Ada legenda Perjanjian Lama tentang bagaimana orang-orang di kota kuno Babilonia mulai membangun menara, tetapi Yang Mahakuasa mencampurkan lidah mereka, dan menara itu belum selesai. Memang menara itu dibangun oleh ratusan kelompok kecil, yang sama-sama tidak saling memahami. Dan tanpa saling memahami, mustahil untuk berinteraksi. Memang, itu hanya kegilaan untuk menyebut satu hal yang sama, menyiratkannya sama, dengan kata yang berbeda. Dan tidak ada yang mengejutkan di sini.
Legenda Perjanjian Lama dapat dengan mudah ditransfer ke perusahaan besar modern yang menerapkan solusi TI modern. Contoh dari perusahaan semacam itu, tidak diragukan lagi, dapat dikaitkan dengan bank Rusia modern, yang memiliki lusinan, bahkan ratusan unit bisnis, yang mengembangkan subkultur komunikasi mereka sendiri, yang dibangun di atas aturan mereka sendiri dan gaya perputaran bisnis yang unik. Wajar saja saat membentuk infrastruktur TI, gaya penamaan badan usaha yang sudah mapan di tim diperhitungkan. Selama sepuluh tahun terakhir, banyak karya tentang topik ini telah muncul, misalnya yang ini [1]. Mereka yang telah menemukan analisis sistem informasi di bank tahu apa artinya melakukan apa yang disebut "pemetaan" data, terutama jika sistem akhir dibuat oleh tim analis, pengembang, dan pelanggan atau vendor yang berbeda. Biasanya,60% kompilasi pemetaan adalah pemahaman tentang esensi dan semantik dari data yang dikirimkan.
Tren saat ini adalah menggunakan serangkaian metodologi tangkas. Semua orang berbicara tentang Agile . Anda bisa berdebat sampai serak apakah itu baik untuk bisnis atau merugikan. Tapi satu hal tidak akan membuat siapa pun menolak. Dalam kursus Agile, banyak tim yang berbeda, baik di dalam bank maupun dari vendor yang berbeda, membuat berbagai solusi TI untuk bisnis, dan seringkali, tanpa berinteraksi satu sama lain, tim membuat terminologi mereka sendiri. Dan pada saat integrasi benar-benar terjadi, situasi yang sama yang dijelaskan dalam Perjanjian Lama terjadi. Bagaimana tidak menyerupai pasar Babilonia dengan ribuan pedagang, toko, barang, orang suci, fakir dan pemakan api? Maka, semua orang ini, dipersenjatai dengan ide dan pemikiran yang berbeda, mulai membangun Menara.
XSD ( JSON ) , - . , , «» , Confluence, Zoom Webex, « » , — .
, ESB ( ) -, , , «-» , . … , , . , , - , Kafka. , , , . XML , XSD , , , , JSON, - , «» «». , , , JSON . . , . XSD , . JSON . .
? , - . , ?
.
- . , . MS Excel, , , «» . ( JSON path), — . «». . , :
« »
« »
«20- »
«12- »
« , »
, , , , -. , : , . – “ ”. , , , , , , .
, , , PIP! xslx , . , , Python, .
, – Python. , Python. , , - . , , . – , , . : « , ». — - PyQt Tkinter. , . .
, JSONpath , . , , , Python. , .
. JSON.
. “” 33- . 33 ? – “33” . «». . , , , [2]. . «» . : , , 33- . . . , ABC :
di mana setiap koordinat x pada posisi yang sesuai adalah jumlah huruf yang sesuai dari komentar bidang di file excel. Misalnya, kami memiliki komentar "Nomor rekening individu". Mari kita bandingkan vektor yang muncul dari koordinat asal sistem Cartesian dalam ruang alfabet 33 dimensi, akan terlihat seperti ini: koordinat X A - sesuai dengan jumlah huruf "a". Dan itu sama dengan dua. X B - dalam hal ini akan sama dengan nol, karena tidak ada huruf “b” dalam pernyataan ini. Hal yang sama berlaku untuk x B - huruf " B " tidak ada. Tapi x Dan - akan sama dengan 3, karena huruf "dan" dalam komentar muncul tiga kali.

