Memulai sebuah contoh
Di bawah ini kami akan menulis aplikasi sederhana di java (penulis menggunakan java 14, tetapi java 8 juga baik-baik saja), mengukur kinerjanya menggunakan penghitung di dalam aplikasi, dan mencoba meningkatkan hasilnya dengan menjalankan kode di beberapa utas. Semua yang diperlukan untuk mereproduksi contoh adalah lingkungan pengembangan java atau hanya jdk dan utilitas visualvm yang akan membantu kami mendiagnosis masalah yang muncul. Contoh tersebut sengaja tidak menggunakan berbagai tolok ukur untuk mengukur kinerja dan alat canggih lainnya - dalam hal ini, mereka berlebihan. Kasus uji dijalankan di bawah Windows pada prosesor Intel Core i7 dengan 4 inti fisik dan 8 inti logis.
Jadi, mari kita buat aplikasi sederhana yang dalam satu loop akan melakukan tugas komputasi yang membebani prosesor, yaitu perhitungan faktorial. Selain itu, setiap tugas dalam loop juga akan menghitung faktorial dari sebuah bilangan yang berada dalam rentang dari 1 hingga 25. Rentang mengambang diambil untuk membawa contoh lebih dekat ke kenyataan. Di bawah ini adalah kode untuk fungsi work ():
void work(int power) {
for (int i = 0; i < power; i++) {
long result = factorial(RandomUtils.nextInt(1, 25));
}
if (counter.incrementAndGet() % LOG_STEP == 0) {
System.out.printf("%d %d %n", counter.longValue(), (long) ((System.currentTimeMillis() - startTime) / 1000));
}
}
Fungsi menerima sebagai masukan jumlah siklus untuk menghitung faktorial, ditentukan oleh konstanta:
private static final int POWER_BASE = 1000000;Setelah menyelesaikan sejumlah tugas yang ditentukan dalam variabel
private static final int LOG_STEP = 10;Jumlah tugas yang diselesaikan dan total waktu pelaksanaannya dicatat. Fungsi
work () juga menggunakan:
//
private long startTime;
//
private AtomicLong counter = new AtomicLong();
//
private long factorial(int power) {
if (power == 1) return power;
else return power * factorial(power - 1);
}
Perlu dicatat bahwa eksekusi satu kali dari fungsi work () dalam satu utas membutuhkan waktu sekitar 20 md, sehingga panggilan yang disinkronkan ke variabel penghitung bersama di akhir, yang dapat menjadi hambatan, tidak menimbulkan masalah, karena ini terjadi untuk setiap utas tidak lebih dari 20 kali ms, yang secara signifikan melebihi waktu eksekusi counter.incrementAndGet (). Dengan kata lain, perselisihan antara utas yang terkait dengan akses ke penghitung tersinkronisasi tidak boleh secara signifikan memengaruhi hasil eksperimen dan dapat diabaikan.
Mari kita jalankan kode berikut dalam satu utas dan lihat hasilnya:
startTime = System.currentTimeMillis();
for (int i = 0; i < Integer.MAX_VALUE; i++) {
work(POWER_BASE);
}
Di konsol kita melihat output berikut:
10 Tugas selesai dalam 0 detik
...
100 Tugas selesai dalam 2 detik
...
500 Tugas selesai dalam 10 detik
Jadi, dalam satu utas, kami mendapatkan kinerja yang setara dengan 50 tugas per detik atau 20 md per tugas.
Memparalelkan kode
Jika kami mendapatkan kinerja X dalam satu utas, maka pada 4 prosesor, jika tidak ada beban tambahan, kami dapat mengharapkan bahwa kinerja akan menjadi sekitar 4 * X, yaitu akan meningkat 4 kali lipat. Ini sepertinya cukup logis. Ayo coba!
Mari perkenalkan kolam sederhana dengan jumlah utas tetap:
private ExecutorService executorService = Executors.newFixedThreadPool(POOL_SIZE);
Konstan:
private static final int POOL_SIZE = 1;Kami akan mengubah rentang dari 1 hingga 16 dan memperbaiki hasilnya.
