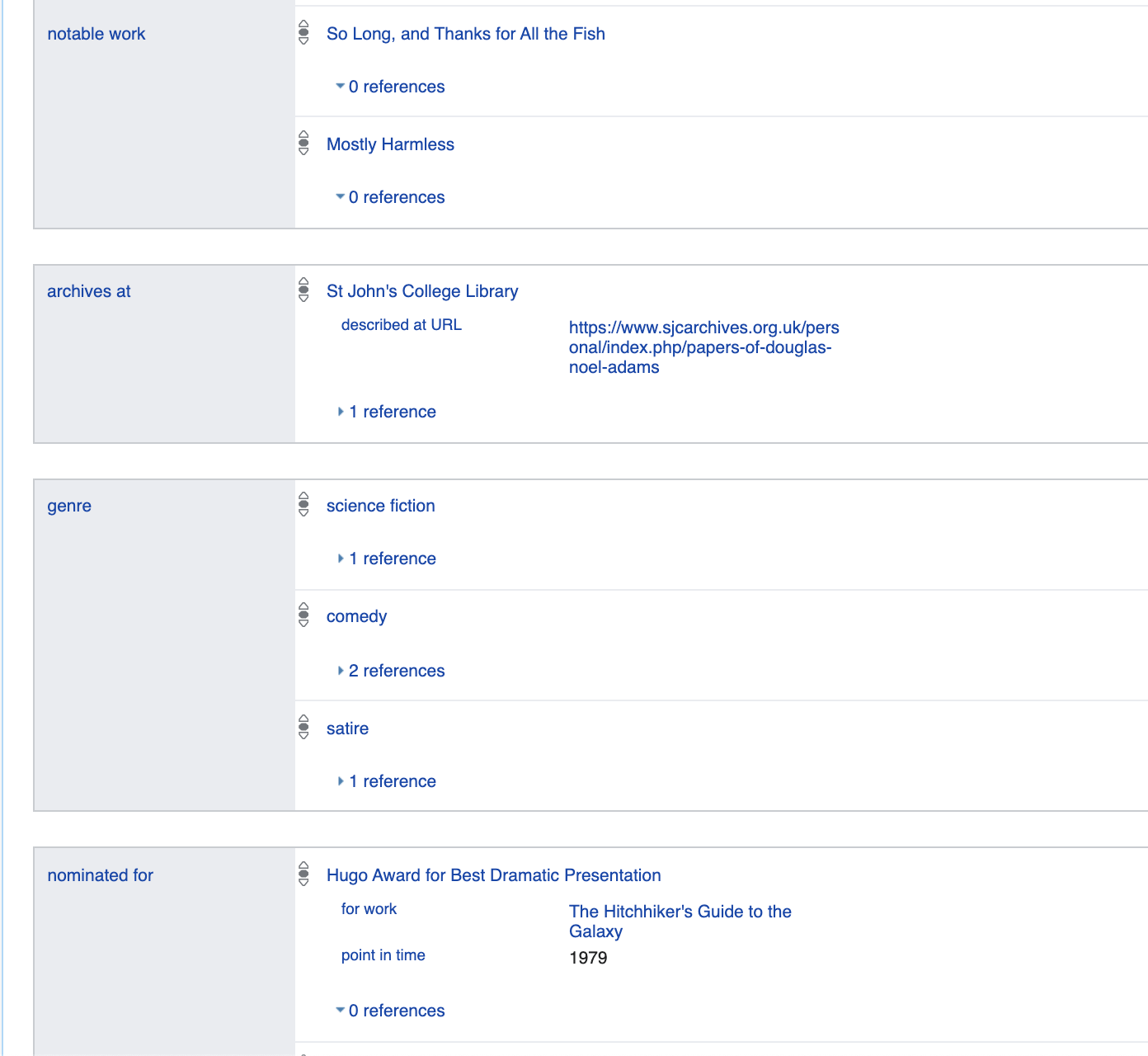
Mari kita bicara lebih banyak tentang properti yang ditentukan di sini. Misalnya, jenis kelamin: pria

