Hari ini kami melakukan percakapan fisik dan teknis dengan Mikhail Burtsev , kepala laboratorium jaringan saraf di MIPT. Minat penelitiannya meliputi model pembelajaran jaringan saraf, sistem neurokognitif dan neurohibrid, evolusi sistem adaptif dan algoritme evolusioner, pengontrol saraf, dan robotika. Semua ini akan dibahas.

- Bagaimana sejarah Laboratorium Jaringan Neural dan Pembelajaran Mendalam di Phystech dimulai?
- Pada tahun 2015, saya mengambil bagian dalam inisiatif Agency for Strategic Initiatives (ASI) yang disebut "Foresight Fleet" - ini adalah platform multi-hari untuk diskusi di bawah National Technical Initiative. Topik utamanya adalah teknologi yang perlu dikembangkan agar perusahaan muncul di Rusia dengan potensi untuk mengambil posisi terdepan di pasar global. Pesan utamanya adalah bahwa sangat sulit untuk memasuki pasar yang terbentuk, tetapi teknologi membuka wilayah baru dan pasar baru, dan justru di situlah kita perlu masuk.
Jadi kami berlayar dengan kapal motor di sepanjang Volga dan membahas teknologi apa yang dapat membantu menciptakan pasar semacam itu dan memecahkan hambatan teknologi saat ini. Dan dalam diskusi tentang masa depan ini, topik asisten pribadi telah berkembang. Jelas bahwa kami sudah mulai menggunakannya - Alexa, Alice, Siri ... dan jelas ada hambatan teknis dalam memahami antara manusia dan komputer. Di sisi lain, banyak perkembangan penelitian yang terakumulasi, misalnya di bidang reinforcement learning, dalam natural language processing. Dan menjadi jelas: banyak tugas sulit menjadi lebih baik dan lebih baik diselesaikan dengan bantuan jaringan saraf.
Dan saya baru saja melakukan penelitian tentang algoritme jaringan saraf. Berdasarkan hasil diskusi Foresight Fleet, kami merumuskan konsep proyek pengembangan teknologi untuk waktu dekat, yang kemudian ditransformasikan menjadi proyek iPavlov. Ini adalah awal interaksi saya dengan Phystech.
Secara lebih rinci, kami telah merumuskan tiga tugas. Infrastruktur - membuat perpustakaan terbuka untuk melakukan dialog dengan pengguna. Yang kedua adalah penelitian dalam pemrosesan bahasa alami. Ditambah solusi dari masalah bisnis tertentu .
Sberbank bertindak sebagai mitra, dan proyek itu sendiri dibentuk di bawah naungan Prakarsa Teknis Nasional.
, 2015 -: deephack.me — , , - , . Open Data Science.
Pada awal 2018, kami menerbitkan repositori pertama perpustakaan terbuka kami DeepPavlov, dan selama dua tahun terakhir kami telah melihat pertumbuhan yang stabil pada penggunanya (berfokus pada bahasa Rusia dan Inggris): kami memiliki sekitar 50% instalasi dari AS, 20-30% dari Rusia. Secara keseluruhan, ini ternyata menjadi proyek open source yang cukup sukses.
Kami tidak hanya mengembangkan, tetapi juga mencoba berkontribusi pada agenda penelitian global tentang AI percakapan. Menyadari perlunya kompetisi akademik di bidang ini, kami meluncurkan seri Conversational AI Challenges sebagai bagian dari NeuIPS, konferensi pembelajaran mesin terkemuka.
Apalagi kami tidak hanya menyelenggarakan kompetisi, tapi juga berpartisipasi. Jadi, tim laboratorium kami tahun lalu ikut serta dalam kompetisi dari Amazon yang disebut Alexa Prize - membuat bot obrolan yang akan membuat orang tertarik untuk berbicara selama 20 menit.
Kompetisi berikutnya akan dimulai pada bulan November.
Ini adalah kompetisi universitas, dan pesertanya terdiri dari mahasiswa dan staf universitas. Ada total 350 tim, tujuh dipilih untuk teratas dan tiga diundang berdasarkan hasil tahun lalu - kami berhasil mencapai puncak.