Mendesain ulang kode peluncuran:
startTime = System.currentTimeMillis();
for (int i = 0; i < Integer.MAX_VALUE; i++) {
executorService.execute(() -> work(POWER_BASE));
}
Secara default, ukuran antrian tugas di kumpulan utas adalah Integer.MAX_VALUE, kami menambahkan tidak lebih dari tugas Integer.MAX_VALUE ke kumpulan utas, jadi antrian tugas tidak boleh meluap.
Pergilah!
Pertama, mari kita setel konstanta POOL_SIZE menjadi 8 utas:
private static final int POOL_SIZE = 8;menjalankan aplikasi dan melihat konsol:
10 Tugas selesai dalam 3 detik
20 Tugas selesai dalam 6 detik
30 Tugas selesai dalam 8 detik
40 Tugas selesai dalam 10 detik
50 Tugas selesai dalam 14 detik
60 Tugas selesai dalam 16 detik
70 Tugas selesai dalam 19 detik
80 Tugas diselesaikan dalam 20 detik
90 Tugas selesai dalam 23 detik
100 Tugas selesai dalam 24 detik
110 Tugas selesai dalam 26 detik
120 Tugas selesai dalam 28 detik
130 Tugas selesai dalam 29 detik
140 Tugas selesai dalam 31 detik
150 Tugas selesai dalam 33 detik
160 Tugas selesai dalam 36 detik
170 Tugas diselesaikan dalam 46 detik
Apa yang kita lihat? Alih-alih peningkatan kinerja yang diharapkan, itu turun lebih dari 10 kali dari 20ms per tugas menjadi 270ms. Tapi itu belum semuanya! Pesan tentang 170 tugas yang diselesaikan adalah yang terakhir di log. Kemudian aplikasi tersebut sepertinya berhenti total.
Sebelum membahas alasan untuk perilaku aneh program ini, mari pahami dinamika dan hapus log secara berurutan untuk 4 dan 16 utas dengan menyetel konstanta POOL_SIZE ke nilai yang sesuai.
Log untuk 4 utas:
10 Tugas selesai dalam 2 detik
20 Tugas selesai dalam 4 detik
30 Tugas selesai dalam 6 detik
40 Tugas selesai dalam 8 detik
50 Tugas selesai dalam 10 detik
60 Tugas selesai dalam 13 detik
70 Tugas selesai dalam 15 detik
80 Tugas selesai dalam 18 detik
90 Tugas selesai dalam 21 detik
100 Tugas selesai dalam 33 detik
90 tugas pertama diselesaikan dalam waktu yang hampir bersamaan dengan 8 utas, kemudian 12 detik lagi diperlukan untuk menyelesaikan 10 tugas lagi dan aplikasi macet.
Log untuk 16 thread:
10 Tugas selesai dalam 2 detik
20 Tugas selesai dalam 3 detik
30 Tugas selesai dalam 6 detik
40 Tugas selesai dalam 8 detik
...
290 Tugas selesai dalam 51 detik
300 Tugas selesai dalam 52 detik
310 Tugas selesai dalam 63 detik
Setelah selesai Untuk 310 tugas, aplikasi membeku dan, seperti pada kasus sebelumnya, 10 tugas terakhir membutuhkan waktu lebih dari 10 detik untuk diselesaikan.
Mari kita rangkum:
Memparalelkan pelaksanaan tugas menyebabkan penurunan kinerja sebanyak 10 kali atau lebih
. Dalam semua kasus, aplikasi hang dan semakin sedikit utas semakin cepat hang (kami akan kembali ke fakta ini)
Cari masalah
Jelas, ada yang salah dengan kode kami. Tetapi bagaimana Anda menemukan alasannya? Untuk melakukan ini, kami akan menggunakan utilitas visualvm. Dan kami akan meluncurkannya sebelum eksekusi aplikasi kami, dan setelah meluncurkan aplikasi kami akan beralih ke proses java yang diperlukan dalam antarmuka visualvm. Aplikasi dapat diluncurkan langsung dari lingkungan pengembangan. Tentu saja, ini umumnya salah, tetapi dalam contoh kami hal itu tidak akan memengaruhi hasil.
