Kami melanjutkan serangkaian artikel tentang moderasi konten di situs Pusat Pengembangan Teknologi Keuangan Bank Pertanian Rusia. Di artikel terakhir, kami berbicara tentang bagaimana kami memecahkan masalah moderasi teks untuk salah satu situs ekosistem untuk petani "Bertani Sendiri" . Anda dapat membaca sedikit tentang situs itu sendiri dan hasil apa yang kami dapatkan di sini .
Singkatnya, kami menggunakan ansambel dari pengklasifikasi naif (filter berdasarkan kamus) dan BERT. Teks yang lolos saringan kamus diizinkan untuk masuk BERT, di mana mereka juga diperiksa.
Dan kami, bersama dengan Laboratorium MIPT, terus meningkatkan situs kami, menempatkan diri kami sendiri pada tugas yang lebih sulit dari moderasi informasi grafik. Tugas ini ternyata lebih sulit daripada yang sebelumnya, karena saat memproses bahasa natural, seseorang dapat melakukannya tanpa menggunakan model jaringan saraf. Dengan gambar, semuanya menjadi lebih rumit - sebagian besar tugas diselesaikan menggunakan jaringan neural dan pemilihan arsitektur yang benar. Tetapi dengan tugas ini, menurut kami, kami telah mengatasinya dengan baik! Dan apa yang kami dapatkan dari ini, baca terus.

Apa yang kita inginkan?
Jadi ayo pergi! Mari kita segera tentukan seperti apa alat moderasi gambar itu. Dengan analogi dengan alat moderasi teks, ini seharusnya menjadi semacam "kotak hitam". Dengan mengirimkan gambar yang diunggah ke situs oleh penjual barang sebagai masukan, kami ingin memahami bagaimana gambar ini dapat diterima untuk dipublikasikan di situs. Dengan demikian, kita mendapat tugas: menentukan apakah gambar tersebut cocok untuk dipublikasikan di situs atau tidak.
Tugas moderasi awal gambar adalah hal biasa, tetapi solusinya sering berbeda dari situs ke situs. Dengan demikian, gambar organ dalam mungkin dapat diterima untuk forum medis, tetapi tidak cocok untuk jejaring sosial. Atau, misalnya, gambar bangkai hewan yang dipotong dapat diterima di situs web tempat penjualannya, tetapi gambar tersebut kemungkinan tidak disukai oleh anak-anak yang mengakses internet untuk menonton Smesharikov. Untuk situs kami, gambar produk pertanian (sayuran / buah-buahan, pakan ternak, pupuk, dll.) Dapat diterima untuk itu. Di sisi lain, jelas bahwa tema marketplace kami tidak menyiratkan adanya gambar dengan berbagai konten cabul atau menyinggung.
Untuk memulainya, kami memutuskan untuk mengetahui solusi yang sudah diketahui untuk masalah tersebut dan mencoba menyesuaikannya dengan situs kami. Sebagai aturan, banyak tugas moderasi konten grafis direduksi menjadi pemecahan masalah kelas NSFW , di mana terdapat kumpulan data yang tersedia untuk umum.
Untuk mengatasi masalah NSFW, biasanya digunakan pengklasifikasi berdasarkan ResNet, yang menunjukkan akurasi kualitas> 93%.
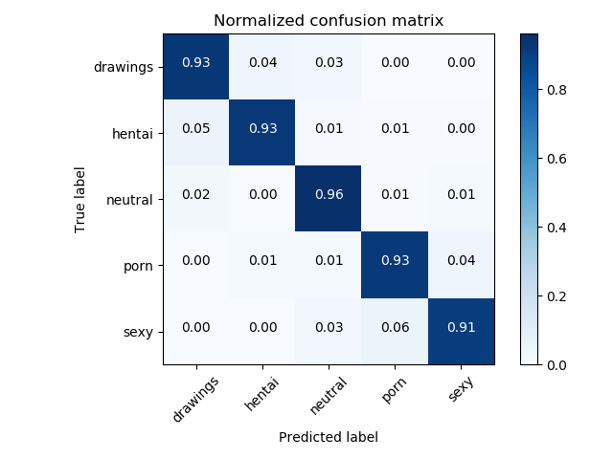
Matriks kesalahan pengklasifikasi NSFW asli
Oke, katakanlah kita memiliki model yang bagus dan kumpulan data siap pakai untuk NSFW, tetapi apakah itu cukup untuk menentukan penerimaan gambar untuk situs tersebut? Ternyata tidak. Setelah membahas pendekatan awal ini dengan model NSFW dengan pemilik situs kami, kami menyadari bahwa perlu untuk menentukan lebih banyak kategori, yaitu:
- ( , )
- ( , , , . )
- ( )
Artinya, kami masih harus membuat kumpulan data kami sendiri dan memikirkan model lain apa yang bisa berguna.
Di sinilah kami mengalami masalah pembelajaran mesin yang umum: kurangnya data. Ini karena fakta bahwa situs kami dibuat belum lama ini, dan tidak ada contoh negatif di dalamnya, yang ditandai sebagai tidak dapat diterima. Untuk mengatasinya, metode pembelajaran beberapa langkah membantu kami . Inti dari metode ini adalah kita dapat melatih ulang, misalnya, ResNet pada dataset kecil yang kita rakit, dan mendapatkan akurasi yang lebih tinggi daripada jika kita membuat pengklasifikasi dari awal dan hanya menggunakan dataset kecil kita.
Bagaimana kamu melakukannya?
Di bawah ini adalah skema umum solusi kami, dimulai dari gambar input dan diakhiri dengan hasil deteksi berbagai kategori, jika gambar apel diumpankan ke input.

