
Ini adalah terjemahan dari artikel kedua dalam seri tentang privasi diferensial.
Minggu lalu, di artikel pertama seri ini - " Privasi Diferensial - Menganalisis Data Sambil Menjaga Kerahasiaan (Pengantar Seri) " - kita melihat konsep dasar dan penggunaan privasi diferensial. Hari ini kami akan mempertimbangkan opsi yang memungkinkan untuk membangun sistem, tergantung pada model ancaman yang diharapkan.
Menerapkan sistem yang memenuhi prinsip privasi diferensial bukanlah tugas yang sepele. Sebagai contoh, di posting kita berikutnya, kita akan melihat program Python sederhana yang mengimplementasikan penambahan noise Laplace secara langsung dalam fungsi yang memproses data sensitif. Tetapi agar ini berfungsi, kami perlu mengumpulkan semua data yang diperlukan di satu server.
Bagaimana jika server diretas? Dalam hal ini, privasi diferensial tidak akan membantu kami, karena hanya melindungi data yang diperoleh sebagai hasil kerja program!
Saat menerapkan sistem berdasarkan prinsip privasi diferensial, penting untuk mempertimbangkan model ancaman: dari lawan mana kami ingin melindungi sistem. Jika model ini menyertakan penyerang yang dapat sepenuhnya menyusupi server dengan data sensitif, maka kita perlu mengubah sistem agar dapat menahan serangan semacam itu.
Artinya, arsitektur sistem yang menghormati privasi diferensial harus mempertimbangkan privasi dan keamanan . Privasi mengontrol apa yang dapat diambil dari data yang dikembalikan oleh sistem. Dan keamanan dapat dianggap sebagai tugas yang berlawanan: ini adalah kontrol atas akses ke bagian dari data, tetapi tidak memberikan jaminan apa pun terkait kontennya.
Model privasi diferensial pusat
Model ancaman yang paling umum digunakan dalam pekerjaan privasi diferensial adalah model privasi diferensial pusat (atau cukup "privasi diferensial pusat").
Komponen utama - penyimpanan data tepercaya (kurator data tepercaya) . Setiap sumber mengirimkan data rahasianya, dan mengumpulkannya di satu tempat (misalnya, di server). Repositori dipercaya jika kami berasumsi bahwa ia memproses data sensitif kami sendiri, tidak mentransfernya kepada siapa pun, dan tidak dapat dikompromikan oleh siapa pun. Dengan kata lain, kami yakin bahwa server dengan data sensitif tidak dapat diretas.
Sebagai bagian dari model utama, kami biasanya menambahkan noise pada respons kueri (kami akan melihat implementasi Laplace di artikel berikutnya). Keuntungan dari model ini adalah kemampuan untuk menambahkan nilai kebisingan serendah mungkin, sehingga menjaga akurasi maksimum yang diperbolehkan oleh prinsip privasi diferensial. Di bawah ini adalah diagram prosesnya. Kami telah menempatkan penghalang privasi antara penyimpanan data tepercaya dan analis sehingga hanya hasil yang memenuhi ketentuan privasi diferensial yang ditentukan yang dapat keluar. Dengan demikian, analis tidak dituntut untuk dipercaya.
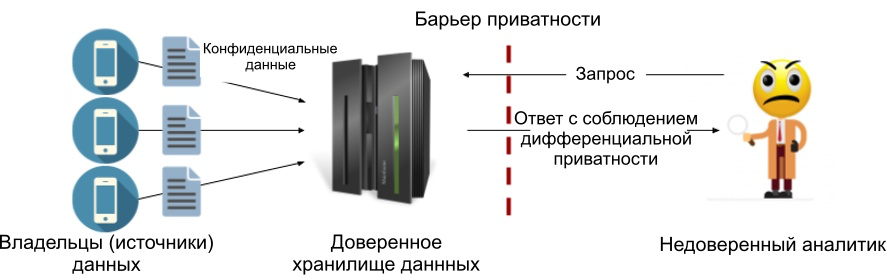
Gambar 1: Model privasi diferensial pusat.
