- Sebenarnya apa yang akan kita bicarakan? Bukan tentang primitif memilih dan bergabung - saya pikir sebagian besar dari Anda sudah tahu tentang mereka.
Kami akan berbicara tentang penggunaan database yang sebenarnya, kesulitan apa yang dapat Anda hadapi dan apa yang perlu Anda ketahui sebagai pengembang backend. Akan ada banyak informasi, ini isinya. Anda tidak perlu mengetahui secara langsung detail dari masing-masing poin tersebut, namun Anda perlu mengetahui bahwa poin tersebut ada.

Dan Anda perlu mengetahui bagaimana masalah diselesaikan sehingga ketika Anda memiliki tugas untuk membangun struktur, menyimpan data, Anda tahu model data mana yang harus dipilih dan bagaimana cara menyimpannya. Atau misalkan Anda memiliki masalah, Anda melihat bahwa database sedang down, lambat, atau Anda memiliki masalah data, inkonsistensi. Maka Anda harus mengerti di mana harus menggali. Artinya, Anda perlu mengetahui konsep apa yang ada dan dari sisi mana pendekatan masalah tersebut.

Pertama, kita akan berbicara tentang data. Apa ini sih? Ada banyak fakta di sekitar kita, banyak informasi, tetapi sampai mereka terkumpul dengan cara apa pun, itu tidak berguna bagi kita. Kami mengumpulkan, menyusun, dan menyimpannya. Dan struktur yang tersimpan inilah yang disebut data, dan yang menyimpannya disebut database. Tetapi sementara data ini dikumpulkan di suatu tempat, pada dasarnya mereka juga tidak berguna bagi kami. Oleh karena itu, ada lapisan di atas database - DBMS. Inilah yang memungkinkan kami mengambil data, menyimpannya, dan menganalisisnya. Dengan demikian, kami mengubah data yang kami terima menjadi informasi yang sudah dapat kami tampilkan kepada pengguna. Pengguna menerima pengetahuan dan menerapkannya.

Kami akan membahas bagaimana menyusun informasi dan fakta, menyimpannya, dalam bentuk data apa, dalam model apa. Dan bagaimana cara mendapatkannya agar banyak pengguna sekaligus dapat mengakses datanya dan mendapatkan hasil yang benar, sehingga ilmu akhir yang akan kita terapkan adalah benar dan tepat.

Pertama, kita akan berbicara tentang database relasional. Saya pikir model relasional sudah tidak asing lagi bagi banyak dari Anda. Ini adalah model dari tipe tabel dan hubungan antar tabel. Bayangkan kita memiliki messenger di mana kita menulis data dan pesan antar pengguna. Kita bisa menulis semuanya dalam satu tabel yang sangat besar, lebar, di mana kita akan memiliki banyak data berulang - dari siapa, siapa, kepada siapa, di mana obrolan. Dan kita bisa menulis semua ini di berbagai tabel, yaitu menormalkan data kita, membawanya ke bentuk normal ketiga.
Ada catatan dan referensi di slide. Kami tidak akan mempelajari setiap konsep sekarang. Saya akan mencoba untuk tidak membicarakan konsep teknis yang mungkin asing bagi Anda. Tapi semua yang saya katakan akan Anda temukan di catatan slide. Termasuk normalisasi, juga akan ada referensi, bisa dibaca jika belum paham dengan konsep ini.

Secara umum, normalisasi adalah penguraian data menjadi tabel dengan tujuan agar data menjadi lebih terstruktur. Misalnya, sekarang ada tabel pengguna, obrolan dan pesan messenger. Struktur ini memastikan bahwa pesan dari pengguna yang kami kenal dan dari obrolan yang kami kenal akan direkam di sini. Artinya, kami memastikan integritas data. Kami memastikan fakta bahwa kami selalu dapat mengumpulkan keseluruhan gambar. Tetapi pada saat yang sama, kami menyimpan, misalnya, dalam tabel pesan hanya ID, hanya pengenal. Jadi, kami mengurangi ukuran keseluruhan database, membuatnya lebih kecil. Karenanya, kami mempermudah penulisan ke database ini. Kami tidak perlu terus-menerus menulis ke banyak tabel. Kami hanya menulis dalam satu tabel dengan spesialis ID.

Jika kita berbicara tentang normalisasi, umumnya sangat menyederhanakan penglihatan sistem, karena sangat grafis, dan segera menjadi jelas bagi kita hubungan apa yang kita miliki antara tabel mana.
Kami mengurangi jumlah kesalahan saat menulis data, karena jika kami menulis pesan di messenger dan kami belum memiliki pengguna seperti itu, maka kami harus membuatnya. Tetapi gambaran terakhir, data umum, akan tetap lengkap.
Saya telah mengatakan tentang mengurangi ukuran database. Kami tidak harus menulis semua data tentang pengguna di tabel pesan setiap saat. Untuk melihat profilnya, kita cukup masuk ke tabel User.
Saya juga memperingatkan tentang ketergantungan yang tidak konsisten. Ini hanyalah tautan ke ID tabel lain, pengidentifikasi adalah nilai unik dalam satu tabel. Dengan cara lain, mereka disebut kunci utama, dan ketika kita memiliki tautan ke kunci utama ini, maka tautan itu sendiri di tabel lain disebut kunci asing.
Struktur ini juga melindungi data kami dari penghapusan yang tidak disengaja. Kami tidak dapat menghapus pengguna karena, misalnya, dia memiliki pesan. Ini jaring pengaman yang kecil, tapi.
Tampaknya kami telah membuat struktur yang sangat baik, semuanya jelas, semuanya bergantung, semuanya integral. Apa lagi yang perlu Anda kerjakan?

Bayangkan bahwa kita benar-benar menjalankannya, kita memiliki banyak pengguna dan, karenanya, banyak pesan. Mereka terus berkomunikasi satu sama lain. Apa yang terjadi di tabel pesan kita? Itu terus berkembang. Dan untuk mencari di non-data, kita perlu terus-menerus menyortir semua pesan, memeriksa apakah itu dari pengguna ini atau bukan, dalam obrolan ini atau bukan, dan baru kemudian menampilkannya.
Secara alami, semakin banyak pengguna, semakin banyak pesan, semakin lama waktu permintaan pencarian. Kami membutuhkan solusi yang memungkinkan kami untuk mencari pesan di tabel dengan cepat.
Untuk kasus seperti itu, indeks digunakan untuk mempercepat pencarian. Asosiasi paling sederhana dengan indeks adalah konten dalam sebuah buku. Jika Anda perlu mencari informasi di sebuah buku, Anda bisa membolak-balik buku itu, atau Anda bisa pergi ke daftar isi. Indeks adalah semacam daftar isi.
Ada juga contoh bagus dengan buku telepon. Anda dapat mengklik sebuah surat di telepon Anda, dan Anda akan segera dilempar dengan mengacu pada nama keluarga yang dimulai dengan surat ini. Indeks database bekerja dengan cara yang sangat mirip. Mari kita lihat tabel kita dengan pesan dan bagaimana kita akan mendapatkan data ini.

Harap perhatikan bagaimana kami akan bekerja dengan data. Bukan dengan baris apa yang kita miliki di tabel, tapi secara umum. Indeks dibuat atas dasar kueri yang Anda buat.
Mari kita bayangkan bahwa kita terutama membuat permintaan melalui obrolan, yaitu, kita mencari tahu pesan apa yang ada dalam obrolan ini. Mari kita buat indeks persis di kolom obrolan. Indeks database adalah struktur terpisah. Tabel tidak bergantung padanya. Artinya, Anda dapat menghapus dan membangun kembali indeks kapan saja, dan tabel tidak akan terpengaruh karenanya.
Di sini Anda dapat melihat bahwa kami telah memilih, meletakkan indeks pada kolom, dan kami memiliki struktur terpisah, yang telah sedikit mengurangi jumlah entri, karena sudah ada beberapa pesan dalam obrolan 11. DBMS menyediakan pencarian cepat di meja obrolan kecil ini. Bagaimana itu dilakukan? Secara alami, pencarian bukanlah pencarian yang sederhana. Ada banyak algoritma pencarian cepat, kita akan melihat salah satu algoritma paling populer yang digunakan secara default di kebanyakan database. Itu adalah pohon yang seimbang.

