( NLP) oleh Tim Dettmers, Ph.D. Deep Learning (DL) adalah area dengan permintaan daya komputasi yang tinggi, jadi pilihan GPU Anda akan sangat menentukan pengalaman Anda di bidang ini. Tapi properti apa yang penting untuk dipertimbangkan saat membeli GPU baru? Memori, inti, inti tensor? Bagaimana cara membuat pilihan terbaik dalam hal nilai uang? Dalam artikel ini, saya akan menganalisis secara detail semua pertanyaan ini, kesalahpahaman umum, memberi Anda pemahaman intuitif tentang GPU, serta beberapa tip untuk membantu Anda membuat pilihan yang tepat.
Artikel ini ditulis untuk memberi Anda beberapa tingkat pemahaman tentang GPU, termasuk. seri Ampere baru dari NVIDIA. Anda punya pilihan:
- Jika Anda tidak tertarik dengan detail GPU, apa sebenarnya yang membuat GPU cepat, dan apa yang unik tentang GPU baru dari seri NVIDIA RTX 30 Ampere, Anda dapat melewati awal artikel, langsung ke grafik tentang kecepatan dan kecepatan per biaya $ 1, serta bagian rekomendasi. Ini adalah inti dari artikel ini dan konten paling berharga.
- Jika Anda tertarik dengan pertanyaan spesifik, maka saya akan membahasnya paling sering di bagian terakhir artikel.
- Jika Anda membutuhkan pemahaman mendalam tentang cara kerja GPU dan Tensor Cores, cara terbaik Anda adalah membaca artikel ini dari awal hingga akhir. Bergantung pada pengetahuan Anda tentang mata pelajaran tertentu, Anda dapat melewati satu atau dua bab.
Setiap bagian didahului dengan ringkasan singkat untuk membantu Anda memutuskan apakah akan membacanya secara keseluruhan atau tidak.
Kandungan
GPU?
GPU,
/ L1 /
Ampere
Ampere
Ampere
Ampere / RTX 30
GPU
GPU
GPU
11 ?
11 ?
GPU-
GPU
GPU?
PCIe 4.0?
PCIe 8x/16x?
RTX 3090, 3 PCIe?
4 RTX 3090 4 RTX 3080?
GPU ?
NVLink, ?
. ?
?
?
Intel GPU?
?
AMD GPU + ROCm - NVIDIA GPU + CUDA?
, – GPU?
,
Artikel ini disusun sebagai berikut. Pertama saya jelaskan apa yang membuat GPU cepat. Saya akan menjelaskan perbedaan antara prosesor dan GPU, inti tensor, bandwidth memori, hierarki memori GPU, dan bagaimana semuanya berkaitan dengan kinerja dalam tugas GO. Penjelasan ini dapat membantu Anda lebih memahami parameter GPU yang Anda butuhkan. Kemudian saya akan memberikan perkiraan teoretis tentang kinerja GPU dan korespondensinya dengan beberapa tes kecepatan NVIDIA untuk mendapatkan data kinerja yang andal tanpa bias. Saya akan menjelaskan fitur unik dari GPU NVIDIA RTX 30 Ampere Series untuk dipertimbangkan saat membeli. Kemudian saya akan memberikan rekomendasi GPU untuk 1-2 cluster chip, 4, 8, dan GPU. Kemudian akan ada bagian jawaban atas pertanyaan yang sering diajukan yang saya tanyakan di Twitter.Ini juga akan menghilangkan kesalahpahaman umum dan menyoroti berbagai masalah seperti cloud versus desktop, pendinginan, AMD versus NVIDIA, dll.
Bagaimana cara kerja GPU?
Jika Anda sering menggunakan GPU, memahami cara kerjanya akan sangat membantu. Pengetahuan ini akan berguna bagi Anda untuk memahami mengapa dalam beberapa kasus GPU lebih lambat dan di kasus lain lebih cepat. Dan kemudian Anda dapat memahami apakah Anda memerlukan GPU sama sekali, dan opsi perangkat keras apa yang dapat bersaing dengannya di masa mendatang. Anda dapat melewati bagian ini jika Anda hanya menginginkan beberapa informasi berguna tentang kinerja dan argumen untuk memilih GPU tertentu. Penjelasan umum terbaik saya tentang cara kerja GPU ada di jawaban di Quora .
Ini adalah penjelasan umum, dan menjelaskan dengan baik pertanyaan mengapa GPU lebih cocok untuk GO daripada prosesor. Jika kita mempelajari detailnya, kita dapat memahami bagaimana GPU berbeda satu sama lain.
Karakteristik GPU terpenting yang memengaruhi kecepatan pemrosesan
Bagian ini akan membantu Anda berpikir lebih intuitif tentang kinerja di bidang GO. Pemahaman ini akan membantu Anda mengevaluasi sendiri GPU masa depan.
Tensor core
Ringkasan:
- Kernel tensor mengurangi jumlah siklus clock yang diperlukan untuk menghitung perkalian dan penambahan sebanyak 16 kali - dalam contoh saya untuk matriks 32 × 32 dari 128 menjadi 8 siklus clock.
- Kernel Tensor mengurangi ketergantungan pada akses berulang ke memori bersama, menghemat siklus akses memori.
- Kernel tensor sangat cepat sehingga komputasi tidak lagi menjadi hambatan. Satu-satunya hambatan adalah transfer data kepada mereka.
Ada begitu banyak GPU murah di luar sana saat ini sehingga hampir semua orang mampu membeli GPU dengan inti tensor. Oleh karena itu, saya selalu merekomendasikan GPU dengan Tensor Cores. Sangat berguna untuk memahami cara kerjanya untuk menghargai pentingnya modul komputasi ini, yang berspesialisasi dalam perkalian matriks. Menggunakan contoh sederhana perkalian matriks A * B = C, di mana ukuran semua matriks adalah 32 × 32, saya akan menunjukkan kepada Anda seperti apa perkalian itu dengan dan tanpa kernel tensor.
Untuk memahami ini, Anda harus terlebih dahulu memahami konsep bar. Jika prosesor berjalan pada 1 GHz, itu 10 9kutu per detik. Setiap jam adalah kesempatan untuk kalkulasi. Tetapi untuk sebagian besar, operasi memakan waktu lebih lama dari satu siklus clock. Ternyata pipeline - untuk mulai melakukan satu operasi, Anda harus menunggu clock cycle sebanyak yang diperlukan untuk menyelesaikan operasi sebelumnya. Ini juga disebut operasi tertunda.
Berikut adalah beberapa durasi atau penundaan operasi yang penting:
- Akses ke memori global hingga 48 GB: ~ 200 siklus jam.
- Akses memori bersama (hingga 164 KB per streaming multiprosesor): ~ 20 jam.
- Perkalian-penjumlahan gabungan (SUS): 4 ukuran.
- Perkalian matriks dalam kernel tensor: 1 siklus clock.
Selain itu, Anda perlu tahu bahwa unit terkecil dari utas di GPU - paket 32 utas - disebut warp. Warps biasanya bekerja secara serempak - semua utas di dalam warp harus menunggu satu sama lain. Semua operasi memori GPU dioptimalkan untuk warps. Misalnya, memuat dari memori global membutuhkan 32 * 4 byte - 32 angka floating point, satu nomor tersebut untuk setiap utas di warp. Dalam streaming multiprosesor (setara dengan inti prosesor untuk GPU), terdapat hingga 32 warps = 1024 thread. Sumber daya multiprosesor dibagikan di antara semua warps aktif. Oleh karena itu, terkadang kita memerlukan lebih sedikit warps untuk bekerja, sehingga satu warp memiliki lebih banyak register, memori bersama, dan resource inti tensor.
Untuk kedua contoh, anggap saja kita memiliki sumber daya komputasi yang sama. Dalam contoh kecil perkalian matriks 32 × 32 ini, kami menggunakan 8 multiprosesor (~ 10% dari RTX 3090) dan 8 warps pada multiprosesor.
