
Dunia kita menghasilkan lebih banyak informasi. Beberapa bagian darinya cepat berlalu dan hilang secepat dikumpulkan. Yang lain harus disimpan lebih lama, sementara yang lain dirancang "selama berabad-abad" - setidaknya begitulah cara kita melihatnya dari sekarang. Arus informasi mengendap di pusat data dengan kecepatan sedemikian rupa sehingga pendekatan baru apa pun, teknologi apa pun yang dirancang untuk memenuhi "permintaan" yang tak ada habisnya ini dengan cepat menjadi usang.
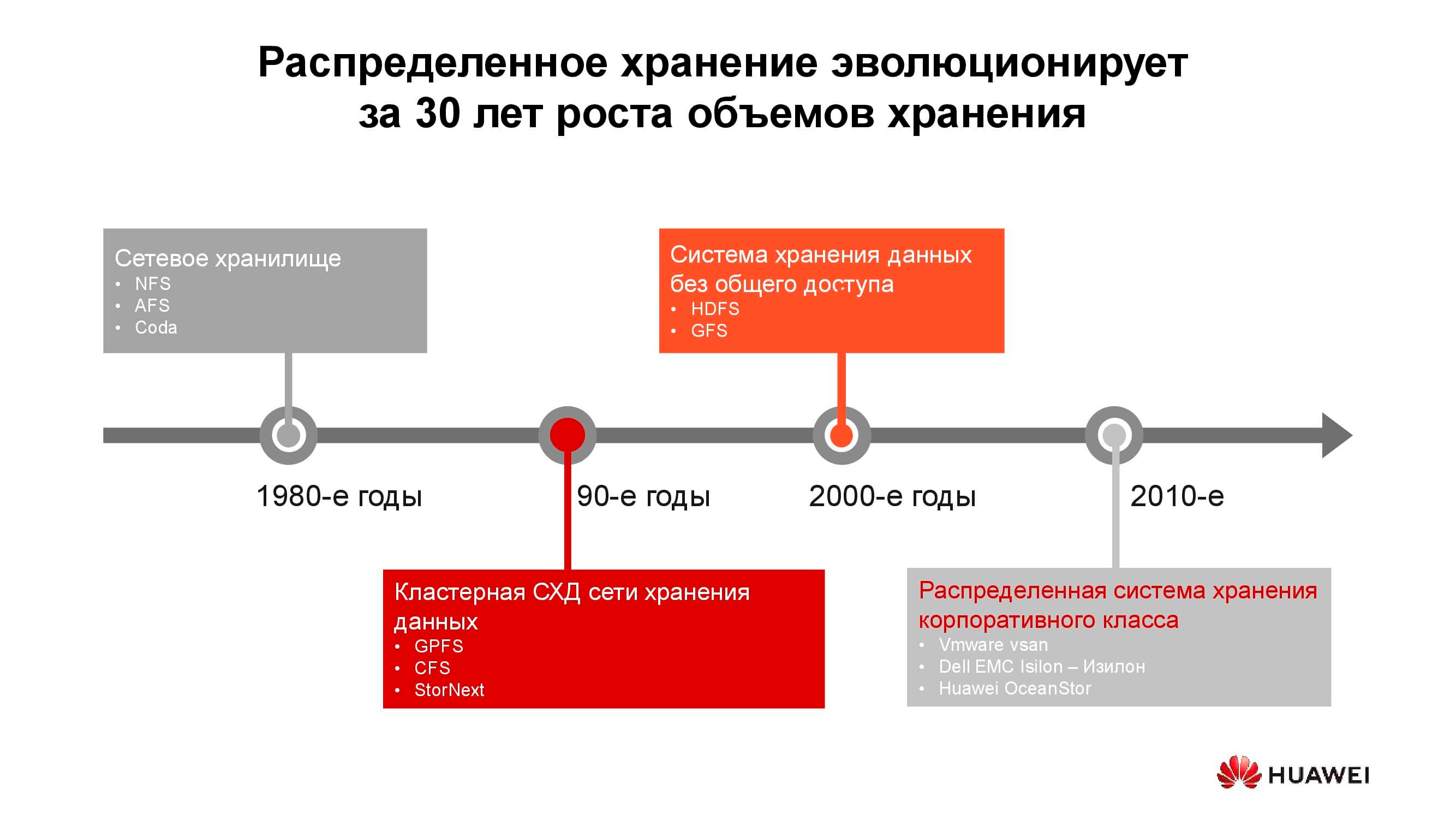
40 tahun pengembangan sistem penyimpanan terdistribusi
Penyimpanan terlampir jaringan pertama muncul dalam bentuk biasa pada 1980-an. Banyak dari Anda telah menemukan NFS (Network File System), AFS (Andrew File System) atau Coda. Satu dekade kemudian, mode dan teknologi telah berubah, dan sistem file terdistribusi telah digantikan oleh sistem penyimpanan berkerumun berdasarkan GPFS (General Parallel File System), CFS (Clustered File Systems) dan StorNext. Sebagai dasar, penyimpanan blok dari arsitektur klasik digunakan, di atasnya satu sistem file dibuat menggunakan lapisan perangkat lunak. Solusi ini dan yang serupa masih digunakan, menempati ceruknya sendiri, dan cukup diminati.
Pada pergantian milenium, paradigma penyimpanan terdistribusi telah agak berubah, dan sistem dengan arsitektur SN (Shared-Nothing) memimpin. Ada transisi dari penyimpanan cluster ke penyimpanan pada node terpisah, yang, biasanya, merupakan server klasik dengan perangkat lunak yang menyediakan penyimpanan yang andal; pada prinsip-prinsip tersebut dibangun, katakanlah, HDFS (Hadoop Distributed File System) dan GFS (Global File System).
Mendekati tahun 2010-an, konsep dasar penyimpanan terdistribusi semakin tercermin dalam produk komersial lengkap seperti VMware vSAN, Dell EMC Isilon, dan Huawei OceanStor kami.... Di balik platform yang disebutkan bukan lagi komunitas peminat, tetapi vendor khusus yang bertanggung jawab atas fungsionalitas, dukungan, layanan produk, dan menjamin pengembangan lebih lanjut. Solusi semacam itu paling diminati di beberapa bidang.
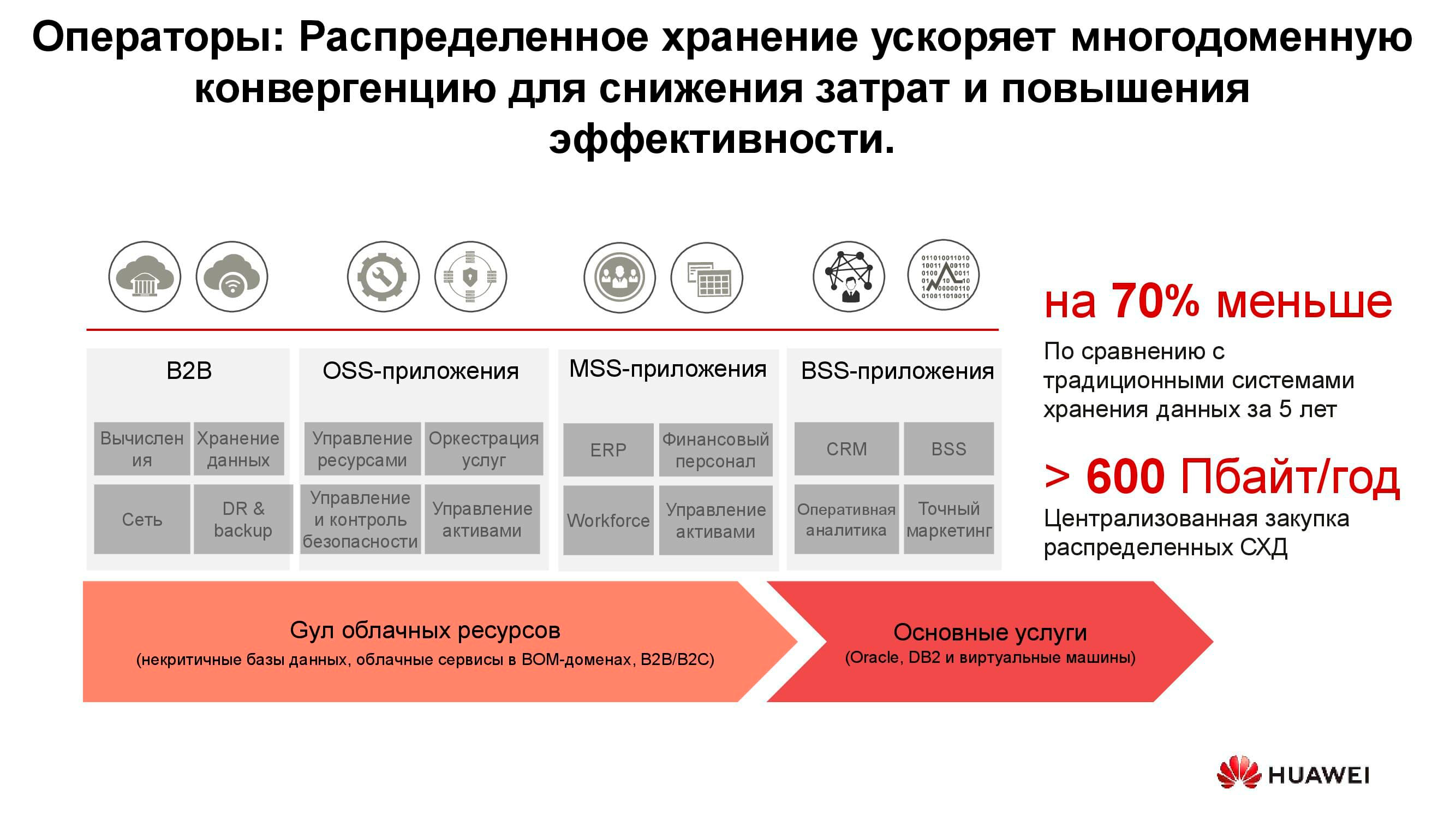
Operator telekomunikasi
Mungkin salah satu konsumen tertua dari sistem penyimpanan terdistribusi adalah operator telekomunikasi. Diagram menunjukkan grup aplikasi mana yang menghasilkan sebagian besar data. OSS (Sistem Dukungan Operasi), MSS (Layanan Dukungan Manajemen) dan BSS (Sistem Dukungan Bisnis) adalah tiga lapisan perangkat lunak pelengkap yang diperlukan untuk memberikan layanan kepada pelanggan, pelaporan keuangan kepada penyedia, dan dukungan operasional kepada para insinyur operator.