Bagaimana cara kerjanya? Kami memiliki nomor obrolan, ini adalah nilai integer, dan pohon dibangun sesuai dengan prinsip berikut: apa yang kurang di sebelah kiri node, lebih banyak nilai di sebelah kanan node. Apa yang diberikan struktur ini kepada kita? Jika Anda melihat pada lembar ringkasan pohon ini, maka semua nilai di bagian bawah telah diurutkan. Ini adalah nilai tambah yang sangat besar dalam perolehan produktivitas. Sekarang saya akan menunjukkan alasannya.
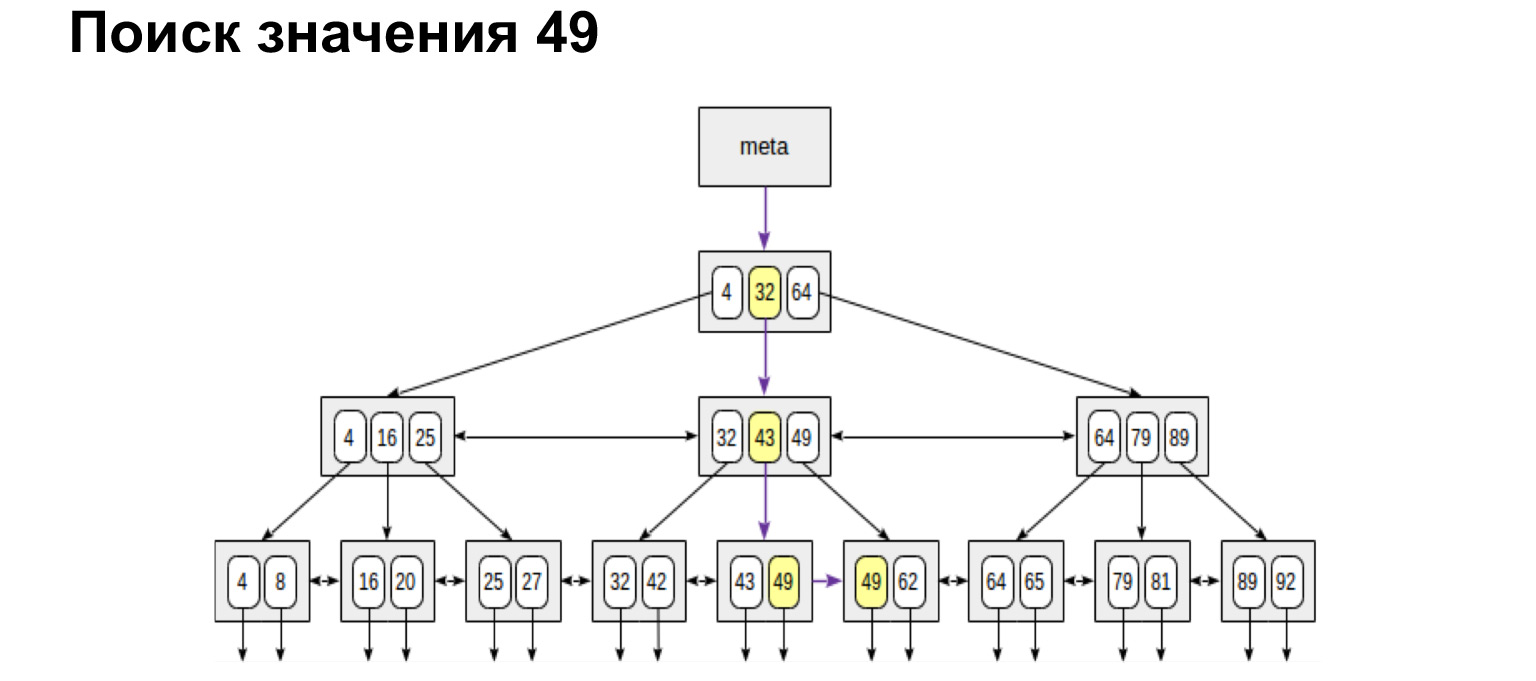
Misalnya, kami mencari nilai. Sangat mudah untuk mencari satu makna. Kami turun ke bawah pohon atau ke kiri, ke kanan - tergantung pada apakah nilai ini lebih besar atau lebih kecil.
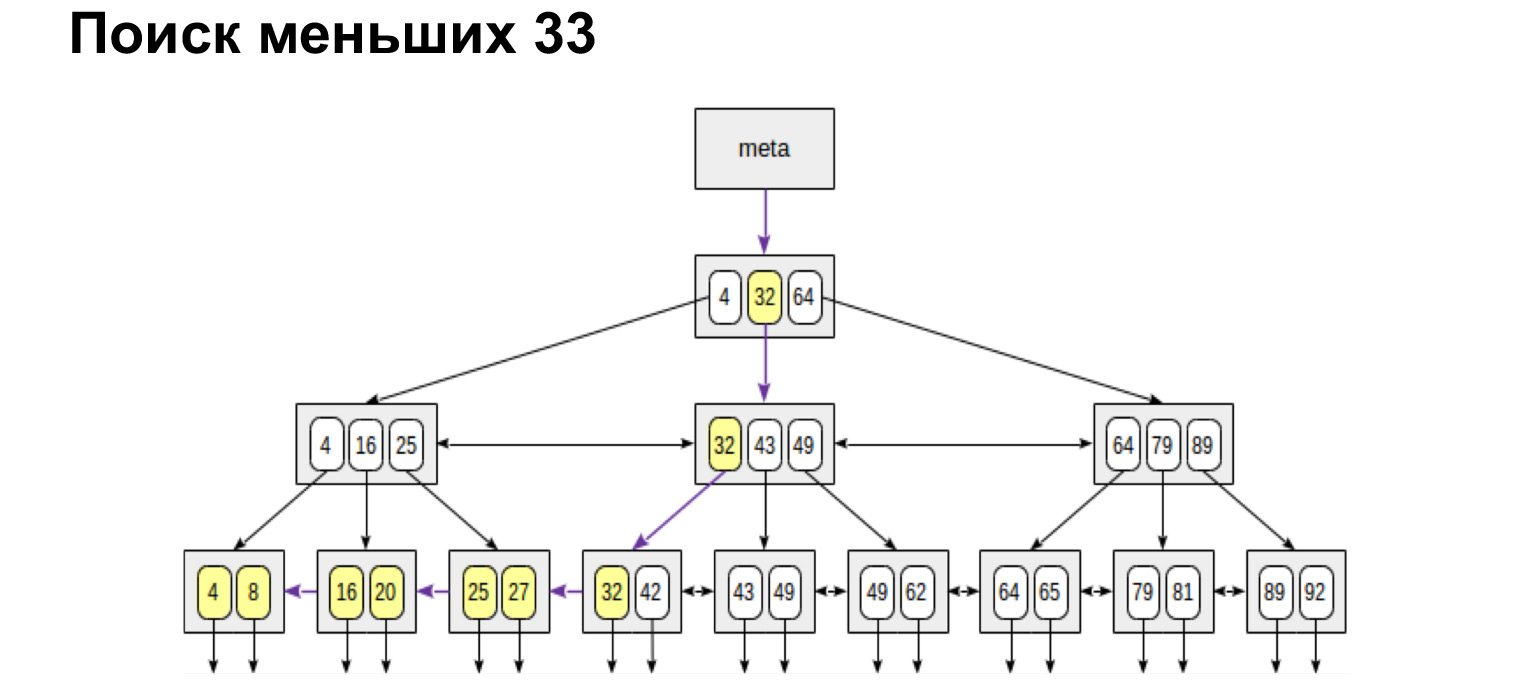
Dan jika kita ingin menemukan, misalnya, rentang, maka lihat betapa sederhana dan cepat hasilnya. Kami mencapai nilai dan kemudian mengikuti tautan di daun, sudah di sepanjang nilai yang dipesan, pergi ke akhir.
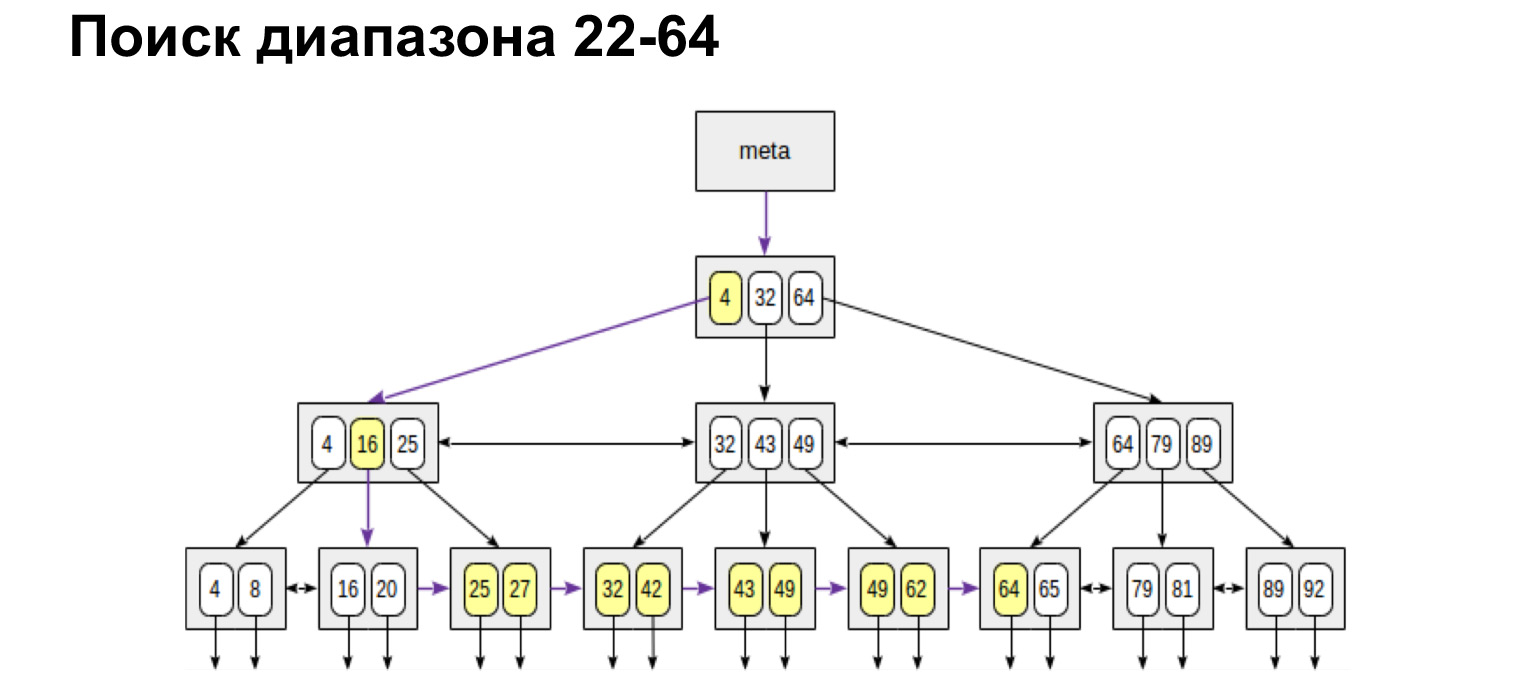
Jika kami membutuhkan rentang yang ditentukan dari dan ke, kami melakukan hal yang persis sama. Kami menemukan nilai awal dan mengikuti tautan daun ke nilai maksimum. Kami berjalan di pohon hanya sekali. Sangat nyaman, sangat cepat.
Dengan cara yang sama, kami akan mencari nilai maksimum dan minimum. Berjalanlah sepenuhnya ke kiri, sepenuhnya ke kanan. Kami juga akan menerima daftar pesanan. Artinya, jika kita hanya perlu mendapatkan semua obrolan secara berurutan, kita mencapai yang pertama dan melewati daun ke nilai paling kanan, kita mendapatkan daftar yang teratur. Dengan prinsip inilah database dengan sangat cepat mencari di tabel indeks untuk baris-baris yang perlu kita pilih, dan mengembalikannya.
Apa yang penting untuk diketahui di sini? Tampaknya struktur yang keren - sekarang kita akan membangun untuk setiap kolom menurut pohon seperti itu dan akan mencari. Menurut Anda mengapa itu tidak akan berhasil? Mengapa kita tidak memiliki peningkatan kecepatan jika kita membangun pohon untuk setiap kolom? (...)
Pilihan kami akan sangat cepat. Setiap kali ketika kita perlu melewati beberapa nilai, kita pergi ke indeks, temukan di sana tautan ke nilai itu sendiri. Indeks biasanya berisi referensi garis persis, bukan garis itu sendiri. Dan untuk memilihnya bekerja dengan sempurna. Tetapi segera setelah kita ingin mengatur data tabel, memperbarui atau menghapus data, maka semua pohon ini harus dibangun kembali.
Faktanya, menghapus tidak akan membangun kembali, tetapi hanya memecah pohon ini, dan kita akan mendapatkan banyak nilai kosong. Akan ada pohon besar dengan nilai kosong. Tetapi dengan pembaruan dan pembuatan pohon-pohon ini akan dibangun kembali setiap saat. Akibatnya, kita akan mendapatkan biaya overhead yang sangat besar untuk semua struktur ini. Dan alih-alih mengambil data dengan cepat dan mempercepat database, kami akan memperlambat kueri kami.
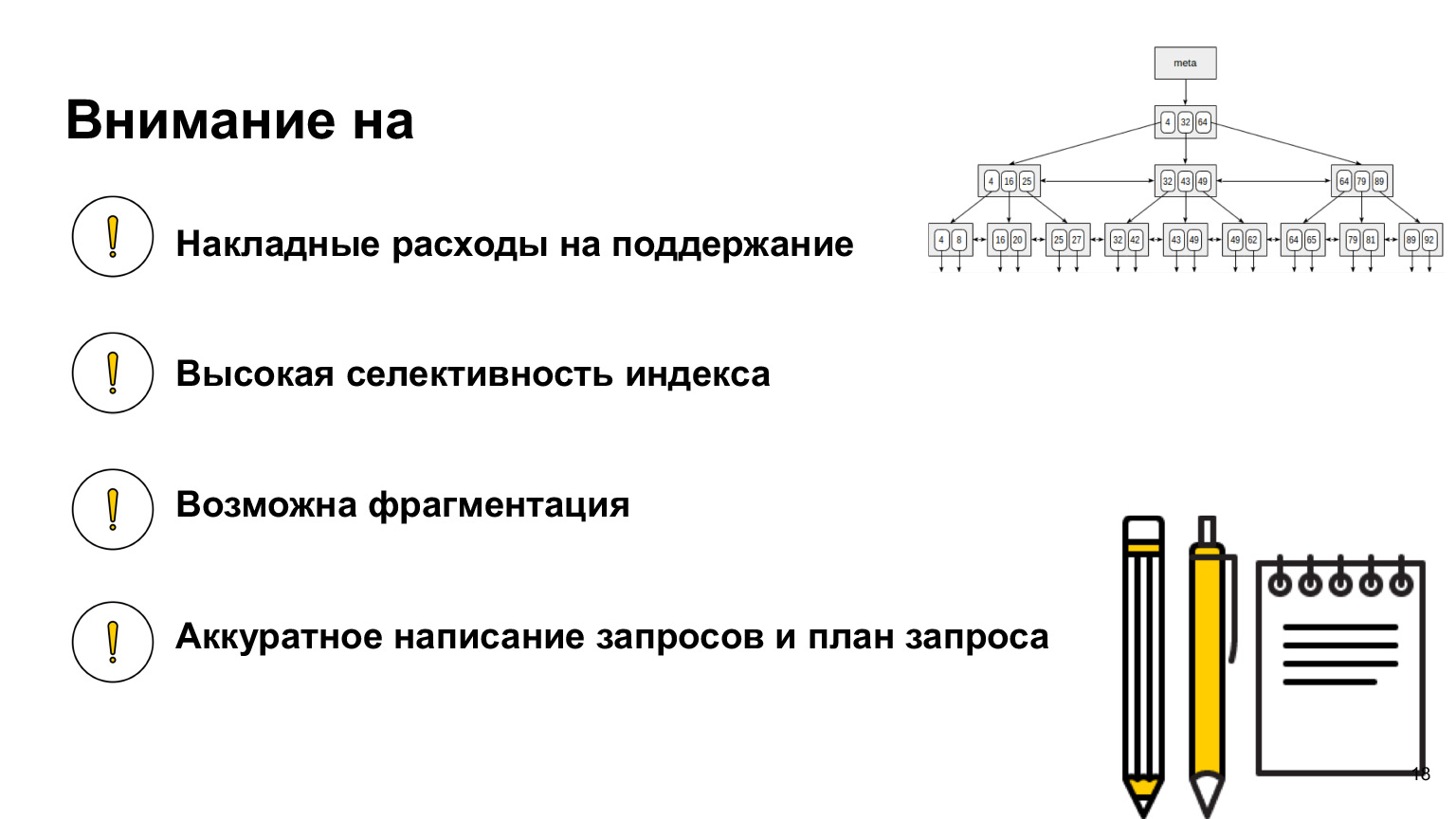
Apa lagi yang penting untuk diketahui? Saat Anda bekerja dengan database, lihat, baca, indeks apa yang ada di dalamnya, karena setiap database memiliki implementasinya sendiri, indeksnya sendiri-sendiri berbeda. Ada indeks untuk dipercepat, ada indeks untuk memastikan integritas. Salah satu yang paling sederhana hanyalah kunci utama. Ini juga merupakan indeks unik. Dan mengenai database Anda, lihat cara kerjanya, cara bekerja dengannya, karena ini adalah jenis pengetahuan yang akan membantu Anda menulis kueri yang paling optimal.
Kami membahas apa yang perlu diingat tentang overhead pemeliharaan indeks saat memasukkan data. Saya lupa mengatakan bahwa ketika Anda membangun indeks, itu harus sangat selektif. Apa artinya?
Mari kita lihat pohon ini. Kami memahami bahwa jika indeks disetel ke benar salah, maka kami hanya mendapatkan dua potong kayu besar di kiri dan kanan. Dan kami memeriksa 50% dari tabel, yang sebenarnya tidak terlalu efisien. Cara terbaik adalah membuat indeks pada kolom-kolom yang memiliki nilai paling berbeda. Ini akan mempercepat pilihan kami.
Saya mengatakan tentang fragmentasi; saat menghapus data, Anda harus mengingatnya. Jika kita sering mengalami penghapusan data yang terdapat dalam indeks, maka mungkin perlu dilakukan defragmentasi, dan hal ini juga perlu dipantau. Penting juga untuk memahami bahwa Anda membuat indeks tidak berdasarkan kolom apa yang Anda miliki, tetapi pada cara Anda menggunakan data tersebut. Dan kueri yang menyertakan indeks perlu ditulis dengan sangat hati-hati. Apa artinya rapi? Saat Anda menulis kueri, kirimkan ke database, tidak dikirim langsung ke database, tetapi ke lapisan perangkat lunak tertentu yang disebut penjadwal kueri.
Penjadwal memiliki tabel korespondensi tertentu tentang berapa biaya operasi dan seberapa mahal harganya. Dalam contoh PostgreSQL, ada tabel teknis khusus yang mengumpulkan informasi tentang data Anda, tentang tabel Anda. Perencana melihat kueri apa yang Anda miliki, data apa yang disimpan di tabel pg_stat. Ini persis dengan tabel yang menyimpan informasi umum tentang berapa banyak data yang Anda miliki dan kolom apa yang ada di tabel Anda, indeks apa yang ada di dalamnya. Berdasarkan ini, dia melihat rencana untuk eksekusi kueri Anda, menghitung berapa banyak waktu menurut rencana mana yang diperlukan untuk kueri, dan memilih yang paling optimal.

