pengantar
Teknologi pembelajaran mesin telah berkembang dengan kecepatan yang luar biasa selama setahun terakhir. Semakin banyak perusahaan membagikan praktik terbaik mereka, sehingga membuka kemungkinan baru untuk menciptakan asisten digital pintar.
Dalam kerangka artikel ini, saya ingin berbagi pengalaman saya dalam menerapkan asisten suara dan menawarkan beberapa ide untuk membuatnya lebih pintar dan lebih berguna.

Apa yang bisa dilakukan asisten suara saya?
| Deskripsi keterampilan | Pekerjaan offline | Dependensi yang diperlukan |
| Mengenali dan mensintesis ucapan | Didukung | pip install PyAudio (menggunakan mikrofon)
pip install pyttsx3 (sintesis ucapan) Anda dapat memilih satu atau keduanya untuk pengenalan suara:
|
| pip install pyowm (OpenWeatherMap) | ||
| Google ( ) | pip install google | |
| YouTube | - | |
| Wikipedia c | pip install wikipedia-api | |
| pip install googletrans (Google Translate) | ||
| - | ||
| « » | - | |
| ( ) | - | |
| - | ||
| TODO ... | ||
1.
Mari kita mulai dengan mempelajari cara menangani masukan suara. Kami membutuhkan mikrofon dan beberapa perpustakaan yang terpasang: PyAudio dan SpeechRecognition.
Mari persiapkan alat dasar untuk pengenalan ucapan:
import speech_recognition
if __name__ == "__main__":
#
recognizer = speech_recognition.Recognizer()
microphone = speech_recognition.Microphone()
while True:
#
voice_input = record_and_recognize_audio()
print(voice_input)
Sekarang mari buat fungsi untuk merekam dan mengenali ucapan. Untuk pengenalan online, kami membutuhkan Google, karena Google memiliki kualitas pengenalan yang tinggi dalam banyak bahasa.
def record_and_recognize_audio(*args: tuple):
"""
"""
with microphone:
recognized_data = ""
#
recognizer.adjust_for_ambient_noise(microphone, duration=2)
try:
print("Listening...")
audio = recognizer.listen(microphone, 5, 5)
except speech_recognition.WaitTimeoutError:
print("Can you check if your microphone is on, please?")
return
# online- Google
try:
print("Started recognition...")
recognized_data = recognizer.recognize_google(audio, language="ru").lower()
except speech_recognition.UnknownValueError:
pass
#
except speech_recognition.RequestError:
print("Check your Internet Connection, please")
return recognized_data
Bagaimana jika tidak ada akses internet? Anda dapat menggunakan solusi untuk pengenalan offline. Saya pribadi sangat menyukai proyek Vosk .
Faktanya, Anda tidak perlu menerapkan opsi offline jika Anda tidak membutuhkannya. Saya hanya ingin menunjukkan kedua metode dalam kerangka artikel, dan Anda sudah memilih berdasarkan persyaratan sistem Anda (misalnya, Google tidak diragukan lagi adalah pemimpin dalam jumlah bahasa pengenalan yang tersedia).Sekarang, setelah menerapkan solusi offline dan menambahkan model bahasa yang diperlukan ke proyek, jika tidak ada akses ke jaringan, kami akan secara otomatis beralih ke pengenalan offline.
Perhatikan bahwa agar tidak harus mengulangi frasa yang sama dua kali, saya memutuskan untuk merekam audio dari mikrofon ke dalam file wav sementara yang akan dihapus setelah setiap pengenalan.
