
Perusahaan dapat membantu pengembang mereka memaksimalkan produktivitas dengan berbagai cara, mulai dari mengubah ruang kantor hingga memperoleh alat yang lebih baik dan membersihkan kode sumber. Tetapi keputusan mana yang akan memiliki dampak terbesar? Berdasarkan literatur tentang pengembangan perangkat lunak dan psikologi industri / organisasi, kami mengidentifikasi faktor-faktor terkait produktivitas dan mewawancarai 622 pengembang dari tiga perusahaan. Kami tertarik pada faktor-faktor yang disebutkan dan bagaimana orang menilai produktivitas mereka sendiri. Temuan kami menunjukkan bahwa harga diri paling dipengaruhi oleh faktor non-teknis: antusiasme di tempat kerja, dukungan untuk ide-ide baru oleh rekan-rekan Anda, dan mendapatkan umpan balik yang berguna tentang produktivitas Anda. Dibandingkan dengan pekerja pengetahuan lainnya,Penilaian pengembang perangkat lunak terhadap produktivitas mereka lebih bergantung pada variasi tugas dan kemampuan untuk bekerja dari jarak jauh.
1. Perkenalan
Penting untuk meningkatkan produktivitas pengembang. Menurut definisi, saat mereka menyelesaikan tugas, mereka dapat menghabiskan waktu luang untuk tugas berguna lainnya: memperkenalkan fitur baru dan pemeriksaan baru. Tapi apa yang membantu pengembang menjadi lebih produktif?
Perusahaan membutuhkan panduan praktis tentang faktor mana yang harus dimanipulasi untuk memaksimalkan produktivitas. Misalnya, haruskah pengembang menghabiskan waktu mencari alat dan pendekatan yang lebih baik, atau haruskah mereka mematikan pemberitahuan pada siang hari? Haruskah pemimpin berinvestasi dalam refactoring untuk mengurangi kompleksitas kode, atau memberi pengembang lebih banyak otonomi? Haruskah bos berinvestasi dalam alat pengembangan yang lebih baik atau kantor yang lebih nyaman? Dalam dunia yang ideal, kita akan berinvestasi dalam berbagai faktor untuk meningkatkan produktivitas, tetapi waktu dan uang terbatas, jadi kita harus memilih.
Artikel ini adalah tentang studi terluas tentang perkiraan produktivitas pengembang perangkat lunak hingga saat ini. Seperti dijelaskan di bagian 3.1, produktivitas dapat diukur secara obyektif (misalnya, dalam baris kode per bulan) atau secara subyektif (seperti yang diperkirakan oleh pengembang sendiri). Meskipun tidak ada pendekatan yang disukai, kami telah mencoba membahas topik secara luas dengan penilaian subjektif untuk menjawab tiga pertanyaan:
- Faktor apa yang menjadi prediktor terbaik tentang bagaimana pengembang akan mengevaluasi produktivitas mereka?
- Bagaimana faktor-faktor ini berubah dari perusahaan ke perusahaan?
- Apa yang memprediksikan penilaian pengembang atas produktivitas mereka, khususnya, dibandingkan dengan pekerja berpengetahuan lainnya?
Untuk menjawab pertanyaan pertama, kami melakukan penelitian di sebuah perusahaan software besar.
Untuk menjawab pertanyaan kedua, yang membantu untuk memahami sejauh mana hasil yang diperoleh dapat digeneralisasikan, kami melakukan studi di dua perusahaan dari industri yang berbeda.
Untuk menjawab pertanyaan ketiga, yang membantu untuk memahami bagaimana pengembang berbeda dari yang lain, kami melakukan studi di antara perwakilan dari profesi lain dan membandingkannya dengan hasil yang diperoleh dalam studi pengembang.
Hasil kami menunjukkan bahwa di perusahaan yang kami pelajari, harga diri untuk produktivitas mereka sangat dipengaruhi oleh antusiasme di tempat kerja, dukungan rekan kerja untuk ide-ide baru, dan umpan balik yang berguna tentang produktivitas mereka. Dibandingkan dengan pekerja pengetahuan lainnya, penilaian pengembang perangkat lunak terhadap produktivitas mereka lebih bergantung pada variasi tugas dan kemampuan untuk bekerja dari jarak jauh. Perusahaan dapat menggunakan temuan kami untuk memprioritaskan inisiatif terkait produktivitas (Bagian 4.7).
Bagian 2 menjelaskan perusahaan yang kami pelajari. Bagian 3 menjelaskan metodologi penelitian. Bagian 4 menjelaskan dan menganalisis hasil yang diperoleh. Bagian 5 menjelaskan karya lain tentang topik ini.

2. Perusahaan yang diteliti
2.1. Google
Google memiliki sekitar 40 kantor pengembangan di seluruh dunia, mempekerjakan puluhan ribu pengembang. Perusahaan menghargai kolaborasi erat dalam tim, dan kantor biasanya bersifat terbuka untuk mendekatkan anggota tim. Perusahaan ini relatif muda (didirikan pada akhir 1990-an), struktur organisasinya agak datar, dan pengembang memiliki banyak otonomi. Proses promosi mencakup umpan balik dari rekan kerja, dan pengembang tidak perlu beralih ke posisi manajerial untuk maju. Pengembang merencanakan waktunya sendiri, kalender mereka ditampilkan di jaringan perusahaan. Google menggunakan proses pengembangan tangkas (seperti Agile), biasanya diterapkan ke seluruh tim.
Google menghargai keterbukaan. Sebagian besar pengembang mengerjakan basis kode monolitik umum, dan mereka didorong untuk membuat perubahan pada kode proyek orang lain. Perusahaan memiliki budaya pengujian dan peninjauan kode yang kuat: kode yang dikirimkan ke repositori ditinjau oleh pengembang lain, biasanya menggunakan pengujian. Kebanyakan menulis kode sisi server yang sering dirilis dan membuatnya relatif mudah untuk meluncurkan perbaikan. Toolkit pengembangan sebagian besar disatukan (tidak termasuk editor) dan dibangun secara internal, termasuk alat analisis dan integrasi berkelanjutan, dan infrastruktur untuk rilis.
2.2. ABB
ABB memiliki lebih dari 100.000 karyawan di seluruh dunia. Sebagai konglomerat teknik, perusahaan ini mempekerjakan berbagai macam profesi. Ada sekitar 4.000 pengembang perangkat lunak umum dan lebih dari 10.000 pengembang aplikasi yang membangun sistem industri menggunakan bahasa visual dan tekstual khusus industri. Untuk mengoperasikan infrastruktur TI yang besar, perusahaan memiliki sejumlah besar staf karyawan yang tanggung jawabnya mencakup pembuatan skrip dan pemrograman yang disederhanakan.
Meskipun ABB telah mengambil alih sejumlah perusahaan kecil, ABB memiliki organisasi pusat yang bertanggung jawab untuk menyatukan proses pengembangan perangkat lunak. Jadi, terlepas dari perbedaan antar departemen, sebagian besar alat dan pendekatannya konsisten. Hal yang sama berlaku untuk sebagian besar jalur karier: untuk teknisi dari pengembang junior hingga senior, dan untuk eksekutif, dari pemimpin grup hingga pemimpin departemen dan manajemen pusat.
2.3. Instrumen Nasional
Instrumen Nasional didirikan pada tahun 1970-an. Pengembangan perangkat lunak terutama terkonsentrasi di empat pusat penelitian dan pengembangan internasional. Kalender karyawan dapat dilihat oleh seluruh perusahaan, siapa pun dapat membuat janji dengan karyawan lain.
Tanggung jawab pekerjaan memfasilitasi proses pengembangan. Pengembang tidak dapat memilih proyek secara mandiri, tetapi mereka dapat mengambil tugas atau fitur tertentu. Sebagian besar bekerja dengan basis kode monolitik umum, dengan bagian logis yang berbeda memiliki pemilik tertentu. Kode yang dimasukkan harus disetujui oleh "pemilik". Sebaiknya kode dianalisis oleh pimpinan teknis. Kebijakan ini opsional, tetapi banyak yang mengikutinya.
Pengembang memiliki banyak kebebasan dalam memilih alat. Tidak ada alat generik, kecuali ada manfaat langsung. Misalnya, pilihan IDE sangat bergantung pada tugas. Ada sejumlah alat pembuatan dan pengujian khusus yang tersedia. Bagian perusahaan yang berbeda memiliki sistem yang berbeda standar untuk manajemen dan analisis kode sumber. Pembaruan perangkat lunak biasanya dirilis setiap tiga bulan atau setiap tahun, dengan pengecualian untuk patch kritis yang langka.
Tabel 1. Profil dari tiga perusahaan yang diteliti:
| ABB | Instrumen Nasional | ||
| Ukuran | Besar. | Besar. | Mungil. |
| Kantor | Buka kantor. | Kantor terbuka dan tertutup. | Buka kantor. |
| Alat | Sebagian besar alat pengembangan terpadu. | Alat yang sama. | Fleksibilitas dalam pemilihan alat |
| Tipe perkembangan | Sebagian besar sisi server dan kode seluler. | Kombinasi pengembangan web, perangkat lunak tertanam dan desktop. | Sebagian besar perangkat lunak tertanam dan desktop. |
| Gudang | Repositori monolitik. | Repositori terpisah. | Repositori monolitik. |
| Bias | Pengembangan perangkat lunak. | Konglomerat teknik. | Pengembangan perangkat lunak dan peralatan. |
3. Metodologi
Tujuan kami: untuk mengetahui faktor-faktor apa yang memprediksi produktivitas pengembang perangkat lunak. Untuk melakukan ini, kami melakukan studi yang berisi serangkaian pertanyaan, satu set faktor produktivitas, dan satu set variabel demografis.
3.1 Menilai produktivitas Anda
Pertama, mari kita gambarkan bagaimana kita akan mengukur produktivitas. Ramírez dan Nembhard telah mengusulkan klasifikasi teknik pengukuran kinerja yang dijelaskan dalam literatur, termasuk analisis titik fungsi, penilaian diri, penilaian sejawat, proporsionalitas hasil dan upaya, dan penggunaan waktu secara profesional [2]. Teknik-teknik ini dapat dibagi menjadi obyektif (misalnya, berapa banyak baris kode yang ditulis per minggu) dan subjektif (misalnya, penilaian diri atau peer review).
Tidak ada teknik yang disukai; kedua kategori memiliki kelemahan. Pengukuran obyektif kurang fleksibel dan menyenangkan. Mari kita ambil jumlah baris kode per minggu. Pengembang yang produktif dapat menulis perbaikan satu baris untuk bug yang sulit ditemukan. Dan pengembang yang tidak produktif dapat dengan mudah meningkatkan jumlah baris. Di sisi lain, pengukuran subjektif bisa jadi tidak akurat karena bias kognitif. Ambil penilaian rekan: mereka mungkin tidak menyukai pengembang yang produktif, dan oleh karena itu, peringkat mereka akan lebih buruk, bahkan jika rekan kerja mencari objektivitas.
Seperti tim peneliti yang dipimpin oleh Meyer yang menganalisis produktivitas pengembang perangkat lunak [3], kami menggunakan pertanyaan penelitian kami sebagai ukuran subjektif dari produktivitas. Ada dua alasan utama. Pertama, seperti dicatat oleh Ramirez dan Nembhardt, penelitian adalah "cara sederhana dan populer untuk mengukur produktivitas [pekerja pengetahuan]." Kedua, penelitian memberikan tanggapan dari pengembang dalam peran yang berbeda, dan juga memungkinkan responden untuk menambahkan informasi yang berbeda ke penilaian kinerja mereka.
Angka: 1. Metodologi penelitian:

Kami bertanya kepada responden seberapa setuju mereka dengan pernyataan:
Saya secara teratur mencapai produktivitas tinggi.
Dengan itu, kami ingin mengukur produktivitas seluas mungkin. Kami pertama-tama merumuskan delapan opsi untuk pertanyaan tersebut, dan kemudian menguranginya menjadi di atas dengan berbicara secara informal dengan lima pengembang Google tentang interpretasi mereka atas frasa tersebut (Gambar 1, kiri bawah). Kami menambahkan kata "tinggi" dan "teratur" ke pertanyaan karena tiga alasan. Pertama, kami ingin menangkap keadaan di mana orang dapat membandingkan diri mereka sendiri. Kedua, kami ingin status ini menjadi tinggi untuk menghindari efek mencapai batas atas dalam tanggapan responden. Ketiga, kami ingin responden fokus pada dua ukuran produktivitas tertentu - intensitas dan frekuensi. Ke depan, peneliti dapat menerapkan pengukuran yang lebih detail dengan membagi intensitas dan frekuensi pada dua isu yang terpisah.