Seringkali, data dari lapisan ini sangat bercampur satu sama lain, dan untuk menghindari akumulasi salinan yang tidak perlu, penyimpanan terdistribusi digunakan, yang mengakumulasi seluruh jumlah informasi yang datang dari jaringan kerja. Penyimpanan digabungkan menjadi kumpulan umum, yang dirujuk oleh semua layanan.
Perhitungan kami menunjukkan bahwa transisi dari sistem penyimpanan klasik ke sistem penyimpanan blok memungkinkan Anda menghemat hingga 70% dari anggaran hanya karena pengabaian sistem penyimpanan kelas atas khusus dan penggunaan server konvensional dengan arsitektur klasik (biasanya x86), yang bekerja bersama dengan perangkat lunak khusus. Operator seluler telah lama mulai membeli solusi semacam itu dalam volume yang serius. Secara khusus, operator Rusia telah menggunakan produk semacam itu dari Huawei selama lebih dari enam tahun.
Ya, sejumlah tugas tidak dapat dilakukan menggunakan sistem terdistribusi. Misalnya, dengan peningkatan persyaratan kinerja atau kompatibilitas dengan protokol yang lebih lama. Tetapi setidaknya 70% dari data yang diproses oleh operator dapat ditempatkan di kumpulan terdistribusi.
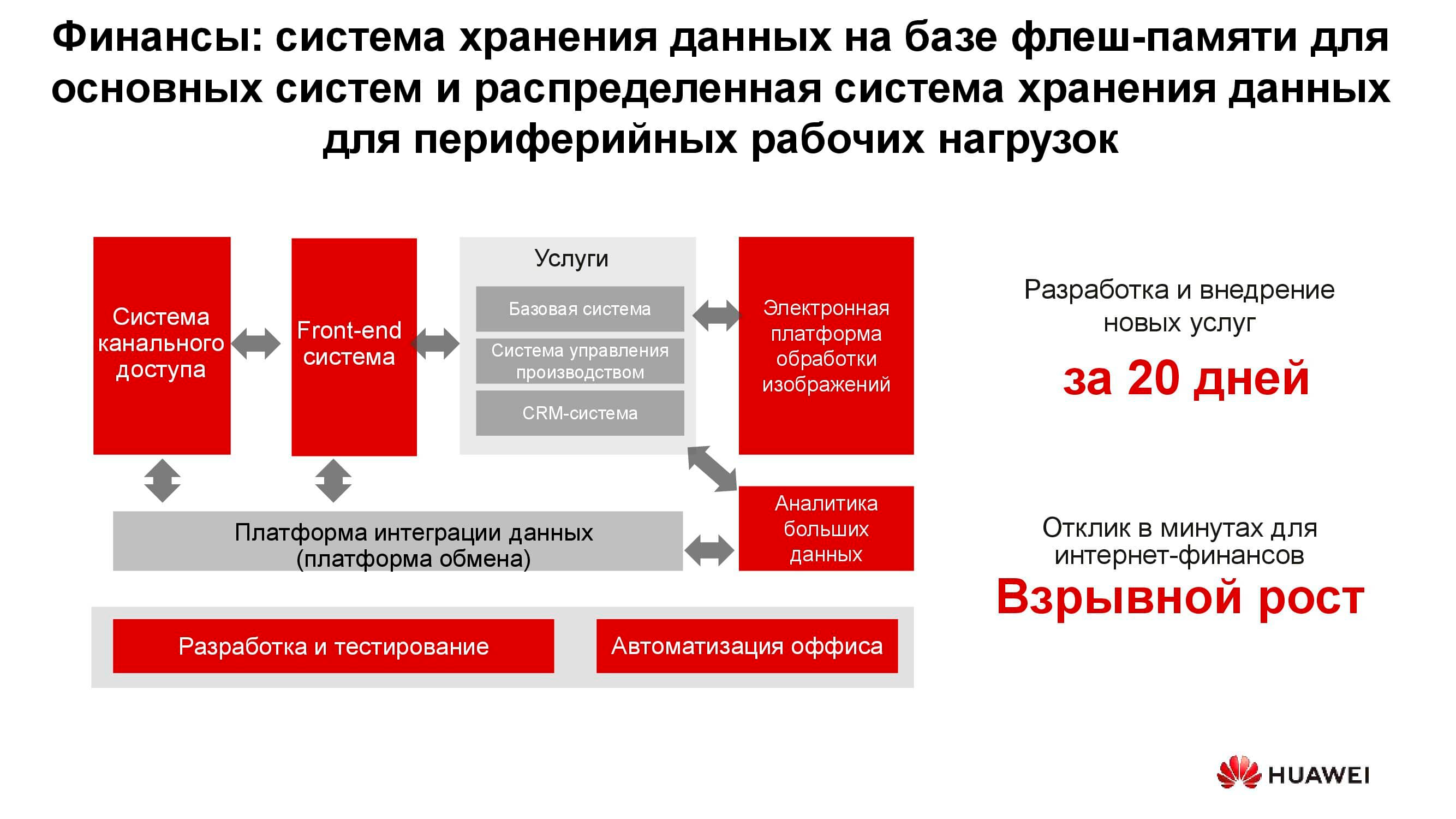
Sektor perbankan
Di bank mana pun, terdapat banyak sistem TI yang berbeda, dari pemrosesan hingga sistem perbankan otomatis. Infrastruktur ini juga bekerja dengan sejumlah besar informasi, sementara sebagian besar tugas tidak memerlukan peningkatan kinerja dan keandalan sistem penyimpanan, misalnya, pengembangan, pengujian, otomatisasi proses kantor, dll. Di sini, penggunaan sistem penyimpanan klasik dimungkinkan, tetapi setiap tahun semakin kurang menguntungkan. Selain itu, dalam hal ini, tidak ada fleksibilitas dalam penggunaan sumber daya penyimpanan, yang kinerjanya dihitung dari beban puncak.
Saat menggunakan sistem penyimpanan terdistribusi, node mereka, yang sebenarnya adalah server biasa, dapat diubah kapan saja, misalnya, menjadi server farm dan digunakan sebagai platform komputasi.
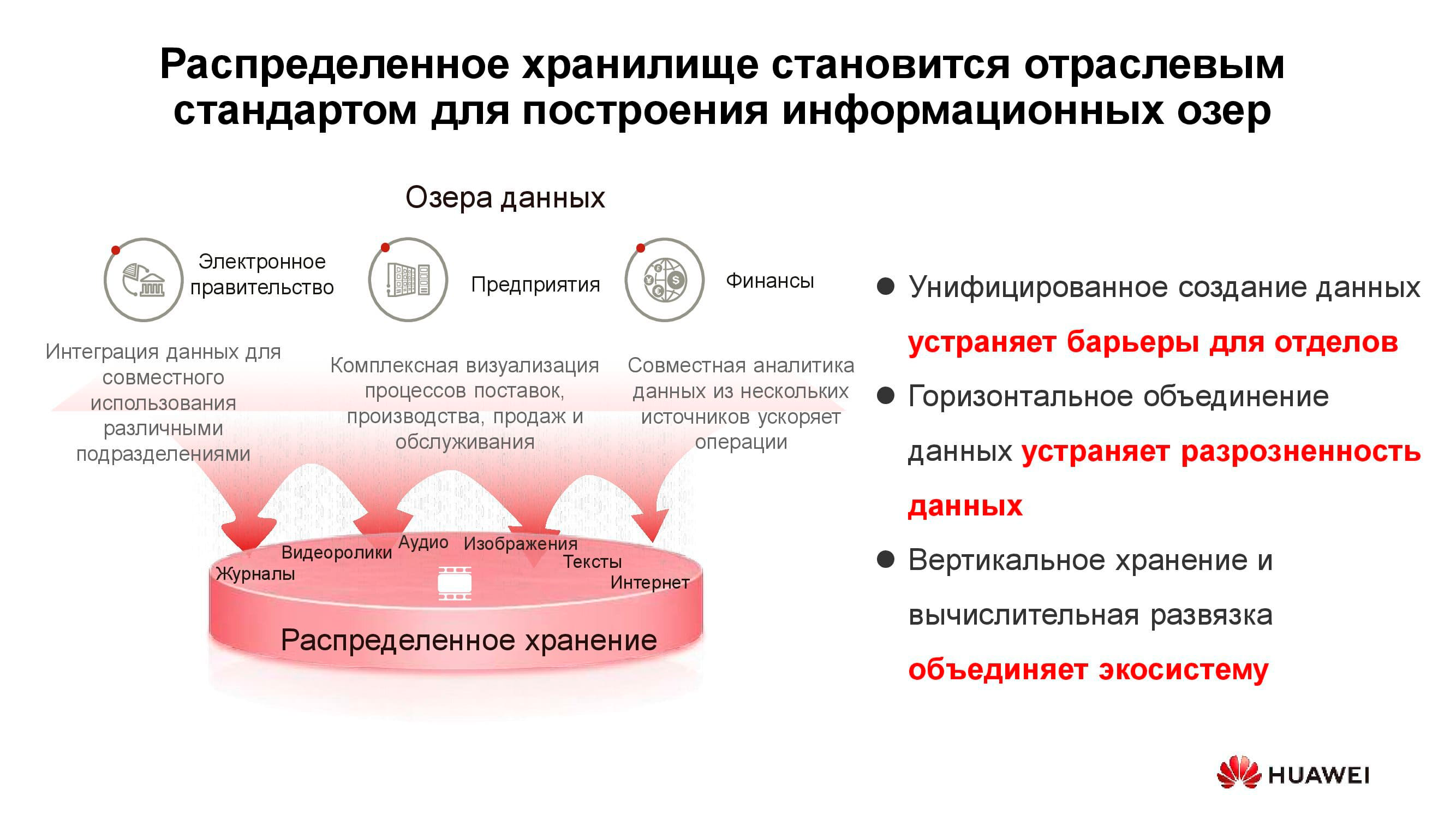
Danau data
Diagram di atas menunjukkan daftar konsumen tipikal layanan data lake . Ini bisa berupa layanan e-government (misalnya, "Gosuslugi"), perusahaan digital, struktur keuangan, dll. Mereka semua perlu bekerja dengan informasi heterogen dalam jumlah besar.
