
Terapkan dan bandingkan 4 pengoptimal pelatihan jaringan neural yang populer: pengoptimal impuls, propagasi rms, penurunan gradien batch mini, dan estimasi torsi adaptif. Repositori, banyak kode Python dan outputnya, visualisasi, dan rumusnya semuanya terpotong.
pengantar
Model adalah hasil dari algoritme pembelajaran mesin yang berjalan pada beberapa data. Model tersebut merepresentasikan apa yang telah dipelajari oleh algoritme. Ini adalah "hal" yang tetap ada setelah menjalankan algoritme pada data pelatihan dan mewakili aturan, angka, dan struktur data lainnya yang spesifik untuk algoritme dan diperlukan untuk prediksi.
Apa itu pengoptimal?
Sebelum melanjutkan ke ini, kita perlu tahu apa itu fungsi kerugian. Fungsi kerugian adalah ukuran seberapa baik model prediksi Anda memprediksi hasil (atau nilai) yang diharapkan. Fungsi kerugian juga disebut fungsi biaya (informasi lebih lanjut di sini ).
Selama pelatihan, kami mencoba meminimalkan hilangnya fungsi dan memperbarui parameter untuk meningkatkan akurasi. Parameter jaringan saraf biasanya adalah bobot tautan. Dalam hal ini, parameter dipelajari pada tahap pelatihan. Jadi, algoritme itu sendiri (dan data masukan) menyesuaikan parameter ini. Informasi lebih lanjut dapat ditemukan di sini .
Jadi, pengoptimal adalah metode untuk mencapai hasil yang lebih baik, membantu mempercepat pembelajaran. Dengan kata lain, ini adalah algoritme yang digunakan untuk membuat sedikit penyesuaian pada parameter seperti bobot dan kecepatan pembelajaran agar model tetap berjalan dengan benar dan cepat. Berikut adalah ikhtisar dasar dari berbagai pengoptimal yang digunakan dalam pembelajaran mendalam dan model sederhana untuk memahami penerapan model tersebut. Saya sangat merekomendasikan kloning repositori ini dan membuat perubahan dengan mengamati pola perilaku.
Beberapa istilah yang umum digunakan:
- Propagasi balik
Tujuan propagasi mundur sederhana: sesuaikan setiap bobot di jaringan sesuai dengan seberapa besar kontribusinya terhadap kesalahan keseluruhan. Jika Anda mengurangi kesalahan setiap bobot secara berulang, Anda akan mendapatkan serangkaian bobot yang memberikan prediksi yang baik. Kami menemukan kemiringan setiap parameter untuk fungsi kerugian dan memperbarui parameter dengan mengurangi kemiringan (info lebih lanjut di sini ).

- Penurunan gradien
Penurunan gradien adalah algoritme pengoptimalan yang digunakan untuk meminimalkan fungsi dengan bergerak secara berulang menuju penurunan paling curam, yang ditentukan oleh nilai gradien negatif. Dalam pembelajaran mendalam, kami menggunakan penurunan gradien untuk memperbarui parameter model (info selengkapnya di sini ).
- Hyperparameter
Hyperparameter model adalah konfigurasi di luar model, yang nilainya tidak dapat diperkirakan dari data. Misalnya, jumlah neuron tersembunyi, kecepatan pembelajaran, dll. Kami tidak dapat memperkirakan kecepatan pembelajaran dari data (informasi selengkapnya di sini ).
- Kecepatan pembelajaran
Kecepatan pembelajaran (α) adalah parameter penyetelan dalam algoritme pengoptimalan yang menentukan ukuran langkah pada setiap iterasi sambil bergerak menuju fungsi kerugian minimum (informasi selengkapnya di sini).
Pengoptimal populer

Di bawah ini adalah beberapa SEO paling populer:
- Penurunan Gradien Stochastic (SGD).
- Pengoptimal Momentum.
- Root mean square propagation (RMSProp).
- Estimasi torsi adaptif (Adam).
Mari kita pertimbangkan masing-masing secara rinci.
1. Penurunan gradien stokastik (terutama tumpukan-mini)
Kami menggunakan satu contoh saat melatih model (dalam SGD murni) dan memperbarui parameter. Tapi kita harus menggunakan yang lain untuk loop. Ini akan memakan banyak waktu. Oleh karena itu, kami menggunakan SGD mini-batch.
Penurunan gradien batch mini berupaya menyeimbangkan ketahanan penurunan gradien stokastik dan efisiensi penurunan gradien batch. Ini adalah implementasi penurunan gradien yang paling umum digunakan dalam pembelajaran mendalam. Dalam SGD batch mini, saat melatih model, kami mengambil sekelompok contoh (misalnya 32, 64 contoh, dll.). Pendekatan ini bekerja lebih baik karena hanya membutuhkan satu putaran untuk minibatch, tidak semua contoh. Paket mini dipilih secara acak untuk setiap iterasi, tetapi mengapa? Ketika paket mini dipilih secara acak, maka ketika terjebak dalam minimum lokal, beberapa langkah yang berisik dapat menyebabkan keluarnya dari minimum ini. Mengapa kita membutuhkan pengoptimal ini?
- Laju pembaruan parameter lebih tinggi daripada di penurunan gradien batch sederhana, yang memungkinkan konvergensi lebih andal dengan menghindari minimum lokal.