Kami mengujinya dengan meminta tiga eksekutif di Google untuk mengirimkannya ke tim mereka dan bertanya, "Apa yang Anda pertimbangkan saat menanggapi pernyataan produktivitas?" Kami menerima tanggapan dari 23 pengembang (Gambar 1, tengah bawah). Pilihan tersebut dianggap dapat diterima untuk tujuan kami karena pertimbangan responden sesuai dengan harapan kami mengenai nilai produktivitas. Pertimbangan ini meliputi masalah alur kerja, hasil kerja, berada di zona atau alur, kebahagiaan, tujuan yang dicapai, efisiensi pemrograman, kemajuan, dan meminimalkan pemborosan. Kami tidak menganalisis tanggapan ini dalam makalah ini, tetapi penelitian ini menyertakan empat tambahan, ukuran produktivitas yang diambil dari pekerjaan sebelumnya [2], [4], [5].
Kami memilih dua ukuran produktivitas yang nyaman untuk menambahkan data yang objektif guna mengontekstualisasikan harga diri, lalu menghubungkannya satu sama lain di Google. Ukuran objektif pertama adalah jumlah baris kode yang diubah oleh pengembang per minggu - ukuran produktivitas yang populer namun menantang [6], [7]. Ukuran kedua adalah jumlah perubahan yang dibuat oleh pengembang ke basis kode Google utama per unit waktu. Ini hampir setara dengan pull request bulanan yang digunakan oleh tim yang dipimpin oleh Vasilescu [8]. Untuk menilai produktivitas kami, kami menggunakan tanggapan untuk survei serupa di Google (n = 3344 tanggapan). Kami tidak dapat menggunakan data dari penelitian kami untuk analisis ini karena tanggapan tidak berisi ID peserta.di mana ukuran objektif produktivitas dapat dibandingkan. Dalam penelitian tersebut, mereka mengajukan pertanyaan serupa: "Seberapa sering Anda merasa sangat produktif di tempat kerja?" Peserta dapat menjawab "Jarang atau tidak pernah", "Kadang-kadang", "Sekitar separuh waktu", "Sering kali" dan "Selalu atau hampir selalu". Kami kemudian membuat regresi linier dengan kinerja yang dilaporkan sendiri sebagai variabel dependen ordinal (masing-masing diberi kode 1, 2, 3, 4, dan 5). Regresi linier mengasumsikan jarak yang sama antara peringkat produktivitas. Mengingat kata-kata yang digunakan dalam pertanyaan tersebut, kami menganggap asumsi ini dapat dibenarkan. Untuk regresi logistik terurut, asumsi ini tidak diperlukan. Penerapan teknik ini di sini memberikan hasil yang andal: koefisien yang sama signifikan dalam linier,dan dalam model yang teratur.
Kami menggunakan ukuran obyektif logaritmik sebagai variabel independen, karena keduanya memiliki kecondongan positif. Untuk kontrol, kami mengambil kode pekerjaan (misalnya, insinyur perangkat lunak, insinyur penelitian, dll.) Sebagai variabel kategori, serta peringkat (junior, menengah, senior, dll.) Sebagai angka (misalnya, 3 untuk perangkat lunak insinyur tingkat pemula di Google). Kode pekerjaan signifikan secara statistik untuk dua peran pekerja di setiap model linier. Ada tiga model secara keseluruhan: dua dengan salah satu ukuran objektif dan satu lagi dengan kedua ukuran objektif.

Angka: 2: Model yang memprediksi penilaian subjektif produktivitas berdasarkan dua ukuran objektif. ns berarti faktor yang secara statistik tidak signifikan dengan p> 0,05, ** berarti p <0,01, *** berarti p <0,001. Penjelasan lengkap model diberikan dalam Bahan Pelengkap.
Hasil kontekstualisasi ditunjukkan pada Gambar. 2. Setiap model menunjukkan tingkat yang signifikan secara statistik dengan peringkat negatif, yang kami interpretasikan sebagai: pengembang dengan peringkat yang lebih tinggi cenderung menilai diri mereka sendiri sebagai sedikit kurang produktif. Ini adalah argumen yang kuat untuk kontrol peringkat (bagian 3.7.). Dua model pertama menunjukkan hubungan positif yang penting antara ukuran produktivitas objektif dan subjektif. Artinya, semakin banyak baris kode ditulis atau diubah, semakin produktif seorang pengembang menganggap dirinya sendiri. Model gabungan yang dihasilkan dan perkiraan untuk dua model pertama menunjukkan bahwa jumlah perubahan yang dilakukan merupakan indikator produktivitas yang lebih penting daripada jumlah baris yang ditulis. Tetapi perhatikan bahwa di semua model parameter R 2, mewakili proporsi varian yang dijelaskan, cukup rendah - kurang dari 3% untuk setiap model.
Secara umum, hasil yang diperoleh menunjukkan bahwa jumlah baris kode dan perubahan yang dilakukan mempengaruhi penilaian pengembang terhadap produktivitas mereka, tetapi tidak signifikan.
3.2. Faktor produktivitas
Kemudian, selama studi berlangsung, kami bertanya kepada peserta tentang faktor-faktor yang dianggap terkait dengan produktivitas di studi lain. Kami telah mengumpulkan pertanyaan dari empat sumber (Gambar 1, kiri tengah). Sumber-sumber ini diambil karena, sejauh pengetahuan kami, mereka mewakili ikhtisar paling komprehensif tentang faktor produktivitas individu dalam penelitian programmer dan pekerja pengetahuan lainnya.
Sumber pertamaMerupakan alat yang dibuat oleh tim yang dipimpin oleh Palvalin untuk meninjau ukuran produktivitas untuk pekerja pengetahuan [4]. Alat yang disebut SmartWoW telah digunakan oleh empat perusahaan dan mencakup aspek ruang kerja fisik, virtual dan sosial, praktik kerja pribadi, dan kesejahteraan di tempat kerja. Kami telah mengubah beberapa pertanyaan untuk lebih mencerminkan terminologi pengembang saat ini dan lebih cocok dengan bahasa Inggris Amerika. Misalnya, SmartWoW bertanya:
Saya sering bekerja jarak jauh untuk melaksanakan tugas yang membutuhkan konsentrasi tanpa gangguan.
Kami telah memparafrasekan:
Saya sering bekerja dari jarak jauh untuk melaksanakan tugas-tugas yang membutuhkan konsentrasi tanpa gangguan.
Dari SmartWoW, pertama-tama kami memilih 38 pertanyaan untuk studi kami.
Sumber kedua adalah review oleh Hernaus dan Mikulić tentang dampak karakteristik lingkungan kerja terhadap produktivitas pekerja pengetahuan [9]. Pekerjaan mereka yang terbukti mencerminkan studi produktivitas sebelumnya: kuesioner desain lingkungan kerja [10], studi lingkungan kerja diagnostik [11], penilaian kolaborasi kelompok [12] penilaian "sifat tugas" [13]. Kami telah mengubah pertanyaan menjadi pendek dan konsisten. Untuk tujuan yang sama, kami mengambil pertanyaan langsung dari tempat kerja [12], yang dikhususkan untuk kelompok kerja dengan sedikit pertimbangan tentang produktivitas pribadi.
Sumber ketiga- review terstruktur dari Wagner dan Ruhe faktor produktivitas dalam pengembangan perangkat lunak [14]. Tidak seperti sumber lain, karya ini belum sepenuhnya ditinjau oleh komunitas ilmiah dan tidak mengandung penelitian empiris asli. Namun sepengetahuan kami, ini adalah survei paling komprehensif tentang riset produktivitas pemrograman. Faktor-faktor yang dirumuskan oleh Wagner dan Rouet dibagi menjadi faktor-faktor teknis dan non-kuantitatif, dan kemudian faktor lingkungan, budaya perusahaan, proyek, produk dan lingkungan pengembangan, kemampuan dan pengalaman juga disorot.
Sumber keempatMerupakan studi pengembang Microsoft yang dipimpin oleh tim yang dipimpin oleh Meyer. Dari situ, kami mengumpulkan lima alasan utama hari kerja produktif, termasuk penetapan tujuan, rapat kerja, dan istirahat dari pekerjaan [15].
Kami juga menambahkan tiga faktor yang menurut kami tidak diperhitungkan dengan baik dalam karya-karya sebelumnya, tetapi ternyata penting dalam konteks Google. Salah satunya adalah penilaian produktivitas pekerja pengetahuan [16], pendahulu SmartWoW yang tidak dipublikasikan. Kami mengadaptasinya seperti ini:
Informasi yang diberikan kepada saya (laporan bug, skrip pengguna, dll.) Akurat.
Faktor kedua diambil dari kuisioner desain lingkungan kerja dan diadaptasi sebagai berikut:
Saya mendapatkan umpan balik yang berguna tentang produktivitas kerja saya.
Dan kami membuat faktor ketiga yang penting di lingkungan ABB:
Saya memerlukan akses langsung ke perangkat keras tertentu untuk menguji perangkat lunak saya.
Pertama, kami memilih 127 faktor. Untuk menguranginya menjadi sejumlah pertanyaan yang responden dapat menjawab tanpa kelelahan yang signifikan [17], kami menggunakan kriteria yang ditunjukkan di tengah Gambar. 1:
- Duplikat dihapus. Misalnya, dalam SmartWoW [4] dan kerja Meyer dengan rekan kerja [15], penetapan tujuan dianggap sebagai faktor penting dalam produktivitas.
- Faktor-faktor serupa digabungkan. Misalnya, Hernaus dan Mikulich menggambarkan aspek interaksi yang berbeda antara kelompok kerja yang meningkatkan produktivitas, tetapi kami telah menguranginya menjadi satu faktor [9].
- Preferensi diberikan kepada faktor-faktor dengan kegunaan yang jelas. Misalnya, SmartWoW [4] memiliki faktor berikut:
Karyawan memiliki kesempatan untuk melihat kalender satu sama lain.
Di Google, hal ini berlaku di semua tempat dan tidak mungkin berubah, sehingga faktor tersebut memiliki utilitas yang rendah.
Kami telah menerapkan kriteria ini bersama-sama dan berulang-ulang. Pertama, poster besar dari semua pertanyaan kandidat untuk digunakan dalam penelitian dicetak. Kemudian kami memasang poster Google di samping kantor kami. Kemudian masing-masing dari kami secara mandiri menganalisis pertanyaan berdasarkan kriteria di atas. Poster digantung selama beberapa minggu, kami secara berkala menambah dan merevisi daftar itu lagi. Akhirnya, daftar pertanyaan terakhir dibuat.
Studi kami memasukkan 48 faktor dalam bentuk pernyataan (Gbr. 4, kolom kiri). Responden menunjukkan tingkat persetujuan mereka dengan pernyataan ini dalam skala lima poin, dari "Sangat tidak setuju" hingga "Sangat setuju". Faktor dapat dikelompokkan ke dalam blok yang terkait dengan metodologi, fokus, pengalaman, pekerjaan, peluang, orang, proyek, perangkat lunak, dan konteks. Kami juga menanyakan satu pertanyaan terbuka tentang faktor-faktor yang menurut responden mungkin kami lewatkan. Kuesioner lengkap dari penelitian kami tersedia di Materi Tambahan.

Angka: 3: Contoh pertanyaan dari penelitian.
3.3. Demografi
Kami mengajukan pertanyaan tentang beberapa faktor demografis, seperti yang ditunjukkan pada Gambar 1:
- Lantai.
- Posisi.
- Pangkat.
Penulis karya sebelumnya telah menyarankan bahwa jenis kelamin dikaitkan dengan faktor produktivitas pengembang perangkat lunak, misalnya, dengan keberhasilan debugging [18]. Oleh karena itu, penelitian memiliki pertanyaan opsional tentang jenis kelamin (laki-laki, perempuan, menolak menjawab, saya sendiri). Responden yang tidak menjawab pertanyaan dimasukkan ke dalam kelompok “menolak menjawab” (Google n = 26 [6%], ABB n = 4 [3%], Instrumen Nasional n = 5 [6%]). Kami memperlakukan data ini sebagai kategori.
Untuk posisi tersebut, kami mengambil senioritas kami di Google dari departemen SDM. Ini tidak mungkin dengan ABB dan Instrumen Nasional, jadi kami menambahkan pertanyaan opsional ke penelitian. Di ABB, dengan tidak adanya tanggapan (n = 4 [3%]), kami mengambil pengalaman 12 tahun, ini adalah rata-rata dari data yang dikumpulkan. Di Instrumen Nasional, kami mengambil 9 tahun untuk alasan yang sama (n = 1 [1%]). Anda dapat membuatnya lebih sulit [19], misalnya, menggunakan substitusi untuk memprediksi nilai yang hilang berdasarkan data yang tersedia. Misalkan informasi peringkat yang hilang dapat diisi dengan cukup akurat berdasarkan posisi dan jenis kelamin. Namun, kami hanya mengganti nilai statistik rata-rata, karena faktor demografis bukan yang terpenting bagi kami, mereka hanya menyertai informasi untuk kontrol. Kami memproses data ini sebagai angka.