Sistem dialog kami melakukan sekitar 100 ribu dialog dengan pengguna di Amerika Serikat dan pada akhirnya memiliki rating sekitar 3.35-3.4 dari 5, yang cukup bagus. Ini menunjukkan bahwa kami telah berhasil membentuk tim kelas dunia di MIPT dalam waktu yang cukup singkat.
Sekarang laboratorium sedang melaksanakan proyek dengan berbagai perusahaan, di antaranya yang besar adalah Huawei dan Sberbank. Proyek dalam arah yang berbeda: AutoML, teori jaringan saraf dan, tentu saja, arah utama kami - NLP.
- Tentang tugas-tugas yang dulunya sulit untuk pembelajaran mesin: mengapa pembelajaran mendalam berhasil memecahkan masalah ini?
- Sulit dikatakan. Sekarang saya akan menjelaskan intuisi saya dengan cara yang sedikit disederhanakan. Intinya adalah jika model memiliki banyak parameter, maka secara mengejutkan dapat menggeneralisasi hasil dengan baik ke data baru. Dalam artian banyaknya parameter bisa sepadan dengan banyaknya contoh. Untuk alasan yang sama, ML klasik telah lama menolak tekanan jaringan neural - tampaknya tidak ada hal baik yang muncul darinya dalam situasi ini.
Munculnya parameter dalam model pembelajaran yang dalam ( sumber )
Anehnya, ternyata tidak. Ivan Skorokhodov dari laboratorium kami menunjukkan ( .pdf ) bahwa hampir semua pola dua dimensi dapat ditemukan di ruang fungsi kehilangan jaringan saraf.
Anda dapat memilih bidang sedemikian rupa sehingga setiap titik pada bidang ini akan sesuai dengan satu set parameter jaringan neural. Dan kerugian mereka akan sesuai dengan pola yang berubah-ubah, dan, karenanya, Anda dapat mengambil jaringan saraf sedemikian rupa sehingga mereka akan jatuh langsung pada gambar ini.
Hasil yang sangat lucu. Ini menunjukkan bahwa bahkan dengan batasan yang tidak masuk akal seperti itu, jaringan saraf dapat mempelajari tugas yang diberikan padanya. Begitulah intuisi di sini, ya.