- Pembaruan batch memberikan proses komputasi yang lebih efisien daripada penurunan gradien stokastik.
- Jika Anda memiliki sedikit RAM, maka paket mini adalah pilihan terbaik. Pengelompokan efisien karena tidak adanya semua data pelatihan dalam memori dan implementasi algoritma.
Bagaimana cara membuat paket mini acak?
def RandomMiniBatches(X, Y, MiniBatchSize):
m = X.shape[0]
miniBatches = []
permutation = list(np.random.permutation(m))
shuffled_X = X[permutation, :]
shuffled_Y = Y[permutation, :].reshape((m,1)) #sure for uptpur shape
num_minibatches = m // MiniBatchSize
for k in range(0, num_minibatches):
miniBatch_X = shuffled_X[k * MiniBatchSize:(k + 1) * MiniBatchSize,:]
miniBatch_Y = shuffled_Y[k * MiniBatchSize:(k + 1) * MiniBatchSize,:]
miniBatch = (miniBatch_X, miniBatch_Y)
miniBatches.append(miniBatch)
#handeling last batch
if m % MiniBatchSize != 0:
# end = m - MiniBatchSize * m // MiniBatchSize
miniBatch_X = shuffled_X[num_minibatches * MiniBatchSize:, :]
miniBatch_Y = shuffled_Y[num_minibatches * MiniBatchSize:, :]
miniBatch = (miniBatch_X, miniBatch_Y)
miniBatches.append(miniBatch)
return miniBatches
Apa format modelnya?
Saya memberikan gambaran umum tentang model ini jika Anda baru dalam pembelajaran mendalam. Ini terlihat seperti ini:
def model(X,Y,learning_rate,num_iter,hidden_size,keep_prob,optimizer):
L = len(hidden_size)
params = initilization(X.shape[1], hidden_size)
for i in range(1,num_iter):
MiniBatches = RandomMiniBatches(X, Y, 64) # GET RAMDOMLY MINIBATCHES
p , q = MiniBatches[2]
for MiniBatch in MiniBatches: #LOOP FOR MINIBATCHES
(MiniBatch_X, MiniBatch_Y) = MiniBatch
cache, A = model_forward(MiniBatch_X, params, L,keep_prob) #FORWARD PROPOGATIONS
cost = cost_f(A, MiniBatch_Y) #COST FUNCTION
grad = backward(MiniBatch_X, MiniBatch_Y, params, cache, L,keep_prob) #BACKWARD PROPAGATION
params = update_params(params, grad, beta=0.9,learning_rate=learning_rate)
return params
Pada gambar berikut, Anda dapat melihat perubahan besar dalam SGD. Gerakan vertikal tidak perlu: kami hanya menginginkan gerakan horizontal. Jika Anda mengurangi gerakan vertikal dan meningkatkan gerakan horizontal, model akan belajar lebih cepat, setuju?

Bagaimana cara meminimalkan getaran yang tidak diinginkan? Pengoptimal berikut meminimalkannya dan membantu mempercepat pembelajaran.
2. Pengoptimal impuls
Ada banyak keraguan dalam SGD atau penurunan gradien. Anda harus bergerak maju, bukan ke atas dan ke bawah. Kami perlu meningkatkan kecepatan pembelajaran model ke arah yang benar, dan kami akan melakukannya dengan pengoptimal momentum.

Seperti yang Anda lihat pada gambar di atas, Garis Hijau Pengoptimal Pulsa lebih cepat daripada yang lain. Pentingnya belajar dengan cepat dapat dilihat ketika Anda memiliki kumpulan data yang besar dan banyak iterasi. Bagaimana cara menerapkan pengoptimal ini?

Nilai normal untuk β adalah sekitar 0,9 Anda
dapat melihat bahwa kami membuat dua parameter - vdW, dan vdb - dari parameter backpropagation . Perhatikan nilai β = 0.9, maka persamaannya berupa:
vdw= 0.9 * vdw + 0.1 * dw
vdb = 0.9 * vdb + 0.1 * dbSeperti yang Anda lihat, vdw lebih bergantung pada nilai vdw sebelumnya daripada dw. Jika render adalah grafik, Anda dapat melihat bahwa Pengoptimal Momentum memperhitungkan gradien masa lalu untuk memperlancar pembaruan. Inilah mengapa dimungkinkan untuk meminimalkan fluktuasi. Saat kami menggunakan SGD, jalur yang diambil oleh penurunan gradien tumpukan-mini berosilasi menuju konvergensi. Pengoptimal Momentum membantu mengurangi fluktuasi ini.
def update_params_with_momentum(params, grads, v, beta, learning_rate):
# grads has the dw and db parameters from backprop
# params has the W and b parameters which we have to update
for l in range(len(params) // 2 ):
# HERE WE COMPUTING THE VELOCITIES
v["dW" + str(l + 1)] = beta * v["dW" + str(l + 1)] + (1 - beta) * grads['dW' + str(l + 1)]
v["db" + str(l + 1)] = beta * v["db" + str(l + 1)] + (1 - beta) * grads['db' + str(l + 1)]
#updating parameters W and b
params["W" + str(l + 1)] = params["W" + str(l + 1)] - learning_rate * v["dW" + str(l + 1)]
params["b" + str(l + 1)] = params["b" + str(l + 1)] - learning_rate * v["db" + str(l + 1)]
return params
Repositori ada di sini
3. Root mean square spread
Root root mean square (RMSprop) adalah mean yang membusuk secara eksponensial. Properti penting dari RMSprop adalah Anda tidak terbatas hanya pada jumlah gradien sebelumnya, tetapi Anda lebih terbatas pada gradien dari langkah terakhir kali. RMSprop berkontribusi pada rata-rata yang membusuk secara eksponensial dari "gradien hukum kuadrat" masa lalu. Dalam RMSProp kami mencoba untuk mengurangi gerakan vertikal dengan menggunakan mean, karena mereka menjumlahkan sekitar 0 dengan mengambil mean. RMSprop memberikan rata-rata untuk pembaruan.