Dalam hal peringkat, di Google kami meminta peserta untuk menunjukkan level mereka sebagai angka. Jawaban yang hilang (n = 26 [6%]) adalah nilai yang paling umum.
Di ABB, kontributor dapat secara opsional menunjukkan "pengembang perangkat lunak junior atau senior", meskipun banyak yang menunjukkan judul "berbeda". Jika jawabannya mencantumkan kata-kata:
- lebih tua
- terkemuka
- Pengelola
- arsitek
- peneliti
- utama
- ilmuwan
kemudian kami merujuk jawaban seperti itu kepada jawaban "senior". Sisanya disebut sebagai "junior". Jawaban yang hilang (n = 4 [3%]) kami kaitkan dengan arti yang paling umum - “senior”.
Instrumen Nasional memiliki pilihan:
- penantang
- staf
- lebih tua
- arsitek / insinyur utama
- kepala arsitek / insinyur
- insinyur terhormat
- peserta
- lain
Satu-satunya "lainnya" ternyata adalah seorang magang, yang kami pindahkan ke "pelamar". Jawaban yang hilang (n = 3 [4%]) kami kaitkan dengan arti yang paling umum - “senior”.
Kami telah membuat kode peringkat di semua perusahaan dengan angka.
3.4. Perbandingan dengan non-developer
Selanjutnya, kami tertarik pada apa yang sebenarnya memungkinkan kami untuk memprediksi bagaimana pengembang mengevaluasi produktivitas mereka. Misalnya, kami berasumsi bahwa produktivitas dipengaruhi oleh gangguan dari pekerjaan, tetapi itu bisa dikatakan untuk semua pekerja pengetahuan. Oleh karena itu, pertanyaan yang wajar muncul: apakah hal ini mempengaruhi produktivitas pengembang dengan cara yang khusus?
Untuk menjawab pertanyaan ini, kami memilih profesi yang sebanding dengan pengembang perangkat lunak. Pertama, kami mencoba memilih berdasarkan posisi di Google. Meskipun beberapa posisi menunjukkan bahwa mereka adalah pekerja pengetahuan, indikator yang paling umum dan, menurut pendapat kami, indikator yang paling dapat diandalkan dari non-pengembang yang sesuai adalah adanya kata "analis" dalam posisi tersebut. Kami memutuskan untuk membandingkan analis Google dan pengembang, daripada membandingkan analis Google dengan pengembang dari ketiga perusahaan. Kami memutuskan bahwa ini akan memungkinkan kami untuk mengontrol karakteristik tertentu dari perusahaan (misalnya, jika tiba-tiba karyawan Google secara statistik lebih atau kurang sensitif terhadap gangguan dibandingkan karyawan perusahaan lain).
Kami kemudian menyesuaikan penelitian kami untuk analis. Pertanyaan yang dihapus yang jelas terkait dengan pengembangan perangkat lunak, seperti "Persyaratan perangkat lunak saya sering berubah". Kami memiliki pertanyaan lain yang dibuat ulang khusus untuk analis. Misalnya, alih-alih "Saya menggunakan alat dan teknik terbaik untuk mengembangkan perangkat lunak," kami menulis "Saya menggunakan alat dan pendekatan terbaik untuk melakukan pekerjaan saya."
Skor produktivitas diukur dengan cara yang sama seperti pengembang. Hal yang sama berlaku untuk menilai jenis kelamin, posisi dan pangkat. Kami menguji versi "analitik" dari studi tersebut pada sampel yang terdiri dari lima analis yang mengatakan studi tersebut secara umum jelas dan membuat beberapa perubahan kecil. Kami menerimanya dan melakukan studi menyeluruh terhadap non-pengembang.

3.5. kontrol qestion
Untuk mengecualikan jawaban yang diberikan tanpa berpikir, setelah sekitar 70% dari awal penelitian, kami memasukkan pertanyaan untuk perhatian [20]: "Jawab ini," Saya agak tidak setuju. " Kami tidak memperhitungkan formulir yang tidak berisi jawaban untuk pertanyaan ini.
3.6. Bagikan tanggapan
Di Google, kami memilih 1.000 karyawan penuh waktu acak dari sumber daya manusia yang berperan dalam pengembangan perangkat lunak. Kami menerima 436 formulir lengkap dari mereka, yaitu, tingkat responsnya adalah 44%, yang merupakan indikator yang sangat tinggi untuk penelitian di antara pengembang [21]. Setelah menghapus formulir dengan jawaban yang salah untuk pertanyaan keamanan (n = 29 [7%]), tersisa 407 jawaban.
Untuk survei pekerja pengetahuan, kami memilih 200 karyawan Google penuh waktu acak dengan kata "analis" di jabatan mereka. Kami memutuskan untuk tidak meneliti terlalu banyak analis karena target kami adalah pengembang perangkat lunak. 94 orang, 47%, menjawab pertanyaan kami. Setelah menghapus kuesioner dengan jawaban yang salah untuk pertanyaan keamanan (n = 6 [6%]), 88 tetap.
Kami mengirimkan kuesioner kami kepada sekitar 2.200 pengembang perangkat lunak yang dipilih secara acak di ABB dan menerima 176 tanggapan. Ini adalah 8%, di batas bawah untuk studi semacam itu [21]. Setelah menghapus kuesioner yang salah (n = 39 [22%]), tersisa 137.
Akhirnya, kami mengirimkan kuesioner kepada sekitar 350 pengembang perangkat lunak di National Instruments dan menerima 91 tanggapan (26%). Setelah menghapus kuesioner yang salah (n = 13 [14%]), 78 tetap.
3.7. Analisis
Untuk setiap faktor di setiap perusahaan, kami menerapkan model regresi linier individual, menggunakan faktor sebagai variabel independen (misalnya, "Batas waktu proyek saya ketat"), dan estimasi produktivitas kami sebagai variabel dependen. Kami menjalankan model terpisah untuk setiap perusahaan demi privasi, sehingga data sumber dari perusahaan yang berbeda tidak tercampur. Untuk mengurangi pengaruh variabel jaminan, kami menambahkan variabel demografis yang ada ke setiap model regresi. Dalam menafsirkan hasil, kami fokus pada tiga aspek rasio faktor produktivitas:
- Penilaian . Menunjukkan tingkat pengaruh setiap faktor sambil mempertahankan konstanta demografis. Semakin tinggi nilainya, semakin tinggi dampaknya.
- . . , .
- . p < 0,05. 48 , p -, [22].
Dalam menafsirkan hasil, kami lebih fokus pada tingkat pengaruh (penilaian) dan lebih sedikit pada signifikansi statistik, karena dapat diekstraksi dari kumpulan data yang cukup besar, meskipun signifikansi praktisnya rendah. Seperti yang akan kita lihat di bawah, hasil yang signifikan secara statistik paling sering ditemukan di Google, dengan tingkat respons tertinggi; paling tidak - dalam Instrumen Nasional, di mana tingkat respons lebih rendah. Kami merasa bahwa perbedaan ini sebagian besar disebabkan oleh kekuatan statistik. Kami mendorong Anda untuk lebih percaya diri dengan hasil yang signifikan secara statistik.
Untuk memberikan konteks, kami juga menganalisis bagaimana faktor demografis berkorelasi dengan peringkat kinerja. Untuk melakukan ini, kami menjalankan regresi linier berganda untuk setiap perusahaan dengan variabel demografis sebagai variabel independen dan estimasi produktivitas kami sebagai variabel dependen. Kami kemudian menganalisis nilai prediksi keseluruhan dari model yang dihasilkan, serta dampak dari setiap variabel penjelas.
3.8. Tentang kausalitas
Metodologi kami memungkinkan kami untuk menilai hubungan antara faktor-faktor produktivitas dan penilaian produktivitas mereka sendiri, meskipun pada dasarnya kami tertarik pada tingkat pengaruh masing-masing faktor terhadap perubahan produktivitas. Seberapa benar untuk percaya bahwa ada hubungan kausal antara faktor dan produktivitas?
Ketepatan bergantung terutama pada kekuatan bukti sebab akibat dalam pekerjaan sebelumnya. Dan kekuatan ini berbeda untuk faktor yang berbeda. Misalnya, tim yang dipimpin oleh Guzzo melakukan meta-analisis dari 26 artikel tentang penilaian dan umpan balik, dan hasilnya memberikan bukti yang sangat baik bahwa umpan balik memang meningkatkan produktivitas di tempat kerja [23]. Namun, menentukan kekuatan bukti untuk setiap faktor yang diselidiki membutuhkan banyak pekerjaan, yang berada di luar cakupan artikel ini.
Untuk meringkas: meskipun penelitian kami tidak memungkinkan pembentukan hubungan sebab akibat, tetapi berdasarkan pekerjaan sebelumnya, kami dapat dengan yakin percaya bahwa faktor-faktor ini mempengaruhi produktivitas, tetapi menafsirkan hasil kami dengan hati-hati.

4. Hasil
Untuk memulainya, kami menjelaskan hubungan antara semua faktor produktivitas dan penilaian produktivitas mereka saat mengontrol karakteristik demografis. Data ini akan digunakan untuk menjawab setiap jawaban survei, dilanjutkan dengan pembahasan hasilnya. Kami kemudian akan membahas hubungan antara karakteristik demografis dan pengukuran kinerja. Terakhir, mari kita bahas implikasi dan risikonya.
4.1. Faktor produktivitas
Dalam gambar. 4 menunjukkan hasil analisis kami yang dijelaskan di bagian 3.7. Kolom pertama mencantumkan faktor-faktor yang diajukan kepada peserta dalam bentuk pernyataan; diikuti dengan label faktor (F1, F2, dll.) yang kami tetapkan setelah analisis selesai. Kurangnya data berarti bahwa faktor-faktor ini khusus untuk pengembang dan tidak disarankan untuk analis (misalnya, F10).
