
Sumber gambar
Dua revolusi dalam pemrosesan bahasa alami
Revolusi pertama di NLP dikaitkan dengan keberhasilan model berdasarkan representasi vektor dari semantik bahasa, diperoleh dengan menggunakan metode pembelajaran tanpa pengawasan. Perkembangan model ini dimulai dengan publikasi hasil Tomáš Mikolov , mahasiswa PhD Yoshua Bengio (salah satu pendiri pembelajaran mendalam modern, pemenang Turing Prize.), dan munculnya alat word2vec yang populer. Revolusi kedua dimulai dengan pengembangan mekanisme perhatian dalam jaringan saraf berulang, yang menghasilkan pemahaman bahwa mekanisme perhatian adalah swasembada dan dapat digunakan dengan baik tanpa jaringan berulang itu sendiri. Model jaringan saraf yang dihasilkan disebut "transformator". Itu dipresentasikan kepada komunitas ilmiah pada tahun 2017 dalam sebuah artikel berjudul "Attention Is All You Need ," yang ditulis oleh sekelompok peneliti dari Google Brain dan Google Research. Perkembangan pesat jaringan berbasis transformator telah menghasilkan model bahasa raksasa seperti OpenAI's Generative Pre-training Transformer 3 (GPT-3)mampu memecahkan banyak masalah NLP secara efisien.
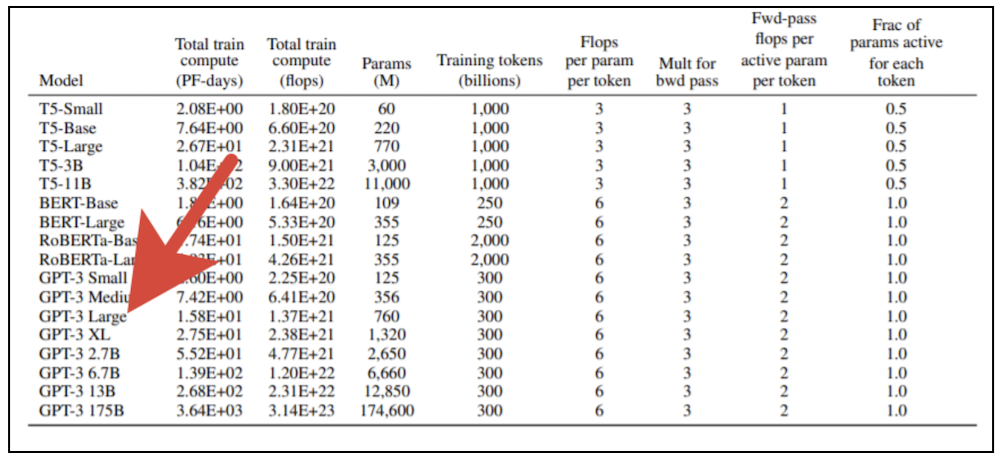
Dibutuhkan sumber daya komputasi yang signifikan untuk melatih model transformator raksasa. Anda tidak bisa hanya mengambil kartu grafis modern dan melatih model seperti itu di komputer rumah Anda. Dalam publikasi OpenAI asli, disajikan 8 varian model, dan jika Anda mengambil yang terkecil (GPT-3 Kecil) dengan 125 juta parameter dan mencoba melatihnya menggunakan kartu video NVidia V100 profesional yang dilengkapi dengan inti tensor yang kuat, maka akan memakan waktu sekitar enam bulan. Jika kita mengambil versi model terbesar dengan 175 miliar parameter, maka hasilnya harus menunggu hampir 500 tahun. Biaya pelatihan versi model terbesar dengan tarif layanan cloud yang menyediakan perangkat komputasi modern untuk disewa,melebihi satu miliar rubel (dan ini masih tunduk pada penskalaan kinerja linier dengan peningkatan jumlah prosesor yang terlibat, yang pada prinsipnya tidak dapat dicapai).
Superkomputer berumur panjang!