Jika Anda ingin melihat perkiraan waktu eksekusi untuk kueri Anda, Anda dapat menggunakan operasi Jelaskan. Jika Anda menginginkan eksekusi yang sebenarnya, Anda dapat menggunakan Jelaskan analisis. Apa bedanya? Seperti yang saya katakan, penjadwal awalnya menghitung waktu eksekusi berdasarkan perkiraan waktu untuk setiap operasi. Oleh karena itu, waktu sebenarnya dapat berbeda bergantung pada mesin dan sifat data Anda. Jadi jika Anda menginginkan eksekusi yang sebenarnya, maka lebih baik menggunakan analisis Explain.
Anda dapat melihat contohnya di slide ini. Ini menunjukkan bahwa terkadang kueri yang didasarkan pada kolom Anda yang memiliki indeks mungkin tidak menggunakan indeks pemindaian, tetapi hanya pemindaian penuh di seluruh tabel. Ini terjadi jika kita memiliki selektivitas indeks rendah dan jika perencana berpikir bahwa kueri pemindaian penuh di atas meja akan lebih menguntungkan.
Bayangkan kita memiliki messenger kita dan kita ingin di daftar chat, misalnya, menampilkan nama chat atau jumlah pesan yang belum dibaca. Jika setiap kita membuka chat, kita menghitung ulang semua data untuk semua chat, itu akan sangat tidak menguntungkan.
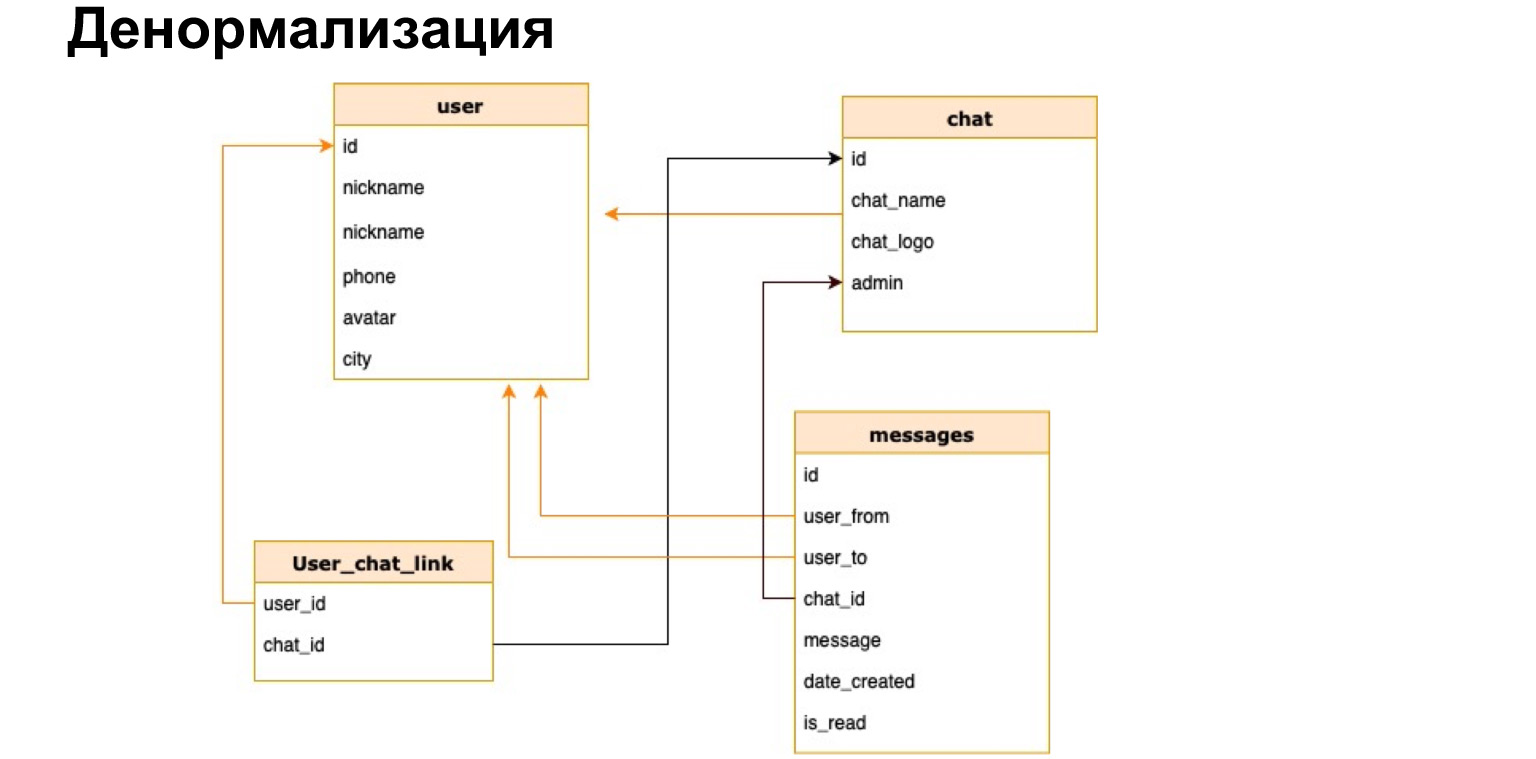
Ada hal seperti itu - denormalisasi. Ini adalah penyalinan data terpanas yang digunakan atau pra-perhitungan dari data yang diperlukan dan menyimpannya ke tabel.
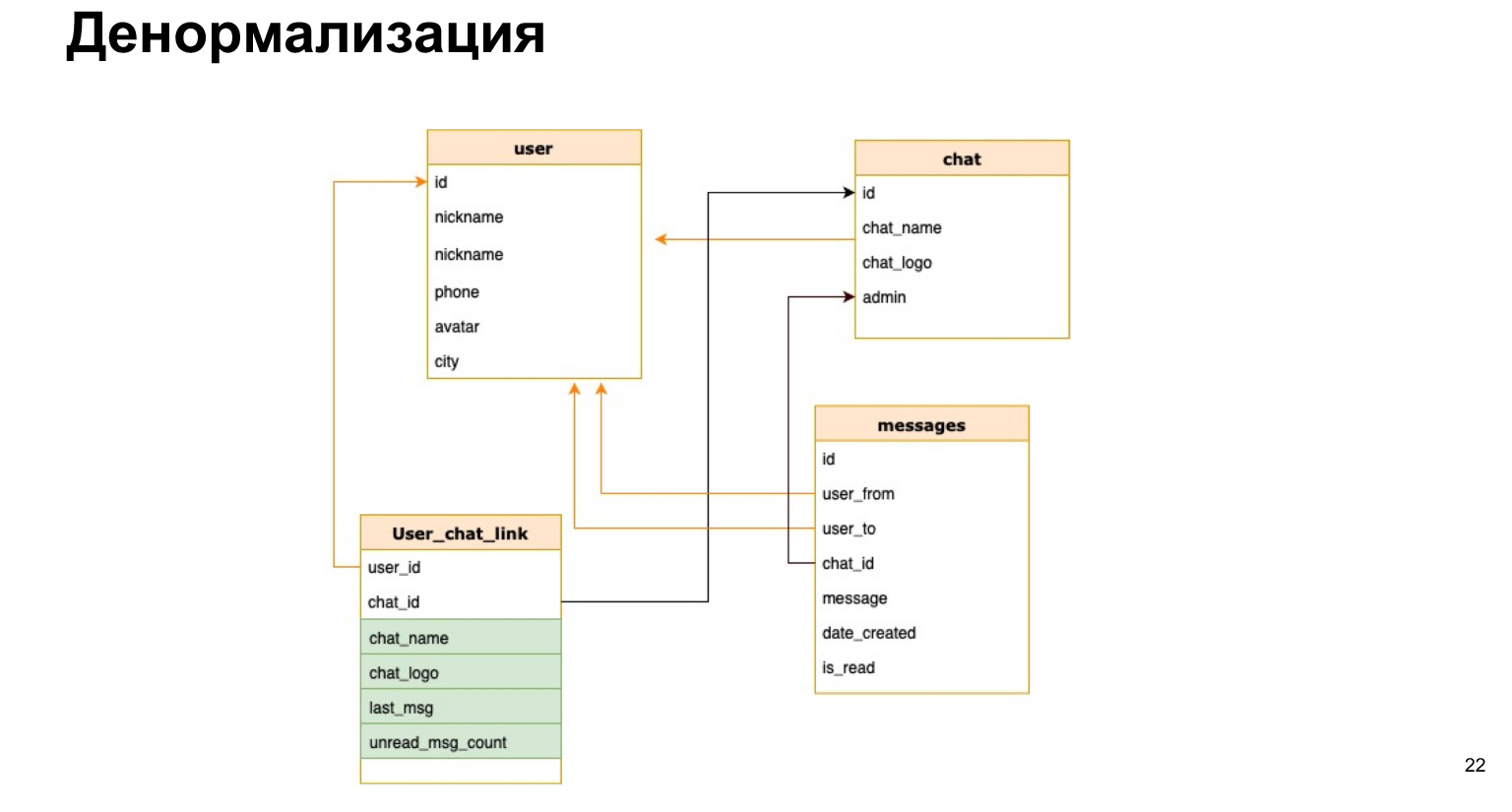
Seperti inilah kemungkinan hubungan antara pengguna dan obrolan. Artinya, selain ID pengguna dan ID obrolan, kami akan secara singkat menyimpan nama obrolan, log obrolan, dan jumlah pesan yang belum dibaca di sana. Jadi, setiap kali kita tidak perlu memuat semua tabel kita, membuat pilihan dan menghitung ulang semua ini.

Apa kelebihan dari denormalisasi? Kami mempercepat proses pengambilan sampel data. Artinya, pilihan kami diproses secepat mungkin, kami memberikan jawaban kepada pengguna secepat mungkin.
Kesulitannya adalah setiap kali kita menambahkan data baru, kita perlu menghitung ulang semua kolom ini dan kemungkinan kesalahannya sangat tinggi. Artinya, jika pilihan kita menjadi lebih sederhana dan kita tidak perlu bergabung sepanjang waktu, maka pembaruan dan pembuatan kita menjadi sangat tidak praktis, karena kita perlu menggantung pemicu di sana, menghitung ulang dan tidak melupakan apa pun.
Oleh karena itu, Anda sebaiknya hanya menggunakan denormalisasi saat Anda benar-benar membutuhkannya. Dan karena kita sekarang mengikuti seluruh logika ini, pertama-tama Anda perlu menormalkan data, lihat bagaimana Anda akan menggunakannya, sesuaikan indeksnya. Jika Anda memiliki kueri yang menurut Anda tidak berkinerja baik, lihat Jelaskan sebelum melakukan denormalisasi. Cari tahu bagaimana sebenarnya kinerjanya, bagaimana penjadwal melakukannya. Dan baru setelah itu, jika Anda sudah sampai pada kesimpulan bahwa denormalisasi masih diperlukan, maka Anda bisa melakukannya. Tetapi ada praktik seperti itu, dan dalam proyek nyata, denormalisasi data sering digunakan.
Mari melangkah lebih jauh. Bahkan jika Anda menyusun data dengan baik, memilih model data, mengumpulkannya, mendenormalisasi semuanya, menghasilkan indeks, masih banyak hal di dunia TI yang bisa salah.
Perangkat lunak mungkin gagal, listrik mungkin mati, perangkat keras atau jaringan mungkin gagal. Ada juga masalah kelas kedua: banyak pengguna menggunakan database kami secara bersamaan. Mereka dapat memperbarui data yang sama pada waktu yang sama. Kita harus bisa menyelesaikan semua masalah ini.
Mari kita lihat contoh spesifik tentang apa ini.

Bayangkan ada dua pengguna yang ingin memesan ruang rapat. Pengguna 1 melihat bahwa ruang rapat saat ini kosong dan mulai memesannya. Jendelanya terbuka, dan dia berpikir siapa rekan saya yang akan saya hubungi. Selagi berpikir, pengguna 2 juga melihat bahwa ruang rapat itu gratis dan membuka jendela pengeditan untuk dirinya sendiri.
Akibatnya, saat pengguna 1 menyimpan data ini, dia pergi dan berpikir bahwa semuanya baik-baik saja, ruang rapat sudah dipesan. Namun saat ini, pengguna 2 menimpa datanya, dan ternyata ruang obrolan tersebut ditetapkan ke pengguna 2. Ini disebut konflik data. Dan kita harus bisa menunjukkan konflik ini kepada orang-orang dan menyelesaikannya. Di tempat inilah kami akan merekam ulang.

