Bagaimana kita tahu algoritma itu bekerja?
Sebelum mengembangkan algoritme, Anda perlu memikirkan tentang bagaimana kami akan mengevaluasi kinerjanya. Katakanlah kita menulis algoritme, dan dikatakan bahwa "gambar ini memiliki warna berikut" - akankah keputusannya benar? Dan apa artinya itu - "benar"?
Untuk mengatasi masalah ini, kami telah memilih dua dimensi penting - penandaan warna primer yang benar dan jumlah warna yang benar. Kami menetapkan ini sebagai jarak CIEDE 2000 ( rumus perbedaan warna ) antara warna latar depan yang diprediksi oleh algoritme kami dan warna latar depan kami yang sebenarnya, dan kami juga menghitung kesalahan absolut rata-rata dalam jumlah warna. Kami membuat pilihan ini karena alasan berikut:
- Parameter ini mudah dihitung.
- Saat jumlah metrik meningkat, akan lebih sulit untuk memilih algoritme "terbaik".
- Dengan mengurangi jumlah metrik, kami mungkin kehilangan perbedaan penting antara kedua algoritme tersebut.
- Bagaimanapun, kebanyakan garmen memiliki satu atau dua warna primer, dan banyak dari proses kami mengandalkan warna primer. Oleh karena itu, menghitung warna dasar dengan benar jauh lebih penting daripada menghitung warna kedua atau ketiga dengan benar.
Bagaimana dengan data "nyata"? Tim merchandiser kami memberi kami label, tetapi alat kami memungkinkan mereka untuk memilih hanya warna yang paling umum, seperti "abu-abu" atau "biru" - mereka tidak dapat disebut nilai pasti. Definisi umum semacam itu mencakup beberapa corak yang berbeda, sehingga tidak dapat digunakan sebagai warna asli. Kami harus membangun kumpulan data kami sendiri.
Beberapa dari Anda mungkin sudah memikirkan tentang layanan seperti Mechanical Turk. Tapi kita tidak perlu menandai terlalu banyak gambar, jadi mendeskripsikan tugas ini mungkin lebih sulit daripada hanya menyelesaikannya. Selain itu, membuat kumpulan data membantu Anda lebih memahaminya. Kami dengan cepat mengacaukan aplikasi HTML / Javascript dan secara acak memilih 1000 gambar, memilih untuk setiap piksel yang mewakili warna utamanya, dan menandai jumlah warna yang kami lihat di gambar. Setelah itu, menjadi mudah untuk mendapatkan dua angka yang mengevaluasi kualitas algoritme kami (jarak ke warna utama CIEDE dan jumlah warna MAE).
Terkadang kami memeriksa program secara manual, menjalankan kedua algoritme pada gambar yang sama dan menampilkan dua daftar warna. Kami kemudian menilai 200 gambar secara manual, memilih warna mana yang dianggap "terbaik". Sangat penting untuk bekerja sama dengan data dengan cara ini - tidak hanya untuk mendapatkan hasil ("Algoritme B bekerja lebih baik daripada Algoritme A dalam 70% kasus"), tetapi juga untuk memahami apa yang terjadi di setiap kasus ("Algoritme B biasanya memilih terlalu banyak grup, tetapi Algoritma A kehilangan warna terang ”).

Sweater dan warna dipilih dengan dua algoritma berbeda
Algoritme ekstraksi warna kami
Sebelum memproses gambar, kami mengonversinya ke ruang warna CIELAB (atau hanya LAB) daripada RGB yang lebih umum. Akibatnya, ketiga angka kita tidak akan mewakili jumlah warna merah, hijau dan biru. Titik-titik ruang LAB (L * a * b * akan lebih tepat, tetapi kami akan menulis LAB untuk kesederhanaan) menunjukkan tiga sumbu yang berbeda. L menunjukkan kecerahan dari hitam 0 ke putih 100. A dan B menunjukkan warna: A menunjukkan lokasi dalam kisaran dari -128 hijau hingga 127 merah, dan B dari -128 biru hingga 127 kuning. Keuntungan utama dari ruang ini adalah keseragaman yang dirasakan. Jarak atau perbedaan antara dua titik dalam ruang LAB akan dianggap sama, terlepas dari lokasinya, jika jarak Euclidean antar keduanya dalam ruang juga sama.
Biasanya, LAB memiliki masalah lain: misalnya, kami mempertimbangkan gambar pada layar komputer yang menggunakan ruang RGB khusus perangkat. Selain itu, gamut LAB lebih lebar daripada RGB, artinya, di LAB Anda dapat mengekspresikan warna yang tidak dapat diekspresikan melalui RGB. Oleh karena itu, konversi dari LAB ke RGB tidak boleh dua sisi - dengan mengonversi satu titik ke satu arah dan kemudian ke arah yang berlawanan, Anda bisa mendapatkan nilai yang berbeda. Secara teoritis, kekurangan ini ada, tetapi dalam praktiknya metode tersebut masih berhasil.
Dengan mengkonversi gambar ke LAB, kita akan mendapatkan sekumpulan piksel yang dapat dilihat sebagai titik (L, A, B, X, Y). Algoritme lainnya berkaitan dengan pengelompokan titik-titik ini, di mana kelompok tahap pertama menggunakan semua lima pengukuran, dan tahap kedua menghilangkan pengukuran X dan Y.
Pengelompokan dalam ruang
Kami mulai dengan gambar tanpa pengelompokan piksel yang telah mengalami penyesuaian warna yang dijelaskan di artikel sebelumnya , dikompresi menjadi 320x200 dan dikonversi ke LAB.