Pengoperasian sistem penyimpanan klasik untuk memecahkan masalah semacam itu tidak efektif, karena diperlukan akses kinerja tinggi untuk memblokir database dan akses reguler ke pustaka dokumen yang dipindai yang disimpan sebagai objek. Misalnya, sistem pemesanan melalui portal web dapat ditautkan di sini. Untuk mengimplementasikan semua ini pada platform penyimpanan klasik, Anda akan membutuhkan banyak peralatan untuk berbagai tugas. Satu sistem penyimpanan universal horizontal mungkin mencakup semua tugas yang terdaftar sebelumnya: Anda hanya perlu membuat beberapa kumpulan di dalamnya dengan karakteristik penyimpanan yang berbeda.

Generator informasi baru
Jumlah informasi yang disimpan di dunia tumbuh sekitar 30% per tahun. Ini adalah kabar baik bagi vendor penyimpanan, tetapi apa yang menjadi dan akan menjadi sumber utama data ini?
Sepuluh tahun yang lalu, jejaring sosial menjadi generator seperti itu, yang membutuhkan pembuatan sejumlah besar algoritme baru, solusi perangkat keras, dll. Sekarang ada tiga pendorong utama pertumbuhan volume penyimpanan. Yang pertama adalah komputasi awan. Saat ini, sekitar 70% perusahaan menggunakan layanan cloud dengan satu atau lain cara. Ini bisa berupa sistem email, backup, dan entitas virtual lainnya.
Penggerak kedua adalah jaringan generasi kelima. Ini adalah kecepatan baru dan volume baru transfer data. Kami memperkirakan adopsi 5G yang meluas akan menyebabkan penurunan permintaan untuk kartu memori flash. Tidak peduli berapa banyak memori yang ada di telepon, itu tetap habis, dan jika ada saluran 100 megabit di gadget, tidak perlu menyimpan foto secara lokal.
Kelompok ketiga alasan meningkatnya permintaan untuk sistem penyimpanan termasuk perkembangan pesat kecerdasan buatan, transisi ke analitik data besar dan tren otomatisasi universal dari segala sesuatu yang mungkin dilakukan.
Salah satu fitur dari "lalu lintas baru" adalah ketidakstrukturnya... Kami perlu menyimpan data ini tanpa menentukan formatnya. Ini hanya diperlukan untuk bacaan berikutnya. Misalnya, sistem penilaian perbankan untuk menentukan jumlah pinjaman yang tersedia akan melihat foto yang Anda posting di jejaring sosial, menentukan apakah Anda sering mengunjungi laut dan restoran, dan pada saat yang sama mempelajari kutipan dari dokumen medis Anda yang tersedia untuk itu. Data ini, di satu sisi, mencakup semuanya, dan di sisi lain, kurang dalam keseragaman.

Lautan data yang tidak terstruktur
Masalah apa yang ditimbulkan oleh munculnya "data baru"? Yang terpenting di antara mereka, tentu saja, adalah jumlah informasi itu sendiri dan perkiraan waktu penyimpanan. Mobil otonom modern tanpa pengemudi sendiri menghasilkan hingga 60 TB data setiap hari dari semua sensor dan mekanismenya. Untuk mengembangkan algoritme gerakan baru, informasi ini harus diproses dalam hari yang sama, jika tidak maka akan mulai terakumulasi. Apalagi harus disimpan untuk waktu yang sangat lama - puluhan tahun. Hanya dengan demikian di masa depan dimungkinkan untuk menarik kesimpulan berdasarkan sampel analitik yang besar.
Perangkat pengurutan genetik tunggal menghasilkan sekitar 6 TB per hari. Dan data yang dikumpulkan dengan bantuannya tidak menyiratkan penghapusan sama sekali, artinya, secara hipotetis, itu harus disimpan selamanya.
Akhirnya, semua jaringan generasi kelima sama. Selain informasi yang ditransmisikan secara aktual, jaringan semacam itu sendiri merupakan generator data yang sangat besar: log tindakan, catatan panggilan, hasil perantara dari interaksi mesin-ke-mesin, dll.
Semua ini memerlukan pengembangan pendekatan dan algoritme baru untuk menyimpan dan memproses informasi. Dan pendekatan seperti itu muncul.
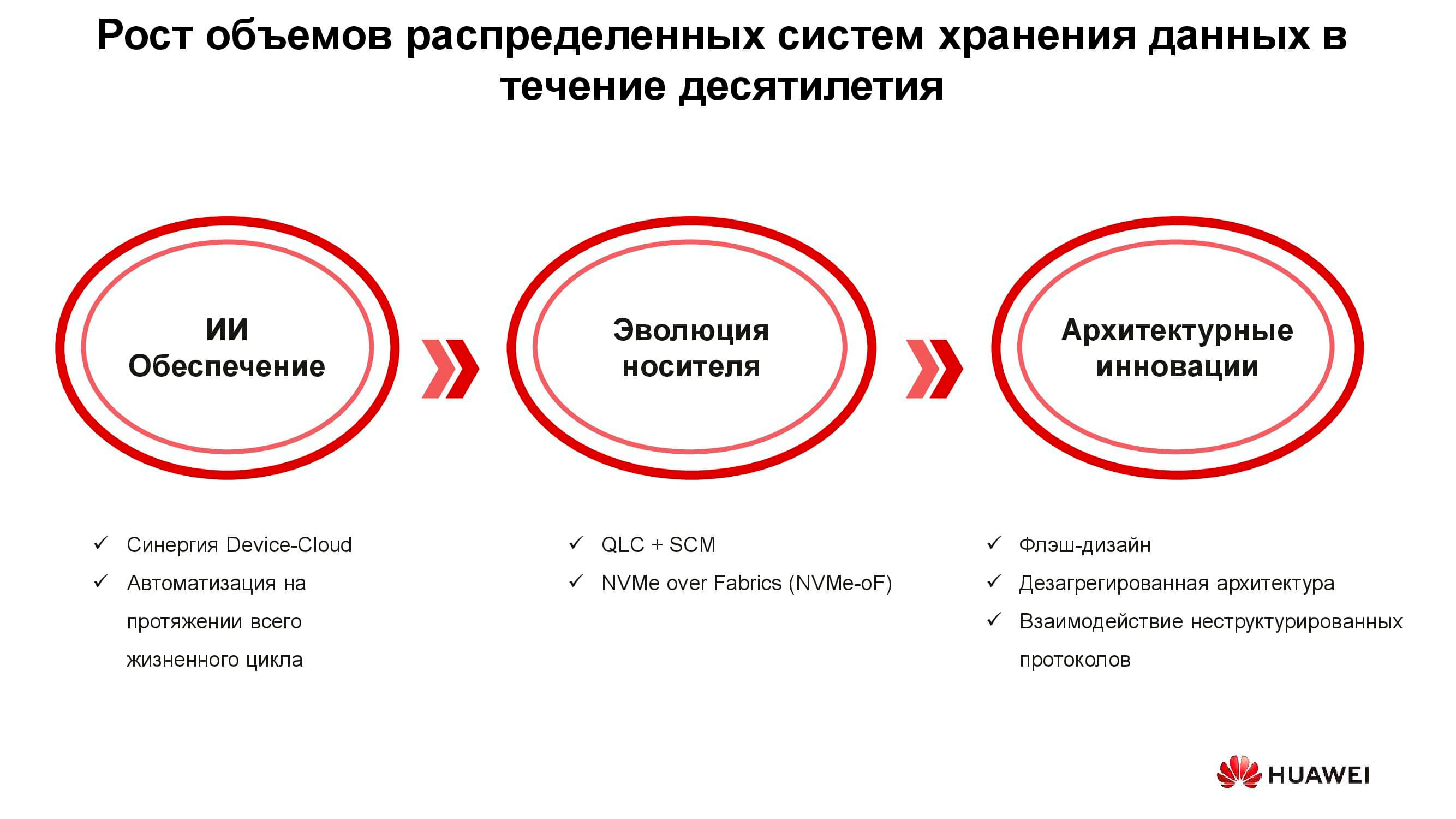
Teknologi era baru
Ada tiga kelompok solusi yang dirancang untuk mengatasi persyaratan baru untuk sistem penyimpanan: pengenalan kecerdasan buatan, evolusi teknis media penyimpanan, dan inovasi di bidang arsitektur sistem. Mari kita mulai dengan AI.

