Ini sering terjadi ketika ada banyak konversi, harganya dapat diterima, dan penjualan tidak tumbuh bahkan turun. Di sini analitik "sebelum laba per klik" tidak lagi cukup untuk mencari tahu alasannya. Dan kemudian analisis "sebelum keuntungan dari manajer" datang untuk menyelamatkan. Karena betapapun idealnya iklan disiapkan, pelanggan pertama-tama berinteraksi dengan manajer, dan baru kemudian membuat keputusan. Keberhasilan bisnis Anda bergantung pada kualitas pekerjaan karyawan Anda.
Sistem analitik tradisional menggunakan CRM untuk mencatat fakta penjualan / kontak dengan manajer. Namun, pendekatan ini hanya menyelesaikan sebagian dari masalah: pendekatan ini mengevaluasi efisiensi karyawan "pada intinya". Artinya, ini menunjukkan penjualan dan konversi, tetapi membiarkan komunikasi dengan klien "berlebihan". Tetapi hasilnya tergantung pada tingkat komunikasi.
Untuk mengisi kekosongan tersebut, kami telah mengembangkan alat yang secara otomatis akan menghubungkan setiap panggilan ke manajer yang menanganinya. Anda tidak harus menggunakan CRM dan layanan pihak ketiga. Faktanya, sistem kami memberi tag "nama manajer" pada setiap panggilan masuk.
Jadi kepala departemen penjualan / layanan pelanggan akan mengontrol kualitas pekerjaan, menemukan area masalah, dan membangun analitik. Segmentasi cepat panggilan ke manajer yang menerimanya akan membantu dalam hal ini.
Rumusan masalah
Tugas yang kami tentukan sendiri adalah sebagai berikut: biarkan sistem mengetahui pola ucapan semua manajer yang dapat menerima panggilan. Kemudian untuk panggilan baru Anda perlu menandai manajer, yang suaranya paling "mirip" dalam percakapan dari daftar orang yang dikenal.
Dalam hal ini, dianggap apriori bahwa panggilan telepon baru berhasil. Artinya, percakapan antara pengelola dan klien benar-benar terjadi. Secara informal, tugas ini dapat dikaitkan dengan kelas tugas "mengajar dengan guru", yaitu klasifikasi.
Sebagai objek - dalam beberapa cara rekaman audio vektorisasi (digital), di mana hanya suara pengelola yang berbunyi. Responsnya adalah label kelas (nama manajer). Maka tugas dari algoritma penandaan adalah:
- Ekstraksi fitur penting dari file audio
- Memilih algoritma klasifikasi yang paling sesuai
- Mempelajari algoritma dan model manajer penyimpanan
- Mengevaluasi kualitas algoritme dan mengubah parameternya
- Memberi tag (mengklasifikasikan) panggilan baru
Beberapa dari tugas ini termasuk dalam sub-tugas terpisah. Hal ini disebabkan oleh kondisi spesifik di mana algoritme harus beroperasi. Panggilan telepon biasanya berisik. Seorang klien dalam satu percakapan dapat berkomunikasi dengan beberapa manajer. Selain itu, ini tidak akan dilakukan sama sekali, dan panggilan sering kali menyertakan IVR, dll.
Misalnya, tugas menandai panggilan baru dapat dibagi menjadi:
- Memeriksa panggilan untuk sukses (fakta bahwa ada panggilan)
- Membagi stereo menjadi trek mono
- Penyaringan kebisingan
- Identifikasi area dengan ucapan (menyaring musik dan suara asing lainnya)
Di masa mendatang, kami akan membicarakan setiap subtugas tersebut secara terpisah. Sementara itu, kami akan merumuskan kendala teknis yang kami terapkan pada data masukan, solusi yang dihasilkan, serta pada algoritma klasifikasi itu sendiri.
Kendala solusi
Kebutuhan akan pembatasan sebagian ditentukan oleh teknik dan persyaratan kompleksitas implementasi, dan juga oleh keseimbangan antara universalitas algoritme dan keakuratan operasinya.