Angka: 4: Hubungan antara 48 faktor dan bagaimana pengembang dan analis mengevaluasi produktivitas mereka sendiri di tiga perusahaan:
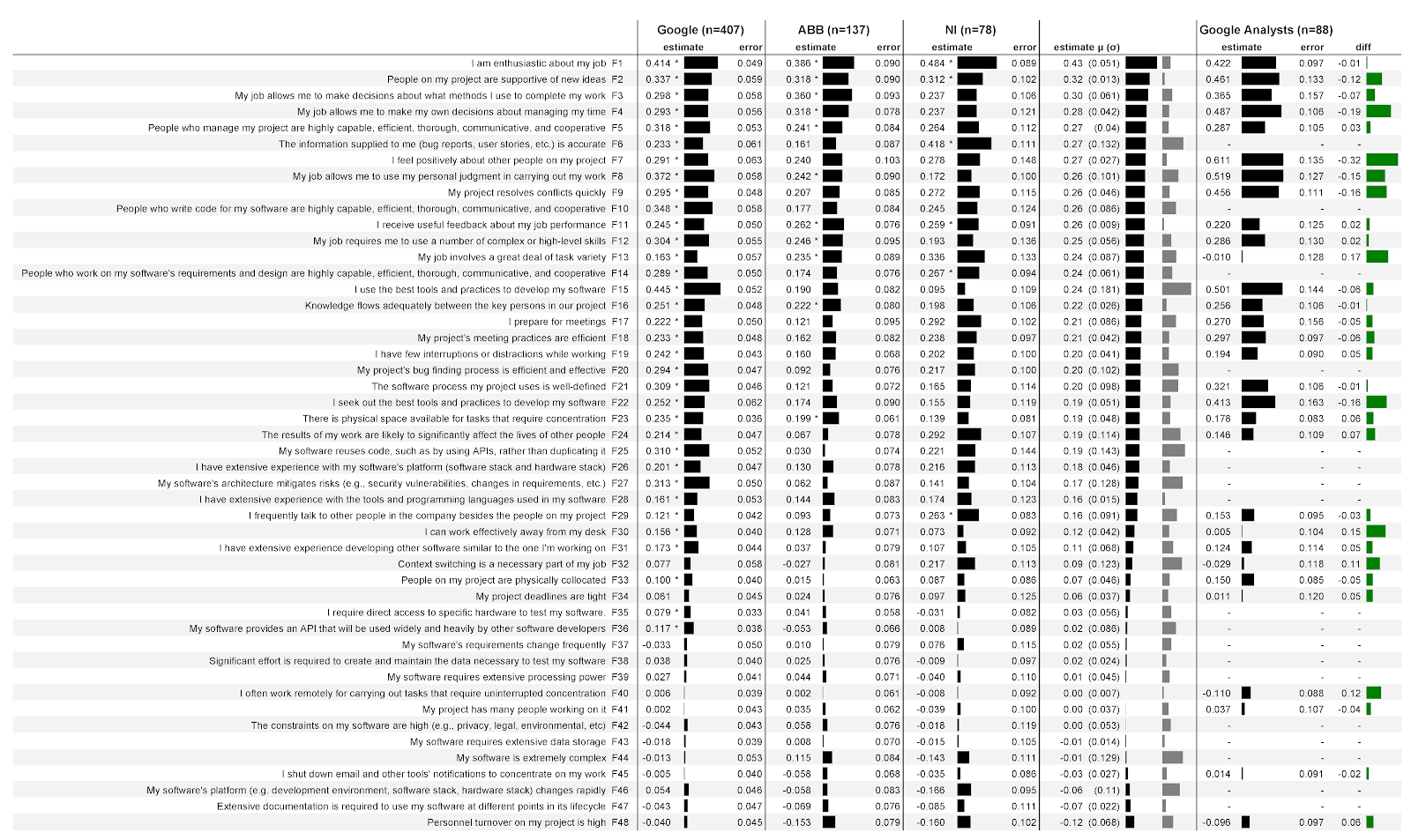
Tiga kolom berikutnya adalah data dari tiga perusahaan, serta data dari analis Google. Masing-masing kolom ini dibagi menjadi dua sub-kolom. Estimasi
sub-kolom(skor) berisi koefisien regresi yang mengukur kekuatan asosiasi faktor dengan estimasi produktivitasnya. Semakin besar angkanya, semakin kuat hubungannya. Misalnya, di kolom pertama Google, perkiraannya adalah 0,414. Artinya, untuk setiap poin peningkatan kesesuaian dengan pernyataan antusias dalam bekerja (F1), model memprediksi peningkatan peringkat produktivitas responden sebesar 0,414 poin dengan pengendalian variabel demografis. Peringkatnya bisa negatif. Misalnya, di ketiga perusahaan, semakin banyak pergantian staf dalam tim (F48), semakin rendah estimasi produktivitas mereka. Di samping setiap skor terdapat indikator yang secara jelas mencerminkan skor tersebut.
Perhatikan bahwa skor tidak berarti peringkat faktor yang lebih tinggi, tetapi korelasi yang lebih tinggi antara faktor dan peringkat produktivitas Anda. Misalnya, Instrumen Nasional (F1) mendapat nilai antusias yang lebih tinggi daripada perusahaan lain. Ini tidak berarti bahwa pengembang ada yang lebih antusias: di perusahaan ini, dia adalah faktor yang lebih kuat dalam memprediksi penilaian produktivitas mereka. Kami tidak memberikan rating sendiri, karena ini dilarang berdasarkan ketentuan kerja sama. Tanpa konteks lengkap, peringkat dapat disalahartikan. Misalnya, jika kami melaporkan bahwa pengembang di satu perusahaan kurang antusias dengan pekerjaan mereka dibandingkan dengan pengembang di perusahaan lain, Anda mungkin mendapat kesan bahwa lebih baik tidak bekerja di perusahaan lain tersebut. Kesalahan
subkolom kedua(error) berisi kesalahan standar model untuk setiap faktor. Semakin rendah nilainya, semakin baik. Secara intuitif, nilai yang lebih rendah tampaknya menunjukkan bahwa ketika faktor berubah, model memprediksi kinerjanya dengan lebih andal. Nilai kesalahan keseluruhan cukup stabil dari satu faktor ke faktor lain, terutama di Google dengan jumlah responden yang besar.
Tanda bintang (*) menunjukkan bahwa faktor ini signifikan secara statistik dalam model. Misalnya, antusiasme untuk bekerja (F1) signifikan secara statistik di ketiga perusahaan, sedangkan persiapan untuk rapat (F17) hanya signifikan di Google.
Kolom berikutnya berisi skor rata-rata ( μ ) untuk ketiga perusahaan dengan deviasi standar dalam tanda kurung ( σ). Indikator pertama dengan jelas menunjukkan nilai skor rata-rata, indikator kedua - nilai standar deviasi. Misalnya, skor rata-rata untuk antusiasme di tempat kerja (F1) adalah 0,43, dan standar deviasi 0,051. Tabel diurutkan berdasarkan peringkat rata-rata.
Kolom terakhir berisi diffs antara pengembang perangkat lunak dan peringkat analis di Google. Nilai positif berarti peringkat pengembang lebih tinggi, negatif berarti peringkat analis lebih tinggi. Misalnya, dalam hal antusiasme (F1), skor analis sedikit lebih rendah daripada pengembang.
4.2. Faktor apa yang paling baik memprediksi bagaimana pengembang akan mengevaluasi produktivitas mereka?
Faktor prediktif terkuat adalah pernyataan dengan skor rata-rata absolut tertinggi. Faktor prediksi terlemah adalah yang memiliki skor rata-rata absolut terendah. Dengan kata lain, faktor-faktor di atas tabel pada Gambar. 4 adalah prediktor terbaik. Untuk memahami faktor mana yang paling memberikan keyakinan pada hasil, kami telah menyoroti hasil yang signifikan secara statistik untuk ketiga perusahaan:
- Antusiasme untuk bekerja (F1)
- Dukungan rekan untuk ide-ide baru (F2)
- Umpan balik yang berguna tentang kinerja kerja (F11)
Diskusi . Harap dicatat bahwa 10 faktor produktivitas pertama bukanlah teknis. Ini mengejutkan mengingat, dalam perkiraan kami, sebagian besar penelitian pengembang perangkat lunak difokuskan pada aspek teknis. Oleh karena itu, reorientasi aktif terhadap faktor manusia dapat menyebabkan peningkatan pengaruh peneliti terhadap industri secara signifikan. Misalnya, jawaban atas pertanyaan-pertanyaan berikut bisa sangat bermanfaat:
- Apa yang membuat pengembang perangkat lunak antusias dengan pekerjaannya? Apa yang menjelaskan perbedaan antusiasme? Intervensi apa yang dapat meningkatkan antusiasme? Artikel ini dapat melengkapi penelitian tentang kebahagiaan [24] dan motivasi [25].
- ? , ? ?
- , ? ? ?
Fitur penting lainnya adalah peringkat faktor-faktor dari lini penelitian COCOMO II. Faktor-faktor ini, yang diperoleh selama studi empiris proyek perangkat lunak industri dan diverifikasi oleh analisis numerik dari 83 proyek [26], pada awalnya diformulasikan untuk memperkirakan biaya pengembangan perangkat lunak. Misalnya, faktor produktivitas dari COCOMO II mencakup volatilitas platform dasar dan kompleksitas produk. Anehnya, faktor COCOMO II yang diperhitungkan dalam penelitian kami (F5, F10, F14, F16, F24, F26, F28, F32, F33, F34, F36, F38, F39, F43, F44, F46, F47, F48) diterima lebih rendah nilai-nilai. Dapat diasumsikan bahwa mereka memungkinkan untuk memprediksi produktivitas yang lebih buruk. Setengah bagian atas dari faktor prediktif (F1 - F24) hanya mencakup 5 dari COCOMO II, dan bagian bawah - 14 faktor. Kami dapat menawarkan dua interpretasi yang berbeda. Pertama:COCOMO II kekurangan beberapa faktor produktivitas penting, dan iterasi COCOMO II di masa mendatang mungkin lebih prediktif jika lebih banyak faktor yang kami selidiki, seperti dukungan untuk pendekatan otonomi kerja, diperkenalkan di perusahaan. Interpretasi lain: COCOMO II diadaptasi untuk tugas saat ini - memperbaiki produktivitas di tingkat proyek [6], [27], [28], [29], [30], [31] - tetapi kurang cocok untuk memperbaiki produktivitas di tingkat pengembang individu. Interpretasi ini menekankan pentingnya dan kebaruan hasil kami.COCOMO II diadaptasi untuk tugas saat ini - memperbaiki produktivitas di tingkat proyek [6], [27], [28], [29], [30], [31] - tetapi kurang cocok untuk memperbaiki produktivitas di tingkat pengembang individu. Interpretasi ini menekankan pentingnya dan kebaruan hasil kami.COCOMO II diadaptasi untuk tugas saat ini - memperbaiki produktivitas di tingkat proyek [6], [27], [28], [29], [30], [31] - tetapi kurang cocok untuk memperbaiki produktivitas di tingkat pengembang individu. Interpretasi ini menekankan pentingnya dan kebaruan hasil kami.
Selain itu, semua faktor COCOMO II relatif rendah dan faktor prediktif yang secara statistik tidak signifikan untuk produktivitas di ketiga perusahaan. Misalnya:
- Perangkat lunak saya membutuhkan banyak daya pemrosesan (F39).
- Perangkat lunak saya membutuhkan penyimpanan data yang besar (F43).
- Platform perangkat lunak saya (misalnya lingkungan pengembangan, tumpukan perangkat lunak atau perangkat keras) berubah dengan cepat (F46).
Satu penjelasan: Dalam 20 tahun sejak pembuatan dan pengujian COCOMO II, platform menjadi kurang beragam dalam hal produktivitas. Sepertinya sistem operasi standar sekarang melindungi pengembang dari kehilangan produktivitas karena perubahan perangkat keras (seperti Android dalam pengembangan seluler). Demikian pula, platform cloud dapat melindungi pengembang dari kehilangan produktivitas karena penskalaan proses dan kebutuhan penyimpanan. Belum lagi, kerangka kerja modern dan platform cloud mudah digunakan. Selain itu, perbedaan produktivitas saat memproses data dalam jumlah besar dan kecil mungkin telah hilang sejak pembuatan COCOMO II.
4.3. Bagaimana faktor-faktor ini berbeda dari perusahaan ke perusahaan?
Untuk menjawab pertanyaan ini, Anda dapat melihat deviasi standar dalam estimasi untuk ketiga perusahaan tersebut. Berikut adalah tiga faktor dengan variabilitas paling kecil, yaitu, dengan nilai paling stabil di seluruh perusahaan:
- Menggunakan telework untuk fokus (F40).
- Umpan balik yang berguna tentang prestasi kerja (F4).
- Dukungan rekan untuk ide-ide baru (F2).
Kami percaya bahwa stabilitas faktor-faktor ini menjadikannya kandidat yang baik untuk digeneralisasikan. Perusahaan lain cenderung melihat hasil serupa pada faktor-faktor ini.
Dan berikut adalah tiga faktor dengan variabilitas terbesar, yaitu, dengan penyebaran nilai terbesar di seluruh perusahaan:
- Menggunakan alat dan pendekatan terbaik (F15).
- Penggunaan kembali kode (F25).
- Akurasi informasi yang masuk (F6).
Diskusi . Tiga faktor variabel terkecil (F40, F4 dan F2) memiliki fitur yang sama - tidak terkait dengan teknologi, tetapi dengan masyarakat dan lingkungan. Mungkin ini menunjukkan bahwa di mana pun pengembang bekerja, mereka sama-sama terpengaruh oleh pekerjaan jarak jauh, umpan balik, dan dukungan rekan untuk ide baru. Mengubah ketiga faktor ini mungkin terbukti menjadi dampak terbesar.
Mengapa faktor F15, F25 dan F6 begitu berbeda di perusahaan yang berbeda? Untuk masing-masing, kami memiliki penjelasan yang mungkin berdasarkan apa yang kami ketahui tentang perusahaan tersebut.
Penggunaan alat dan pendekatan terbaik (F15) paling erat kaitannya dengan skor kinerja Google, tetapi tidak terkait secara signifikan dengan Instrumen Nasional. Penjelasan yang mungkin: Basis kode Google jauh lebih besar. Oleh karena itu, menggunakan alat dan pendekatan yang lebih baik untuk menavigasi dan memahami basis kode yang lebih besar secara efisien memiliki dampak signifikan pada produktivitas. Dan di National Instruments, produktivitas kurang bergantung pada alat karena basis kodenya lebih kecil dan lebih jelas.
Penggunaan ulang kode (F25) sangat terkait dengan skor kinerja Google, tetapi tidak secara signifikan terkait dengan ABB. Penjelasan yang mungkin: Google mempermudah penggunaan kembali kode. Basis kode bersifat monolitik, dan semua pengembang dapat memeriksa hampir setiap baris kode di perusahaan, jadi penggunaan kembali tidak memerlukan banyak usaha. Dan ABB memiliki banyak repositori yang harus Anda akses. Dan di perusahaan ini, keuntungan produktivitas (melalui penggunaan kembali) dapat diimbangi dengan kerugian produktivitas (dari menemukan dan mendapatkan kode yang tepat).