Contoh pola dari artikel oleh Ivan Skorokhodov
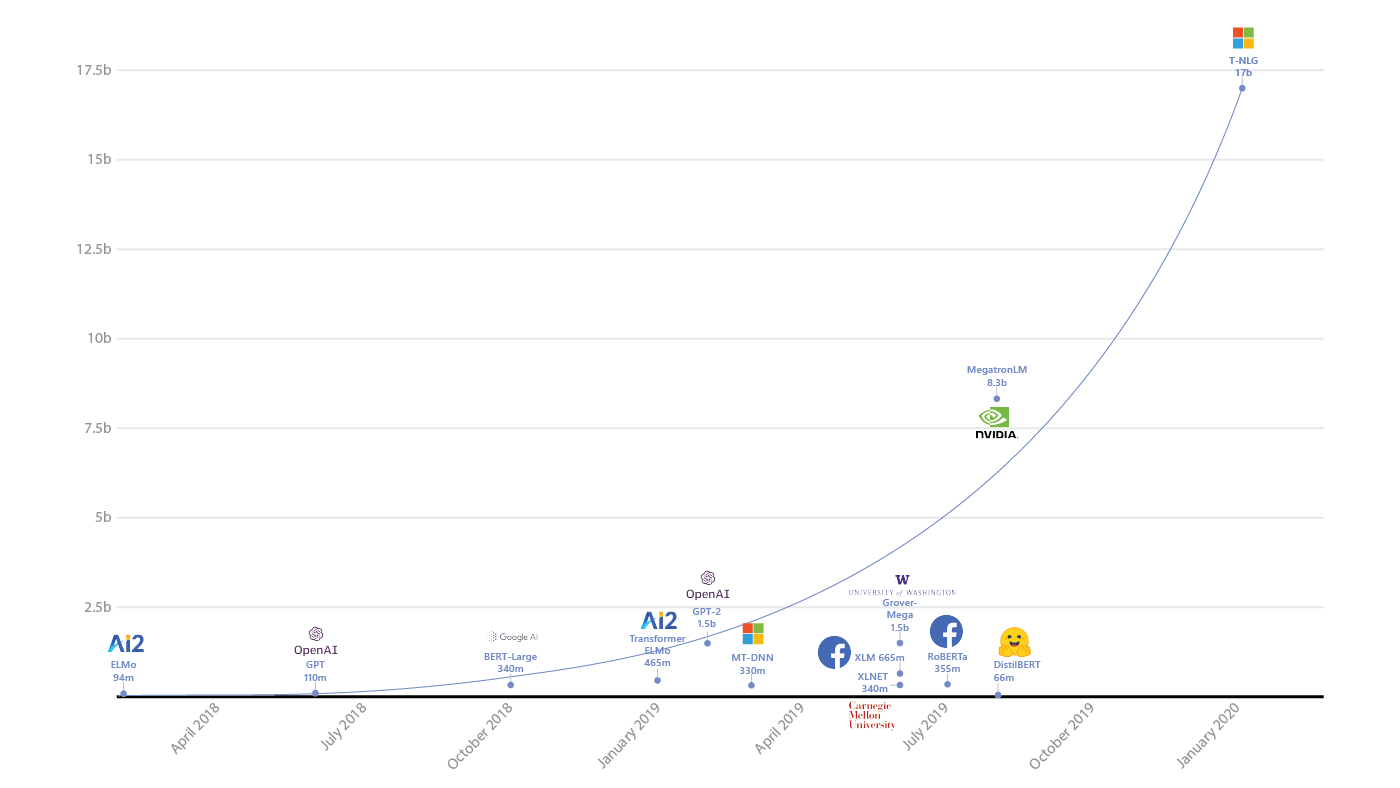
- Dalam beberapa tahun terakhir, kemajuan yang signifikan telah terlihat di bidang pembelajaran mendalam, tetapi apakah cakrawala sudah terlihat di mana kita akan mengubur diri dalam batas indikator?

Pertumbuhan ukuran model AI dan sumber daya yang mereka konsumsi (sumber: openai.com/blog/ai-and-compute/ )
- Di NLP kami, batasnya belum terasa, meskipun tampaknya, misalnya, dalam pembelajaran penguatan, sesuatu sudah dimulai tergelincir. Artinya, tidak ada perubahan kualitatif selama beberapa tahun terakhir. Ada ledakan besar dari Atari ke AlphaGo dengan hibridisasi dengan Pencarian Pohon Monte Carlo, tetapi sekarang tidak ada terobosan langsung.
Tetapi di NLP sebaliknya: jaringan berulang, jaringan konvolusional, dan akhirnya arsitektur transformator dan GPT itu sendiri ( salah satu model transformator terbaru dan paling menarik, sering digunakan untuk menghasilkan teks - catatan penulis) Apakah sudah merupakan perkembangan ekstensif murni. Dan kemudian tampaknya masih ada margin untuk mencapai sesuatu yang baru. Oleh karena itu, di NLP, bilah dari atas belum terlihat. Meskipun, tentu saja, hampir tidak mungkin untuk memprediksi apa pun di sini.
- Jika kita membayangkan pengembangan bahasa dan kerangka kerja untuk pembelajaran mesin, maka kita beralih dari menulis (bersyarat) dalam numpy murni, scikit-learn ke tensorflow, keras - tingkat abstraksi tumbuh. Apa selanjutnya untuk kita?
— , : - . , , low level high level code: numpy . , , NLP : .
- Tensorflow / Pytorch — : .
- : NLP- — DeepPavlov.
- : — DeepPavlov Dream .
- Sistem untuk beralih antar keterampilan / jalur pipa, termasuk Agen DeepPavlov kami.