Sumber

Lihatlah kode di bawah ini. Ini akan memberi Anda pemahaman dasar tentang cara menerapkan pengoptimal ini. Semuanya sama dengan SGD, kita harus mengubah fungsi update.
def initilization_RMS(params):
s = {}
for i in range(len(params)//2 ):
s["dW" + str(i)] = np.zeros(params["W" + str(i)].shape)
s["db" + str(i)] = np.zeros(params["b" + str(i)].shape)
return s
def update_params_with_RMS(params, grads,s, beta, learning_rate):
# grads has the dw and db parameters from backprop
# params has the W and b parameters which we have to update
for l in range(len(params) // 2 ):
# HERE WE COMPUTING THE VELOCITIES
s["dW" + str(l)]= beta * s["dW" + str(l)] + (1 - beta) * np.square(grads['dW' + str(l)])
s["db" + str(l)] = beta * s["db" + str(l)] + (1 - beta) * np.square(grads['db' + str(l)])
#updating parameters W and b
params["W" + str(l)] = params["W" + str(l)] - learning_rate * grads['dW' + str(l)] / (np.sqrt( s["dW" + str(l)] )+ pow(10,-4))
params["b" + str(l)] = params["b" + str(l)] - learning_rate * grads['db' + str(l)] / (np.sqrt( s["db" + str(l)]) + pow(10,-4))
return params
4. Adam Optimizer
Adam adalah salah satu algoritme pengoptimalan paling efisien dalam pelatihan jaringan saraf. Ini menggabungkan ide RMSProp dan Pulse Optimizer. Alih-alih mengadaptasi kecepatan pembelajaran dari parameter berdasarkan mean dari momen pertama (mean), seperti di RMSProp, Adam juga menggunakan mean momen kedua gradien. Secara khusus, algoritme menghitung rata-rata pergerakan eksponensial dari gradien dan gradien kuadrat, serta parameter
beta1dan beta2kontrol tingkat peluruhan dari rata-rata bergerak ini. Bagaimana?
def initilization_Adam(params):
s = {}
v = {}
for i in range(len(params)//2 ):
v["dW" + str(i)] = np.zeros(params["W" + str(i)].shape)
v["db" + str(i)] = np.zeros(params["b" + str(i)].shape)
s["dW" + str(i)] = np.zeros(params["W" + str(i)].shape)
s["db" + str(i)] = np.zeros(params["b" + str(i)].shape)
return v, s
def update_params_with_Adam(params, grads,v, s, beta1,beta2, learning_rate,t):
epsilon = pow(10,-8)
v_corrected = {}
s_corrected = {}
# grads has the dw and db parameters from backprop
# params has the W and b parameters which we have to update
for l in range(len(params) // 2 ):
# HERE WE COMPUTING THE VELOCITIES
v["dW" + str(l)] = beta1 * v["dW" + str(l)] + (1 - beta1) * grads['dW' + str(l)]
v["db" + str(l)] = beta1 * v["db" + str(l)] + (1 - beta1) * grads['db' + str(l)]
v_corrected["dW" + str(l)] = v["dW" + str(l)] / (1 - np.power(beta1, t))
v_corrected["db" + str(l)] = v["db" + str(l)] / (1 - np.power(beta1, t))
s["dW" + str(l)] = beta2 * s["dW" + str(l)] + (1 - beta2) * np.power(grads['dW' + str(l)], 2)
s["db" + str(l)] = beta2 * s["db" + str(l)] + (1 - beta2) * np.power(grads['db' + str(l)], 2)
s_corrected["dW" + str(l)] = s["dW" + str(l)] / (1 - np.power(beta2, t))
s_corrected["db" + str(l)] = s["db" + str(l)] / (1 - np.power(beta2, t))
params["W" + str(l)] = params["W" + str(l)] - learning_rate * v_corrected["dW" + str(l)] / np.sqrt(s_corrected["dW" + str(l)] + epsilon)
params["b" + str(l)] = params["b" + str(l)] - learning_rate * v_corrected["db" + str(l)] / np.sqrt(s_corrected["db" + str(l)] + epsilon)
return params
Hyperparameter
- Nilai β1 (beta1) hampir 0,9
- β2 (beta2) - hampir 0,999
- ε - mencegah pembagian dengan nol (10 ^ -8) (tidak mempengaruhi pembelajaran terlalu banyak)
Mengapa pengoptimal ini?
Keuntungannya:
- Implementasinya sederhana.
- Efisiensi komputasi.
- Persyaratan memori rendah.
- Invariant untuk penskalaan gradien diagonal.
- Sangat cocok untuk tugas besar dalam hal data dan parameter.
- Cocok untuk keperluan non-stasioner.