Jadi, kode yang dihasilkan terlihat seperti ini:
Kode lengkap untuk pengenalan ucapan untuk bekerja
from vosk import Model, KaldiRecognizer # - Vosk
import speech_recognition # (Speech-To-Text)
import wave # wav
import json # json- json-
import os #
def record_and_recognize_audio(*args: tuple):
"""
"""
with microphone:
recognized_data = ""
#
recognizer.adjust_for_ambient_noise(microphone, duration=2)
try:
print("Listening...")
audio = recognizer.listen(microphone, 5, 5)
with open("microphone-results.wav", "wb") as file:
file.write(audio.get_wav_data())
except speech_recognition.WaitTimeoutError:
print("Can you check if your microphone is on, please?")
return
# online- Google
try:
print("Started recognition...")
recognized_data = recognizer.recognize_google(audio, language="ru").lower()
except speech_recognition.UnknownValueError:
pass
#
# offline- Vosk
except speech_recognition.RequestError:
print("Trying to use offline recognition...")
recognized_data = use_offline_recognition()
return recognized_data
def use_offline_recognition():
"""
-
:return:
"""
recognized_data = ""
try:
#
if not os.path.exists("models/vosk-model-small-ru-0.4"):
print("Please download the model from:\n"
"https://alphacephei.com/vosk/models and unpack as 'model' in the current folder.")
exit(1)
# ( )
wave_audio_file = wave.open("microphone-results.wav", "rb")
model = Model("models/vosk-model-small-ru-0.4")
offline_recognizer = KaldiRecognizer(model, wave_audio_file.getframerate())
data = wave_audio_file.readframes(wave_audio_file.getnframes())
if len(data) > 0:
if offline_recognizer.AcceptWaveform(data):
recognized_data = offline_recognizer.Result()
# JSON-
# ( )
recognized_data = json.loads(recognized_data)
recognized_data = recognized_data["text"]
except:
print("Sorry, speech service is unavailable. Try again later")
return recognized_data
if __name__ == "__main__":
#
recognizer = speech_recognition.Recognizer()
microphone = speech_recognition.Microphone()
while True:
#
#
voice_input = record_and_recognize_audio()
os.remove("microphone-results.wav")
print(voice_input)
Anda mungkin bertanya "Mengapa mendukung kemampuan offline?"
Menurut pendapat saya, selalu ada baiknya mempertimbangkan bahwa pengguna mungkin terputus dari jaringan. Dalam hal ini, asisten suara masih dapat berguna jika Anda menggunakannya sebagai bot percakapan atau untuk menyelesaikan sejumlah tugas sederhana, misalnya menghitung sesuatu, merekomendasikan film, membantu memilih dapur, bermain game, dll.
Langkah 2. Konfigurasi asisten suara
Karena asisten suara kita dapat memiliki gender, bahasa ucapan, dan, menurut klasik, sebuah nama, mari pilih kelas terpisah untuk data ini, yang akan kita gunakan di masa mendatang.
Untuk menyetel suara untuk asisten kami, kami akan menggunakan pustaka sintesis ucapan offline pyttsx3. Secara otomatis akan menemukan suara yang tersedia untuk sintesis di komputer kita, tergantung pada pengaturan sistem operasi (oleh karena itu, mungkin saja Anda memiliki suara lain yang tersedia dan Anda akan membutuhkan indeks yang berbeda).
Kami juga akan menambahkan ke fungsi utama inisialisasi sintesis ucapan dan fungsi terpisah untuk memainkannya. Untuk memastikan semuanya berfungsi, mari kita periksa apakah pengguna telah menyambut kita, dan memberinya salam balasan dari asisten:
Kode lengkap untuk kerangka asisten suara (sintesis dan pengenalan ucapan)
from vosk import Model, KaldiRecognizer # - Vosk
import speech_recognition # (Speech-To-Text)
import pyttsx3 # (Text-To-Speech)
import wave # wav
import json # json- json-
import os #
class VoiceAssistant:
"""
, , ,
"""
name = ""
sex = ""
speech_language = ""
recognition_language = ""
def setup_assistant_voice():
"""
(
)
"""
voices = ttsEngine.getProperty("voices")
if assistant.speech_language == "en":
assistant.recognition_language = "en-US"
if assistant.sex == "female":
# Microsoft Zira Desktop - English (United States)
ttsEngine.setProperty("voice", voices[1].id)
else:
# Microsoft David Desktop - English (United States)
ttsEngine.setProperty("voice", voices[2].id)
else:
assistant.recognition_language = "ru-RU"
# Microsoft Irina Desktop - Russian
ttsEngine.setProperty("voice", voices[0].id)
def play_voice_assistant_speech(text_to_speech):
"""
( )
:param text_to_speech: ,
"""
ttsEngine.say(str(text_to_speech))
ttsEngine.runAndWait()
def record_and_recognize_audio(*args: tuple):
"""
"""
with microphone:
recognized_data = ""
#
recognizer.adjust_for_ambient_noise(microphone, duration=2)
try:
print("Listening...")
