CREATE TABLE task AS
SELECT
id
, (random() * 100)::integer person -- 100
, least(trunc(-ln(random()) / ln(2)), 10)::integer priority -- 2
FROM
generate_series(1, 1e5) id; -- 100K
CREATE INDEX ON task(person, priority);
Kata "ada" dalam SQL berubah menjadi
EXISTS
- inilah versi yang paling sederhana dan mari kita mulai:
SELECT
*
FROM
generate_series(0, 99) pid
WHERE
EXISTS(
SELECT
NULL
FROM
task
WHERE
person = pid AND
priority = 10
);

semua gambar rencana dapat diklik
Sejauh ini, semuanya terlihat bagus, tapi ...
EXISTS + IN
... lalu mereka mendatangi kami dan meminta untuk memasukkan tidak hanya
priority = 10
8 dan 9 sebagai "super" :
SELECT
*
FROM
generate_series(0, 99) pid
WHERE
EXISTS(
SELECT
NULL
FROM
task
WHERE
person = pid AND
priority IN (10, 9, 8)
);

Mereka membaca 1,5 kali lebih banyak, dan itu juga memengaruhi waktu eksekusi.
ATAU + ADA
Mari kita coba gunakan pengetahuan kita bahwa
priority = 8
kemungkinan besar akan bertemu rekor dengan lebih dari 10:
SELECT
*
FROM
generate_series(0, 99) pid
WHERE
EXISTS(
SELECT
NULL
FROM
task
WHERE
person = pid AND
priority = 8
) OR
EXISTS(
SELECT
NULL
FROM
task
WHERE
person = pid AND
priority = 9
) OR
EXISTS(
SELECT
NULL
FROM
task
WHERE
person = pid AND
priority = 10
);

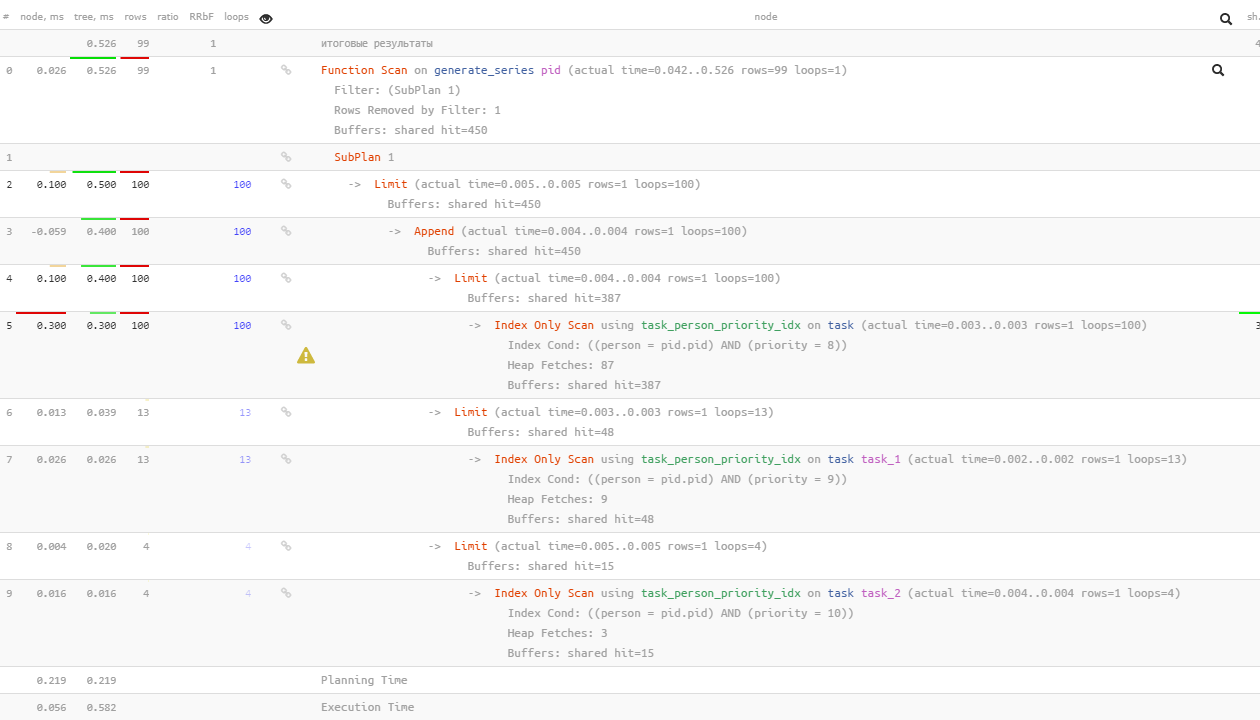
Perhatikan bahwa PostgreSQL 12 sudah cukup pintar untuk membuat
EXISTS
-subkueri berikutnya hanya untuk yang "tidak ditemukan" oleh yang sebelumnya setelah 100 mencari nilai 8 - hanya 13 untuk nilai 9, dan hanya 4 untuk 10.
KASUS + ADA + ...
Pada versi sebelumnya, hasil yang serupa dapat dicapai dengan "bersembunyi di bawah CASE" kueri berikut:
SELECT
*
FROM
generate_series(0, 99) pid
WHERE
CASE
WHEN
EXISTS(
SELECT
NULL
FROM
task
WHERE
person = pid AND
priority = 8
) THEN TRUE
ELSE
CASE
WHEN
EXISTS(
SELECT
NULL
FROM
task
WHERE
person = pid AND
priority = 9
) THEN TRUE
ELSE
EXISTS(
SELECT
NULL
FROM
task
WHERE
person = pid AND
priority = 10
)
END
END;
ADA + UNI SEMUA + BATAS
Hal yang sama, tetapi Anda bisa mendapatkan sedikit lebih cepat jika Anda menggunakan "retas"
UNION ALL + LIMIT
:
SELECT
*
FROM
generate_series(0, 99) pid
WHERE
EXISTS(
(
SELECT
NULL
FROM
task
WHERE
person = pid AND
priority = 8
LIMIT 1
)
UNION ALL
(
SELECT
NULL
FROM
task
WHERE
person = pid AND
priority = 9
LIMIT 1
)
UNION ALL
(
SELECT
NULL
FROM
task
WHERE
person = pid AND
priority = 10
LIMIT 1
)
LIMIT 1
);
Indeks yang benar adalah kunci kesehatan database
Sekarang mari kita lihat masalah dari sisi yang sama sekali berbeda. Jika kita tahu pasti bahwa
task
jumlah record yang ingin kita temukan beberapa kali lebih sedikit dari yang lain , maka kita akan membuat indeks parsial yang sesuai. Pada saat yang sama, mari kita langsung dari penghitungan "titik"
8, 9, 10
ke
>= 8
:
CREATE INDEX ON task(person) WHERE priority >= 8;
SELECT
*
FROM
generate_series(0, 99) pid
WHERE
EXISTS(
SELECT
NULL
FROM
task
WHERE
person = pid AND
priority >= 8
);

Saya harus membaca 2 kali lebih cepat dan 1,5 kali lebih sedikit!
Tapi, mungkin, untuk mengurangi semua yang cocok
task
sekaligus - apakah akan lebih cepat? ..
SELECT DISTINCT
person
FROM
task
WHERE
priority >= 8;

Jauh dari biasanya, dan tentu saja tidak dalam kasus ini - karena alih-alih 100 bacaan dari rekaman pertama yang tersedia, kita harus membaca lebih dari 400!
Dan agar tidak menebak opsi kueri mana yang lebih efektif, dan mengetahuinya dengan percaya diri - gunakan menjelaskan.tensor.ru .