Kerugian dari model sentral adalah membutuhkan penyimpanan tepercaya, dan banyak di antaranya tidak. Faktanya, kurangnya kepercayaan pada konsumen data biasanya menjadi alasan utama untuk menggunakan prinsip privasi diferensial.
Model privasi diferensial lokal
Model privasi diferensial lokal memungkinkan Anda menyingkirkan penyimpanan data tepercaya: setiap sumber data (atau pemilik data) menambahkan gangguan ke datanya sebelum mentransfernya ke penyimpanan. Artinya, penyimpanan tersebut tidak akan pernah berisi informasi sensitif, yang berarti tidak perlu surat kuasa. Gambar di bawah ini menunjukkan perangkat model lokal: di dalamnya, ada penghalang privasi antara setiap pemilik data dan penyimpanan (yang mungkin dipercaya atau tidak).
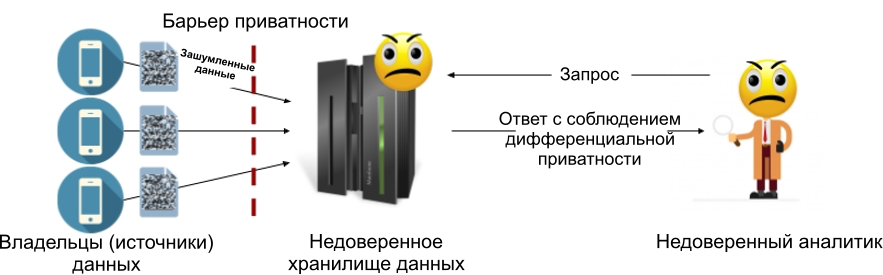
Gambar 2: Model privasi diferensial lokal.
Model lokal privasi diferensial menghindari masalah utama dari model pusat: jika gudang data disusupi, peretas hanya akan memiliki akses ke data berisik yang telah memenuhi persyaratan privasi diferensial. Ini adalah alasan utama mengapa model lokal dipilih untuk sistem seperti Google RAPPOR [1] dan sistem pengumpulan data Apple [2].
Tetapi di sisi lain? Model lokal kurang akurat dibandingkan model pusat. Dalam model lokal, setiap sumber menambahkan derau secara independen untuk memenuhi kondisi privasi diferensial masing-masing, sehingga derau total dari semua peserta jauh lebih besar daripada derau di model pusat.
Pada akhirnya, pendekatan ini hanya dibenarkan untuk kueri dengan tren (sinyal) yang sangat persisten. Apple, misalnya, menggunakan model lokal untuk memperkirakan popularitas emoji, tetapi hasilnya hanya berguna untuk emoji paling populer (yang trennya paling menonjol). Biasanya, model ini tidak digunakan untuk kueri yang lebih kompleks seperti yang digunakan oleh Biro Sensus AS [10] atau pembelajaran mesin.
Model hibrida
Model pusat dan lokal memiliki kelebihan dan kekurangan, dan sekarang upaya utama adalah memanfaatkan yang terbaik dari model tersebut.
Sebagai contoh, Anda dapat menggunakan yang model yang menyeret diimplementasikan dalam sistem Prochlo [4]. Ini berisi penyimpanan data yang tidak tepercaya, banyak pemilik data individual, dan beberapa pengocok tepercaya sebagian .... Setiap sumber pertama-tama menambahkan sedikit noise ke datanya dan kemudian mengirimkannya ke agitator, yang menambahkan lebih banyak noise sebelum mengirimkannya ke gudang data. Intinya adalah bahwa agitator tidak mungkin untuk "berkolusi" (atau dikompromikan pada saat yang sama) dengan penyimpanan data atau dengan satu sama lain, jadi sedikit suara yang ditambahkan oleh sumber akan cukup untuk menjamin privasi. Setiap agitator dapat menangani berbagai sumber, seperti model pusat, jadi sedikit noise akan menjamin privasi untuk kumpulan data yang dihasilkan.