audio = recognizer.listen(microphone, 5, 5)
with open("microphone-results.wav", "wb") as file:
file.write(audio.get_wav_data())
except speech_recognition.WaitTimeoutError:
print("Can you check if your microphone is on, please?")
return
# online- Google
# ( )
try:
print("Started recognition...")
recognized_data = recognizer.recognize_google(audio, language="ru").lower()
except speech_recognition.UnknownValueError:
pass
#
# offline- Vosk
except speech_recognition.RequestError:
print("Trying to use offline recognition...")
recognized_data = use_offline_recognition()
return recognized_data
def use_offline_recognition():
"""
-
:return:
"""
recognized_data = ""
try:
#
if not os.path.exists("models/vosk-model-small-ru-0.4"):
print("Please download the model from:\n"
"https://alphacephei.com/vosk/models and unpack as 'model' in the current folder.")
exit(1)
# ( )
wave_audio_file = wave.open("microphone-results.wav", "rb")
model = Model("models/vosk-model-small-ru-0.4")
offline_recognizer = KaldiRecognizer(model, wave_audio_file.getframerate())
data = wave_audio_file.readframes(wave_audio_file.getnframes())
if len(data) > 0:
if offline_recognizer.AcceptWaveform(data):
recognized_data = offline_recognizer.Result()
# JSON-
# ( )
recognized_data = json.loads(recognized_data)
recognized_data = recognized_data["text"]
except:
print("Sorry, speech service is unavailable. Try again later")
return recognized_data
if __name__ == "__main__":
#
recognizer = speech_recognition.Recognizer()
microphone = speech_recognition.Microphone()
#
ttsEngine = pyttsx3.init()
#
assistant = VoiceAssistant()
assistant.name = "Alice"
assistant.sex = "female"
assistant.speech_language = "ru"
#
setup_assistant_voice()
while True:
#
#
voice_input = record_and_recognize_audio()
os.remove("microphone-results.wav")
print(voice_input)
# ()
voice_input = voice_input.split(" ")
command = voice_input[0]
if command == "":
play_voice_assistant_speech("")
Sebenarnya, di sini saya ingin belajar cara menulis penyintesis suara sendiri, tetapi pengetahuan saya di sini tidak akan cukup. Jika Anda dapat menyarankan literatur yang baik, kursus atau solusi terdokumentasi yang menarik yang akan membantu Anda memahami topik ini secara mendalam, silakan tulis di komentar.
Langkah 3. Pemrosesan perintah
Sekarang kita telah "belajar" untuk mengenali dan mensintesis pidato dengan bantuan perkembangan ilahi sederhana dari kolega kita, kita dapat mulai menemukan kembali roda kita untuk memproses perintah ucapan pengguna: D
Dalam kasus saya, saya menggunakan opsi multibahasa untuk menyimpan perintah, karena saya tidak memiliki begitu banyak peristiwa, dan saya puas dengan keakuratan definisi perintah ini atau itu. Namun, untuk proyek besar, saya sarankan untuk membagi konfigurasi berdasarkan bahasa.
Saya dapat menawarkan dua cara untuk menyimpan perintah.