Pertama, mari terapkan algoritme Quickshift, yang mengelompokkan piksel terdekat ke dalam "superpiksel".

Ini sudah mengurangi gambar 60.000 piksel kami menjadi beberapa ratus superpiksel, menghilangkan kerumitan yang tidak perlu. Anda bahkan dapat lebih menyederhanakan situasi dengan menggabungkan superpiksel terdekat dengan jarak warna yang kecil di antara keduanya. Untuk melakukan ini, kami menggambar grafik kedekatan regionalnya - grafik di mana simpul yang menunjukkan dua superpiksel berbeda dihubungkan dengan tepi jika pikselnya bersentuhan.

– (Regional Adjacency Graph, RAG) . , , , , . , , , , . – , .
Simpul grafik adalah superpiksel yang kami hitung, dan tepinya adalah jarak di antara keduanya dalam ruang warna. Tepi yang menghubungkan dua superpiksel terdekat dengan warna serupa akan memiliki bobot yang rendah (garis gelap), dan tepi di antara superpiksel dengan warna yang sangat berbeda akan memiliki bobot yang tinggi (garis cerah, serta tidak adanya garis - tidak akan digambar jika bobotnya lebih dari 20). Ada banyak cara untuk menggabungkan superpiksel terdekat, tetapi ambang batas sederhana 10 sudah cukup bagi kami.
Dalam kasus kami, kami berhasil mengurangi 60.000 piksel menjadi 100 area, yang masing-masing berisi piksel dengan warna yang sama. Ini memberikan keuntungan komputasi: Pertama, kita tahu bahwa superpiksel besar dengan warna hampir putih adalah latar belakang dan dapat dihapus. Kami menghapus semua superpiksel dengan L> 99, dan A dan B berada dalam kisaran dari -0,5 hingga 0,5. Kedua, kita bisa sangat mengurangi jumlah piksel di langkah berikutnya. Kami tidak akan dapat mengurangi jumlahnya menjadi 100, karena kami perlu menimbang area berdasarkan jumlah piksel yang dikandungnya. Tetapi kami dapat dengan mudah menghapus 90% piksel dari setiap grup tanpa kehilangan terlalu banyak detail dan hampir tidak ada distorsi pada pengelompokan berikutnya.
Pengelompokan tanpa menggunakan ruang
Pada langkah ini, kami memiliki beberapa ribu piksel dengan koordinat (L, A, B). Ada banyak teknik yang dapat mengelompokkan piksel ini dengan baik. Kami memilih metode k-means karena cepat, mudah dipahami, data kami hanya memiliki 3 dimensi, dan jarak Euclidean di ruang LAB masuk akal.
Kami tidak terlalu pintar dan melakukan pengelompokan dengan K = 8. Jika beberapa grup berisi kurang dari 3% poin, kami coba lagi, kali ini dengan K = 7, lalu 6, dan seterusnya. Hasilnya, kami memiliki daftar 1 hingga 8 pusat pengelompokan dan proporsi jumlah titik yang dimiliki oleh masing-masing pusat. Mereka diberi nama oleh algoritma colornamer yang dijelaskan di artikel sebelumnya.
Hasil dan masalah yang tersisa
Kami mencapai jarak rata-rata 5,86 pada skala CIEDE 2000 antara warna yang diprediksi dan warna "nyata". Agak sulit untuk menafsirkan indikator ini dengan benar. Pada metrik jarak CIE76 sederhana , jarak rata-rata kita adalah 7,82. Pada metrik ini, nilai 2,3 mewakili perbedaan yang halus. Oleh karena itu, kami dapat mengatakan bahwa hasil kami, sedikit di atas 3, menunjukkan perbedaan yang halus.
Juga MAE kami adalah 2.28 warna. Tetapi sekali lagi, ini adalah metrik sekunder. Banyak algoritme yang dijelaskan di bawah ini mengurangi kesalahan ini, tetapi dengan mengorbankan jarak warna. Jauh lebih mudah untuk mengabaikan warna salah tempat ke-5 atau ke-6 daripada mengabaikan warna pertama yang salah.