Perkalian matriks tanpa kernel tensor
Jika kita perlu mengalikan matriks A * B = C, yang masing-masing berukuran 32 × 32, maka kita perlu memuat data dari memori, yang terus-menerus kita akses, ke dalam memori bersama, karena penundaan akses sekitar 10 kali lebih sedikit (tidak 200 batang, dan 20 batang). Sebuah blok memori dalam memori bersama sering disebut sebagai ubin memori, atau hanya ubin. Memuat dua angka floating point 32x32 ke dalam ubin memori bersama dapat dilakukan secara paralel menggunakan 2 * 32 warps. Kami memiliki 8 multiprosesor dengan masing-masing 8 warps, jadi berkat paralelisasi, kami perlu menjalankan satu pemuatan berurutan dari global ke memori bersama, yang akan membutuhkan 200 siklus clock.
Untuk mengalikan matriks, kita perlu memuat vektor 32 angka dari memori bersama A dan memori bersama B, dan menjalankan CMS, dan kemudian menyimpan output dalam register C. Kami membagi pekerjaan ini sehingga setiap multiprosesor berurusan dengan 8 produk skalar (32 × 32 ) untuk menghitung 8 data keluaran untuk C. Mengapa tepatnya ada 8 dari mereka (dalam algoritma lama - 4), ini adalah fitur teknis murni. Untuk mengetahuinya, saya sarankan membaca artikel oleh Scott Grey . Ini berarti bahwa kita akan memiliki 8 akses ke memori bersama, dengan biaya masing-masing 20 siklus, dan 8 operasi CMS (32 paralel), masing-masing seharga 4 siklus. Secara total, biayanya adalah:
200 tick (memori global) + 8 * 20 tick (memori bersama) + 8 * 4 tick (CMS) = 392 tick
Sekarang mari kita lihat biaya untuk inti tensor.
Perkalian matriks dengan kernel tensor
Dengan menggunakan kernel tensor, Anda dapat mengalikan matriks 4 × 4 dalam satu siklus. Untuk melakukan ini, kita perlu menyalin memori ke inti tensor. Seperti di atas, kita perlu membaca data dari memori global (200 tick) dan menyimpannya di memori bersama. Untuk mengalikan matriks 32 × 32, kita perlu melakukan operasi 8 × 8 = 64 dalam kernel tensor. Satu multiprosesor berisi 8 inti tensor. Dengan 8 multiprosesor, kami memiliki 64 inti tensor - sebanyak yang kami butuhkan! Kita dapat mentransfer data dari memori bersama ke inti tensor dalam 1 transfer (20 siklus clock), dan kemudian melakukan 64 operasi ini secara paralel (1 siklus clock). Artinya total biaya perkalian matriks dalam inti tensor adalah:
200 siklus jam (memori global) + 20 siklus jam (memori bersama) + 1 siklus jam (inti tensor) = 221 siklus jam
Jadi, dengan menggunakan kernel tensor, kami secara signifikan mengurangi biaya perkalian matriks, dari 392 menjadi 221 siklus jam. Dalam contoh sederhana kami, tensor kernel telah mengurangi biaya akses memori bersama dan operasi SNS.
Meskipun contoh ini secara kasar mengikuti urutan langkah komputasi dengan dan tanpa kernel tensor, perlu diketahui bahwa ini adalah contoh yang sangat disederhanakan. Dalam kasus nyata, perkalian matriks melibatkan banyak hal seperti ubin memori besar dan urutan tindakan yang sedikit berbeda.
Namun, menurut saya contoh ini menjelaskan mengapa atribut berikutnya, bandwidth memori, sangat penting untuk GPU dengan inti tensor. Karena memori global adalah hal yang paling mahal saat mengalikan matriks dengan inti tensor, GPU kami akan jauh lebih cepat jika kami dapat mengurangi latensi akses ke memori global. Ini dapat dilakukan baik dengan meningkatkan kecepatan jam memori (lebih banyak jam per detik, tetapi lebih banyak panas dan konsumsi daya), atau dengan meningkatkan jumlah elemen yang dapat ditransfer pada satu waktu (lebar bus).
Bandwidth memori
Di bagian sebelumnya, kita melihat seberapa cepat kernel tensor bekerja. Mereka sangat cepat sehingga mereka duduk diam di sebagian besar waktu, menunggu data dari memori global tiba. Misalnya, selama pelatihan untuk proyek BERT Large, di mana matriks yang sangat besar digunakan - semakin besar, semakin baik untuk tensor kernel - pemanfaatan kernel tensor di TFLOPS adalah sekitar 30%, yang berarti bahwa 70% dari waktu kernel tensor menganggur.
Artinya, saat membandingkan dua GPU dengan inti tensor, salah satu indikator performa terbaik untuk masing-masing adalah bandwidth memori. Misalnya, GPU A100 memiliki bandwidth 1,555 GB / s, sedangkan V100 memiliki 900 GB / s. Perhitungan sederhana mengatakan bahwa A100 akan menjadi 1555/900 = 1,73 kali lebih cepat dari V100.
Memori Bersama / Cache / Register L1
Karena faktor pembatas kecepatan adalah transfer data ke memori kernel tensor, kita harus beralih ke properti lain dari GPU, yang memungkinkan kita untuk mempercepat transfer data ke sana. Terkait dengan ini adalah memori bersama, cache L1 dan jumlah register. Untuk memahami bagaimana hierarki memori mempercepat transfer data, akan sangat membantu untuk memahami bagaimana matriks berkembang biak di GPU.
Untuk perkalian matriks, kami menggunakan hierarki memori yang beralih dari memori global lambat ke memori bersama lokal cepat, lalu ke register ultra cepat. Namun, semakin cepat memorinya, semakin kecil ukurannya. Oleh karena itu, kita perlu membagi matriks menjadi matriks yang lebih kecil, dan kemudian mengalikan ubin yang lebih kecil ini dalam memori bersama lokal. Maka itu akan terjadi dengan cepat dan lebih dekat ke streaming multiprosesor (PM) - setara dengan inti prosesor. Kernel tensor memungkinkan kita untuk mengambil satu langkah lagi: kita mengambil semua ubin dan memuat beberapa di antaranya ke dalam kernel tensor. Memori bersama memproses ubin matriks 10-50 kali lebih cepat daripada memori GPU global, dan register inti tensor memprosesnya 200 kali lebih cepat daripada memori GPU global.
Meningkatkan ukuran ubin memungkinkan kami menggunakan kembali lebih banyak memori. Saya menulis tentang ini secara rinci di artikel saya TPU vs GPU . Di TPU, ada ubin yang sangat, sangat besar untuk setiap inti tensor. TPU dapat menggunakan kembali lebih banyak memori dengan setiap transfer baru dari memori global, yang membuatnya sedikit lebih efisien dalam menangani perkalian matriks dibandingkan dengan GPU.
Ukuran ubin ditentukan oleh jumlah memori untuk setiap PM - setara dengan inti prosesor pada GPU. Bergantung pada arsitekturnya, volume ini adalah:
- Volta: Memori Bersama 96KB / 32KB L1
- Turing: Memori Bersama 64KB / 32KB L1
- Ampere: 164KB memori bersama / 32KB L1
Dapat dilihat bahwa Ampere memiliki lebih banyak memori bersama, yang memungkinkan penggunaan ubin yang lebih besar, yang mengurangi jumlah panggilan ke memori global. Oleh karena itu, Ampere membuat penggunaan bandwidth memori GPU lebih efisien. Ini meningkatkan kinerja sebesar 2-5%. Peningkatan ini terutama terlihat pada matriks yang sangat besar.
Kernel tensor ampere memiliki keunggulan lain - mereka memiliki jumlah data yang lebih besar yang umum untuk beberapa utas. Ini mengurangi jumlah panggilan register. Ukuran register dibatasi hingga 64 k per PM atau 255 per utas. Dibandingkan dengan Volta, Ampere Tensor Cores menggunakan register 3 kali lebih sedikit, jadi ada Tensor Cores yang lebih aktif per ubin di memori bersama. Dengan kata lain, kita dapat memuat inti tensor 3 kali lebih banyak dengan jumlah register yang sama. Namun, karena bandwidth tetap menjadi hambatan, peningkatan TFLOPS dalam praktiknya akan diabaikan dibandingkan dengan teoritis. Kernel tensor baru telah meningkatkan kinerja sekitar 1-3%.
Secara keseluruhan, dapat dilihat bahwa arsitektur Ampere telah dioptimalkan untuk menggunakan bandwidth memori secara lebih efisien melalui hierarki yang ditingkatkan - dari memori global hingga ubin memori bersama hingga register inti tensor.