pada dasarnya adalah cerminan dari fakta logis: p21 (Q42, Q6581097).
Dimana p21 → ini adalah identitas_kender / 2 - predikat biner
Q42 → Douglas Adams
Q6581097 → laki-laki
Dengan demikian, semua data disajikan sebagai predikat unary, misalnya is_dead (Q42), atau sebagai biner p21 (Q42, Q6581097).
Sebenarnya, ini adalah paradigma paradigma lain dari pemodelan - logika orde pertama, tetapi pada predikat uner dan biner.
Dan di sini sangat mudah untuk menambahkan data baru: segala sesuatu yang tidak ditunjukkan dalam bentuk predikat atas objek adalah salah, dalam literatur ini dikenal sebagai asumsi Dunia Tertutup .
Selain itu, format ini memungkinkan pemodelan meta yang benar-benar alami
https://www.wikidata.org/wiki/Q42395533
Ada beberapa penyimpanan dasar dan menulis kueri untuk data semacam itu - mari kita lihat opsi yang populer.
RDF dan Bahasa Kueri SPARQL
RDF adalah bahasa formal untuk mendeskripsikan data terkait untuk pemrosesan kueri selanjutnya, yaitu format yang dapat dibaca mesin.
Faktanya, bagi dia, kuncinya adalah konsep triplet:

Dan berikut adalah contoh pencatatan data dalam model ini (prefiks menentukan di mana letak “deskripsi” dari predikat

ini ). Format perekaman ini memungkinkan Anda untuk merepresentasikan data tentang objek secara grafis - misalnya, Anda dapat menulis informasi tentang kota Berlin.

Untuk format RDF, mereka membuat bahasa kueri SPARQL: yang pada dasarnya menjelaskan batasan pada predikat logika dan mengatakan variabel mana yang harus diekstrak dari ekspresi logis:

Apa yang sebenarnya ingin kami temukan adalah nilai variabel? Negara, sehingga member_of benar untuk member_of (? Country, q458) dan q458 adalah ID EU.
Dalam kode sebenarnya, akan terlihat seperti ini:
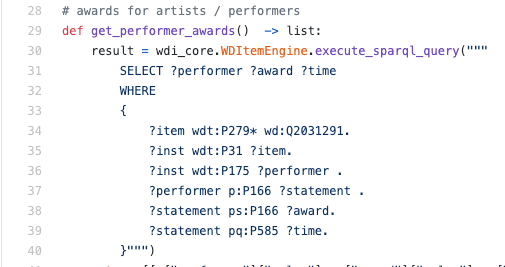
Total: RDF adalah format untuk merepresentasikan data dalam bentuk tripel (predikat biner) dan SPARQL adalah bahasa query berbasis logika untuk tripel.
Bahasa Query Datalog dan Turunannya
Selain itu, untuk menulis kueri ke RDF (dan tidak hanya itu, lebih banyak lagi nanti), Anda dapat menggunakan Datalog - bahasa deklaratif (sering kali) yang secara sintaksis mewakili subset Prolog (paling sering).
Di dalamnya, kueri terlihat seperti ini:
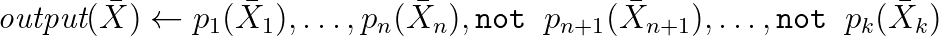
Sintaksnya sering diperluas dengan agregasi dan hal-hal praktis penting lainnya. Faktanya, ini adalah aturan inferensi yang diambil dari logika, dan dengan bantuannya Anda dapat membuat model inferensi properti baru dan menulis kueri ke RDF. Berikut ini adalah contoh dunia nyata yang bekerja dengan WikiData berdasarkan salah satu dialek

Keuntungan penting lainnya dari bahasa kueri logis berbasis Datalog adalah bagi mereka RDF hanyalah format untuk merekam fakta (pernyataan) logika biner. Mereka juga dapat menangani pernyataan logis lainnya - tidak harus biner.
kesimpulan
Pertama, data relasional sangat cocok untuk memodelkan domain tetap, di mana skema jarang berubah atau perubahan tidak hanya tentang catatan tunggal, tetapi seluruh segmen.
Kedua, bahasa relasional cocok untuk tugas pemodelan di mana Anda perlu mengekstrak sub-tabel, mengubah dan menggabungkan yang sudah ada - ini bukan alat yang ideal ketika bagian penting dari pekerjaan berjalan pada tingkat modifikasi dan / atau kesimpulan pada rekaman tertentu.
Ketiga, jika domain pemodelan adalah area yang komprehensif, dan bahkan berubah, di mana bahkan catatan dari kelas yang sama sangat berbeda, data yang koheren sangat cocok.
Keempat, representasi standar adalah RDF dan masuk akal untuk mencobanya terlebih dahulu. Dengan mengacaukan database yang diperlukan dan menggunakan bahasa seperti SPARQ, Anda dapat mengekstrak data yang diperlukan.
Kelima, jika pemodelan dengan triplet menjadi rumit dan tidak nyaman, Anda dapat mempertimbangkan representasi logis dari data dan Datalog sebagai bahasa kueri.