Bagaimana cara melakukannya? Kami cukup memblokir ruang rapat untuk sementara waktu sementara pengguna 1 berpikir. Jika dia menyimpan data, maka kami tidak akan mengizinkan pengguna 2 untuk melakukan ini. Jika dia merilis data dan tidak menyimpan, maka pengguna 2 akan dapat memesan ruang konferensi. Anda bisa melihat gambar serupa saat membeli tiket bioskop. Anda diberi waktu 15 menit untuk membayar tiket, jika tidak tiket akan diberikan lagi kepada orang lain yang juga dapat mengambil dan membayarnya.
Berikut contoh lain yang akan menunjukkan kepada kita betapa pentingnya memastikan bahwa operasi kita dilakukan sepenuhnya. Katakanlah saya ingin mentransfer uang dari rekening bank 1 ke rekening 2. Saat ini saya memiliki tiga operasi. Saya memeriksa bahwa saya memiliki cukup dana, mengurangi dana dari akun pertama saya dan menyetorkannya ke akun kedua. Jelas bahwa jika pada saat-saat ini saya mengalami kegagalan, maka ada sesuatu yang salah.
Misalnya, jika pada tahap ini terjadi transaksi lain yang membaca data, maka dana di akun saya tidak lagi mencukupi, saya tidak akan dapat melakukan operasi lain. Jika masalah terjadi pada saat kedua, maka kami, misalnya, menarik uang dari satu akun, tetapi tidak menaruh uang pada akun kedua. Ternyata akibatnya, rekening bank saya, semua rekening saya, akan berkurang sejumlah. Uang ini tidak dapat dikembalikan dengan cara apapun.
Untuk mengatasi masalah seperti itu, ada konsep transaksi - eksekusi integral atomik dari ketiga operasi secara bersamaan.
Bagaimana database melakukannya? Ini menulis semua perubahan ini ke log tertentu dan menerapkannya hanya ketika transaksi kami dilakukan. Dengan demikian, kami menjamin bahwa semua operasi ini akan dilakukan secara keseluruhan atau tidak akan dilakukan sama sekali.
Jika suatu saat kita mengalami kegagalan, maka uang tidak akan dikurangkan dari rekening pertama dan, karenanya, kita tidak akan kehilangannya.
Transaksi memiliki empat properti, empat persyaratan untuk mereka. Ini adalah Atomicity, Consistency, Isolation dan Durability - atomicity data, konsistensi, isolasi dan persistensi. Apa sajakah properti ini?
- Atomicity atau atomicity adalah jaminan bahwa operasi yang Anda lakukan akan selesai secara penuh, tidak akan dilakukan sebagian. Dengan demikian, kami memastikan bahwa keseluruhan konsistensi data dalam database kami akan baik sebelum dan sesudah operasi.
- Consistency — -, . (Integrity). - , , Integrity Error, : , . . — , .
, , , , . . .
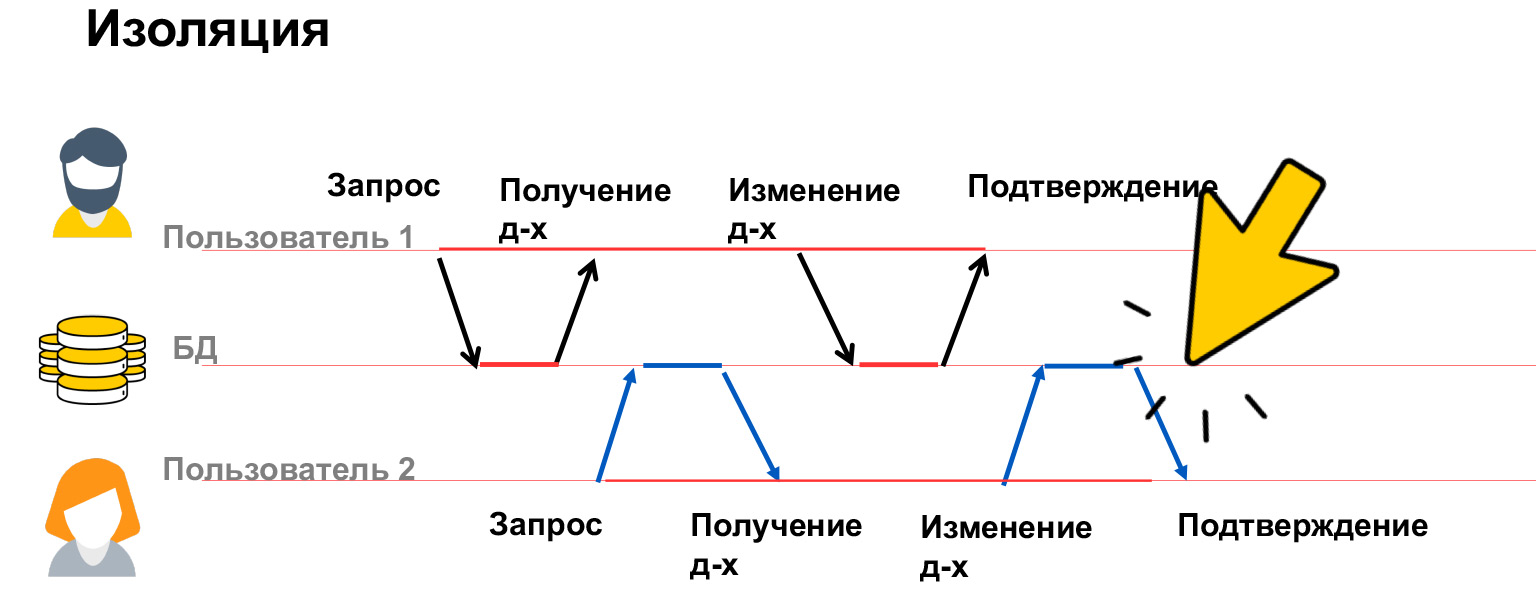
- Isolation — , . . , .
- Durability — , , , , .
Mari kita bicara lebih banyak tentang isolasi. Isolasi transaksi adalah properti yang sangat mahal, banyak sumber daya dihabiskan untuk itu, itulah sebabnya kami memiliki beberapa tingkat isolasi dalam database kami. Mari kita lihat apa masalahnya, dan berdasarkan ini, kita sudah akan membahas cara menyelesaikannya.
Ada empat kelas utama masalah - update yang hilang, pembacaan kotor, pembacaan yang tidak dapat diulangi, dan pembacaan bayangan. Mari kita lihat lebih dekat.
Pembaruan yang hilang seperti dalam contoh pada ruang obrolan, ketika pengguna 1 telah menimpa data dan dia tidak mengetahuinya. Artinya, kami tidak memblokir data yang diubah pengguna ini, dan, karenanya, menerima penimpaannya.
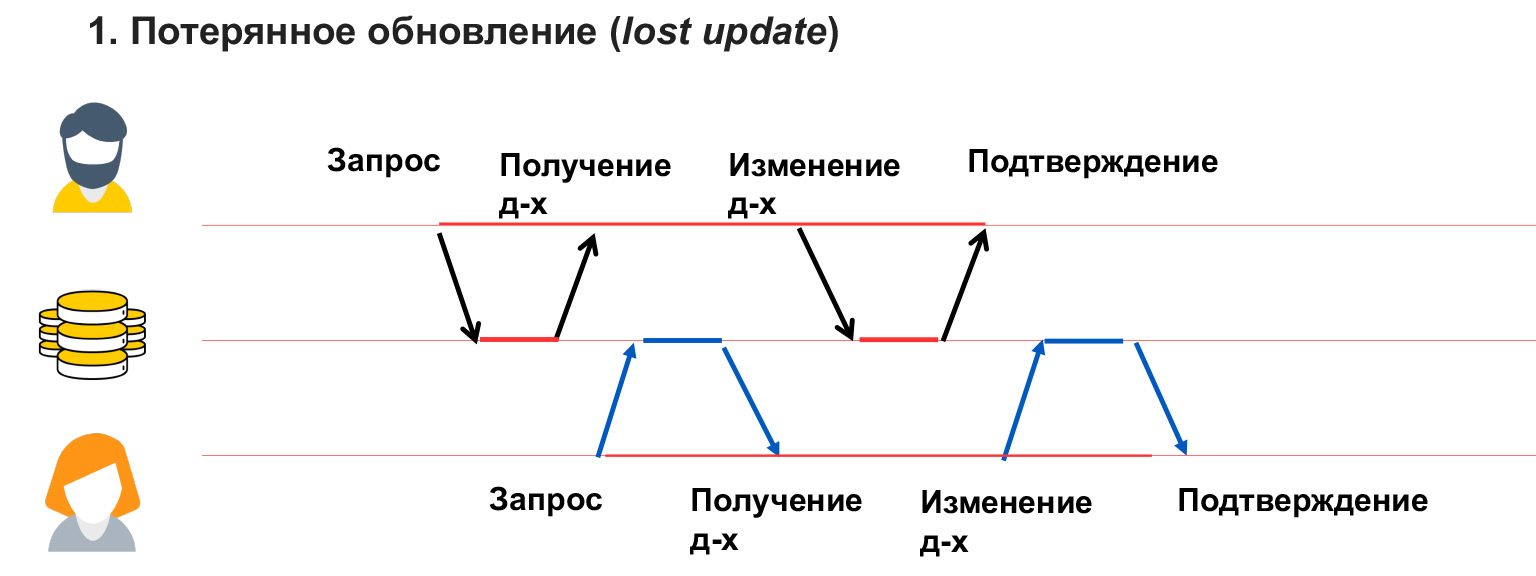
Masalah baca kotor terjadi ketika pengguna melihat perubahan sementara oleh pengguna lain, yang kemudian dapat dibatalkan atau dibuat sementara.

Dalam hal ini, pengguna 1 menulis sesuatu ke database. Pengguna 2 saat itu sedang menghitung sesuatu dari sana dan membangun analitik pada data ini. Dan pengguna 1 mengalami kesalahan, ketidakkonsistenan, dan memutar kembali data ini. Dengan demikian, analitik yang ditulis pengguna 2 akan palsu, salah, karena data yang dia hitung sudah tidak ada lagi. Anda juga harus bisa menyelesaikan masalah ini.
Pembacaan yang tidak dapat diulang adalah ketika kita memiliki pengguna dengan 1 transaksi panjang. Dia mengambil data dari database, dan saat ini pengguna 2 mengubah sebagian dari data yang sama.
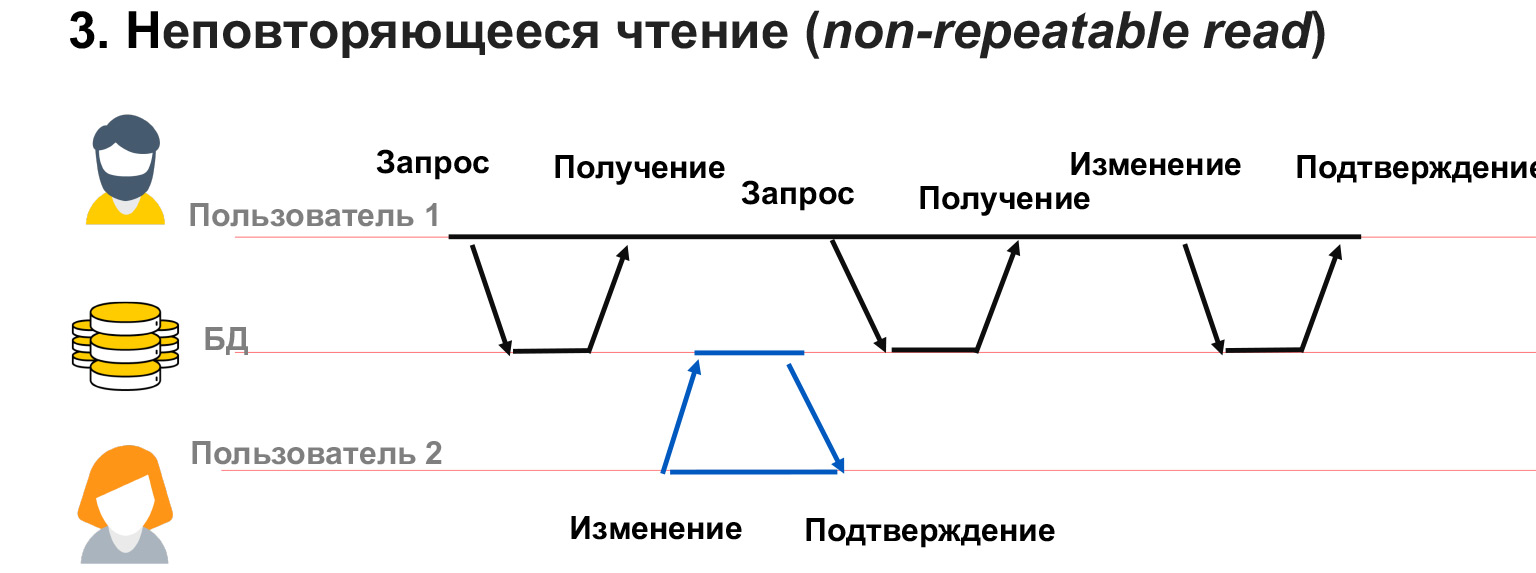
Dalam hal ini, ternyata pengguna 1 belum memblokir perubahan pada data yang dimilikinya. Dan terlepas dari kenyataan bahwa dia sendiri menerima snapshot dari data tersebut, ketika dia berulang kali diminta untuk memilih yang sama, dia bisa mendapatkan nilai yang berbeda di baris ini. Dengan demikian, akan ada konflik, ketidakcocokan dalam data yang ditulisnya.

Masalah serupa dapat terjadi jika pengguna 2 telah menambahkan atau menghapus data. Artinya, pengguna 1 membuat permintaan, dan kemudian, setelah permintaan kedua untuk data yang sama, dia memiliki atau menghilangkan baris. Dalam hal ini, dalam kerangka transaksi, sangat sulit untuk memahami apa yang harus dilakukan dengannya, bagaimana memprosesnya sama sekali.

Untuk mengatasi masalah tersebut, ada empat tingkat isolasi. Tingkat pertama dan terendah adalah Baca tanpa komitmen. Inilah yang digambarkan PostgreSQL sebagai Tanpa kunci. Saat kami membaca atau menulis data, kami tidak memblokir pengguna lain untuk membaca atau menulis data tersebut. Ternyata kami tidak memblokir perubahan apa pun. Keempat masalah tersebut masih bisa terjadi. Tapi apa yang dilindungi oleh tingkat isolasi ini? Ini memastikan bahwa semua transaksi yang masuk ke database akan dieksekusi. Jika dua pengguna secara bersamaan mulai menjalankan kueri dengan data yang sama, maka kedua transaksi ini akan dijalankan secara berurutan.
Untuk apa ini berguna? Level isolasi ini sangat jarang digunakan dalam praktik, tetapi dapat berguna, misalnya, ketika ada kueri analitik yang besar dan Anda ingin membaca di kueri kedua dan melihat pada tahap apa analitik Anda, data mana yang sudah direkam dan mana yang tidak. Dan kemudian permintaan kedua - yaitu untuk men-debug, men-debug, memeriksa - Anda jalankan hanya di tingkat isolasi ini. Dan dia melihat semua perubahan dalam kueri analitik pertama Anda, yang pada akhirnya dapat dibatalkan. Atau tidak dibatalkan, tetapi saat ini Anda dapat melihat status sistem.

Baca berkomitmen, baca data berkomitmen. Level isolasi ini digunakan secara default di sebagian besar database relasional, termasuk PostgreSQL dan Oracle. Ini memastikan bahwa Anda tidak pernah membaca data kotor. Artinya, transaksi lain tidak pernah melihat tahapan perantara dari transaksi pertama. Keuntungannya adalah ini berfungsi sangat baik untuk kueri kecil dan pendek. Kami menjamin bahwa kami tidak akan pernah mengalami situasi di mana kami melihat beberapa bagian data, data yang tidak lengkap. Misalnya, kami menaikkan gaji seluruh departemen dan kami tidak melihat ketika hanya sebagian orang yang menerima kenaikan, dan bagian kedua duduk dengan gaji non-indeks. Karena jika kita mengalami situasi seperti itu, maka logis jika analis kita akan langsung "pergi".
Apa yang tidak dilindungi oleh tingkat isolasi ini? Itu tidak melindungi dari fakta bahwa data yang telah Anda pilih dapat diubah. Untuk kueri kecil, tingkat isolasi ini cukup, tetapi untuk kueri yang besar dan panjang, analitik yang kompleks, tentu saja, Anda dapat menggunakan tingkat yang lebih kompleks yang mengunci tabel Anda.
Tingkat isolasi baca berulang melindungi dari tiga masalah pertama yang kita diskusikan dengan Anda. Ini dan pembaruan yang hilang ketika kami merekam ulang ruang obrolan kami; Bacaan kotor - membaca data yang tidak terikat; dan data baca-baca yang tidak dapat diulang ini diperbarui oleh transaksi lain.