Evaluasi efektivitas Ampere di GO
Ringkasan:
- Perkiraan teoretis berdasarkan bandwidth memori dan hierarki memori yang ditingkatkan untuk GPU Ampere memprediksi akselerasi 1,78 - 1,87 kali.
- NVIDIA telah merilis data tentang pengukuran kecepatan untuk Tesla A100 dan V100 GPU. Mereka lebih memasarkan, tetapi Anda dapat membangun model yang tidak bias berdasarkan mereka.
- Model yang tidak bias menunjukkan bahwa dibandingkan dengan V100, Tesla A100 1,7 kali lebih cepat dalam pemrosesan bahasa alami dan 1,45 kali lebih cepat dalam penglihatan komputer.
Bagian ini ditujukan bagi mereka yang ingin mempelajari detail teknis tentang bagaimana saya mendapatkan skor kinerja GPU Ampere. Jika Anda tidak tertarik, Anda dapat melewatinya dengan aman.
Perkiraan kecepatan teoritis Ampere
Dengan argumen di atas, perbedaan antara dua arsitektur GPU dengan inti tensor seharusnya terletak pada bandwidth memori. Manfaat tambahan datang dari peningkatan memori bersama dan cache L1, serta penggunaan register yang efisien.
Bandwidth GPU Tesla A100 meningkat 1555/900 = 1,73 kali lipat dibandingkan Tesla V100. Masuk akal juga untuk mengharapkan peningkatan kecepatan 2-5% karena total memori yang lebih besar, dan 1-3% karena peningkatan inti tensor. Ternyata akselerasi harus dari 1,78 ke 1,87 kali.
Ampere
Katakanlah kita memiliki satu skor GPU untuk arsitektur seperti Ampere, Turing, atau Volta. Mudah untuk mengekstrapolasi hasil ini ke GPU lain dengan arsitektur atau seri yang sama. Untungnya, NVIDIA telah melakukan benchmark membandingkan A100 dan V100 pada berbagai tugas yang berkaitan dengan computer vision dan pemahaman bahasa alami. Sayangnya, NVIDIA telah melakukan segala kemungkinan sehingga angka-angka ini tidak dapat dibandingkan secara langsung - pengujian menggunakan ukuran paket data yang berbeda dan jumlah GPU yang berbeda sehingga A100 tidak dapat menang. Jadi, dalam arti tertentu, indikator kinerja yang diperoleh sebagian jujur, sebagian lagi adalah iklan. Secara keseluruhan, dapat dikatakan bahwa peningkatan ukuran paket data dibenarkan karena A100 memiliki lebih banyak memori - namun,untuk membandingkan arsitektur GPU, kita perlu membandingkan data kinerja yang tidak bias pada tugas-tugas dengan ukuran paket data yang sama.
Untuk mendapatkan perkiraan yang tidak bias, Anda dapat menskalakan pengukuran V100 dan A100 dengan dua cara: memperhitungkan perbedaan ukuran paket data, atau memperhitungkan perbedaan jumlah GPU - 1 versus 8. Kami beruntung dan dapat menemukan perkiraan serupa untuk kedua kasus dalam data yang disediakan oleh NVIDIA.
Menggandakan ukuran paket akan meningkatkan throughput sebesar 13,6% dalam gambar per detik (untuk jaringan saraf konvolusional, CNN). Saya mengukur kecepatan tugas yang sama dengan arsitektur Transformer di RTX Titan saya dan, yang mengejutkan, mendapatkan hasil yang sama - 13,5%. Ini tampaknya merupakan perkiraan yang dapat diandalkan.
Dengan meningkatkan paralelisasi jaringan, dengan meningkatkan jumlah GPU, kami kehilangan kinerja karena overhead yang terkait dengan jaringan. Tetapi GPU A100 8x berkinerja lebih baik pada jaringan (NVLink 3.0) dibandingkan dengan GPU V100 8x (NVLink 2.0) - faktor lain yang membingungkan. Jika Anda melihat data dari NVIDIA, Anda dapat melihat bahwa untuk memproses SNS, sistem dengan A100 ke-8 memiliki overhead 5% lebih sedikit daripada sistem dengan V10000 ke-8. Ini berarti bahwa jika transisi dari A10000 ke-1 ke A10000 ke-8 memberi Anda akselerasi, katakanlah, 7,0 kali, maka transisi dari V10000 ke-1 ke V10000 ke-8 memberi Anda percepatan hanya 6,67 kali. Untuk transformer, angkanya 7%.
Dengan menggunakan informasi ini, kami dapat memperkirakan akselerasi beberapa arsitektur GO tertentu langsung dari data yang disediakan oleh NVIDIA. Tesla A100 memiliki keunggulan kecepatan berikut dibandingkan Tesla V100:
- SE-ResNeXt101: 1,43 kali.
- Masked-R-CNN: 1,47 kali.
- Transformer (12 lapisan, terjemahan mesin, WMT14 en-de): 1,70 kali.
Oleh karena itu, untuk computer vision, angkanya diperoleh di bawah perkiraan teoretis. Hal ini dapat disebabkan oleh dimensi tensor yang lebih kecil, overhead operasi yang diperlukan untuk menyiapkan perkalian matriks seperti img2col atau FFT, atau operasi yang tidak dapat memenuhi GPU (lapisan yang dihasilkan seringkali relatif kecil). Ini juga bisa berupa artefak dari arsitektur tertentu (konvolusi yang dikelompokkan).
Penilaian praktis kecepatan transformator sangat dekat dengan teoritis. Mungkin karena algoritme untuk bekerja dengan matriks besar sangat mudah. Saya akan menggunakan perkiraan praktis untuk menghitung efisiensi biaya GPU.
Kemungkinan ketidakakuratan perkiraan
Di atas adalah peringkat komparatif A100 dan V100. Di masa lalu, NVIDIA secara diam-diam menurunkan performa "gaming" RTX GPUs: mengurangi penggunaan tensor core, menambahkan kipas game untuk pendinginan, dan melarang transfer data antar GPU. Ada kemungkinan bahwa seri RT 30 juga membuat kerusakan yang tidak diketahui pada Ampere A100.
Apa lagi yang perlu dipertimbangkan dalam kasus Ampere / RTX 30
Ringkasan:
- Ampere memungkinkan Anda melatih jaringan berdasarkan matriks renggang, yang mempercepat proses pelatihan hingga dua kali.
- Pelatihan jaringan yang jarang masih jarang digunakan, namun berkat itu, Ampere tidak akan segera menjadi usang.
- Ampere memiliki tipe data presisi rendah baru yang membuatnya lebih mudah untuk menggunakan presisi rendah, tetapi tidak selalu memberikan peningkatan kecepatan dibandingkan GPU sebelumnya.
- Desain kipas baru bagus jika Anda memiliki ruang kosong di antara GPU - namun, tidak jelas apakah GPU yang berdiri berdekatan akan mendingin secara efektif.
- Desain 3 slot RTX 3090 akan menjadi tantangan untuk 4 build GPU. Solusi yang mungkin adalah menggunakan opsi 2 slot atau pelebar PCIe.
- Empat RTX 3090 akan membutuhkan lebih banyak daya daripada yang ditawarkan PSU standar mana pun di pasaran.
NVIDIA Ampere RTX 30 baru memiliki keunggulan tambahan dibandingkan NVIDIA Turing RTX 20 - pembelajaran yang jarang dan pemrosesan jaringan saraf yang lebih baik. Properti lainnya, seperti tipe data baru, dapat dianggap sebagai peningkatan kenyamanan sederhana - properti mempercepat dengan cara yang sama seperti seri Turing, tanpa memerlukan pemrograman tambahan.
Pembelajaran yang jarang
Ampere memungkinkan Anda mengalikan matriks renggang dengan kecepatan tinggi dan otomatis. Cara kerjanya seperti ini - Anda mengambil matriks, memotongnya menjadi 4 elemen, dan kernel tensor yang mendukung matriks renggang memungkinkan dua dari empat elemen ini menjadi nol. Ini menghasilkan speedup 2x karena kebutuhan bandwidth selama perkalian matriks dibelah dua.
