
- Apa sebenarnya yang menghabiskan begitu banyak memori?
- Apakah ada cara untuk menghindari hal ini?
Di sini saya ingin berbicara tentang bagaimana saya mencari jawaban atas pertanyaan-pertanyaan ini. Saya berencana untuk menggunakan materi ini sebagai referensi setiap kali saya perlu membuat profil kode Python.
Saya mulai mem-parsing Pylint, mulai dari titik masuk program (
pylint/__main__.py), dan sampai ke loop "fundamental" foryang Anda harapkan dalam program yang memeriksa banyak file:
def _check_files(self, get_ast, file_descrs):
# pylint/lint/pylinter.py
with self._astroid_module_checker() as check_astroid_module:
for name, filepath, modname in file_descrs:
self._check_file(get_ast, check_astroid_module, name, filepath, modname)
Untuk memulainya, saya hanya meletakkan pernyataan di loop ini
print(«HI»)untuk memastikan bahwa ini memang loop yang dimulai ketika saya menjalankan perintah pylint my_code. Eksperimen ini berjalan mulus.
Selanjutnya, saya memutuskan untuk mencari tahu apa sebenarnya yang disimpan dalam memori selama pengerjaan Pylint. Jadi saya menggunakannya
heapydan membuat "heap dump" sederhana, berharap dapat menganalisis dump ini untuk menemukan sesuatu yang tidak biasa:
from guppy import hpy
hp = hpy()
i = 0
for name, filepath, modname in file_descrs:
self._check_file(get_ast, check_astroid_module, name, filepath, modname)
i += 1
if i % 10 == 0:
print("HEAP")
print(hp.heap())
if i == 100:
raise ValueError("Done")
Profil heap hampir seluruhnya terdiri dari frame stack panggilan (
types.FrameType). Saya, untuk beberapa alasan, mengharapkan sesuatu seperti ini. Begitu banyak benda serupa di tempat sampah membuat saya berpikir bahwa tampaknya ada lebih banyak dari yang seharusnya.
Partition of a set of 2751394 objects. Total size = 436618350 bytes.
Index Count % Size % Cumulative % Kind (class / dict of class)
0 429084 16 220007072 50 220007072 50 types.FrameType
1 535810 19 30005360 7 250012432 57 types.TracebackType
2 516282 19 29719488 7 279731920 64 tuple
3 101904 4 29004928 7 308736848 71 set
4 185568 7 21556360 5 330293208 76 dict (no owner)
5 206170 7 16304240 4 346597448 79 list
6 117531 4 9998322 2 356595770 82 str
7 38582 1 9661040 2 366256810 84 dict of astroid.node_classes.Name
8 76755 3 6754440 2 373011250 85 tokenize.TokenInfo
Pada saat itulah saya menemukan alat Peramban Profil , yang memungkinkan Anda bekerja dengan data semacam itu dengan nyaman.
Saya mengkonfigurasi mesin dump sehingga data akan ditulis ke file setiap 10 iterasi loop. Kemudian saya membuat diagram yang menunjukkan perilaku program selama operasi.
for name, filepath, modname in file_descrs:
self._check_file(get_ast, check_astroid_module, name, filepath, modname)
i += 1
if i % 10 == 0:
hp.heap().stat.dump("/tmp/linting.stats")
if i == 100:
hp.pb("/tmp/linting.stats")
raise ValueError("Done")
Saya berakhir dengan apa yang ditunjukkan di bawah ini. Diagram ini mengonfirmasi bahwa objek
type.FrameTypedan type.TracebackType(informasi jejak) menghabiskan banyak memori selama menjalankan Pylint yang diselidiki.

Analisis Data
Tahap penelitian selanjutnya adalah analisis objek
types.FrameType. Karena mekanisme manajemen memori dalam Python didasarkan pada penghitungan jumlah referensi ke objek, data disimpan dalam memori selama ada yang merujuk padanya. Saya memutuskan untuk mencari tahu apa sebenarnya yang "menyimpan" data dalam memori.
