
DBMS dalam hal ini bekerja sesuai dengan prinsip yang sama - " kata mereka menggali, dan saya menggali ". Permintaan Anda tidak hanya dapat memperlambat proses yang berdekatan, terus-menerus menempati sumber daya prosesor, tetapi juga "menjatuhkan" seluruh database sepenuhnya, "memakan" semua memori yang tersedia. Oleh karena itu, merupakan tanggung jawab pengembang untuk melindungi dari rekursi tak terbatas .
Di PostgreSQL, kemampuan untuk menggunakan kueri rekursif telah
WITH RECURSIVEmuncul sejak jaman dahulu di versi 8.4, tetapi Anda masih dapat secara teratur menghadapi kueri "tak berdaya" yang berpotensi rentan. Bagaimana cara menyelamatkan diri dari masalah seperti ini?
Jangan menulis kueri rekursif
Dan tulis non-rekursif. Hormat kami, K.O.Faktanya, PostgreSQL menyediakan sejumlah besar fungsionalitas yang dapat Anda gunakan untuk menghindari rekursi.
Gunakan pendekatan yang berbeda secara fundamental untuk tugas tersebut
Terkadang Anda bisa melihat masalah "dari sisi lain". Saya memberikan contoh situasi seperti itu di artikel "SQL HowTo: 1000 dan salah satu cara agregasi" - perkalian sekumpulan angka tanpa menggunakan fungsi agregat khusus:
WITH RECURSIVE src AS (
SELECT '{2,3,5,7,11,13,17,19}'::integer[] arr
)
, T(i, val) AS (
SELECT
1::bigint
, 1
UNION ALL
SELECT
i + 1
, val * arr[i]
FROM
T
, src
WHERE
i <= array_length(arr, 1)
)
SELECT
val
FROM
T
ORDER BY --
i DESC
LIMIT 1;Permintaan semacam itu dapat diganti dengan varian dari para ahli matematika:
WITH src AS (
SELECT unnest('{2,3,5,7,11,13,17,19}'::integer[]) prime
)
SELECT
exp(sum(ln(prime)))::integer val
FROM
src;Gunakan generate_series sebagai ganti loop
Katakanlah kita dihadapkan pada tugas menghasilkan semua prefiks yang mungkin untuk sebuah string
'abcdefgh':
WITH RECURSIVE T AS (
SELECT 'abcdefgh' str
