Menurut kepercayaan populer, mengekstrak teks dari PDF seharusnya tidak terlalu sulit. Bagaimanapun, ini dia, teks, tepat di depan mata kita, dan orang-orang yang terus-menerus dan dengan sukses besar memahami konten PDF. Dari mana asal kesulitan dalam ekstraksi teks otomatis?
Ternyata bekerja dengan nama orang sulit untuk algoritma karena banyak kasus tepi dan asumsi yang salah, bekerja dengan PDF sulit karena fleksibilitas ekstrim dari format PDF.
Masalah utamanya adalah bahwa PDF tidak dimaksudkan sebagai format untuk entri data - itu dikembangkan sebagai saluran keluaran, memungkinkan untuk menyempurnakan tampilan dokumen akhir.
Pada dasarnya, format PDF terdiri dari aliran instruksi yang menjelaskan bagaimana gambar dibuat pada halaman. Secara khusus, data teks tidak disimpan sebagai paragraf - atau bahkan kata - tetapi sebagai karakter yang digambar di lokasi tertentu pada halaman. Akibatnya, saat mengonversi teks atau dokumen Word ke PDF, sebagian besar semantik konten hilang. Seluruh struktur internal teks berubah menjadi sup karakter amorf yang mengambang di halaman.
Dengan mengisi FilingDB, kami telah mengekstrak data teks dari puluhan ribu dokumen PDF. Dalam prosesnya, kami mengamati betapa semua asumsi kami tentang struktur file PDF ternyata salah. Misi kami sangat sulit karena kami harus memproses dokumen PDF yang berasal dari sumber berbeda dengan gaya, font, dan tampilan yang sangat berbeda.
Berikut ini penjelasan tentang fitur file PDF yang menyulitkan atau bahkan tidak mungkin mengekstrak teks darinya.
Perlindungan baca PDF
Anda mungkin pernah menemukan file PDF yang melarang menyalin konten teks darinya. Misalnya, inilah yang dihasilkan oleh program SumatraPDF saat mencoba menyalin teks dari dokumen yang dilindungi hak cipta:

Menariknya, teks tersebut terlihat, tetapi pemirsa menolak untuk mentransfer teks yang dipilih ke papan klip.
Ini dilakukan dengan beberapa tanda "izin akses", salah satunya mengontrol izin salin. Penting untuk dipahami bahwa file PDF itu sendiri tidak memaksakan ini - isinya tidak berubah dari ini, dan tugas implementasinya terletak sepenuhnya pada penampil.
Secara alami, ini tidak benar-benar melindungi dari mengekstrak teks dari PDF, karena perpustakaan yang cukup canggih untuk bekerja dengan PDF akan memungkinkan pengguna untuk mengubah tanda ini atau mengabaikannya.
Karakter di luar halaman
Seringkali, PDF berisi lebih banyak data tekstual daripada yang ditampilkan di halaman. Ambil halaman ini dari Laporan Tahunan 2010 Nestle.
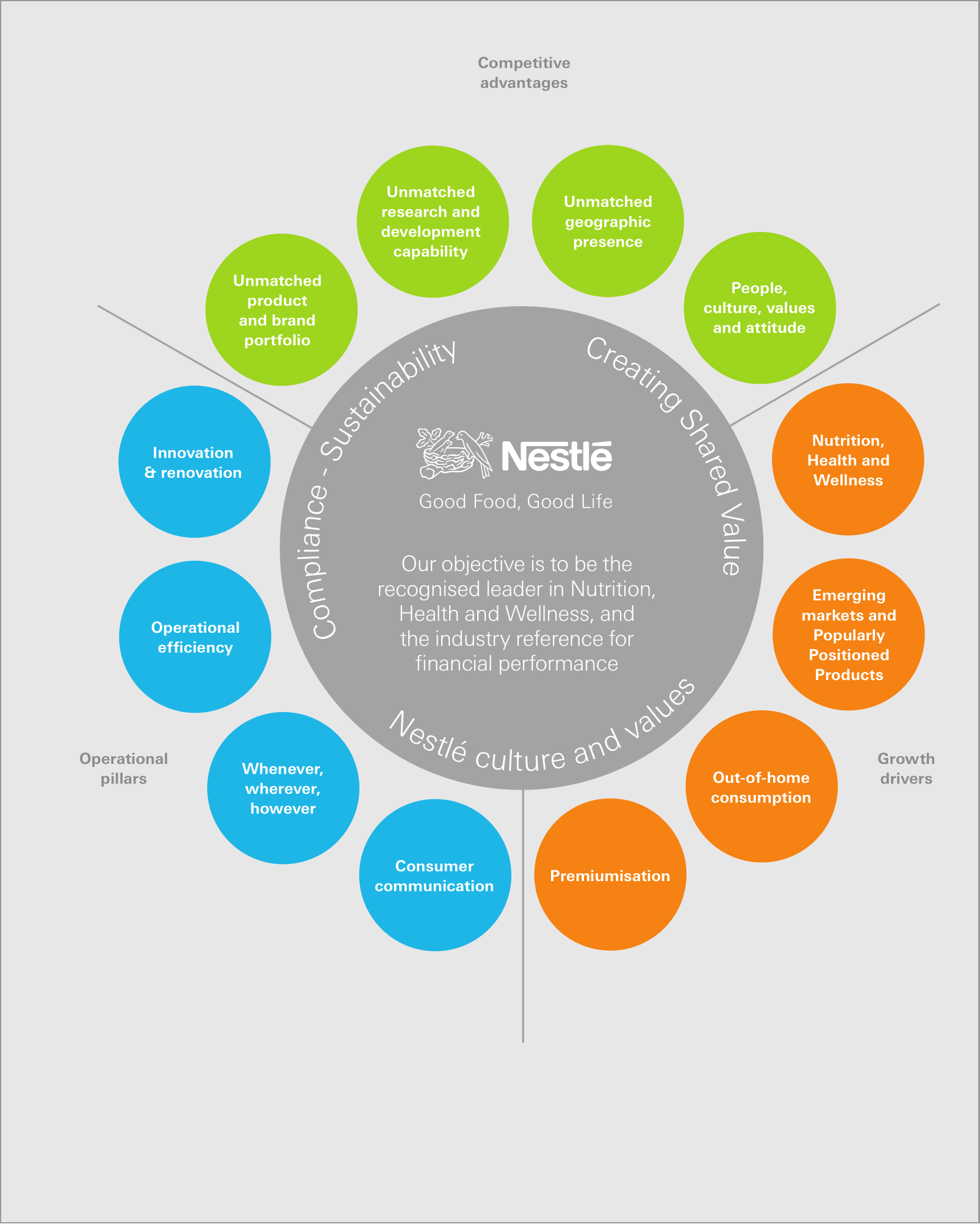
Ada lebih banyak teks yang dilampirkan ke halaman ini daripada yang terlihat. Secara khusus, berikut ini dapat ditemukan di konten yang terkait dengannya:
KitKat merayakan ulang tahunnya yang ke-75 pada tahun 2010, tetapi tetap muda dan trendi dengan lebih dari 2,5 juta penggemar Facebook. Produknya dijual di lebih dari 70 negara, dan penjualannya tumbuh dengan baik di negara maju dan pasar berkembang seperti Timur Tengah, India, dan Rusia. Jepang adalah pasar terbesar kedua perusahaan.
Teks ini di luar halaman, jadi sebagian besar penampil PDF tidak akan menampilkannya. Namun, datanya ada di sana dan dapat diambil secara terprogram.
Ini terkadang karena keputusan menit terakhir untuk mengganti atau menghapus teks selama proses persetujuan.
Karakter kecil atau tidak terlihat
Terkadang, karakter yang sangat kecil atau bahkan tidak terlihat dapat ditemukan di halaman PDF. Misalnya, berikut adalah halaman dari laporan Nestle 2012.

Halaman tersebut memiliki teks putih kecil dengan latar belakang putih yang bertuliskan:
Wyeth Nutrition logo Identity Guidance untuk memasarkan
Vevey Octobre 2012 RCC / CI & D
Ini terkadang dilakukan untuk meningkatkan aksesibilitas, untuk tujuan yang sama seperti tag alt di HTML.
Terlalu banyak spasi
Terkadang spasi tambahan disisipkan di antara huruf kata dalam PDF. Ini mungkin dilakukan untuk tujuan kerning (mengubah jarak antar karakter).
Misalnya, laporan Farmasi Hikma 2013 berisi teks berikut:

Jika Anda menyalinnya, kami mendapatkan:
ch a i r m a n ' s s tat em en tSecara umum, sulit untuk memecahkan masalah rekonstruksi teks asli. Pendekatan kami yang paling sukses adalah menggunakan pengenalan karakter optik, OCR.
Tidak cukup ruang
Terkadang PDF kehilangan spasi atau telah diganti dengan karakter yang berbeda.
Contoh 1: Ekstrak berikut ini dari Laporan Tahunan SEB 2017.