Jelas bahwa eksperimen semacam itu hanya tersedia untuk perusahaan dengan sumber daya komputasi yang signifikan. Untuk mengatasi masalah tersebut, pada tahun 2019 Sberbank mengoperasikan superkomputer Christophari , yang menempati posisi pertama dalam performa di antara superkomputer yang tersedia di negara kita. 75 node komputasi DGX-2 (masing-masing dengan 16 kartu NVidia V100 ) dihubungkan dengan bus ultra-cepat berdasarkan teknologi Infinibandmemungkinkan Anda untuk melatih GPT-3 Small hanya dalam beberapa jam. Namun, bahkan untuk mesin seperti itu, tugas melatih varian model yang lebih besar bukanlah hal yang sepele. Pertama, bagian dari mesin sibuk dengan pelatihan model lain yang dirancang untuk memecahkan masalah di bidang visi komputer, pengenalan dan sintesis suara, dan banyak bidang minat lainnya ke berbagai perusahaan dari ekosistem Sberbank. Kedua, proses pembelajaran itu sendiri, yang secara bersamaan menggunakan banyak node komputasi dalam situasi di mana bobot model tidak sesuai dengan memori satu kartu, agak non-standar.
Secara umum, kami menemukan diri kami dalam situasi di mana obor yang didistribusikan, yang akrab bagi banyak orang, tidak sesuai untuk tujuan kami. Kami tidak memiliki banyak opsi, sebagai hasilnya kami beralih ke implementasi "asli" untuk NVidia Megatron-LMdan gagasan baru Microsoft - DeepSpeed , yang membutuhkan pembuatan kontainer buruh pelabuhan khusus di Christophari, yang segera membantu kolega kami dari SberCloud . DeepSpeed, pertama-tama, memberi kami alat yang nyaman untuk pelatihan paralel model, yaitu menyebarkan satu model ke beberapa GPU dan membagi pengoptimal di antara GPU. Ini memungkinkan Anda menggunakan batch yang lebih besar, serta melatih model dengan lebih dari 1,5 miliar bobot tanpa segunung kode tambahan.
Anehnya, teknologi selama setengah abad terakhir dalam perkembangannya telah menggambarkan putaran spiral berikutnya - sepertinya era mainframe (komputer yang kuat dengan akses terminal) kembali. Kami sudah terbiasa dengan fakta bahwa alat pengembangan utama adalah komputer pribadi yang dialokasikan untuk penggunaan eksklusif oleh pengembang. Pada akhir 1960-an dan awal 1970-an, satu jam biaya operasi mainframe hampir sama dengan gaji sebulan penuh untuk operator komputer! Tampaknya waktu-waktu ini telah berlalu selamanya dan "besi" menjadi lebih murah selamanya daripada waktu kerja. Namun, perangkat kerasnya tampaknya telah membuat comeback yang mengesankan. Kehidupan sehari-hari seorang spesialis pembelajaran mesin modern kembali menyerupai kehidupan sehari-hari Sasha Privalov dari kisah Strugatsky bersaudara "Senin dimulai pada hari Sabtu", dengan satu-satunya perbedaan bahwa tempat "Aldan" dalam kasus kami diambil oleh "Christofari", dan peran sihir dan sihir dilakukan dengan metode pembelajaran yang mendalam.
Dari pengalaman SberDevices
Sering kali di masa lalu kami harus mempelajari model lain berdasarkan transformator - ini adalah berbagai pewaris BERT, dan model encoder-decoder, seperti T5 dari Google . Asisten virtual yang dibuat oleh SberDevices untuk berbagai permukaan, dimulai dengan terbaru SberBox dan SberPortaldan diakhiri dengan aplikasi Sberbank Online yang sudah tidak asing lagi, mereka menggunakan beberapa model serupa dalam pekerjaan mereka untuk memecahkan berbagai masalah dalam proses komunikasi dengan pengguna. Misalnya, asisten virtual Joy menggunakan model Medium GPT-2 dalam mode chatting, dilatih pada kumpulan besar literatur Rusia, dilatih pada kumpulan data dialog khusus dan dilengkapi dengan mekanisme peringkat khusus yang dirancang untuk memilih jawaban yang paling menarik. Model seperti itu mampu melakukan percakapan dengan pengguna, tidak memilih isyarat dari kumpulan jawaban yang telah disiapkan sebelumnya, tetapi membuat frasa mereka sendiri "dengan cepat", yang membuat komunikasi dengan mereka lebih beragam dan menghibur.
