EXPLAIN (ANALYZE, BUFFERS) ...merupakan alat favorit Anda untuk mempelajari tentang kekhasan DBMS ini, "chip" baru yang berguna dari layanan kami untuk visualisasi dan analisis rencana menjelaskan.tensor.ru pasti akan berguna bagi Anda dalam tugas yang sulit ini.
Tapi izinkan saya segera mengingatkan Anda bahwa tanpa pemantauan komprehensif lengkap dari database PostgreSQL, hanya menggunakan analisis rencana adalah bertindak dari posisi bijak # 5!

[ sumber KDPV , "Si Buta dan Gajah" ]
, 1940
, ,
.
,
,
, .
, —
.
,
:
—
!
,
,
, ,
.
,
,
,
.
Perselisihan muncul di antara orang buta
Dan berlangsung selama setahun penuh.
Kemudian orang-
orang buta itu akhirnya menggerakkan tangan mereka.
Dan karena yang kelima kuat,
- Dia menutup mulut semua orang.
Dan untuk selanjutnya gajah terdiri dari
satu ekor!
Jadi, hari ini dalam program:
- ubah "tanda pangkat" menjadi "tali bahu"
- kami menyatukan rencana "mega"
- kami menyimpan arsip pribadi
- mempelajari silsilah rencana
- mengintip ke dalam "jendela"
Tidak ada satu warna pun!
Secara historis, saat melihat rencana, kami menandai node "terpanas" dengan "chevron" vertikal di sebelah kiri nilai - semakin tinggi nilainya, semakin kaya warnanya.

Tetapi dalam model seperti itu, rasio nilai dipersepsikan dengan buruk - misalnya, penyimpangan 30% dalam perbedaan corak hanya dapat dilihat oleh mata yang terlatih. Oleh karena itu, kami membuat histogram dari "tali bahu" horizontal.

Statistik yang berguna untuk rencana "mega"
Banyak orang tidak memperhatikan tab "Statistik" dari rencana tersebut, ini dia di sebelah kanan:

Dan siapa pun yang memperhatikan - hampir tidak aktif menggunakannya. Kami memutuskan untuk memperbaiki kelalaian ini dan membuatnya sangat berguna untuk analisis rencana "besar" (100+ node).
Mengelompokkan node
Semua node rencana "identik" (yaitu node dengan jenis node yang sama, tabel yang digunakan, dan indeks) dikelompokkan ke dalam satu baris tabel. Dalam hal ini, semua indikatornya (waktu eksekusi, jumlah catatan yang dibaca dan dibuang, jumlah operan dan jumlah data yang dibaca) diringkas.
Dan untuk kejelasan, setiap jenis node membawa label warna:
- merah - membaca data
nodeSeq Scan,Index Scan,CTE Scandan berbagai lainnya... Scan - kuning - mengolah data
nodeSort,Unique,Aggregate,Group,Materialize, ... - hijau - koneksi
nodeNested Loop,Merge Join,Hash Join, ...

Menyortir berdasarkan indikator apa pun
Jika tiba-tiba Anda membutuhkan analisis bukan berdasarkan total waktu, tetapi berdasarkan jenis node, misalnya - cukup klik pada judul kolom - dan semuanya akan menjadi:

Petunjuk node kontekstual
Untuk memahami secara mendetail kontribusi node tertentu dalam grup, arahkan kursor ke nomor salah satu dari mereka - dan Anda akan melihat petunjuk tradisional tentang apa yang sebenarnya terjadi di sana:
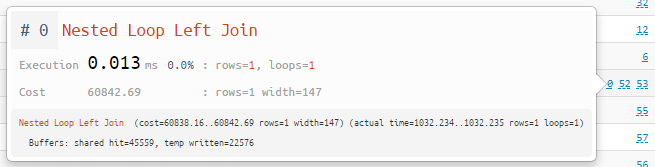
Arsip pribadi rencana
"Tanpa registrasi dan SMS!"Jika Anda secara aktif menggunakan layanan kami, sekarang akan jauh lebih mudah untuk menemukan rencana Anda yang sebelumnya dianalisis - cukup beralih ke tab "milik saya" di arsip . Rencana jatuh di sini terlepas dari publikasi dalam arsip umum dan hanya dapat dilihat oleh Anda.

Silsilah rencana
Sebelumnya, cukup sulit untuk menemukan rencana Anda secara spesifik dalam arsip, sekarang menjadi sederhana. Mereka dapat diberi nama dan dikelompokkan ke dalam "pohon keluarga" pengoptimalan!
Cukup tentukan nama saat menambahkan rencana:

... atau pada rencana yang ada, Anda dapat mengaturnya, mengedit atau menambahkan rencana tertaut:

Kemudian Anda dapat dengan cepat beralih ke seluruh pohon opsi untuk mengevaluasi efek pengoptimalan tertentu:

Dan jika tautan ke rencana tertentu tiba-tiba hilang, dia dapat dengan mudah diidentifikasi dengan namanya di arsip pribadinya:

Kami mengintip ke dalam "jendela"
Peningkatan kecil namun bermanfaat untuk Query Profiler , yang saya tulis sebelumnya - kami mengajarkannya untuk "melihat ke dalam jendela" dan memetakan dengan benar untuk merencanakan node:
-> WindowAgg ==> WINDOW / OVER
-> Sort ==> PARTITION BY / ORDER BY... sebagai beberapa definisi independen dari "window" (
WINDOW) dalam satu kueri:
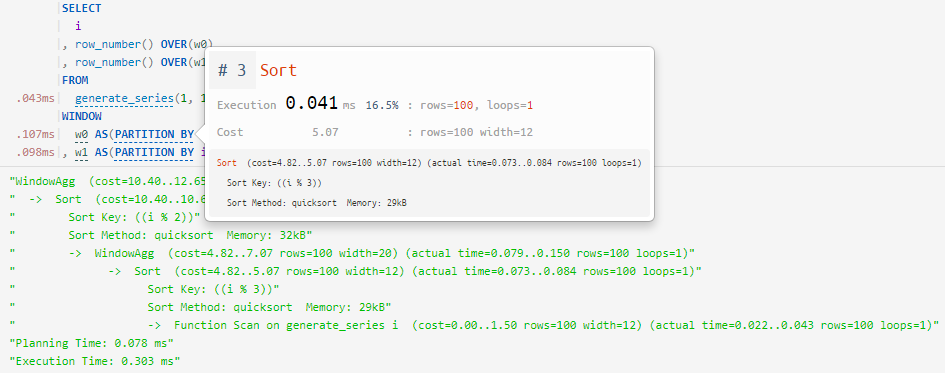
... dan penyortiran dalam fungsi jendela tanpa definisi eksplisit:

Selamat berburu berbagai inefisiensi!