Akurasi Informasi (F6) sangat terkait dengan skor kinerja Instrumen Nasional, tetapi tidak secara signifikan terkait dengan ABB. Penjelasan yang mungkin: Pengembang di ABB lebih terlindung dari pengaruh informasi yang tidak akurat. Secara khusus, di ABB, beberapa level tim dukungan didedikasikan untuk mendapatkan informasi yang benar tentang bug dari pelanggan. Jika developer menerima informasi yang tidak akurat, maka produktivitasnya bisa turun, karena ia harus mendelegasikan tugas pemurnian data kembali ke tim support.
4.4. Apa yang memungkinkan untuk memprediksi penilaian pengembang atas produktivitas mereka, khususnya, dibandingkan dengan pekerja berpengetahuan lainnya?
Untuk menjawab pertanyaan ini, buka kolom terakhir pada Gambar. 4. Jika kita melihat beberapa hubungan antara peringkat maksimum, kita akan melihat bahwa penilaian analis terhadap produktivitas mereka lebih terkait erat dengan:
- Persepsi positif rekan satu tim mereka (F7).
- Otonomi dalam pengaturan waktu kerja (F4).
Di sisi lain, penilaian pengembang atas produktivitas mereka lebih terkait dengan:
- Melakukan berbagai tugas dalam pekerjaan (F13).
- Bekerja secara efektif di luar tempat kerja mereka (F30).
Diskusi . Secara keseluruhan, hasil menunjukkan bahwa pengembang agak mirip dengan pekerja pengetahuan lainnya, dan agak berbeda. Misalnya, produktivitas pengembang paling baik diprediksi oleh antusiasme di tempat kerja, dan analis memiliki kesamaan. Kami yakin bahwa perusahaan dapat menggunakan temuan kami untuk memilih inisiatif produktivitas yang menargetkan pengembang, atau memilih inisiatif yang lebih luas.
Toolkit Pengembangan Terpadu Google dapat menjelaskan mengapa peningkatan keragaman tugas dikaitkan dengan peringkat produktivitas yang lebih tinggi dari pengembang, bukan dari analis. Keragaman tugas dapat mengurangi kebosanan dan meningkatkan produktivitas untuk kedua grup, tetapi alat pengembangan terpadu Google dapat berarti bahwa pengembang dapat menggunakan alat yang sama untuk tugas yang berbeda. Dan analis mungkin perlu menggunakan alat yang berbeda untuk tugas yang berbeda, yang meningkatkan upaya kognitif dalam peralihan konteks.
Pekerjaan di luar kantor dapat menjelaskan mengapa meningkatkan efisiensi kerja jauh dari tempat kerja lebih terkait erat dengan perolehan produktivitas bagi pengembang daripada bagi analis. Kami percaya bahwa mengambil istirahat dari pekerjaan lebih berbahaya selama pemrograman daripada selama pekerjaan analitis.
Parnin dan Rugaber menemukan bahwa kembali bekerja setelah gangguan adalah masalah yang sering dan terus-menerus bagi pengembang [32], yang mengarah pada kebutuhan akan alat yang lebih baik untuk membantu mereka kembali bekerja pada suatu masalah [33].

4.5. Faktor produktivitas lainnya
Di akhir kuesioner, responden dapat menunjukkan faktor tambahan yang menurut mereka mempengaruhi produktivitas. Sebagian besar, penambahan ini adalah deskripsi yang sama atau lebih halus dari 48 faktor kami. Kami membuang penambahan seperti itu, tetapi, jika perlu, menciptakan faktor-faktor baru. Materi Pelengkap berisi deskripsi faktor-faktor baru, serta deskripsi terbaru dari faktor-faktor yang awalnya kami usulkan. Calon peneliti mungkin memiliki pertanyaan tim campuran baru untuk mengerjakan proyek, atau memperbaiki atau menyarankan rincian pertanyaan yang lebih spesifik untuk faktor F15, F16, dan F19.
4.6. Demografi
Di Google dan National Instruments, tidak ada model demografis umum, tetapi variabel petugas individu secara statistik merupakan prediktor signifikan dari skor kinerja mereka.
Untuk ABB, model demografis ternyata signifikan ( F = 3 , 406 , df = (5 , 131) , p <0,007). Gender juga ternyata menjadi faktor yang signifikan secara statistik ( p = 0,007); perempuan memperkirakan produktivitas mereka 0,83 poin lebih tinggi daripada laki-laki. Peserta dari jenis kelamin lain (“lainnya”) menunjukkan skor 1,6 poin lebih tinggi dibandingkan laki-laki ( p = 0,03). Posisi ( hal= 0,04), setiap tahun tambahan perusahaan menaikkan estimasi kinerjanya sebesar 0,02 poin. Sejauh yang kami ketahui, perbedaan antara ABB dan dua perusahaan lainnya tidak menjelaskan mengapa faktor demografis ini diperkirakan hanya signifikan di ABB dan tidak di tempat lain.
4.7. Aplikasi dalam praktek dan penelitian
Bagaimana cara menggunakan hasil kami dalam latihan? Kami telah menyediakan daftar peringkat dari faktor-faktor terpenting dalam memprediksi produktivitas yang dapat digunakan untuk memprioritaskan inisiatif. Contoh inisiatif dapat ditemukan di makalah penelitian sebelumnya.
Misalnya, untuk meningkatkan semangat kerja, Markos dan Sridevi menyarankan untuk membantu pekerja tumbuh secara profesional [34] melalui lokakarya tentang teknologi dan komunikasi antarpribadi. Selain itu, peneliti menyarankan untuk memperkenalkan praktik penghargaan atas pekerjaan yang baik. Misalnya, ABB sedang bereksperimen dengan apresiasi publik untuk pengembang yang telah menerapkan alat dan teknik untuk menavigasi kode terstruktur [35].
Untuk meningkatkan dukungan untuk ide-ide baru, Brown dan Duguid telah mengusulkan cara formal dan informal untuk berbagi praktik terbaik [36]. Di Google, penyebaran pengetahuan satu arah adalah melalui inisiatif Pengujian Toilet: Pengembang menulis berita pendek tentang pengujian atau area lain, dan kemudian catatan ini diposting di toilet di seluruh perusahaan.
Untuk meningkatkan kualitas umpan balik pada produktivitas kerja, London dan Smither menyarankan untuk fokus pada umpan balik yang tidak menghakimi, berbasis perilaku, dapat ditafsirkan dan berorientasi pada hasil [37]. Di Google, umpan balik semacam itu dapat diperoleh melalui postmortems yang tidak berbahaya: setelah kejadian negatif penting seperti penurunan layanan, para insinyur bersama-sama menulis laporan tentang tindakan yang memengaruhi akar penyebab masalah, tanpa menyalahkan karyawan tertentu.
Kami melihat beberapa arah untuk penelitian masa depan berdasarkan pekerjaan kami.
Pertama, tinjauan sistematis artikel yang mencirikan dampak dan konteks bukti untuk setiap faktor produktivitas yang dibahas di sini akan meningkatkan kegunaan pekerjaan kita dengan menciptakan hubungan sebab akibat. Jika lemah, penerapan dapat ditingkatkan dengan melakukan serangkaian eksperimen untuk menetapkan penyebab.
Kedua, seperti yang disebutkan di Bagian 4.5 dan 4.6, calon peneliti dapat menggunakan faktor tambahan yang disarankan oleh responden kami dan memeriksa pengaruh gender dan faktor demografis lainnya pada produktivitas pengembang.
Ketiga, dampak penelitian produktivitas pada pengembangan perangkat lunak dapat ditingkatkan dengan seperangkat metrik dan alat multidimensi yang telah divalidasi melalui penelitian empiris dan triangulasi.
Keempat, jika peneliti dapat menghitung biaya perubahan faktor yang mempengaruhi produktivitas, perusahaan dapat membuat keputusan investasi yang lebih cerdas.
4.8. Resiko
Saat menafsirkan hasil penelitian ini, beberapa risiko terhadap validitasnya harus dipertimbangkan.
4.8.1. Risiko akurasi data
Pertama, kami hanya membicarakan satu pengukuran - penilaian produktivitas Anda. Ada dimensi lain, termasuk ukuran objektif, seperti jumlah baris kode yang ditulis per hari, pendekatan yang digunakan oleh Facebook [38]. Seperti yang kami tunjukkan di Bagian 3.1, semua metrik produktivitas memiliki kekurangan, termasuk mengukur produktivitas Anda sendiri. Misalnya, pengembang mungkin menilai produktivitas mereka terlalu ringan, atau melebih-lebihkan penilaian mereka secara artifisial karena bias di masyarakat [39]. Terlepas dari kekurangan ini, tim yang dipimpin oleh Zelenski mengembangkan pekerjaan sebelumnya untuk memperdebatkan validitas penilaian kinerja [40], yang juga digunakan dalam artikel ini.
Kedua, kami mengukur produktivitas kami dengan satu pertanyaan yang hampir tidak mencakup seluruh spektrum produktivitas pengembang. Misalnya pertanyaan berfokus pada frekuensi dan intensitas, tetapi tidak mempertimbangkan kualitas. Kami juga tidak meminta responden untuk membatasi tanggapan mereka pada kerangka waktu tertentu, jadi beberapa peserta mungkin menanggapi berdasarkan pengalaman mereka selama seminggu terakhir, sementara yang lain menilai pengalaman mereka selama setahun terakhir. Dalam retrospeksi, penelitian harus beroperasi dengan interval waktu yang tetap.
Ketiga, karena jumlah pertanyaan yang terbatas, kami hanya mengandalkan faktor-faktor yang diteliti pada karya sebelumnya. 48 pertanyaan yang kami pilih mungkin tidak mencakup semua aspek perilaku terkait produktivitas. Atau, faktor yang kami pilih bisa jadi terlalu umum dalam kasus tertentu. Misalnya, dalam retrospeksi, faktor yang terkait dengan "alat dan pendekatan" (F14) terbaik mungkin lebih kuat jika kita memisahkan alat dari metode.
4.8.2. Risiko internal terhadap keandalan
Keempat, seperti yang kami sebutkan di bagian 3.8, kami telah menggunakan pekerjaan sebelumnya untuk membangun hubungan sebab akibat antara faktor dan produktivitas, tetapi kekuatan bukti untuk hubungan dapat bervariasi. Mungkin ternyata beberapa faktor mempengaruhi penilaian produktivitas mereka hanya secara tidak langsung, melalui faktor-faktor lain, atau hubungan mereka secara umum berlawanan arah. Misalnya, kemungkinan besar faktor utama dalam produktivitas, meningkatnya antusiasme untuk bekerja (F1), sebenarnya mungkin disebabkan oleh peningkatan produktivitas.
4.8.3. Risiko eksternal terhadap keandalan
Kelima, meskipun kami memeriksa tiga perusahaan yang cukup berbeda, kemampuan generalisasi dengan jenis perusahaan lain, organisasi lain, dan jenis pekerja berpengetahuan lain masih terbatas. Dalam makalah ini, kami telah memilih analis sebagai perwakilan dari non-pengembang, tetapi kategori ini mencakup beberapa jenis pekerja pengetahuan - dokter, arsitek, dan pengacara. Risiko lain terhadap keandalan adalah bias karena kurangnya tanggapan: orang yang menjawab kuesioner itu dipilih sendiri.
Keenam, kami menganalisis setiap faktor produktivitas secara terpisah, tetapi banyak faktor yang dapat menyertai satu sama lain. Ini bukan masalah analisis, tetapi penerapan hasil. Jika faktor-faktor bersifat kodependen, maka mengubah satu faktor dapat mempengaruhi yang lain secara negatif.
4.8.4. Resiko terhadap
Kredibilitas Konstruktif Ketujuh, dalam membuat studi ini, kami prihatin tentang kemungkinan responden mengenali metodologi analisis kami dan tidak menjawab dengan jujur. Kami mencoba mengurangi kemungkinan ini dengan memisahkan masalah produktivitas dari faktor-faktornya, tetapi para responden mungkin dapat menarik kesimpulan tentang metodologi analisis kami.
Akhirnya, kami telah menyusun ulang beberapa pertanyaan untuk menyesuaikan studi dengan analis, yang dapat mengubah arti pertanyaan secara tidak diinginkan. Akibatnya, perbedaan antara pengembang dan analis mungkin muncul dari perbedaan pertanyaan, bukan dalam profesi.