Bahkan benda-benda yang warnanya jelas-jelas sama, seperti celana pendek ini, berisi area yang tampak jauh lebih gelap karena
bayangan. Masalah bayangan tetap ada. Kain tidak dapat diletakkan dengan sempurna secara merata, oleh karena itu, bagian dari gambar akan selalu berada dalam bayangan, dan warnanya akan tampak berbeda. Pendekatan paling sederhana seperti menemukan warna duplikat dengan bayangan yang sama dan kecerahan berbeda tidak berfungsi, karena transisi dari "piksel tanpa bayangan" ke "piksel dalam bayangan" tidak selalu berfungsi dengan cara yang sama. Di masa mendatang, kami berharap dapat menggunakan teknik yang lebih canggih seperti DeshadowNet atau deteksi bayangan otomatis .

Kami hanya berkonsentrasi pada warna pakaian. Perhiasan dan sepatu memiliki masalahnya sendiri: foto perhiasan kita terlalu kecil, dan foto sepatu sering kali memperlihatkan bagian dalamnya. Dalam contoh di atas, kami menunjukkan adanya merah anggur dan oker di foto, meskipun hanya yang pertama yang penting.
Apa lagi yang sudah kami coba
Algoritma terakhir ini tampaknya cukup sederhana, tetapi tidak mudah untuk membuatnya! Pada bagian ini, saya akan menjelaskan opsi-opsi yang telah kami coba dan pelajari.
Penghapusan latar belakang
Kami telah mencoba algoritme penghapusan latar belakang - misalnya, algoritme Lyst . Evaluasi informal menunjukkan bahwa mereka tidak bekerja seakurat penghapusan latar belakang putih. Namun, kami berencana untuk mempelajarinya lebih dalam saat kami memproses gambar yang tidak dapat dikerjakan oleh studio foto kami.
Piksel hashing
Beberapa pustaka ekstraksi warna telah memilih solusi sederhana untuk masalah ini: mengelompokkan piksel dengan melakukan hashing ke dalam beberapa wadah yang cukup lebar, lalu mengembalikan nilai rata-rata wadah LAB dengan jumlah piksel terbesar. Kami mencoba perpustakaan Colorgram.py; terlepas dari kesederhanaannya, ia bekerja dengan sangat baik. Selain itu, ini bekerja dengan cepat - tidak lebih dari satu detik per gambar, sementara algoritme kami menghabiskan puluhan detik per gambar. Namun, Colorgram.py memiliki jarak rata-rata yang lebih besar ke warna dasar daripada algoritme kami - terutama karena hasilnya diambil dari jarak rata-rata ke wadah besar. Namun, terkadang kami menggunakannya untuk kasus di mana kecepatan lebih penting daripada akurasi.
Algoritme pemisahan superpiksel lainnya
Kami menggunakan algoritme Quickshift untuk membagi gambar menjadi superpiksel, tetapi ada beberapa algoritme yang memungkinkan - misalnya, SLIC, Watershed, dan Felzenszwalb. Dalam praktiknya, Quickshift telah menunjukkan hasil terbaik berkat pekerjaannya dengan komponen kecil. Misalnya, SLIC memiliki masalah dengan hal-hal seperti garis-garis yang memakan banyak ruang pada gambar. Berikut hasil indikatif dari algoritma SLIC dengan pengaturan berbeda: Kekompakan

citra asli

= 1

kekompakan = 10

kekompakan = 100
Untuk bekerja dengan data kami, Quickshift memiliki satu keunggulan teoretis: tidak memerlukan komunikasi superpiksel berkelanjutan. Para peneliti mencatat bahwa hal ini dapat menyebabkan masalah pada algoritme, tetapi dalam kasus kami ini adalah keuntungan - sering kali kami menemukan area kecil dengan detail kecil yang ingin kami bawa ke satu grup.