Gambar 1 . , « » . «»= 2, «» =3. – xA=2, x=3.
, , ( ) , 33- « », :
, , « «»» ( , , «» «») « ». :
Sekarang kita menemukan perbedaan antara vektor dalam sistem koordinat Cartesian ruang alfabet, ditemukan, masing-masing, sesuai dengan rumus yang terkenal dari geometri analitik:
Dimana dan koordinat vektor yang sesuai untuk sumbu yang sesuai dengan surat itu.
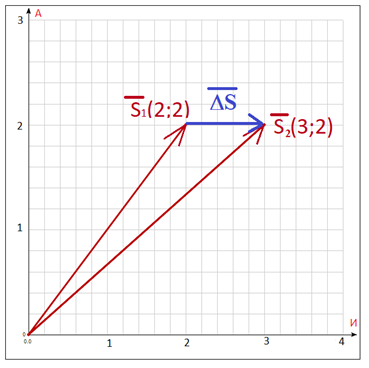
Gambar 2. Warna biru menunjukkan perbedaan antar vektordi bidang huruf - dari ruang alfabet.
Jadi, vektor yang sesuai dengan perbedaan antara pernyataan "Nomor rekening seorang individu" dan "Nomor rekening seorang fisikawan" akan terlihat seperti ini:
,
vektor yang sesuai dengan perbedaan antara pernyataan "Nomor akun individu" dan "Nomor akun klien" akan terlihat seperti ini:
Selanjutnya, panjang vektor perbedaan dihitung diperoleh dengan rumus:
Jika Anda membuat perhitungan aritmatika, Anda mendapatkan:
Ini secara matematis mengasumsikan bahwa frasa "Nomor rekening seorang individu" lebih dekat artinya dengan "Nomor rekening seorang fisikawan" daripada "Nomor rekening badan hukum". Ini ditunjukkan dengan panjang vektor perbedaan. Semakin pendek panjangnya, semakin dekat makna pernyataan tersebut satu sama lain. Jika kita, misalnya, mengambil dan membandingkan pernyataan "Nomor rekening seorang individu" dan "nomor cabang di mana rekening seorang individu dibuka", kita mendapatkan gambar 6.63. Ini akan menunjukkan bahwa jika dua pernyataan pertama memiliki arti yang dekat dengan aslinya (perbedaan dalam vektor 3.32 dan 4.00, masing-masing), maka pernyataan ketiga, jelas, bahkan akan memiliki esensi bisnis yang berbeda, meskipun sekumpulan kata identik yang terlihat terlihat identik ...
Anda dapat melangkah lebih jauh dan mencoba, melalui vektorisasi, untuk mengukur kedekatan komentar dalam arti. Untuk melakukan ini, saya sarankan menggunakan proyeksi vektor di atas satu sama lain. Kemudian cari perbandingan antara proyeksi panjang angin yang dibandingkan dengan panjang angin yang dibandingkan. Rasio ini akan selalu kurang dari atau sama dengan satu. Dan dengan demikian, jika pernyataannya identik satu sama lain, maka proyeksi akan bergabung dengan vektor yang menjadi tujuan proyeksi. Semakin jauh makna pernyataan yang dibandingkan, semakin sedikit proyeksinya. Jika Anda mengalikannya dengan 100%, Anda bisa mendapatkan derajat korespondensi pernyataan vektorisasi dalam persen. Jadi, proyeksi vektor pernyataan yang dibandingkan pada vektor pernyataan asli akan ditemukan dengan rumus berikut:
Jadi, derajat kepatuhan akan dihitung menggunakan rumus berikut:

Gambar 3. Ilustrasi proyeksi vektor per vektor ...
Parameter inilah yang diusulkan untuk dijadikan dasar dalam menentukan korespondensi semantik.
Implementasi algoritma dengan Python . Sedikit tentang aprikot. Bagaimana mengatur dan menangani vektor
Saya menamai algoritme Jerdella . Tidak ada yang aneh, saya baru saja dari Rostov-on-Don.
. , --, , , . , , -, -, -, “”. , .
, , Python , . , . , NumPy. , , NumPy? , – , , - « », . , NumPy. — . , , PIP... Oleh karena itu, Jerdella kami akan menggunakan paket standar yang disertakan dalam Edisi Komunitas PyCharm untuk penerjemah Python 3 .
Jadi hal yang baik tentang Python adalah ia memiliki kemampuan untuk mengimplementasikan berbagai macam struktur data. Dan mengapa kami tidak puas dengan daftar untuk merekam vektor? Daftar elemen tipe int adalah apa yang Anda butuhkan untuk mendefinisikan vektor dalam ruang alfabet dan operasi lebih lanjut dengannya.
Kami telah menulis sejumlah prosedur dasar, yang akan saya jelaskan secara singkat di bawah ini.
Bagaimana cara mengatur vektor?
Saya mengatur vektor dengan prosedur vektor berikut:
def vector(self,a):
vector=[]
abc = ["", '', "", "", "", "", "", "", "", "", "", "", "", "", "", "", "", "", "", "",
"", "", "", "", "", "", "", "", "", "", "", "", ""]
for char in abc:
count=a.count(char)
vector.append(count)
return(vector)Artinya, dalam perulangan for atas elemen daftar abc yang telah disiapkan sebelumnya , saya menggunakan operasi standar untuk menemukan lampiran ke string hitungan . Setelah itu, dengan menggunakan metode append, saya mengisi daftar vektor baru , yang akan menjadi vektor untuk perhitungan selanjutnya.
Bagaimana cara menghitung selisih vektor?
Untuk melakukan ini, saya membuat prosedur delta yang mengambil dua daftar sebagai input - a dan b .
def delta(self, a, b):
delta = []
for char1, char2 in zip(a, b):
d = char1 - char2
delta.append(d)
return (delta)Pada loop for , dengan melakukan iterasi pada kedua daftar, perbedaannya dihitung, ditambahkan pada setiap langkah iterasi ke akhir daftar delta , yang akhirnya dikembalikan oleh prosedur sebagai vektor.
Bagaimana Anda menghitung panjang vektor dan dengan demikian memperkirakan perbedaannya?
Untuk melakukan ini, saya membuat prosedur len_delta , yang mengambil daftar sebagai masukan, dan dengan mengulang setiap elemen dari daftar ini (ini juga merupakan koordinat dalam ruang alfabet), sesuai dengan aturan untuk menemukan modul vektor, menghitung panjang vektor.
def len_delta(self, a):
len = 0
for d in a:
len += d * d
return round(math.sqrt(len), 2)Bagaimana cara menghitung rasio proyeksi ke vektor dan dengan demikian memperkirakan persentase kebetulan?
Untuk ini, prosedur sederhanakan dibuat yang menggunakan dua daftar sebagai input. Di dalamnya, saya menerapkan rumus (6). Dan di sini poin penting adalah menentukan vektor mana yang memiliki panjang terbesar. Untuk kejelasan yang lebih baik dari penilaian kebetulan, akan lebih mudah untuk memproyeksikan vektor yang lebih kecil ke yang lebih besar.
def simplify(self, a, b):
len1 = 0
len2 = 0
scalar = 0
for x in a: len1 += x * x
for y in b: len2 += y * y
for x, y in zip(a, b): scalar += x * y
if len1 > len2:
return (scalar / len1) * 100
else:
return (scalar / len2) * 100Diskusi hasil yang diperoleh. Kami menaklukkan ruang semantik dengan menyusunnya
, , Jerdella . : 1) , , . 2) -. , CRM Siebel ESB, -. , , , -. , , . … . , , , …
… 2 , Agile, , point-to-point, , .
. , , . 2-3 , , . , , , : « » « », « », « », « », , . , 3000 , 500 ? – ? . , - 3000 ?
. «» , . . Python . «». “” , . « ». , , , – .
, :
{'Nomor rekening individu': [{4.69: 'Rekening bank klien'}, {6.0: 'Nama belakang'}, {4.8: 'Nomor rekening logam'}, {4.8: 'Nomor klien'}]}.
Diagram ini juga dapat divisualisasikan dalam bentuk grafik. Anda dapat melakukan banyak hal dengan kamus dengan Python ... Untuk visualisasi dan demonstrasi hasil, kami menggunakan proyek Internet terbuka www.graphonline.ru . Platform ini memungkinkan Anda untuk dengan cepat membuat grafik yang ditulis menggunakan GraphML .

Gambar 4. Grafik hubungan entitas "Jumlah individu". Ilustrasi keberadaan "orbit korespondensi semantik" dalam suatu entitas.
«» , (3) , , «» , . « » « ». , . , , , . .
? , « » «-». ( ( 3) (5)), . , « » . , « ».
, , , . . .

5. , .
, . … , , . , – ? ? ? — . 80%, , . , . , … - – . , .
, , , , . , , «» ( 6), . «», «», «», - -. , 30% . . , . , , , .

6. «» . , .
. .
«-» . , , - . ? , -.
. - . , . : « - ». , , . « » . , , , . – « ! - »…
, , - , , « », « » « », « », « ». , « ». , . ? ? « »?
, , , , , . – .
, :
[1] . . : . . 2010.
[2]. , . , . . Python. . – . , 2019, — 368 .
P.S. Accenture — ,