Dalam solusi baru Huawei, kecerdasan buatan sudah digunakan di tingkat penyimpanan itu sendiri, yang dilengkapi dengan prosesor AI yang memungkinkan sistem untuk menganalisis statusnya secara independen dan memprediksi kegagalan. Jika sistem penyimpanan terhubung ke cloud layanan yang memiliki kemampuan komputasi yang signifikan, kecerdasan buatan dapat memproses lebih banyak informasi dan meningkatkan keakuratan hipotesisnya.
Selain kegagalan, AI tersebut mampu memprediksi beban puncak di masa mendatang dan waktu yang tersisa hingga kapasitas habis. Ini memungkinkan Anda untuk mengoptimalkan kinerja dan menskalakan sistem bahkan sebelum peristiwa yang tidak diinginkan terjadi.

Sekarang tentang evolusi pembawa data. Flash drive pertama dibuat dengan menggunakan teknologi SLC (Single-Level Cell). Perangkat yang didasarkan padanya cepat, andal, stabil, tetapi memiliki kapasitas kecil dan sangat mahal. Peningkatan volume dan penurunan harga dicapai melalui konsesi teknis tertentu, yang karenanya kecepatan, keandalan, dan masa pakai hard disk berkurang. Namun demikian, tren tersebut tidak mempengaruhi sistem penyimpanan itu sendiri, yang, karena berbagai trik arsitektur, secara umum menjadi lebih produktif dan lebih dapat diandalkan.
Tetapi mengapa Anda membutuhkan sistem penyimpanan Semua-Flash? Bukankah cukup hanya dengan mengganti HDD lama dalam sistem yang sudah digunakan dengan SSD baru dengan faktor bentuk yang sama? Diperlukan ini untuk menggunakan semua sumber daya solid-state drive baru secara efisien, yang tidak mungkin dilakukan di sistem lama.
Huawei, misalnya, telah mengembangkan berbagai teknologi untuk mengatasi tantangan ini, salah satunya adalah FlashLink , yang memaksimalkan interaksi pengontrol disk.
Identifikasi cerdas memungkinkan penguraian data menjadi beberapa aliran dan mengatasi sejumlah fenomena yang tidak diinginkan seperti WA (tulis amplifikasi). Pada saat yang sama, algoritma pemulihan baru, khususnya RAID 2.0+, meningkatkan kecepatan rekondisi, mengurangi waktunya menjadi nilai yang sama sekali tidak signifikan.
Kegagalan, kepadatan berlebih, "pengumpulan sampah" - faktor-faktor ini juga tidak lagi memengaruhi kinerja sistem penyimpanan berkat modifikasi khusus dari pengontrol.
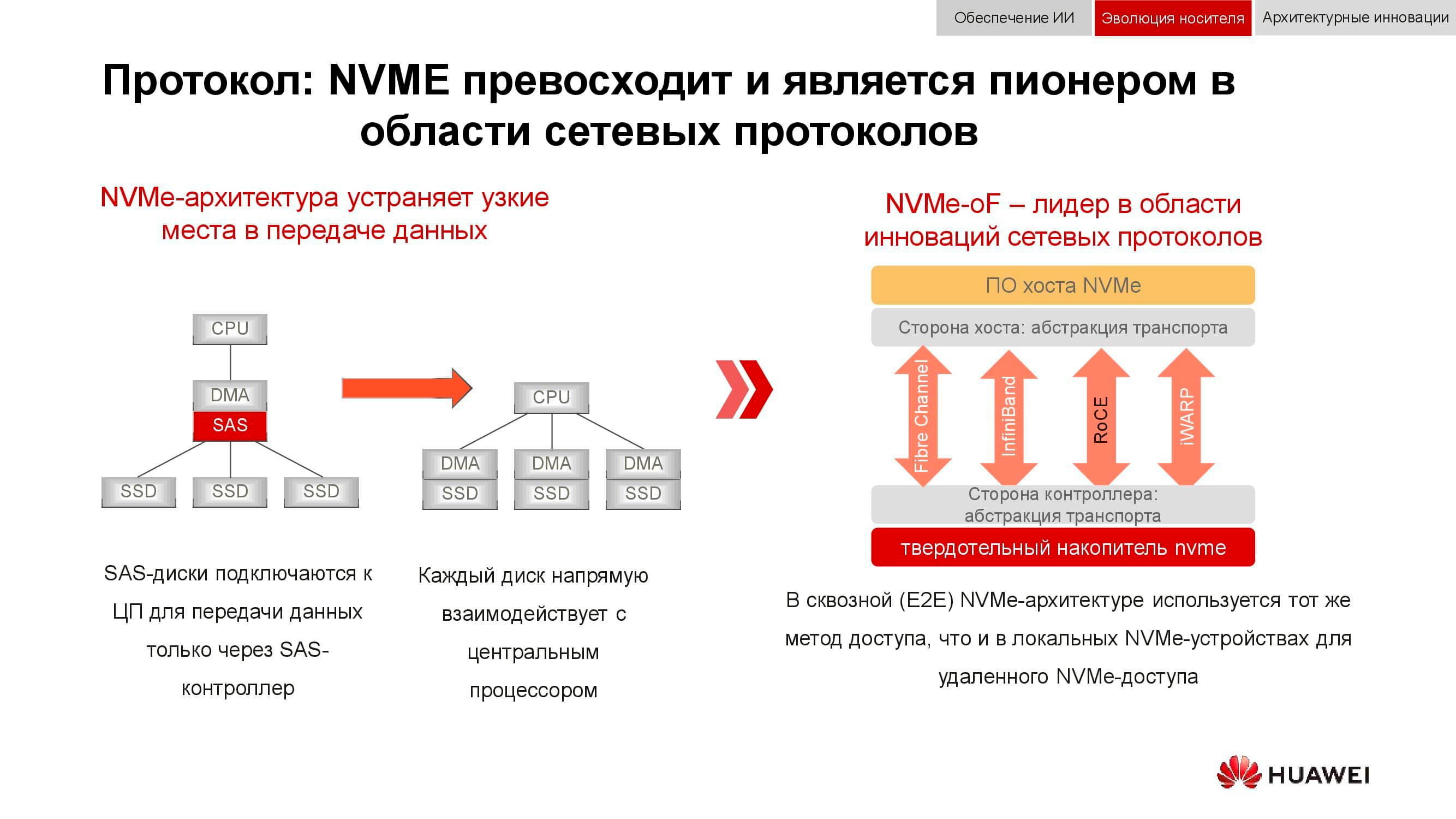
Dan blok penyimpanan data bersiap-siap untuk bertemu NVMe . Ingatlah bahwa skema klasik untuk mengatur akses data bekerja sebagai berikut: prosesor mengakses pengontrol RAID melalui bus PCI Express. Itu, pada gilirannya, berinteraksi dengan disk mekanis melalui SCSI atau SAS. Penggunaan NVMe di bagian belakang secara signifikan mempercepat keseluruhan proses, tetapi ada satu kelemahan: drive harus terhubung langsung ke prosesor untuk menyediakan akses langsung ke memori.
Fase perkembangan teknologi berikutnya yang kami lihat sekarang adalah penggunaan NVMe-oF (NVMe over Fabrics). Sedangkan untuk teknologi blok Huawei, mereka sudah mendukung FC-NVMe (NVMe over Fibre Channel), dan pada pendekatan NVMe over RoCE (RDMA over Converged Ethernet). Model uji cukup fungsional, beberapa bulan tersisa sebelum presentasi resmi mereka. Perhatikan bahwa semua ini juga akan muncul dalam sistem terdistribusi, di mana "Ethernet lossless" akan sangat diminati.