Dalam penelitian saya, saya telah bekerja dengan jaringan pembelajaran yang jarang. Pekerjaan tersebut dikritik, khususnya, karena fakta bahwa saya "mengurangi FLOPS yang diperlukan untuk jaringan, tetapi tidak meningkatkan kecepatan karena hal ini, karena GPU tidak dapat dengan cepat menggandakan matriks renggang." Baik - dukungan untuk perkalian matriks jarang muncul di kernel tensor, dan algoritme saya, atau algoritme lainnya ( tautan, link , link , link ), bekerja dengan matriks renggang, sekarang sebenarnya dapat bekerja dua kali lebih cepat selama pelatihan.
Meskipun properti ini saat ini dianggap eksperimental, dan pelatihan jaringan jarang tidak diterapkan secara universal, jika GPU Anda memiliki dukungan untuk teknologi ini, Anda siap untuk masa depan pelatihan jarang.
Perhitungan presisi rendah
Saya telah mendemonstrasikan bagaimana tipe data baru dapat meningkatkan stabilitas propagasi mundur dengan fidelitas rendah dalam pekerjaan saya. Sejauh ini, masalah dengan backpropagation stabil dengan bilangan floating point 16-bit adalah tipe data biasa hanya mendukung span [-65,504, 65,504]. Jika gradien Anda melampaui celah ini, gradien akan meledak, menghasilkan nilai NaN. Untuk mencegah hal ini, kami biasanya menskalakan nilai dengan mengalikannya dengan angka kecil sebelum melakukan propagasi mundur untuk menghindari ledakan gradien.
Format Brain Float 16 (BF16) menggunakan lebih banyak bit untuk eksponen, jadi kisaran nilai yang mungkin sama seperti di FP32: [-3 * 10 ^ 38, 3 * 10 ^ 38]. BF16 memiliki presisi yang kurang, yaitu digit signifikan lebih sedikit, tetapi akurasi gradien saat jaringan pelatihan tidak begitu penting. Oleh karena itu, BF16 memastikan bahwa Anda tidak perlu melakukan penskalaan atau mengkhawatirkan ledakan gradien. Dengan format ini, kita akan melihat peningkatan stabilitas pelatihan dengan mengorbankan sedikit kehilangan presisi.
Artinya bagi Anda: Akurasi BF16 bisa lebih konsisten daripada akurasi FP16, tetapi kecepatannya sama. Dengan presisi TF32, Anda mendapatkan stabilitas hampir seperti FP32 dan akselerasi hampir seperti FP16. Kelebihannya adalah saat menggunakan tipe data ini, Anda dapat mengubah FP32 ke TF32, dan FP16 ke BF16, tanpa mengubah apa pun di kode!
Secara umum, tipe data baru ini dapat dianggap malas, dalam artian Anda bisa mendapatkan semua manfaatnya menggunakan tipe data lama dan sedikit pemrograman (menskalakan dengan benar, menginisialisasi, menormalkan, menggunakan Apex). Oleh karena itu, tipe data ini tidak memberikan akselerasi, tetapi membuatnya lebih mudah untuk menggunakan fidelitas rendah dalam pelatihan.
Desain kipas baru dan masalah pembuangan panas
Desain kipas baru untuk seri RTX 30 memiliki kipas angin bertiup dan kipas angin. Desainnya sendiri cerdas dan akan bekerja dengan sangat efisien jika ada ruang kosong di antara GPU. Namun, tidak jelas bagaimana GPU akan berperilaku jika dipaksakan satu sama lain. Kipas angin yang bertiup akan mampu menghembuskan udara dari GPU lain, tetapi tidak mungkin untuk mengetahui bagaimana ini akan bekerja karena bentuknya berbeda dari sebelumnya. Jika Anda berencana untuk meletakkan 1 atau 2 GPU di mana terdapat 4 slot maka Anda seharusnya tidak mengalami masalah. Tetapi jika Anda ingin menggunakan 3-4 GPU RTX 30 secara berdampingan, pertama-tama saya akan menunggu laporan tentang kondisi suhu, dan kemudian saya memutuskan apakah saya membutuhkan lebih banyak kipas, ekspander PCIe, atau solusi lain.
Bagaimanapun, pendingin air dapat membantu menyelesaikan masalah dengan unit pendingin. Banyak pabrikan menawarkan solusi seperti itu untuk kartu RTX 3080 / RTX 3090, dan kemudian mereka tidak akan menjadi hangat, bahkan jika ada 4. Namun, jangan membeli solusi GPU siap pakai jika Anda ingin membangun komputer dengan 4 GPU, karena akan sangat sulit dalam banyak kasus mendistribusikan radiator.
Solusi lain untuk masalah pendinginan adalah dengan membeli ekspander PCIe dan mendistribusikan kartu di dalam casing. Ini sangat efektif - Saya dan mahasiswa pascasarjana lainnya di Vanington University menggunakan opsi ini dengan sangat sukses. Ini tidak terlihat sangat rapi, tetapi GPU tidak menjadi panas! Selain itu, opsi ini akan membantu jika Anda tidak memiliki cukup ruang untuk mengakomodasi GPU. Jika Anda memiliki ruang di casing, Anda dapat, misalnya, membeli RTX 3090 standar dengan tiga slot, dan mendistribusikannya menggunakan ekspander di seluruh casing. Jadi, masalah ruang dan pendinginan 4 RTX 3090s dapat diselesaikan secara bersamaan

. 1: 4 GPU dengan PCIe Expanders
Kartu tiga slot dan masalah daya
RTX 3090 menempati 3 slot, jadi masing-masing tidak dapat digunakan 4 slot dengan kipas default NVIDIA. Ini tidak mengherankan karena membutuhkan TDP 350W. RTX 3080 hanya sedikit lebih rendah, membutuhkan 320W TDP, dan mendinginkan sistem dengan empat RTX 3080 akan sangat sulit.
Juga sulit untuk memberi daya pada sistem dengan 4 kartu 350W = 1400W. Ada catu daya (PSU) 1600 W, tetapi 200 W untuk prosesor dan motherboard mungkin tidak cukup. Konsumsi daya maksimum hanya terjadi pada beban penuh, dan selama HE prosesor biasanya dimuat dengan ringan. Oleh karena itu, PSU 1600W mungkin cocok untuk 4 RTX 3080-an, tetapi untuk 4 RTX 3090-an, lebih baik mencari PSU 1700W atau lebih. Tidak ada PSU seperti itu di pasaran saat ini. PSU server atau blok khusus untuk cryptominers dapat berfungsi, tetapi mereka mungkin memiliki faktor bentuk yang tidak biasa.
Efisiensi GPU dalam pembelajaran mendalam
Tes berikutnya tidak hanya mencakup perbandingan Tesla A100 dan Tesla V100 - Saya membuat model yang cocok dengan data ini dan empat tes berbeda, di mana Titan V, Titan RTX, RTX 2080 Ti dan RTX 2080 diuji ( tautan , tautan , tautan , tautan ).
Saya juga mengukur hasil benchmark untuk kartu kelas menengah seperti RTX 2070, RTX 2060 atau Quadro RTX dengan menginterpolasi poin data uji. Biasanya dalam arsitektur GPU, data tersebut diskalakan secara linier sehubungan dengan perkalian matriks dan bandwidth memori.
Saya hanya mengumpulkan data dari tes pelatihan FP16 dengan presisi campuran, karena saya tidak melihat alasan mengapa pelatihan dengan nomor FP32 harus digunakan.

Angka: Gambar 2: Kinerja Dinormalisasi oleh RTX 2080 Ti
Dibandingkan dengan RTX 2080 Ti, RTX 3090 berjalan 1,57 kali lebih cepat dengan jaringan konvolusional, 1,5 kali lebih cepat dengan transformator, dan biaya 15% lebih tinggi. Ampere RTX 30 ternyata menunjukkan peningkatan yang signifikan sejak seri Turing RTX 20.
Kecepatan pembelajaran mendalam GPU per biaya
GPU mana yang akan menjadi nilai terbaik untuk uang? Itu semua tergantung pada total biaya sistem. Jika mahal, masuk akal untuk berinvestasi pada GPU yang lebih mahal.