Bagaimana ini disediakan? Dengan mengunci tabel, yaitu mengunci pilihan kita. Saat kami memilih ke dalam transaksi kami, ini terlihat seperti cuplikan data. Dan saat ini kami tidak melihat perubahan dari pengguna lain, sepanjang waktu kami bekerja dengan snapshot data ini. Sisi negatifnya adalah kami memblokir data dan, karenanya, kami memiliki lebih sedikit permintaan paralel yang dapat bekerja dengan data. Ini adalah aspek yang sangat penting. Dan secara umum, mengapa ada begitu banyak level isolasi ini?
Semakin tinggi levelnya, semakin banyak blok dan lebih sedikit pengguna yang bisa bekerja dengan database secara paralel. Setiap transaksi melihat snapshot tertentu dari data yang tidak dapat diubah. Tetapi data baru mungkin muncul. Sehingga tingkat isolasi ini tidak menyelamatkan kita dari munculnya data baru yang layak untuk dipilih.
Ada satu tingkat isolasi lagi - serialisasi. Ini sering disebut dengan pemesanan. Ini adalah kunci data lengkap di atas meja. Ini menghemat dari pembacaan bayangan, yaitu, dari hanya membaca data yang telah kami tambahkan atau hapus, karena kami mengunci tabel, kami tidak mengizinkan penulisan padanya. Dan kami memenuhi permintaan kami secara holistik.

Ini sangat berguna untuk kueri analitik yang kompleks dan besar di mana akurasi dan integritas data sangat penting. Tidak akan ternyata bahwa di beberapa titik kami membaca data pengguna, lalu statistik baru muncul di tabel lain dan ternyata tidak sinkron.
Ini adalah tingkat isolasi tertinggi. Ini memiliki jumlah kunci terbesar dan kemungkinan paralelisasi kueri terkecil.
Apa yang perlu Anda ketahui tentang transaksi? Bahwa mereka menyederhanakan hidup kita, karena diterapkan pada level DBMS dan kita hanya perlu membuat kueri dengan benar, membentuknya dengan benar, sehingga datanya pada akhirnya konsisten. Dan untuk memblokir dengan tepat data yang digunakan pengguna kami. Harus diingat bahwa memblokir segalanya itu buruk, di mana-mana. Bergantung pada sistem apa yang Anda miliki dan siapa yang membaca / menulis seberapa banyak, Anda akan memiliki tingkat isolasi yang berbeda. Jika Anda menginginkan sistem secepat mungkin yang membuat beberapa kesalahan, Anda dapat memilih tingkat isolasi minimum. Jika Anda memiliki sistem perbankan yang harus memastikan bahwa datanya konsisten, semuanya dilakukan dan tidak ada yang hilang - maka, tentu saja, Anda perlu memilih tingkat isolasi maksimum.
Kami telah membuat kemajuan yang cukup bagus dalam memahami bagaimana menyusun database dan apa yang bisa terjadi. Mari melangkah lebih jauh.
Seberapa amankah menyimpan satu database. Pastinya tidak aman. Jika sesuatu terjadi padanya, kami kehilangan semua data. Jika ada cadangan, kami dapat menggulungnya, tetapi kemudian akan ada sistem downtime. Jika jaringan kami rusak atau node menjadi tidak tersedia, sistem juga akan menganggur untuk beberapa waktu, saat downtime.
Bagaimana ini bisa diselesaikan? Ada konsep seperti itu - replikasi. Ini adalah duplikasi database ke node dan server lain.

Ini persis duplikasi lengkap, salinan database. Bagaimana kita bisa menggunakan mekanisme ini?
Pertama, jika sesuatu terjadi pada database, kita dapat mengalihkan permintaan ke salinan database lain, yang pada prinsipnya logis. Ini adalah aplikasi utama. Bagaimana lagi kita bisa menggunakan ini?
Mari kita bayangkan bahwa pengguna jauh dari server. Kami dapat mendistribusikan server untuk memenuhi jumlah maksimum pengguna dan mengirim permintaan kepada mereka secepat mungkin. Masing-masing server ini akan memiliki salinan yang sama dengan yang lain, tetapi permintaan akan kembali ke pengguna lebih cepat.

Penggunaan lain yang sangat populer adalah load balancing. Karena kita memiliki salinan data yang identik, kita tidak dapat membaca bukan dari kepala kita, bukan dari satu database, tetapi dari database yang berbeda. Jadi, kami membongkar server kami.