Batasan pada file masukan dan file contoh pelatihan:
- Format - wav atau wave (Anda selanjutnya dapat mengode ulang ke mp3)
- Stereo kemudian harus dibagi menjadi 2 trek - operator dan klien
- Kecepatan pengambilan sampel - 16.000 Hz ke atas
- Kedalaman bit - dari 16 bit dan banyak lagi
- File untuk melatih model harus berdurasi minimal 30 detik dan hanya berisi suara manajer tertentu
- , , ,
Semua persyaratan di atas, kecuali yang terakhir, dirumuskan sebagai hasil dari serangkaian percobaan yang dilakukan pada tahap penyiapan algoritme. Kombinasi ini telah terbukti paling efektif dalam meminimalkan kemungkinan kesalahan, yaitu kesalahan klasifikasi dalam kondisi penyetelan yang mudah.
Misalnya, jelas bahwa semakin panjang file dalam set pelatihan, pengklasifikasi akan semakin akurat. Tetapi semakin sulit untuk menemukan file seperti itu di log panggilan (contoh pelatihan kami). Oleh karena itu, durasi 30 detik merupakan kompromi antara akurasi dan kompleksitas pengaturan. Persyaratan terakhir (sukses) diperlukan. Sistem tidak boleh menandai seorang manajer ke panggilan yang sebenarnya tidak ada percakapan.
Keterbatasan algoritme mengarah pada solusi berikut:
- , . « ». . - , .
- . , , .
Persyaratan pertama berasal dari eksperimen. Kemudian ternyata manajer yang "tidak dikenal" mempersulit arsitektur solusi tersebut. Untuk ini, perlu untuk memilih ambang batas yang setelah itu karyawan akan diklasifikasikan sebagai "tidak dikenal". Selain itu, manajer "tidak dikenal" mengurangi akurasi sebesar 10 poin persentase.
Selain itu, kesalahan jenis kedua muncul saat manajer yang dikenal diklasifikasikan sebagai tidak diketahui. Probabilitas kesalahan seperti itu adalah 7-10%, tergantung pada jumlah kesalahan yang diketahui. Persyaratan ini bisa disebut esensial. Ini mewajibkan tuner algoritme untuk menunjukkan semua manajer dalam sampel pelatihan. Dan juga perkenalkan model karyawan baru disana dan singkirkan mereka yang berhenti.
Persyaratan kedua berasal dari pertimbangan praktis dan arsitektur algoritme yang kami gunakan. Singkatnya, algoritme membagi audio yang dianalisis menjadi fragmen ucapan dan "membandingkan" masing-masing dengan semua model pengelola terlatih satu per satu.
Akibatnya, "mini-tag" ditetapkan ke setiap mini-fragmen. Dengan pendekatan ini, ada kemungkinan besar bahwa beberapa fragmen dikenali dengan tidak benar. Misalnya, jika tetap berisik atau panjangnya terlalu pendek.
Kemudian, jika semua "tag mini" ditampilkan di solusi akhir, selain tag dari pengelola sebenarnya, banyak tag "sampah" yang akan ditampilkan. Oleh karena itu, hanya tag paling "sering" yang ditampilkan.
Deskripsi data masukan / keluaran
Kami akan membagi data input menjadi 2 jenis:
Data pada input algoritma untuk menghasilkan model manajer (data untuk pelatihan):
- File audio + label kelas
Data pada masukan dari algoritma penandaan (data untuk pengujian / operasi normal):
- Data eksternal (file audio)
- Data internal (model tersimpan)
Outputnya juga dibagi menjadi 2 jenis:
- Data keluaran dari algoritma pembangkitan model
- Model manajer terlatih
- Keluaran dari algoritme pemberian tag
- Tag manajer
Pada masukan algoritme, dalam mode apa pun operasinya, file audio yang memenuhi persyaratan diterima. Mereka ada di bagian "pembatasan".
Pada input dari algoritma pembangkitan model, diperbolehkan bahwa beberapa file input berhubungan dengan satu kelas (manajer). Tetapi satu file tidak dapat berhubungan dengan banyak manajer. Nama label kelas dapat ditempatkan di nama file. Atau buat saja direktori terpisah untuk setiap karyawan.