1 cara
Anda bisa menggunakan objek seperti JSON yang indah untuk menyimpan maksud, skenario pengembangan, respons jika ada upaya yang gagal (ini sering digunakan untuk bot obrolan). Ini terlihat seperti ini:
config = {
"intents": {
"greeting": {
"examples": ["", "", " ",
"hello", "good morning"],
"responses": play_greetings
},
"farewell": {
"examples": ["", " ", "", " ",
"goodbye", "bye", "see you soon"],
"responses": play_farewell_and_quit
},
"google_search": {
"examples": [" ",
"search on google", "google", "find on google"],
"responses": search_for_term_on_google
},
},
"failure_phrases": play_failure_phrase
}
Pilihan ini cocok untuk mereka yang ingin melatih asisten untuk merespons frasa yang sulit. Selain itu, di sini Anda bisa menerapkan pendekatan NLU dan membuat kemampuan untuk memprediksi maksud pengguna dengan memeriksanya terhadap yang sudah ada dalam konfigurasi.
Kami akan mempertimbangkan metode ini secara rinci pada langkah 5 artikel ini. Sementara itu, saya akan menarik perhatian Anda ke opsi yang lebih sederhana.
2 jalan
Anda dapat mengambil kamus yang disederhanakan, yang akan memiliki jenis tupel yang dapat di-hash sebagai kunci (karena kamus menggunakan hash untuk menyimpan dan mengambil elemen dengan cepat), dan nama fungsi yang akan dijalankan akan dalam bentuk nilai. Untuk perintah singkat, opsi berikut ini cocok:
commands = {
("hello", "hi", "morning", ""): play_greetings,
("bye", "goodbye", "quit", "exit", "stop", ""): play_farewell_and_quit,
("search", "google", "find", ""): search_for_term_on_google,
("video", "youtube", "watch", ""): search_for_video_on_youtube,
("wikipedia", "definition", "about", "", ""): search_for_definition_on_wikipedia,
("translate", "interpretation", "translation", "", "", ""): get_translation,
("language", ""): change_language,
("weather", "forecast", "", ""): get_weather_forecast,
}
Untuk memprosesnya, kita perlu menambahkan kode sebagai berikut:
def execute_command_with_name(command_name: str, *args: list):
"""
:param command_name:
:param args: ,
:return:
"""
for key in commands.keys():
if command_name in key:
commands[key](*args)
else:
pass # print("Command not found")
if __name__ == "__main__":
#
recognizer = speech_recognition.Recognizer()
microphone = speech_recognition.Microphone()
while True:
#
#
voice_input = record_and_recognize_audio()
os.remove("microphone-results.wav")
print(voice_input)
# ()
voice_input = voice_input.split(" ")
command = voice_input[0]
command_options = [str(input_part) for input_part in voice_input[1:len(voice_input)]]
execute_command_with_name(command, command_options)