Skema umum solusinya
Mari kita pertimbangkan setiap bagian dari skema secara lebih rinci.
Tahap 1: Detektor grafiti
Kami berharap barang dengan teks pada paket akan dimuat ke situs kami dan, karenanya, tugas untuk mendeteksi prasasti dan mengidentifikasi artinya muncul.
Pada tahap pertama, kami menggunakan pustaka Deteksi Teks OpenCV untuk menemukan label pada paket.
OpenCV Text Detection adalah alat pengenalan karakter optik (OCR) untuk Python. Artinya, ia mengenali dan "membaca" teks yang disematkan dalam gambar.

Contoh operasi detektor EAST
Anda dapat melihat contoh deteksi prasasti di foto. Untuk mengidentifikasi kotak pembatas, kami menggunakan model EAST, tetapi di sini pembaca mungkin merasakan kesulitan, karena model ini dilatih untuk mengenali teks bahasa Inggris, dan pada gambar kami teksnya dalam bahasa Rusia. Oleh karena itu, selanjutnya digunakan model klasifikasi biner (coretan / bukan coretan) berbasis ResNet, yang telah dilatihkan untuk memenuhi kualitas yang disyaratkan pada data kami. Kami menggunakan ResNet-18, karena model ini terbukti menjadi yang terbaik saat memilih arsitektur.
Dalam tugas kita, kita ingin membedakan foto yang tulisannya adalah tulisan pada kemasan barang dari coretan. Oleh karena itu, kami memutuskan untuk membagi semua foto dengan teks menjadi dua kelas: grafiti dan non-grafiti.
Akurasi model yang diperoleh adalah 95% pada sampel yang ditangguhkan:
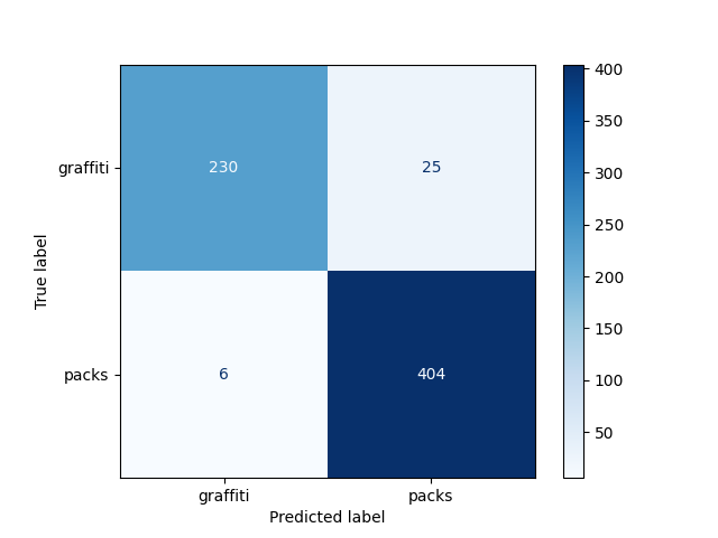
Graffiti Detector Bug Matrix
Lumayan! Sekarang kami dapat mengisolasi teks dalam foto dan dengan probabilitas yang baik memahami apakah teks tersebut cocok untuk publikasi. Tetapi bagaimana jika tidak ada teks di foto?
Tahap 2: Detektor NSFW
Jika kami tidak menemukan teks pada gambar, bukan berarti teks tersebut tidak dapat diterima, oleh karena itu, selanjutnya kami ingin mengevaluasi bagaimana konten pada gambar sesuai dengan tema situs.
Pada tahap ini, tugasnya adalah menetapkan gambar ke salah satu kategori:
- narkoba
- porno (porno)
- hewan
- foto yang dapat menyebabkan penolakan (termasuk gambar) (gore / drawing_gore)
- hentai (hentai)
- gambar netral (netral)
Penting bahwa model tidak hanya mengembalikan kategori, tetapi juga tingkat kepercayaan algoritme di dalamnya.
Model berbasis NSFW digunakan untuk klasifikasi. Dia dilatih sedemikian rupa sehingga dia membagi foto menjadi 7 kelas dan hanya satu yang kami harapkan untuk dilihat di situs. Oleh karena itu, kami hanya meninggalkan foto netral.
Hasil dari model tersebut adalah 97% (dalam hal akurasi)