Di bawah ini adalah data tentang tiga rakitan pada PCIe 3.0, yang saya gunakan sebagai dasar untuk biaya sistem dengan 2 atau 4 GPU. Saya mengambil biaya dasar ini dan menambahkan biaya GPU ke dalamnya. Saya menghitung yang terakhir sebagai harga rata-rata antara penawaran dari Amazon dan eBay. Untuk Ampere baru, saya hanya menggunakan satu harga. Secara bersama-sama dengan data kinerja di atas, ini memberikan nilai kinerja per dolar. Untuk sistem dengan 8 GPU, saya menggunakan barebone Supermicro sebagai standar industri untuk server RTX. Grafik yang ditampilkan tidak menyertakan persyaratan memori. Pertama-tama Anda perlu memikirkan memori apa yang Anda butuhkan, dan kemudian mencari opsi terbaik pada grafik. Contoh tip untuk memori:
- Menggunakan trafo terlatih, atau melatih trafo kecil dari awal> = 11 GB.
- Pelatihan transformator besar atau jaringan konvolusional dalam penelitian atau produksi:> = 24 GB.
- Prototipe jaringan saraf (transformator atau jaringan konvolusional)> = 10 GB.
- Partisipasi dalam kontes Kaggle> = 8 GB.
- Visi komputer> = 10 GB.
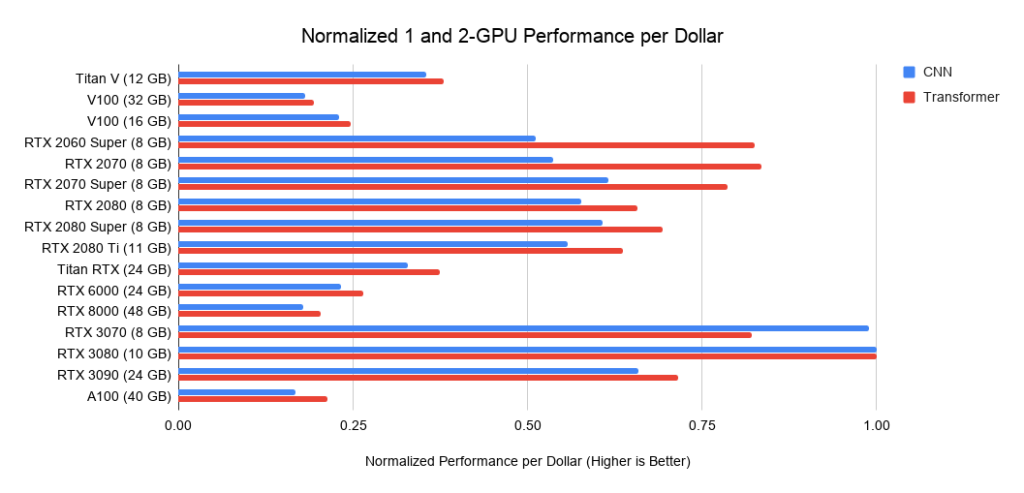
Angka:

Gambar 3: Kinerja dolar yang dinormalisasi versus RTX 3080. Gambar. Gambar 4: Kinerja dolar yang dinormalkan versus RTX 3080
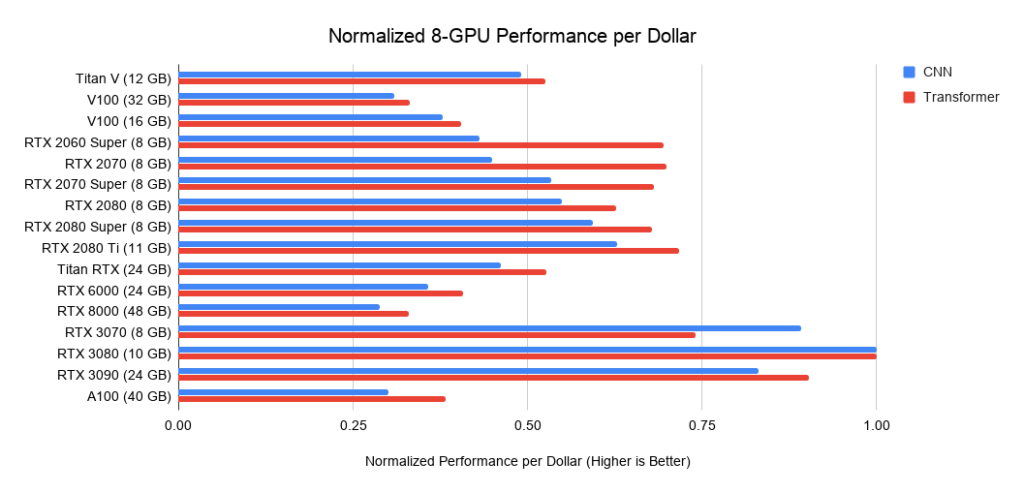
. 5: Kinerja dolar yang dinormalkan versus RTX 3080.
Rekomendasi GPU
Sekali lagi, saya ingin menekankan: saat memilih GPU, pertama-tama pastikan ia memiliki cukup memori untuk tugas Anda. Langkah-langkah untuk memilih GPU harus sebagai berikut:
- , GPU: Kaggle, , , , - .
- , .
- GPU, .
- GPU - ? , RTX 3090, ? GPU? , GPU?
Beberapa langkah mengharuskan Anda untuk memikirkan tentang apa yang Anda inginkan dan melakukan sedikit riset tentang seberapa banyak memori yang digunakan orang lain untuk melakukan hal yang sama. Saya dapat memberikan beberapa saran, tetapi saya tidak dapat sepenuhnya menjawab semua pertanyaan di bidang ini.
Kapan saya membutuhkan penyimpanan lebih dari 11GB?
Saya sudah menyebutkan bahwa saat bekerja dengan transformator, Anda akan membutuhkan setidaknya 11 GB, dan saat melakukan penelitian di bidang ini, setidaknya 24 GB. Sebagian besar model sebelumnya memiliki persyaratan memori yang sangat tinggi dan telah dilatih pada RTX 2080 Ti atau GPU yang lebih tinggi dengan memori minimal 11 GB. Oleh karena itu, jika Anda memiliki memori kurang dari 11 GB, meluncurkan beberapa model dapat menjadi sulit atau bahkan tidak mungkin.
Area lain yang membutuhkan memori dalam jumlah besar adalah pencitraan medis, model penglihatan komputer tingkat lanjut, dan semuanya dengan gambar besar.
Secara keseluruhan, jika Anda ingin mengembangkan model yang dapat mengungguli persaingan - baik itu penelitian, aplikasi industri, atau persaingan Kaggle - memori tambahan dapat memberi Anda keunggulan kompetitif.
Kapan Anda dapat bertahan dengan memori kurang dari 11 GB?
Kartu RTX 3070 dan RTX 3080 sangat kuat, tetapi kekurangan memori. Namun, untuk banyak tugas jumlah memori tersebut mungkin tidak diperlukan.
RTX 3070 sangat ideal untuk pelatihan GO. Keterampilan jaringan dasar untuk sebagian besar arsitektur dapat diperoleh dengan menurunkan skala jaringan atau menggunakan gambar yang lebih kecil. Jika saya harus belajar GO, saya akan memilih RTX 3070, atau bahkan beberapa jika saya mampu membelinya.
RTX 3080 adalah kartu yang paling hemat biaya saat ini dan karena itu ideal untuk pembuatan prototipe. Pembuatan prototipe membutuhkan memori dalam jumlah besar, dan memori itu tidak mahal. Dengan membuat prototipe, yang saya maksud adalah membuat prototipe di area mana pun - penelitian, kompetisi Kaggle, mencoba ide untuk sebuah startup, bereksperimen dengan kode penelitian. Untuk semua aplikasi ini, RTX 3080 paling cocok.
Jika, misalnya, saya menjalankan laboratorium penelitian atau startup, saya akan menghabiskan 66-80% dari total anggaran untuk mesin RTX 3080, dan 20-33% untuk mesin RTX 3090 dengan pendingin air yang andal. RTX 3080 lebih hemat biaya dan dapat diakses melalui Slurm... Karena pembuatan prototipe perlu dilakukan dalam mode agile, maka perlu dilakukan dengan model dan kumpulan data yang lebih kecil. Dan RTX 3080 sangat cocok untuk itu. Setelah siswa / kolega membuat model prototipe yang hebat, mereka dapat meluncurkannya ke RTX 3090, meningkatkan ke model yang lebih besar.