Algoritme pelatihan model berbasis input menghasilkan banyak model yang dapat dimuat selama pelatihan. Jumlahnya sesuai dengan jumlah tag yang berbeda dalam kumpulan file audio.
Jadi, jika ada file M yang ditandai dengan n label kelas yang berbeda, algoritme membuat n model manajer pada tahap pelatihan:
- Model_manager_1.pkl
- Model_manager_2.pkl
- ...
- Model_manager_n.pkl
di mana alih-alih " manajer _... " adalah nama kelas.
Masukan ke algoritme penandaan adalah file audio tak berlabel, di mana apriori ada percakapan antara manajer dan klien, serta n model karyawan. Akibatnya, algoritme mengembalikan tag - nama kelas dari manajer yang paling "masuk akal".
Pemrosesan awal data
File audio sudah diproses sebelumnya. Ini berurutan dan berjalan baik dalam mode pemberian tag dan dalam mode pelatihan model:
- Memeriksa keberhasilan panggilan - hanya pada tahap pemberian tag
- Membagi stereo menjadi 2 track mono dan selanjutnya bekerja hanya dengan track operator
- Digitalisasi - ekstraksi parameter sinyal audio
- Penyaringan kebisingan
- Menghapus jeda "panjang" - mengidentifikasi fragmen dengan suara
- Memfilter fragmen non-ucapan - hapus musik, latar belakang, dll.
- Perpaduan fragmen dengan ucapan (hanya pada tahap pelatihan)
Kami tidak akan memikirkan tahap pemeriksaan keberhasilan. Ini adalah subjek untuk artikel terpisah. Singkatnya, inti dari tahapan tersebut adalah bahwa panggilan tersebut diklasifikasikan menurut ada tidaknya percakapan "orang yang hidup" di dalamnya. Yang kami maksud dengan "orang yang hidup" adalah klien dan manajer, bukan asisten suara, musik, dll
. Keberhasilan panggilan diperiksa menggunakan pengklasifikasi yang terlatih khusus dengan ambang batas eksternal - "durasi percakapan minimum setelah panggilan dianggap berhasil".
Pada tahap kedua, file stereo dibagi menjadi 2 track: manajer dan klien. Pemrosesan lebih lanjut dilakukan hanya untuk jalur karyawan.
Pada tahap digitalisasi, parameter "fitur" diekstraksi dari jalur operator, yang merepresentasikan representasi digital dari sinyal. Kami di Calltouch menggunakan komponen kapur-cepstral. Selain itu, parameter diekstrak pada fragmen yang sangat kecil, yang disebut lebar jendela (0,025 detik). Semua fitur dinormalisasi pada saat bersamaan.
nfft=2048 //
appendEnergy = False
def get_MFCC(sr,audio): // , sr=16000 -
features = mfcc.mfcc(audio, sr, 0.025, 0.01, 13, 26, nfft, 0, 1000, appendEnergy)
features = preprocessing.scale(features)
return features
count = 1
features = np.asarray(()) //
for path in file_paths: //
path = path.strip()
sr,audio = read(source + path) //
vector = get_MFCC (sr, audio) #
if features.size == 0:
features = vector
else:
features = np.vstack((features, vector))Pada keluaran, setiap file audio berubah menjadi larik, di mana karakteristik mel-cepstral dari setiap fragmen 0,025 detik direkam baris demi baris.
Pemrosesan lebih lanjut dari file tersebut terdiri dari penyaringan suara, menghilangkan jeda yang lama (bukan jeda antar suara), dan mencari ucapan. Tugas-tugas ini dapat diselesaikan dengan menggunakan berbagai alat. Dalam solusi kami, kami menggunakan metode dari pustaka pyaudioanalysis:
clear_noise(fname,outname,ch_n) # .- fname - file masukan
- nama luar - file keluaran
- ch_n - jumlah saluran
Pada output, kita mendapatkan file outname, yang berisi suara, dibersihkan dari noise, dari file fname.