Pertama-tama, kami melihat tab Monitor dan melihat ada sesuatu yang salah dengan memori.
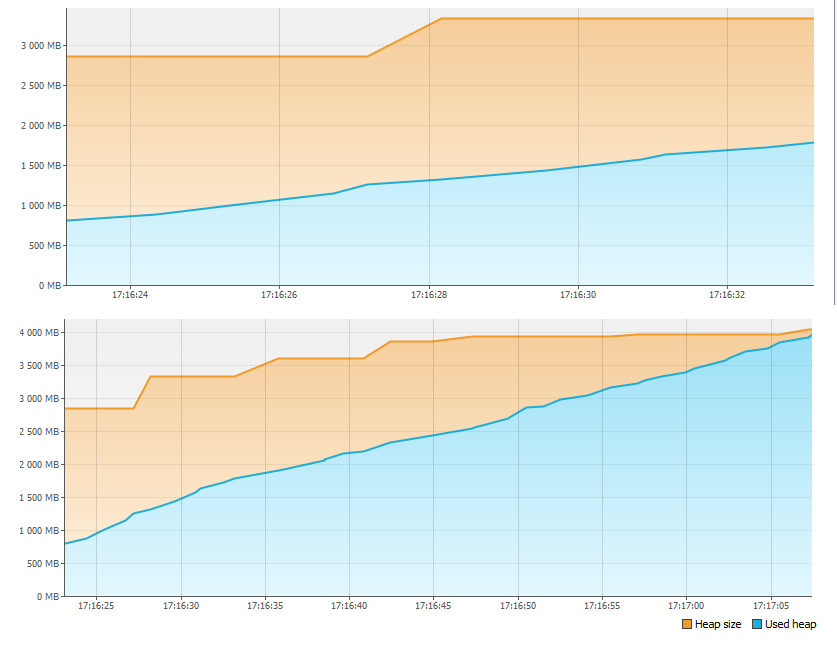
Dalam waktu kurang dari satu menit, memori 4GB akan habis! Oleh karena itu, aplikasi dihentikan. Tapi kemana perginya ingatan itu?
Mulai ulang aplikasi dan tekan tombol Heap Dump pada tab Monitor. Setelah menghapus dan membuka dump memori, kita melihat:

Di bagian Classes by Size of Instances, lebih dari 1 GB ditempati oleh class $ Node LinkedBlockingQueue. Ini tidak lebih dari satu atas antrian tugas kumpulan benang. Kelas terbesar kedua adalah tugas itu sendiri ditambahkan ke kumpulan utas. Untuk mendukung ini, di bagian Classes By Number of Instances, kita melihat korespondensi antara jumlah instance dari kelas pertama dan kedua (kecocokan tidak sepenuhnya akurat, tampaknya karena fakta bahwa tugas pertama dibuat, dan kemudian hanya top antrian baru, dan karena perbedaan waktu dikalikan dengan jumlah utas, kami memiliki sedikit perbedaan dalam jumlah contoh).
Sekarang mari kita hitung. Kami membuat sekitar 2 miliar tugas dalam satu lingkaran (Integer.MAX_VALUE), yaitu sekitar 2 GB tugas. Tugas dijalankan lebih lambat daripada yang dibuat, sehingga ukuran antrian terus bertambah. Meskipun setiap tugas hanya membutuhkan memori 8 byte, ukuran antrian maksimum adalah:
8 * 2GB = 16GB
Dengan total ukuran heap 4GB, tidak mengherankan jika memori tidak cukup. Faktanya, jika kita tidak menghentikan eksekusi aplikasi yang lognya berhenti, setelah beberapa saat kita akan melihat OutOfMemoryError yang terkenal dan bahkan tanpa visualvm, hanya dengan melihat kodenya, kita bisa menebak kemana perginya memori.