Rekomendasi umum
Secara keseluruhan, model seri RTX 30 sangat bertenaga dan saya sangat merekomendasikannya. Pertimbangkan persyaratan memori seperti yang dinyatakan sebelumnya, serta persyaratan daya dan pendinginan. Jika Anda memiliki slot kosong di antara GPU, tidak akan ada masalah dengan pendinginan. Jika tidak, berikan kartu RTX 30 dengan pendingin air, ekspander PCIe, atau kartu efisien dengan kipas.
Secara keseluruhan, saya akan merekomendasikan RTX 3090 kepada siapa saja yang mampu membelinya. Ini tidak hanya cocok untuk Anda sekarang, tetapi akan tetap sangat efektif selama 3-7 tahun ke depan. Tidak mungkin dalam tiga tahun ke depan memori HBM akan menjadi jauh lebih murah, jadi GPU berikutnya hanya akan 25% lebih baik daripada RTX 3090. Dalam 5-7 tahun, kita mungkin akan melihat memori HBM yang murah, setelah itu Anda pasti perlu memperbarui armada ...
Jika Anda membangun sistem dari beberapa RTX 3090, berikan sistem pendinginan dan daya yang cukup.
Kecuali Anda memiliki persyaratan ketat untuk keunggulan kompetitif, saya akan merekomendasikan RTX 3080. Ini adalah solusi yang lebih hemat biaya dan akan memberikan pelatihan cepat untuk sebagian besar jaringan. Jika Anda melakukan trik memori yang Anda inginkan dan tidak keberatan menulis kode tambahan, ada banyak trik untuk menjejalkan jaringan 24GB ke dalam GPU 10GB.
RTX 3070 juga merupakan kartu yang bagus untuk pelatihan dan pembuatan prototipe GO, dan lebih murah $ 200 daripada RTX 3080. Jika Anda tidak mampu membeli RTX 3080 maka RTX 3070 adalah pilihan Anda.
Jika anggaran Anda terbatas dan RTX 3070 terlalu mahal untuk Anda, Anda dapat menemukan RTX 2070 bekas di eBay dengan harga sekitar $ 260. Belum jelas apakah RTX 3060 akan keluar, tetapi jika anggaran Anda terbatas, mungkin pantas untuk ditunggu. Jika harganya sesuai dengan RTX 2060 dan GTX 1060, maka itu harus sekitar $ 250- $ 300, dan itu akan bekerja dengan baik.
Rekomendasi untuk cluster GPU
Tata letak cluster GPU sangat bergantung pada penggunaannya. Untuk sistem dengan 1024 GPU atau lebih, hal utama adalah kehadiran jaringan, tetapi jika Anda menggunakan tidak lebih dari 32 GPU pada satu waktu, tidak ada gunanya berinvestasi dalam membangun jaringan yang kuat.
Secara umum, kartu RTX berdasarkan perjanjian CUDA tidak dapat digunakan di pusat data. Namun, universitas sering kali menjadi pengecualian dari aturan ini. Jika Anda ingin mendapatkan izin seperti itu, sebaiknya hubungi perwakilan NVIDIA. Jika Anda dapat menggunakan kartu RTX, maka saya akan merekomendasikan sistem standar Supermicro 8 GPU RTX 3080 atau RTX 3090 (jika Anda dapat menjaganya tetap dingin). Satu set kecil 8 node A10000 memastikan penggunaan model yang efisien setelah pembuatan prototipe, terutama jika server pendingin dengan 8 RTX 3090 tidak memungkinkan. Dalam hal ini, saya akan merekomendasikan A10000 daripada RTX 6000 / RTX 8000 karena A10000s cukup hemat biaya dan tidak akan cepat tua.
Jika Anda perlu melatih jaringan yang sangat besar pada cluster GPU (256 GPU atau lebih), saya akan merekomendasikan sistem NVIDIA DGX SuperPOD dengan A10000. dari 256 GPU, jaringan menjadi penting. Jika Anda ingin mengembangkan lebih dari 256 GPU, Anda memerlukan sistem yang sangat dioptimalkan sehingga solusi standar tidak akan berfungsi lagi.
Terutama pada skala GPU 1.024 dan seterusnya, satu-satunya solusi kompetitif di pasar tetap Google TPU Pod dan NVIDIA DGX SuperPod. Pada skala ini, saya lebih memilih Google TPU Pod, karena infrastruktur jaringan khusus mereka terlihat lebih baik daripada NVIDIA DGX SuperPod - meskipun pada prinsipnya, kedua sistem tersebut cukup dekat. Dalam aplikasi dan perangkat keras, sistem GPU lebih fleksibel daripada TPU, sedangkan sistem TPU mendukung model yang lebih besar dan menskalakan dengan lebih baik. Oleh karena itu, kedua sistem memiliki kelebihan dan kekurangan masing-masing.
GPU mana yang lebih baik untuk tidak dibeli
Saya tidak menyarankan membeli beberapa Edisi Pendiri RTX atau Titans RTX pada satu waktu, kecuali Anda memiliki ekspander PCIe untuk mengatasi masalah pendinginannya. Mereka hanya akan melakukan pemanasan dan kecepatannya akan turun drastis dibandingkan dengan yang ditunjukkan dalam grafik. Empat Edisi Pendiri RTX 2080 Ti akan dengan cepat memanas hingga 90 ° C, menurunkan kecepatan jam, dan bekerja lebih lambat daripada RTX 2070 yang biasanya didinginkan.
Saya merekomendasikan membeli Tesla V100 atau A100 hanya dalam kasus ekstrim, karena dilarang digunakan di pusat data perusahaan. Atau beli jika Anda perlu melatih jaringan yang sangat besar pada cluster GPU yang besar - rasio harga / performanya tidak ideal.
Jika Anda mampu membeli sesuatu yang lebih baik, jangan gunakan kartu seri GTX 16. Mereka tidak memiliki inti tensor, jadi performa mereka di GO buruk. Saya akan menggunakan RTX 2070 / RTX 2060 / RTX 2060 Super bekas. Mereka dapat dipinjam jika anggaran Anda sangat terbatas.
Kapan sebaiknya tidak membeli GPU baru?
Jika Anda sudah memiliki RTX 2080 Ti atau lebih baik, meningkatkan ke RTX 3090 hampir tidak ada gunanya. GPU Anda sudah bagus, dan manfaat kecepatan akan diabaikan dibandingkan dengan masalah daya dan pendinginan yang diperoleh - ini tidak sepadan.
Satu-satunya alasan saya ingin meningkatkan dari empat RTX 2080 Ti ke empat RTX 3090 adalah jika saya melakukan penelitian pada transformator yang sangat besar atau jaringan lain yang sangat bergantung pada daya komputasi. Namun, jika Anda mengalami masalah memori, Anda harus mempertimbangkan berbagai trik terlebih dahulu untuk menjejalkan model besar ke dalam memori yang ada.
Jika Anda memiliki satu atau lebih RTX 2070-an, saya akan berpikir dua kali jika saya menjadi Anda sebelum meningkatkan. Ini adalah GPU yang cukup bagus. Mungkin masuk akal untuk menjualnya di eBay dan membeli RTX 3090 jika 8GB tidak cukup untuk Anda - seperti halnya dengan banyak GPU lainnya. Jika tidak ada cukup memori, pembaruan sedang dilakukan.
Jawaban atas pertanyaan dan kesalahpahaman
Ringkasan:
- Jalur PCIe dan PCIe 4.0 tidak relevan untuk sistem GPU ganda. Untuk sistem dengan 4 GPU, secara praktis tidak.
- Mendinginkan RTX 3090 dan RTX 3080 akan sulit. Gunakan pendingin air atau ekspander PCIe.
- NVLink hanya diperlukan untuk kluster GPU.
- Anda dapat menggunakan GPU yang berbeda di komputer yang sama (misalnya, GTX 1080 + RTX 2080 + RTX 3090), tetapi paralelisasi tidak akan berfungsi.
- Untuk menjalankan lebih dari dua mesin secara paralel, Anda memerlukan Infiniband dan jaringan 50 Gbps.
- Prosesor AMD lebih murah daripada prosesor Intel, dan yang terakhir hampir tidak memiliki keunggulan.
- Terlepas dari upaya heroik para insinyur, AMD GPU + ROCm tidak akan mampu bersaing dengan NVIDIA karena kurangnya komunitas dan inti tensor yang setara dalam 1-2 tahun ke depan.