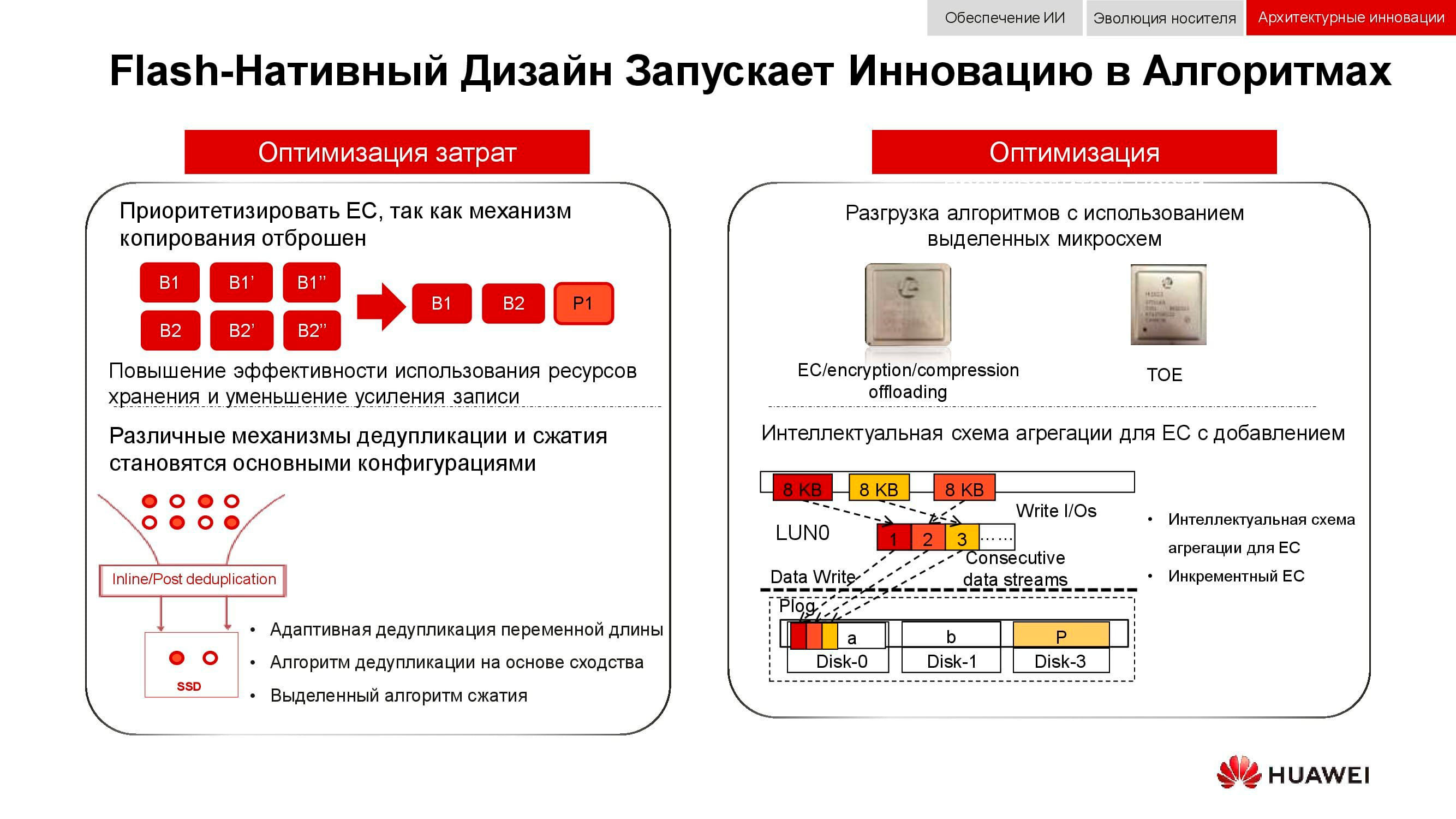
Cara tambahan untuk mengoptimalkan pekerjaan penyimpanan terdistribusi adalah penolakan total terhadap pencerminan data. Solusi Huawei tidak lagi menggunakan n salinan, seperti pada RAID 1 biasa, dan sepenuhnya beralih ke mekanisme EC(Hapus coding). Paket matematika khusus dengan frekuensi tertentu menghitung blok kontrol yang memungkinkan Anda memulihkan data perantara jika terjadi kehilangan.
Mekanisme deduplikasi dan kompresi menjadi wajib. Jika dalam sistem penyimpanan klasik kami dibatasi oleh jumlah prosesor yang dipasang di pengontrol, maka dalam sistem penyimpanan skala-keluar terdistribusi, setiap node berisi semua yang Anda butuhkan: disk, memori, prosesor, dan interkoneksi. Sumber daya ini cukup untuk deduplikasi dan kompresi agar memiliki dampak kinerja yang minimal.
Dan tentang metode pengoptimalan perangkat keras. Di sini, dimungkinkan untuk mengurangi beban pada prosesor pusat dengan bantuan sirkuit mikro khusus tambahan (atau blok khusus dalam prosesor itu sendiri), yang memainkan peran TOE(TCP / IP Offload Engine) atau mengambil alih masalah matematika EC, deduplikasi dan kompresi.
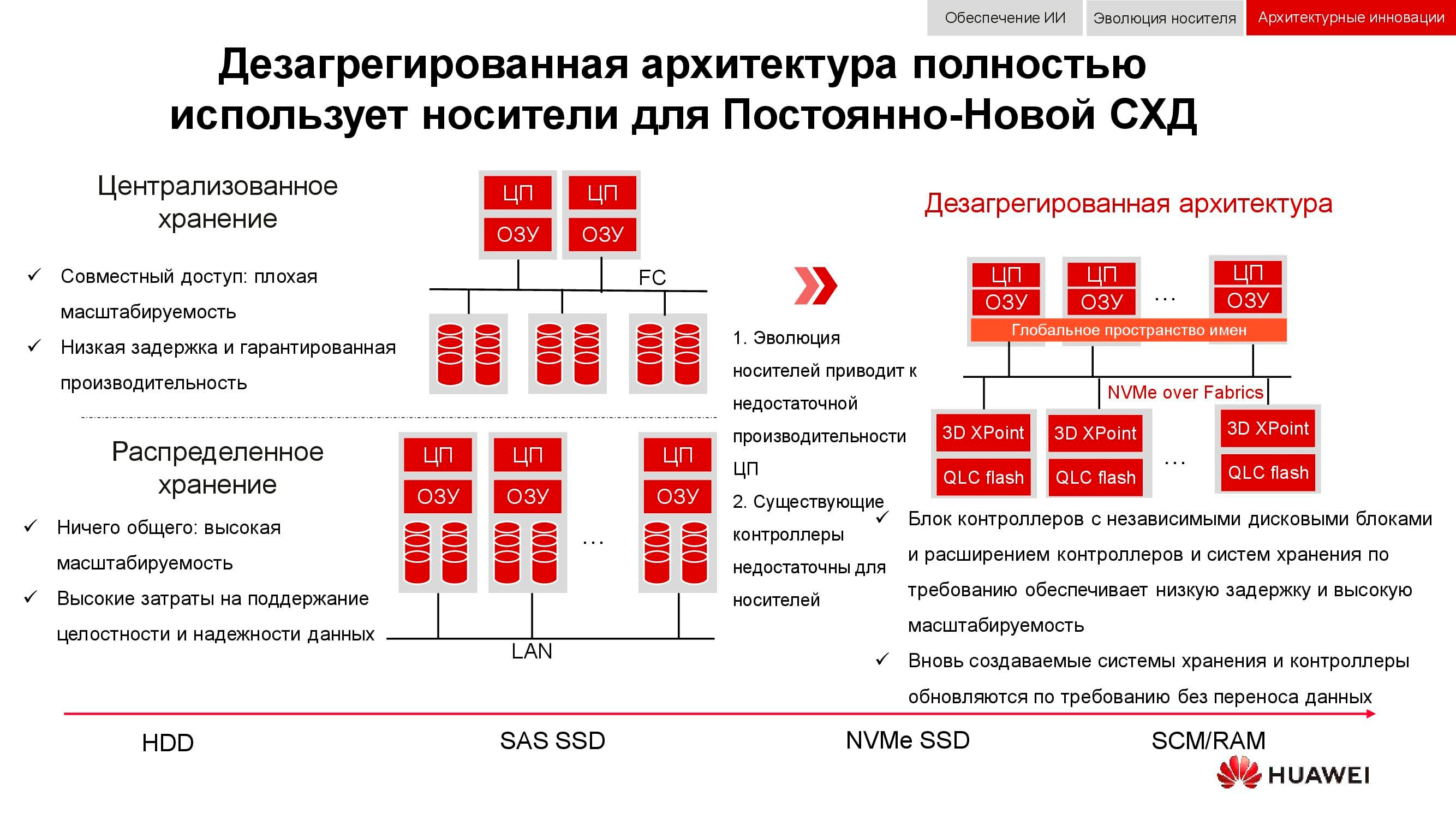
Pendekatan baru untuk penyimpanan data diwujudkan dalam arsitektur terpilah (terdistribusi). Dalam sistem penyimpanan terpusat, ada pabrik server yang terhubung melalui Fibre Channel ke SAN dengan jumlah array yang besar. Kerugian dari pendekatan ini adalah kesulitan dalam penskalaan dan memberikan tingkat layanan yang terjamin (kinerja atau latensi). Sistem hyper-converged menggunakan host yang sama untuk menyimpan dan memproses informasi. Ini memberikan skalabilitas yang hampir tidak terbatas, tetapi memerlukan biaya tinggi untuk menjaga integritas data.
Berbeda dengan kedua hal di atas, arsitektur terpilah menyiratkan pemisahan sistem menjadi kain komputasi dan sistem penyimpanan horizontal . Hal ini memberikan manfaat dari kedua arsitektur dan memungkinkan Anda untuk menskalakan hampir tanpa batas waktu hanya untuk elemen yang tidak memiliki performa.