Kami juga memiliki konsep kueri OLTP dan kueri OLAP. Apa itu? OLTP - pertanyaan transaksional singkat. OLAP adalah analitik jangka panjang. Ini adalah saat kami mengambil gabungan besar, pemilihan besar, kami menggabungkan semuanya, dan sangat penting bagi kami bahwa saat ini semua data terkunci, sehingga tidak ada perubahan dan database lengkap.
Untuk situasi seperti itu, Anda dapat melakukan analitik pada salinan database yang terpisah. Jadi kami tidak akan mempengaruhi pengguna kami, mereka juga dapat membuat entri di database, lalu entri ini akan masuk ke salinan kami.
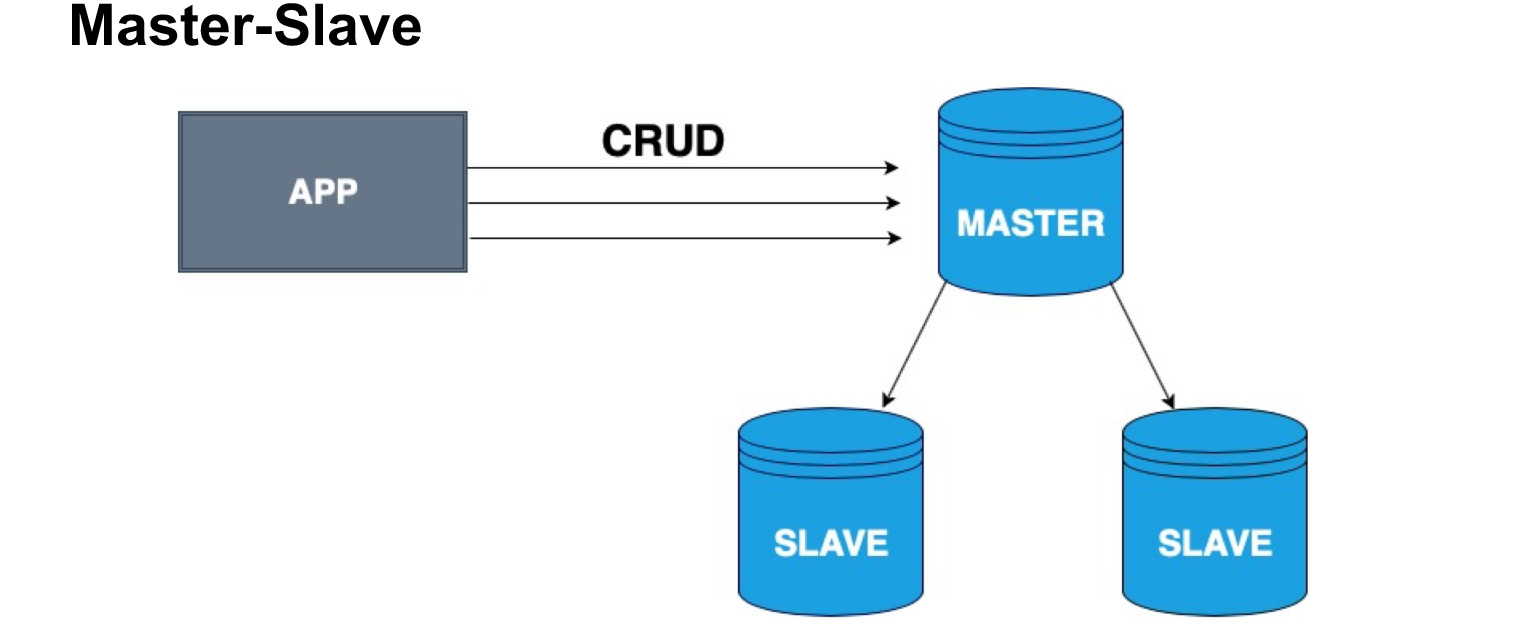
Untuk mendistribusikan salinan database dengan benar, konsep node master dan node slave, Master dan Slave, diperkenalkan. Budak sangat sering disebut replika atau pengikut. Master - node tempat pengguna kita, aplikasi kita menulis. Master menerapkan semua perubahan, menyimpan log perubahan, dan mengirimkan log ini ke Slave. Slave tidak menerima perubahan dari pengguna, tetapi hanya menerapkan perubahan ke log dari Master. Harap dicatat bahwa Guru tidak mengirim salinan setiap waktu, tetapi mengirim perubahan. Budak menggulung perubahan ini dan menerima salinan data yang sama seperti di Master.
Parameter yang sangat penting dari sistem yang direplikasi adalah permintaan dijalankan secara sinkron atau asinkron. Apa itu Permintaan Sinkron? Ini adalah saat Master mengirimkan permintaan ke replika sinkron, ke Slave sinkron, dan menunggu Slave mengatakan: "Ya, saya setuju" - dan Master mengembalikan konfirmasi. Baru setelah itu Master akan mengembalikan jawaban kepada pengguna. Jika replika tersebut tidak sinkron, Master mengirimkan permintaan ke replika tersebut, tetapi segera memberi tahu pengguna bahwa "Itu saja, saya tulis." Mari kita lihat cara kerjanya.
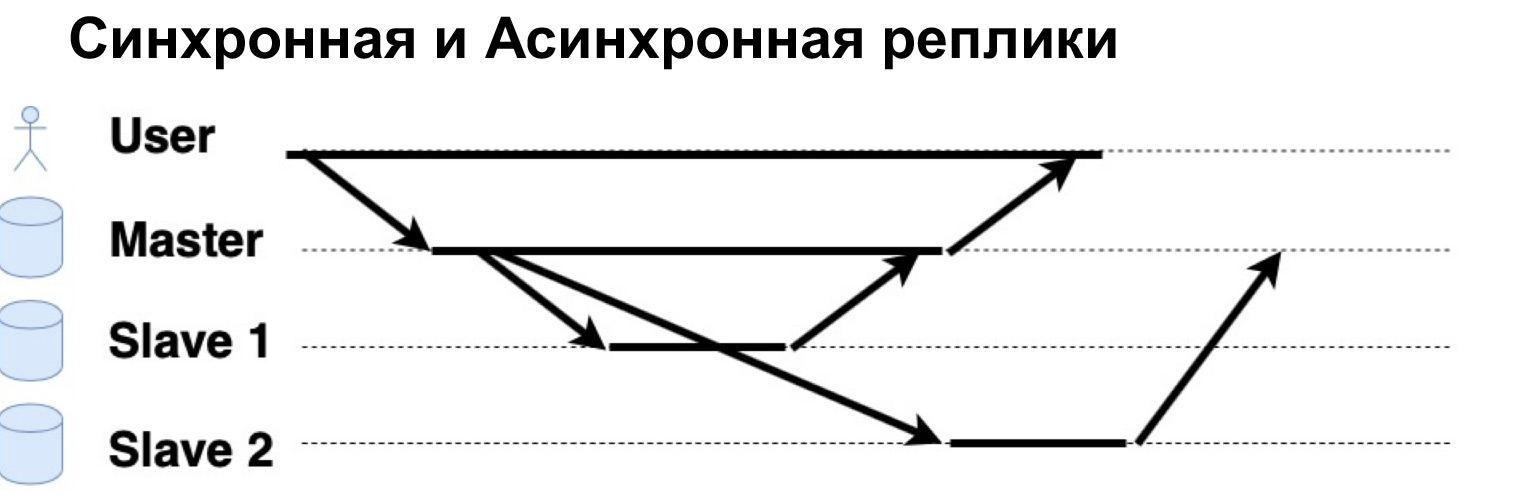
Ada pengguna yang telah menulis data ke Master. Guru mengirimnya ke dua replika, menunggu tanggapan dari replika sinkron dan segera memberikan jawaban kepada pengguna. Replika asynchronous direkam dan berkata kepada Master: "Ya, tidak apa-apa, datanya sudah tertulis."
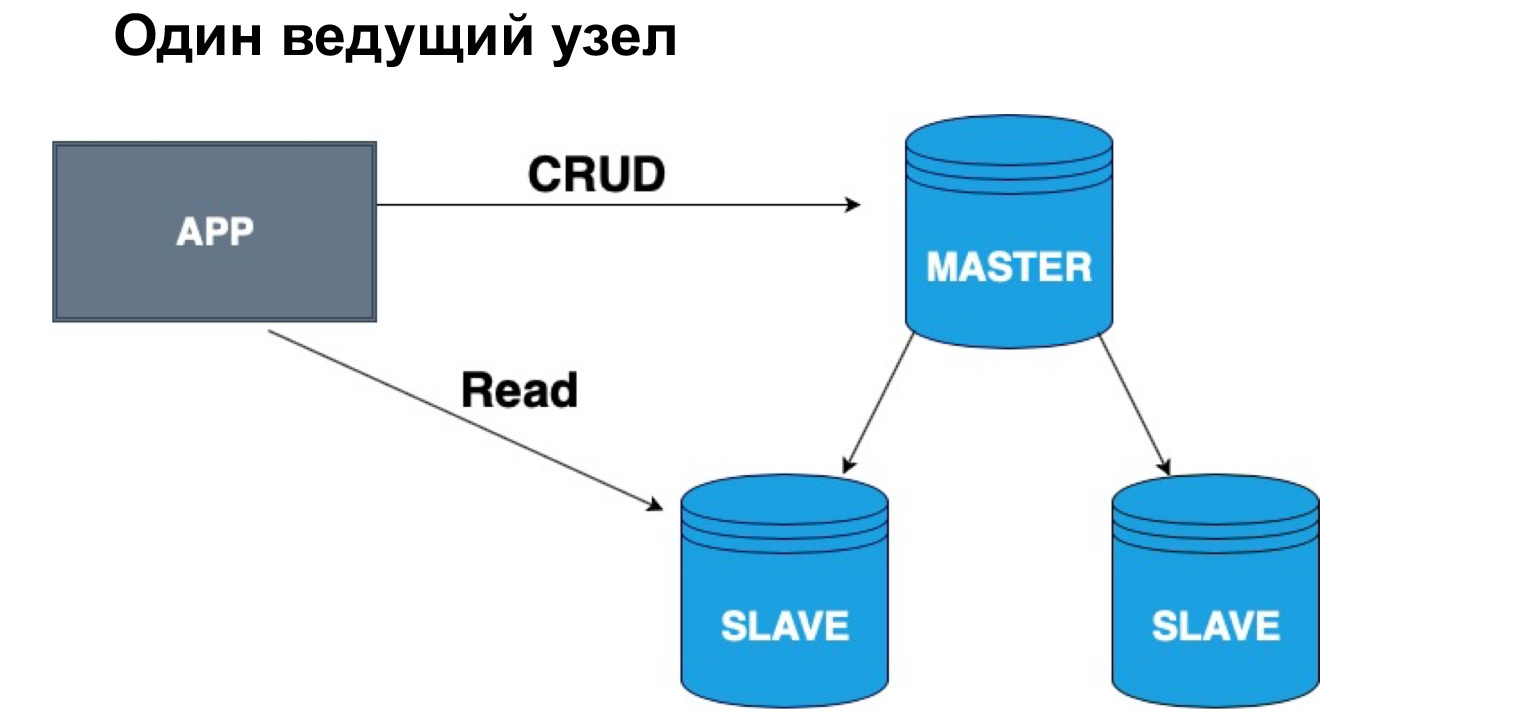
Dalam hierarki seperti itu, Tuan dan Budak, kita dapat memiliki satu atau beberapa kepala. Jika kita memiliki satu node master, akan sangat mudah untuk menulis padanya, tetapi Anda dapat membaca dari replika sinkron. Mengapa tepatnya dari sinkron? Karena replika sinkron memastikan bahwa data adalah yang terbaru dengan akurasi maksimum.
Ketika kueri diterapkan ke data, operasi dari log, juga membutuhkan waktu. Oleh karena itu, jika akurasi seratus persen dari data yang ingin Anda terima penting bagi Anda, Anda harus pergi membaca, untuk memilih di Master. Jika Anda tidak kritis bahwa data mungkin tiba dengan sedikit penundaan, Anda dapat membaca dari Slave sinkron. Jika Anda sama sekali tidak kritis terhadap relevansi data, Anda dapat membaca, termasuk dari replika asinkron, dengan demikian mengeluarkan Master dan replika sinkron dari permintaan.
Replikasi juga dapat memiliki banyak master. Aplikasi yang berbeda dapat menulis ke kepala yang berbeda, dan Master ini kemudian menyelesaikan konflik satu sama lain.
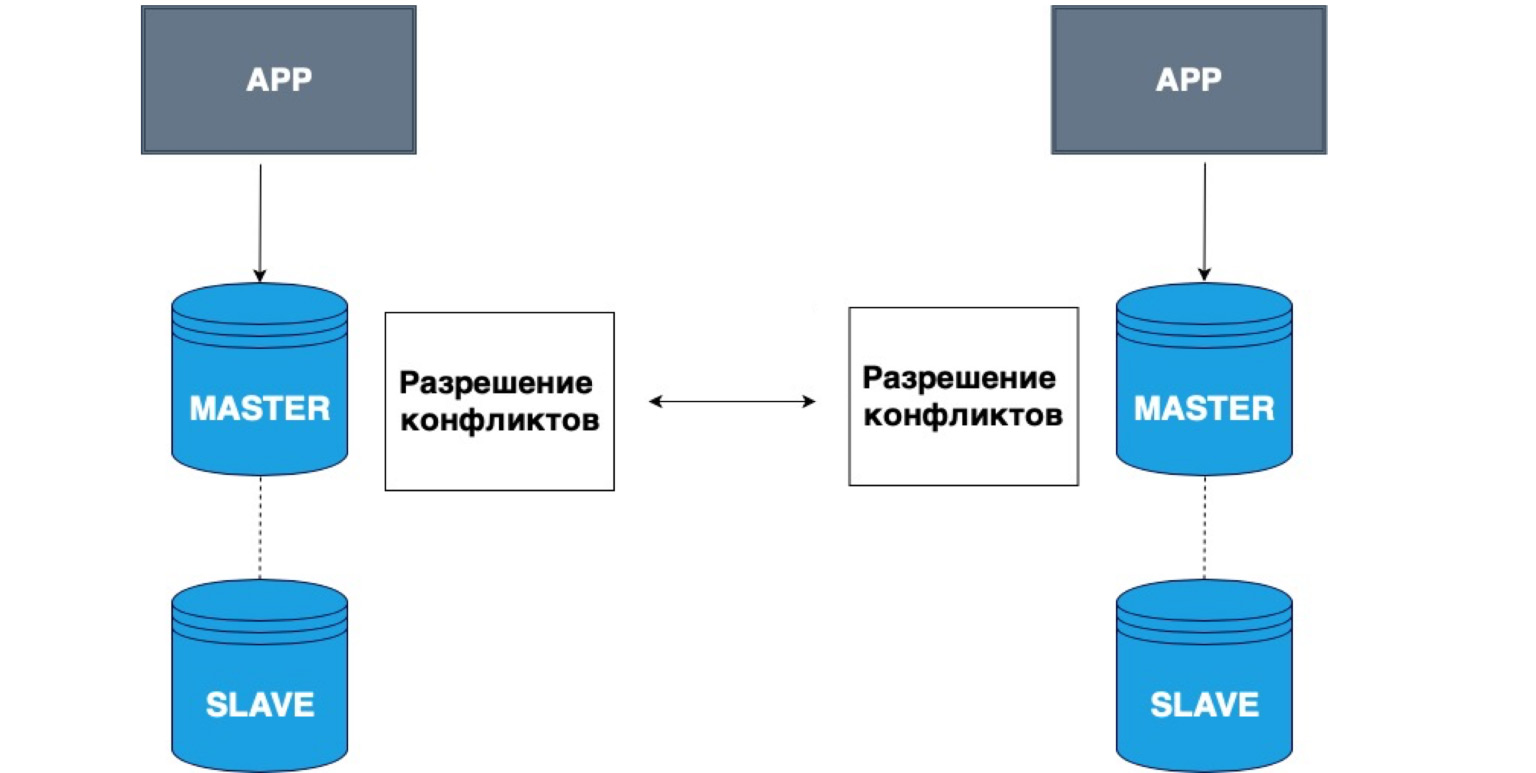
Contoh yang sangat sederhana untuk menggunakan data semacam itu adalah semua jenis aplikasi offline. Misalnya, Anda memiliki kalender di ponsel Anda. Anda telah terputus dari jaringan dan merekam acara di kalender Dalam hal ini, penyimpanan lokal Anda, telepon Anda, adalah Master. Itu telah menyimpan datanya sendiri, dan ketika jaringan Master muncul, salinan lokal Anda dan salinan di server akan menyelesaikan konflik dan menggabungkan data ini.
Ini adalah contoh replikasi yang sangat sederhana. Ini sering digunakan untuk pengeditan kolaboratif dokumen online, atau ketika ada kemungkinan besar kehilangan jaringan.
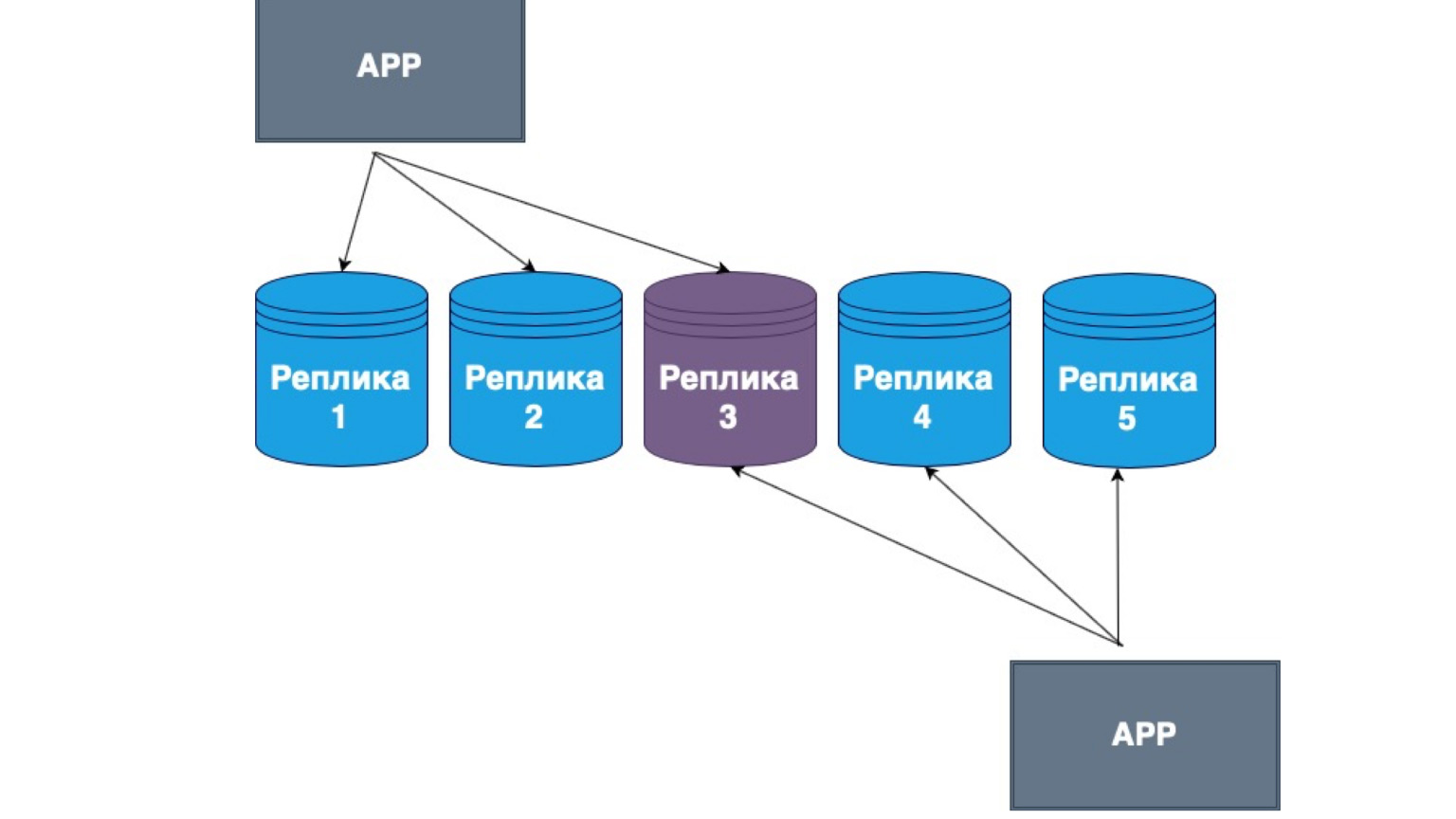
Replikasi tak bertuan juga ada. Apa itu? Ini adalah replikasi, di mana klien mengirim sendiri data ke sebagian besar replika dan membacanya juga dari sebagian besar replika. Di sini Anda dapat melihat replika tengah kami adalah persimpangan dari Baca dan pembaruan kami.
Artinya, kami menjamin bahwa setiap kali kami membaca data, kami akan masuk ke setidaknya satu replika, di mana datanya paling relevan. Dan di antara mereka sendiri, replika membangun mekanisme pertukaran informasi dengan log utama perubahan dan konflik antar replika. Dalam kasus ini, seringkali klien gemuk yang diimplementasikan. Jika dia menerima data dari replika yang berisi perubahan yang lebih baru dari yang lain, maka dia hanya mengirim data ke replika lain atau menyelesaikan konflik.