Argumen tambahan akan diteruskan ke fungsi setelah kata perintah. Artinya, jika Anda mengucapkan frasa " video adalah kucing lucu ", perintah " video " akan memanggil fungsi search_for_video_on_youtube () dengan argumen " kucing lucu " dan akan memberikan hasil sebagai berikut:
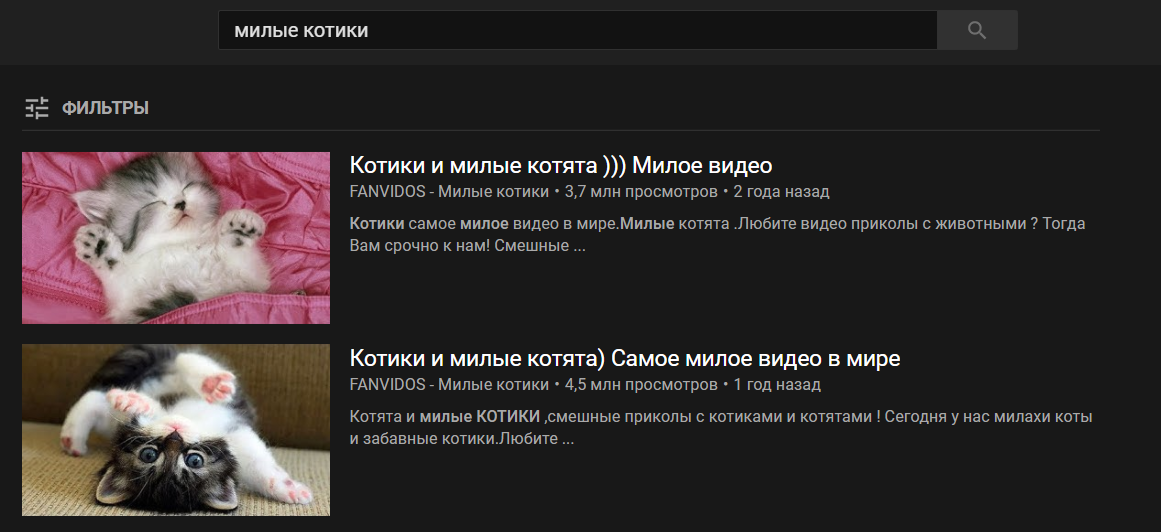
Contoh fungsi tersebut dengan memproses argumen yang masuk:
def search_for_video_on_youtube(*args: tuple):
"""
YouTube
:param args:
"""
if not args[0]: return
search_term = " ".join(args[0])
url = "https://www.youtube.com/results?search_query=" + search_term
webbrowser.get().open(url)
#
# , JSON-
play_voice_assistant_speech("Here is what I found for " + search_term + "on youtube")
Itu dia! Fungsi utama bot sudah siap. Kemudian Anda dapat terus meningkatkannya dengan berbagai cara. Implementasi saya dengan komentar mendetail tersedia di GitHub saya .
Di bawah ini kami akan melihat sejumlah peningkatan untuk membuat asisten kami semakin pintar.
Langkah 4. Menambahkan multibahasa
Untuk mengajari asisten kami bekerja dengan berbagai model bahasa, akan lebih mudah untuk mengatur file JSON kecil dengan struktur sederhana:
{
"Can you check if your microphone is on, please?": {
"ru": ", , ",
"en": "Can you check if your microphone is on, please?"
},
"What did you say again?": {
"ru": ", ",
"en": "What did you say again?"
},
}
Dalam kasus saya, saya menggunakan peralihan antara bahasa Rusia dan Inggris, karena model pengenalan ucapan dan suara untuk sintesis ucapan tersedia untuk saya untuk ini. Bahasa akan dipilih tergantung pada bahasa ucapan asisten suara itu sendiri.
Untuk menerima terjemahan, kita dapat membuat kelas terpisah dengan metode yang akan mengembalikan string dengan terjemahan:
class Translation:
"""
"""
with open("translations.json", "r", encoding="UTF-8") as file:
translations = json.load(file)
def get(self, text: str):
"""
( )
:param text: ,
:return:
"""
if text in self.translations:
return self.translations[text][assistant.speech_language]
else:
#
#
print(colored("Not translated phrase: {}".format(text), "red"))
return text
Pada fungsi utama, sebelum loop, kita akan mendeklarasikan translator kita sebagai berikut: translator = Translation ()
Sekarang, saat memainkan pidato asisten, kita bisa mendapatkan terjemahannya sebagai berikut:
play_voice_assistant_speech(translator.get(
"Here is what I found for {} on Wikipedia").format(search_term))
Seperti yang Anda lihat dari contoh di atas, ini berfungsi bahkan untuk baris yang memerlukan argumen tambahan untuk disisipkan. Jadi, Anda dapat menerjemahkan set frasa "standar" untuk asisten Anda.
