
Unicorn badak mistis.
Pelatihan MS TECH / PIXABAY dalam waktu kurang dari satu kali percobaan membantu model mengidentifikasi lebih banyak objek daripada jumlah contoh yang telah dilatihnya.
Biasanya, pembelajaran mesin membutuhkan banyak contoh. Agar model AI dapat mengenali seekor kuda, Anda perlu menunjukkannya ribuan gambar kuda. Inilah sebabnya mengapa teknologi sangat mahal secara komputasi dan sangat berbeda dari pembelajaran manusia. Seorang anak sering kali perlu melihat hanya beberapa contoh dari suatu objek, atau bahkan satu, untuk belajar mengenalinya seumur hidup.
Bahkan, anak-anak kadang-kadang tidak perlu setiap contoh untuk mengidentifikasi apa-apa. Tunjukkan gambar kuda dan badak, beri tahu mereka bahwa unicorn ada di antara keduanya dan mereka akan mengenali makhluk mitos di buku bergambar segera setelah mereka melihatnya untuk pertama kali.

Mmm ... Tidak juga! MS TECH / PIXABAY
Sekarang penelitian dari University of Waterloo di Ontario menunjukkan bahwa model AI dapat melakukan ini juga - sebuah proses yang oleh para peneliti disebut pembelajaran "dalam waktu kurang dari satu" percobaan. Dengan kata lain, model AI dapat dengan jelas mengenali lebih banyak objek daripada jumlah contoh yang telah dilatihnya. Ini bisa menjadi penting di area yang menjadi semakin mahal dan tidak dapat diakses seiring dengan bertambahnya kumpulan data yang digunakan.
« »
Para peneliti pertama kali mendemonstrasikan ide ini dengan bereksperimen dengan kumpulan data pelatihan computer vision yang dikenal sebagai MNIST. MNIST berisi 60.000 gambar angka tulisan tangan dari 0 sampai 9, dan kumpulan tersebut sering digunakan untuk menguji ide-ide baru di bidang ini.
Dalam artikel sebelumnya, para peneliti di Massachusetts Institute of Technology mempresentasikan metode "menyaring" kumpulan data raksasa menjadi yang kecil. Sebagai bukti konsep, mereka mengompresi MNIST menjadi 10 gambar. Gambar tidak diambil sampelnya dari kumpulan data asli. Mereka telah dirancang dan dioptimalkan dengan hati-hati untuk memuat setara dengan satu set informasi lengkap. Hasilnya, saat dilatih pada 10 gambar ini, model AI mencapai akurasi yang hampir sama seperti yang dilatih pada seluruh set MNIST.

Contoh gambar dari set MNIST. WIKIMEDIA

10 dalam foto, "disaring" dari MNIST, dapat melatih model AI untuk mencapai akurasi pengenalan digit tulisan tangan 94 persen. Tongzhou Wang dkk.
Peneliti di Universitas Wotrelu ingin melanjutkan proses distilasi. Jika memungkinkan untuk mengurangi 60.000 gambar menjadi 10, mengapa tidak mengompresnya menjadi lima? Triknya, mereka sadari, adalah mencampur beberapa angka dalam satu gambar, dan kemudian memasukkannya ke dalam model AI dengan apa yang disebut label hybrid atau label "lunak". (Bayangkan seekor kuda dan badak yang diberi ciri unicorn.)
“Pikirkan angka 3, sepertinya angka 8, tapi bukan angka 7,” kata Ilya Sukholutsky, mahasiswa pascasarjana Waterloo dan penulis utama artikel tersebut. - Tanda lunak mencoba menangkap kesamaan ini. Jadi, alih-alih memberi tahu mobil: "Gambar ini adalah nomor 3", kami mengatakan: "Gambar ini 60% nomor 3, 30% nomor 8 dan 10% nomor 0" ".