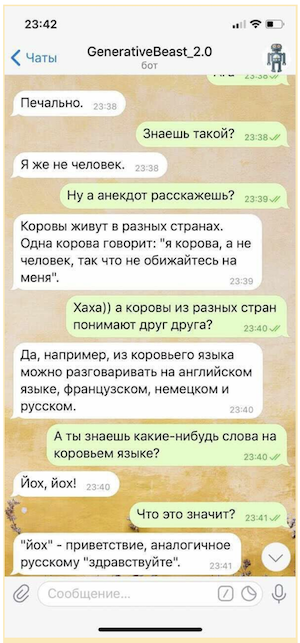

Tentu saja, "obrolan" semacam itu tidak dapat digunakan tanpa jaminan dalam bentuk sistem niat mikro (aturan yang dirancang untuk memberikan jawaban terkontrol untuk beberapa pertanyaan paling sensitif) dan model terpisah yang dirancang untuk menghindari pertanyaan provokatif, tetapi bahkan dalam bentuk yang terbatas. "Obrolan" generatif mampu secara signifikan meningkatkan mood lawan bicaranya.
Singkatnya, pengalaman kami dalam mengajar model transformator besar menjadi berguna ketika manajemen Sberbank memutuskan untuk mengalokasikan sumber daya komputasi untuk proyek penelitian guna melatih GPT-3. Proyek semacam itu membutuhkan penggabungan upaya beberapa unit sekaligus. Di bagian SberDevices, peran kepemimpinan dalam proses ini diambil oleh Departemen Sistem Pembelajaran Mesin Eksperimental (dengan partisipasi sejumlah pakar dari tim lain), dan di pihak Sberbank.AI - oleh tim AGI NLP . Rekan kami dari SberCloud, yang mendukung Christophari, juga secara aktif bergabung dalam proyek ini.
Bersama rekan-rekan dari tim AGI NLP, kami berhasil merakit versi pertama dari korpus pelatihan bahasa Rusia dengan total volume lebih dari 600 GB. Ini mencakup koleksi besar literatur Rusia, snapshot dari Wikipedia bahasa Rusia dan Inggris, koleksi snapshot situs berita dan Tanya Jawab , bagian publik Pikabu , koleksi lengkap materi dari portal sains populer 22century.ru dan portal perbankan banki.ru , serta Omnia Russica corpus . Selain itu, karena kami ingin bereksperimen dengan kemampuan untuk menangani kode program, kami menyertakan snapshot dari github dan StackOverflow dalam korpus pelatihan.... Tim AGI NLP telah melakukan banyak pekerjaan pada pembersihan dan deduplikasi data, serta menyiapkan set untuk validasi dan pengujian model. Jika dalam korpus asli yang digunakan oleh OpenAI, rasio bahasa Inggris ke bahasa lain adalah 93: 7, maka dalam kasus kami rasio bahasa Rusia ke bahasa lain adalah sekitar 9: 1.
Kami memilih arsitektur GPT-3 Medium (350 juta parameter) dan GPT-3 Large (760 juta parameter) sebagai dasar untuk eksperimen pertama. Dalam melakukannya, kami melatih model seperti dengan blok trafo bolak-balik dengan jarangdan mekanisme dan model perhatian padat di mana semua blok perhatian diselesaikan. Faktanya adalah bahwa karya asli dari OpenAI berbicara tentang blok interleaving, tetapi tidak memberikan urutan spesifiknya. Jika semua blok perhatian dalam model selesai, itu meningkatkan biaya komputasi pelatihan, tetapi memastikan bahwa potensi prediktif model dieksploitasi sepenuhnya. Saat ini, komunitas ilmiah secara aktif mempelajari berbagai model perhatian, yang dirancang untuk mengurangi biaya komputasi model pelatihan dan meningkatkan akurasi. Dalam waktu singkat, para peneliti telah mengusulkan longformer , reformer , trafo dengan rentang perhatian adaptif., Trafo kompresi [transformator tekan] , trafo ENBLOCK [trafo blokir] , BigBird , trafo dengan kompleksitas linier [linformer] dan beberapa model sejenis lainnya. Kami juga terlibat dalam penelitian di bidang ini, sementara model yang hanya terdiri dari blok padat adalah sejenis patokan yang memungkinkan kami menilai tingkat penurunan akurasi berbagai versi model yang "dipercepat".