- Cocok untuk tugas-tugas dengan gradien yang sangat bising atau jarang.
- Hyperparameter sangat mudah dan biasanya membutuhkan sedikit penyetelan.
Mari buat model dan lihat bagaimana hyperparameter mempercepat pembelajaran
Mari kita lakukan peragaan langsung tentang cara mempercepat pembelajaran. Pada artikel ini kita tidak akan menjelaskan hal-hal lain (inisialisasi, pemutaran,
forward_prop, back_prop, gradient descent, dan sebagainya. D.). Fungsi yang diperlukan untuk pelatihan sudah ada di dalam NumPy. Jika Anda ingin melihatnya, berikut tautannya !
Ayo mulai!
Saya membuat fungsi model generik yang berfungsi untuk semua pengoptimal yang dibahas di sini.
1. Inisialisasi:
Kami menginisialisasi parameter menggunakan fungsi inisialisasi yang mengambil input seperti
features_size (dalam kasus kami 12288) dan larik ukuran tersembunyi (kami menggunakan [100,1]) dan output ini sebagai parameter inisialisasi. Ada metode inisialisasi lain. Saya mendorong Anda untuk membaca artikel ini .
def initilization(input_size,layer_size):
params = {}
np.random.seed(0)
params['W' + str(0)] = np.random.randn(layer_size[0], input_size) * np.sqrt(2 / input_size)
params['b' + str(0)] = np.zeros((layer_size[0], 1))
for l in range(1,len(layer_size)):
params['W' + str(l)] = np.random.randn(layer_size[l],layer_size[l-1]) * np.sqrt(2/layer_size[l])
params['b' + str(l)] = np.zeros((layer_size[l],1))
return params
2. Forward Propagation:
Dalam fungsi ini, inputnya adalah X, serta parameternya, tingkat hidden layer dan dropout, yang digunakan dalam teknik dropout.
Saya menetapkan nilainya ke 1 sehingga tidak ada efek yang terlihat dalam latihan. Jika model Anda overfitted, Anda dapat menyetel nilai yang berbeda. Saya hanya menerapkan dropout pada lapisan genap .
Kami menghitung nilai aktivasi untuk setiap lapisan menggunakan fungsi
forward_activation.
#activations-----------------------------------------------
def forward_activation(A_prev, w, b, activation):
z = np.dot(A_prev, w.T) + b.T
if activation == 'relu':
A = np.maximum(0, z)
elif activation == 'sigmoid':
A = 1/(1+np.exp(-z))
else:
A = np.tanh(z)
return A
#________model forward ____________________________________________________________________________________________________________
def model_forward(X,params, L,keep_prob):
cache = {}
A =X
for l in range(L-1):
w = params['W' + str(l)]
b = params['b' + str(l)]
A = forward_activation(A, w, b, 'relu')
if l%2 == 0:
cache['D' + str(l)] = np.random.randn(A.shape[0],A.shape[1]) < keep_prob
A = A * cache['D' + str(l)] / keep_prob
cache['A' + str(l)] = A
w = params['W' + str(L-1)]
b = params['b' + str(L-1)]
A = forward_activation(A, w, b, 'sigmoid')
cache['A' + str(L-1)] = A
return cache, A
3. Backpropagation:
Di sini kita menulis fungsi backpropagation. Ini akan mengembalikan grad ( kemiringan ). Kami menggunakan
gradsaat memperbarui parameter (jika Anda tidak mengetahuinya). Saya merekomendasikan membaca artikel ini .
def backward(X, Y, params, cach,L,keep_prob):
grad ={}
m = Y.shape[0]
cach['A' + str(-1)] = X
grad['dz' + str(L-1)] = cach['A' + str(L-1)] - Y
cach['D' + str(- 1)] = 0
for l in reversed(range(L)):
grad['dW' + str(l)] = (1 / m) * np.dot(grad['dz' + str(l)].T, cach['A' + str(l-1)])
grad['db' + str(l)] = 1 / m * np.sum(grad['dz' + str(l)].T, axis=1, keepdims=True)
if l%2 != 0:
grad['dz' + str(l-1)] = ((np.dot(grad['dz' + str(l)], params['W' + str(l)]) * cach['D' + str(l-1)] / keep_prob) *
np.int64(cach['A' + str(l-1)] > 0))
else :
grad['dz' + str(l - 1)] = (np.dot(grad['dz' + str(l)], params['W' + str(l)]) *
np.int64(cach['A' + str(l - 1)] > 0))
return grad
Kami telah melihat fitur pembaruan pengoptimal, jadi kami akan menggunakannya di sini. Mari membuat beberapa perubahan kecil pada fungsi model dari diskusi SGD.
