
Mari kita bicara tentang jaringan saraf yang menggunakan pembelajaran mendalam dan pembelajaran penguatan untuk bermain Snake. Anda akan menemukan kode di Github, analisis kesalahan, demonstrasi AI, dan eksperimen di dalamnya.
Sejak saya menonton film dokumenter Netflix di AlphaGo, saya terpesona oleh pembelajaran penguatan. Pembelajaran seperti itu sebanding dengan pembelajaran manusia: Anda melihat sesuatu, Anda melakukan sesuatu, dan tindakan Anda memiliki konsekuensi. Baik atau buruk. Anda belajar dari konsekuensi dan tindakan yang benar. Pembelajaran penguatan memiliki banyak aplikasi: mengemudi otonom, robotika, perdagangan, permainan. Jika Anda terbiasa dengan pembelajaran penguatan, lewati dua bagian berikutnya.
Pembelajaran penguatan
Prinsipnya sederhana. Agen belajar melalui interaksi dengan lingkungan. Dia memilih suatu tindakan dan menerima tanggapan dari lingkungan dalam bentuk keadaan (atau observasi) dan penghargaan. Siklus ini berlanjut terus menerus atau sampai terputus. Kemudian episode baru dimulai. Secara skematis terlihat seperti ini:

Tujuan agen adalah mendapatkan hadiah maksimum per episode. Pada awal pelatihan, agen memeriksa lingkungan: mencoba tindakan berbeda dalam keadaan yang sama. Saat pembelajaran berlangsung, agen semakin sedikit meneliti. Sebaliknya, dia memilih tindakan yang paling bermanfaat berdasarkan pengalamannya sendiri.
Pembelajaran Penguatan Mendalam
Pembelajaran mendalam menggunakan jaringan saraf untuk menghasilkan keluaran dari masukan. Dengan hanya satu lapisan tersembunyi, pembelajaran mendalam dapat memperbesar fitur apa pun. Bagaimana itu bekerja? Jaringan neural adalah lapisan dengan node. Lapisan pertama adalah lapisan data masukan. Lapisan kedua yang tersembunyi mengubah data menggunakan bobot dan fungsi aktivasi. Lapisan terakhir adalah lapisan perkiraan.

Seperti namanya, deep reinforcement learning merupakan kombinasi dari deep learning dan reinforcement learning. Agen belajar untuk memprediksi tindakan terbaik untuk suatu keadaan menggunakan keadaan sebagai masukan, nilai tindakan sebagai keluaran, dan penghargaan untuk menyesuaikan bobot ke arah yang benar. Mari menulis Snake menggunakan pembelajaran penguatan mendalam.

Mendefinisikan tindakan, penghargaan, dan kondisi
Untuk mempersiapkan permainan bagi agen, kami meresmikan masalahnya. Mendefinisikan tindakan itu mudah. Agen bisa memilih arah: atas, kanan, bawah atau kiri. Imbalan dan status ruang sedikit lebih rumit. Ada banyak solusi dan satu akan bekerja lebih baik dan yang lainnya lebih buruk. Saya akan menjelaskan salah satunya di bawah ini dan mari kita coba.
Jika Snake mengambil sebuah apel, hadiahnya adalah 10 poin. Jika Ular mati, kurangi 100 poin dari penghargaan. Untuk membantu agen, tambahkan 1 poin saat Ular bergerak mendekati apel dan kurangi satu poin saat Ular menjauh dari apel.
Negara memiliki banyak pilihan. Anda dapat mengambil koordinat Ular dan apel atau arah ke apel. Penting untuk menambahkan lokasi rintangan, yaitu dinding dan tubuh Ular, sehingga agen belajar untuk bertahan hidup. Di bawah ini adalah ringkasan tindakan, ketentuan, dan penghargaan. Kita akan melihat nanti bagaimana penyesuaian negara mempengaruhi kinerja.