Kompetisi "AI 4 Humaniora: ruGPT-3"
Tahun ini, dalam rangka AI Journey, tim Sberbank.AI menyelenggarakan kompetisi AI 4 Humanities: ruGPT-3. Sebagai bagian dari tes keseluruhan, peserta diundang untuk mengirimkan prototipe solusi untuk masalah bisnis atau sosial apa pun yang dibuat menggunakan model ruGPT-3 yang telah dilatih sebelumnya. Peserta dalam nominasi khusus "AIJ Junior" diundang untuk menciptakan solusi untuk menghasilkan esai yang bermakna pada empat mata pelajaran kemanusiaan (bahasa Rusia, sejarah, sastra, ilmu sosial) kelas 11 (USE) berdasarkan ruGPT-3 berdasarkan ruGPT-3 untuk topik / teks tugas tertentu.
Khusus untuk kompetisi ini, kami melatih tiga versi model GPT-3: 1) GPT-3 Sedang, 2) GPT-3 Besar dengan trafo yang jarang dan padat bergantian, 3) GPT-3 Besar yang paling "kuat", hanya terdiri dari blok padat. Set data pelatihan dan tokenizer identik untuk semua model - BBPE tokenizer dan set data Large1 kustom kami dengan volume 600 GB digunakan (komposisinya diberikan dalam teks di atas).
Ketiga model tersebut tersedia untuk diunduh di gudang kompetisi.
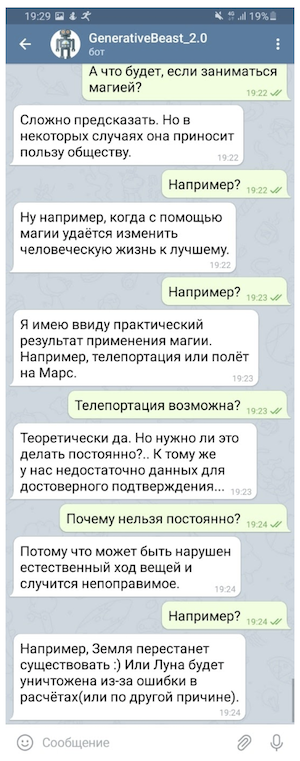
Berikut beberapa contoh menyenangkan tentang cara kerja model ketiga:



Bagaimana model seperti GPT-3 akan mengubah dunia kita?
Penting untuk dipahami bahwa model seperti GPT-1/2/3, pada kenyataannya, memecahkan satu masalah dengan tepat - mereka mencoba memprediksi token berikutnya (biasanya sebuah kata atau bagian darinya) dalam urutan yang sebelumnya. Pendekatan ini memungkinkan untuk menggunakan data "tidak berlabel" untuk pelatihan, yaitu, dilakukan tanpa melibatkan "guru", dan di sisi lain, memungkinkan pemecahan masalah yang cukup luas dari bidang NLP. Memang dalam teks dialog misalnya reply-reply merupakan kelanjutan dari sejarah komunikasi, dalam sebuah karya fiksi - teks tiap paragraf melanjutkan teks sebelumnya, dan pada sesi tanya jawab, teks jawabannya mengikuti teks soal. Hasilnya, model berkapasitas besar dapat menyelesaikan banyak masalah seperti itu tanpa pelatihan tambahan khusus - model hanya memerlukan contoh yang sesuai dengan "konteks model"yang GPT-3 miliki cukup mengesankan - sebanyak 2048 token.