5. Pekerjaan terkait
Banyak peneliti telah mempelajari faktor produktivitas individu untuk pengembang perangkat lunak. Sebagai contoh, Moser dan Nierstrasz menganalisis 36 proyek pengembangan perangkat lunak dan mengeksplorasi dampak potensial dari teknologi berorientasi objek pada peningkatan produktivitas pengembang [41].
Contoh lain adalah studi oleh DeMarco dan Lister terhadap 166 programmer dari 35 organisasi yang melakukan latihan pemrograman satu hari. Para penulis menemukan bahwa tempat kerja dan organisasi berhubungan dengan produktivitas [42].
Contoh ketiga adalah percobaan laboratorium oleh Kersten dan Murphy dengan 16 pengembang. Ternyata mereka yang menggunakan alat untuk fokus pada tugas jauh lebih produktif daripada yang lain [43].
Selain itu, analisis sistematis Wagner dan Rouet memberikan gambaran yang baik tentang hubungan antara faktor individu dan produktivitas [14]. Tim yang dipimpin oleh Mayer menawarkan analisis yang lebih baru tentang gambaran umum faktor produktivitas [3]. Secara umum, pekerjaan kami didasarkan pada studi faktor-faktor individu ini dengan studi yang lebih luas tentang keragamannya.
Tinjauan sistematis Petersen menyatakan bahwa tujuh makalah mengukur faktor yang memprediksi produktivitas pengembang perangkat lunak [44]. Dalam setiap pekerjaan, metode numerik digunakan untuk peramalan, biasanya ini regresi, yang juga kami gunakan dalam penelitian kami. Faktor yang paling umum terkait dengan ukuran proyek, dan 6 dari 7 faktor secara eksplisit diformulasikan berdasarkan pendorong produktivitas COCOMO II ([6], [27], [28], [29], [30], [31]). Model peramalan paling kompleks dalam studi Petersen menggunakan 16 faktor [6].
Pekerjaan kami memiliki dua perbedaan utama. Pertama, dibandingkan dengan pekerjaan sebelumnya, kami memperkirakan lebih banyak faktor (48), dan variasinya lebih luas. Kami memilih faktor berdasarkan psikologi industri dan organisasi. Kedua, kami memiliki subjek analisis yang berbeda: peneliti sebelumnya mempelajari apa yang dapat memprediksi produktivitas dalam kerangka proyek, dan kami tertarik pada produktivitas pribadi orang.
Selain pengembangan perangkat lunak, penelitian sebelumnya membandingkan faktor-faktor yang memprediksi produktivitas dalam profesi lain, khususnya di bidang psikologi industri dan organisasi. Sementara studi tersebut telah difokuskan pada produktivitas tingkat perusahaan [45] dan tenaga kerja fisik seperti manufaktur [46], fokus terdekat adalah pada produktivitas pekerja pengetahuan. Artinya, orang secara aktif menggunakan pengetahuan dan informasi dalam pekerjaannya, biasanya menggunakan komputer [47]. Perbandingan faktor-faktor profesi tersebut disajikan dalam dua karya utama. Yang pertama adalah studi tim yang dipimpin oleh Palwalin, mengeksplorasi 38 faktor yang dibandingkan dengan produktivitas dalam studi sebelumnya. Faktor-faktor tersebut meliputi ruang kerja fisik, virtual dan sosial,pendekatan kerja pribadi dan kesejahteraan di tempat kerja [4]. Yang kedua adalah studi oleh Hernaus dan Mikulich dari 512 pekerja pengetahuan. Penulis mempelajari 14 faktor, dibagi menjadi tiga kategori [9]. Kami mengandalkan kedua pekerjaan ini dalam mempersiapkan studi kami (Bagian 3.2).
Namun, studi yang membandingkan faktor produktivitas untuk pekerja pengetahuan belum memperhatikan pengembang perangkat lunak. Ada dua alasan utama untuk ini. Pertama, tidak jelas sejauh mana keseluruhan hasil yang diperoleh diproyeksikan ke pengembang. Kedua, studi semacam itu biasanya disarikan dari faktor-faktor khusus pengembang, seperti penggunaan kembali perangkat lunak dan kompleksitas basis kode [48]. Oleh karena itu, terdapat kesenjangan literatur dalam memahami faktor-faktor yang memungkinkan untuk memprediksi produktivitas pengembang. Mengisi celah ini praktis. Kami telah membentuk tiga tim peneliti di tiga perusahaan untuk meningkatkan produktivitas. Menjembatani kesenjangan pengetahuan ini membantu tim kami melakukan penelitian, dan perusahaan berinvestasi dalam produktivitas pengembang.
6. Kesimpulan
Banyak faktor yang memengaruhi produktivitas pengembang, tetapi organisasi memiliki sumber daya terbatas untuk fokus pada peningkatan produktivitas. Kami membuat dan melakukan studi di tiga perusahaan untuk memeringkat dan membandingkan berbagai faktor. Pengembang dan pemimpin dapat menggunakan temuan kami untuk memprioritaskan upaya mereka. Sederhananya, makalah sebelumnya telah menyarankan banyak cara untuk meningkatkan produktivitas pengembang perangkat lunak, dan kami telah menyarankan bagaimana Anda dapat memprioritaskan cara-cara tersebut.

Blok pertanyaan
Apa yang membuat pengembang produktif?
Riset anonim satu halaman ini akan memakan waktu 15 menit dan akan membantu kami lebih memahami apa yang memengaruhi produktivitas pengembang. Mohon jawab dengan terbuka dan jujur.
Riset ini akan menanyakan pertanyaan tentang Anda, proyek Anda, dan perangkat lunak Anda. Harap diingat:
Perangkat lunak saya mengacu pada perangkat lunak inti yang Anda kembangkan di ABB, termasuk produk dan infrastruktur. Jika Anda mengerjakan program yang berbeda, maka jawablah hanya yang utama.
Proyek saya termasuk dalam tim tempat Anda membuat perangkat lunak. Harap jawab semua pertanyaan terkait tentang pengembang perangkat lunak lain di ABB.
Beberapa pertanyaan menyentuh topik yang berpotensi sensitif. Isi jawaban sehingga tidak ada yang bisa mengintip dari balik bahu Anda, dan hapus riwayat browser dan cookie Anda setelah mengisi kuesioner.
Silakan menilai persetujuan Anda dengan pernyataan berikut.
Daftar pertanyaan penelitian





Pertanyaan-pertanyaan ini dirancang untuk memberikan penilaian komprehensif tentang faktor-faktor yang dapat memengaruhi produktivitas. Apakah kita melewatkan sesuatu?
Jenis kelamin (opsional)
Apa gelar Anda? (opsional)
Pada tahun berapa Anda bergabung dengan ABB?
Bahan tambahan
Faktor produktivitas dicatat oleh responden
Di bagian ini, kami membuat daftar faktor-faktor yang dijelaskan responden dalam tanggapan mereka terhadap pertanyaan terbuka. Pertama, kami akan menjelaskan beberapa faktor baru, dan kemudian kami akan memberikan deskripsi faktor-faktor yang terkait dengan yang sudah ada dalam penelitian. Kami melengkapi komentar responden dengan kode menggunakan faktor kami. Di sini kami tidak membahas atau mengevaluasi jawaban orang, kami tidak melengkapi deskripsi faktor kami yang ada.
Faktor baru
Dalam komentar, 4 topik diangkat yang tidak tercermin dalam penelitian kami. Enam tanggapan mengangkat topik dari tim proyek campuran, khususnya rasio manajer dengan pengembang; adanya cukup banyak karyawan dalam proyek; dan apakah manajemen mampu mempertahankan kepemilikan yang kuat atas produk tersebut. Seorang responden mencatat dampak pada produktivitas jenis perangkat lunak (server, klien, seluler, dll.). Yang lain mencatat pengaruh faktor fisiologis seperti jumlah jam tidur. Yang lain menyebutkan peluang untuk pertumbuhan pribadi.
Faktor yang tersedia
F1. Lima responden menyebutkan faktor-faktor yang berhubungan dengan antusiasme dalam bekerja: dua menyebutkan motivasi kerja dan pengakuan, satu - moral, yang lain - gedung kantor yang menyedihkan.
F3. Empat responden mencatat faktor-faktor yang berkaitan dengan kemandirian dalam memilih metode kerja. Satu menyebutkan otonomi di tingkat tim, yang lain tentang kebijakan yang mencegah penggunaan sistem sumber terbuka yang baik, yang ketiga tentang prioritas yang diadopsi di perusahaan yang membatasi penggunaan metode tertentu dalam tim.
F4. Seorang responden mencatat otonomi dalam penjadwalan jam kerja, yang dibatasi pada prioritas yang ditentukan oleh kebutuhan untuk promosi.
F5. Tiga responden mencatat kompetensi kepemimpinan. Yang pertama menyebutkan kepemimpinan dengan strategi yang koheren, yang kedua - prioritas yang saling bertentangan diturunkan oleh manajemen, dan yang ketiga - mengelola produktivitas karyawan.
F6. Delapan responden mengatakan mereka memberikan informasi yang akurat. Tiga disebutkan komunikasi lintas tim melalui dokumentasi (dan saluran lain), dan dua menyebutkan definisi yang jelas tentang tujuan dan rencana tim.
F7. Dua responden mencatat perasaan positif terhadap rekan kerja dalam terang tim dan kohesi tim.
F8. Seorang responden mencatat otonomi dalam melakukan pekerjaan: kebijakan perusahaan menentukan sumber daya apa yang dapat digunakan.
F9. Seorang responden mencatat resolusi konflik, yang menunjukkan bahwa kebiasaan pribadi rekan satu tim bertentangan dengan norma sosial.
F10. Empat responden mencatat kompetensi para pengembang. Yang satu menyebutkan kesulitan dalam memahami kode, yang lain - pengetahuan tentang bidang subjek, yang ketiga - keseriusan sikap terhadap pengujian.
F11. Seorang responden mencatat umpan balik tentang produktivitas kerja: mendapatkan pengakuan dari kolega dan manajemen, promosi.
F12. Seorang responden mencatat kompleksitas implementasi perangkat lunak "dari otak saya ke produk yang dikirim".
F13. Dua responden mencatat variasi tugas, khususnya, mencegat tugas atas nama tim mereka dan peralihan konteks.
F14 Empat responden menilai persyaratan dan orang arsitektur sebagai kompeten. Satu menyebutkan perhatian yang tidak mencukupi terhadap masalah, yang lain - keterbacaan dokumen arsitektur, yang ketiga - kualitas rencana proyek, keempat - ketersediaan "dukungan yang memadai dalam pengembangan persyaratan."
F15. Tiga puluh dua responden melaporkan menggunakan alat dan pendekatan terbaik. Dua belas menyebutkan performa alat, terutama masalah kecepatan dan latensi dalam pembuatan dan pengujian. Lima orang menyebutkan fitur yang tersedia, tiga menyebutkan masalah kompatibilitas dan migrasi, dua menyebutkan bahwa bahkan alat terbaik yang tersedia mungkin tidak memenuhi kebutuhan. Komentar lain tentang alat dan pendekatan menyebutkan tingkat otomatisasi yang ditawarkan alat; debugger dan simulator khusus; Pendekatan tangkas; tes bersisik dan alat terkait; alat yang bekerja dengan baik dari jarak jauh; pilihan bahasa pemrograman; alat usang; pemisahan preferensi pribadi dalam alat dari yang diadopsi di perusahaan.
F16. Sembilan belas responden mencatat transfer pengetahuan yang memadai di antara orang-orang. Sembilan orang menyebutkan kesulitan berkomunikasi dengan tim lain: tiga - menyepakati tujuan antar tim, satu - menyepakati tujuan dalam tim besar, yang lain - mencapai kesepakatan antar tim. Dua orang mencatat kesulitan mengoordinasikan pekerjaan dalam tim internasional atau zona waktu. Dua lainnya menyebutkan perlunya mengandalkan dokumentasi tim lain. Dua orang berkomentar tentang durasi peninjauan kode. Dua lainnya menyebutkan kesadaran fasilitas kerja rekan satu tim. Yang satu menyebutkan pencarian orang yang tepat, yang lain - keterlambatan interaksi, yang ketiga - komunikasi antara insinyur dan spesialis di bidang subjek. Terakhir, seseorang menyebutkan pentingnya memperjelassaluran komunikasi mana yang lebih baik digunakan dalam situasi tertentu.
F18. Dua responden mencatat pendekatan untuk mengadakan rapat, satu menyebutkan bahwa efektivitas rapat tergantung pada ketersediaan ruang rapat.