UNION ALL
SELECT
substr(str, 1, length(str) - 1)
FROM
T
WHERE
length(str) > 1
)
TABLE T;Tepatnya, apakah Anda memerlukan rekursi di sini? .. Jika Anda menggunakan
LATERALdan generate_series, bahkan CTE tidak diperlukan:
SELECT
substr(str, 1, ln) str
FROM
(VALUES('abcdefgh')) T(str)
, LATERAL(
SELECT generate_series(length(str), 1, -1) ln
) X;Ubah struktur database
Misalnya, Anda memiliki tabel posting forum dengan tautan ke siapa yang menjawab seseorang atau utas di jejaring sosial :
CREATE TABLE message(
message_id
uuid
PRIMARY KEY
, reply_to
uuid
REFERENCES message
, body
text
);
CREATE INDEX ON message(reply_to);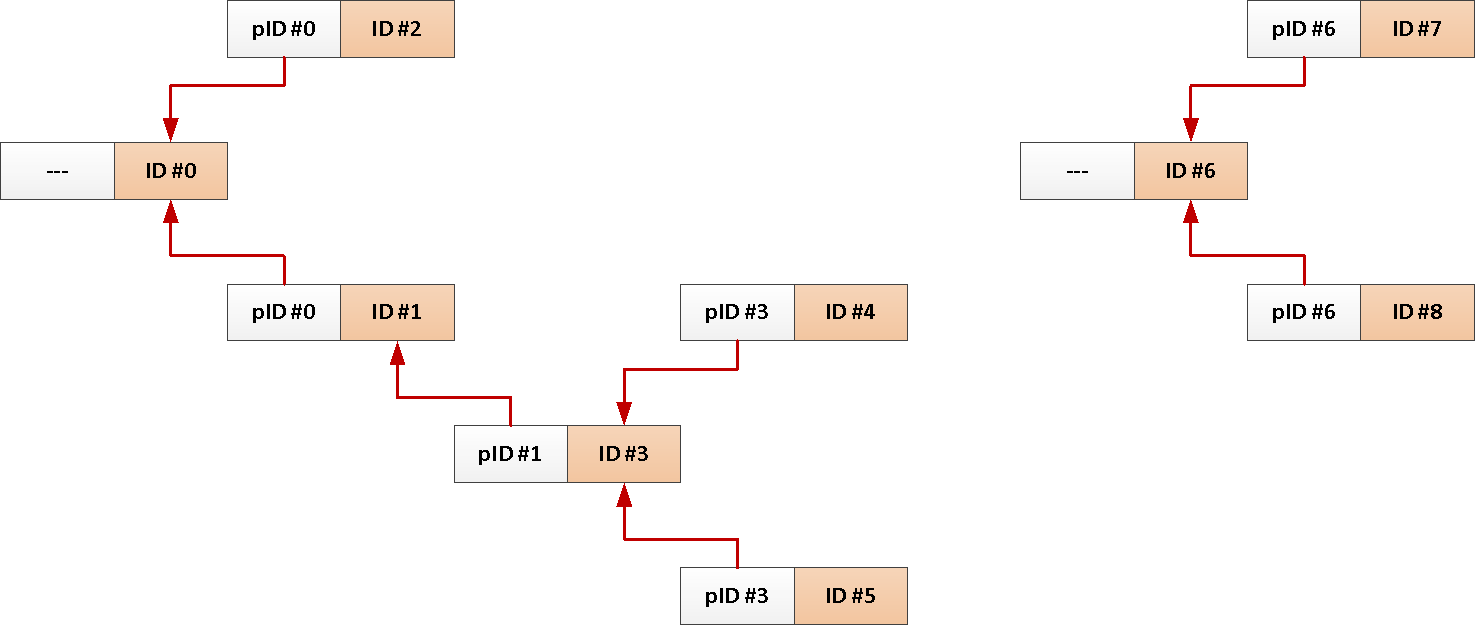
Nah, permintaan umum untuk mengunduh semua pesan pada satu topik terlihat seperti ini:
WITH RECURSIVE T AS (
SELECT
*
FROM
message
WHERE
message_id = $1
UNION ALL
SELECT
m.*
FROM
T
JOIN
message m
ON m.reply_to = T.message_id
)
TABLE T;Tetapi karena kita selalu membutuhkan seluruh subjek dari pesan root, mengapa tidak menambahkan pengenalnya ke setiap posting secara otomatis?
--
ALTER TABLE message
ADD COLUMN theme_id uuid;
CREATE INDEX ON message(theme_id);
--
CREATE OR REPLACE FUNCTION ins() RETURNS TRIGGER AS $$
BEGIN
NEW.theme_id = CASE
WHEN NEW.reply_to IS NULL THEN NEW.message_id --
ELSE ( -- ,
SELECT
theme_id
FROM
message
WHERE
message_id = NEW.reply_to
)
END;
RETURN NEW;
END;
$$ LANGUAGE plpgsql;
CREATE TRIGGER ins BEFORE INSERT
ON message
FOR EACH ROW
EXECUTE PROCEDURE ins();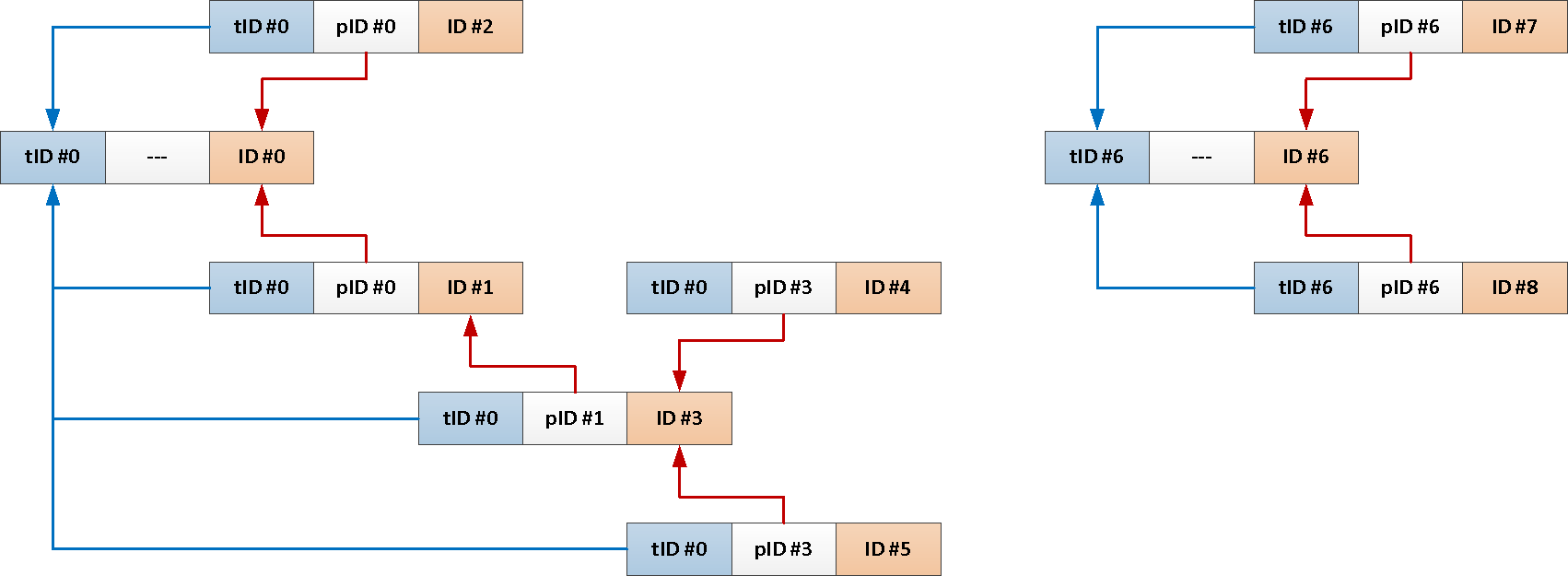
Sekarang seluruh kueri rekursif kami dapat direduksi menjadi hanya ini:
SELECT
*
FROM
message
WHERE
theme_id = $1;Gunakan "kendala" yang diterapkan
Jika kami tidak dapat mengubah struktur database karena beberapa alasan, mari kita lihat apa yang dapat kami andalkan sehingga bahkan adanya kesalahan dalam data tidak menyebabkan rekursi tak terbatas.