GPT-3 tidak hanya mampu menghasilkan teks (termasuk puisi, lelucon dan parodi sastra), tetapi juga mengoreksi kesalahan tata bahasa, melakukan dialog dan bahkan (KELUAR NEGARA!) Menulis kode program yang lebih atau kurang bermakna. Banyak kegunaan menarik dari GPT-3 dapat ditemukan di situs peneliti independen Gwern Branwen. Branuen, mengembangkan ide yang diungkapkan dalam cuitan lelucon oleh Andrej Karpathy, mengajukan pertanyaan menarik: apakah kita menyaksikan munculnya paradigma pemrograman baru?
Berikut teks tweet asli Karpaty:
“Saya menyukai ide Software 3.0. Pemrograman bergerak dari menyiapkan kumpulan data ke menyiapkan kueri yang memungkinkan sistem pembelajaran meta untuk "memahami" esensi tugas yang perlu dilakukan. LOL "[Suka ide untuk Software 3.0. Pemrograman berpindah dari kurasi kumpulan data ke petunjuk kurasi untuk membuat pelajar meta "mendapatkan" tugas yang seharusnya dilakukannya. LOL].
Mengembangkan ide Karpaty, Branuen menulis:
« GPT-3 [ ] , : , , , ( GPT-2); , , , [prompt], , , «» - , , . , , «» «», GPT-3 . « » , : , , , , , , , , , ».
Karena model kami "saw" github dan StackOverflow dalam proses pembelajaran, model ini cukup mampu menulis kode (terkadang tidak memiliki makna yang sangat dalam):
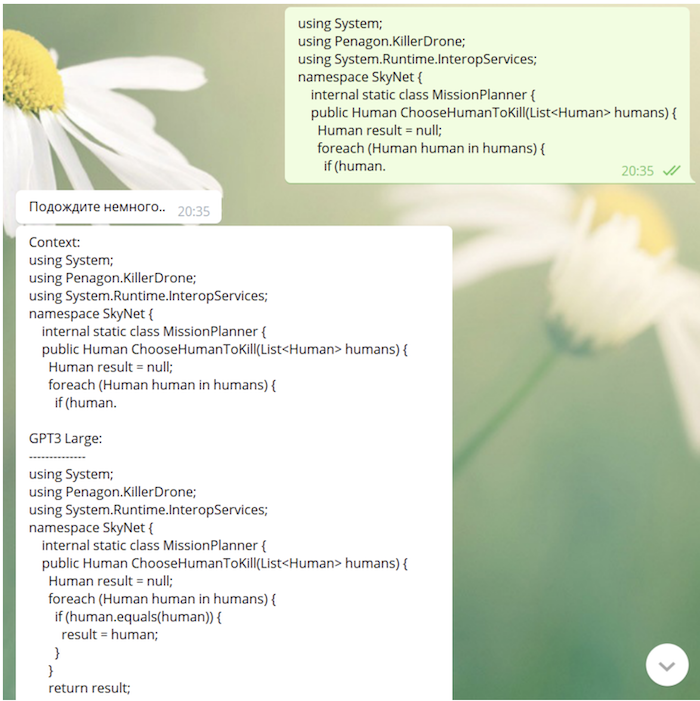
Apa berikutnya
Tahun ini kami akan terus mengerjakan model trafo raksasa. Rencana lebih lanjut terkait dengan perluasan lebih lanjut dan pembersihan kumpulan data (khususnya, akan mencakup snapshot dari layanan pracetak arxiv.org untuk publikasi ilmiah dan perpustakaan penelitian PubMed Central, kumpulan data dialog khusus dan kumpulan data pada logika simbolik), meningkatkan ukuran model terlatih, serta menggunakan tokenizer ditingkatkan.
Kami berharap publikasi model terlatih akan memacu kerja para peneliti dan pengembang Rusia yang membutuhkan model bahasa super canggih, karena berdasarkan ruGPT-3 Anda dapat membuat produk asli Anda sendiri, menyelesaikan berbagai masalah ilmiah dan bisnis. Coba gunakan model kami, bereksperimenlah dengan mereka dan pastikan untuk berbagi dengan semua hasil yang Anda dapatkan. Kemajuan ilmiah membuat dunia kita lebih baik dan lebih menarik, mari bersama-sama meningkatkan dunia!