- Cloud GPU bermanfaat jika digunakan kurang dari satu tahun. Setelah itu, versi desktop menjadi lebih murah.
Apakah saya membutuhkan PCIe 4.0?
Biasanya tidak. PCIe 4.0 sangat bagus untuk cluster GPU. Berguna jika Anda memiliki mesin 8 GPU. Dalam kasus lain, hampir tidak ada keuntungan. Ini meningkatkan paralelisasi dan mentransfer data sedikit lebih cepat. Namun transfer data bukanlah penghambat. Dalam computer vision, hambatan mungkin penyimpanan data, tetapi bukan transfer data PCIe dari GPU ke GPU. Jadi tidak ada alasan bagi kebanyakan orang untuk menggunakan PCIe 4.0. Ini mungkin akan meningkatkan paralelisasi empat GPU sebesar 1-7%.
Apakah saya memerlukan jalur PCIe 8x / 16x?
Seperti PCIe 4.0, biasanya tidak. Jalur PCIe diperlukan untuk paralelisasi dan transfer data yang cepat, yang hampir tidak pernah menjadi hambatan. Jika Anda memiliki 2 GPU, 4 baris sudah cukup untuk mereka. Untuk 4 GPU, saya lebih suka 8 baris per GPU, tapi jika ada 4 baris, itu akan menurunkan kinerja hanya 5-10%.
Bagaimana Anda menyesuaikan empat RTX 3090 ketika masing-masing menggunakan 3 slot PCIe?
Anda dapat membeli salah satu dari dua opsi untuk satu slot, atau mendistribusikannya menggunakan pelebar PCIe. Selain ruang, Anda perlu segera memikirkan pendinginan dan catu daya yang sesuai. Rupanya, solusi termudah adalah dengan membeli Hydro Coppers 4 x RTX 3090 EVGA dengan loop pendingin air khusus. EVGA telah membuat versi kartu tembaga berpendingin air selama bertahun-tahun, dan Anda dapat mempercayai kualitas GPU mereka. Mungkin ada opsi yang lebih murah.
Ekspander PCIe dapat menyelesaikan masalah ruang dan pendinginan, tetapi casing Anda harus memiliki cukup ruang untuk semua kartu. Dan pastikan perpanjangannya cukup panjang!
Bagaimana cara mendinginkan 4 RTX 3090 atau 4 RTX 3080?
Lihat bagian sebelumnya.
Bisakah saya menggunakan beberapa jenis GPU yang berbeda?
Ya, tetapi Anda tidak akan dapat memparalelkan pekerjaan secara efektif. Saya dapat membayangkan sebuah sistem yang menjalankan 3 RTX 3070 + 1 RTX 3090. Di sisi lain, paralelisasi antara empat RTX 3070 akan bekerja sangat cepat jika Anda memasukkan model ke dalamnya. Dan satu lagi alasan mengapa Anda mungkin membutuhkannya adalah menggunakan GPU lama. Ini akan berfungsi, tetapi paralelisasi tidak akan efektif, karena GPU tercepat akan menunggu GPU paling lambat di titik sinkronisasi (biasanya saat gradien diperbarui).
Apa itu NVLink dan apakah saya membutuhkannya?
Anda biasanya tidak membutuhkan NVLink. Ini adalah komunikasi berkecepatan tinggi antara beberapa GPU. Ini diperlukan jika Anda memiliki klaster 128 atau lebih GPU. Dalam kasus lain, ini hampir tidak memiliki keunggulan dibandingkan transfer data PCIe standar.
Saya tidak punya uang bahkan untuk rekomendasi termurah Anda. Apa yang harus dilakukan?
Pasti membeli GPU bekas. RTX 2070 bekas ($ 400) dan RTX 2060 ($ 300) sudah cukup. Jika Anda tidak mampu membelinya, opsi terbaik berikutnya adalah GTX 1070 bekas ($ 220) atau GTX 1070 Ti ($ 230). Jika itu terlalu mahal, temukan GTX 980 Ti bekas (6GB $ 150) atau GTX 1650 Super ($ 190). Jika itu mahal juga, lebih baik Anda menggunakan layanan cloud. Mereka biasanya memberi GPU batas waktu atau daya, setelah itu Anda harus membayar. Tukar layanan hingga Anda mampu membeli GPU Anda sendiri.
Apa yang diperlukan untuk memparalelkan proyek antara dua mesin?
Untuk mempercepat pekerjaan dengan memparalelkan antara dua mesin, Anda memerlukan 50 Gbps atau lebih kartu jaringan. Saya sarankan menginstal setidaknya EDR Infiniband - yaitu, kartu jaringan dengan kecepatan minimal 50 Gbps. Dua kartu EDR dengan kabel di eBay akan membuat Anda mengembalikan $ 500.
Dalam beberapa kasus, Anda dapat bertahan dengan Ethernet 10 Gbps, tetapi ini biasanya hanya berfungsi untuk jenis jaringan neural tertentu (jaringan konvolusional tertentu) atau untuk algoritme tertentu (Microsoft DeepSpeed).
Apakah algoritma perkalian matriks renggang cocok untuk semua matriks renggang?
Sepertinya tidak. Karena matriks harus memiliki 2 angka nol untuk setiap 4 elemen, matriks renggang harus terstruktur dengan baik. Dimungkinkan untuk sedikit mengubah algoritme dengan memproses 4 nilai sebagai representasi terkompresi dari dua nilai, tetapi ini berarti bahwa perkalian yang tepat dari matriks renggang dengan Ampere tidak akan tersedia.
Apakah saya memerlukan prosesor Intel untuk menjalankan banyak GPU?
Saya tidak menyarankan menggunakan prosesor Intel, kecuali Anda memuat prosesor cukup berat di kompetisi Kaggle (di mana prosesor dimuat dengan kalkulasi aljabar linier). Dan bahkan untuk kompetisi seperti itu, prosesor AMD sangat bagus. Prosesor AMD rata-rata lebih murah dan lebih baik untuk GO. Untuk build 4-GPU, Threadripper adalah pilihan pasti saya. Di universitas kami, kami telah mengumpulkan lusinan sistem berdasarkan prosesor tersebut, dan semuanya bekerja dengan sempurna, tanpa keluhan. Untuk sistem dengan 8 GPU, saya akan mengambil prosesor yang memiliki pengalaman pabrikan Anda. Keandalan prosesor dan PCIe dalam sistem 8 kartu lebih penting daripada kecepatan atau efisiensi biaya.
Apakah bentuk casing penting untuk pendinginan?
Tidak. Biasanya GPU mendingin dengan sempurna jika ada celah kecil di antara GPU. Rumah yang berbeda dapat memberikan perbedaan 1-3 ° C, dan jarak kartu yang berbeda dapat memberikan perbedaan 10-30 ° C. Secara umum, jika ada celah di antara kartu Anda, tidak ada masalah dengan pendinginan. Jika tidak ada celah, Anda memerlukan kipas yang tepat (kipas angin) atau solusi lain (pendingin air, ekspander PCIe). Bagaimanapun, jenis casing dan penggemarnya tidak masalah.
Akankah AMD GPU + ROCm Menangkap NVIDIA GPU + CUDA?
Tidak dalam beberapa tahun mendatang. Ada tiga masalah: kernel tensor, perangkat lunak, dan komunitas.
Kristal GPU itu sendiri dari AMD bagus: kinerja luar biasa pada FP16, bandwidth memori luar biasa. Tetapi ketiadaan inti tensor atau yang setara mengarah pada fakta bahwa kinerjanya menderita dibandingkan dengan GPU dari NVIDIA. Dan tanpa penerapan inti tensor di perangkat keras, GPU AMD tidak akan pernah bisa bersaing. Menurut rumor yang beredar, beberapa jenis kartu untuk pusat data dengan analog inti tensor direncanakan untuk tahun 2020, namun belum ada data pasti. Jika mereka hanya memiliki kartu setara Tensor Core untuk server, itu berarti hanya sedikit orang yang mampu membeli GPU AMD, memberikan NVIDIA keunggulan kompetitif.