Teks yang diekstrak:
TenyearsafterthefinancialcrisisstartedContoh 2: Laporan Eurobank 2013 berisi yang berikut ini:

Teks yang diekstrak:
On_April_7,_2013,_the_competent_authoritiesSekali lagi, OCR adalah pilihan terbaik untuk halaman ini.
Font bawaan
PDF bekerja dengan font dengan cara yang kompleks, secara halus. Untuk memahami bagaimana data teks disimpan dalam PDF, pertama-tama kita perlu memahami mesin terbang, nama mesin terbang, dan font.
- Mesin terbang adalah seperangkat instruksi yang menjelaskan cara menggambar karakter atau huruf.
- – , . , « » ™ «» «».
- – . , , , «», .
Dalam PDF, karakter disimpan sebagai angka, kode karakter [titik kode]. Untuk memahami apa yang perlu ditampilkan di layar, penyaji harus mengikuti rantai dari kode karakter ke nama mesin terbang, dan kemudian ke mesin terbang itu sendiri.
Misalnya, PDF mungkin berisi kode karakter 116, yang dipetakan ke nama mesin terbang "t", yang pada gilirannya memetakan ke mesin terbang yang menjelaskan cara menampilkan karakter "t".
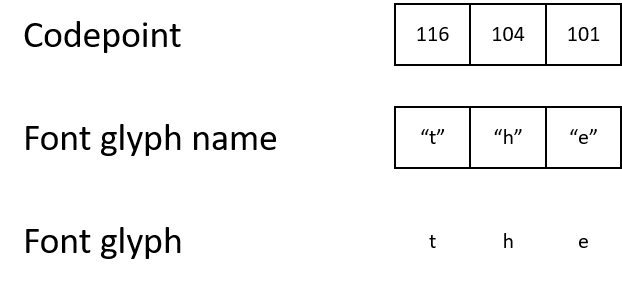
Kebanyakan PDF menggunakan pengkodean karakter standar. Pengkodean karakter adalah sekumpulan aturan yang memberikan arti pada kode karakter itu sendiri. Misalnya:
- ASCII dan Unicode menggunakan kode karakter 116 untuk mewakili huruf "t".
- Unicode memetakan kode karakter 9786 ke mesin terbang "white smiley", yang ditampilkan sebagai ☺, tetapi ASCII tidak mendefinisikan kode tersebut.
Namun, dokumen PDF terkadang menggunakan pengkodean karakternya sendiri dan font khusus. Ini mungkin terdengar aneh, tapi dokumen mungkin menunjukkan huruf "t" dengan kode karakter 1. Ini akan memetakan kode karakter 1 ke nama mesin terbang "c1", yang akan dipetakan ke mesin terbang yang menjelaskan bagaimana menampilkan huruf "t".
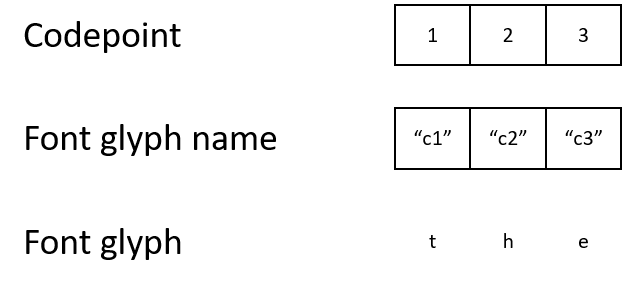
Meskipun hasil akhirnya tidak berbeda dengan manusia, mesin akan bingung dengan kode karakter ini. Jika kode karakter tidak cocok dengan pengkodean standar, hampir tidak mungkin untuk memahami secara terprogram apa arti kode 1, 2, atau 3.
Mengapa PDF menyertakan font dan pengkodean non-standar?
- Salah satu alasannya adalah mempersulit ekstraksi teks.
- – . , PDF . PDF , .
Salah satu cara untuk menyiasatinya adalah dengan mengekstrak font glyph dari dokumen, menjalankannya melalui OCR, dan memetakan font ke Unicode. Ini akan memungkinkan Anda untuk menerjemahkan pengkodean terkait font ke Unicode, misalnya: kode karakter 1 sesuai dengan nama "c1", yang menurut mesin terbang, harus berarti "t", yang sesuai dengan kode Unicode 116.
Peta pengkodean Anda baru saja selesai - yang cocok dengan angka 1 dan 116 - disebut kartu ToUnicode dalam standar PDF. Dokumen PDF dapat berisi kartu ToUnicode-nya sendiri, tetapi ini tidak wajib.
Pengenalan kata dan paragraf
Merekonstruksi paragraf dan bahkan kata-kata dari sup simbolik amorf PDF adalah tugas yang menakutkan.
Dokumen PDF berisi daftar karakter pada halaman, dan terserah konsumen untuk mengenali kata dan paragraf. Manusia secara alami efektif dalam hal ini karena membaca adalah keterampilan umum.
Algoritme pengelompokan yang paling umum digunakan adalah membandingkan ukuran, posisi, dan perataan karakter untuk menentukan apa itu kata atau paragraf.
Implementasi paling sederhana dari algoritme semacam itu dapat dengan mudah mencapai kompleksitas O (n²), yang dapat memakan waktu lama untuk memproses halaman yang padat.
Urutan teks dan paragraf
Mengenali urutan teks dan paragraf itu menantang karena dua alasan.
Pertama, terkadang tidak ada jawaban yang benar. Sementara dokumen dengan himpunan tipografi biasa dengan satu kolom memiliki urutan pembacaan yang natural, dokumen dengan susunan elemen yang lebih tegas lebih sulit ditentukan. Misalnya, tidak sepenuhnya jelas apakah sisipan berikutnya harus diletakkan sebelum, sesudah, atau di tengah artikel di sebelah tempatnya berada:

Kedua, bahkan ketika jawabannya jelas bagi seseorang, komputer bisa sangat sulit untuk menentukan urutan paragraf yang tepat - bahkan menggunakan AI. Anda mungkin merasa pernyataan ini agak berani, tetapi dalam beberapa kasus, urutan paragraf yang benar hanya dapat ditentukan dengan memahami konten teks.
Pertimbangkan pengaturan komponen ini dalam dua kolom, yang menggambarkan persiapan salad sayuran.

Di dunia Barat, masuk akal untuk mengasumsikan bahwa membaca dari kiri ke kanan dan dari atas ke bawah. Oleh karena itu, tanpa memeriksa isi teks, kita dapat mengurangi semua opsi menjadi dua: ABCD dan ACB D.
Setelah memeriksa isinya, memahami apa yang tertulis di sana, dan mengetahui bahwa sayuran dicuci sebelum diiris, kita dapat memahami bahwa urutan yang benar adalah ACB D. Sangat sulit untuk menentukan ini secara algoritmik.
Dalam kasus ini, "dalam banyak kasus" pendekatan yang bergantung pada urutan penyimpanan teks dalam dokumen PDF. Biasanya mengikuti urutan teks yang disisipkan pada waktu pembuatan. Jika potongan besar teks berisi banyak paragraf, biasanya mereka mengikuti urutan yang dimaksudkan penulis.
Gambar yang disematkan
Seringkali, bagian dari isi dokumen (atau keseluruhan dokumen) adalah gambar yang dipindai. Dalam kasus seperti itu, tidak ada data tekstual di dalamnya, dan Anda harus menggunakan OCR.
Misalnya, Laporan Tahunan Yell 2011 hanya tersedia sebagai pindaian:

Mengapa tidak mengenali semuanya?
Meskipun OCR dapat membantu dengan beberapa masalah yang dijelaskan, OCR juga memiliki kekurangannya.
- Waktu pengerjaan yang lama. Menjalankan OCR pada pemindaian dari PDF biasanya membutuhkan urutan besarnya lebih lama (atau bahkan lebih lama) daripada mengekstrak teks langsung dari PDF.
- Kesulitan dengan karakter dan mesin terbang non-standar. Sulit bagi algoritme OCR untuk bekerja dengan karakter baru - emotikon, tanda bintang, lingkaran, kotak (dalam daftar), superskrip, simbol matematika kompleks, dll.
- . , PDF-, , . .
Sejauh ini kami belum menyebutkan betapa sulitnya untuk memastikan bahwa teks diekstrak dengan benar atau seperti yang diharapkan. Kami telah menemukan bahwa yang terbaik adalah menjalankan serangkaian pengujian ekstensif yang mempelajari metrik dasar (panjang teks, panjang halaman, rasio kata terhadap spasi) dan lebih kompleks (persentase kata dalam bahasa Inggris, persentase kata yang tidak dikenali, persentase angka), serta monitor peringatan seperti karakter yang mencurigakan atau tidak terduga.
Saran apa yang dapat kami miliki untuk mengekstrak teks dari PDF? Pertama-tama, pastikan teks tersebut tidak memiliki sumber yang lebih nyaman.
Jika data yang Anda minati hanya dalam format PDF, maka penting untuk dipahami bahwa masalah ini tampak sederhana hanya pada pandangan pertama, dan mungkin tidak dapat diselesaikan dengan akurasi 100%.