Kemeja

Kotak-kotak Pengelompokan Superpixel dengan Quickshift
Meskipun Pengelompokan Superpixel dari Quickshift terlihat kacau, sebenarnya grup ini mengelompokkan semua garis merah dengan warna merah, biru dengan biru, dll.
Metode penghitungan jumlah kelompok yang berbeda
Saat menggunakan metode k-means, pertanyaan paling umum muncul: bagaimana cara membuat "k"? Artinya, jika kita perlu mengelompokkan poin ke dalam sejumlah kelompok tertentu, berapa banyak yang harus kita lakukan? Beberapa pendekatan telah dikembangkan untuk menjawab pertanyaan tersebut. Yang paling sederhana adalah "metode siku", tetapi membutuhkan pemrosesan grafik secara manual, dan kami membutuhkan solusi otomatis. Statistik Gap memformalkan metode ini, dan dengan itu kami mendapatkan hasil terbaik pada metrik "jumlah warna", tetapi dengan mengorbankan keakuratan warna dasar. Karena warna utama adalah yang paling penting, kami tidak menggunakannya dalam program kerja, tetapi kami berencana untuk mempelajari masalah ini lebih lanjut.
Akhirnya, metode siluet adalah metode pemilihan k populer lainnya. Ini memberikan hasil yang sedikit lebih buruk daripada algoritme kami, dan memiliki satu kelemahan serius: memerlukan setidaknya 2 grup. Namun banyak item pakaian yang hanya memiliki satu warna.
DBSCAN
Salah satu solusi potensial untuk pertanyaan memilih k adalah menggunakan algoritme yang tidak mengharuskan Anda memilih parameter ini. Salah satu contoh populer adalah DBSCAN, yang mencari grup dengan kepadatan yang kira-kira sama dalam data.

Blus warna-warni
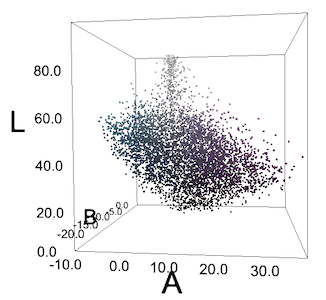
Semua piksel gambarnya berada dalam ruang LAB. Piksel tidak membentuk kelompok cyan dan violet yang jelas.
Seringkali kita tidak mendapatkan kelompok seperti itu, atau kita melihat sesuatu seperti kelompok hanya karena kekhasan persepsi manusia. Bagi kami, "mentimun" biru kehijauan pada blus menonjol dengan latar belakang ungu, tetapi jika kami memplot semua piksel dalam koordinat RGB atau LAB, mereka tidak akan membentuk grup. Tetapi kami tetap mencoba DBSCAN dengan nilai epsilon yang berbeda dan kami mendapatkan hasil yang sangat buruk.
Solusi dari Algolia
Salah satu prinsip peneliti yang baik adalah melihat apakah ada yang telah memecahkan masalah Anda. Leo Ercolanelli dari situs web Algolia menerbitkan penjelasan rinci tentang solusi untuk masalah semacam itu lebih dari tiga tahun lalu. Berkat kemurahan hati mereka dalam mendistribusikan sumber, kami dapat mencoba solusi mereka sendiri. Namun, hasilnya sedikit lebih buruk dari kami, jadi kami meninggalkan algoritme kami. Mereka tidak menyelesaikan masalah yang sama seperti kami: mereka memiliki gambar produk pada model dan dengan latar belakang selain putih, jadi masuk akal jika hasil mereka berbeda dari kami.
Koordinasi warna
Algoritme ini menyelesaikan proses yang dijelaskan di artikel kami sebelumnya. Setelah mengekstrak pusat grup, kami menggunakan Colornamer untuk menamainya dan kemudian mengimpor warna-warna itu ke alat internal kami. Ini membantu kami untuk dengan mudah memvisualisasikan produk kami berdasarkan warna; kami berharap dapat memasukkan data ini ke dalam algoritme rekomendasi pembelian. Proses ini tidak sempurna, ini membantu kami mendapatkan data yang lebih baik tentang ribuan produk kami, yang pada gilirannya berkontribusi pada tujuan utama kami dalam membantu orang menemukan gaya yang mereka sukai.
Wawancara tentang terjemahan bagian pertama