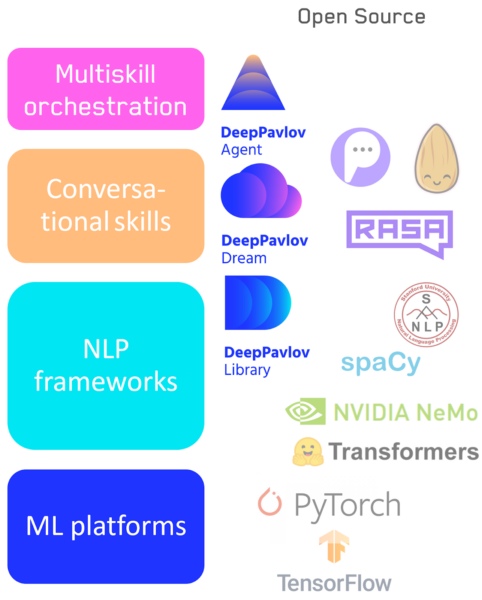
Tumpukan teknologi AI percakapan
Berbagai aplikasi dan tugas memerlukan fleksibilitas alat yang berbeda, dan oleh karena itu menurut saya elemen apa pun dari hierarki ini tidak akan hilang. Baik sistem tingkat rendah maupun tingkat tinggi akan berkembang sesuai kebutuhan. Misalnya, perpustakaan visual yang tidak tersedia untuk pemrogram, tetapi juga perpustakaan tingkat rendah untuk pengembang tidak akan kemana-mana.
- Apakah eksperimen sosial sekarang dilakukan dengan analogi dengan uji Turing klasik, di mana orang harus memahami apakah jaringan saraf ada di depan mereka atau seseorang?
- Eksperimen semacam itu dilakukan secara teratur. Dalam Alexa Challenge, seseorang harus menilai kualitas percakapan, sementara dia tidak tahu dengan siapa dia berbicara - bot atau orang. Sejauh ini, dari sudut pandang percakapan langsung, perbedaan antara mesin dan manusia itu signifikan, tetapi semakin menurun setiap tahun. Ngomong-ngomong, artikel kami tentang ini baru saja keluar di Majalah AI.
Di luar komunitas ilmiah, hal ini dilakukan secara rutin. Baru-baru ini, seseorang melatih model GPT, menyiapkan akun Twitter untuknya, dan mulai memposting tanggapan. Banyak orang mendaftar, akun tersebut mendapatkan popularitas, dan tidak ada yang tahu bahwa itu adalah jaringan saraf.
Format singkat seperti itu, seperti di Twitter, ketika formulasinya umum dan "mendalam", sangat cocok dengan sistem inferensi jaringan saraf.
- Area apa yang menurut Anda paling menjanjikan, di mana Anda mengharapkan lompatan?
- ( Tertawa ) Saya dapat mengatakan bahwa dalam penyatuan semua arah favorit saya lompatan itu akan terjadi. Saya akan mencoba menjelaskan lebih detail dalam kerangka problematisasi. Kami memiliki model GPT berbasis transformator saat ini - mereka tidak memiliki tujuan dalam hidup, mereka hanya menghasilkan teks seperti manusia, sama sekali tanpa tujuan. Dan mereka tidak bisa mengaitkannya dengan situasi dan tujuan dalam konteks dunia itu sendiri.
Dan salah satu caranya adalah dengan membuat pengikatan pandangan logis dunia ke GPT, yang telah membaca banyak, banyak teks, dan di dalamnya, memang, sudah ada banyak koneksi logis. Misalnya, melalui hibridisasi dengan Wikidata (ini adalah grafik yang menjelaskan pengetahuan tentang dunia, di atasnya terdapat artikel Wikipedia).
Jika kita bisa menghubungkan keduanya sehingga GPT bisa menggunakan basis pengetahuan, itu akan menjadi lompatan ke depan.