Di sini saya menggunakan pustaka luar biasa
objgraphyang, menggunakan kemampuan pengelola memori Python, memberikan informasi tentang objek mana yang ada di memori, dan memungkinkan Anda untuk mengetahui apa sebenarnya yang merujuk ke objek-objek ini.
Faktanya, sangat bagus bahwa kami memiliki kemampuan untuk melakukan penelitian perangkat lunak semacam ini. Yaitu, jika ada referensi ke suatu objek, Anda dapat menemukan semua yang mengacu pada objek ini (dalam kasus ekstensi-C, semuanya tidak begitu mulus, tetapi, secara umum,
objgraphmemberikan informasi yang cukup akurat). Sebelum kami adalah alat yang sangat baik untuk men-debug kode, memberikan akses ke banyak informasi tentang mekanisme internal CPython. Bagi saya, ini adalah alasan lain untuk menganggap Python sebagai bahasa yang menyenangkan untuk digunakan.
Pada awalnya, saya tersandung pada pencarian objek, karena tim
objgraph.by_type('types.TracebackType')tidak dapat menemukan apa pun. Dan ini terlepas dari kenyataan bahwa saya tahu ada sejumlah besar objek seperti itu. Ternyata string harus digunakan sebagai nama tipe traceback. Alasan untuk ini tidak sepenuhnya jelas bagi saya, tetapi apa adanya. Perintah yang benar, pada akhirnya, terlihat seperti ini:
random.choice(objgraph.by_type('traceback'))
Konstruksi ini memilih objek secara acak
traceback. Dan dengan bantuan objgraph.show_backrefsAnda dapat membuat diagram tentang apa yang mengacu pada objek tersebut.
Pada akhirnya, alih-alih hanya memberikan pengecualian, saya memutuskan untuk menyelidiki apa yang terjadi di loop
for( import pdb; pdb.set_trace()) setelah 100 iterasi. Saya mulai mempelajari objek yang dipilih secara acak traceback.
def exclude(obj):
return 'Pdb' in str(type(obj))
def f(depth=7):
objgraph.show_backrefs([random.choice(objgraph.by_type('traceback'))],
max_depth=depth,
filter=lambda elt: not exclude(elt))
Awalnya, saya hanya melihat rangkaian objek
traceback, jadi saya memutuskan untuk mendaki hingga kedalaman 100 objek ...

Menganalisis objek traceback
Ternyata, beberapa objek
tracebackmerujuk ke objek lain yang berjenis sama. Sangat baik. Dan ada banyak rantai seperti itu.
Untuk beberapa waktu, tanpa banyak keberhasilan untuk bisnis, saya mempelajarinya, dan kemudian beralih ke studi objek jenis kedua yang menarik bagi saya -
FrameType(frame). Mereka juga tampak curiga. Menganalisisnya, saya sampai pada diagram yang menyerupai berikut ini.

Parsing frame objek
Ternyata objek
tracebackmemegang objekframe(jadi ada sejumlah objek serupa). Semua ini, tentu saja, terlihat sangat membingungkan, tetapi objekframesetidaknya mengarah ke baris kode tertentu. Semua ini membuat saya menyadari satu hal yang sangat sederhana: Saya tidak pernah repot-repot melihat data menggunakan memori dalam jumlah besar. Saya pasti harus melihat objek itu sendiritraceback.