matriks kesalahan detektor NSFW
Tahap 3: Detektor orang
Tetapi bahkan setelah kita mempelajari cara memfilter NSFW, masalahnya masih belum dapat dipecahkan. Misalnya, foto seseorang tidak termasuk dalam kategori NSFW atau foto dengan kategori teks, tetapi kami juga tidak ingin melihat gambar seperti itu di situs. Kemudian kami menambahkan ke arsitektur kami model deteksi manusia - Detektor Tembakan Tunggal (selanjutnya disebut sebagai SSD).
Memilih orang atau objek lain yang sebelumnya dikenal juga merupakan tugas populer dengan berbagai aplikasi. Kami menggunakan model nvidia_ssd siap pakai dari pytorch.

Contoh algoritma SSD
Hasil model lebih rendah (akurasi - 96%):

Matriks kesalahan detektor manusia
hasil
Kami menilai kualitas instrumen kami menggunakan metrik F1, Presisi, Perolehan berbobot. Hasilnya disajikan dalam tabel:
| Metrik | Akurasi diperoleh |
| F1 berbobot | 0.96 |
| Presisi Tertimbang | 0.96 |
| Recall Tertimbang | 0.96 |
Dan berikut adalah beberapa contoh ilustratif dari pekerjaannya:
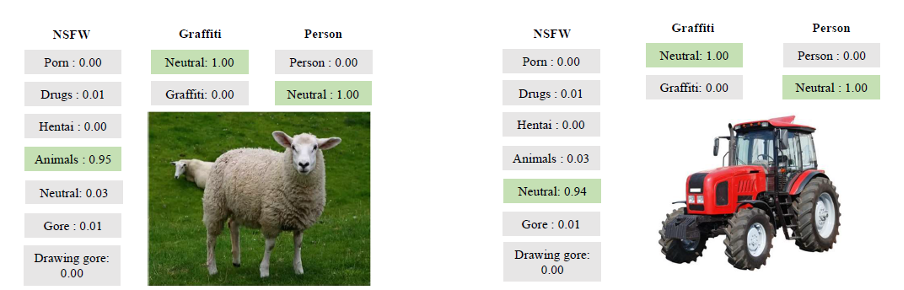
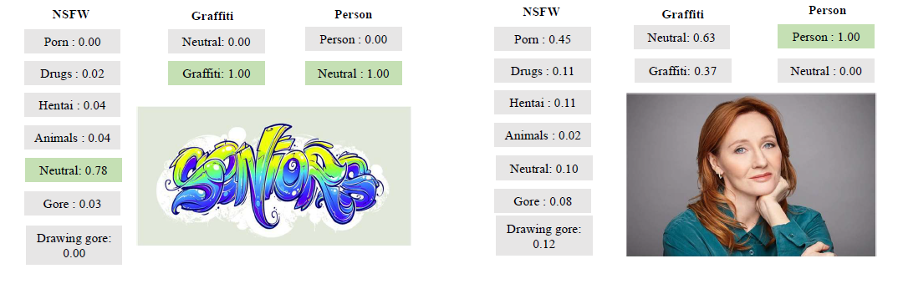
Contoh alat
Kesimpulan
Dalam proses pemecahannya, kami menggunakan seluruh "kebun binatang" model yang sering digunakan untuk tugas-tugas computer vision. Kami belajar untuk "membaca" teks dari sebuah foto, menemukan orang, dan membedakan konten yang tidak pantas.
Akhirnya, saya ingin mencatat bahwa masalah yang dipertimbangkan berguna dari sudut pandang mendapatkan pengalaman dan menggunakan model klasik yang dimodifikasi. Berikut beberapa wawasan yang kami dapatkan:
- Anda dapat mengatasi masalah kekurangan data menggunakan metode pembelajaran beberapa langkah: model besar dapat dilatih dengan akurasi yang diperlukan pada datanya sendiri
- : ,
- , ,
- , , . , , ,
- Terlepas dari kenyataan bahwa tugas moderasi gambar cukup populer, solusinya, seperti dalam kasus teks, mungkin berbeda dari situs ke situs, karena masing-masing dirancang untuk audiens yang berbeda. Dalam kasus kami, misalnya, kami, selain konten yang tidak pantas, juga mendeteksi hewan dan manusia
Terima kasih atas perhatiannya dan sampai jumpa di artikel selanjutnya!