silenceRemoval(x, Fs, stWin, stStep) # « »- x - larik masukan (sinyal digital)
- Fs - laju sampling
- stWin - lebar jendela ekstraksi fitur
- stStep - ukuran langkah offset
Pada keluaran, kita mendapatkan larik dengan bentuk:
[l_1, r_1]
[l_2, r_2]
[l_3, r_3]
…
[l_N, r_N] di
mana l_i adalah waktu mulai dari segmen ke-i (detik), r_i adalah waktu akhir dari segmen ke-i (detik ).
detect_audio_segment(x,thrs) # .- x - larik masukan (sinyal digital)
- jam - panjang minimum (dalam detik) dari fragmen ucapan yang terdeteksi
Pada output, kita mendapatkan orang-fragmen [l_i, r_i] , yang mengandung pidato yang berlangsung dari thrs detik.
Sebagai hasil dari
pra-pemrosesan,
file audio input diubah ke dalam bentuk larik: [l_1, r_1] [l_2, r_2] [l_3, r_3] … [l_N, r_N], di
mana setiap fragmen adalah interval waktu dari file ucapan yang dihapus.
Dengan demikian, kita dapat mencocokkan setiap fragmen tersebut dengan matriks fitur (karakteristik kecil-cepstral), yang akan digunakan untuk melatih model dan pada tahap pemberian tag.
Metode / Algoritma yang Digunakan
Seperti disebutkan di atas, solusi kami didasarkan pada pustaka pyaudioanalysis.py yang ditulis dengan Python 2.7. Karena fakta bahwa solusi umum kami diimplementasikan dengan Python 3.7, beberapa fungsi perpustakaan telah dimodifikasi dan diadaptasi untuk versi bahasa ini.
Secara umum, algoritme alat untuk memberi tag pengelola dapat dibagi menjadi 2 bagian:
- Pelatihan manajer model
- Pemberian tag
Penjelasan yang lebih rinci dari setiap bagian terlihat seperti ini.
Pelatihan manajer model:
- Memuat sampel pelatihan
- Pemrosesan awal data
- Menghitung jumlah kelas
- Membuat model manajer untuk setiap kelas
- Menyimpan model
Penandaan:
- Pemuatan panggilan
- Memeriksa panggilan untuk sukses
- Pra-pemrosesan panggilan yang berhasil
- Memuat semua model manajer terlatih
- Klasifikasi setiap fragmen panggilan yang diproses
- Menemukan model manajer yang paling mungkin
- Pemberian tag
Kami telah membahas secara detail tugas preprocessing data. Sekarang mari kita lihat metode untuk membuat model manajer.
Kami menggunakan algoritma GMM (Gaussian Mixture Model) sebagai model . Ini memodelkan data kami dengan asumsi bahwa mereka adalah realisasi variabel acak dengan distribusi yang dijelaskan oleh campuran Gaussians - masing-masing dengan variansnya sendiri dan ekspektasi matematisnya sendiri.
Diketahui bahwa algoritma yang paling umum untuk menemukan parameter optimal dari campuran semacam itu adalah algoritma EM (Expectation Maximization) . Dia membagi masalah sulit untuk memaksimalkan kemungkinan variabel acak multidimensi menjadi serangkaian masalah pemaksimalan dimensi yang lebih rendah.
Sebagai hasil dari serangkaian percobaan, kami sampai pada parameter algoritma GMM berikut:
gmm = GMM(n_components = 16, n_iter = 200, covariance_type='diag',n_init = 3)Model seperti itu dibuat untuk setiap manajer, dan kemudian dilatih - parameternya disesuaikan dengan data tertentu.
gmm.fit(features)Selanjutnya, model disimpan untuk digunakan pada tahap penandaan:
picklefile = path[path.find('/')+1:path.find('.')]+".gmm"
pickle.dump(gmm,open(dest + picklefile,'wb'))Pada tahap pemberian tag, kami memuat model yang disimpan sebelumnya:
gmm_files = [os.path.join(modelpath,fname) for fname in
os.listdir(modelpath) if fname.endswith('.gmm')]modelpath adalah direktori tempat kita menyimpan model.