Saya berjalan menuju tujuan ini, tampaknya, jalan yang paling berliku dari semua jalan yang mungkin. Yakni, ia mengenali alamat di dump yang dibuat oleh
objgraph, lalu melihat alamat di memori, lalu mencari di Internet untuk "cara mendapatkan objek Python, mengetahui alamatnya." Setelah semua eksperimen ini, saya menghasilkan skema tindakan berikut:
ipdb> import ctypes
ipdb> ctypes.cast(0x7f187d22b880, ctypes.py_object)
py_object(<traceback object at 0x7f187d22b880>)
ipdb> ctypes.cast(0x7f187d22b880, ctypes.py_object).value
<traceback object at 0x7f187d22b880>
ipdb> my_tb = ctypes.cast(0x7f187d22b880, ctypes.py_object).value
ipdb> traceback.print_tb(my_tb, limit=20)
Faktanya, Anda bisa mengatakan pada Python, “Lihat memori ini. Setidaknya ada objek Python biasa di sini. "
Kemudian saya menyadari bahwa saya sudah memiliki tautan ke objek yang menarik untuk saya terima
objgraph. Yaitu - saya bisa menggunakannya.
Rasanya seperti perpustakaan
astroid, parser AST yang digunakan di Pylint, membuat objek di mana traceback- mana melalui kode penanganan pengecualian. Saya kira ketika sesuatu digunakan di suatu tempat yang bisa disebut "trik menarik", maka sepanjang jalan mereka lupa tentang bagaimana hal yang sama bisa dilakukan lebih mudah. Jadi saya tidak terlalu mengeluh tentang itu.
Objek
tracebackmemiliki banyak data terkait astroid. Ada beberapa kemajuan dalam penelitian saya! Perpustakaanastroidsangat mirip dengan program yang mampu menyimpan data dalam jumlah besar di memori, karena ia mem-parsing file.
Saya mencari-cari kode dan menemukan baris berikut di file
astroid/manager.py:
except Exception as ex:
raise exceptions.AstroidImportError(
"Loading {modname} failed with:\n{error}",
modname=modname,
path=found_spec.location,
) from ex
Ini dia, pikir saya, inilah yang saya cari! Ini adalah urutan pengecualian yang menghasilkan rantai objek terpanjang
traceback. Dan di sini, antara lain, file diurai, sehingga mekanisme rekursif juga dapat ditemukan di sini. Dan sesuatu yang menyerupai konstruksi raise thing from other_thingmengikat semuanya.
Saya menghapus
from exdan ... tidak ada yang terjadi. Jumlah memori yang dikonsumsi oleh program secara praktis tetap sama, objeknya tracebackjuga tidak pergi kemana-mana.
Saya tahu bahwa pengecualian menyimpan binding lokalnya di objek
traceback, jadi Anda bisa melakukannya ex. Akibatnya, memori mereka tidak bisa dihapus.
Saya melakukan pemfaktoran ulang kode secara besar-besaran, pada dasarnya mencoba menyingkirkan blok tersebut
except, atau setidaknya dari tautan ke ex. Tapi, sekali lagi, saya tidak mendapat apa-apa.
Saya, setidaknya retak, tidak bisa "menghasut" pengumpul sampah ke objek
traceback, bahkan mengingat tidak ada referensi ke objek tersebut. Saya berasumsi bahwa alasannya adalah ada beberapa tautan lain di suatu tempat.
Faktanya, saya mengambil jalan yang salah saat itu. Saya tidak tahu apakah ini penyebab kebocoran memori, karena pada satu titik saya mulai menyadari bahwa saya tidak memiliki bukti untuk mendukung "teori rantai pengecualian" saya. Saya hanya punya banyak tebakan dan jutaan objek
traceback.
Kemudian saya mulai melihat objek-objek ini secara acak untuk mencari beberapa petunjuk tambahan. Saya mencoba untuk “memanjat” rantai mata rantai secara manual, tetapi pada akhirnya saya hanya menemukan kekosongan.
Kemudian saya sadar: semua objek
tracebackini terletak "satu di atas yang lain", tetapi harus ada objek yang "di atas" semua yang lain. Salah satu yang tidak direferensikan oleh objek lain semacam itu.