F19. Dua puluh empat responden melaporkan gangguan dan gangguan dari pekerjaan. Sepuluh lingkungan yang bising disebutkan, dan tujuh menunjukkan bahwa kantor terbuka mengurangi produktivitas. Empat kesulitan yang disebutkan dengan multitasking dan pengalihan konteks. Empat lainnya melaporkan kebutuhan untuk fokus pada pekerjaan utama mereka atau pada tugas-tugas "opsional" seperti wawancara. Dua menyebutkan kesulitan berkonsentrasi saat pergi dan pulang kerja.
F25. Seorang responden mencatat penggunaan ulang kode, menunjukkan bahwa API 2-3 baris meningkatkan kompleksitas dengan kontribusi minimal untuk mengurangi duplikasi.
F26. Seorang responden mengomentari pengalaman dengan platform perangkat lunak, menunjukkan bahwa masalah bertambah ketika pengembang beralih antar proyek.
F27. Tiga responden mencatat arsitektur perangkat lunak dan pengurangan risiko. Seseorang menunjukkan "seberapa terkenal arsitektur produk, seberapa saling berhubungan, dan bagaimana hal itu mendukung orang-orang yang mengetahui peran mereka dan mampu untuk fokus, yang mengetahui tanggung jawab dan keterbatasan mereka, dan apa yang mereka miliki." Lain mencatat bahwa arsitektur, melalui modularitas, dapat memfasilitasi pertukaran antar komponen perangkat lunak. Yang ketiga menyarankan bahwa arsitektur harus konsisten dengan struktur organisasi.
F32. Empat responden menyebutkan perlunya peralihan konteks. Dua disebutkan bahwa peralihan diperlukan saat berpindah antar proyek. Seseorang menjelaskan bahwa kebutuhan akan sakelar konteks berbeda dari kenikmatan sakelar. Yang lain menyebutkan bahwa "proyek produktivitas" dengan sendirinya dapat mengurangi produktivitas.
F34. Lima responden mencatat tenggat waktu yang ketat. Satu menunjukkan bahwa ini berkontribusi pada pertumbuhan hutang teknis, yang lain - bahwa tenggat waktu seperti itu dapat menyebabkan pemborosan sumber daya.
F42. Tiga responden mencatat keterbatasan perangkat lunak. Dua menunjuk ke batasan privasi dan satu lagi ke batasan keamanan kritis.
F44. Sebelas responden mencatat kompleksitas perangkat lunak. Dua menyebutkan kompleksitas tertentu dari kode warisan, dua mengacu pada hutang teknis, dan masing-masing versi yang dicatat, pemeliharaan perangkat lunak, dan
pemahaman kode.
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) 2.786969 0.111805 24.927 < 0.0000000000000002 ***
log(lines_changed + 1) 0.045189 0.009296 4.861 0.00000122 ***
level -0.050649 0.015833 -3.199 0.00139 **
job_codeENG_TYPE2 0.194108 0.172096 1.128 0.25944
job_codeENG_TYPE3 0.034189 0.076718 0.446 0.65589
job_codeENG_TYPE4 -0.185930 0.084484 -2.201 0.02782 *
job_codeENG_TYPE5 -0.375294 0.085896 -4.369 0.00001285 ***
---
Signif. codes: 0 `***` 0.001 `**` 0.01 `*` 0.05 `.` 0.1 ` ` 1
Residual standard error: 0.8882 on 3388 degrees of freedom
Multiple R-squared: 0.01874, Adjusted R-squared: 0.017
F-statistic: 10.78 on 6 and 3388 DF, p-value: 0.000000000006508
Angka: 5: Model 1: Hasil Regresi Linier Lengkap
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) 2.74335 0.09706 28.265 < 0.0000000000000002
log(changelists_created + 1) 0.11220 0.01608 6.977 0.00000000000362
level -0.04999 0.01574 -3.176 0.00151
job_codeENG_TYPE2 0.27044 0.17209 1.571 0.11616
job_codeENG_TYPE3 0.02451 0.07644 0.321 0.74847
job_codeENG_TYPE4 -0.21640 0.08411 -2.573 0.01013
job_codeENG_TYPE5 -0.40194 0.08559 -4.696 0.00000275538534
(Intercept) ***
log(changelists_created + 1) ***
level **
job_codeENG_TYPE2
job_codeENG_TYPE3
job_codeENG_TYPE4 *
job_codeENG_TYPE5 ***
---
Signif. codes: 0 `***` 0.001 `**` 0.01 `*` 0.05 `.` 0.1 ` ` 1
Residual standard error: 0.885 on 3388 degrees of freedom
Multiple R-squared: 0.02589, Adjusted R-squared: 0.02416
F-statistic: 15.01 on 6 and 3388 DF, p-value: < 0.00000000000000022
Angka: 6: Model 2: Hasil Regresi Linier Lengkap
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) 2.79676 0.11141 25.102 < 0.0000000000000002
log(lines_changed + 1) -0.01462 0.01498 -0.976 0.32897
log(changelists_created + 1) 0.13215 0.02600 5.082 0.000000394
level -0.05099 0.01578 -3.233 0.00124
job_codeENG_TYPE2 0.27767 0.17226 1.612 0.10706
job_codeENG_TYPE3 0.02226 0.07647 0.291 0.77102
job_codeENG_TYPE4 -0.22446 0.08452 -2.656 0.00795
job_codeENG_TYPE5 -0.40819 0.08583 -4.756 0.000002057
(Intercept) ***
log(lines_changed + 1)
log(changelists_created + 1) ***
level **
job_codeENG_TYPE2
job_codeENG_TYPE3
job_codeENG_TYPE4 **
job_codeENG_TYPE5 ***
---
Signif. codes: 0 `***` 0.001 `**` 0.01 `*` 0.05 `.` 0.1 ` ` 1
Residual standard error: 0.885 on 3387 degrees of freedom
Multiple R-squared: 0.02616, Adjusted R-squared: 0.02415
F-statistic: 13 on 7 and 3387 DF, p-value: < 0.00000000000000022
Angka: 7: Model 3: Hasil Regresi Linier Lengkap.
Bibliografi
[1] R. S. Nickerson, “Confirmation bias: A ubiquitous phenomenon in many guises.” Review of general psychology, vol. 2, no. 2, p. 175, 1998.
[2] Y. W. Ramírez and D. A. Nembhard, “Measuring knowledge worker productivity: A taxonomy,” Journal of Intellectual Capital, vol. 5, no. 4, pp. 602–628, 2004.
[3] A. N. Meyer, L. E. Barton, G. C. Murphy, T. Zimmermann, and T. Fritz, “The work life of developers: Activities, switches and perceived productivity,” IEEE Transactions on Software Engineering, 2017.
[4] M. Palvalin, M. Vuolle, A. Jääskeläinen, H. Laihonen, and A. Lönnqvist, “Smartwow–constructing a tool for knowledge work performance analysis,” International Journal of Productivity and Performance Management, vol. 64, no. 4, pp. 479–498, 2015.
[5] C. H. C. Duarte, “Productivity paradoxes revisited,” Empirical Software Engineering, pp. 1–30, 2016.
[6] K. D. Maxwell, L. VanWassenhove, and S. Dutta, “Software development productivity of european space, military, and industrial applications,” IEEE Transactions on Software Engineering, vol. 22, no. 10, pp. 706–718, 1996.
[7] J. D. Blackburn, G. D. Scudder, and L. N. Van Wassenhove, “Improving speed and productivity of software development: a global survey of software developers,” IEEE transactions on software engineering, vol. 22, no. 12, pp. 875–885, 1996.
[8] B. Vasilescu, Y. Yu, H.Wang, P. Devanbu, and V. Filkov, “Quality and productivity outcomes relating to continuous integration in github,” in Proceedings of the 2015 10th Joint Meeting on Foundations of Software Engineering. ACM, 2015, pp. 805–816.
[9] T. Hernaus and J. Mikulic, “Work characteristics and work performance of knowledge workers,” EuroMed Journal of Business, vol. 9, no. 3, pp. 268–292, 2014.
[10] F. P. Morgeson and S. E. Humphrey, “The work design questionnaire (wdq): developing and validating a comprehensive measure for assessing job design and the nature of work.” Journal of applied psychology, vol. 91, no. 6, p. 1321, 2006.
[11] J. R. Idaszak and F. Drasgow, “A revision of the job diagnostic survey: Elimination of a measurement artifact.” Journal of Applied Psychology, vol. 72, no. 1, p. 69, 1987.
[12] M. A. Campion, G. J. Medsker, and A. C. Higgs, “Relations between work group characteristics and effectiveness: Implications for designing effective work groups,” Personnel psychology, vol. 46, no. 4, pp. 823–847, 1993.
[13] T. Hernaus, “Integrating macro-and micro-organizational variables through multilevel approach,” Unpublished doctoral thesis). Zagreb: University of Zagreb, 2010.
[14] S. Wagner and M. Ruhe, “A systematic review of productivity factors in software development,” in Proceedings of 2nd International Workshop on Software Productivity Analysis and Cost Estimation, 2008.
[15] A. N. Meyer, T. Fritz, G. C. Murphy, and T. Zimmermann, “Software developers’ perceptions of productivity,” in Proceedings of the International Symposium on Foundations of Software Engineering. ACM, 2014, pp. 19–29.
[16] R. Antikainen and A. Lönnqvist, “Knowledge work productivity assessment,” Tampere University of Technology, Tech. Rep., 2006.
[17] M. Galesic and M. Bosnjak, “Effects of questionnaire length on participation and indicators of response quality in a web survey,” Public opinion quarterly, vol. 73, no. 2, pp. 349–360, 2009.
[18] L. Beckwith, C. Kissinger, M. Burnett, S. Wiedenbeck, J. Lawrance, A. Blackwell, and C. Cook, “Tinkering and gender in end-user programmers’ debugging,” in Proceedings of the SIGCHI conference on Human Factors in computing systems. ACM, 2006, pp. 231–240.
[19] D. B. Rubin, Multiple imputation for nonresponse in surveys. John Wiley & Sons, 2004, vol. 81.
[20] A. W. Meade and S. B. Craig, “Identifying careless responses in survey data.” Psychological methods, vol. 17, no. 3, p. 437, 2012.
[21] E. Smith, R. Loftin, E. Murphy-Hill, C. Bird, and T. Zimmermann, “Improving developer participation rates in surveys,” in Proceedings of Cooperative and Human Aspects on Software Engineering, 2013.
[22] Y. Benjamini and Y. Hochberg, “Controlling the false discovery rate: a practical and powerful approach to multiple testing,” Journal of the royal statistical society. Series B (Methodological),
pp. 289–300, 1995.
[23] R. A. Guzzo, R. D. Jette, and R. A. Katzell, “The effects of psychologically based intervention programs on worker productivity: A meta-analysis,” Personnel psychology, vol. 38, no. 2, pp.
275–291, 1985.
[24] D. Graziotin, X. Wang, and P. Abrahamsson, “Happy software developers solve problems better: psychological measurements in empirical software engineering,” PeerJ, vol. 2, p. e289, 2014.
[25] J. Noll, M. A. Razzak, and S. Beecham, “Motivation and autonomy in global software development: an empirical study,” in Proceedings of the 21st International Conference on Evaluation
and Assessment in Software Engineering. ACM, 2017, pp. 394–399.
[26] B. Clark, S. Devnani-Chulani, and B. Boehm, “Calibrating the cocomo ii post-architecture model,” in Proceedings of the International Conference on Software Engineering. IEEE, 1998, pp. 477–480.
[27] B. Kitchenham and E. Mendes, “Software productivity measurement using multiple size measures,” IEEE Transactions on Software Engineering, vol. 30, no. 12, pp. 1023–1035, 2004.
[28] S. L. Pfleeger, “Model of software effort and productivity,” Information and Software Technology, vol. 33, no. 3, pp. 224–231, 1991.
[29] G. Finnie and G. Wittig, “Effect of system and team size on 4gl software development productivity,” South African Computer Journal, pp. 18–18, 1994.
[30] D. R. Jeffery, “A software development productivity model for mis environments,” Journal of Systems and Software, vol. 7, no. 2, pp. 115–125, 1987.
[31] L. R. Foulds, M. Quaddus, and M. West, “Structural equation modelling of large-scale information system application development productivity: the hong kong experience,” in Computer and Information Science, 2007. ICIS 2007. 6th IEEE/ACIS International Conference on. IEEE, 2007, pp. 724–731.
[32] C. Parnin and S. Rugaber, “Resumption strategies for interrupted programming tasks,” Software Quality Journal, vol. 19, no. 1, pp. 5–34, 2011.