models = [pickle.load(open(fname,'rb'),encoding='latin1') for fname in gmm_files]Dan juga memuat nama model (ini adalah tag kami):
speakers = [fname.split("/")[-1].split(".gmm")[0] for fname
in gmm_files]File audio yang diunggah yang ingin Anda beri tag adalah vektor dan diproses sebelumnya. Selanjutnya, setiap fragmen dengan ucapan di dalamnya dibandingkan dengan model terlatih dan pemenangnya ditentukan dalam hal kemungkinan logaritma maksimum:
log_likelihood = np.zeros(len(models)) #
for i in range(len(models)):
gmm = models[i] #
scores = np.array(gmm.score(vector))
log_likelihood[i] = scores.sum() # i –
winner = np.argmax(log_likelihood) #
print("\tdetected as - ", speakers[winner])Hasilnya, algoritme kami memiliki kira-kira kesimpulan berikut:
dimulai pada: 1,92 diakhiri dengan: 8,72
[-10400.93604115 -12111.38278205]
terdeteksi sebagai - Olga
dimulai pada: 9,22 diakhiri dengan: 15,72
[-10193.80504138 -11911.11095894]
terdeteksi sebagai - Olga
dimulai pada: 26,7 berakhir di: 29.82
[-4867.97641331 -5506.44233563]
terdeteksi sebagai - Ivan
dimulai di: 33.34 diakhiri dengan:
47.14 [-21143.02629011 -24796.44582627]
terdeteksi sebagai - Ivan
dimulai di: 52.56 diakhiri dengan: 59.24
[-10916.83282132 -12124.26855 start538]
terdeteksi
sebagai53855 start538 in: 116.32 diakhiri dengan:
134.56 [-36764.94876054 -34810.38959083]
terdeteksi sebagai - Olga
dimulai di: 151.18 diakhiri dengan: 154.86
[-8041.33666572 -6859.14253903]
terdeteksi sebagai - Olga
dimulai di: 159.7 diakhiri dengan: 162.92
[-6421.72235531 -5983.90538059]
terdeteksi sebagai - Olga
dimulai di: 185.02 diakhiri dengan: 208.7
…
dimulai di: 442.04 diakhiri dengan: 445.5
[-7451.0289772 -6286.6619 ]
terdeteksi sebagai - Olga
*******
PEMENANG - Olga
Contoh ini mengasumsikan bahwa setidaknya ada 2 kelas - [Olga, Ivan] . File audio dipotong menjadi beberapa segmen [1.92, 8.72], [9.22, 15.72],…, [442.04, 445.5] dan model yang paling sesuai ditentukan untuk masing-masing segmen.
Logaritma kemungkinan kumulatif ditunjukkan dalam tanda kurung di samping setiap potongan:[-10400.93604115 -12111.38278205] , elemen pertama adalah kemungkinan Olga , dan yang kedua adalah Ivan . Karena argumen pertama lebih besar dari argumen kedua, segmen ini diklasifikasikan sebagai Olga . Pemenang akhir ditentukan oleh mayoritas "suara" dari fragmen.
hasil
Awalnya, kami merancang algoritme dengan asumsi bahwa manajer "tidak dikenal" mungkin ada dalam panggilan masuk - yaitu, modelnya tidak ada dalam sampel pelatihan.
Untuk mendeteksi pengguna seperti itu, kita perlu memasukkan beberapa metrik pada vektor log_likelihood . Sehingga nilai tertentu akan menunjukkan bahwa kemungkinan besar fragmen ini tidak cukup dijelaskan oleh model yang ada. Kami menyarankan metrik berikut sebagai pengujian:
Leukl=(log_likelihood-np.min(log_likelihood))/(np.max(log_likelihood)-np.min(log_likelihood))
-sorted(-np.array(Leukl))[1]<TNilai ini menunjukkan seberapa “merata” distribusi skor dalam vektor log_likelihood . Keseragaman perkiraan (kedekatannya satu sama lain) berarti bahwa semua model berperilaku dengan cara yang sama dan tidak ada pemimpin yang jelas.