Tautan dibuat melalui properti
tb_next, urutan tautan tersebut adalah rantai sederhana. Jadi saya memutuskan untuk melihat objek tracebackdi ujung rantai masing-masing:
bottom_tbs = [tb for tb in objgraph.by_type('traceback') if tb.tb_next is None]
Ada sesuatu yang ajaib tentang menjebol setengah juta objek dengan satu baris dan menemukan apa yang Anda butuhkan.
Secara umum, saya menemukan apa yang saya cari. Menemukan alasan mengapa Python harus menyimpan semua objek ini dalam memori.

Menemukan Sumber Masalah
Itu semua tentang cache file!
Intinya adalah bahwa pustaka
astroidmenyimpan hasil pemuatan modul. Jika kode membutuhkan modul yang telah digunakan, perpustakaan hanya akan menyediakannya dengan hasil pemuatan modul yang sudah dimilikinya. Ini juga mengarah pada reproduksi kesalahan dengan menyimpan pengecualian yang ditampilkan.
Pada titik ini, saya membuat keputusan yang berani, dengan alasan seperti ini: “Masuk akal untuk menyimpan sesuatu yang tidak mengandung kesalahan. Tapi menurut saya tidak ada gunanya menyimpan objek yang
tracebackdihasilkan oleh kode kami. "
Saya memutuskan untuk menyingkirkan pengecualian, mempertahankan kelas saya sendiri,
Errordan hanya membangun kembali pengecualian saat diperlukan. Detail dapat ditemukan di siniPR, tapi ternyata tidak terlalu menarik.
Hasilnya, saya dapat mengurangi konsumsi memori saat bekerja dengan basis kode kami dari 500 MB menjadi 100 MB.
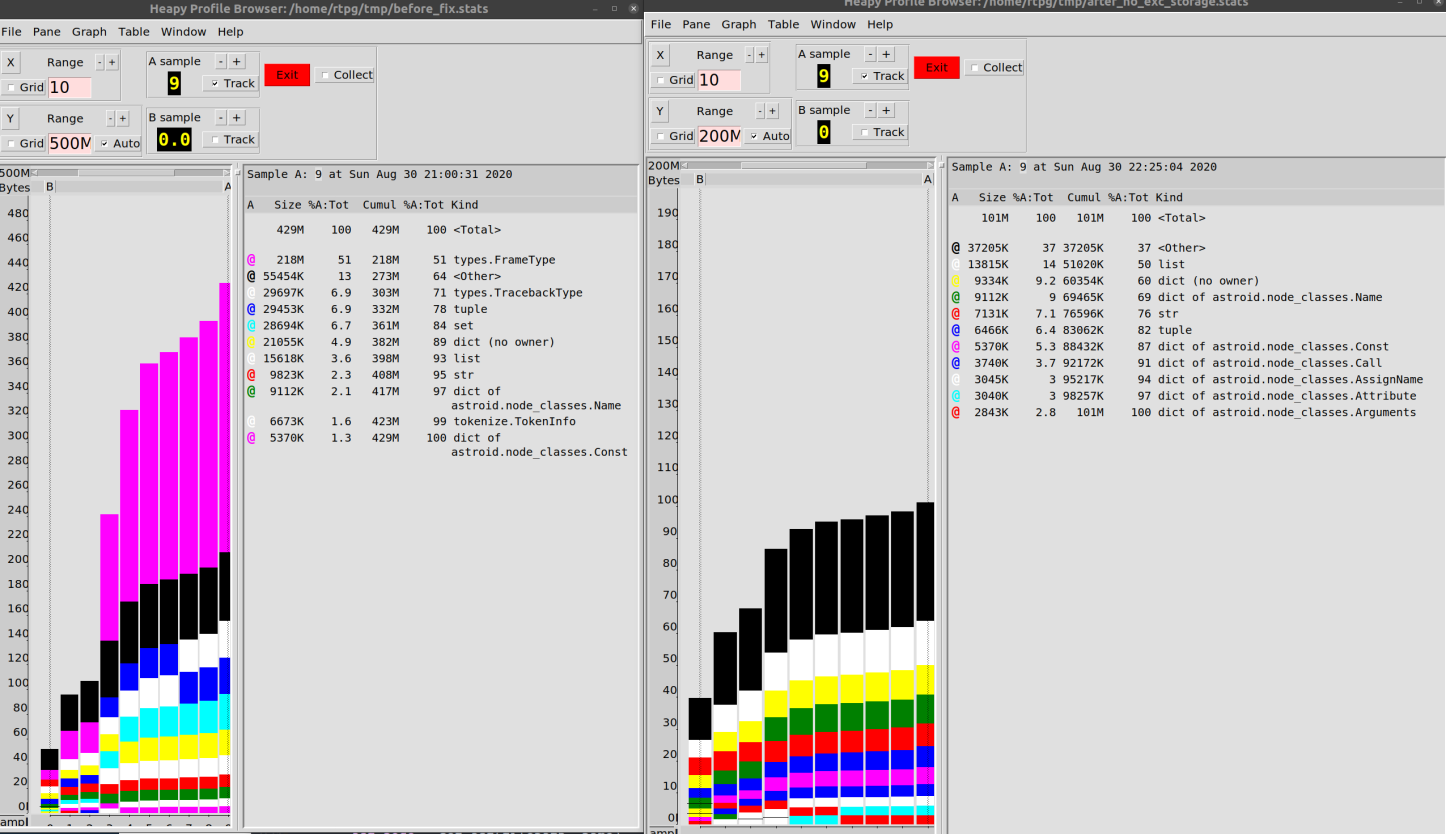
Menurut saya, peningkatan 80% tidak terlalu buruk,