Model agitator adalah kompromi antara model lokal dan sentral: model ini menambahkan lebih sedikit noise daripada model lokal, tetapi lebih dari sentral.
Anda juga dapat menggabungkan privasi diferensial dengan kriptografi, seperti dalam komputasi multipartai yang aman (MPC) atau enkripsi homomorfik penuh (FHE). FHE memungkinkan komputasi dengan data terenkripsi tanpa terlebih dahulu mendekripsinya, dan MPC memungkinkan sekelompok peserta untuk mengeksekusi kueri dengan aman melalui sumber terdistribusi tanpa mengungkapkan data mereka. Perhitungan Fungsi Pribadi Diferensialmenggunakan komputasi crypto-safe (atau hanya aman) adalah cara yang menjanjikan untuk mencapai akurasi model sentral dengan semua manfaat lokal. Selain itu, dalam kasus ini, penggunaan komputasi aman menghilangkan kebutuhan untuk memiliki penyimpanan tepercaya. Pekerjaan terbaru [5] menunjukkan hasil yang menggembirakan dari kombinasi MPC dan privasi diferensial, menyerap sebagian besar keuntungan dari kedua pendekatan tersebut. Benar, dalam kebanyakan kasus, penghitungan yang aman beberapa kali lipat lebih lambat daripada penghitungan yang dilakukan secara lokal, yang sangat penting untuk kumpulan data besar atau kueri kompleks. Komputasi aman saat ini sedang dalam fase pengembangan aktif, sehingga kinerjanya meningkat pesat.
Begitu?
Di artikel berikutnya, kita akan melihat alat sumber terbuka pertama kami untuk menerapkan konsep privasi diferensial. Mari kita lihat alat lain, yang tersedia untuk pemula dan dapat diterapkan untuk database yang sangat besar, seperti yang ada di Biro Sensus AS. Kami akan mencoba menghitung data populasi sesuai dengan prinsip privasi diferensial.
Berlangganan ke blog kami dan jangan lewatkan terjemahan artikel selanjutnya. Secepatnya.
Sumber
[1] Erlingsson, Úlfar, Vasyl Pihur, dan Aleksandra Korolova. "Rappor: Tanggapan ordinal pemelihara privasi agregat acak." Dalam Prosiding konferensi ACM SIGSAC 2014 tentang komputer dan keamanan komunikasi, hal. 1054-1067. 2014.
[2] Apple Inc. "Ikhtisar Teknis Privasi Diferensial Apple". Diakses 7/31/2020. https://www.apple.com/privacy/docs/Differential_Privacy_Overview.pdf
[3] Garfinkel, Simson L., John M. Abowd, dan Sarah Powazek. "Masalah yang dihadapi saat menerapkan privasi diferensial." Dalam Proceedings of the 2018 Workshop on Privacy in the Electronic Society, hal. 133-137. 2018.
[4] Bittau, Andrea, Úlfar Erlingsson, Petros Maniatis, Ilya Mironov, Ananth Raghunathan, David Lie, Mitch Rudominer, Ushasree Kode, Julien Tinnes, dan Bernhard Seefeld. "Prochlo: Privasi yang kuat untuk analitik di kerumunan." Dalam Prosiding Simposium 26 tentang Prinsip Sistem Operasi, hal. 441-459. 2017.
[5] Roy Chowdhury, Amrita, Chenghong Wang, Xi He, Ashwin Machanavajjhala, dan Somesh Jha. "Cryptε: Privasi Diferensial yang Dibantu oleh Crypto pada Server yang Tidak Dipercaya." Dalam Prosiding Konferensi Internasional ACM SIGMOD 2020 tentang Manajemen Data, hal. 603-619. 2020.