Ini menunjukkan bahwa kemungkinan besar semua model salah dan kami memiliki manajer yang tidak berada pada tahap pelatihan. Hubungan antara T dan kualitas klasifikasi ditunjukkan pada gambar.
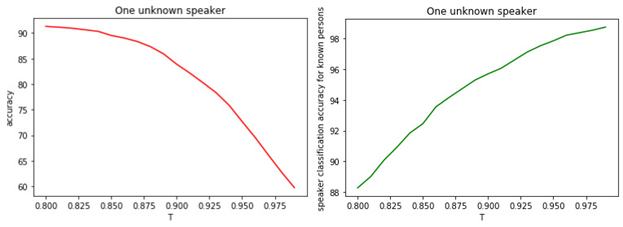
Angka: 1.
a) Akurasi klasifikasi biner dari manajer yang dikenal dan tidak dikenal.
b) Keakuratan klasifikasi manajer terkenal.

Angka: 2.
a) Proporsi manajer terkenal yang ditugaskan ke kelas manajer terkenal.
b) Proporsi manajer yang tidak diketahui yang ditugaskan ke kelas yang diketahui.
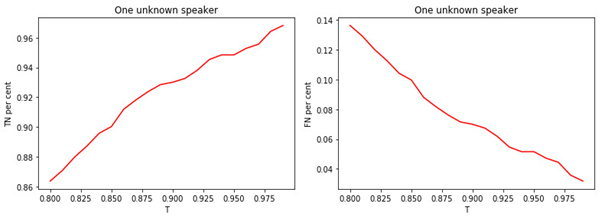
Angka: 3.
a) Bagian dari manajer yang tidak diketahui ditugaskan ke kelas yang tidak diketahui.
b) Proporsi manajer terkenal yang ditugaskan ke kelas yang tidak diketahui.
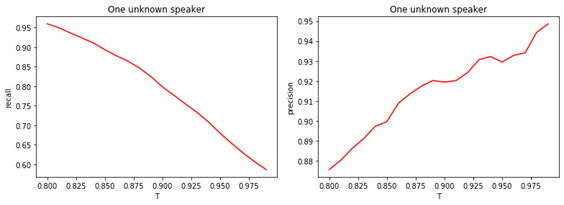
Angka: 4.
a) Kelengkapan klasifikasi biner (recall).
b) Presisi klasifikasi biner (presisi).
Hubungan antara nilai ambang T dan kualitas klasifikasi (penandaan) terlihat jelas. Semakin besar T (semakin ketat kondisi untuk menugaskan seorang manajer ke kelas yang tidak diketahui), semakin kecil kemungkinan seorang manajer terkenal untuk diklasifikasikan sebagai tidak diketahui. Namun, kemungkinan besar "kehilangan" manajer yang tidak dikenal.
Nilai ambang optimal adalah 0,8 . Karena kami mengklasifikasikan manajer terkenal dengan akurasi sekitar 90%dan tentukan "yang tidak diketahui" dengan akurasi 81% . Jika kita berasumsi bahwa semua manajer "familiar" bagi kita, maka keakuratannya sekitar 98% .
kesimpulan
Dalam artikel tersebut, kami menjelaskan gagasan umum tentang fungsi alat kami untuk mengidentifikasi manajer dalam panggilan. Tentu saja, kami tidak berpura-pura bahwa algoritme kami optimal dan tidak dapat ditingkatkan.
Ini didasarkan pada sejumlah asumsi yang tidak selalu dipenuhi dalam praktik. Misalnya, kami mungkin menemukan manajer yang tidak dikenal jika tidak ada data tentang dia. Atau dua atau lebih manajer dapat melakukan percakapan dengan klien "dengan porsi yang sama". Dari sudut pandang algoritme, petunjuk berikut untuk perbaikan lebih lanjut dapat diusulkan:
- Memilih model algoritme yang berbeda dari GMM
- Mengoptimalkan parameter GMM
- Memilih metrik yang berbeda untuk mendeteksi manajer baru
- Telusuri fitur paling signifikan dari sinyal ucapan
- Kombinasi berbagai alat preprocessing audio dan optimalisasi parameter metode ini