Pendekatan kedua untuk masalah tanpa tujuan model NLP didasarkan pada integrasi pemahaman tujuan manusia ke dalamnya. Jika kita memiliki model yang dapat menggerakkan model bahasa generatif yang dikaitkan dengan grafik pengetahuan, maka kita dapat melatihnya untuk membantu seseorang mencapai tujuan mereka. Dan asisten seperti itu harus memahami orang tersebut melalui NLP, dan tujuan orang tersebut, dan situasinya - kemudian dia perlu merencanakan tindakan. Dan dalam perencanaan, pembelajaran penguatan bekerja paling baik.
Bagaimana menggabungkan dan mengoptimalkan semua ini adalah pertanyaan terbuka.
Dan yang terakhir adalah pencarian arsitektur neural network. Saat, misalnya, menggunakan pendekatan evolusioner, kita mencari ruang arsitektur yang optimal untuk tugas tertentu. Tetapi semua ini tidak akan diputuskan hari ini - ada terlalu banyak ruang untuk pencarian.
Dari kabar baik: perangkat keras berkembang sangat cepat dan, mungkin, ini akan memungkinkan kita dalam 5-10 tahun untuk menggabungkan model bahasa jaringan saraf, grafik pengetahuan, dan pembelajaran penguatan. Dan kemudian kita akan memiliki lompatan kuantum dalam pemahaman mesin tentang manusia.
Dengan bantuan asisten seperti itu, dimungkinkan untuk meluncurkan solusi tugas lain: analisis gambar, analisis catatan medis atau situasi ekonomi, pemilihan barang.
Oleh karena itu, saya akan mengatakan bahwa dari sudut pandang ilmiah, dalam lima tahun ke depan kita akan melihat perkembangan pesat di bidang hibridisasi - ada banyak tugas keren.
Teman-teman, kekurangan staf akan sangat besar, dan ada peluang besar untuk mendapatkan hasil yang baru dan menarik, dan juga untuk mempengaruhi perkembangan industri. Terhubung - Anda perlu memanfaatkan momen!( Penulis secara aktif mendukung jawaban ini, karena dia hanya berurusan dengan sistem seperti itu. )
- Bagaimana cara mulai mendalami pembelajaran mendalam?
- Cara termudah, menurut saya, adalah dengan mengambil kursus di deep learning school : awalnya ditujukan untuk siswa sekolah menengah, tetapi akan sangat cocok untuk siswa. Secara umum, ini adalah usaha yang bagus, saya membantu dengan penjadwalan dan memberikan kuliah pengantar di sana.
Saya juga merekomendasikan menonton kursus pengantar dari universitas, melakukan tugas - ada banyak hal di Internet. Alat terbaik untuk "bermain" adalah Colab dari Google, ada jutaan contoh tugas, Anda dapat mengetahuinya dan menjalankan solusi paling modern - tanpa menginstal perangkat lunak apa pun di komputer Anda sama sekali.
Cara lain adalah dengan bersaing di Kaggle. Dan juga bergabunglah dengan Open Data Science - komunitas berbahasa Rusia untuk Data Science, di mana terdapat beberapa saluran pembelajaran mendalam. Selalu ada orang di sana yang siap membantu dengan saran dan kode.
Ini adalah cara utama.
Leader-ID : friends, untuk pilihan akselerator promosi proyek AI yang sekarang diluncurkan , kami telah memikirkan opsi login untuk developer indie. Tidak, ini tidak mengubah kondisi dasar di mana hanya tim yang berpartisipasi secara intensif. Tetapi kami memiliki banyak pertanyaan dari individu yang tidak memiliki proyek sendiri sekarang, tetapi ingin berpartisipasi (dan ini bukan hanya programmer, desainer memiliki minat yang besar pada proyek AI). Dan kami menemukan solusinya: kami akan membantu mengumpulkan tim dan orang-orang yang berpikiran sama melalui hackathon online gratis . Ini akan dimulai pada 10 Oktober pukul 12:00 dan akan berakhir tepat satu hari kemudian. Di atasnya, bot akan mendistribusikan Anda ke dalam tim, dan kemudian, di bawah kepemimpinannya, Anda akan melalui tahapan utama pengembangan proyek dan mengirimkannya ke Archipelago 20.35. Semua detail ada di akun pribadi Anda, Anda hanya perlu mendaftar tepat waktu.