berbicara tentang PR, saya tidak yakin apakah akan dimasukkan ke dalam proyek. Perubahan yang dibawanya tidak hanya terkait dengan kinerja. Saya percaya bahwa cara kerjanya dapat, dalam beberapa situasi, mengurangi nilai data pelacakan tumpukan. Ini, mengingat semua detail, perubahan yang agak kasar, meskipun solusi ini lolos semua pengujian.
Hasilnya, saya membuat kesimpulan berikut untuk diri saya sendiri:
- Python memberi kita kemampuan analisis memori yang luar biasa. Saya harus menggunakan fitur ini lebih sering saat men-debug kode.
- , .
- , -, « ». . , , , .
- , (, , Git). , , . , .
Ketika saya menulis ini, saya menyadari bahwa saya telah melupakan banyak hal yang membuat saya sampai pada kesimpulan tertentu. Jadi saya akhirnya memeriksa beberapa cuplikan kode lagi. Kemudian saya menjalankan pengukuran pada basis kode yang berbeda dan menemukan bahwa keanehan memori hanya spesifik untuk satu proyek. Saya menghabiskan banyak waktu untuk mencari dan memperbaiki gangguan ini, tetapi kemungkinan besar ini hanyalah fitur dari perilaku alat yang kami gunakan, yang hanya memanifestasikan dirinya dalam sejumlah kecil dari mereka yang menggunakan alat tersebut.
Sangat sulit untuk mengatakan sesuatu yang pasti tentang kinerja bahkan setelah melakukan pengukuran seperti itu.
Saya akan mencoba mentransfer pengalaman yang diperoleh dari eksperimen yang saya jelaskan ke proyek lain. Saya yakin ada banyak masalah kinerja dalam proyek Python open source yang cukup mudah diperbaiki. Faktanya adalah bahwa komunitas pengembang Python biasanya memberikan perhatian yang relatif sedikit untuk masalah ini (ini - jika kita tidak membicarakan proyek yang merupakan ekstensi untuk Python, yang ditulis dalam C).
Pernahkah Anda harus mengoptimalkan kinerja kode Python Anda?