def model(X,Y,learning_rate,num_iter,hidden_size,keep_prob,optimizer):
L = len(hidden_size)
params = initilization(X.shape[1], hidden_size)
costs = []
itr = []
if optimizer == 'momentum':
v = initilization_moment(params)
elif optimizer == 'rmsprop':
s = initilization_RMS(params)
elif optimizer == 'adam' :
v,s = initilization_Adam(params)
for i in range(1,num_iter):
MiniBatches = RandomMiniBatches(X, Y, 32) # GET RAMDOMLY MINIBATCHES
p , q = MiniBatches[2]
for MiniBatch in MiniBatches: #LOOP FOR MINIBATCHES
(MiniBatch_X, MiniBatch_Y) = MiniBatch
cache, A = model_forward(MiniBatch_X, params, L,keep_prob) #FORWARD PROPOGATIONS
cost = cost_f(A, MiniBatch_Y) #COST FUNCTION
grad = backward(MiniBatch_X, MiniBatch_Y, params, cache, L,keep_prob) #BACKWARD PROPAGATION
if optimizer == 'momentum':
params = update_params_with_momentum(params, grad, v, beta=0.9,learning_rate=learning_rate)
elif optimizer == 'rmsprop':
params = update_params_with_RMS(params, grad, s, beta=0.9,learning_rate=learning_rate)
elif optimizer == 'adam' :
params = update_params_with_Adam(params, grad,v, s, beta1=0.9,beta2=0.999, learning_rate=learning_rate,t=i) #UPDATE PARAMETERS
elif optimizer == "minibatch":
params = update_params(params, grad,learning_rate=learning_rate)
if i%5 == 0:
costs.append(cost)
itr.append(i)
if i % 100 == 0 :
print('cost of iteration______{}______{}'.format(i,cost))
return params,costs,itr
Pelatihan dengan paket mini
params, cost_sgd,itr = model(X_train, Y_train, learning_rate = 0.01,
num_iter=500, hidden_size=[100, 1],keep_prob=1,optimizer='minibatch')
Y_train_pre = predict(X_train, params, 2)
print('train_accuracy------------', accuracy_score(Y_train_pre, Y_train))Kesimpulan saat melakukan pendekatan dengan paket mini:
cost of iteration______100______0.35302967575683797
cost of iteration______200______0.472914548745098
cost of iteration______300______0.4884728238471557
cost of iteration______400______0.21551100063345618
train_accuracy------------ 0.8494208494208494
Pelatihan Pengoptimal Pulsa
params,cost_momentum, itr = model(X_train, Y_train, learning_rate = 0.01,
num_iter=500, hidden_size=[100, 1],keep_prob=1,optimizer='momentum')
Y_train_pre = predict(X_train, params, 2)
print('train_accuracy------------', accuracy_score(Y_train_pre, Y_train))Output pengoptimal pulsa:
cost of iteration______100______0.36278494129038086
cost of iteration______200______0.4681552335189021
cost of iteration______300______0.382226159384529
cost of iteration______400______0.18219310793752702 train_accuracy------------ 0.8725868725868726Pelatihan dengan RMSprop
params,cost_rms,itr = model(X_train, Y_train, learning_rate = 0.01,
num_iter=500, hidden_size=[100, 1],keep_prob=1,optimizer='rmsprop')
Y_train_pre = predict(X_train, params, 2)
print('train_accuracy------------', accuracy_score(Y_train_pre, Y_train))Keluaran RMSprop:
cost of iteration______100______0.2983858963793841
cost of iteration______200______0.004245700579927428
cost of iteration______300______0.2629426607580565
cost of iteration______400______0.31944824707807556 train_accuracy------------ 0.9613899613899614Pelatihan dengan Adam
params,cost_adam, itr = model(X_train, Y_train, learning_rate = 0.01,
num_iter=500, hidden_size=[100, 1],keep_prob=1,optimizer='adam')
Y_train_pre = predict(X_train, params, 2)
print('train_accuracy------------', accuracy_score(Y_train_pre, Y_train))Kesimpulan Adam:
cost of iteration______100______0.3266223660473619
cost of iteration______200______0.08214547683157716
cost of iteration______300______0.0025645257286439583
cost of iteration______400______0.058015188756586206 train_accuracy------------ 0.9845559845559846Pernahkah Anda melihat perbedaan akurasi di antara keduanya? Kami menggunakan parameter inisialisasi yang sama, kecepatan pembelajaran yang sama, dan jumlah iterasi yang sama; hanya pengoptimalnya saja yang berbeda, tetapi lihat hasilnya!
Mini-batch accuracy : 0.8494208494208494
momemtum accuracy : 0.8725868725868726
Rms accuracy : 0.9613899613899614
adam accuracy : 0.9845559845559846Visualisasi grafis model

Anda dapat memeriksa repositori jika Anda ragu tentang kodenya.
