
Jalan yang sulit dan sulit dari seseorang yang telah menemukan FSIS USRN Rosreestr. Dia menunggu tanpa henti menunggu browser untuk memuat, kunci, captcha, interval antara permintaan 5 menit. Mengapa dia begitu menderita? Dia telah menyumbangkan uang hasil jerih payahnya ketika dia memutuskan untuk bekerja dengan sistem ini dan memesan ekstraknya. Tetapi tidak - mendapatkan ekstrak dari USRN seperti membuka baju. Langkah terakhir yang menunggu penderita - ekstrak yang diunduh dan didambakan diwakili oleh arsip zip, di mana, um, arsip lain dan file sig. Dan sudah di dalam adalah file pernyataan itu sendiri. Tapi juga tidak mudah untuk membacanya - ini dalam xml. Dan agar semuanya tumbuh bersama, ternyata perlu mengunduh xml ini bersama dengan sig ke halaman khusus Rosreestr. Dan di sana, masih ada captcha yang menunggu. Begitu pula dengan setiap pernyataan! Kami akan mengatasi rasa sakit terakhir ini hari ini menggunakan python.
Tugas:
- buka semua zip di folder,
- unduh berdasarkan spesifikasi. tautan ke Rosreestr,
- akhirnya unduh!, tampilan pernyataan yang dapat dibaca manusia.
Jadi, awalnya di folder tersebut ada arsip zip yang diunduh dari ekstrak:
Setelah mengimpor modul python:
import os
import zipfile
import webbrowser,time
from selenium import webdriver
from selenium.common.exceptions import NoSuchElementException
from selenium.webdriver.common.keys import Keys
from selenium.webdriver.common.action_chains import ActionChains
Mari kita buka semua arsip zip dan hapus sehingga tidak bingung dengan isinya:
zipFiles = []
sigFiles = []
for filename in os.listdir('.'):
if filename.endswith('.zip'):
zipfile.ZipFile(filename, 'r').extractall()
os.remove(filename)
Kami mendapat arsip zip dan file sig untuknya, yang kemudian akan diunggah ke situs web Rosreestr:
Buka loop program utama untuk semua file di direktori (dalam kasus saya, "C: / 2"):
for filename in zipFiles:
act = browser.find_element_by_id('sig_file')
act.send_keys('C:\\2\\'+str(filename)+'.sig')
act = browser.find_element_by_id('xml_file')
# zip
zip_ref = zipfile.ZipFile(filename, 'r').extractall()
# xml
for f in os.listdir('.'):
if f.endswith('.xml'):
print(f)
# xml
act.send_keys('C:\\2\\'+str(f))
act = browser.find_element_by_css_selector('input.brdg1111')
act.click()
i = str(input(" : "))
for b in i:
act.send_keys(b)
time.sleep (0.1)
#act.submit()
act = browser.find_element_by_css_selector('.terminal-button-bright')
act.click()
time.sleep (5)
try:
act = browser.find_element_by_link_text(' ')
act.click()
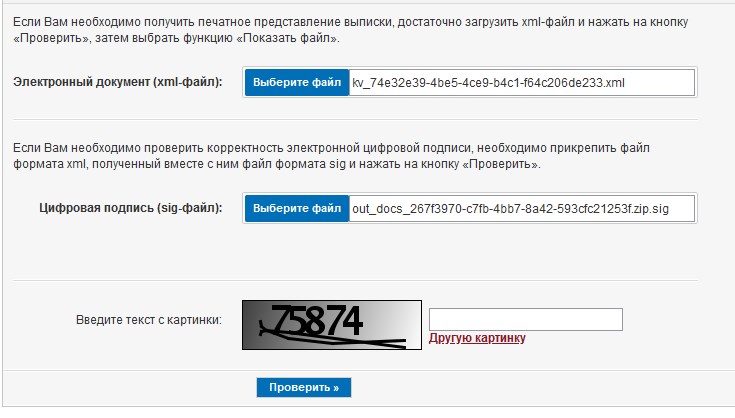
Setelah berhasil memuat halaman portal Rosreestr rosreestr.gov.ru/wps/portal/cc_vizualisation , program akan menemukan arsip zip di direktori, mendapatkan file pernyataan xml dari sana dan memasukkannya ke bidang yang diperlukan di situs. Program akan melakukan hal yang sama dengan file sig yang dilampirkan ke xml:
Selanjutnya, program akan menunggu captcha dimasukkan:
Setelah pengguna memasukkan captcha, ia akan mengirimkannya ke situs dan mengklik tautan unduhan untuk ekstrak "normal" dari USRN:
Sebuah jendela akan terbuka di mana yang selesai ekstrak, yang dapat disimpan dalam html atau dengan menekan CTRL + P di Chrome - dalam pdf.
Tetap menambahkan captcha pemecahan otomatis dan unduh otomatis ekstrak yang dapat dibaca manusia. Tapi ini hal yang paling sederhana, bukan?
Kode programnya ada di sini .