Langkah 5. Sedikit pembelajaran mesin
Sekarang mari kita kembali ke objek JSON untuk menyimpan perintah multi-kata, yang khas untuk kebanyakan chatbots, yang saya sebutkan di paragraf 3. Sangat cocok untuk mereka yang tidak ingin menggunakan perintah yang ketat dan berencana untuk memperluas pemahaman mereka tentang maksud pengguna menggunakan NLU -metode.
Secara kasar, dalam hal ini, frasa " selamat siang ", " selamat malam ", dan " selamat pagi " akan dianggap setara. Asisten akan memahami bahwa dalam ketiga kasus tersebut, niat pengguna adalah untuk menyapa asisten suara mereka.
Dengan menggunakan metode ini, Anda juga dapat membuat bot percakapan untuk obrolan atau mode percakapan untuk asisten suara Anda (untuk kasus ketika Anda membutuhkan lawan bicara).
Untuk mengimplementasikan kemungkinan seperti itu, kita perlu menambahkan beberapa fungsi:
def prepare_corpus():
"""
"""
corpus = []
target_vector = []
for intent_name, intent_data in config["intents"].items():
for example in intent_data["examples"]:
corpus.append(example)
target_vector.append(intent_name)
training_vector = vectorizer.fit_transform(corpus)
classifier_probability.fit(training_vector, target_vector)
classifier.fit(training_vector, target_vector)
def get_intent(request):
"""
:param request:
:return:
"""
best_intent = classifier.predict(vectorizer.transform([request]))[0]
index_of_best_intent = list(classifier_probability.classes_).index(best_intent)
probabilities = classifier_probability.predict_proba(vectorizer.transform([request]))[0]
best_intent_probability = probabilities[index_of_best_intent]
#
if best_intent_probability > 0.57:
return best_intent
Dan juga sedikit memodifikasi fungsi utama dengan menambahkan inisialisasi variabel untuk menyiapkan model dan mengubah loop ke versi yang sesuai dengan konfigurasi baru:
#
# ( )
vectorizer = TfidfVectorizer(analyzer="char", ngram_range=(2, 3))
classifier_probability = LogisticRegression()
classifier = LinearSVC()
prepare_corpus()
while True:
#
#
voice_input = record_and_recognize_audio()
if os.path.exists("microphone-results.wav"):
os.remove("microphone-results.wav")
print(colored(voice_input, "blue"))
# ()
if voice_input:
voice_input_parts = voice_input.split(" ")
# -
#
if len(voice_input_parts) == 1:
intent = get_intent(voice_input)
if intent:
config["intents"][intent]["responses"]()
else:
config["failure_phrases"]()
# -
# ,
#
if len(voice_input_parts) > 1:
for guess in range(len(voice_input_parts)):
intent = get_intent((" ".join(voice_input_parts[0:guess])).strip())
if intent:
command_options = [voice_input_parts[guess:len(voice_input_parts)]]
config["intents"][intent]["responses"](*command_options)
break
if not intent and guess == len(voice_input_parts)-1:
config["failure_phrases"]()
Namun, metode ini lebih sulit dikendalikan: metode ini memerlukan verifikasi terus-menerus bahwa frasa ini atau itu masih diidentifikasi dengan benar oleh sistem sebagai bagian dari maksud ini atau itu. Oleh karena itu, metode ini harus digunakan dengan hati-hati (atau bereksperimen dengan model itu sendiri).
Kesimpulan
Ini menyimpulkan tutorial kecil saya.
Saya akan senang jika Anda berbagi dengan saya di komentar solusi sumber terbuka yang Anda tahu yang dapat diterapkan dalam proyek ini, serta ide Anda tentang fungsi online dan offline lainnya yang dapat diterapkan.
Sumber terdokumentasi dari asisten suara saya dalam dua versi dapat ditemukan di sini .
PS: Solusi berfungsi di Windows, Linux dan MacOS dengan perbedaan kecil saat menginstal pustaka PyAudio dan Google.