Ciptakan lingkungan dan agen
Dengan menambahkan metode ke program Snake, kami menciptakan lingkungan belajar penguatan. Metode adalah sebagai berikut:
reset(self), step(self, action)dan get_state(self). Selain itu, Anda perlu menghitung hadiah di setiap langkah agen. Coba lihat run_game(self).
Agen tersebut bekerja dengan jaringan Deep Q untuk menemukan tindakan terbaik. Parameter model di bawah ini:
# epsilon sets the level of exploration and decreases over time
params['epsilon'] = 1
params['gamma'] = .95
params['batch_size'] = 500
params['epsilon_min'] = .01
params['epsilon_decay'] = .995
params['learning_rate'] = 0.00025
params['layer_sizes'] = [128, 128, 128]
Jika Anda tertarik untuk melihat kodenya, Anda dapat menemukannya di GitHub .
Agen memainkan Snake
Dan sekarang - pertanyaan kuncinya! Akankah agen belajar bermain? Mari kita lihat bagaimana itu berinteraksi dengan lingkungan. Di bawah ini adalah game pertama. Agen tidak mengerti apapun:

Apel pertama! Tapi sepertinya jaringan saraf tidak tahu apa yang dilakukannya.

Menemukan apel pertama ... dan kemudian membentur tembok. Awal dari game keempat belas:

Agen itu belajar: jalannya menuju apel bukanlah yang terpendek, tetapi dia menemukan apel itu. Di bawah ini adalah game ketiga puluh:

Setelah hanya 30 pertandingan, Snake menghindari tabrakan dengan dirinya sendiri dan menemukan cara cepat menuju apel.
Mari bermain dengan luar angkasa
Dimungkinkan untuk mengubah ruang negara dan mencapai kinerja yang serupa atau lebih baik. Di bawah ini adalah opsi yang memungkinkan.
- Tidak Ada Arah: Jangan beri tahu agen arah ke mana Ular bergerak.
- Status dengan koordinat: ganti posisi apel (atas, kanan, bawah, dan / atau kiri) dengan koordinat apel (x, y) dan ular (x, y). Nilai koordinat berada pada skala dari 0 hingga 1.
- Arah 0 atau 1 negara.
- Status hanya dinding: Melaporkan hanya jika ada dinding. Tapi bukan tentang dimana tubuh itu: bawah, atas, kanan atau kiri.

Di bawah ini adalah grafik kinerja untuk berbagai negara bagian:
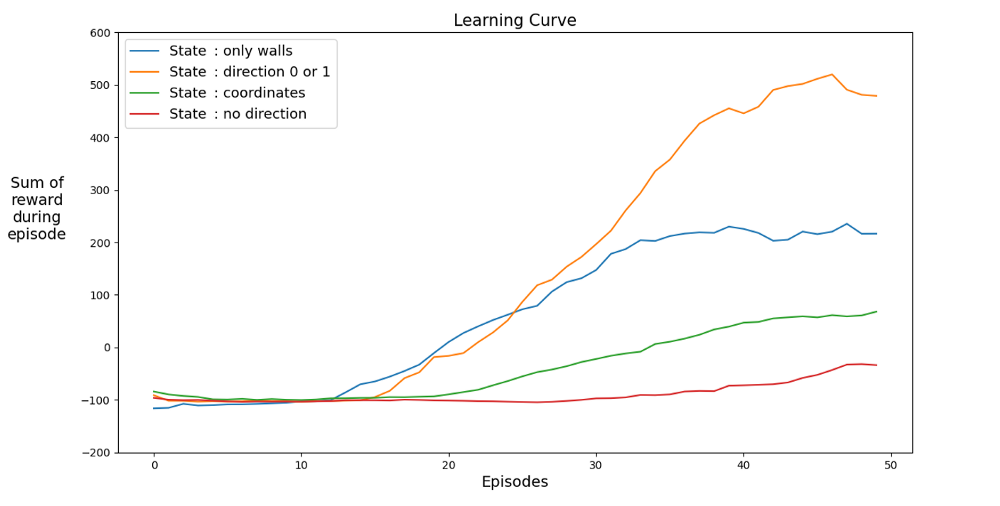
Mari temukan ruang yang mempercepat pembelajaran. Grafik menunjukkan pencapaian rata-rata dari 12 game terakhir dengan status berbeda.
Jelas bahwa ketika ruang negara memiliki arah, agen belajar dengan cepat, mencapai hasil terbaik. Tetapi ruang dengan koordinat lebih baik. Mungkin Anda bisa mencapai hasil yang lebih baik dengan melatih jaringan lebih lama. Alasan untuk belajar lambat mungkin karena banyaknya kemungkinan status: 20⁴ * 2⁴ * 4 = 1.024.000. Jalur 20 x 20, 64 opsi rintangan dan 4 opsi tajuk saat ini. Untuk ruang varian asli, 3² * 2⁴ * 4 = 576. Ini lebih dari 1700 kali kurang dari 1.024.000 dan tentu saja memengaruhi pembelajaran.
Mari bermain dengan penghargaan
Apakah ada logika reward internal yang lebih baik? Izinkan saya mengingatkan Anda bahwa Ular dianugerahi seperti ini:

Kesalahan pertama. Berjalan berputar-putar
Bagaimana jika Anda mengubah -1 menjadi +1? Ini bisa memperlambat kurva belajar, tapi pada akhirnya Snake tidak mati. Dan ini sangat penting untuk permainan. Agen dengan cepat belajar untuk menghindari kematian.

Pada satu titik waktu, agen menerima satu poin bertahan hidup.
Kesalahan kedua. Menabrak dinding
Mari kita ubah jumlah poin untuk mengoper apel menjadi -1. Mari kita tetapkan hadiah untuk apel itu sendiri pada 100 poin. Apa yang akan terjadi? Agen menerima penalti untuk setiap gerakan, jadi dia bergerak ke apel secepat mungkin. Ini bisa terjadi, tetapi ada opsi lain.

AI berjalan di sepanjang tembok terdekat untuk meminimalkan kerugian.
Pengalaman
Anda hanya membutuhkan 30 game. Rahasia kecerdasan buatan adalah pengalaman permainan sebelumnya, yang diperhitungkan agar jaringan saraf belajar lebih cepat. Pada setiap langkah reguler, serangkaian langkah pemutaran ulang (parameter
batch_size) dilakukan . Ini bekerja dengan sangat baik karena, untuk pasangan tindakan dan keadaan tertentu, ada sedikit perbedaan dalam penghargaan dan keadaan selanjutnya.
Kesalahan nomor 3. Tidak ada pengalaman Apakah pengalaman
benar-benar penting? Mari kita keluarkan. Dan ambil hadiah 100 poin untuk apel. Di bawah ini adalah agen tanpa pengalaman yang telah memainkan 2500 game.

Meskipun agen memainkan 2500 (!) Game, dia tidak memainkan snake. Permainan berakhir dengan cepat. Jika tidak, 10.000 pertandingan akan memakan waktu berhari-hari. Setelah 3000 pertandingan kami hanya memiliki 3 apel. Setelah 10.000 pertandingan, apel masih ada 3. Apakah keberuntungan atau hasil pembelajaran?
Memang, pengalaman sangat membantu. Setidaknya pengalaman yang memperhitungkan hadiah dan jenis ruang. Berapa replay yang Anda butuhkan per langkah? Jawabannya mungkin mengejutkan. Untuk menjawab pertanyaan ini, mari bermain-main dengan parameter batch_size. Dalam eksperimen asli, ini disetel ke 500. Ikhtisar hasil dengan pengalaman berbeda:

200 game dengan pengalaman berbeda: 1 game (tanpa pengalaman), 2 dan 4. Rata-rata untuk 20 game.
Bahkan dengan pengalaman di 2 game, sang agen sudah belajar bermain. Dalam grafik Anda melihat dampaknya
batch_size, kinerja yang sama dicapai untuk 100 game jika 4 digunakan, bukan 2. Solusi dalam artikel memberikan hasil. Agen tersebut belajar bermain Snake dan mendapatkan hasil yang bagus, mengumpulkan 40 hingga 60 apel dalam 50 pertandingan.
Seorang pembaca yang penuh perhatian mungkin berkata: jumlah maksimum apel pada seekor ular adalah 399. Mengapa AI tidak menang? Faktanya, perbedaan antara 60 dan 399 kecil. Dan ini benar. Dan ada masalah di sini: Ular tidak menghindari tabrakan saat berputar balik.
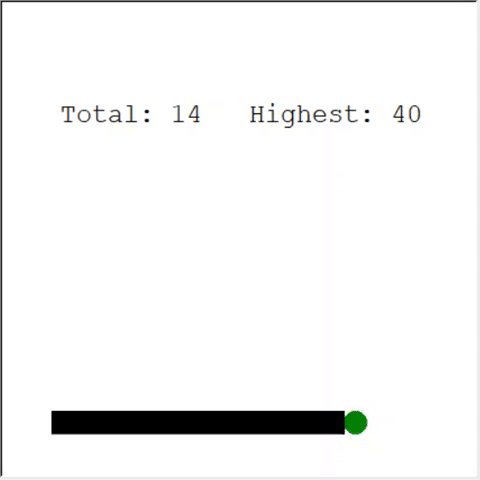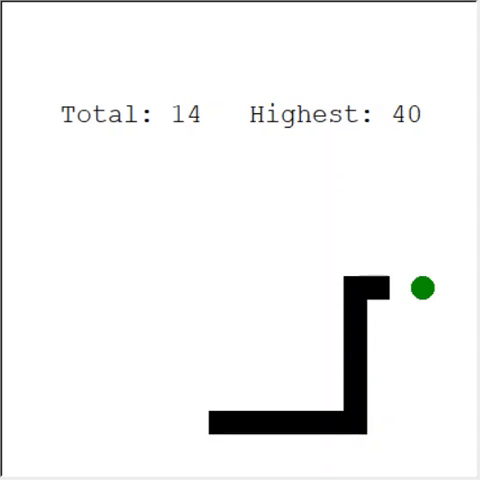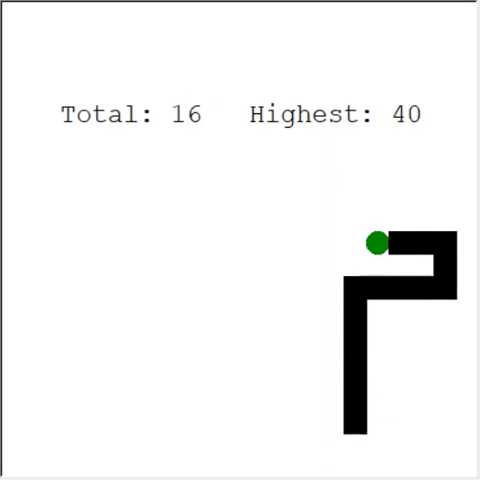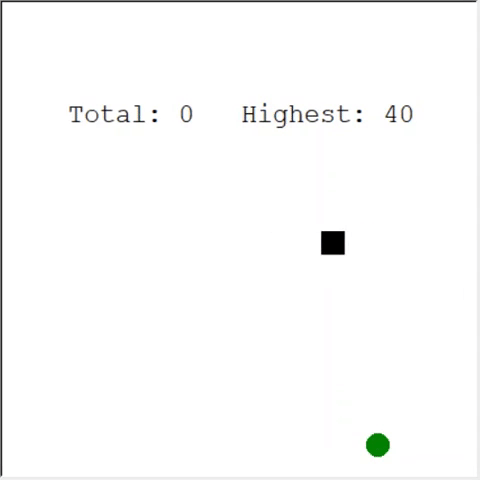
Cara yang menarik untuk memecahkan masalah tersebut adalah dengan menggunakan CNN sebagai lapangan permainan. Dengan cara ini AI dapat melihat keseluruhan game, bukan hanya rintangan di sekitar. Dia akan dapat mengenali tempat-tempat yang perlu dikunjungi untuk menang.
Bibliografi
[1] K. Hornik, M. Stinchcombe, H. White, Multilayer feedforward networks are universal approximators (1989), Neural networks 2.5: 359–366
[2] Mnih et al, Playing Atari with Deep Reinforcement Learning (2013)
[2] Mnih et al, Playing Atari with Deep Reinforcement Learning (2013)
, Level Up , - SkillFactory:
- Machine Learning (12 )
- « Machine Learning Data Science» (20 )
- «Machine Learning Pro + Deep Learning» (20 )
- Data Science (12 )
E
- - (8 )
- - Data Analytics (5 )
- (6 )
- (18 )
- «Python -» (9 )
- DevOps (12 )
- Java- (18 )
- JavaScript (12 )
- UX- (9 )
- Web- (7 )