Apa yang penting untuk diketahui tentang replikasi? Titik utama replikasi adalah toleransi kesalahan sistem, ketersediaan tinggi server Anda. Apa pun yang terjadi pada database, sistem akan tersedia, pengguna Anda akan dapat menulis data, dan ketika koneksi dengan Master atau replika lain dipulihkan, semua data juga akan dipulihkan.
Replikasi sangat membantu dalam membongkar server dan mendistribusikan ulang permintaan baca dari Master ke replika. Kami dapat menskalakan pembacaan ini, membuat lebih banyak replika baca, dan membuat sistem kami lebih cepat. Anda juga dapat mereplikasi kueri analitik jangka panjang yang kompleks yang memerlukan banyak kunci dan dapat memengaruhi ketersediaan sistem.
Menggunakan aplikasi offline sebagai contoh, kami melihat bagaimana Anda dapat menyimpan data tersebut dan menyelesaikan konflik. Dalam kasus replika sinkron, mungkin ada Replikasi lag, yaitu jeda waktu. Dalam kasus replika asinkron, replika tersebut hampir selalu ada. Artinya, saat Anda membaca data dari replika asinkron, Anda harus memahami bahwa itu mungkin tidak relevan.
Menurut hierarki, saya lupa mengatakan bahwa ketika ada satu Master menunggu respons dari replika sinkron, logis untuk mengasumsikan bahwa jika semua replika sinkron, dan beberapa tiba-tiba menjadi tidak tersedia, maka sistem kami tidak akan dapat menyimpan permintaan tersebut. Kemudian Master akan mengirim kita ke Slave sinkron pertama, menerima tanggapan, meminta Slave kedua, tidak menerima tanggapan, dan akhirnya harus memutar kembali seluruh transaksi.
Oleh karena itu, dalam sistem seperti itu, sebagai aturan, satu replika dibuat sinkron, dan sisanya asinkron. Replika sinkron memastikan bahwa data Anda masih ada di tempat lain. Artinya, selain Master, yang dengannya sesuatu dapat terjadi, kami menjamin bahwa setidaknya ada satu node lagi yang berisi salinan lengkap dari log transaksi yang sama persis, data yang sama.
Replika asinkron, di sisi lain, tidak menjamin integritas data. Jika kita hanya memiliki replika asinkron dan Master telah memutuskan sambungan, maka mereka mungkin tertinggal, datanya mungkin belum sampai di sana. Dalam kasus seperti itu, sebagai aturan, mereka membangun hierarki sedemikian rupa sehingga kita memiliki Master, satu replika sinkron dan sisanya asinkron, atau kita memiliki Master dan semua replika tidak sinkron, jika persistensi data tidak penting bagi kami.
Ada satu "tetapi": semua replika harus memiliki konfigurasi yang sama. Jika kita berbicara tentang PostgreSQL sebagai contoh, mereka harus memiliki versi yang sama dari PostgreSQL itu sendiri, karena versi database yang berbeda dapat memiliki format log operasi yang berbeda. Dan jika replika muncul dari versi yang berbeda, replika tersebut mungkin tidak membaca operasi yang ditulis oleh basis lain.
Apa replika itu? Ini adalah salinan lengkap dari semua data. Mari kita bayangkan bahwa ada begitu banyak data sehingga server tidak dapat menanganinya. Apa solusi pertama?
Keputusan pertama adalah membeli mesin yang lebih mahal dengan lebih banyak memori, dengan CPU yang lebih besar, dengan disk yang lebih besar. Keputusan ini akan benar untuk sebagian besar, selama Anda tidak menghadapi masalah tingginya biaya besi. Suatu hari nanti akan terlalu mahal untuk membeli mobil baru, atau tidak akan ada tempat untuk tumbuh. Ada sejumlah besar data yang secara fisik tidak mungkin dimasukkan ke dalam satu mesin.
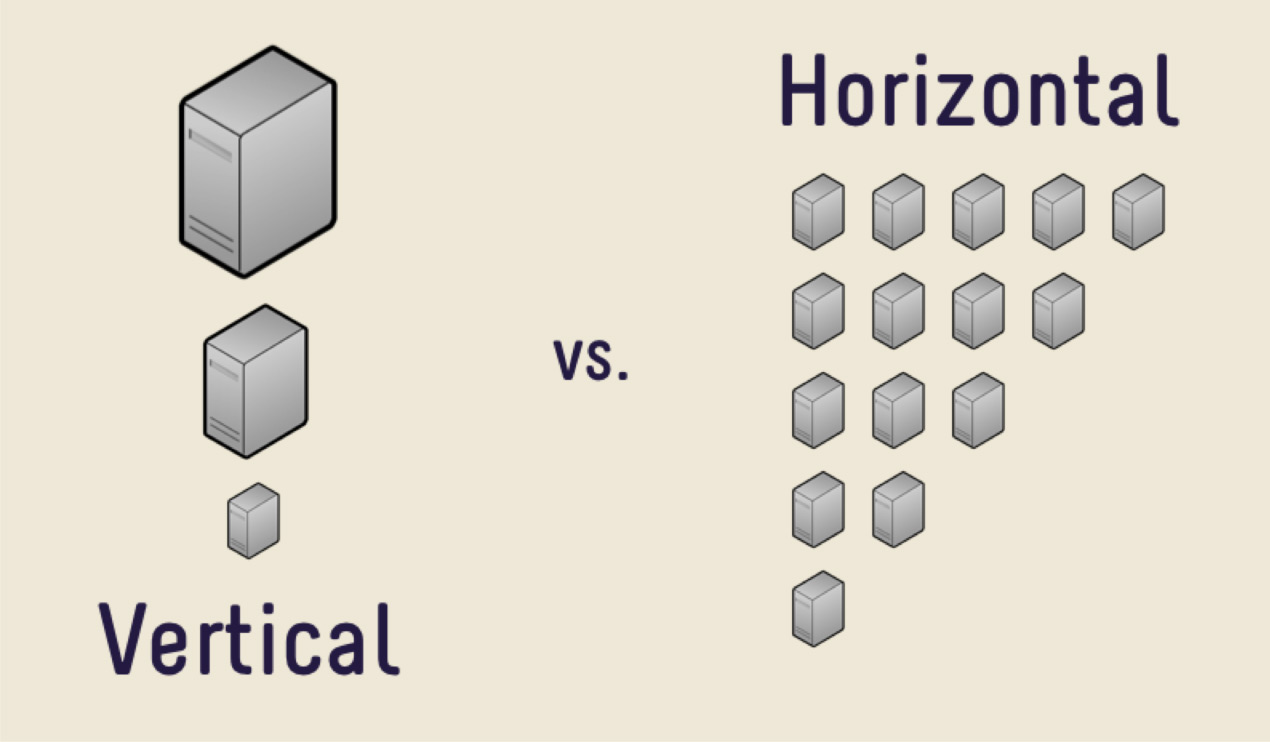
Dalam kasus seperti itu, Anda dapat menggunakan penskalaan horizontal. Apa yang kita lihat sebelumnya, peningkatan kinerja per mesin, adalah penskalaan vertikal. Peningkatan jumlah mesin adalah penskalaan horizontal.
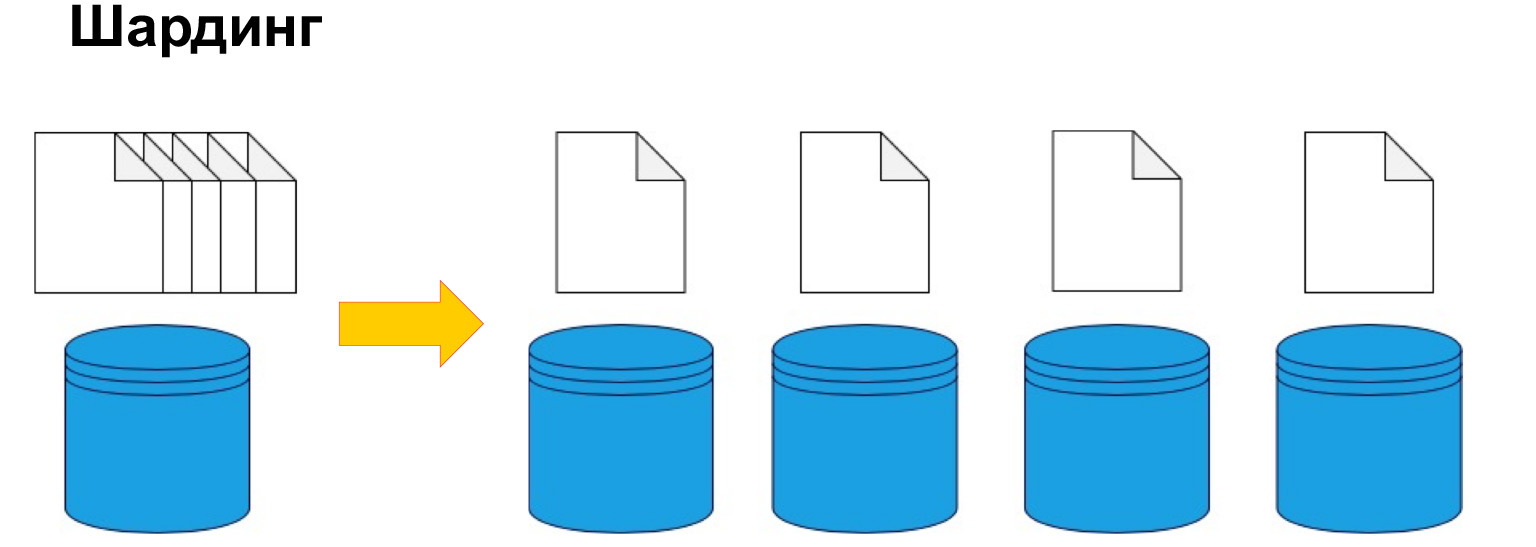
Untuk membagi data dengan mesin, sharding atau, dengan kata lain, digunakan partisi. Yaitu, membagi data menjadi beberapa bagian dan blok menurut kunci, berdasarkan ID, berdasarkan tanggal. Kita akan membicarakan ini lebih lanjut, ini adalah salah satu parameter kunci, tetapi intinya adalah membagi data sesuai dengan kriteria tertentu dan mengirimkannya ke mesin yang berbeda. Dengan demikian, mesin kami mungkin menjadi kurang efisien, tetapi sistem masih dapat berfungsi dan menerima data dari mesin yang berbeda.
Untuk memahami secara umum di mana data itu, Anda memerlukan tabel korespondensi tertentu dari pecahan, salinan, dan data kami.
Ada kalanya penyimpanan data khusus tidak digunakan dan klien berjalan bergantian ke setiap pecahan dan memeriksa apakah ada data yang cocok dengan permintaannya.
Ada lapisan perangkat lunak khusus yang menyimpan pengetahuan tertentu tentang pecahan mana yang berada dalam rentang datanya. Dan, oleh karena itu, ia berjalan tepat di sana, ke simpul di mana data yang diperlukan berada.

Ada klien yang gemuk. Ini terjadi ketika kita tidak menjahit klien itu sendiri ke dalam lapisan terpisah, tetapi kita menjahit ke dia data tentang bagaimana data kita dibagi.
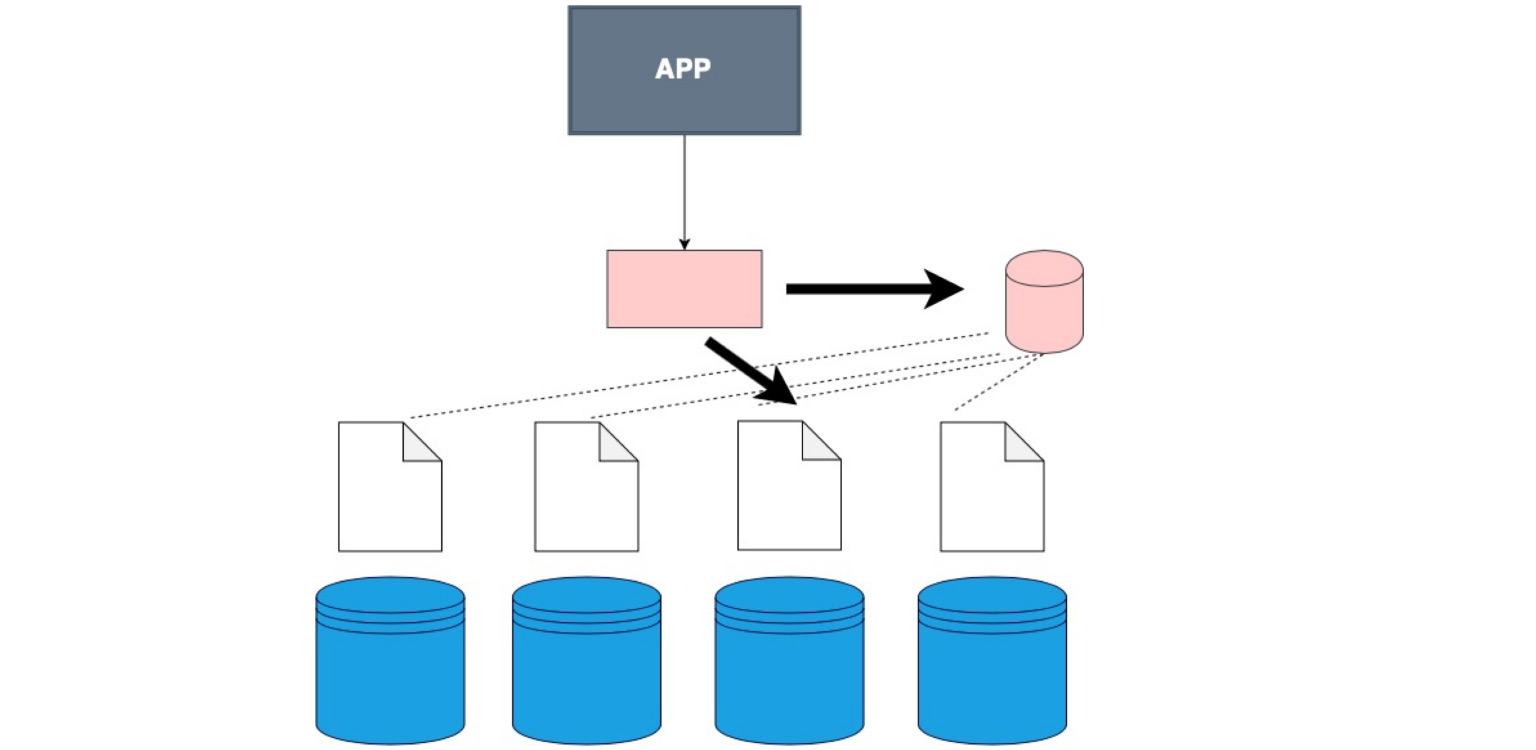
Inilah masalahnya. Ngomong-ngomong, ini yang paling sering digunakan. Hal yang baik adalah bahwa aplikasi kita, klien kita, bahkan kode yang Anda tulis, tidak tahu bahwa tabel tersebut di-shard, meskipun kami menunjukkan ini di konfigurasi, di database itu sendiri. Kami hanya memberi tahu dia - pilih, dan sudah di database itu sendiri, ada pembagian menjadi pecahan dan pemahaman tentang di mana harus memilih. Di sini, dalam kode itu sendiri, Anda menentukan dari mana harus membaca data.
Ada layanan khusus yang membantu menyusun dan memperbarui informasi secara umum. Sulit untuk membuatnya konsisten dan relevan. Kami telah memilih sesuatu, merekam data baru. Atau ada sesuatu yang berubah dan kami perlu mengarahkan permintaan kami dengan sangat benar. Ada layanan khusus untuk mengkoordinasikan permintaan. Salah satunya adalah Zookeper. Anda dapat melihat cara kerjanya secara umum. Struktur yang sangat menarik. Mereka menghemat banyak saraf dan waktu bagi para pengembang.
Yang penting, aspek apa yang perlu diingat saat Anda melakukan partisi? Penting untuk memahami kunci apa yang akan kita gunakan untuk sharding. Pengumpulan kembali semua data ini cukup mahal, jadi sangat penting untuk tidak membuat kesalahan tentang bagaimana data tersebut berpotensi digunakan di masa mendatang. Jika kami melakukan sharding dengan baik dan benar, dengan kueri yang paling sering digunakan, kami akan selalu tahu replika mana yang harus dituju.
Misalnya, jika kita, menurut ID pengguna, menyimpan semua data mereka pada replika tertentu, maka kita memahami bahwa kita dapat mengunjungi replika yang satu ini dan melakukan semua penggabungan di atasnya. Tapi menyimpannya dengan ID bukanlah ide yang paling keren. Sekarang saya akan memberi tahu Anda alasannya.
Jika kami salah mengidentifikasi kunci dalam pemartisian, jika kami memiliki kueri yang sangat kompleks, maka kami benar-benar harus pergi ke pecahan yang berbeda, menggabungkan semua data dan baru kemudian memberikannya ke aplikasi. Untungnya, sebagian besar DBMS melakukan ini untuk kami. Tapi overhead seperti apa yang akan muncul di bawah pertanyaan yang ditulis dengan buruk? Atau di bawah sharding, yang rusak pada node yang salah?
Tentang ID. Jika sistem hanya bekerja dengan pengguna baru dan kami memiliki peningkatan ID, maka semua permintaan akan menuju ke node terakhir.
Apa yang terjadi? Tiga mesin lainnya yang sedang berjalan akan diam. Dan mobil ini hanya akan terbakar - yang disebut titik panas. Ini adalah hambatan dari sistem potensial Anda, tempat yang bahkan mungkin menolak koneksi.
Oleh karena itu, saat kami menentukan kunci sharding, sangat penting untuk memahami seberapa seimbang node ini nantinya. Hash sangat sering digunakan, ini adalah pengaturan data yang kurang lebih netral dan seimbang. Tetapi jika Anda memiliki fungsi hash pada tombol, maka Anda tidak akan dapat memilih, misalnya, berdasarkan rentang. Ini logis, karena rentang tidak dapat disebarkan ke dalam pecahan yang berbeda.
Berdasarkan tanggal - sama. Jika, misalnya, kita menyebarkan analitik dan membuat pecahan berdasarkan tanggal, maka, tentu saja, pecahan apa pun sepuluh tahun yang lalu tidak akan digunakan sama sekali. Itu tidak menguntungkan bagi kami. Dan selalu sangat mahal untuk membangun kembali data dan melakukan overharden.
Saya akan menjawab pertanyaan yang datang sebelumnya. Apakah lebih baik untuk menentukan indeks atau membuat pecahan? Indeks, tentu saja.
Lihat, pecahan adalah mesin terpisah dengan infrastruktur yang diangkat seluruhnya. Dan komponen tengah ini berisi sesuatu yang mirip dengan indeks. Ada pencarian cepat berdasarkan parameter - kemana, kemana harus pergi. Berikut rasionya. Tapi jika ada sharding, gambar akhirnya akan seperti ini:

Ada aplikasi, semacam head yang tahu kemana harus pergi. Dan ada pecahan, yang masing-masing replikanya dikonfigurasi. Ini adalah overhead yang sangat besar jika tidak ada banyak data. Artinya, Anda hanya perlu menggunakan sharding ketika Anda benar-benar telah mencapai batas penskalaan vertikal, ketika membeli mesin yang lebih mahal tidak relevan dengan data atau pendapatan Anda. Kemudian Anda dapat membeli beberapa mobil berbeda yang lebih murah dan membangun arsitektur seperti itu di atasnya.
Untuk apa replika itu, menurut saya, sudah jelas: karena pecahan rusak, itu adalah bagian dari database, tetapi agak unik. Mereka hanya ditemukan di tempat-tempat ini. Kami juga memecahnya menjadi salinan, yang membuat node kami toleran terhadap kesalahan dan memastikan terhadap masalah.