[33] C. Parnin and R. DeLine, “Evaluating cues for resuming interrupted programming tasks,” in Proceedings of the SIGCHI conference on human factors in computing systems. ACM, 2010, pp. 93–102.
[34] S. Markos and M. S. Sridevi, “Employee engagement: The key to improving performance,” International Journal of Business and Management, vol. 5, no. 12, pp. 89–96, 2010.
[35] W. Snipes, A. R. Nair, and E. Murphy-Hill, “Experiences gamifying developer adoption of practices and tools,” in Companion Proceedings of the 36th International Conference on Software Engineering. ACM, 2014, pp. 105–114.
[36] J. S. Brown and P. Duguid, “Balancing act: How to capture knowledge without killing it.” Harvard business review, vol. 78, no. 3, pp. 73–80, 1999.
[37] M. London and J. W. Smither, “Feedback orientation, feedback culture, and the longitudinal performance management process,” Human Resource Management Review, vol. 12, no. 1,
pp. 81–100, 2002.
[38] T. Savor, M. Douglas, M. Gentili, L. Williams, K. Beck, and M. Stumm, “Continuous deployment at facebook and oanda,” in Proceedings of the 38th International Conference on Software Engineering Companion. ACM, 2016, pp. 21–30.
[39] R. J. Fisher, “Social desirability bias and the validity of indirect questioning,” Journal of consumer research, vol. 20, no. 2, pp. 303–315, 1993.
[40] J. M. Zelenski, S. A. Murphy, and D. A. Jenkins, “The happyproductive worker thesis revisited,” Journal of Happiness Studies, vol. 9, no. 4, pp. 521–537, 2008.
[41] S. Moser and O. Nierstrasz, “The effect of object-oriented frameworks on developer productivity,” Computer, vol. 29, no. 9, pp. 45–51, 1996.
[42] T. DeMarco and T. Lister, “Programmer performance and the effects of the workplace,” in Proceedings of the International Conference on Software Engineering. IEEE Computer Society
Press, 1985, pp. 268–272.
[43] M. Kersten and G. C. Murphy, “Using task context to improve programmer productivity,” in Proceedings of the 14th ACM SIGSOFT international symposium on Foundations of software engineering. ACM, 2006, pp. 1–11.
[44] K. Petersen, “Measuring and predicting software productivity: A systematic map and review,” Information and Software Technology, vol. 53, no. 4, pp. 317–343, 2011.
[45] M. J. Melitz, “The impact of trade on intra-industry reallocations and aggregate industry productivity,” Econometrica, vol. 71, no. 6, pp. 1695–1725, 2003.
[46] M. N. Baily, C. Hulten, D. Campbell, T. Bresnahan, and R. E. Caves, “Productivity dynamics in manufacturing plants,” Brookings papers on economic activity. Microeconomics, vol. 1992, pp. 187–267, 1992.
[47] A. Kidd, “The marks are on the knowledge worker,” in Proceedings of the SIGCHI conference on Human factors in computing systems. ACM, 1994, pp. 186–191.
[48] G. K. Gill and C. F. Kemerer, “Cyclomatic complexity density and software maintenance productivity,” IEEE transactions on software engineering, vol. 17, no. 12, pp. 1284–1288, 1991.
[2] Y. W. Ramírez and D. A. Nembhard, “Measuring knowledge worker productivity: A taxonomy,” Journal of Intellectual Capital, vol. 5, no. 4, pp. 602–628, 2004.
[3] A. N. Meyer, L. E. Barton, G. C. Murphy, T. Zimmermann, and T. Fritz, “The work life of developers: Activities, switches and perceived productivity,” IEEE Transactions on Software Engineering, 2017.
[4] M. Palvalin, M. Vuolle, A. Jääskeläinen, H. Laihonen, and A. Lönnqvist, “Smartwow–constructing a tool for knowledge work performance analysis,” International Journal of Productivity and Performance Management, vol. 64, no. 4, pp. 479–498, 2015.
[5] C. H. C. Duarte, “Productivity paradoxes revisited,” Empirical Software Engineering, pp. 1–30, 2016.
[6] K. D. Maxwell, L. VanWassenhove, and S. Dutta, “Software development productivity of european space, military, and industrial applications,” IEEE Transactions on Software Engineering, vol. 22, no. 10, pp. 706–718, 1996.
[7] J. D. Blackburn, G. D. Scudder, and L. N. Van Wassenhove, “Improving speed and productivity of software development: a global survey of software developers,” IEEE transactions on software engineering, vol. 22, no. 12, pp. 875–885, 1996.
[8] B. Vasilescu, Y. Yu, H.Wang, P. Devanbu, and V. Filkov, “Quality and productivity outcomes relating to continuous integration in github,” in Proceedings of the 2015 10th Joint Meeting on Foundations of Software Engineering. ACM, 2015, pp. 805–816.
[9] T. Hernaus and J. Mikulic, “Work characteristics and work performance of knowledge workers,” EuroMed Journal of Business, vol. 9, no. 3, pp. 268–292, 2014.
[10] F. P. Morgeson and S. E. Humphrey, “The work design questionnaire (wdq): developing and validating a comprehensive measure for assessing job design and the nature of work.” Journal of applied psychology, vol. 91, no. 6, p. 1321, 2006.
[11] J. R. Idaszak and F. Drasgow, “A revision of the job diagnostic survey: Elimination of a measurement artifact.” Journal of Applied Psychology, vol. 72, no. 1, p. 69, 1987.
[12] M. A. Campion, G. J. Medsker, and A. C. Higgs, “Relations between work group characteristics and effectiveness: Implications for designing effective work groups,” Personnel psychology, vol. 46, no. 4, pp. 823–847, 1993.
[13] T. Hernaus, “Integrating macro-and micro-organizational variables through multilevel approach,” Unpublished doctoral thesis). Zagreb: University of Zagreb, 2010.
[14] S. Wagner and M. Ruhe, “A systematic review of productivity factors in software development,” in Proceedings of 2nd International Workshop on Software Productivity Analysis and Cost Estimation, 2008.
[15] A. N. Meyer, T. Fritz, G. C. Murphy, and T. Zimmermann, “Software developers’ perceptions of productivity,” in Proceedings of the International Symposium on Foundations of Software Engineering. ACM, 2014, pp. 19–29.
[16] R. Antikainen and A. Lönnqvist, “Knowledge work productivity assessment,” Tampere University of Technology, Tech. Rep., 2006.
[17] M. Galesic and M. Bosnjak, “Effects of questionnaire length on participation and indicators of response quality in a web survey,” Public opinion quarterly, vol. 73, no. 2, pp. 349–360, 2009.
[18] L. Beckwith, C. Kissinger, M. Burnett, S. Wiedenbeck, J. Lawrance, A. Blackwell, and C. Cook, “Tinkering and gender in end-user programmers’ debugging,” in Proceedings of the SIGCHI conference on Human Factors in computing systems. ACM, 2006, pp. 231–240.
[19] D. B. Rubin, Multiple imputation for nonresponse in surveys. John Wiley & Sons, 2004, vol. 81.
[20] A. W. Meade and S. B. Craig, “Identifying careless responses in survey data.” Psychological methods, vol. 17, no. 3, p. 437, 2012.
[21] E. Smith, R. Loftin, E. Murphy-Hill, C. Bird, and T. Zimmermann, “Improving developer participation rates in surveys,” in Proceedings of Cooperative and Human Aspects on Software Engineering, 2013.
[22] Y. Benjamini and Y. Hochberg, “Controlling the false discovery rate: a practical and powerful approach to multiple testing,” Journal of the royal statistical society. Series B (Methodological),
pp. 289–300, 1995.
[23] R. A. Guzzo, R. D. Jette, and R. A. Katzell, “The effects of psychologically based intervention programs on worker productivity: A meta-analysis,” Personnel psychology, vol. 38, no. 2, pp.
275–291, 1985.
[24] D. Graziotin, X. Wang, and P. Abrahamsson, “Happy software developers solve problems better: psychological measurements in empirical software engineering,” PeerJ, vol. 2, p. e289, 2014.
[25] J. Noll, M. A. Razzak, and S. Beecham, “Motivation and autonomy in global software development: an empirical study,” in Proceedings of the 21st International Conference on Evaluation
and Assessment in Software Engineering. ACM, 2017, pp. 394–399.
[26] B. Clark, S. Devnani-Chulani, and B. Boehm, “Calibrating the cocomo ii post-architecture model,” in Proceedings of the International Conference on Software Engineering. IEEE, 1998, pp. 477–480.
[27] B. Kitchenham and E. Mendes, “Software productivity measurement using multiple size measures,” IEEE Transactions on Software Engineering, vol. 30, no. 12, pp. 1023–1035, 2004.
[28] S. L. Pfleeger, “Model of software effort and productivity,” Information and Software Technology, vol. 33, no. 3, pp. 224–231, 1991.
[29] G. Finnie and G. Wittig, “Effect of system and team size on 4gl software development productivity,” South African Computer Journal, pp. 18–18, 1994.
[30] D. R. Jeffery, “A software development productivity model for mis environments,” Journal of Systems and Software, vol. 7, no. 2, pp. 115–125, 1987.
[31] L. R. Foulds, M. Quaddus, and M. West, “Structural equation modelling of large-scale information system application development productivity: the hong kong experience,” in Computer and Information Science, 2007. ICIS 2007. 6th IEEE/ACIS International Conference on. IEEE, 2007, pp. 724–731.
[32] C. Parnin and S. Rugaber, “Resumption strategies for interrupted programming tasks,” Software Quality Journal, vol. 19, no. 1, pp. 5–34, 2011.
[33] C. Parnin and R. DeLine, “Evaluating cues for resuming interrupted programming tasks,” in Proceedings of the SIGCHI conference on human factors in computing systems. ACM, 2010, pp. 93–102.
[34] S. Markos and M. S. Sridevi, “Employee engagement: The key to improving performance,” International Journal of Business and Management, vol. 5, no. 12, pp. 89–96, 2010.
[35] W. Snipes, A. R. Nair, and E. Murphy-Hill, “Experiences gamifying developer adoption of practices and tools,” in Companion Proceedings of the 36th International Conference on Software Engineering. ACM, 2014, pp. 105–114.
[36] J. S. Brown and P. Duguid, “Balancing act: How to capture knowledge without killing it.” Harvard business review, vol. 78, no. 3, pp. 73–80, 1999.
[37] M. London and J. W. Smither, “Feedback orientation, feedback culture, and the longitudinal performance management process,” Human Resource Management Review, vol. 12, no. 1,
pp. 81–100, 2002.
[38] T. Savor, M. Douglas, M. Gentili, L. Williams, K. Beck, and M. Stumm, “Continuous deployment at facebook and oanda,” in Proceedings of the 38th International Conference on Software Engineering Companion. ACM, 2016, pp. 21–30.
[39] R. J. Fisher, “Social desirability bias and the validity of indirect questioning,” Journal of consumer research, vol. 20, no. 2, pp. 303–315, 1993.
[40] J. M. Zelenski, S. A. Murphy, and D. A. Jenkins, “The happyproductive worker thesis revisited,” Journal of Happiness Studies, vol. 9, no. 4, pp. 521–537, 2008.
[41] S. Moser and O. Nierstrasz, “The effect of object-oriented frameworks on developer productivity,” Computer, vol. 29, no. 9, pp. 45–51, 1996.
[42] T. DeMarco and T. Lister, “Programmer performance and the effects of the workplace,” in Proceedings of the International Conference on Software Engineering. IEEE Computer Society
Press, 1985, pp. 268–272.
[43] M. Kersten and G. C. Murphy, “Using task context to improve programmer productivity,” in Proceedings of the 14th ACM SIGSOFT international symposium on Foundations of software engineering. ACM, 2006, pp. 1–11.
[44] K. Petersen, “Measuring and predicting software productivity: A systematic map and review,” Information and Software Technology, vol. 53, no. 4, pp. 317–343, 2011.
[45] M. J. Melitz, “The impact of trade on intra-industry reallocations and aggregate industry productivity,” Econometrica, vol. 71, no. 6, pp. 1695–1725, 2003.
[46] M. N. Baily, C. Hulten, D. Campbell, T. Bresnahan, and R. E. Caves, “Productivity dynamics in manufacturing plants,” Brookings papers on economic activity. Microeconomics, vol. 1992, pp. 187–267, 1992.
[47] A. Kidd, “The marks are on the knowledge worker,” in Proceedings of the SIGCHI conference on Human factors in computing systems. ACM, 1994, pp. 186–191.
[48] G. K. Gill and C. F. Kemerer, “Cyclomatic complexity density and software maintenance productivity,” IEEE transactions on software engineering, vol. 17, no. 12, pp. 1284–1288, 1991.