Penghitung "kedalaman" rekursi
Kami hanya meningkatkan penghitung satu per satu di setiap langkah rekursi sampai batas tercapai, yang kami anggap jelas tidak memadai:
WITH RECURSIVE T AS (
SELECT
0 i
...
UNION ALL
SELECT
i + 1
...
WHERE
T.i < 64 --
)Pro: Saat kami mencoba melakukan loop, kami masih akan membuat tidak lebih dari batas iterasi yang ditentukan "secara mendalam".
Kontra: Tidak ada jaminan bahwa kami tidak akan memproses rekaman yang sama lagi - misalnya, pada kedalaman 15 dan 25, lalu akan ada setiap +10. Dan tidak ada yang menjanjikan apa pun tentang "luasnya".
Secara formal, rekursi semacam itu tidak akan terbatas, tetapi jika pada setiap langkah jumlah record meningkat secara eksponensial, kita semua tahu betul bagaimana akhirnya ...

Penjaga "cara"
Satu per satu kami menambahkan semua pengenal objek yang kami temui di sepanjang jalur rekursi ke dalam sebuah larik, yang merupakan "jalur" unik untuk itu:
WITH RECURSIVE T AS (
SELECT
ARRAY[id] path
...
UNION ALL
SELECT
path || id
...
WHERE
id <> ALL(T.path) --
)Pro: Jika ada loop di data, kami benar-benar tidak akan memproses ulang record yang sama di jalur yang sama.
Kontra: Tetapi pada saat yang sama kita dapat melewati, secara harfiah, semua catatan tanpa mengulang.
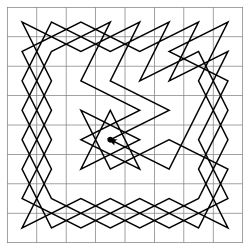
Batasan panjang jalur
Untuk menghindari situasi rekursi "berkeliaran" pada kedalaman yang tidak dapat dipahami, kita dapat menggabungkan dua metode sebelumnya. Atau, jika kita tidak ingin mendukung kolom yang tidak diperlukan, tambahkan kondisi kelanjutan rekursi dengan perkiraan panjang jalur:
WITH RECURSIVE T AS (
SELECT
ARRAY[id] path
...
UNION ALL
SELECT
path || id
...
WHERE
id <> ALL(T.path) AND
array_length(T.path, 1) < 10
)Pilih metode sesuai selera Anda!