Keterbatasan metode pengajaran baru
Setelah para peneliti berhasil menggunakan label lunak untuk mencapai adaptasi MNIST ke pembelajaran dalam waktu kurang dari satu upaya, mereka mulai bertanya-tanya sejauh mana gagasan itu bisa berjalan. Apakah ada batasan jumlah kategori yang dapat dipelajari oleh model AI dari sejumlah kecil contoh?
Anehnya, sepertinya tidak ada batasan. Dengan soft label yang dirancang dengan cermat, bahkan dua contoh secara teoritis dapat menyandikan sejumlah kategori. “Hanya dengan dua titik, Anda dapat membagi seribu kelas, atau 10.000 kelas, atau satu juta kelas," kata Sukholutsky.
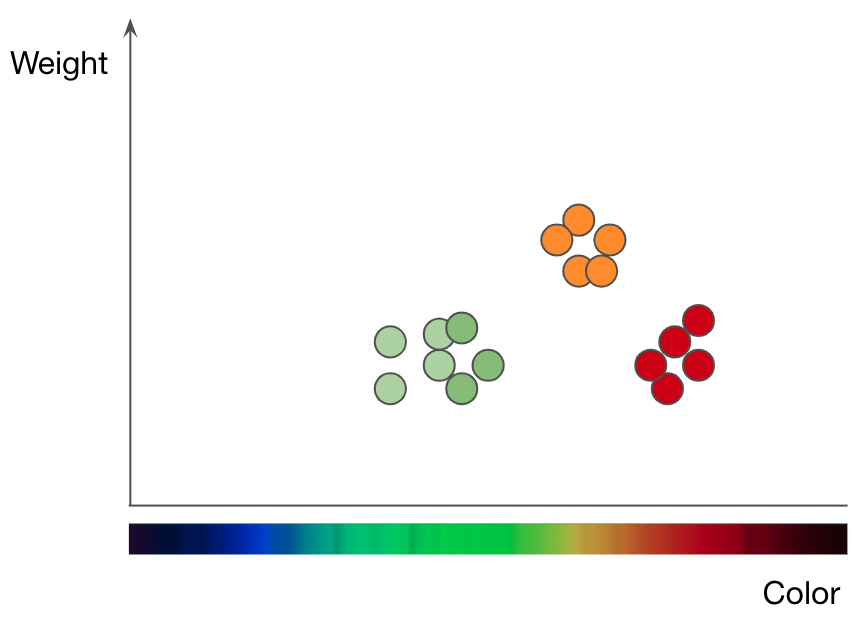
Rincian apel (titik hijau dan merah) dan jeruk (titik oranye) menurut berat dan warnanya. Diadaptasi dari presentasi Jason Mace, Machine Learning 101
Inilah yang ditunjukkan para ilmuwan dalam artikel terbaru mereka melalui penelitian matematika murni. Mereka mengimplementasikan konsep ini menggunakan salah satu algoritma pembelajaran mesin paling sederhana yang dikenal sebagai k-neighbourhood (kNN), yang mengklasifikasikan objek menggunakan pendekatan grafis.
Untuk memahami cara kerja metode kNN, mari kita ambil masalah klasifikasi buah sebagai contoh. Untuk melatih model kNN agar memahami perbedaan antara apel dan jeruk, Anda harus terlebih dahulu memilih fungsi yang ingin Anda gunakan untuk merepresentasikan setiap buah. Jika Anda memilih warna dan berat, maka untuk setiap apel dan jeruk Anda masukkan satu titik data dengan warna buah sebagai nilai x dan bobot sebagai nilai y... Algoritme kNN kemudian memplot semua titik data dalam grafik 2D dan menggambar garis di tengah antara apel dan jeruk. Grafik sekarang dengan rapi dibagi menjadi dua kelas, dan algoritme dapat memutuskan apakah titik data baru mewakili apel atau jeruk - tergantung pada sisi mana titik tersebut berada.