Hal yang paling penting: sharding digunakan tepat di tempat Anda tidak hanya ingin memecah data ke dalam klasifikasi, tetapi juga di tempat yang benar-benar memiliki banyak data.
Sekarang mari kita pelajari lebih dalam model data dan melihat bagaimana data dapat disimpan.
Basis data relasional yang kita lihat sebelumnya memiliki sejumlah besar keuntungan, karena, pertama-tama, mereka sangat umum dan dapat dimengerti oleh semua orang. Mereka secara visual menunjukkan hubungan antara objek dan memberikan integritas.
Tetapi ada sisi negatifnya: mereka membutuhkan struktur yang jelas. Ada tabel di mana kita harus mendorong semua data. Jika Anda melihat semua informasi dan fakta yang kami kumpulkan secara umum, keduanya sangat berbeda. Artinya, kita bisa bekerja dengan data produk, dengan data pengguna, pesan, dan sebagainya. Data ini sangat membutuhkan struktur dan integritas yang jelas. Database relasional sangat ideal untuk mereka.
Tetapi misalkan kita memiliki, misalnya, log operasi atau deskripsi objek, di mana setiap objek memiliki karakteristik yang berbeda. Kami, tentu saja, dapat menuliskannya ke sebuah jason dalam database relasional dan senang bahwa kami telah mengembangkannya tanpa akhir.
Dan kita dapat melihat skema lain, di sistem penyimpanan lain. NoSQL adalah singkatan yang sangat mencolok, bahkan secara langsung provokatif - "no SQL". Bagaimana itu terjadi?
Ketika orang-orang menghadapi fakta bahwa database relasional tidak berhasil di mana-mana, mereka mengadakan konferensi yang membutuhkan tagar, dan mereka menghasilkan #NoSQL. Itu berakar. Kemudian mereka mulai mengatakan bukan "tidak ada SQL", tetapi "bukan hanya SQL". Itu hanya segala sesuatu yang tidak relasional: keluarga besar database berbeda yang tidak terstruktur, skematis, dan tabular kaku seperti database relasional.
Keluarga model data non-relasional dibagi menjadi empat jenis: basis data nilai-kunci, berorientasi dokumen, kolom dan grafik. Mari kita pertimbangkan masing-masing poin ini, cari tahu data mana yang lebih baik untuk disimpan di mana dari mereka dan untuk apa mereka digunakan.

Nilai kunci. Ini yang paling sederhana. Ini kamusnya, ini rasionya. Ini adalah database di mana datanya disimpan oleh kunci, dan tidak peduli apa yang ada di bawah kunci tertentu. Kami memiliki kunci itu sendiri dan datanya dapat berupa struktur yang sederhana dan jauh lebih kompleks. Hal yang baik tentang database semacam itu adalah, seperti indeks, ia mencari data dengan sangat cepat. Inilah mengapa nilai kunci sangat sering digunakan untuk cache. Keuntungannya adalah nilai kami dapat berbeda di kunci yang berbeda.
Kita dapat menggunakan kunci tersebut, misalnya, untuk menyimpan sesi pengguna. Pengguna mengklik, kami menulis ini dalam nilainya. Ini adalah skema, model data tanpa skema tertentu, struktur nilai. Karena ini adalah struktur yang sangat sederhana, cepat dan mudah untuk diukur. Kami sudah memiliki kuncinya, dan kami dapat dengan mudah memecahnya, membuat hashnya. Ini adalah salah satu database yang paling dapat diskalakan.
Contohnya adalah Redis, Memcached, Amazon DynamoDB, Riak, LevelDB. Anda dapat melihat fitur implementasi penyimpanan nilai kunci.

Database dokumen sangat mirip dengan nilai kunci dalam beberapa penggunaannya. Tapi unit mereka adalah dokumen. Ini adalah struktur yang kompleks di mana kita dapat memilih data tertentu, melakukan operasi massal: Penyisipan massal, Pembaruan massal.
Setiap dokumen dapat menyimpan sendiri, sebagai aturan, XML, JSON atau BSON - JSON yang disimpan dalam biner. Tapi sekarang hampir selalu JSON atau BSON. Ini juga semacam key-value pair, Anda bisa membayangkannya sebagai tabel di mana setiap baris memiliki karakteristik tertentu, dan kita bisa mendapatkan sesuatu darinya dengan menggunakan kunci ini.
Keuntungan dari database berorientasi dokumen adalah bahwa mereka memiliki ketersediaan dan fleksibilitas data yang sangat tinggi. Di dokumen apa pun, di JSON apa pun, Anda benar-benar dapat menulis kumpulan data apa pun. Dan mereka sangat sering digunakan - misalnya, saat Anda perlu membuat katalog dan saat setiap produk dalam katalog dapat memiliki karakteristik yang berbeda.
Atau, misalnya, profil pengguna. Seseorang menunjukkan film favoritnya, seseorang - makanan favoritnya. Agar tidak menempel semuanya dalam satu bidang, yang akan menyimpannya tidak jelas apa, kita dapat menulis semuanya di JSON dari basis dokumen.
Model lain yang nyaman untuk menyimpan data adalah database kolom. Mereka juga disebut kolom, database kolom.

Ini adalah struktur yang sangat menarik yang digunakan, menurut saya, di hampir semua proyek besar dan kompleks. Basis data seperti itu menyiratkan bahwa kita menyimpan data pada disk tidak dalam baris, tetapi dalam kolom. Digunakan untuk penelusuran yang sangat cepat pada sejumlah besar data. Sebagai aturan - untuk analitik, saat Anda perlu memilih nilai hanya dari kolom tertentu.
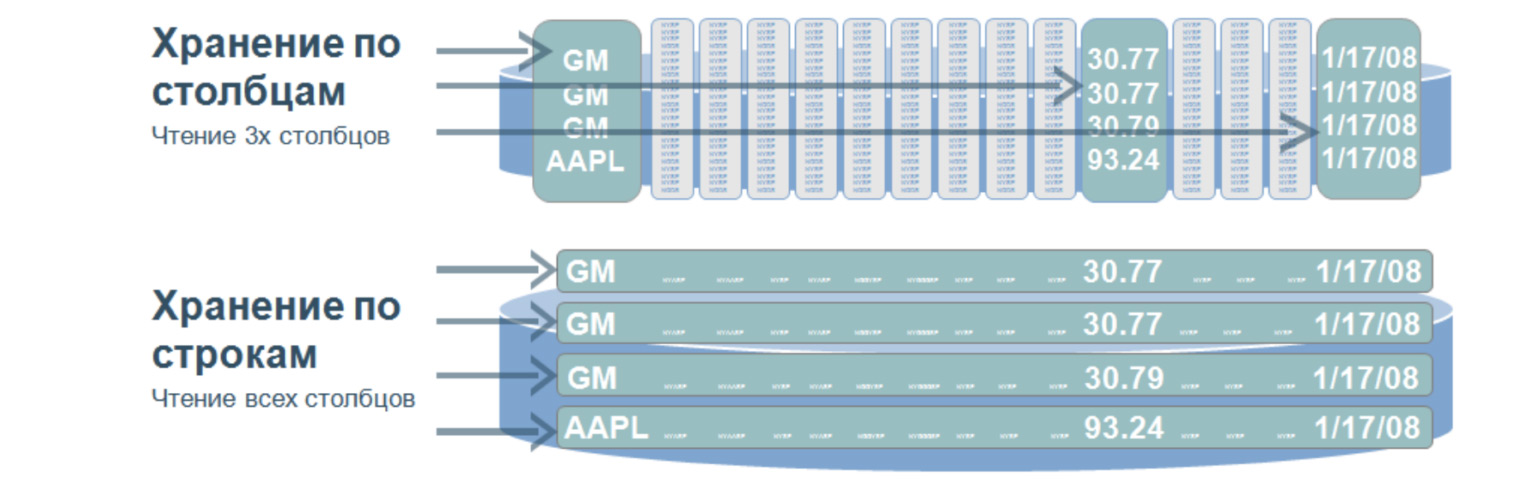
Bayangkan kita memiliki meja besar. Dan jika kita menyimpan data dalam beberapa baris, maka akan menjadi seperti di bawah ini: sejumlah besar baris. Untuk memilih bahkan tiga parameter dari tabel ini, kita perlu memeriksa seluruh tabel. Dan ketika kita menyimpan nilai berdasarkan kolom, kemudian ketika memilih dengan tiga nilai, kita hanya perlu melalui tiga baris, secara kasar, karena kolom kita ditulis seperti ini. Melewati ketiga baris ini, kita segera mendapatkan nomor urut dari nilai yang kita butuhkan dan mendapatkannya dari kolom lain.
Apa keuntungan dari database seperti itu? Karena fakta bahwa mereka menelusuri data dalam jumlah kecil, mereka memiliki kecepatan pemrosesan kueri yang sangat tinggi dan fleksibilitas data yang tinggi, karena kita dapat menambahkan sejumlah kolom tanpa mengubah strukturnya. Di sini, tidak seperti database relasional, kita tidak perlu memaksakan data kita ke dalam frame tertentu.
Kolom yang paling populer mungkin adalah Cassandra, HBase, dan ClickHouse. Uji mereka. Sangat menarik untuk membalik rasio baris dan kolom di kepala Anda. Dan ini sangat efisien dan akses cepat ke data dalam jumlah besar.

Ada juga keluarga database grafik. Mereka juga mengandung node dan edge. Tepi digunakan untuk memperlihatkan hubungan, seperti dalam database relasional. Tetapi basis grafik dapat tumbuh tanpa batas ke arah yang berbeda. Karena itu, lebih fleksibel. Ini memiliki kecepatan pencarian yang sangat tinggi, karena tidak perlu memilih dan menggabungkan semua tabel. Node kami segera memiliki tepi yang menunjukkan hubungan ke semua objek yang berbeda.
Untuk apa database ini digunakan? Paling sering - hanya untuk menunjukkan hubungan. Misalnya, di jejaring sosial, Anda dapat menjawab pertanyaan siapa mengikuti siapa. Kami segera memiliki tautan ke semua pengikut dari orang yang tepat. Masih sangat sering database ini digunakan untuk mengidentifikasi skema penipuan, karena ini juga terkait dengan mendemonstrasikan hubungan transaksi satu sama lain. Misalnya, Anda dapat melacak kapan kartu bank yang sama digunakan di kota lain atau ketika orang lain memasukkan akun pengguna lain dari alamat IP yang sama.
Hubungan kompleks inilah yang membantu menyelesaikan situasi tidak biasa yang sering digunakan untuk menganalisis interaksi dan hubungan semacam itu.
Database non-relasional tidak menggantikan database relasional. Mereka hanya berbeda. Format data berbeda dan logika berbeda dari pekerjaan mereka, tidak lebih buruk dan tidak lebih baik. Ini hanya pendekatan yang berbeda untuk data lain. Dan ya, database non-relasional banyak digunakan. Anda tidak perlu takut padanya; sebaliknya, Anda perlu mencobanya.
Jika Anda membuat cache, maka, tentu saja, ambil semacam Redis, nilai kunci yang sederhana dan cepat. Jika Anda memiliki log dalam jumlah besar untuk dianalisis, Anda dapat memasukkannya ke ClickHouse atau ke beberapa basis kolom, yang kemudian akan sangat nyaman untuk dicari. Atau tuliskan ke dasar dokumen, karena mungkin ada arti dokumen yang berbeda. Ini juga bisa berguna untuk seleksi.
Pilih model data berdasarkan data apa yang akan Anda gunakan. Baik relasional maupun non-relasional. Jelaskan datanya. Dengan cara ini Anda dapat menemukan penyimpanan yang paling sesuai yang dapat Anda skalakan di masa mendatang.

Hari ini Anda belajar banyak tentang berbagai masalah dan cara menyimpan data. Saya akan mengulangi sekali lagi apa yang saya katakan di awal: Anda tidak perlu mengetahui semuanya secara mendetail, Anda tidak perlu mempelajari satu hal. Jika Anda tertarik - tentu saja Anda bisa. Tetapi penting untuk mengetahui bahwa itu ada secara umum, pendekatan apa yang ada dan bagaimana Anda dapat berpikir secara umum. Jika Anda membutuhkan toleransi kesalahan, masuk akal untuk membuat replika. Misalkan saya menulis data, tetapi tidak melihatnya. Kemudian, mungkin, komentar saya agak terlambat. Tidak perlu menemukan kembali roda - sudah ada banyak solusi siap pakai untuk berbagai tugas. Perluas wawasan Anda, dan jika bug atau masalah lain muncul, Anda akan memahami dengan tepat di mana kegagalan terjadi oleh karakteristik bug, dan Anda dapat menemukan solusi melalui mesin pencari. Terima kasih atas perhatian Anda.