Ringkasan
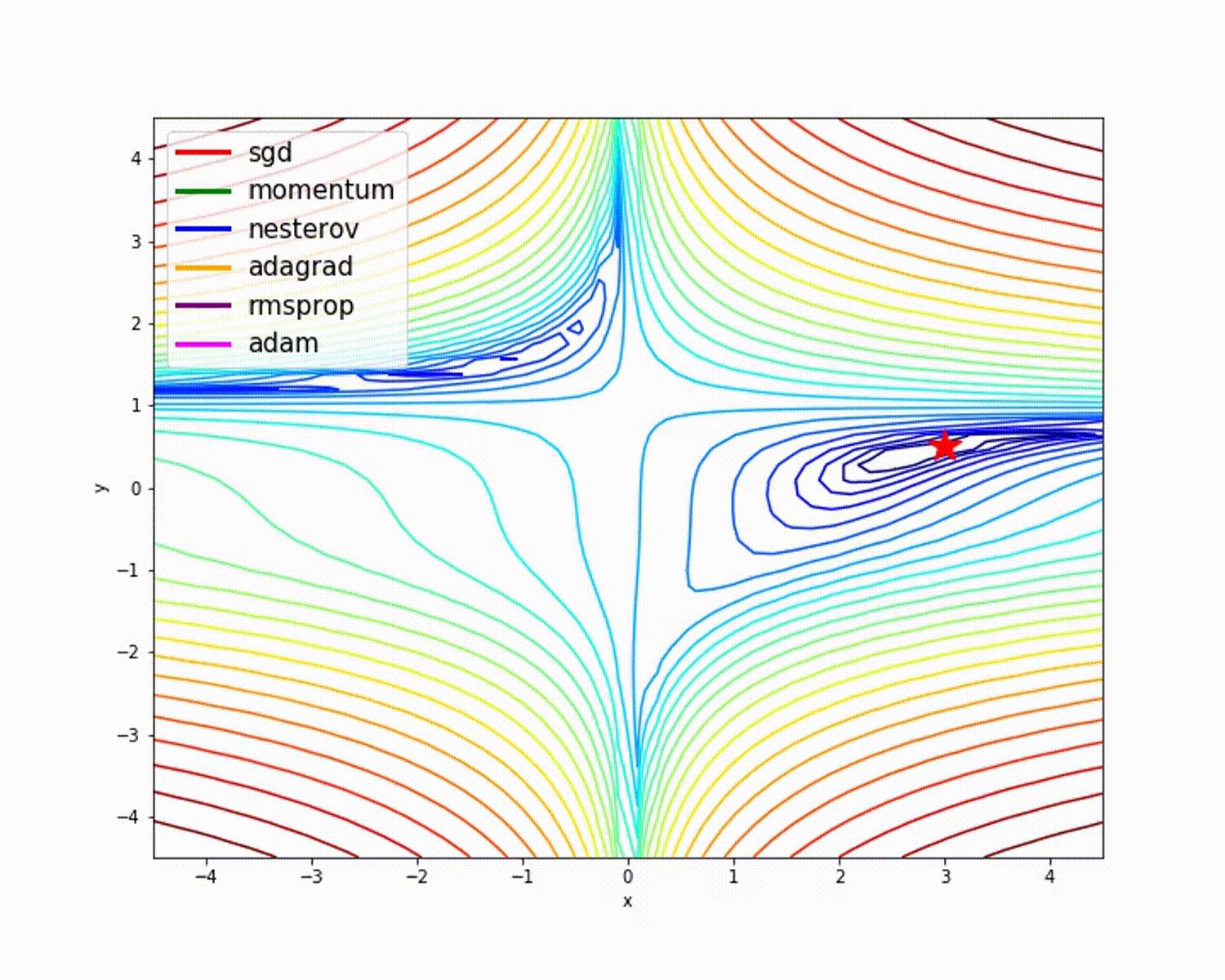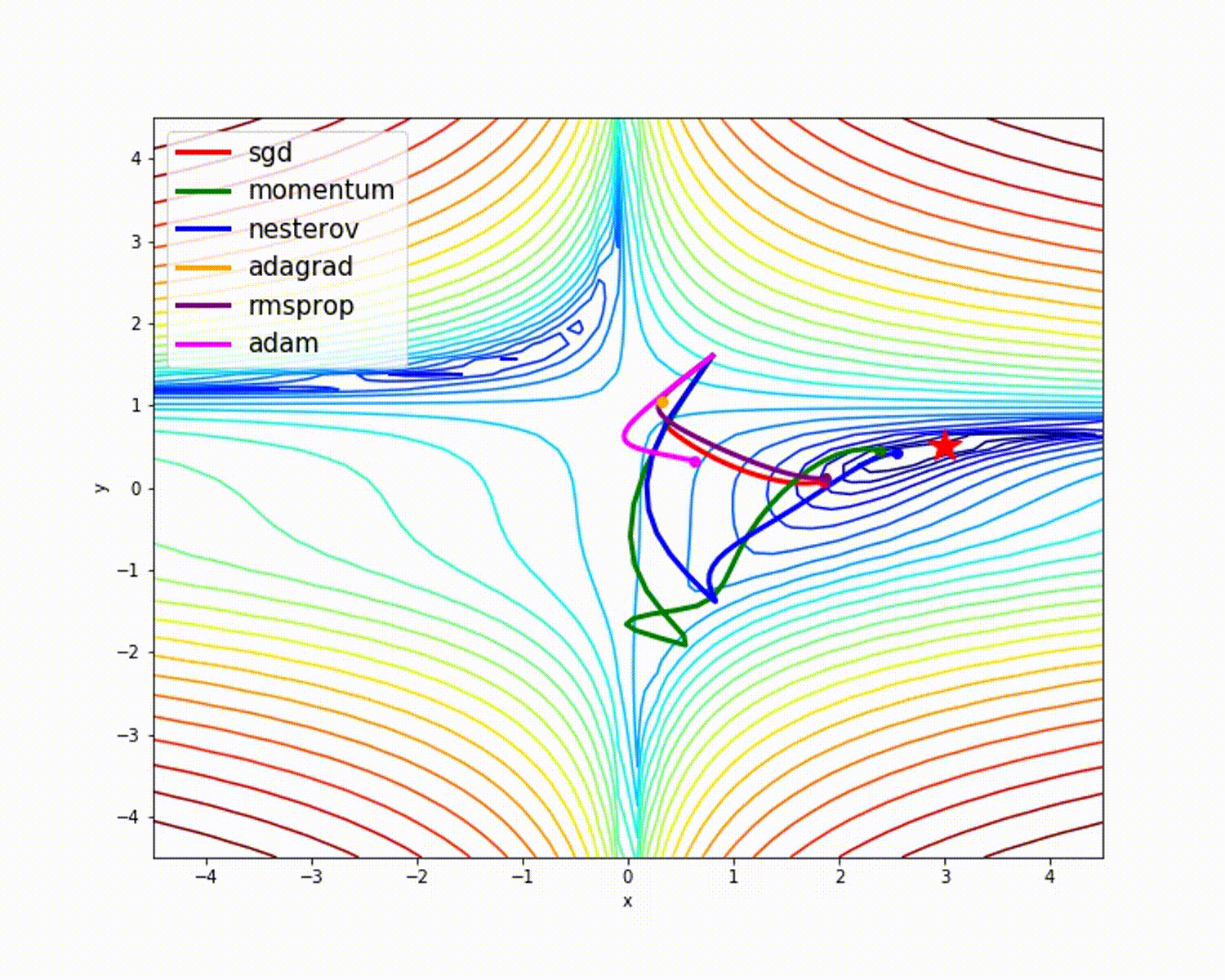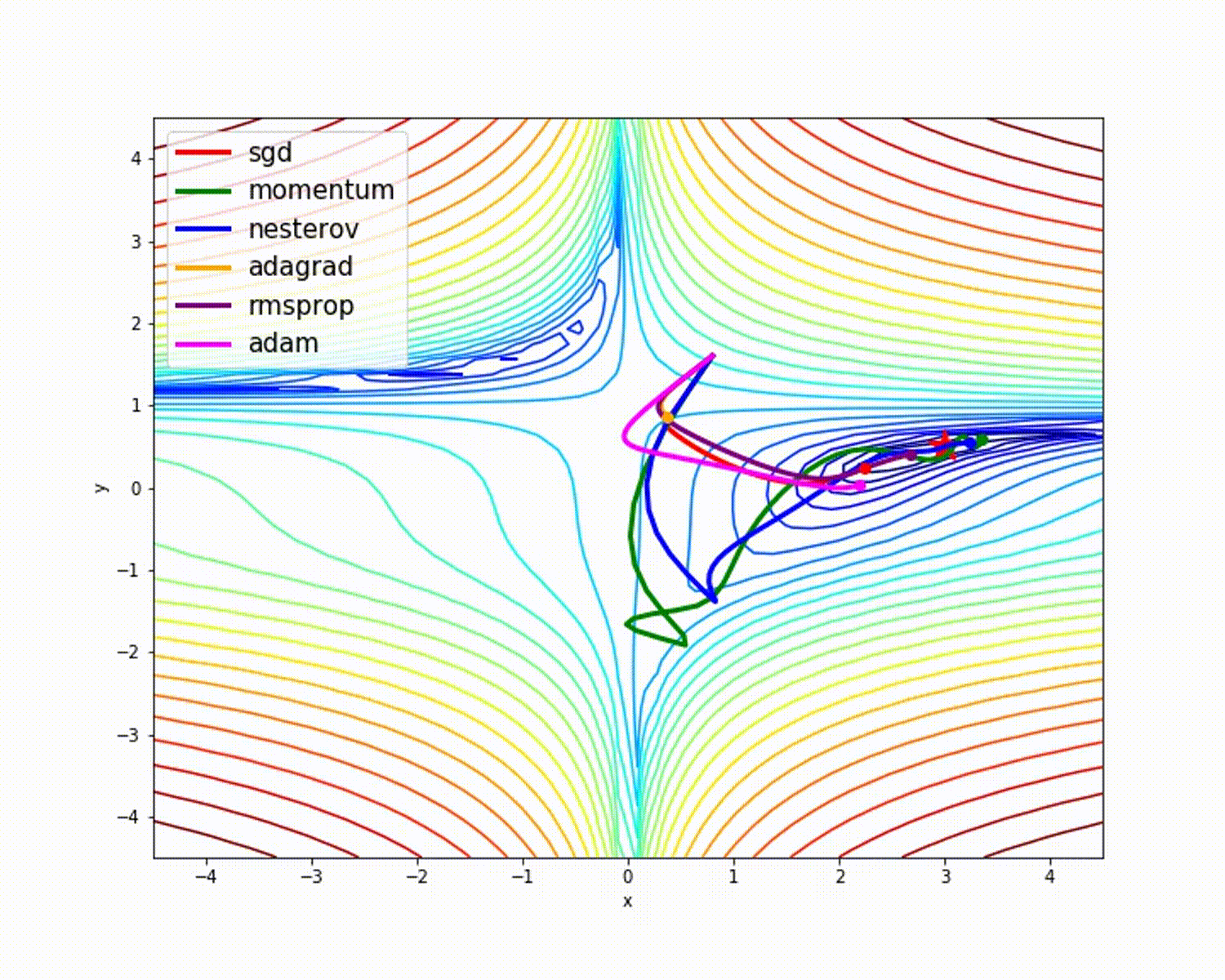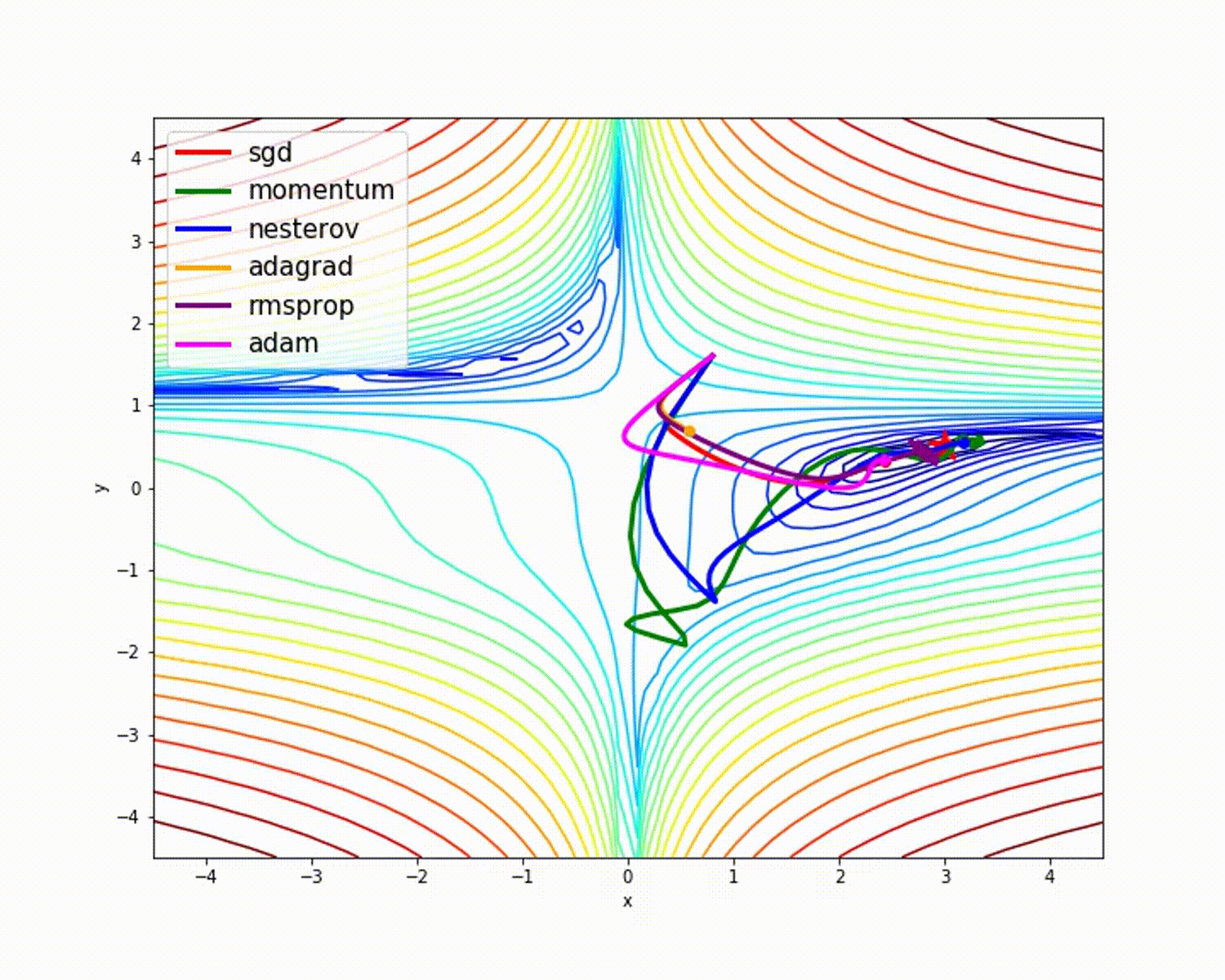
sumber
Seperti yang telah kita lihat, pengoptimal Adam memberikan akurasi yang baik dibandingkan dengan pengoptimal lainnya. Gambar di atas menunjukkan bagaimana model belajar melalui iterasi. Momentum memberikan kecepatan SGD dan RMSProp memberikan bobot rata-rata eksponensial untuk parameter yang diperbarui. Kami telah menggunakan lebih sedikit data dalam model di