Ingatlah bahwa semakin sedikit jumlah thread yang menjalankan tugas, semakin cepat aplikasi berhenti. Sekarang kami dapat mencoba menjelaskan ini. Semakin sedikit jumlah utas, semakin cepat aplikasi berjalan (mengapa - kita belum mengetahuinya) dan semakin cepat antrian tugas terisi dan memori menjadi penuh.
Nah, memperbaiki masalah kelebihan memori sangatlah sederhana. Mari buat konstanta, bukan Integer.MaxValue:
MAX_TASKS pribadi static final = 1024 * 1024;
Dan mari kita ubah kodenya sebagai berikut:
startTime = System.currentTimeMillis();
for (int i = 0; i < MAX_TASKS; i++) {
executorService.execute(() -> work(POWER_BASE));
}
Sekarang tinggal menjalankan aplikasi dan memastikan semuanya sesuai dengan memori:

Kami melanjutkan analisis
Kami meluncurkan aplikasi kami lagi, secara berurutan meningkatkan jumlah utas dan memperbaiki hasilnya.
1 utas - 500 Tugas dalam 10 detik
2 utas - 500 tugas dalam 21 detik
4 utas - 500 Tugas dalam 37 detik
8 utas - 500 Tugas dalam 49 detik
16 utas - 500 Tugas dalam 57 detik
Seperti yang bisa kita lihat, waktu eksekusi 500 tugas saat meningkat jumlah utas tidak berkurang, tetapi bertambah, sedangkan kecepatan eksekusi setiap bagian dari 10 tugas seragam dan utas tidak lagi membeku.
Mari gunakan lagi utilitas visualvm dan ambil thread dump saat aplikasi sedang berjalan. Untuk gambar yang paling akurat, lebih baik membuang saat mengerjakan 16 utas. Ada beberapa utilitas yang berbeda untuk menganalisis thread dump, tetapi dalam kasus kami, Anda cukup menggulir semua utas dengan nama "pool-1-thread-1", "pool-1-thread-2", dll. Di antarmuka visualvm dan lihat yang berikut ini:

Saat membuang, sebagian besar untaian menghasilkan nomor acak berikutnya untuk menghitung faktorial. Ternyata ini adalah fungsi yang paling memakan waktu. Lalu kenapa? Untuk mengetahuinya, mari masuk ke kode sumber Random.next () dan lihat yang berikut ini:
private final AtomicLong seed;
protected int next(int bits) {
long oldseed, nextseed;
AtomicLong seed = this.seed;
do {
oldseed = seed.get();
nextseed = (oldseed * multiplier + addend) & mask;
} while (!seed.compareAndSet(oldseed, nextseed));
return (int)(nextseed >>> (48 - bits));
}
Semua utas berbagi satu contoh dari variabel benih, akses yang disinkronkan menggunakan kelas AtomicLong. Ini berarti bahwa ketika setiap nomor acak dibuat, utas antri untuk mengakses variabel itu, daripada dieksekusi secara paralel. Oleh karena itu, produktivitas tidak tumbuh. Tapi kenapa dia jatuh? Jawabannya sederhana. Saat memparalelkan eksekusi, sumber daya tambahan dihabiskan untuk mendukung pemrosesan paralel, khususnya, mengalihkan konteks prosesor antar utas. Ternyata biaya tambahan telah muncul, dan utas masih tidak berfungsi secara paralel, karena mereka bersaing untuk mendapatkan akses ke nilai variabel seed dan dimasukkan ke dalam antrean saat seed.compareAndSet () dipanggil. Persaingan antar utas untuk sumber daya terbatas, mungkinpenyebab paling umum dari penurunan performa saat memparalelkan komputasi.