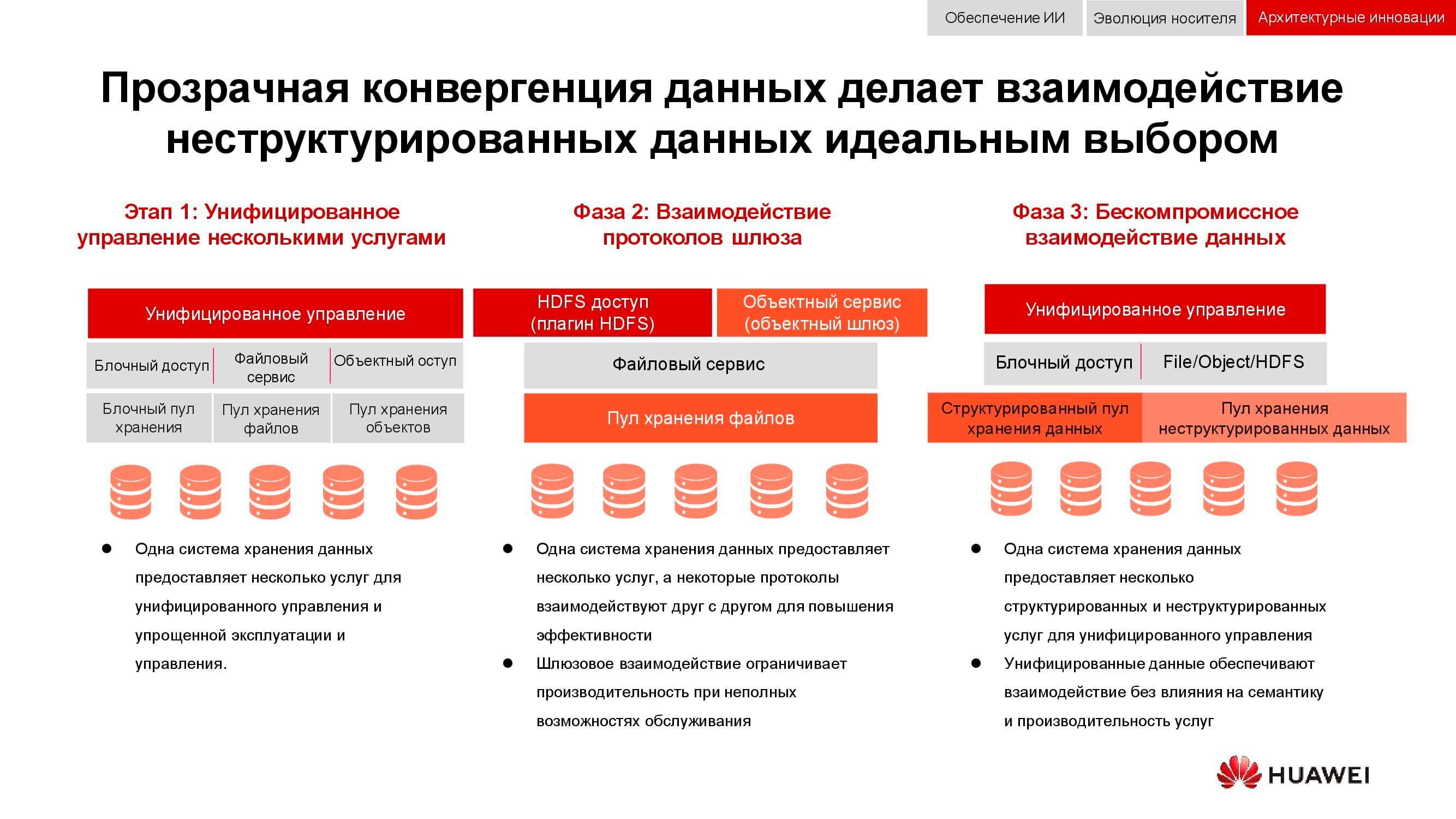
Dari integrasi hingga konvergensi
Tugas klasik, yang relevansinya hanya tumbuh selama 15 tahun terakhir, adalah kebutuhan untuk secara bersamaan menyediakan penyimpanan blok, akses file, akses ke objek, operasi pertanian untuk data besar, dll. Ceri pada kue juga dapat, misalnya, sistem cadangan untuk pita magnetik.
Pada tahap pertama, hanya mungkin untuk menyatukan manajemen layanan ini. Sistem penyimpanan data heterogen dikunci ke dalam beberapa perangkat lunak khusus, di mana administrator mengalokasikan sumber daya dari kumpulan yang tersedia. Tetapi karena kumpulan ini berbeda dalam perangkat keras, migrasi beban di antara mereka tidak mungkin dilakukan. Pada tingkat integrasi yang lebih tinggi, konsolidasi terjadi pada tingkat gateway. Dengan akses file bersama, itu dapat dikirim melalui protokol yang berbeda.
Metode konvergensi paling canggih yang tersedia bagi kita sekarang melibatkan penciptaan sistem hibrida universal. Persis seperti apa OceanStor 100D kita seharusnya . Aksesibilitas menggunakan sumber daya perangkat keras yang sama, secara logis dibagi ke dalam kumpulan berbeda, tetapi memungkinkan migrasi beban kerja. Semua ini dapat dilakukan melalui satu konsol manajemen. Dengan cara ini, kami berhasil menerapkan konsep "satu pusat data - satu sistem penyimpanan".
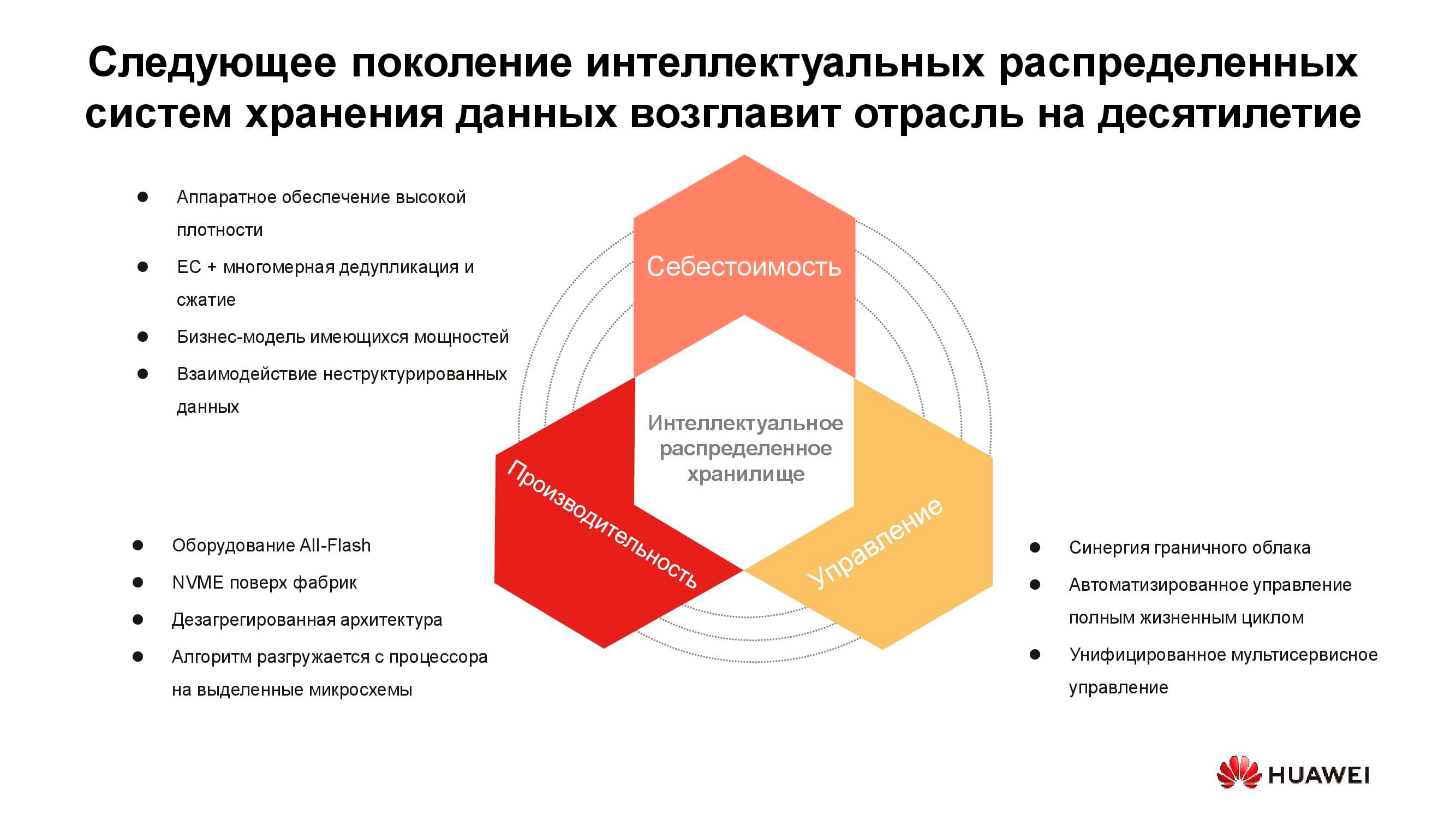
Biaya penyimpanan informasi sekarang menentukan banyak keputusan arsitektural. Dan meskipun dapat ditempatkan dengan aman di garis depan, kami membahas penyimpanan langsung dengan akses aktif hari ini, jadi kinerja juga harus dipertimbangkan. Properti penting lainnya dari sistem terdistribusi generasi berikutnya adalah penyatuan. Lagi pula, tidak ada yang mau memiliki beberapa sistem berbeda yang dikendalikan dari konsol yang berbeda. Semua kualitas ini diwujudkan dalam seri baru produk Huawei OceanStor Pacific .