atas, tetapi kami akan melihat lebih banyak manfaat dari pengoptimal saat bekerja dengan kumpulan data besar dan banyak iterasi. Kami telah membahas ide dasar pengoptimal, dan saya harap ini memberi Anda motivasi untuk mempelajari lebih lanjut tentang pengoptimal dan menggunakannya!
Sumber daya
Prospek jaringan saraf dan pembelajaran mesin yang dalam sangat besar, dan menurut perkiraan paling konservatif, dampaknya pada dunia akan hampir sama dengan dampak listrik pada industri di abad ke-19. Para ahli yang menilai prospek ini sebelum orang lain memiliki setiap kesempatan untuk menjadi pemimpin kemajuan. Untuk orang-orang seperti itu, kami telah membuat kode promo HABR , yang memberikan tambahan 10% untuk diskon pelatihan yang tertera di spanduk.

- Kursus Machine Learning
- Kursus "Matematika dan Pembelajaran Mesin untuk Ilmu Data"
- Kursus Lanjutan "Machine Learning Pro + Deep Learning"
- Bootcamp online untuk Ilmu Data
- Melatih profesi Analis Data dari awal
- Bootcamp Online Analisis Data
- Mengajar profesi Ilmu Data dari awal
- Python untuk Kursus Pengembangan Web