Katakanlah AMD akan memperkenalkan perangkat keras dengan sesuatu seperti inti tensor di masa depan. Kemudian banyak yang akan berkata: “Tetapi tidak ada program yang bekerja dengan GPU AMD! Bagaimana saya bisa menggunakannya? " Ini sebagian besar adalah kesalahpahaman. Perangkat lunak AMD yang menjalankan ROCm sudah berkembang dengan baik, dan dukungan di PyTorch diatur dengan baik. Dan meskipun saya belum melihat banyak laporan tentang kerja AMD GPU + PyTorch, semua fungsi perangkat lunak terintegrasi di sana. Rupanya, Anda dapat memilih jaringan apa pun dan menjalankannya di GPU AMD. Oleh karena itu, AMD sudah berkembang dengan baik di bidang ini, dan masalah ini secara praktis telah diselesaikan.
Namun, dengan perangkat lunak dan kurangnya inti tensor teratasi, AMD akan dihadapkan pada masalah lain: kurangnya komunitas. Saat Anda menemukan masalah dengan GPU NVIDIA, Anda dapat mencari Google untuk mendapatkan solusi dan menemukannya. Ini membangun kepercayaan pada GPU NVIDIA. Sebuah infrastruktur sedang berkembang untuk memfasilitasi penggunaan GPU NVIDIA (platform apa pun untuk karya GO, semua tugas ilmiah didukung). Ada banyak peretasan dan trik yang membuatnya lebih mudah menggunakan GPU NVIDIA (misalnya, apex). Pakar dan pemrogram GPU NVIDIA dapat ditemukan di bawah setiap semak, tetapi saya tahu jauh lebih sedikit pakar GPU AMD.
Dari segi komunitas, situasi AMD mirip dengan Julia vs Python. Julia memiliki banyak potensi, dan banyak yang akan dengan tepat menunjukkan bahwa bahasa pemrograman ini lebih cocok untuk karya ilmiah. Namun, Julia jarang digunakan dibandingkan dengan Python. Hanya saja komunitas Python sangat besar. Ada banyak sekali orang yang berkumpul di sekitar paket hebat seperti Numpy, SciPy, dan Pandas. Situasi ini mirip dengan NVIDIA vs AMD.
Oleh karena itu, sangat mungkin bahwa AMD tidak akan mengejar NVIDIA sampai ia memperkenalkan inti tensor yang setara dan komunitas yang kokoh yang dibangun di sekitar ROCm. AMD akan selalu memiliki pangsa pasarnya di subkelompok tertentu (penambangan cryptocurrency, pusat data). Tetapi NVIDIA kemungkinan besar akan memegang monopoli selama dua tahun lagi.
Kapan lebih baik menggunakan layanan cloud dan kapan komputer GPU khusus?
Aturan praktis sederhana: jika Anda berharap untuk melakukan GO selama lebih dari satu tahun, lebih murah untuk membeli komputer dengan GPU. Jika tidak, lebih baik menggunakan layanan cloud - kecuali Anda memiliki pengalaman ekstensif dalam pemrograman cloud dan ingin memanfaatkan penskalaan jumlah GPU sesuka hati.
Titik kritis yang tepat di mana GPU cloud menjadi lebih mahal daripada memiliki komputer sangat bergantung pada layanan yang digunakan. Lebih baik menghitungnya sendiri. Di bawah ini adalah contoh penghitungan untuk server AWS V100 dengan satu V100, dan membandingkannya dengan biaya komputer desktop dengan satu RTX 3090, yang kinerjanya mendekati. PC RTX 3090 berharga $ 2200 (2-GPU barebone + RTX 3090). Jika Anda berada di AS, tambahkan $ 0,12 per kWh untuk listrik itu. Bandingkan dengan $ 2,14 per jam per server di AWS.
Pada 15% daur ulang per tahun, komputer menggunakan
(350 W (GPU) + 100 W (CPU)) * 0,15 (daur ulang) * 24 jam * 365 hari = 591 kWh per tahun.
591 kWh per tahun memberikan tambahan $ 71.
Titik kritis, ketika komputer dan cloud membandingkan harga pada penggunaan 15%, terjadi sekitar hari ke-300 ($ 2.311 vs $ 2.270):
$ 2.14 / jam * 0,15 (daur ulang) * 24 jam * 300 hari = $ 2.311
Jika Anda menghitung, bahwa model GO Anda akan bertahan lebih dari 300 hari, lebih baik membeli komputer daripada menggunakan AWS.
Perhitungan serupa dapat dibuat untuk layanan cloud apa pun untuk memutuskan apakah akan menggunakan komputer Anda atau cloud.
Angka umum untuk pemanfaatan daya komputasi adalah sebagai berikut:
- Komputer PhD: <15%;
- Kluster GPU pada PhD Slurm:> 35%
- Klaster Riset Perusahaan tentang Slurm:> 60%.
Secara umum, tingkat daur ulang lebih rendah di area di mana memikirkan ide-ide canggih lebih penting daripada mengembangkan solusi praktis. Di beberapa area tingkat pemanfaatan lebih rendah (studi interpretabilitas), sementara di wilayah lain jauh lebih tinggi (terjemahan mesin, pemodelan bahasa). Secara umum, daur ulang mobil pribadi biasanya selalu dilebih-lebihkan. Biasanya, sebagian besar sistem pribadi didaur ulang 5-10%. Oleh karena itu, saya sangat menyarankan agar tim peneliti dan perusahaan mengatur cluster GPU di Slurm daripada di desktop terpisah.
Tips bagi yang malas membaca
GPU terbaik secara keseluruhan : RTX 3080 dan RTX 3090.
GPU yang harus dihindari (sebagai peneliti) : Tesla cards, Quadro, Founders Edition, Titan RTX, Titan V, Titan XP.
Rasio performa-ke-harga yang bagus, tapi mahal : RTX 3080. Rasio
performa-ke-harga yang bagus, lebih murah : RTX 3070, RTX 2060 Super.
Saya punya sedikit uang : Beli kartu bekas. Hirarki: RTX 2070 ($ 400), RTX 2060 ($ 300), GTX 1070 ($ 220), GTX 1070 Ti ($ 230), GTX 1650 Super ($ 190), GTX 980 Ti (6GB $ 150).
Saya hampir tidak punya uang : banyak startup mengiklankan layanan cloud mereka. Gunakan kredit gratis di cloud, ubah dalam lingkaran sampai Anda dapat membeli GPU.
Saya berkompetisi di kompetisi Kaggle: RTX 3070.
Saya berusaha memenangkan persaingan dalam computer vision, pre-training atau mesin terjemahan : 4 buah RTX 3090. Tapi tunggu sampai ahli mengkonfirmasi bahwa ada rakitan dengan pendinginan yang baik dan daya yang cukup.
Saya sedang mempelajari pemrosesan bahasa alami : jika Anda tidak menyukai terjemahan mesin, pemodelan bahasa, atau pra-pembelajaran, RTX 3080 akan melakukannya.
Saya mulai melakukan GO dan benar - benar menyukainya : mulai dengan RTX 3070. Jika Anda tidak bosan dalam 6-9 bulan, jual dan beli empat RTX 3080. Tergantung pada apa yang Anda pilih selanjutnya (startup, Kaggle, riset, GO terapan), tahun dalam tiga, jual GPU Anda dan beli sesuatu yang lebih baik (GPU RTX generasi berikutnya).
Saya ingin mencoba GO, tetapi saya tidak berniat serius : RTX 2060 Super akan menjadi pilihan yang sangat baik, namun mungkin perlu penggantian PSU. Jika Anda memiliki slot PCIe x16 pada motherboard Anda, dan unit catu daya menghasilkan sekitar 300 watt, maka GTX 1050 Ti akan menjadi pilihan yang sangat baik, karena tidak memerlukan investasi lain.
Kluster GPU untuk simulasi paralel dengan kurang dari 128 GPU : jika Anda diizinkan membeli RTX untuk kluster: 66% 8x RTX 3080 dan 33% 8x RTX 3090 (hanya jika Anda dapat mendinginkan rakitan dengan baik). Jika pendinginan tidak cukup, beli GPU 33% RTX 6000 atau 8x Tesla A100. Jika Anda tidak dapat membeli GPU RTX, saya akan menggunakan 8 node Supermicro A100 atau 8 node RTX 6000.
GPU cluster untuk simulasi paralel dengan lebih dari 128 GPU: Pikirkan tentang mobil dengan 8 Tesla A100. Jika Anda membutuhkan lebih dari 512 GPU, pertimbangkan Sistem DGX A100 SuperPOD.