Penyimpanan massal generasi baru
OceanStor Pacific memenuhi persyaratan keandalan pada tingkat "enam sembilan" (99,9999%) dan dapat digunakan untuk membuat pusat data kelas HyperMetro. Dengan jarak hingga 100 km antara dua pusat data, sistem mendemonstrasikan penundaan tambahan sebesar 2 md, yang memungkinkan untuk membangun solusi tahan bencana berdasarkan basis mereka, termasuk yang memiliki server kuorum.
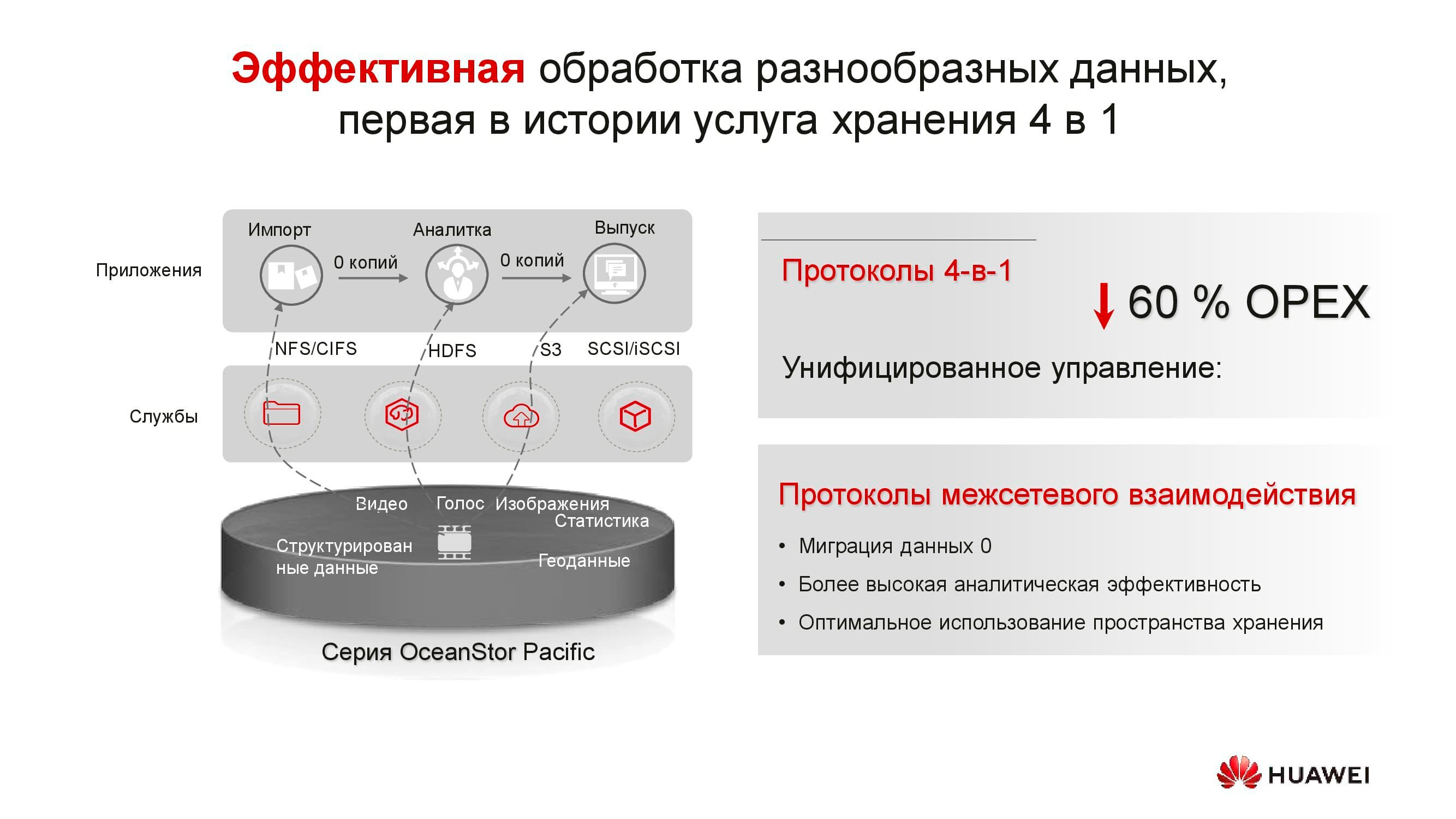
Produk dalam seri baru ini menunjukkan keserbagunaan protokol. OceanStor 100D sudah mendukung akses blokir, akses objek, dan akses Hadoop. Akses file akan diterapkan dalam waktu dekat. Tidak perlu menyimpan banyak salinan data jika dapat dikirim melalui protokol yang berbeda.
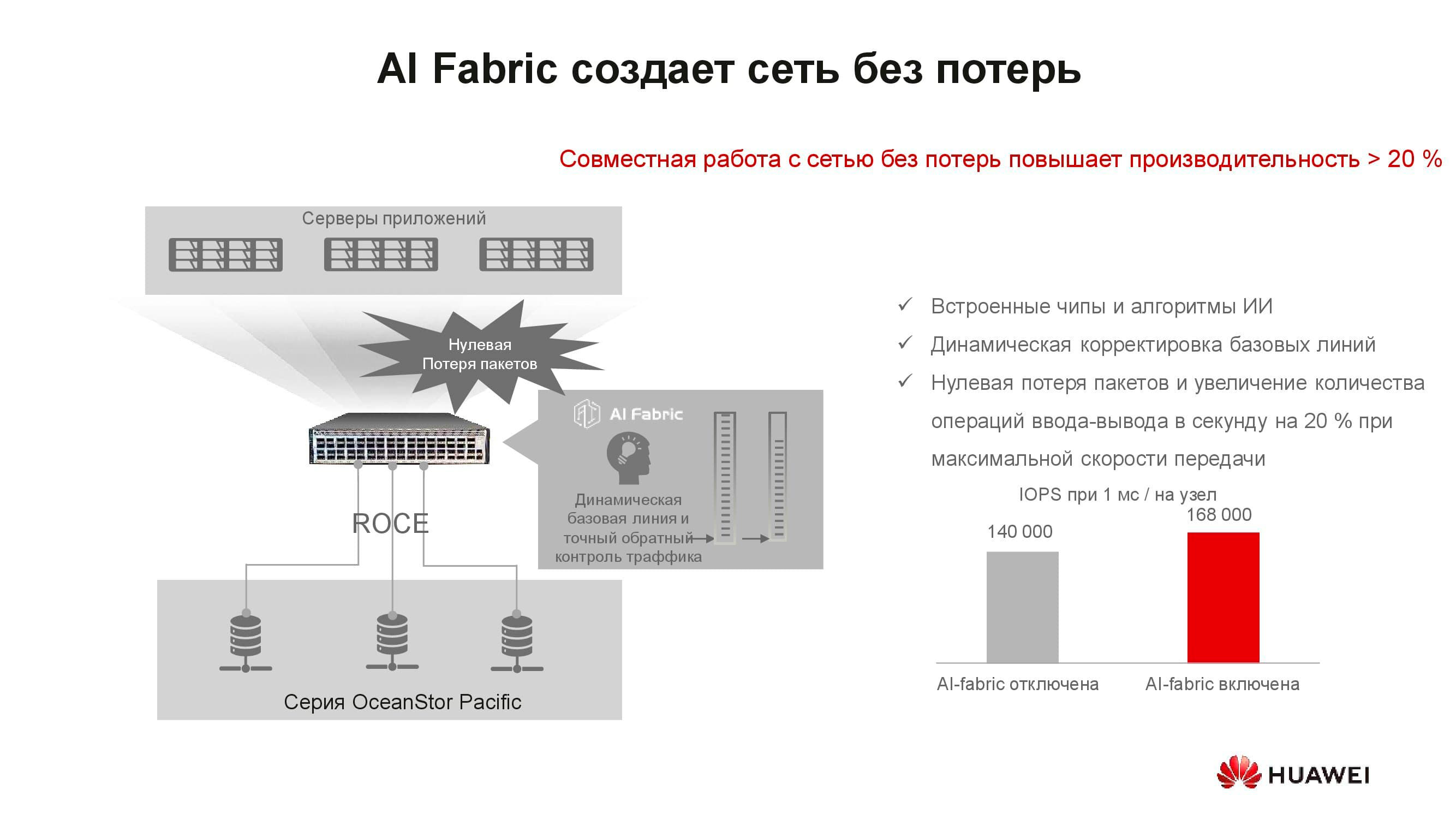
Tampaknya, apa hubungan konsep "jaringan lossless" dengan penyimpanan? Faktanya adalah bahwa sistem penyimpanan terdistribusi dibangun atas dasar jaringan cepat yang mendukung algoritme yang sesuai dan mekanisme RoCE. AI Fabric yang didukung oleh sakelar kami membantu meningkatkan kecepatan jaringan dan mengurangi latensi . Peningkatan kinerja penyimpanan dengan aktivasi AI Fabric bisa mencapai 20%.
