Saya mencatat dengan sedih bahwa Libra (INI ADALAH SAYA!) Berada di tempat terakhir ... Meskipun, menurut data, menurut saya ada anomali. Entah kenapa, Libra kecil mencurigakan!
Bagian 1. Parsing dan mendapatkan data awal
Wikipedia Daftar daftar daftar
pada keluaran Anda membutuhkan basis dengan nama lengkap + tanggal lahir + (jika ada tanda lain - misalnya, m / f, negara, dll.) Ada API .
Situs ini ternyata adalah situs scraped (memanen / menerima / mengekstrak (mengekstrak) / mengumpulkan data yang diperoleh dari sumber web) menggunakan pustaka Python Scrapy.
Instruksi terperinci
pertama - tama diperoleh tautan (lembar dengan orang-orang dari Wikipedia, dan kemudian data).
Dalam kasus lain, mereka berhasil diurai seperti ini .
Hasil: File BD wiki.zip
Bagian 2. Tentang preprocessing (oleh Stanislav Kostenkov - kontak di bawah)
Banyak orang menghadapi kerumitan dalam mengolah data masukan. Jadi dalam tugas ini perlu menarik data kelahiran dari lebih dari 42 ribu artikel dan, jika memungkinkan, menentukan negara kelahiran. Di satu sisi, ini adalah tugas algoritmik sederhana, di sisi lain, alat sistem Excel & BI tidak memungkinkannya untuk dilakukan "langsung".
Pada saat seperti itu, bahasa pemrograman (Python, R) datang untuk menyelamatkan, peluncurannya disediakan di sebagian besar sistem BI. Perlu dicatat bahwa, misalnya, di Power BI ada batas 30 menit untuk menjalankan skrip (program) dengan Python. Oleh karena itu, banyak pemrosesan "berat" dilakukan sebelum peluncuran sistem BI, misalnya, di danau data.
Bagaimana masalah itu diselesaikan
Hal pertama yang saya lakukan setelah mengunduh dan memeriksa nilai yang salah adalah mengubah setiap artikel menjadi daftar kata.
Dalam tugas ini, saya beruntung dengan bahasanya, Inggris. Bahasa ini dicirikan oleh bentuk konstruksi kalimat yang kaku, yang sangat memudahkan pencarian tanggal lahir. Kata kuncinya di sini adalah "lahir", kemudian mencari dan menganalisis apa yang ada setelahnya.
Di sisi lain, semua artikel diambil dari satu sumber, yang juga mempermudah tugas. Semua artikel memiliki struktur dan kecepatan yang kira-kira sama.
Selanjutnya, semua tahun terdiri dari 4 karakter, semua tanggal terdiri dari 1–2 karakter, bulan adalah tekstual. Hanya ada 3-4 kemungkinan variasi dalam ejaan tanggal lahir, yang diselesaikan dengan logika sederhana. Itu juga bisa diurai melalui ekspresi reguler.
Kode sebenarnya tidak dioptimalkan (tugas seperti itu tidak ditetapkan, mungkin ada kekurangan pada nama variabel).
Seperti yang diprediksi oleh negara, saya beruntung menemukan tabel korespondensi negara dan kebangsaan. Biasanya, artikel-artikel tersebut menggambarkan bukan negaranya, tetapi tentang negaranya. Misalnya, Rusia - Rusia. Oleh karena itu, kami mencari kemunculan kebangsaan, tetapi karena mungkin terdapat lebih dari 5 kebangsaan yang berbeda dalam satu artikel, saya membuat hipotesis bahwa kata yang diinginkan akan paling mendekati kata kunci "bakar". Jadi, kriterianya adalah - jarak indeks minimum antara kata-kata yang diperlukan dalam artikel. Kemudian dalam satu baris diubah namanya dari kebangsaan menjadi negara.
Apa yang tidak dilakukan
Dalam artikel, banyak kata memiliki sampah, yaitu beberapa bagian kode terhubung ke kata, atau dua kata digabungkan menjadi satu. Oleh karena itu, kemungkinan menemukan nilai yang diinginkan dalam kata-kata tersebut tidak diperiksa. Anda dapat membersihkan kata-kata ini menggunakan algoritma kesamaan.
Entitas yang memiliki kata kunci "bakar" tidak dianalisis. Ada beberapa contoh kata kuncinya terkait dengan kelahiran kerabat. Contoh-contoh ini dapat diabaikan. Contoh-contoh ini dapat ditelusuri kembali ke fakta bahwa kata kunci tersebut jauh dari awal artikel. Anda dapat menghitung persentil untuk menemukan kata kunci dan menentukan kriteria pemotongan.