Untuk mempelajari pembelajaran dalam waktu kurang dari satu upaya dengan algoritme kNN, para peneliti membuat serangkaian kumpulan data sintetis kecil dan dengan hati-hati memikirkan label lunak mereka. Mereka kemudian mengizinkan algoritme kNN untuk memplot batas yang dilihatnya dan menemukan bahwa algoritme tersebut berhasil membagi grafik menjadi lebih banyak kelas daripada titik data yang ada. Para peneliti juga sebagian besar mengontrol di mana batas-batas itu dijalankan. Dengan berbagai modifikasi pada soft label, mereka membuat algoritma kNN menggambar pola yang tepat dalam bentuk bunga.
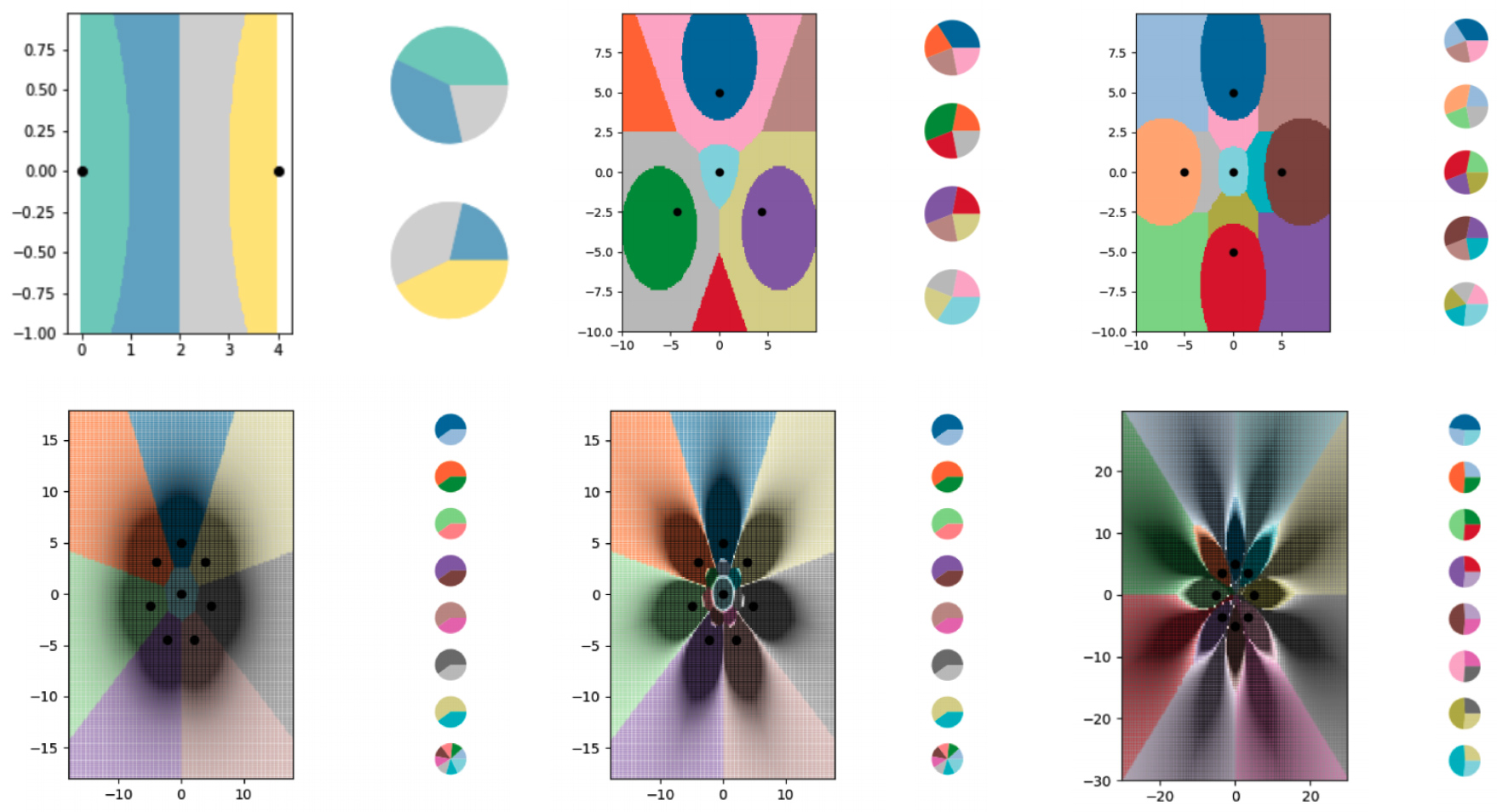
Para peneliti menggunakan contoh soft-label untuk melatih algoritma kNN untuk menyandikan batas-batas yang semakin kompleks dan memecah diagram menjadi lebih banyak kelas daripada yang memiliki titik data. Setiap area berwarna mewakili kelas yang terpisah, dan diagram lingkaran di samping setiap grafik menunjukkan distribusi label lembut untuk setiap titik data.