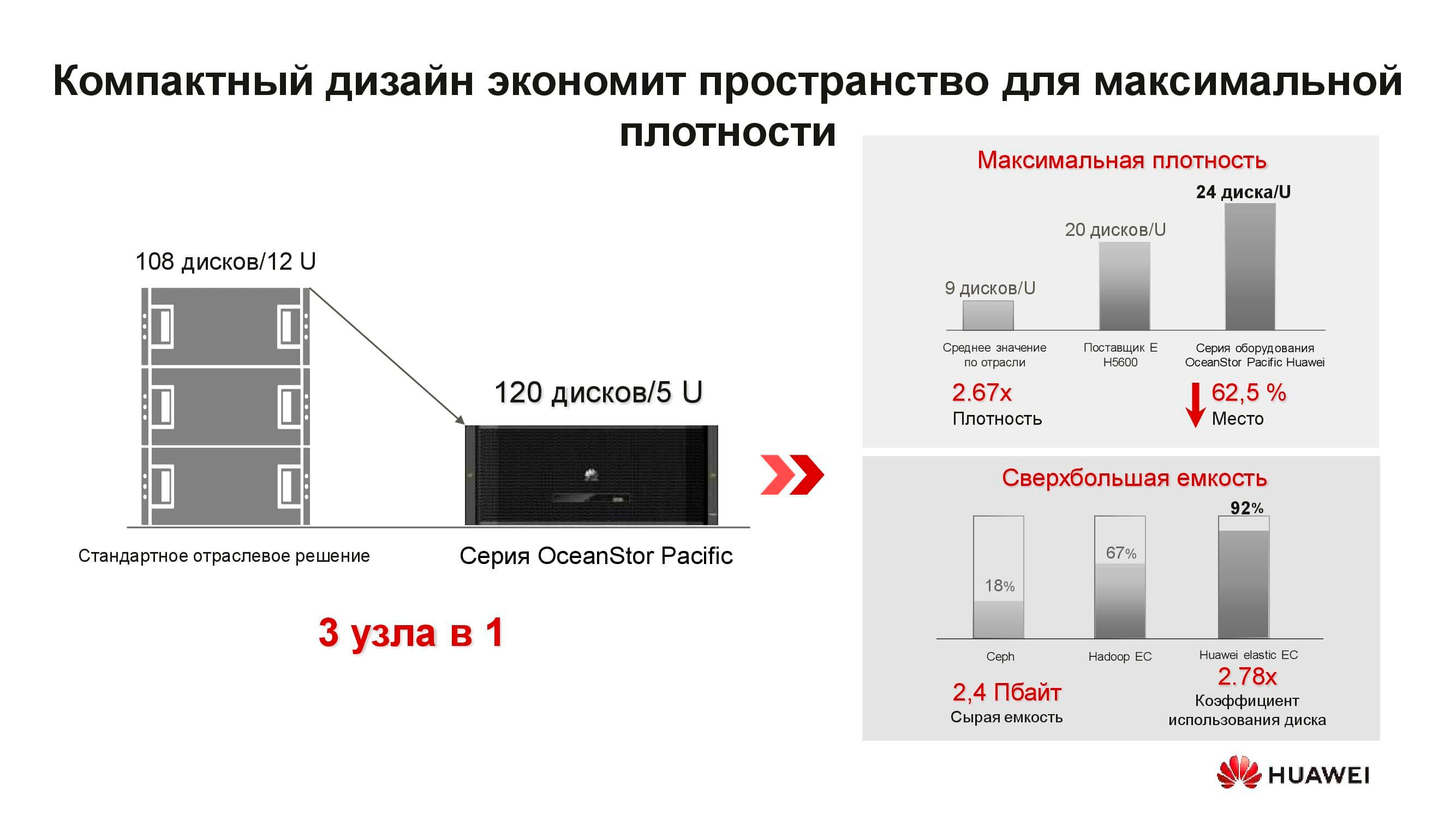
Apa itu node penyimpanan terdistribusi OceanStor Pacific yang baru? Solusi 5U mencakup 120 drive dan dapat menggantikan tiga node klasik, yang menghemat lebih dari dua kali ruang rak. Karena penolakan untuk menyimpan salinan, efisiensi drive meningkat secara signifikan (hingga + 92%).
Kami terbiasa dengan fakta bahwa SDS adalah perangkat lunak khusus yang diinstal pada server klasik. Namun sekarang, untuk mencapai parameter yang optimal, solusi arsitektural ini juga membutuhkan node khusus. Ini terdiri dari dua server berbasis prosesor ARM, yang mengelola berbagai drive 3 inci.
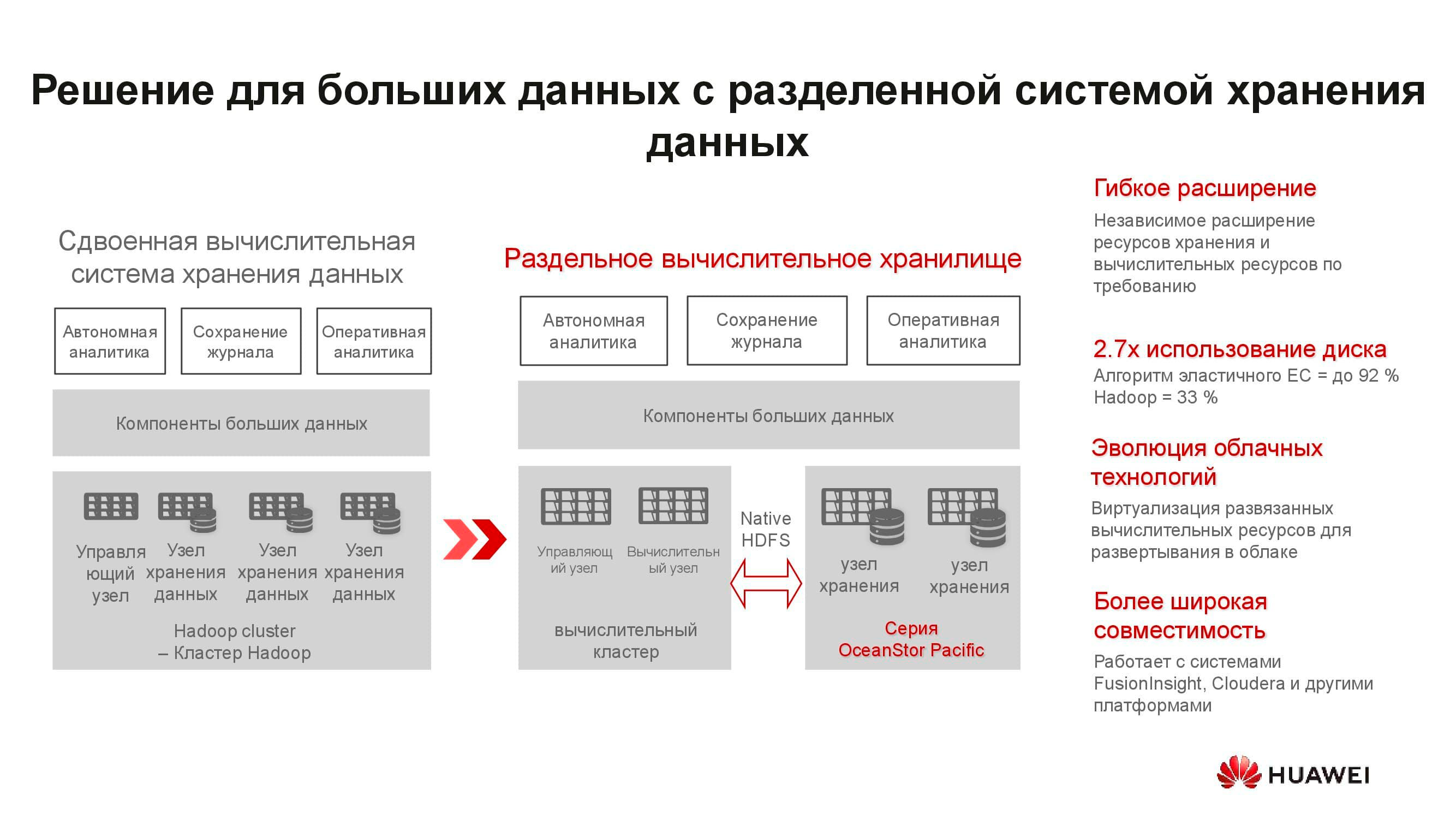
Server ini tidak cocok untuk solusi hyper-converged. Pertama, ada sedikit aplikasi untuk ARM, dan kedua, sulit untuk menjaga keseimbangan beban. Kami mengusulkan untuk pindah ke penyimpanan terpisah: cluster komputasi, yang diwakili oleh server klasik atau rak, beroperasi secara terpisah, tetapi terhubung ke node penyimpanan OceanStor Pacific, yang juga menjalankan tugas langsungnya. Dan itu membenarkan dirinya sendiri.
Sebagai contoh, mari kita ambil solusi penyimpanan data besar hyperconverged klasik yang membutuhkan 15 rak server. Dengan memisahkan beban antara server komputasi individu dan node penyimpanan OceanStor Pacific, memisahkannya dari satu sama lain, jumlah rak yang diperlukan dipotong menjadi dua! Ini mengurangi biaya pengoperasian pusat data dan mengurangi total biaya kepemilikan. Di dunia di mana volume informasi yang disimpan tumbuh 30% per tahun, keuntungan seperti itu tidak tersebar di mana-mana.
***
Anda bisa mendapatkan informasi lebih lanjut tentang solusi dan skenario Huawei untuk penggunaannya di situs web kami atau dengan menghubungi perwakilan perusahaan secara langsung.