Penjelasan singkat tentang kegunaan preprocessing saat membersihkan data
Ada kasus umum ketika kita dapat menebak dengan tepat apa yang seharusnya menggantikan celah tersebut. Namun ada kasus, misalnya, ada kelalaian berdasarkan jenis kelamin pembeli toko dan ada data pembeliannya. Tidak ada teknik standar untuk memecahkan masalah ini dalam sistem BI, tetapi pada saat yang sama, pada tingkat pra-pemrosesan, Anda dapat membuat model "ringan" dan melihat berbagai opsi untuk mengisi celah. Ada opsi pengisian berdasarkan algoritme pembelajaran mesin sederhana. Dan itu layak digunakan. Tidak sulit.
Kode sumber (Python) tersedia di tautan
Hasil: file out_data_fin.xls
Stanislav Kostenkov / CBS Consulting (Izhevsk, Rusia) staskostenkov@gmail.com
Bagian 3. Aplikasi Qlik Sense
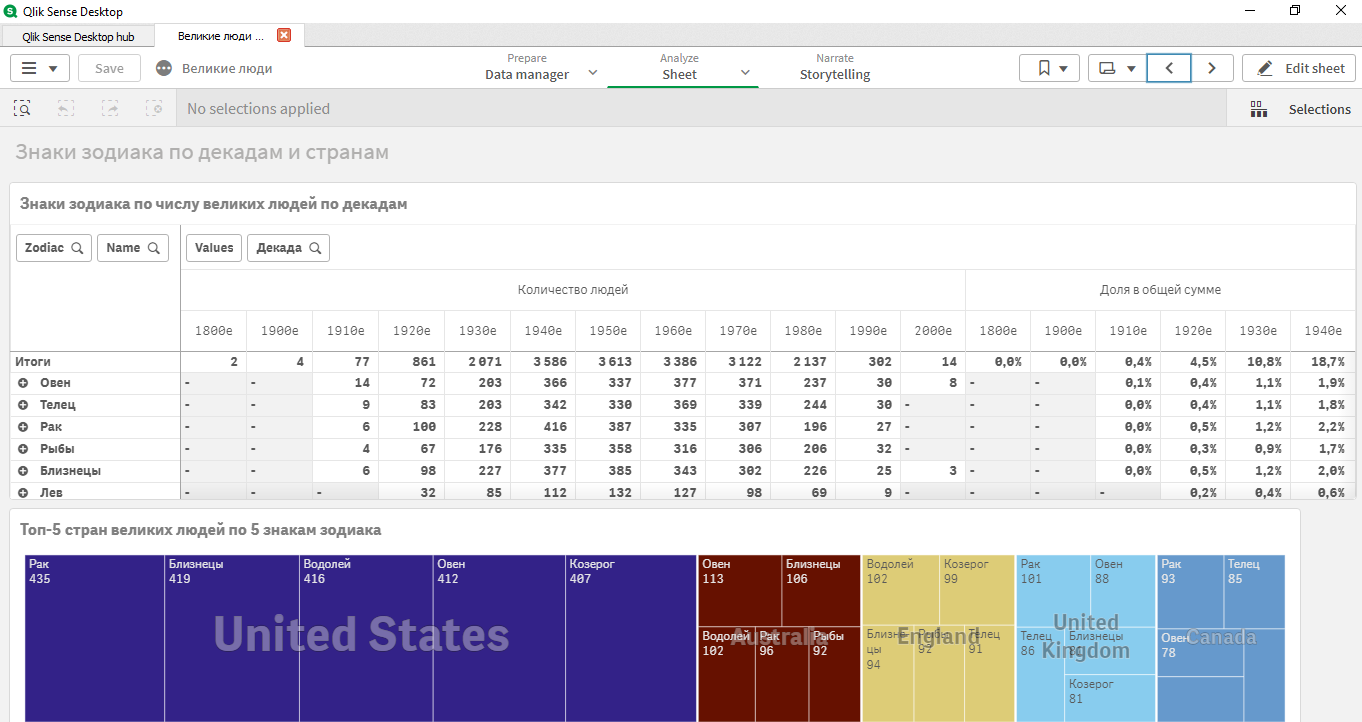
Kemudian aplikasi klasik dibuat, di mana beberapa anomali dengan dataset terungkap:
- masuk akal untuk memilih hanya beberapa dekade dari 1920-1980;
- di berbagai negara ada pemimpin yang berbeda sesuai dengan tanda-tanda horoskop;
- tanda atas: Cancer, Aries, Gemini, Taurus, Capricorn.
Semua data (kumpulan data, data mentah, yang diterima oleh aplikasi Qlik Sense untuk analisis data) berada dengan referensi .