Mari kita ubah kode fungsi work () sebagai berikut:
void work(int power) {
for (int i = 0; i < power; i++) {
long result = factorial(20);
}
if (counter.incrementAndGet() % LOG_STEP == 0) {
System.out.printf("%d %d %n", counter.longValue(), (long) ((System.currentTimeMillis() - startTime) / 1000));
}
}
dan sekali lagi periksa kinerja pada jumlah utas yang berbeda:
1 utas - 1000 tugas dalam 17 detik
2 utas - 1000 tugas dalam 10 detik
4 utas - 1000 tugas dalam 5 detik
8 utas - 1000 tugas dalam 4 detik
16 utas - 1000 tugas dalam 4 detik
Sekarang hasilnya mendekati harapan kami. Performa pada 4 thread telah meningkat sekitar 4 kali lipat. Lebih lanjut, peningkatan kinerja secara praktis terhenti karena paralelisasi dibatasi oleh sumber daya prosesor. Mari kita lihat grafik beban prosesor yang ditangkap melalui visualvm saat mengerjakan 4 dan 8 utas.

Seperti yang dapat dilihat dari grafik, dengan 4 utas, lebih dari 50% sumber daya prosesor gratis, dan dengan 8 utas, prosesor digunakan hampir 100%. Artinya dalam contoh ini, 8 utas adalah batasnya, kinerja selanjutnya hanya akan menurun. Dalam contoh kami, pertumbuhan kinerja sudah berhenti pada 4 utas, tetapi jika utas, alih-alih menghitung faktorial, melakukan I / O sinkron, kemungkinan besar, batas paralelisasi di mana peningkatan kinerja dapat ditingkatkan secara signifikan. Pembaca dapat memeriksanya sendiri dan menulis hasilnya di komentar pada artikel.
Jika kita berbicara tentang latihan, maka dua poin penting dapat dicatat:
Paralelisasi biasanya efektif ketika jumlah utas hingga 2 kali jumlah inti prosesor (tentu saja, jika tidak ada beban prosesor lainnya)
Penggunaan CPU dalam praktiknya tidak boleh melebihi 80% untuk memastikan toleransi kesalahan
Mengurangi perselisihan antar utas
Terbawa oleh pembicaraan tentang kinerja, kita melupakan satu hal yang esensial. Dengan mengubah panggilan ke RandomUtils.nextInt () dalam kode menjadi konstanta, kami mengubah logika bisnis aplikasi kami. Mari kembali ke algoritme lama sambil menghindari masalah kinerja. Kami menemukan bahwa memanggil RandomUtils.nextInt () menyebabkan setiap utas menggunakan variabel benih yang sama untuk menghasilkan nomor acak, dan, sementara itu, ini sepenuhnya opsional. Menggunakan dalam contoh kami, bukan
RandomUtils.nextInt(1, 25)dari kelas ThreadLocalRandom:
ThreadLocalRandom.current().nextInt(1, 25)akan menyelesaikan masalah dengan persaingan. Sekarang setiap utas akan menggunakan contoh sendiri dari variabel internal yang diperlukan untuk menghasilkan nomor acak berikutnya.
Menggunakan variabel terpisah untuk setiap utas, alih-alih akses yang disinkronkan ke satu instance kelas yang dibagi antar utas, adalah teknik umum untuk meningkatkan kinerja dengan mengurangi perselisihan di antara utas. Kelas java.lang.ThreadLocal dapat digunakan untuk menyimpan nilai variabel dalam konteks utas, meskipun ada alat yang lebih canggih, misalnya, Konteks Diagnostik yang Dipetakan.
Sebagai kesimpulan, saya ingin mencatat bahwa mengurangi persaingan antar utas tidak hanya bersifat teknis, tetapi juga tugas logis. Dalam contoh kita, setiap utas dapat menggunakan variabel sendiri tanpa masalah, tetapi bagaimana jika kita membutuhkan satu contoh untuk semua, misalnya, penghitung umum? Dalam kasus ini, Anda harus memfaktor ulang algoritme itu sendiri. Misalnya, simpan penghitung dalam konteks setiap aliran dan secara berkala atau atas permintaan menghitung nilai penghitung total berdasarkan nilai penghitung untuk setiap aliran.
Kesimpulan
Jadi, ada 3 poin yang mempengaruhi kinerja pemrosesan paralel:
- Sumber daya CPU
- Persaingan antar utas
- Faktor lain yang secara tidak langsung mempengaruhi hasil secara keseluruhan