Ilya Sukholutskiy dkk.
Berbagai diagram menunjukkan batas-batas yang dibangun menggunakan algoritma kNN. Setiap diagram memiliki lebih banyak garis batas yang dikodekan dalam kumpulan data kecil.
Tentu saja penelitian teoritis ini memiliki beberapa keterbatasan. Sementara gagasan belajar dari percobaan "kurang dari satu" akan dibawa ke algoritma yang lebih kompleks, tugas mengembangkan contoh dengan label "lunak" menjadi jauh lebih rumit. Algoritme kNN diinterpretasikan dan visual, memungkinkan orang membuat label. Jaringan saraf itu kompleks dan tidak dapat ditembus, yang artinya hal yang sama mungkin tidak berlaku untuk mereka. Distilasi data, yang bagus untuk mengembangkan contoh soft-label untuk jaringan neural, juga memiliki kerugian yang signifikan: metode ini mengharuskan Anda memulai dengan kumpulan data raksasa, mengecilkannya menjadi sesuatu yang lebih efisien.
Sukholutsky mengatakan dia mencoba menemukan cara lain untuk membuat kumpulan data sintetis kecil ini, baik dengan tangan atau dengan algoritma lain. Terlepas dari kerumitan penelitian tambahan ini, artikel ini menyajikan dasar-dasar teoretis pembelajaran. "Terlepas dari kumpulan data apa yang Anda miliki, Anda dapat mencapai peningkatan efisiensi yang signifikan," katanya.
Inilah yang paling menarik minat Tongzhou Wang, seorang mahasiswa pascasarjana di Institut Teknologi Massachusetts. Dia mengarahkan penelitian sebelumnya pada data distilasi. “Artikel ini dibuat berdasarkan tujuan yang benar-benar baru dan penting: melatih model yang kuat dari kumpulan data kecil,” katanya tentang kontribusi Sukholutsky.
Ryan Hurana, seorang peneliti di Institut Montreal untuk Etika Kecerdasan Buatan, berbagi pandangan ini: "Lebih penting lagi, belajar dalam waktu kurang dari satu percobaan akan secara drastis mengurangi kebutuhan data untuk membangun model yang berfungsi." Hal ini dapat membuat AI lebih dapat diakses oleh perusahaan dan industri yang hingga saat ini terhambat oleh persyaratan data di area ini. Ini juga dapat meningkatkan privasi data, karena model utilitas pelatihan akan memerlukan lebih sedikit informasi dari orang-orang.
Sukholutsky menekankan bahwa penelitian ini masih dalam tahap awal. Namun demikian, itu sudah membangkitkan imajinasi. Setiap kali seorang penulis mulai mempresentasikan makalahnya kepada sesama peneliti, reaksi pertama mereka adalah dengan menyatakan bahwa ide tersebut berada di luar kemungkinan. Ketika mereka tiba-tiba menyadari bahwa mereka salah, dunia baru terbuka.

